大模型训练 Pipeline Parallel 流水并行性能有没有什么评价指标?或者分析方法?
在华仔负责大模型训练,目前对大模型进行性能分析和调试调优,直接看底层每个计算、通信、么个线程的空隙和执行时间,就太细了,完全分析不出来。于是就提出了一个很重要的疑问,那这个问题就跟题主的问题相同啦!
在华仔负责大模型训练,目前对大模型进行性能分析和调试调优,直接看底层每个计算、通信、么个线程的空隙和执行时间,就太细了,完全分析不出来。
于是就提出了一个很重要的疑问,pytorch是否有手段,能够快速分析出,大模型的训练&推理在各个阶段:
每个迭代端到端耗时、正反向耗时、特别是分布式并行策略DP/TP/PP的通信、PP bubble ration的大粒度算法层面相关的耗时数据,而不是细粒度分析Profiling再人工提取分析?
那这个问题就跟题主的问题相同啦!在大模型训练过程中,我们应该如何分析PP的性能占比和耗时。首先需要有一个理论的评价指标,根据理论的评价指标对比,具体使用哪种流水并行策略,看看实际大模型训练的Profiling结果,流水并行PP策略下,理论Bubble Size跟实测Bubble Size之间的差异。
流水并行 PP 评价指标
流水并行(Pipeline Parallelism,PP)中,针对流水并行(PP)假设并行的stage 切分为p 份,micro-batches 为m,每个micro-batches 的前向和后向执行时间为tf 和tb。在理想的环境下,前向和后向的合起来理想的执行时间应该是:
![]()
不过在实际 Pipeline 把网络模型切分成不同 stage 放在不同的机器,会导致在正向的 p - 1 和反向的 p – 1 时间内会出现计算等待时间。那这个中间空白的地方,我们叫做 Bubble 空泡。
而空泡 Bubble 的产生,是因为算子内并行和算子间并行解决单设备内存不足的问题,模型经过拆分后的上一个 rank 的 stage 需要长期持续处于空闲状态,等待 其他 rank 的 stage 计算完成,才可以开始计算,这极大降低了设备的平均使用率。这种现象被称为并行空泡(Parallelism Bubble)。
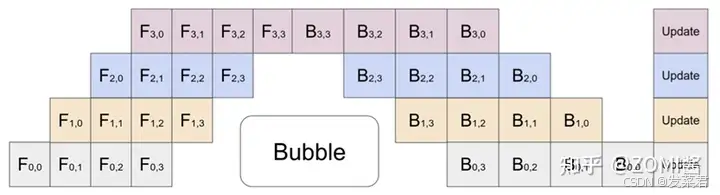

反倒是重计算过程主要是针对网络模型的正向计算,反向计算的时候会跟计算通信重叠,因此流水线并行(PP)引入的气泡不会严重消耗训练效率。
为了充分提升算力利用率,也即是充分发挥硬件的算力,最好的做法是把大模型按照模型并行(实际上优先采用张量并行 TP),如果可以的话加上流水并行PP,把模型并行的机器节点的内存全占满。在这个前提下的话,就可以自由地调整流水线并行(PP)和张量并行(TP)的比例。
由于数据并行(DP)几乎不影响计算时间,假设数据并行(DP)参数设置为 d=1,节点数为n,张量并行(TP)设置为 t,流水并行(PP)设置为 p,并且满足 n=t×p。
流水并行算法
回过头来看看流水并行,实际上流水并行的策略和算法很多,目前主要是Google、微软、NVIDIA三家厂商提出来的5种不同的算法。下面我们来盘点下流水并行的几个算法,还有流水并行的特点,然后看看实际测试过程中遇到的问题和实际的评价指标。
Native
朴素的流水线并行,同一时刻只有一个设备进行计算,其余设备处于空闲状态,计算设备利用率通常较低。
GPipe
将朴素流水线并行的 batch 再进行切分,减小设备间空闲状态的时间,可以显著提升流水线并行设备利用率。其实也是 F-then-B 调度方式所示,将原本的 mini-batch(数据并行切分后的batch)划分成多个 micro-batch(mini-batch再切分后的batch),每个 pipeline stage (流水线并行的计算单元)先整体进行前向计算,再进行反向计算。通过在同一时刻分别计算模型的不同部分,F-then-B 可以显著提升设备资源利用率。但也不难看出这种 F-then-B 模式由于缓存了多个 micro-batch 的中间变量和梯度,显存的实际利用率并不高。
1F1B
1F1B (在流水线并行中,pipeline stage 前向计算和反向计算交叉进行的方式)流水线并行方式解决了这个问题。在 1F1B 模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。
PipeDream
PipeDream 在单个 GPU 上进行短暂的运行时性能分析后,可以自动决定怎样分割这些 DNN 算子,如何平衡不同 stage 之间的计算负载,而同时尽可能减少目标平台上的通信量。PipeDream将DNN的这些层划分为多个阶段——每个阶段(stage)由模型中的一组连续层组成。PipeDream把模型的不同的阶段部署在不同的机器上,每个阶段可能有不同的replication。该阶段对本阶段中所有层执行向前和向后传递。PipeDream将包含输入层的阶段称为输入阶段,将包含输出层的阶段称为输出阶段。
Virtual Pipe
virtual pipeline 是 Megatron-2 这篇论文中最主要的一个创新点。传统的 pipeline 并行通常会在一个 Device 上放置几个 block,我理解这是为了扩展效率考虑,在计算强度和通信强度中间取一个平衡。但 virtual pipeline 的却反其道而行之,在 device 数量不变的情况下,分出更多的 pipeline stage,以更多的通信量,换取空泡比率降低,减小了 step e2e 用时。
性能评价结论
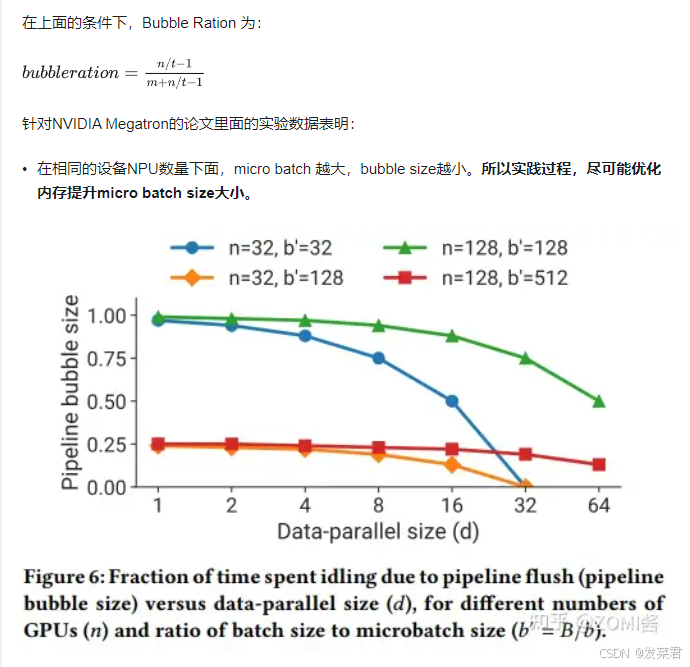
实际验证分析可以发现,增加张量并行(TP)的大小,将会减少泡沫比率(Bubble Ration),也就是提高了整体的利用率减少卡间不同步等待的时间。不过,张量并行(TP)的大小不能无限增加,因为张量并行(TP)会拆分模型降低整体的计算粒度,一般默认张量并行(TP)最大不夸节点,节点内可以增大。
因此可以得出一个简单的结论,张量并行(TP)的大小应该增加随着模型尺寸的增加而缓慢增加,但并行数不超过单个节点。在经过一系列猛烈的操作和实验之后,得到张量并行(TP)最好的配置是:
4\le t\le8
其中参数 t 为张量并行的维度。在 GLM-130B 模型验证过程中,可以知道当 micro-batches(m)=176,p(PP) =8,Bubble size 为 3.8%,足以证明流水线模型并行的效率。如果在 910B 上是 1*16 的机器,模型是千亿 t 尽可能得在 4~16 之间,PP 减少跨服务器节点。
实际实验证明,当 m≥4p 时,在整体计算的过程当中会加上重计算技术来降低内存的消耗,因此 pipeline 中的 bubble ration 的百分比会降低到一个可以忽略的比例,所以最终的 bubble ration 应该是很低。
重计算过程主要是针对网络模型的正向计算,反向计算的时候会跟计算通信重叠,因此流水线并行(PP)引入的气泡不会严重消耗训练效率。
因此,在大模型训练过程中,我们应该如何分析PP的性能占比和耗时?首先需要有一个理论的评价指标,根据理论的评价指标对比,具体使用哪种流水并行策略,看看实际大模型训练的Profiling结果,流水并行PP策略下,理论Bubble Size跟实测Bubble Size之间的差异。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献243条内容
已为社区贡献243条内容

所有评论(0)