机器学习——基于KNN算法求PR曲线和ROC曲线
性能度量是对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量。# 生成数据# 划分训练集和测试集# 训练 KNN 模型# 预测概率# 计算 PR 曲线pr_auc = auc(recall[::-1], precision[::-1]) # 确保 recall 是单调递增的# 计算 ROC 曲线# 绘制 PR 曲线# 绘制 ROC 曲线p
基于KNN算法求PR曲线和ROC曲线
KNN算法基本原理
KNN算法又称K邻近算法。K近邻算法(K-Nearest Neighbors,简称KNN)是一种用于分类和回归的统计方法。KNN 可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一。
KNN的基本原理:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在训练数据集中找到与新数据最邻近的 K 个实例,如果这 K 个实例的多数属于某个类别,那么新数据就属于这个类别。即由那些离新数据最近的 K 个实例来投票决定新数据归为哪一类。
分类模型的性能度量
概述
性能度量是对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量。
混淆矩阵
混淆矩阵是一种用于评估分类模型性能的重要工具。它通过矩阵形式清晰地展示了模型对样本进行分类的结果,帮助我们理解模型在不同类别上的表现。
混淆矩阵的基本结构: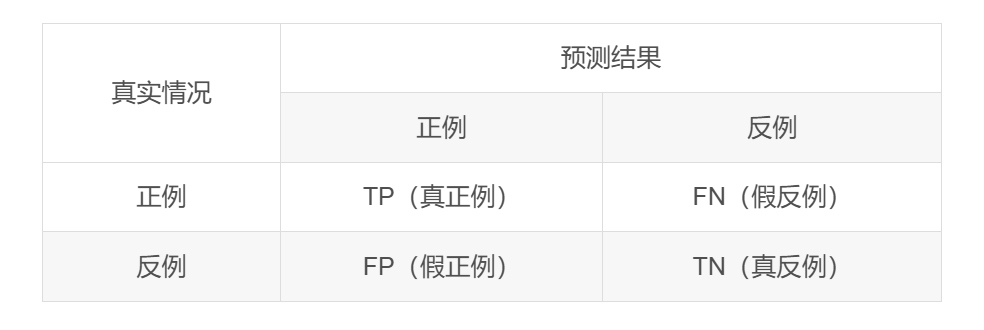
· TP: 模型将实际为正类别的样本正确预测为正类别。
· FN: 模型将实际为正类别的样本错误预测为负类别。
· FP: 模型将实际为负类别的样本错误预测为正类别。
· TN: 模型将实际为负类别的样本正确预测为负类别。
这些元素帮助我们理解模型在分类任务中所做的预测,并将这些预测与实际情况进行对比。
精确率(查准率)
预测结果为正例样本中真实为正例的比例(查得准)
Precision = TP/(TP+FP)
即正确预测的正例数 /预测正例总数
召回率(查全率)
真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力)
Recall = TP/(TP+FN)
即正确预测的正例数 /实际正例总数

PR曲线
在很多情形下,我们可根据学习器的预测结果对样例进行排序,排在前面的是学习器认为"最可能"是正例的样本,排在最后的则是学习器认为"最不可能"是正例的样本。按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的查全率、查准率,以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称"P-R 曲线"。
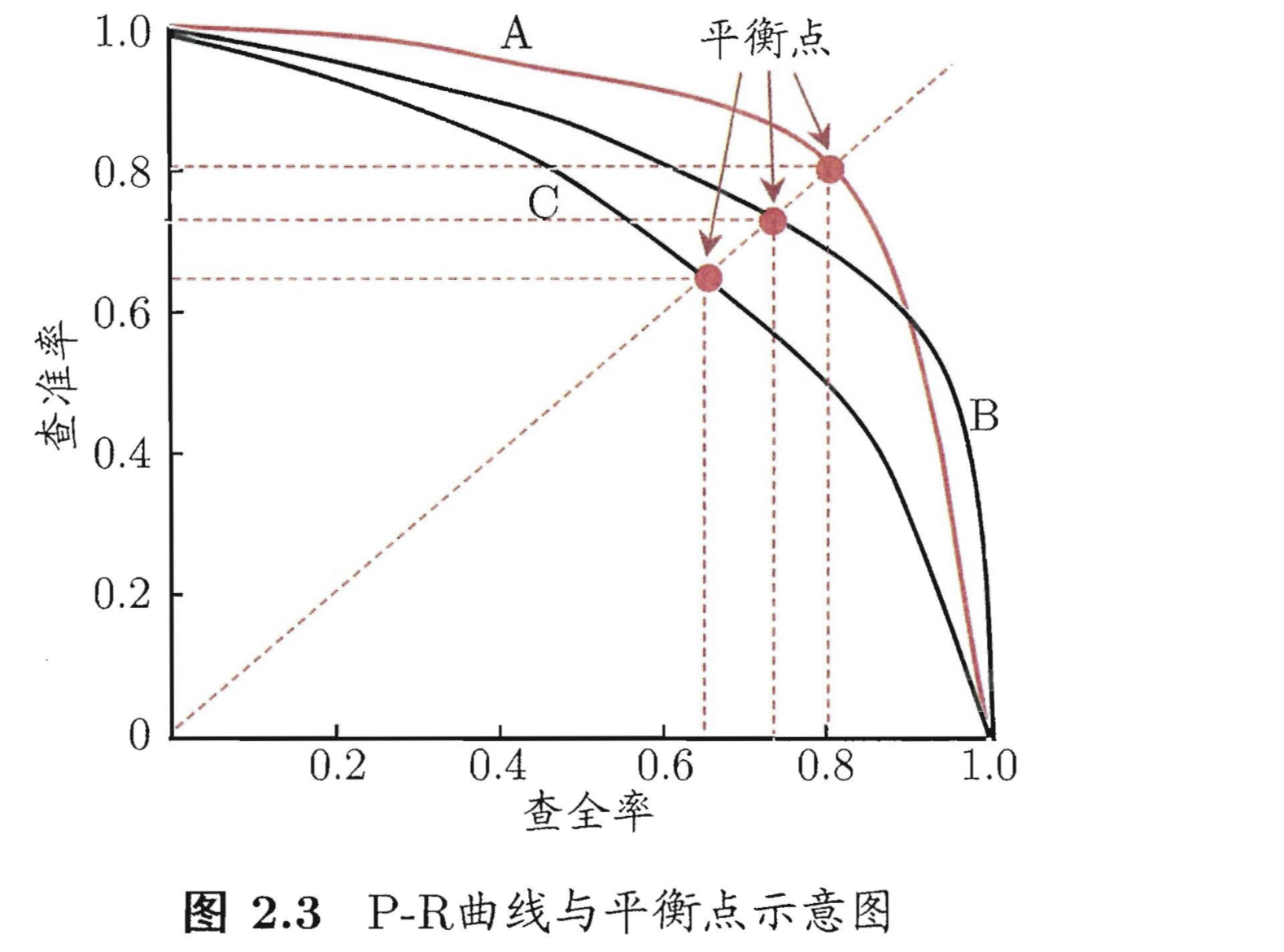
如何通过P-R曲线比较两个机器学习模型的效果:
(1)若一个学习器的P-R 曲线被另一个学习器的曲线完全"包住" , 则可断言后者的性能优于前者, 例如图2.3 中学习器A 的性能优于学习器C;
(2) 如果两个学习器的P-R 曲线发生了交叉, 例如图2.3 中的A 与B,则难以一般性地断言两者的优劣。其中一个的判断依据是,当P=R时成为平衡点(BEP),如果这个值较大,则说明学习器的性能较好。所以 PR 曲线越靠近右上角性能越好。另一个判断依据是,比较P-R曲线下面积的大小,它在一定程度上表征了学习器在查准率和查全率上取得相对"双高"的比例,面积越大性能越好。
ROC曲线
ROC曲线(Receiver Operating Characteristic Curve)是用来评估二分类模型性能的一种常见方法。它是基于分类模型对不同阈值下的预测结果进行排序,并计算真正率(True Positive Rate,即召回率)和假正率(False Positive Rate)之间的关系而得到的曲线。
· 真正率指分类器在所有实际为正例中正确预测为正例的比例,可以通过以下公式计算: 真正率 = TP / (TP + FN)
· 假正率指分类器在所有实际为负例中错误预测为正例的比例,可以通过以下公式计算: 假正率 = FP / (FP + TN)
ROC曲线横轴表示假正率(FPR),纵轴表示真正率(TPR)。分类器在不同阈值下会得到一系列不同的真正率和假正率值,通过将这些值以假正率为横坐标、真正率为纵坐标绘制成曲线,即为ROC曲线。曲线上每个点表示了在对应假正率下的最大真正率值。因此ROC曲线越靠近左上角性能越好。
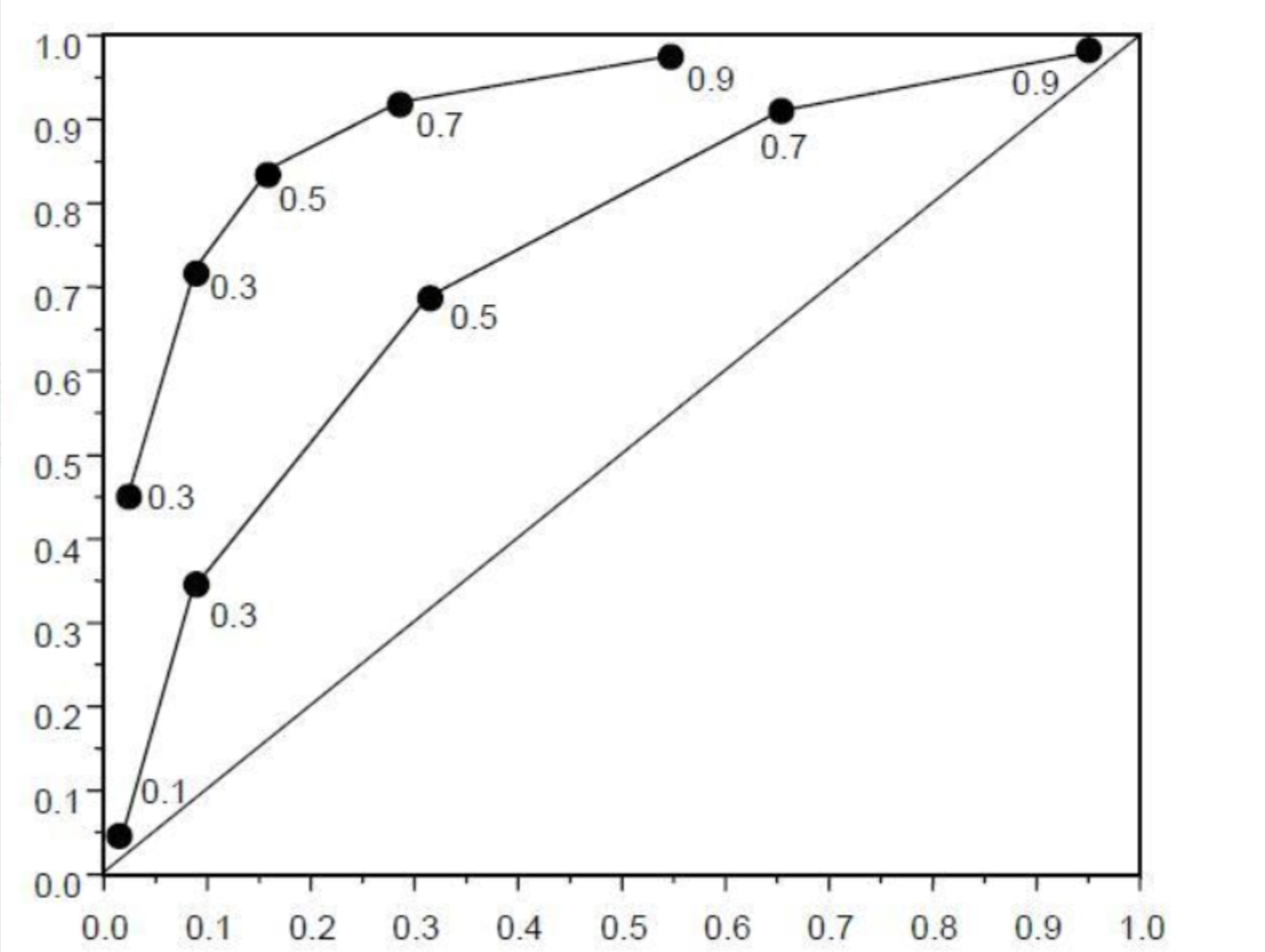
如何通过ROC曲线比较两个机器学习模型的效果:
·ROC曲线的面积越大,表示分类模型在FPR和TPR之间有更好的权衡,性能越好。常用的评估指标是ROC曲线下的面积,即ROC AUC(Area Under the ROC Curve),范围在0到1之间,数值越大越好。
代码实战
创建模拟数据集
该数据集调用sklearn库中的make_classification()函数,生成5000个两个特征的二分类样本。
def createData():
features, actual_labels = make_classification(n_samples=5000, n_classes=2, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1)
return features, actual_labels
# 生成数据
features, actual_labels = createData()
划分训练集和测试集
按7:3比例随机拆分训练集和测试集
# 划分训练集和测试集
features_train_set, features_test_set, labels_train_set, labels_test_set = train_test_split(features, actual_labels, test_size=0.3, random_state=0)
KNN模型训练
初始化KNN分类器(K=3)并用训练数据拟合模型。
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(features_train_set, labels_train_set)
模型预测
获取测试样本属于正类的预测概率(predict_proba)
labels_scores = knn.predict_proba(features_test_set)[:, 1]
PR曲线计算与绘制
计算并绘制精确率-召回率曲线,评估类别不平衡时的性能。
# 计算 PR 曲线
precision, recall, _ = precision_recall_curve(labels_test_set, labels_scores)
pr_auc = auc(recall[::-1], precision[::-1]) # 确保 recall 是单调递增的
# 绘制 PR 曲线
plt.figure(figsize=(20, 6))
plt.subplot(1, 2, 1)
plt.plot(recall, precision, label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc="lower left")
ROC曲线计算与绘制
计算并绘制真/假阳性率曲线,附加对角线作为随机分类基准。
# 计算 ROC 曲线
fpr, tpr, _ = roc_curve(labels_test_set, labels_scores)
roc_auc = auc(fpr, tpr)
# 绘制 ROC 曲线
plt.subplot(1, 2, 2)
plt.plot(fpr, tpr, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--') # 对角线参考线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc="lower right")
显示图片
# 显示图像
plt.show()
总结
全部代码
from sklearn.metrics import auc, precision_recall_curve, roc_curve
from sklearn.datasets import make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
def createData():
features, actual_labels = make_classification(n_samples=5000, n_classes=2, n_features=2, n_informative=2,n_redundant=0, n_clusters_per_class=1)
return features, actual_labels
# 生成数据
features, actual_labels = createData()
# 划分训练集和测试集
features_train_set, features_test_set, labels_train_set, labels_test_set = train_test_split(features, actual_labels, test_size=0.3, random_state=0)
# 训练 KNN 模型
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(features_train_set, labels_train_set)
# 预测概率
labels_scores = knn.predict_proba(features_test_set)[:, 1]
# 计算 PR 曲线
precision, recall, _ = precision_recall_curve(labels_test_set, labels_scores)
pr_auc = auc(recall[::-1], precision[::-1]) # 确保 recall 是单调递增的
# 计算 ROC 曲线
fpr, tpr, _ = roc_curve(labels_test_set, labels_scores)
roc_auc = auc(fpr, tpr)
# 绘制 PR 曲线
plt.figure(figsize=(20, 6))
plt.subplot(1, 2, 1)
plt.plot(recall, precision, label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc="lower left")
# 绘制 ROC 曲线
plt.subplot(1, 2, 2)
plt.plot(fpr, tpr, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--') # 对角线参考线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc="lower right")
# 显示图像
plt.show()
运行结果
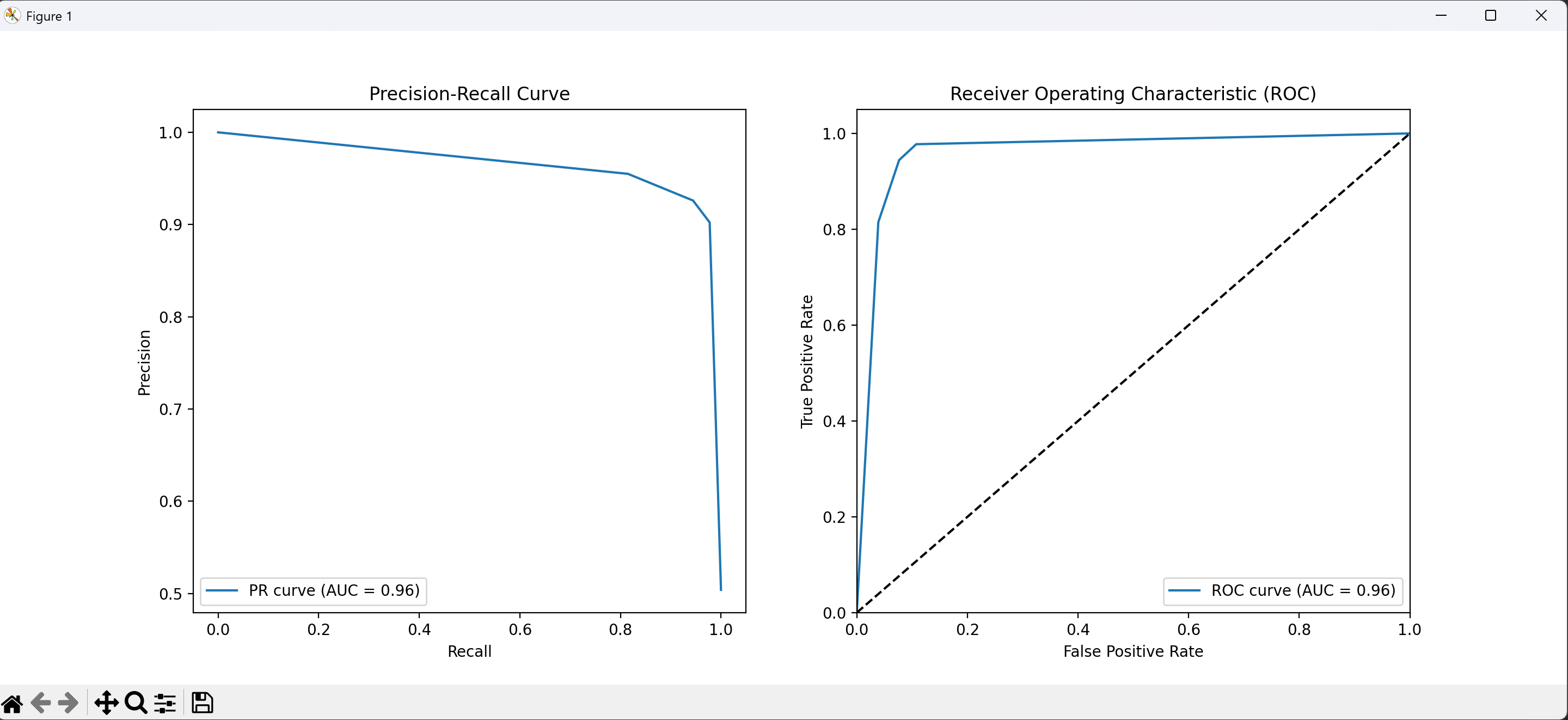
感受
通过PR和ROC两种互补的评估曲线,可以全面了解模型在不同阈值下的表现,AUC值则提供了量化的性能指标。这种评估方式适用于大多数二分类问题,是机器学习中的重要分析方法。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)