YOLOv8训练自己的数据集(包括环境搭建、超参数调整、模型训练、推理、模型导出等)
·
YOLOv8代码官方开源地址:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
1.环境准备(Anconada+pycharm)
先准备好主机需要的环境:
Anconada创建环境:

- 点击开始搜索Anconada promot 进入命令行界面
- 创建环境:conda create -name 环境名 python=3.8
- 查看环境:conda env list
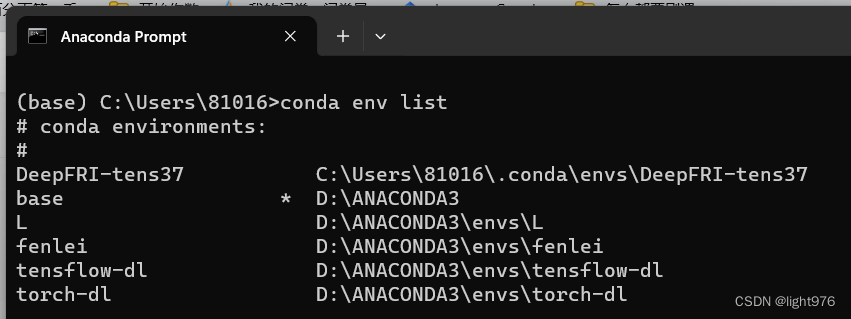
- 激活环境:conda activate 环境名,这里显示已经激活成功。

- 导入依赖: cd到项目文件夹,输入(这里推荐使用清华源)
- pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
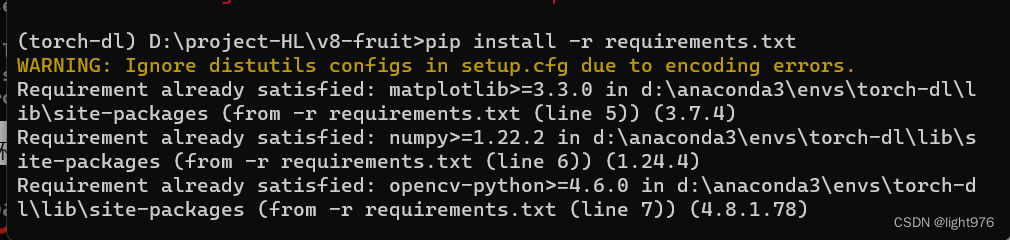
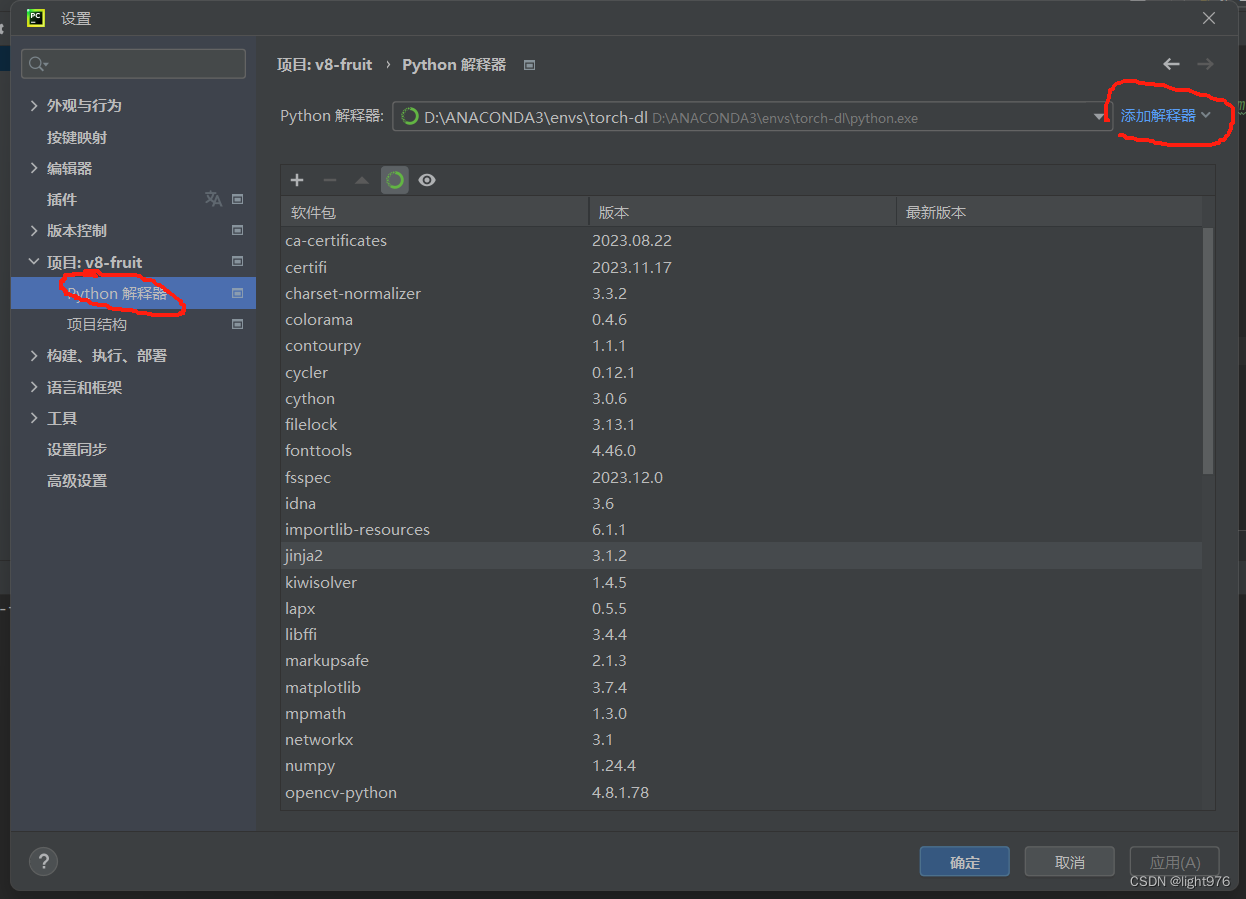
- 进入pycharm打开环境并激活环境,点击添加解释器
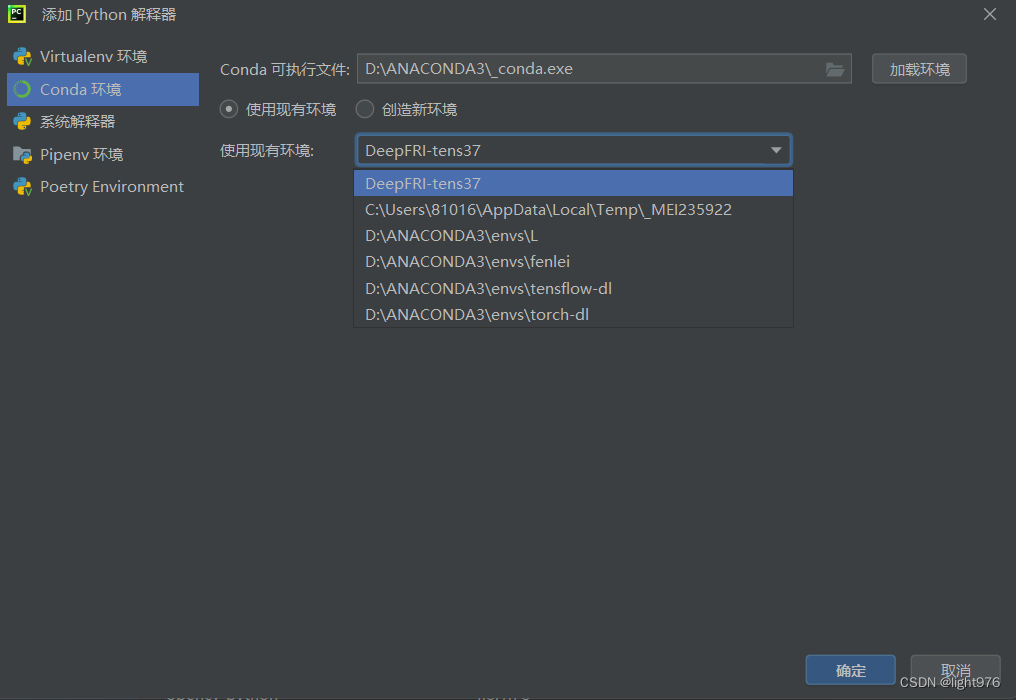
- 选择conda环境并应用,这里conda可执行文件可以找你的conda环境安装位置的_conda.exe并加载,然后选择你刚刚创建的那个环境,我这里选的是torch-dl。
至此环境搭建完成
2.数据集准备
网上大多公开数据集标签是xml格式的,这里附上xml标签转换为txt格式的代码。
import os
import glob
import xml.etree.ElementTree as ET
# 这里指定xml文件目录
xml_file=r'E:\桌面\资料\cv4\数据集\voc数据集\Annotations'
# 这里修改成自己的类别名称
l=['apple', 'banana', 'mixed','orange']
def convert(box,dw,dh):
x=(box[0]+box[2])/2.0
y=(box[1]+box[3])/2.0
w=box[2]-box[0]
h=box[3]-box[1]
x=x/dw
y=y/dh
w=w/dw
h=h/dh
return x,y,w,h
def f(name_id):
xml_o=open(r'E:\桌面\资料\cv4\数据集\voc数据集\Annotations\%s.xml'%name_id)
txt_o=open(r'E:\桌面\资料\cv4\数据集\voc数据集\labels1\%s.txt'%name_id,'w')
# 这里指定xml文件目录和txt文件目录
pares=ET.parse(xml_o)
root=pares.getroot()
objects=root.findall('object')
size=root.find('size')
dw=int(size.find('width').text)
dh=int(size.find('height').text)
for obj in objects :
c=l.index(obj.find('name').text)
bnd=obj.find('bndbox')
b=(float(bnd.find('xmin').text),float(bnd.find('ymin').text),
float(bnd.find('xmax').text),float(bnd.find('ymax').text))
x,y,w,h=convert(b,dw,dh)
write_t="{} {:.5f} {:.5f} {:.5f} {:.5f}\n".format(c,x,y,w,h)
txt_o.write(write_t)
xml_o.close()
txt_o.close()
name=glob.glob(os.path.join(xml_file,"*.xml"))
for i in name :
name_id=os.path.basename(i)[:-4]
f(name_id)
注意修改的就是中文注释处。xml文件存储位置,生成txt文件存储位置,还有你的数据集类别名称,要修改成自己的类别。
3.模型训练
3.1数据集划分
import os
import random
from shutil import move
def split_dataset(src_images, dest_train_images, dest_val_images, src_labels, dest_train_labels, dest_val_labels, split_ratio=0.2):
# 获取所有图片和标签文件
all_images = os.listdir(src_images)
all_labels = os.listdir(src_labels)
# 计算要移动到验证集的数量
num_val_samples = int(len(all_images) * split_ratio)
# 随机选择要移动到验证集的样本
val_samples = random.sample(all_images, num_val_samples)
# 移动图片
for image in val_samples:
src_image_path = os.path.join(src_images, image)
dest_image_path = os.path.join(dest_val_images, image)
move(src_image_path, dest_image_path)
# 移动标签文件
for image in val_samples:
label_file = image.split('.')[0] + '.txt'
src_label_path = os.path.join(src_labels, label_file)
dest_label_path = os.path.join(dest_val_labels, label_file)
move(src_label_path, dest_label_path)
print(f"{num_val_samples} samples moved to validation set.")
# 定义路径
src_images_path = r'D:\project-HL\v8-fruit\datasets\fruit\images\train'
dest_train_images_path = r'D:\project-HL\v8-fruit\datasets\fruit\images\train'
dest_val_images_path = r'D:\project-HL\v8-fruit\datasets\fruit\images\val'
src_labels_path = r'D:\project-HL\v8-fruit\datasets\fruit\labels\train'
dest_train_labels_path = r'D:\project-HL\v8-fruit\datasets\fruit\labels\train'
dest_val_labels_path = r'D:\project-HL\v8-fruit\datasets\fruit\labels\val'
# 调用函数进行数据集划分
split_dataset(src_images_path, dest_train_images_path, dest_val_images_path, src_labels_path, dest_train_labels_path, dest_val_labels_path, split_ratio=0.2)
得到数据集后在你yolo项目中创建一个datasets文件夹,文件结构如下:
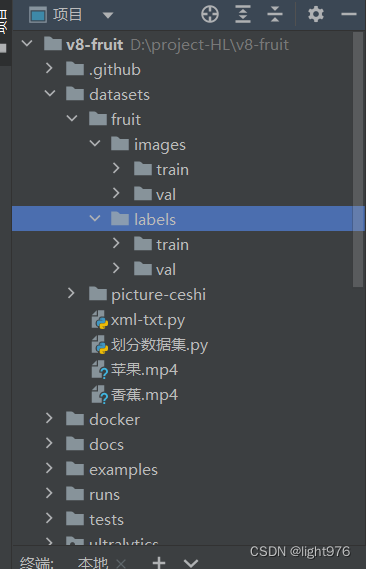
images存放图片,lables存放txt格式的标签,未划分前将所有图片和标签都保存在train文件夹中,然后运行代码划分数据,我这里是8:2,想调整直接看代码最后一个小数。
至此数据集划分完成。
3.2 训练
3.2.1准备一个yaml文件,在此文件夹中复制一个出来放在项目根目录。
自己根据自己的数据集标签,配置一个yaml文件
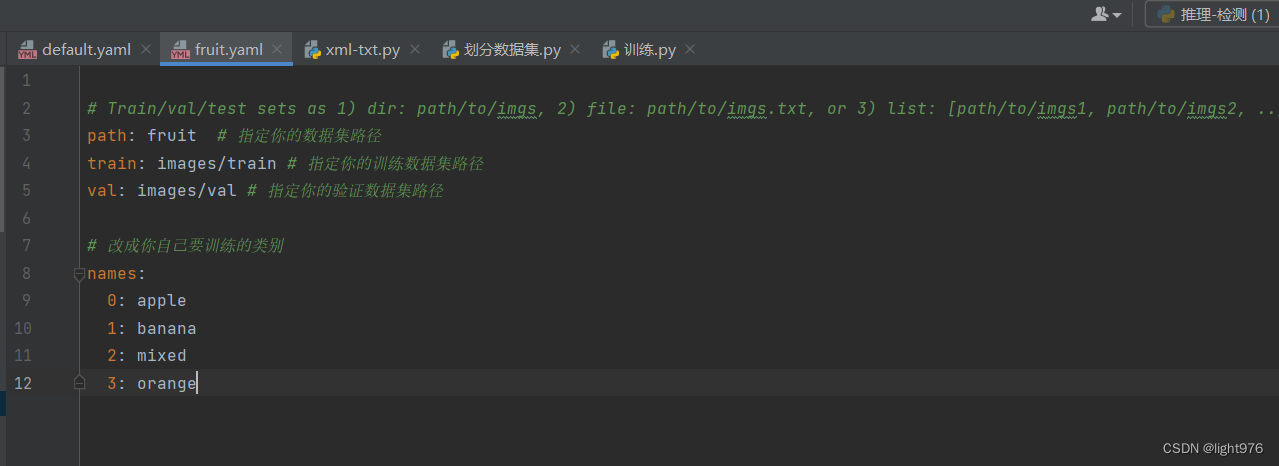
3.2.2 开始训练
在根目录创建一个训练脚本代码如下
from ultralytics import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# Load a model 这里选择预训练模型或者网络结构 有不同模型可以选择 我这使用yolov8n.pt
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model0 data指定你的yaml文件,然后设置超参数
model.train(data="fruit.yaml", epochs=50,batch=8) # train the model
RUN就开始训练了,最后一行可以设置不同的超参数,更多的超参数可以在default.yaml中设置
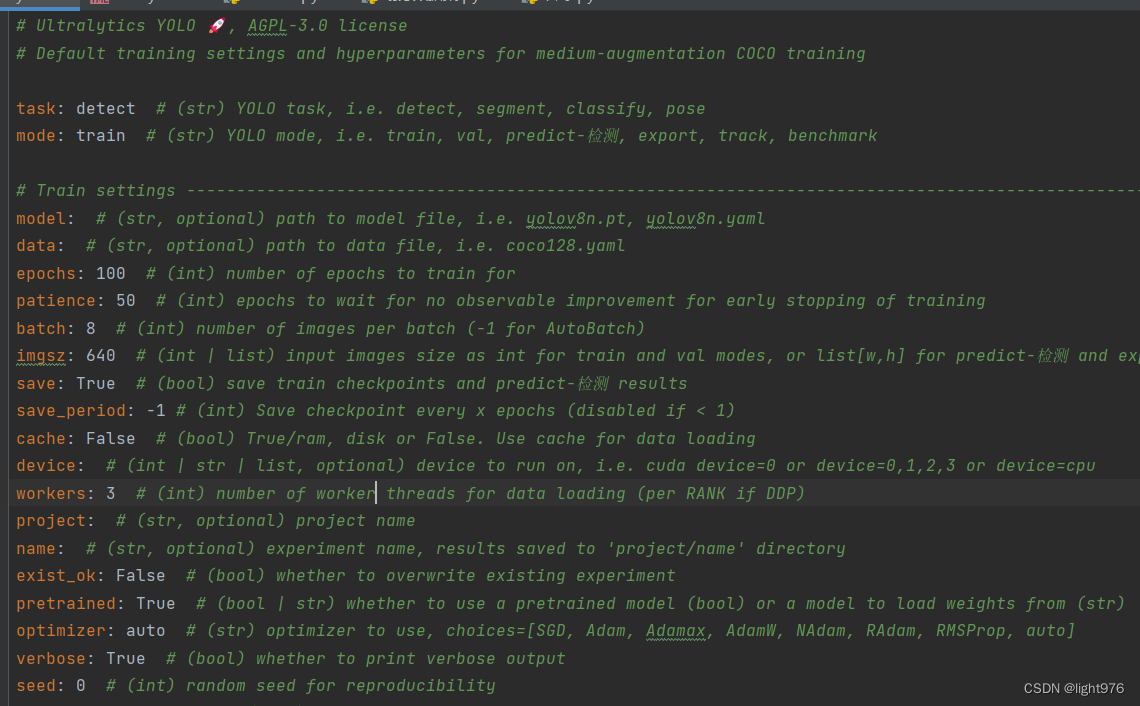
这里包括训练预测的一些超参数。
训练完成后得到结果:
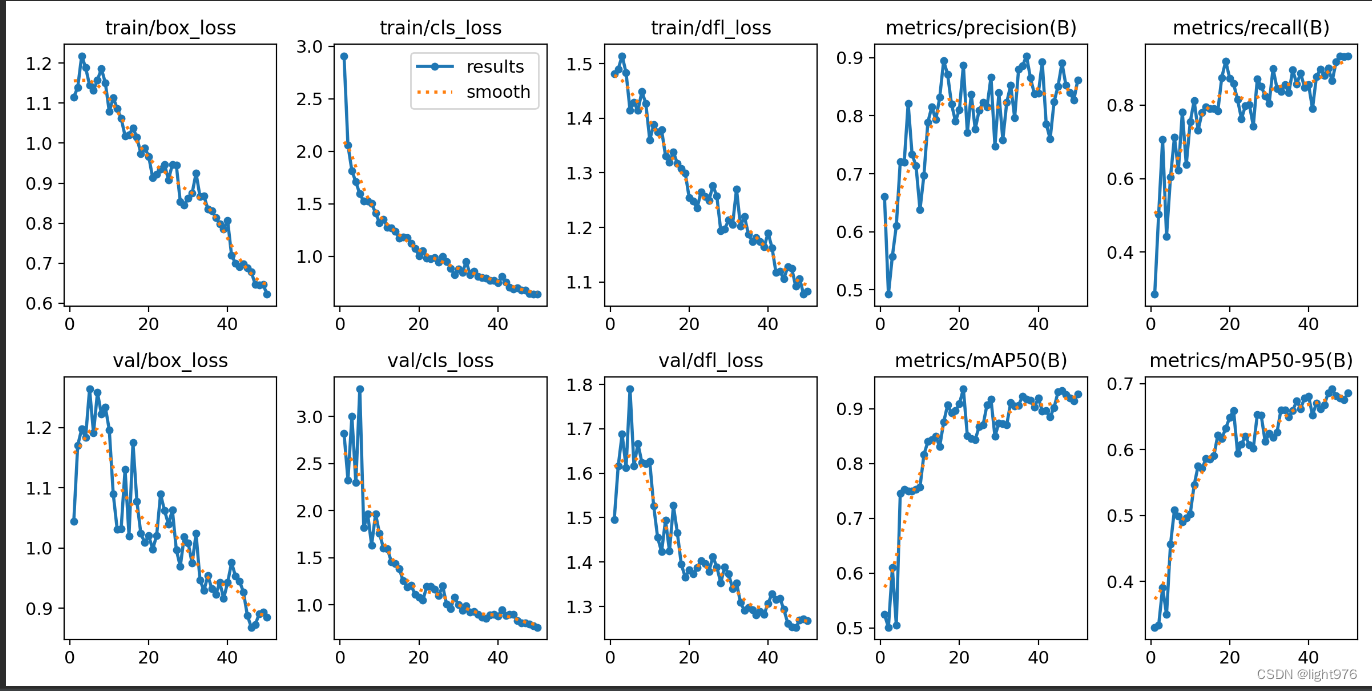
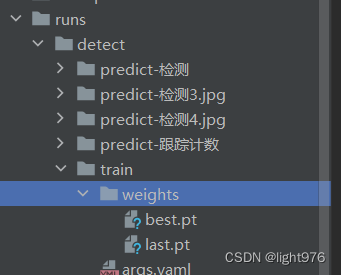
得到这个权重用来进行预测:best.pt指最好的权重,last是最后一次的权重
4.推理
在根目录创建一个推理脚本代码如下
from ultralytics import YOLO
# # 推理结果保存在runs/detect/predict-检测
# 选择模型 这里要选择自己训练得到的权重进行推理
model = YOLO("runs/detect/train/weights/best.pt") # load a pretrained model (recommended for training)
# # 选择数据来源 source
# results = model(source='datasets/picture-ceshi',save=True) # predict-检测 on an image
# 实时显示 source:数据源 show:是否实时显示 save:是否保存预测结果
results = model(source='datasets/picture-ceshi/4.jpg',show=True,save=True) # predict-检测 on an image 
结果如上图
5.模型导出
如果想要部署模型,新建一个脚本。
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
path = model.export(format="onnx") # export the model to ONNX formatformat可以选择不同的导出格式。
就到这里了,希望大家顺利。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)