Pycharm搭建pytorch、cuda环境;用深度学习方法(cnn,yolo等)实现目标检测、多分类任务。(最基础简单的版本一)
1.Tensor,中文叫张量。Tensor实际上就是一个多维数组(multidimensional而Tensor的目的是能够创造更高维度的矩阵、向量。2.
一:Pycharm环境


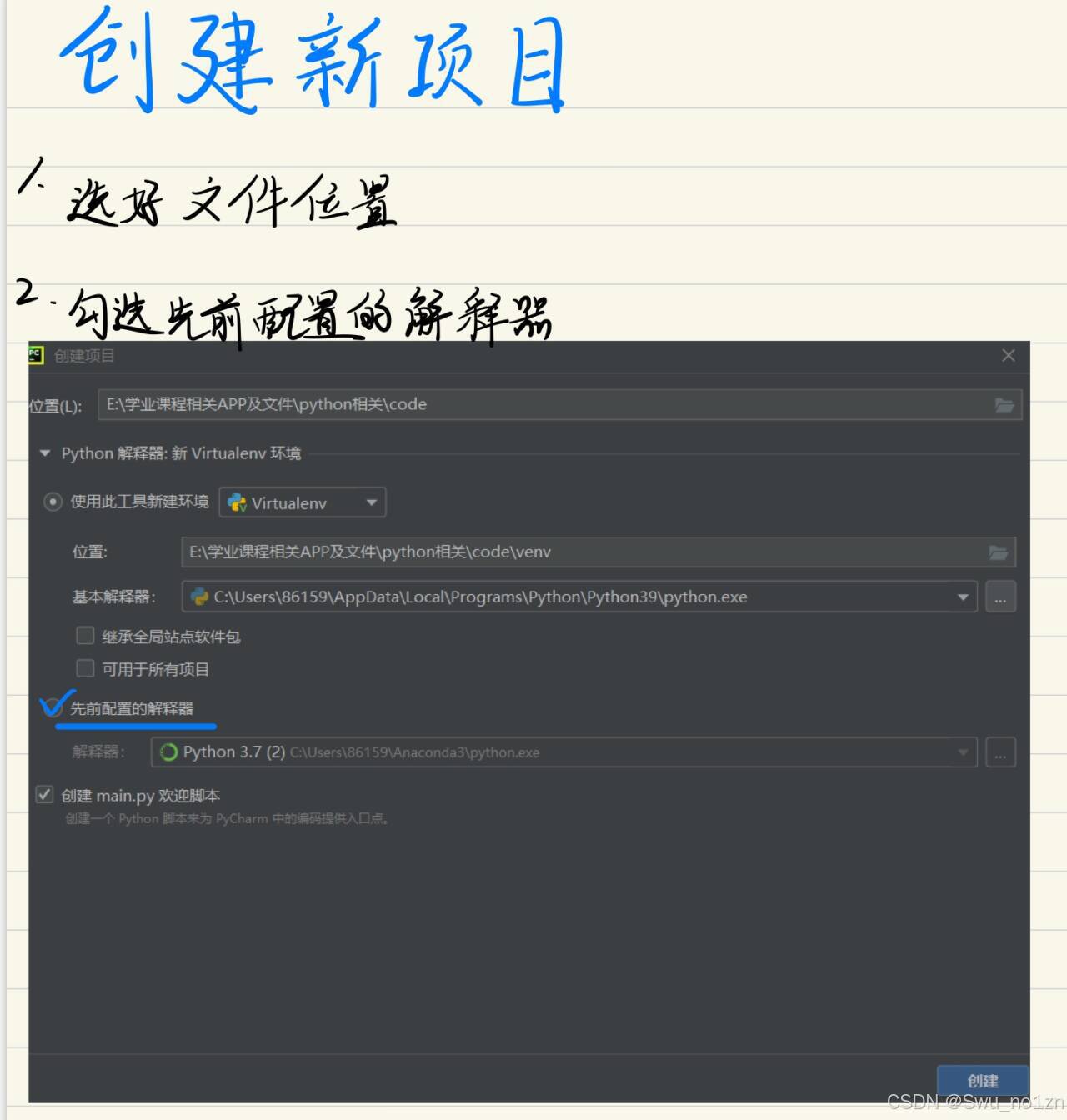
二:深度学习一些基础知识:
1.Tensor,中文叫张量。Tensor实际上就是一个多维数组(multidimensional array)。
而Tensor的目的是能够创造更高维度的矩阵、向量。
2.
三.载入数据集方法及结果(用imagefolder)
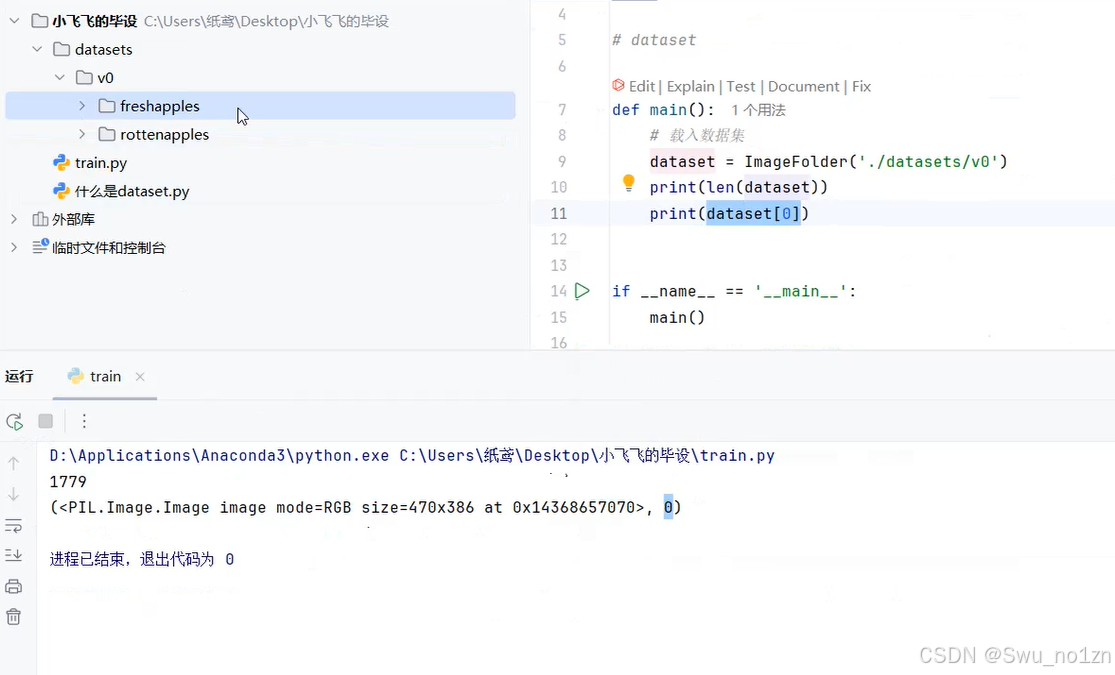
0代表freshapples这个类别,1代表rottenapples
4.查看载入的数据格式以及理解分辨率和像素的定义
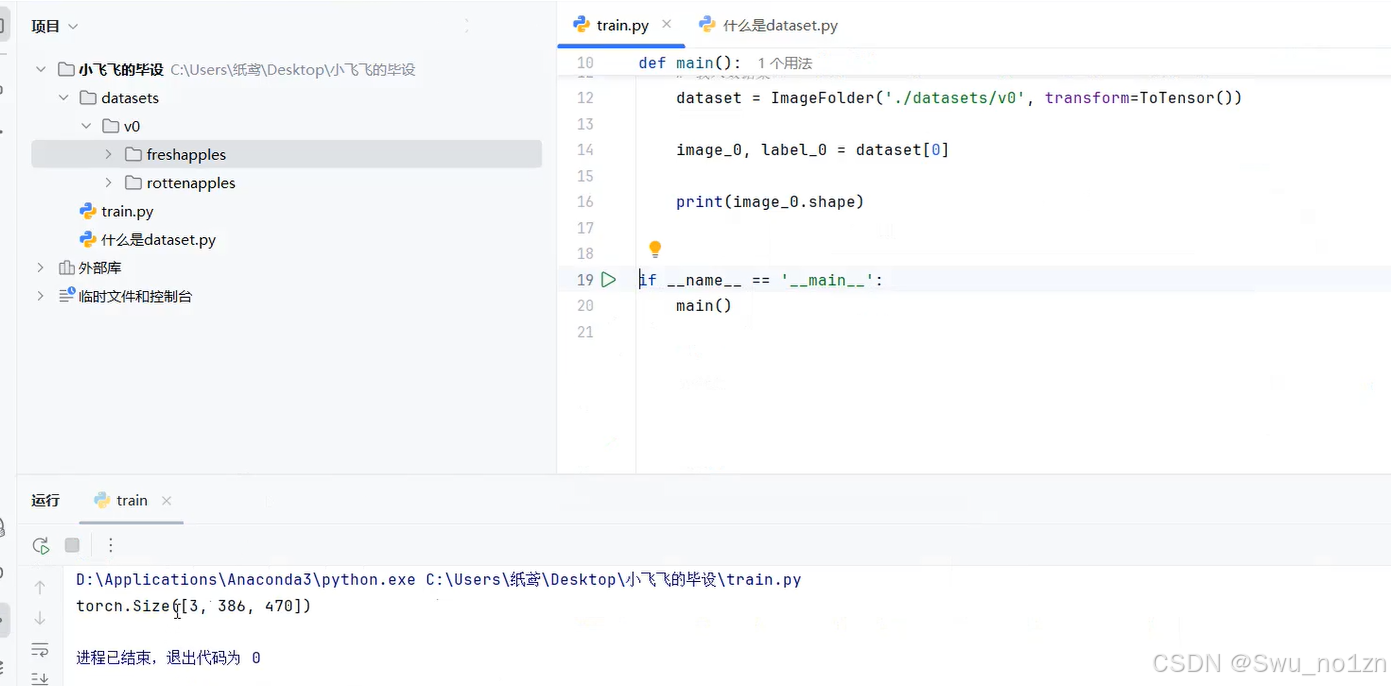
这里的代码是看看这个载入的数据到底是个啥,.shape打印出来是:3是RGB,386和470是分辨率。
图像分辨率:通常指图像中包含的像素数量。它可以表示为水平像素数和垂直像素数的乘积。
像素:图像中的最小单位,每个像素代表图像中的一个点。
颜色信息:每个像素通常包含颜色信息,这些信息可以是灰度值(对于灰度图像)或红、绿、蓝(RGB)值(对于彩色图像)。
5.

6:卷积神经网络 – CNN 最擅长的就是图片的处理。它受到人类视觉神经系统的启发。


四:具体新项目创建方法、文件规划、实践编程、代码逻辑理解等参考保存下来的文件和腾讯会议保存的录像。
文件规划:py文件和datasets文件夹还有这些单个的测试图像都是并列的,都是同一个上司文件(基于Yolo......)
五.详细实验过程数据保存:
1.train.py代码:
import torchvision
import torch
from models import CNN
from torch.optim import SGD, AdamW
from torch.nn import CrossEntropyLoss
from torch.utils.data import random_split, DataLoader #引入以方便划分数据集
from torchvision.datasets import ImageFolder #引入可以将文件夹中图片载入进来的函数
from torchvision.transforms import ToTensor, Resize, Compose #引入可以把图片格式转换为pytorch的数组tensor格式的函数,resize是为了统一
#图片分辨率,compose是前两者将其组合起来
from torchvision.models import resnet18
from matplotlib import pyplot as plt #引入可以将图片展示出来的包
# dataset
def main():
# 训练设备,使用gpu
device = 'cuda'
# 载入数据集 载入进来是图片,因此用transform转换为可以被神经网络接受的数组tensor 矩阵吗?
dataset = ImageFolder('./datasets/v0', transform=Compose([
Resize([200, 200]), #将分辨率统一到3(RGB)×200×200
ToTensor()
]))
print('这是dataset.class_to_idx')
print(dataset.class_to_idx) #Augmented Banana Black Sigatoka Disease': 0, 'Augmented Banana Bract Mosaic Virus Disease': 1......
# 划分数据集
train_dataset, eval_dataset = random_split(
dataset=dataset,
lengths=[0.75, 0.25]
)
# 载入数据
# mini-batch 神经网络的学习也是从训练数据中选出一批数据(称为mini-batch,小批量),然后对每个mini-batch进行学习,称为mini-batch学习
train_dataloader = DataLoader(
dataset=train_dataset,
batch_size=32, #32张图片同时输入同时输出(一次处理32张)
shuffle=True
)
print('这是train_dataloader')
print(train_dataloader)
eval_dataloader = DataLoader(
dataset=eval_dataset,
batch_size=32,
shuffle=True
)
# 载入模型
model = CNN().to(device)
print("这是model")
print(model)
# 载入损失函数
criterion = CrossEntropyLoss()
# 优化器
optimizer = AdamW(model.parameters())
# 开始训练
total_train_accuracies = [] #训练集的准确率
total_eval_accuracies = [] #测试集的准确率
for epoch in range(30):
train_accuracies = 0
eval_accuracies = 0
# 训练
model.train()
for idx, (images, labels) in enumerate(train_dataloader):
images = images.to(device)
labels = labels.to(device)
#对训练集的处理三个步骤:
out = model(images) #推理一次
loss = criterion(out, labels) #计算一次误差
loss.backward()
optimizer.step() #优化一次
optimizer.zero_grad()
n = (out.argmax(dim=1) == labels).cpu().detach().numpy().sum() #判断训练的结果是否与标签一致,argmax是找出概率更大的那个位置
train_accuracies += n #看是否与标签一致,一致+1,不一致+0
print("这是out:") #可查看out是什么数据
print(out)
# 验证
model.eval()
for idx, (images, labels) in enumerate(eval_dataloader):
images = images.to(device)
labels = labels.to(device)
out = model(images)
loss = criterion(out, labels)
n = (out.argmax(dim=1) == labels).cpu().detach().numpy().sum()
eval_accuracies += n
train_s = train_accuracies / len(train_dataset) #得出正确率
eval_s = eval_accuracies / len(eval_dataset)
total_train_accuracies.append(train_s) #向列表末尾添加元素(正确率),方便后续画出折线图
total_eval_accuracies.append(eval_s)
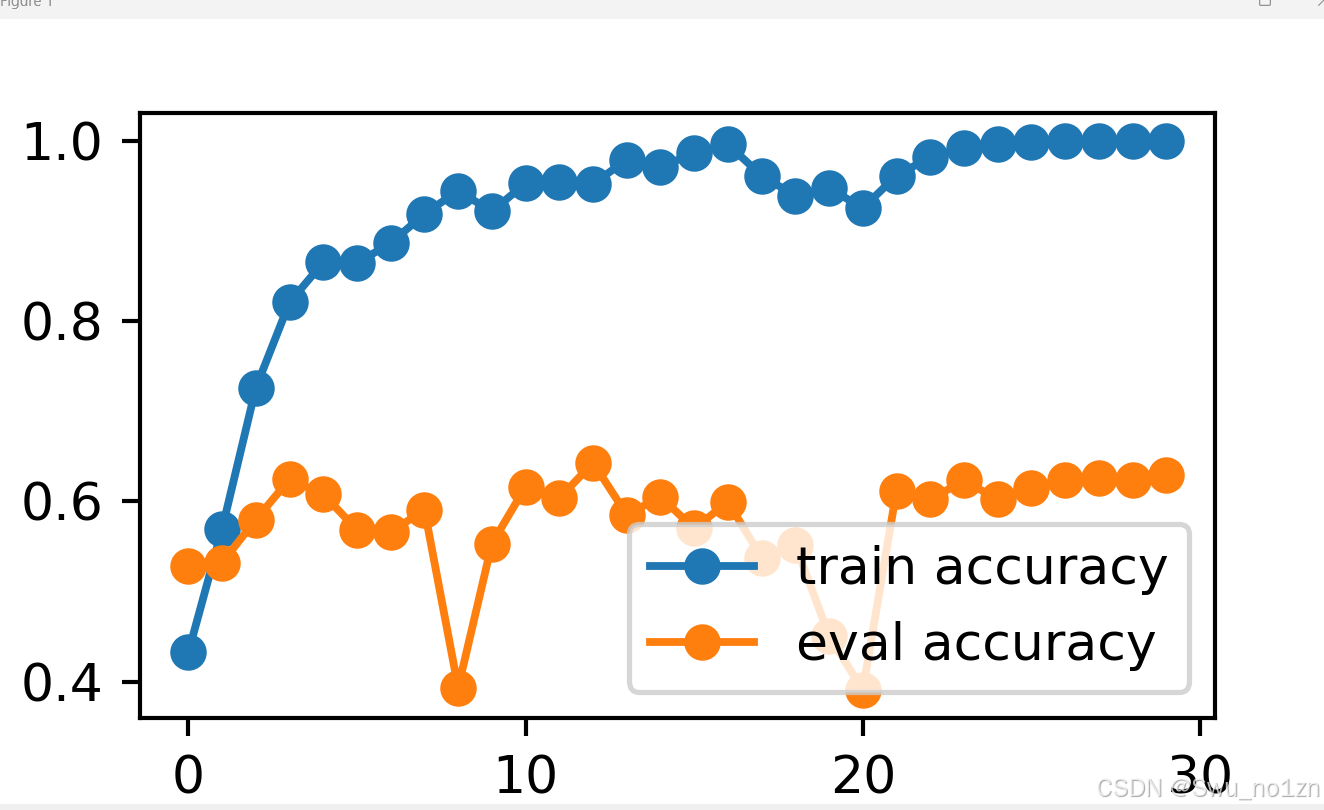
print(f'epoch {epoch}, train accuracy {train_s:.2f}, eval accuracy {eval_s:.2f}')
torch.save(model, 'cnn.pt') #将训练好的模型保存下来 保存该模型为'cnn.pt'
plt.figure(dpi=300) #画图
plt.plot(total_train_accuracies, label='train accuracy', marker='o')
plt.plot(total_eval_accuracies, label='eval accuracy', marker='o')
plt.legend()
plt.show()
if __name__ == '__main__':
main()
train.py运行结果(跑三十遍):验证集怎么这么低啊
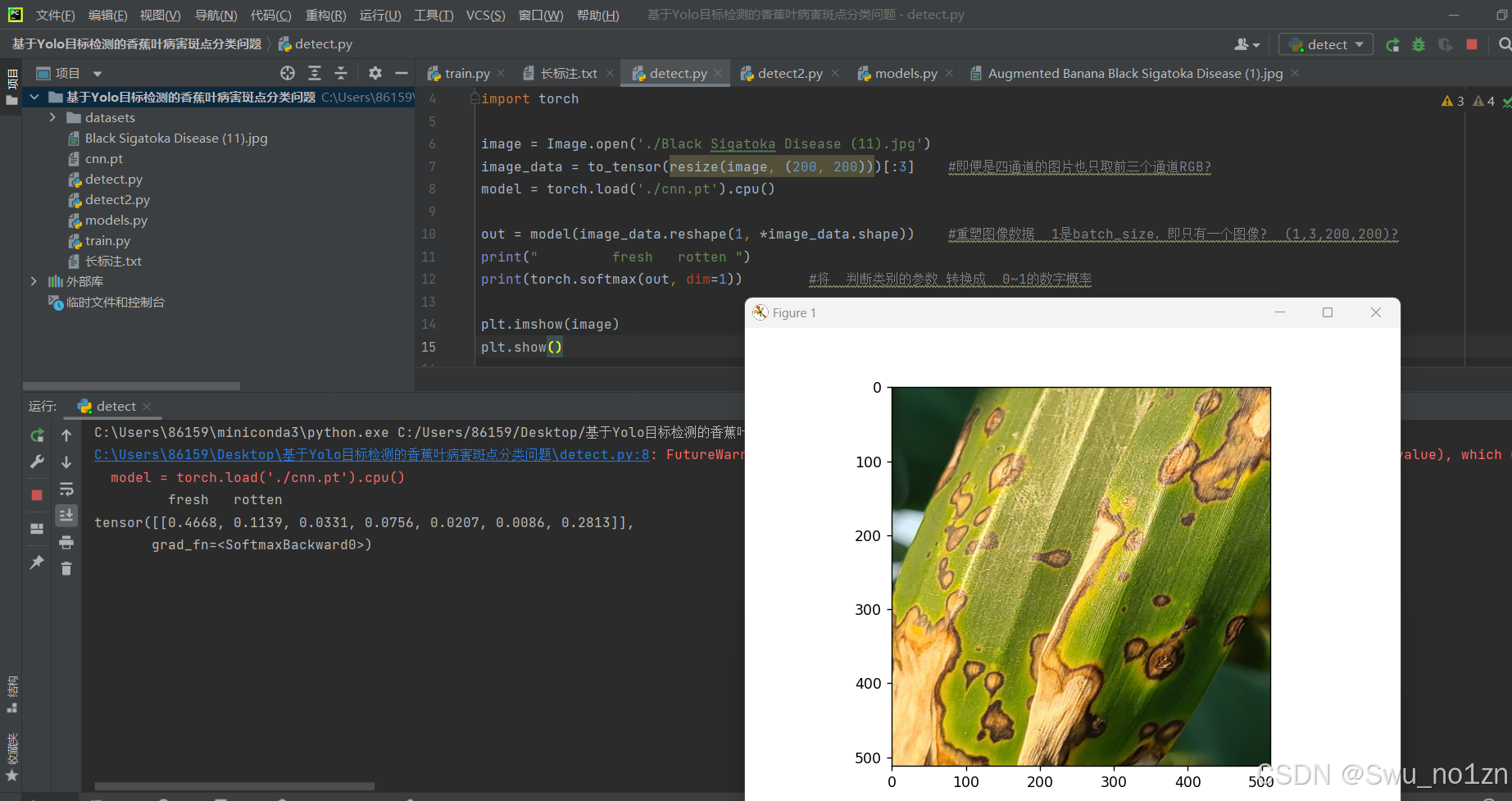
2.detect.py代码:(检测单一图像)
from PIL import Image
from torchvision.transforms.functional import to_tensor, resize
from matplotlib import pyplot as plt
import torch
image = Image.open('t3.jpg')
image_data = to_tensor(resize(image, (200, 200)))[:3] #即便是四通道的图片也只取前三个通道RGB?
model = torch.load('./cnn.pt').cpu()
out = model(image_data.reshape(1, *image_data.shape)) #重塑图像数据 1是batch_size,即只有一个图像? (1,3,200,200)?
print(" fresh rotten ")
print(torch.softmax(out, dim=1)) #将 判断类别的参数 转换成 0~1的数字概率
plt.imshow(image)
plt.show()
运行结果:
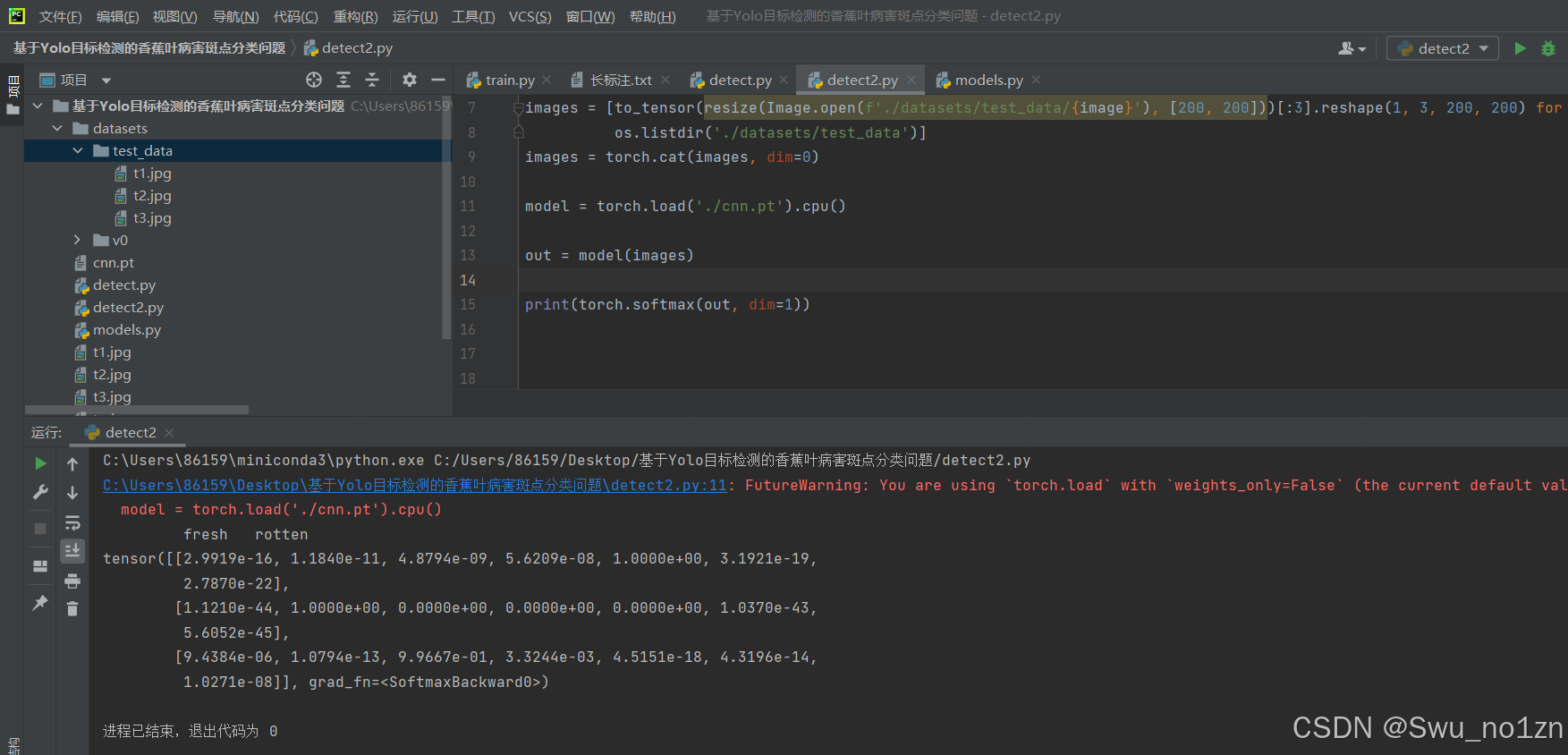
3.detect2.py代码:(检测文件夹中的多个图像)
from PIL import Image
from torchvision.transforms.functional import to_tensor, resize
from matplotlib import pyplot as plt
import torch
import os
images = [to_tensor(resize(Image.open(f'./datasets/test_data/{image}'), [200, 200]))[:3].reshape(1, 3, 200, 200) for image in
os.listdir('./datasets/test_data')]
images = torch.cat(images, dim=0)
model = torch.load('./cnn.pt').cpu()
out = model(images)
print(torch.softmax(out, dim=1))
运行结果:
这都是用的cnn做的最基础版本一,验证集的准确率也很低,后面会更新更好的算法(yolo),实现更多的功能:1.把病变斑点都圈出来 2贴上标签和置信度。
六.杂物柜:
1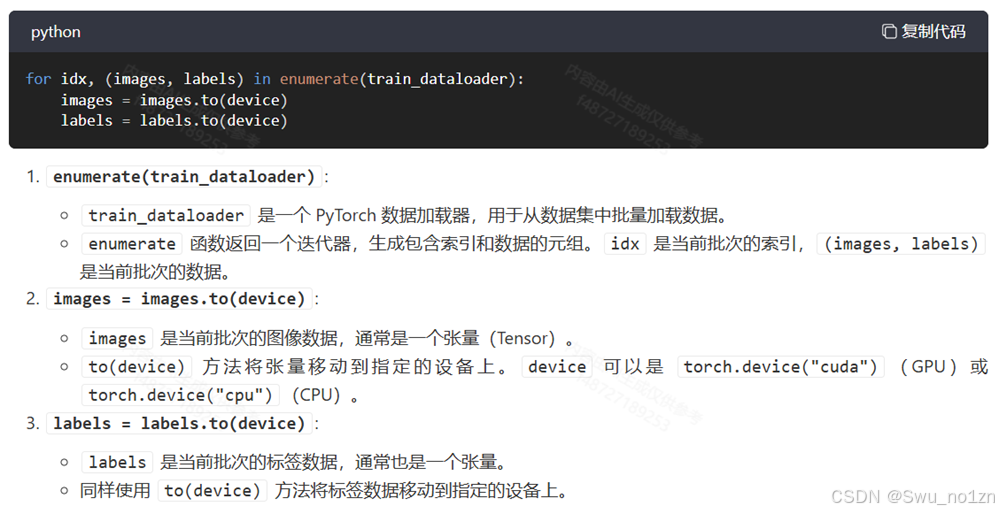
2.python中的.idea文件夹
1、.idea文件夹是怎么自然形成的?
当你使用pycharm作为python的解释器(IDE)时,系统自然会生成.idea文件夹。
2、.idea文件有什么作用?
这个文件夹的主要作用在于存放项目的控制信息,配置信息,包括版本信息,历史记录等等。
3、.idea文件可以删除吗?
可以删除,删除之后不会影响代码的正常使用的,但是如果删除了就不能使用pycharm进行回溯和复原了。
七.学习方法收获:
1.多print一些参数,去看看到底是个什么格式

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)