YOLOv8目标检测(三)_训练模型
YOLOv8目标检测(三)_训练模型
YOLOv8目标检测(一)_检测流程梳理:YOLOv8目标检测(一)_检测流程梳理_yolo检测流程-CSDN博客
YOLOv8目标检测(二)_准备数据集:YOLOv8目标检测(二)_准备数据集_yolov8 数据集准备-CSDN博客
YOLOv8目标检测(三)_训练模型:YOLOv8目标检测(三)_训练模型_yolo data.yaml-CSDN博客
YOLOv8目标检测(三*)_最佳超参数训练:YOLOv8目标检测(三*)_最佳超参数训练_yolo 为什么要选择yolov8m.pt进行训练-CSDN博客
YOLOv8目标检测(四)_图片推理:YOLOv8目标检测(四)_图片推理-CSDN博客
YOLOv8目标检测(五)_结果文件(run/detrct/train)详解:YOLOv8目标检测(五)_结果文件(run/detrct/train)详解_yolov8 yolov8m.pt可以训练什么-CSDN博客
YOLOv8目标检测(六)_封装API接口:YOLOv8目标检测(六)_封装API接口-CSDN博客
YOLOv8目标检测(七)_AB压力测试:YOLOv8目标检测(七)_AB压力测试-CSDN博客
1.准备data.yaml文件
什么是data.yaml文件?
data.yaml文件是一个配置文件,用于定义训练数据集的相关信息和路径。它是 YOLO 系列模型的通用数据格式,指导训练脚本如何加载数据和标签。
# 数据集路径和类别数
#path: /path/to/dataset # 数据集的根目录路径,笔者不用
train: /path/to/dataset/train/images # 训练集的图片路径
val: /path/to/dataset/val/images # 验证集的图片路径
#test: images/test # 测试集的图片路径(可选),笔者不用
# 数据集类别,下面两种写法都可
#names:
# 0: class1
# 1: class2
# 2: class3
names: ['class1','class2','class3']
nc: 3 # 类别数,与 names 的总数一致
2.准备pt文件
下载YOLOV8m.pt,上传到指定位置。
YOLOv8官方网址:YOLOv8 -Ultralytics YOLO 文档
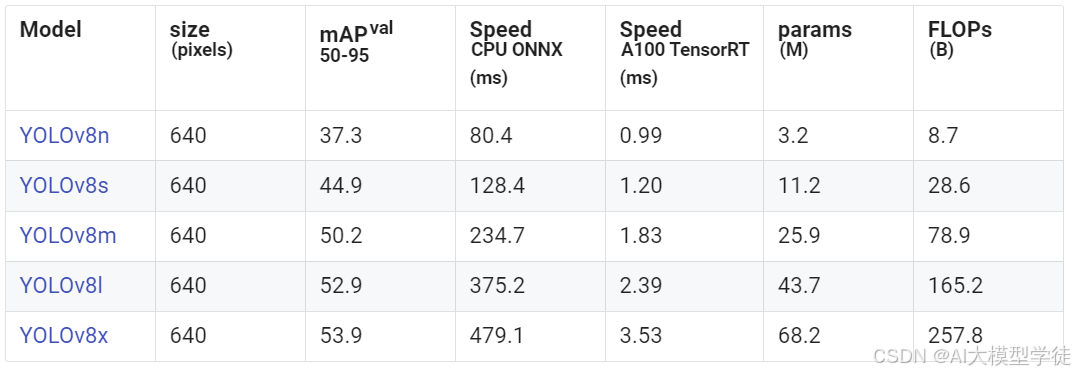
点击蓝色名字即可下载对应Model,这里选择YOLOv8n,如果资源足够可以选择大的模型如YOLOv8m。
什么是pt文件?
pt是PyTorch模型文件的扩展名。YOLOv8模型常使用PyTorch框架进行训练和推理。训练好的模型可保存为.pt文件,便于以后加载和使用。
通俗来说,选择pt就像在一个骨架上训练,更容易得到期望的结果,如果不用,就从0开始随机训练,效果会很差。
3.运行训练命令
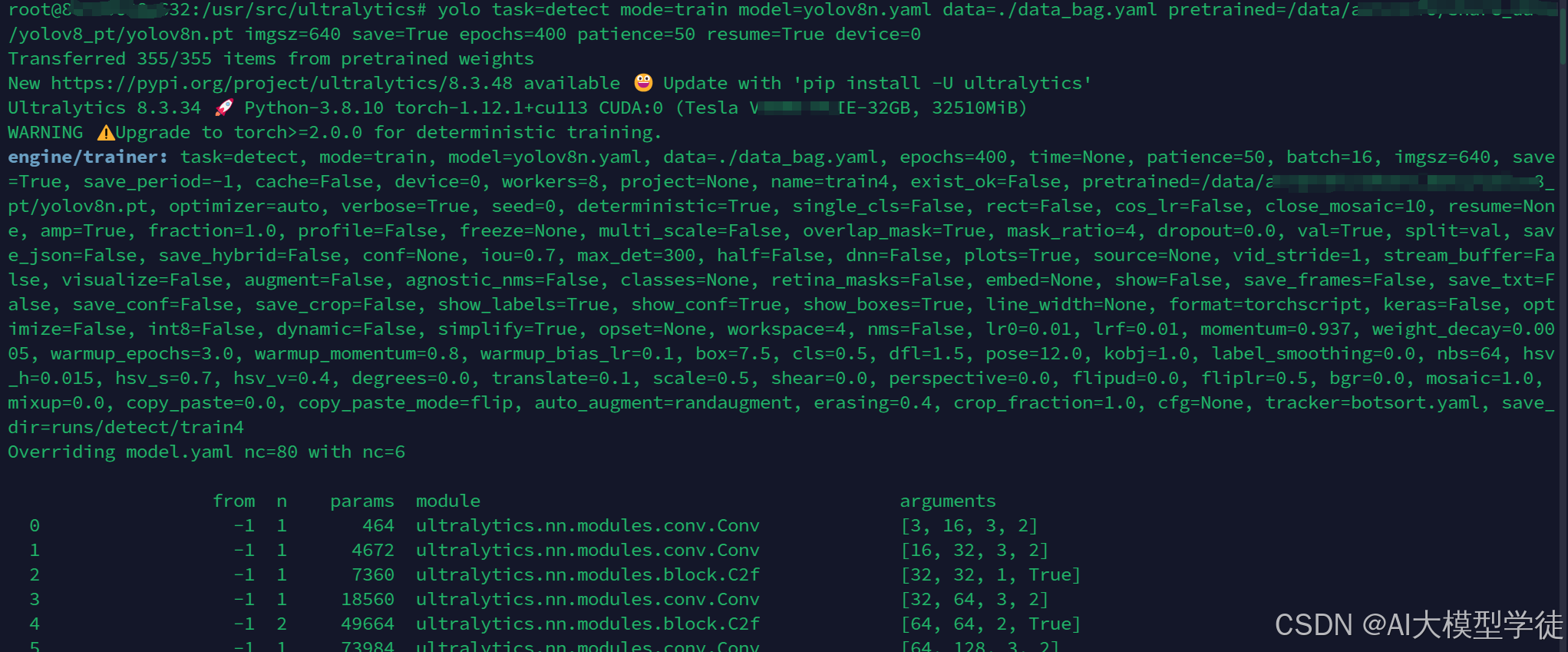
yolo task=detect mode=train model=yolov8n.yaml data=./data.yaml pretrained=./yolov8n.pt imgsz=640 save=True epochs=400 patience=50 resume=True device=0
注意:如果本地没下载这个pt,可能部分读者会下载很慢,几乎不能下载。
1). yolo train
yolo:调用 YOLOv8 的核心工具。train:指定当前模式为训练。YOLOv8 支持多种模式,如:train:训练模型。val:验证模型性能。predict:运行推理任务(检测目标、分割或分类)。export:导出模型到其他格式(如 ONNX、TensorRT)。
2). task=detect
- 指定任务类型为 目标检测。
- YOLOv8 支持以下任务类型:
detect:目标检测(bounding box)。segment:实例分割(mask segmentation)。classify:图像分类。
对于目标检测任务,模型会根据提供的标签框文件(如 .txt 格式)进行训练。
3). model=yolov8m.yaml
- 指定模型的配置文件。
.yaml文件描述了模型的架构(如层数、宽度和深度等)。如果你想从零开始训练,这个文件是必需的。- 如果指定的是
.pt文件,则表示使用预训练权重,同时加载对应的架构。
4). data=./data.yaml
- 指定数据集配置文件的路径。
./data.yaml:表示当前目录下的data.yaml文件。data.yaml文件定义了训练和验证数据集的路径以及类别信息.
5). imgsz=640
- 指定输入图片的尺寸。
imgsz=640:将输入图片调整为 640×640 的大小(宽高相等)。- 图片越大,模型性能可能提升,但推理速度和内存占用会增加。
6). epochs=400
epochs参数:训练的最大迭代次数。- 每个 epoch 意味着模型遍历一次整个训练数据集。
- 设置较大的值(如 400),让模型充分训练。
- 如果验证集性能稳定不再提升,可以通过提前停止(
patience参数)节省训练时间。
7). patience=50
patience参数:控制 提前停止(Early Stopping) 的容忍度。- 如果验证集性能(如 mAP)在连续 50 个 epoch 没有提升,训练会自动停止。
- 优点:
- 节省时间:避免在模型性能无提升时继续浪费资源。
- 防止过拟合:过多的训练可能导致模型在验证集上的性能下降。
8). resume=True
resume参数:指定是否从断点继续训练。True:从上次训练保存的断点继续训练(自动查找runs/detect/train/中的最新权重文件)。False(默认):从头开始重新训练。- 场景:
- 中断训练后无需重新开始。
- 微调时需要从之前的状态继续。
9). device=0
- 指定运行的设备。
0:在第 0 张 GPU 上训练(如NVIDIA GeForce显卡)。cpu:在 CPU 上训练(仅推荐测试用途,速度较慢)。- 多 GPU 支持:例如
device=0,1表示使用第 0 和第 1 张 GPU。
10). pretrained=/data/path/yolov8m.pt
- 指定预训练权重文件的路径。
- 当提供了
pretrained参数时,模型会加载这个权重文件作为初始权重,并在你的数据上进行微调。 - 如果没有指定
pretrained,模型会根据model=yolov8m.yaml随机初始化。
运行成功结果图如下:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)