【机器学习】朴素贝叶斯实战
·
1.贝叶斯公式
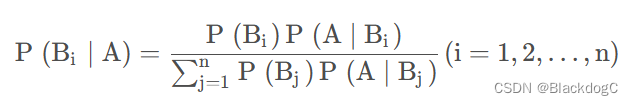
在事件A已经发生的条件下,贝叶斯公式可用来寻找导致A发生的各种原因B的概率。
2.朴素贝叶斯分类器
原始的贝叶斯分类器最大的问题在于联合概率密度函数的估计,首先需要根据经验来假设联合概率分布,其次当属性很多时,训练样本往往覆盖不够,参数的估计会出现很大的偏差。为了避免这个问题,朴素贝叶斯分类器(naive Bayes classifier)采用了“属性条件独立性假设”,即对已知类别,假设所有属性相互独立。换言之,假设每个属性独立地对分类结果发生影响。
1.设置参数
设样本属性集合为x{x1,x2,x3......xn},n为数目,xi为取值;设c为类别集合,把样本划分为某一类,c={y1,y2,y3......ym}.
2.计算后验概率
![]()
3.计算概率
计算各个划分的条件概率 是朴素贝叶斯分类的基础步骤,当特征属性为离散值时,能很方便的统计训练样本中各个划分在每个类别中出现的频率即可用来估计 ,
当特征属性为连续值时,通常假定其值服从高斯分布(也称正态分布)。即:
![]()
只要计算出训练样本中各个类别中此特征项划分的各均值和标准差,代入上述公式即可得到需要的估计值。
简单实现垃圾邮件分类
假设24封用来做训练集,只留一封用来做测试集
def load_file(path):
cab=[]
for i in range(1, 25):
data=open(path %i)
for line in data.readlines():
cab.append(line.strip().split(','))
cab_f=[]
for i in range(len(cab)):
for j in range(len(cab[i])):
if cab[i][j]!='':
cab_f.append(cab[i][j].strip())
cab_final=[]
for i in cab_f:
for j in i.split(' '):
cab_final.append(j)
return cab_final
def bayes(test):
path1='Training/normal/%d.txt'
path2='Training/spam/%d.txt'
normal_data=load_file(path1)
spam_data=load_file(path2)
# 计算p(x|C1)=p1与p(x|C2)=p2
p1=1.0;p2=1.0
for i in range(len(test)):
x=0.0
for j in normal_data:
if test[i]==j:
x=x+1.0
p1=p1*((x+1.0)/(len(normal_data)+2.0)) #拉普拉斯平滑
for i in range(len(test)):
x=0.0
for j in spam_data:
if test[i]==j:
x=x+1.0
p2=p2*((x+1.0)/(len(spam_data)+2.0)) #拉普拉斯平滑
pc1 = len(normal_data) / (len(normal_data)+len(spam_data))
pc2 = 1 - pc1
if p1*pc1>p2*pc2:
return 'normal'
else:
return 'spam'
def test(path):
data=open(path)
cab=[]
for line in data.readlines():
cab.append(line.strip().split(','))
cab_f = []
for i in range(len(cab)):
for j in range(len(cab[i])):
if cab[i][j] != '':
cab_f.append(cab[i][j].strip())
cab_final = []
for i in cab_f:
for j in i.split(' '):
cab_final.append(j)
return bayes(cab_final)
if __name__=='__main__':
print(test('test/normal/25.txt'))
print(test('test/spam/25.txt'))
sum1=0;sum2=0
#再试试训练集
for i in range(1,25):
if test('Training/normal/%d.txt' %i)=='normal':
sum1=sum1+1
for i in range(1,25):
if test('Training/spam/%d.txt' %i)== 'spam':
sum2=sum2+1
print('normal分类正确率:',sum1/24)
print('spam分类正确率:', sum2/24)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)