Scitable包+sciml包手把手带你复现一篇5分charls潜轨迹模型+机器学习文章
今天咱们来介绍一下一篇5分的潜轨迹文章+随机森林charls文章复现,文章的名字叫Predictive analysis of bullying victimization trajectory in a Chinese early adolescent cohort based on machine learning(基于机器学习的中国青少年早期队列欺凌受害轨迹预测分析)
潜轨迹模型(Group-Based Trajectory Modeling, GBTM)是一种统计方法,用于识别具有相似变化模式的群体。这种方法特别适用于纵向数据或面板数据,通过对个体随时间变化的轨迹进行分组来发现潜在的群体趋势。
在既往文章《scitable包手把手带你复现一篇一区8.5分charls潜轨迹文章》中,咱们已经介绍了一篇8.5分charls潜轨迹文章的R语言代码复现,今天咱们来介绍一下一篇5分的潜轨迹文章+随机森林charls文章复现,文章的名字叫Predictive analysis of bullying victimization trajectory in a Chinese early adolescent cohort based on machine learning(基于机器学习的中国青少年早期队列欺凌受害轨迹预测分析)

作者主要是把青少年受到欺凌做了一个评分,然后把评分分成4个发展轨迹,然后把轨迹作为因变量,进行随机森林分析,然后得出重要相关变量,最后进行逻辑回归分析
由于这篇文章是作者自己建的数据库,我并没有这个数据,因此主要介绍的是作者的方法和思路,数据使用文章《中国中老年人社会和智力活动与认知轨迹之间的关联:一项具有全国代表性的队列研究》中的数据来代替,使用认知评分来代替这里的欺凌评分。下面我先导入数据和R包
setwd("E:/公众号文章2025年/轨迹模型GBTM/中国中老年人社会和智力活动与认知轨迹之间的关联:一项具有全国代表性的队列研究")
library(haven)
library(tidyverse)
library(scitable)
library(ggscitable)
datafinal<-read_dta('datafinal.dta') #datafinal
datafinal$spirit2013<-datafinal$cognition2013-datafinal$memory2013
datafinal$spirit2015<-datafinal$cognition2015-datafinal$memory2015
dput(names(datafinal))
认知功能由情景记忆和精神完整性组成,所以作者把这三个都计算,这样3波的话就是九个指标,上图这些是我自己提取的每一个年份的数据指标,做个只能手动慢慢提取,没什么好方法。
作者先玩了个花活,把这9个指标转成一种标准化Z值,然后在分析,不过作者给出了公式还是转换很容易的
var<-c("memory","cognition", "spirit", "memory2013", "cognition2013","spirit2013", "memory2015",
"cognition2015", "spirit2015")
cov<-c("age", "sex", "edu")
datafinal2 <- cognition_z_scores(datafinal, var, cov)
dput(names(datafinal2))
如何做潜轨迹分析我在文章《scitable包手把手带你复现一篇一区8.5分charls潜轨迹文章》已经详细介绍,这里不是重点,需要详细了解的可以跳往连接
整理浩数据后需把宽数据变长数据,这里数据会翻3倍,不理解这个的去查一下原理,我也不能全部喂给你,要有主动学习的精神
df_long <- datafinal2 %>%
pivot_longer(
cols = c('z.cognition', 'z.cognition2013', 'z.cognition2015'), # 需要转换的列名
names_to = "cognitiontime", # 新生成的列名,用来存储原列名
values_to = "cognitionvalue" # 新生成的列名,用来存储原数值
)
###转换年龄
df_long$age2<-ifelse(df_long$cognitiontime=="z.cognition2013",df_long$age+2,
ifelse(df_long$cognitiontime=="z.cognition2015",df_long$age+4,df_long$age))
转换好龄后就可以进行潜轨迹分析了
out<-scigbtm(data=df_long,x="cognitionvalue",ID="communityID", time = "age2",degree=2,n.num = 6,
username=username,token=token)
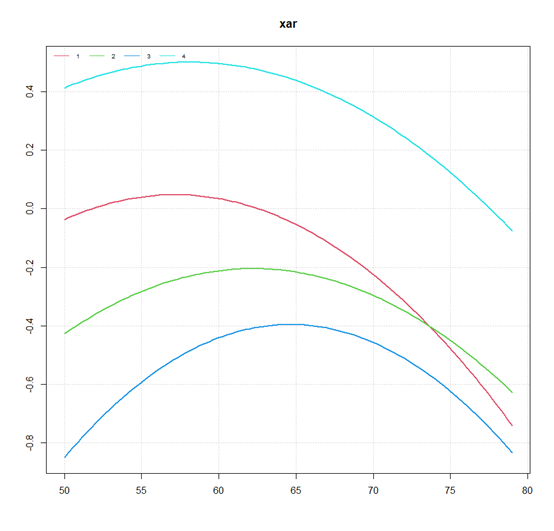
这样图二就生成了
接下来咱们把模型得参数提取出来,
table1<-out[["table1"]] #提取表格
data<-out[["dataorig"]] #提取聚类后的数据
plotdat<-out[["plotdat"]] #提取绘图数据
fit<-out[["mfit"]]
接下来进入本篇文章正题,先复现文章的表一,这个和上一篇文章方法是一样的
先定义需要基线表的变量并整理数据
allVars <-c("age", "sex", "edu", "smoking", "married", "drink", "wc", "bmi","LDL", "FBG", "hba1c",
"TYG", "Hypertension", "CVD", "chd",
"TC", "HDL", "work", "insurance", "consumption", "cluster","cognitionvalue",
"pension","CESD","activities", "intellectual","cognition", "spirit","chronic2")
out2<-organizedata2(data = data,allVars = allVars,username=username,token=token,explore = T)
data2<-out2[["data"]]
fvars<-out2[["factorvarout"]]
dput(names(data))
定义分类变量和分层变量
fvars<-fvars
strata<-"cluster"
绘制表一
tb1<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=data,atotest=F,Overall=T)
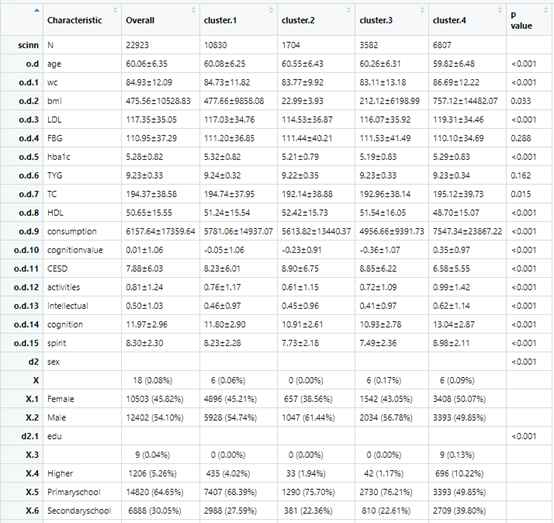
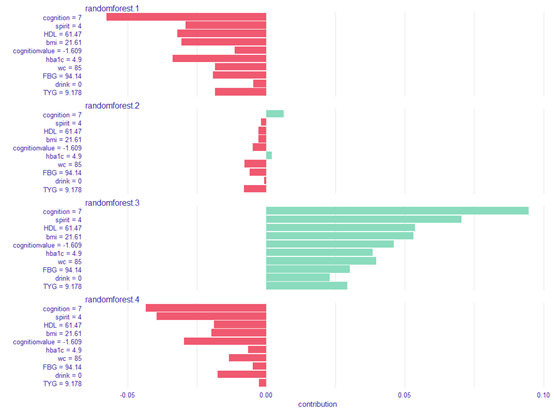
这样表一就绘制好了,接下来咱们做图三和图四,这个是随机森林做出来的
先定义需要做随机森林的变量
Vars <-c("age", "sex", "edu", "smoking", "married", "drink", "wc", "bmi","LDL", "FBG", "hba1c",
"TYG", "Hypertension", "CVD", "chd",
"TC", "HDL", "work", "insurance", "consumption", "cluster","cognitionvalue",
"CESD","activities", "intellectual","cognition", "spirit","chronic2")
data3<-data2[,Vars]
随机森林不能有缺失值,可以删掉缺失值或者插补
data3<-na.omit(data3)
进行随机森林分析,速度是你的电脑而定,大概20-40分钟
out2<-scirandomForest(data=data3,y="cluster",var = Vars,username=username,token=token)
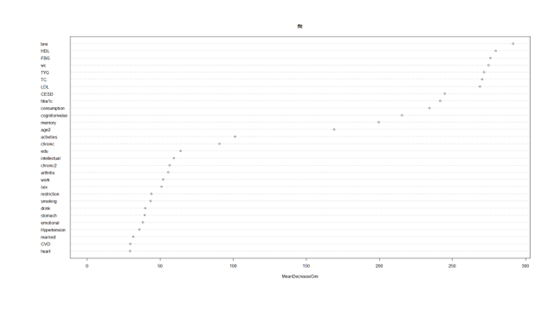
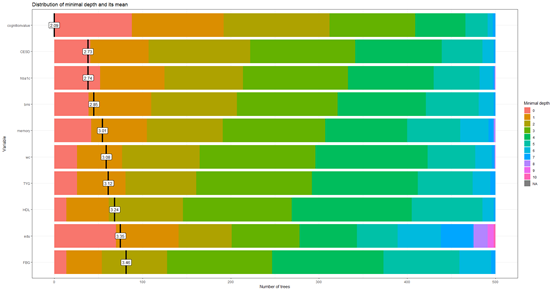
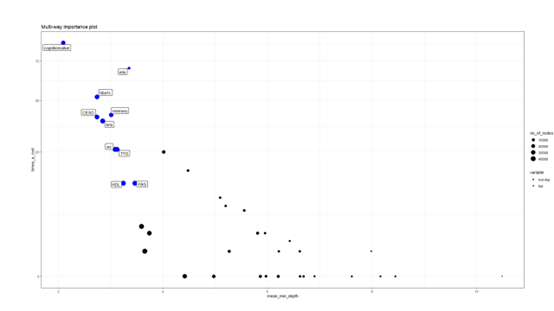
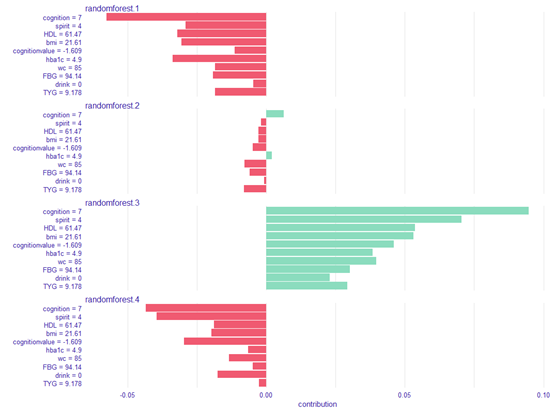
这样图三和图四就做好了,提取重要变量和模型
var2<-out2[["varname"]]
fit2<-out3[["fit"]]
重要变量是
cognition+cognitionvalue+spirit+hba1c+CESD+bmi
接下来依据文章把数据分成训练集和验证集
set.seed(1)
train_idx <- sample(nrow(data3),0.7*nrow(data3))
train_data <- data3[train_idx, ]
test_data <- data3[-train_idx, ]
接下来做文章中的表二,要绘制4个roc,每个类别绘制一个
out3<-scitable::rocdata(fit2,newdata = test_data)
dtroc<-out3[["metrics_df"]]
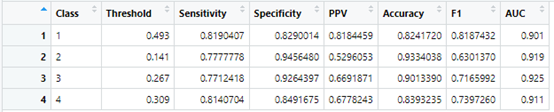
这样表二也做好了,提取ROC数据
roclist<-out3[["roc_list"]]
roctext<-out3[["roctext"]]
绘图
out4<-m.sciroc(roclist,newdata =test_data,obroclist = T,legend.name=roctext)
out4[["p"]]
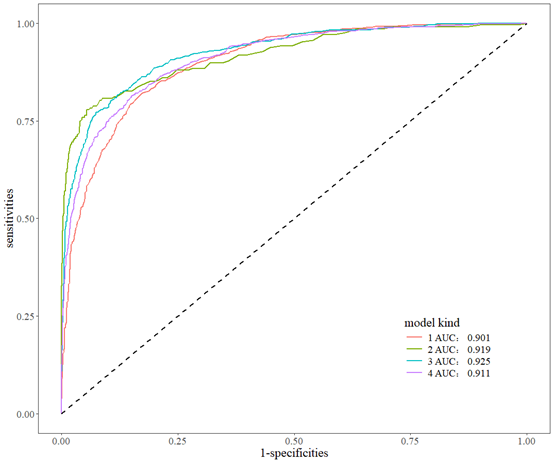
接下来绘制最后的表三,表三做的是逻辑回归,以最低的位参考,做了3次,我只做1和2的比较
取亚组数据
data4<-subset(train_data,train_data$cluster==1 | train_data$cluster==2)
####
data4$cluster<-ifelse(data4$cluster==1,0,1)
data4$cluster<-as.factor(data4$cluster)
dput(names(data2))
定义分析变量和协变量
var<-var2
cov<-var2
这里分析变量和协变量都是var2并没有错,这个和scitb2的算法原理相关,最后通过scitb2计算
tb2<-scitb2(data=data4,x=var ,y="cluster",family = "glm",cov = var2,username=username,token=token)
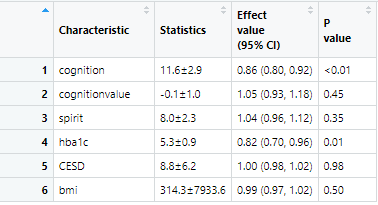
最后表三也复现出来了,文章全部正文表格就复现出来了,文字可能有点快,下面视频介绍更清楚。
Scitable包+sciml包手把手带你复现一篇8.5分charls潜轨迹模型+机器学习文章

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 12
12 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)