机器学习:模型评估
欠拟合(Underfitting):模型太“笨”,没学明白。过拟合(Overfitting):模型太“聪明”,把题都死记硬背了,结果考试不会用。模型在训练集上表现就不好,说明它没学到数据的规律,太简单了。模型在训练集上学得很好,但测试集上表现很差——它不是学懂了,而是背答案了!欠拟合——模型太蠢,学不懂过拟合——模型太聪,死记硬背解决欠拟合——换复杂模型,多训练解决过拟合——模型降智,加数据,做正
一、模型评估概述
1.什么是模型评估
模型评估是机器学习中一个非常关键的环节,它的主要目的是衡量训练好的模型在未见过的数据上的表现,从而判断模型是否泛化得好、有没有过拟合或欠拟合,以及是否能投入实际使用。
简单理解:
就是对模型“考试”,看看它学得咋样,不光是课堂作业(训练集),更重要的是期末考试(测试集)表现。
2.常见的模型评估方式
2.1按任务类型来分:
| 任务类型 | 常用评估指标 |
|---|---|
| 分类(如判断邮件是否为垃圾) | 准确率、精确率、召回率、F1 分数、ROC-AUC |
| 回归(如预测房价) | 均方误差(MSE)、平均绝对误差(MAE)、R² |
| 聚类或无监督任务 | 轮廓系数、互信息、ARI、DBI 等 |
2.2按数据集划分来分:
-
训练集:模型学习用的,不适合做最终评估。
-
验证集:调参用的。
-
测试集:最终评估模型性能的标准,必须是模型“没见过”的数据。
举个例子(分类任务):
比如你训练了一个识别猫狗的模型,现在要评估它:
-
你给它100张新的图片(测试集)
-
它正确识别了90张,错了10张
-
那它的准确率就是90%
但如果数据极度不平衡(比如90张是狗,10张是猫),单看准确率就容易“被忽悠”,所以你可能还要看精确率、召回率、F1等。
3. 什么是过拟合和欠拟合?
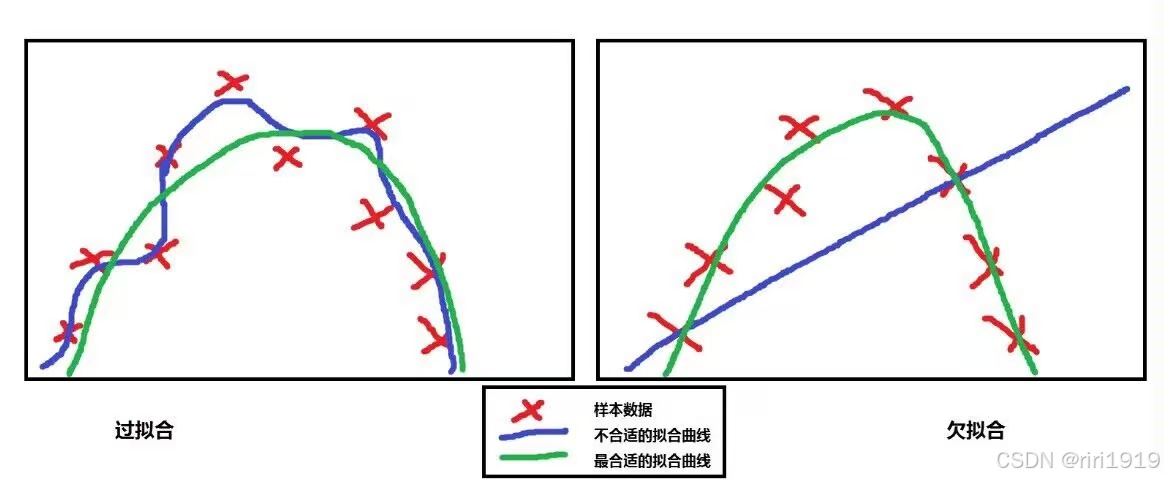
3.1 总结
-
欠拟合(Underfitting):模型太“笨”,没学明白。
-
过拟合(Overfitting):模型太“聪明”,把题都死记硬背了,结果考试不会用。
3.2 欠拟合
定义
模型在训练集上表现就不好,说明它没学到数据的规律,太简单了。
原因
-
模型太简单(比如线性模型处理非线性问题)
-
训练不够(轮数太少)
-
特征太少或者特征提取不行
解决方法
-
模型复杂化
-
增加更多特征,使输入具有更强的表达能力
-
调整参数和超参数
-
降低正则化约束
3.3 过拟合(Overfitting)
定义
模型在训练集上学得很好,但测试集上表现很差——它不是学懂了,而是背答案了!
原因
-
模型太复杂,参数太多
-
数据量太小
-
没做正则化
解决方法
-
增加训练数据数
-
使用正则化约束
-
减少特征值
-
调整超参数和参数
-
降低模型的复杂度
-
使用Dropout
-
提前结束训练
总结口诀
欠拟合——模型太蠢,学不懂
过拟合——模型太聪,死记硬背
解决欠拟合——换复杂模型,多训练
解决过拟合——模型降智,加数据,做正则
二、常见的分类模型评估指标
1. 混淆矩阵 Confusion Matrix
混淆矩阵是监督学习中的一种可视化工具,主要用于模型的分类结果和实例的真实信息的比较 。
矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。
真实值是positive,模型认为是positive的数量(True Positive=TP)
真实值是positive,模型认为是negative的数量(False Negative=FN)
真实值是negative,模型认为是positive的数量(False Positive=FP)
真实值是negative,模型认为是negative的数量(True Negative=TN)
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):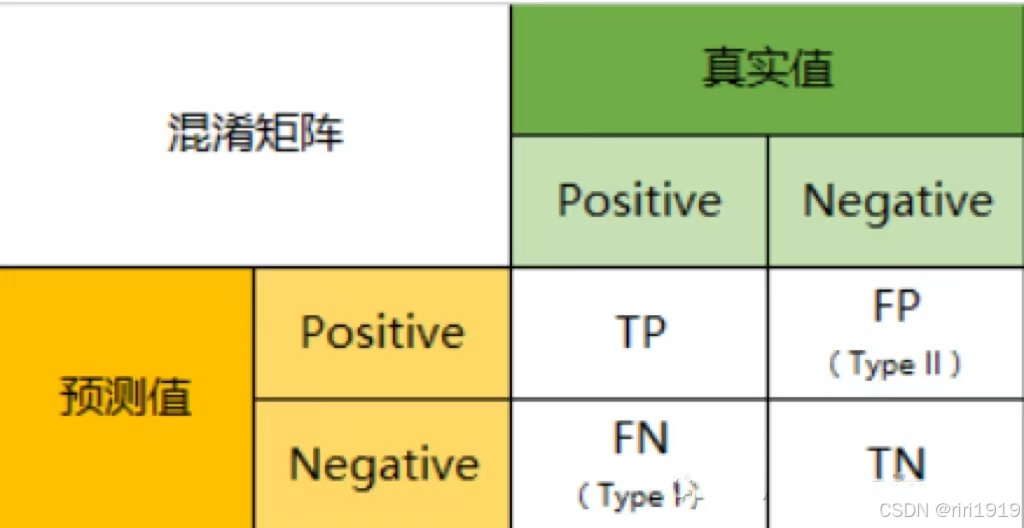
2. 准确率 Accuracy
正确分类的样本数 / 总样本数
即 Accuracy = (TP+TN)/(TP+FN+FP+TN)
-
简单直观
-
在样本不平衡时容易误导
比如99%都是负类,模型全猜负类也有99%准确率。
3. 精确率 Precision
真阳性 / (真阳性 + 假阳性)
即 Precision = TP/(TP+FP)
-
意思是:模型预测为正的那些中,真的是正的有多少?
-
适用于假阳性成本高的场景
比如垃圾邮件识别,宁可漏掉也不能误判正常邮件为垃圾。
4. 召回率 Recall(灵敏度)
真阳性 / (真阳性 + 假阴性)
即 Recall = TP/(TP+FN)
-
意思是:所有真实为正的样本中,模型识别出了多少?
-
适用于假阴性代价高的场景
比如疾病筛查,宁可错杀一千,也不漏掉病人。
5. F1 分数
精确率和召回率的调和平均值
即 F1=2×Precision×RecallPrecision+RecallF1 = 2 \times \frac{Precision \times Recall}{Precision + Recall}F1=2×Precision+RecallPrecision×Recall
-
权衡精确率和召回率的平衡指标
-
适用于正负样本不平衡、你既怕误杀也怕漏判的时候。
6. ROC 曲线 & AUC 值
-
ROC 曲线:全称为“受试者工作特征曲线”,它体现了模型在不同阈值下的“容错能力”。
逻辑回归里面,对于正负例的界定,通常会设一个阈值,大于阈值的为正类,小于阈值为负类。而 ROC 曲线的精髓就在于:不断调整这个阈值(从0到1),记录每个点的真正率和假正率,然后以假阳性率为 X 轴,真阳性率为 Y 轴画出的曲线。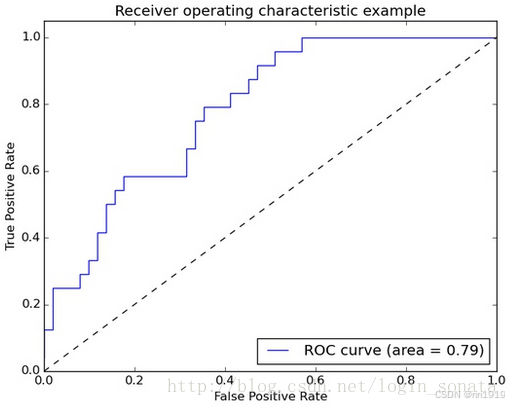
-
AUC(Area Under Curve):ROC 曲线下的面积,范围在 0.5 - 1 之间。随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是 AUC 值。AUC值(面积)越大的分类器,性能越好。
0.5 = 瞎猜,1 = 完美分类
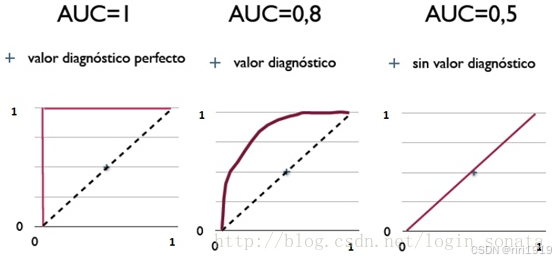
-
适用于模型输出的是概率值的情况,比如逻辑回归、神经网络
7. PR 曲线(Precision-Recall Curve)
-
横轴:召回率 Recall(查全率)
-
纵轴:精确率 Precision(查准率)
-
面积:Average Precision(AP),越大越好
评价标准和ROC一样,先看平滑不平滑(蓝线明显好些)。一般来说,在同一测试集,上面的比下面的好(绿线比红线好)。当P和R的值接近时,F1值最大,此时画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好像AUC对于ROC一样。
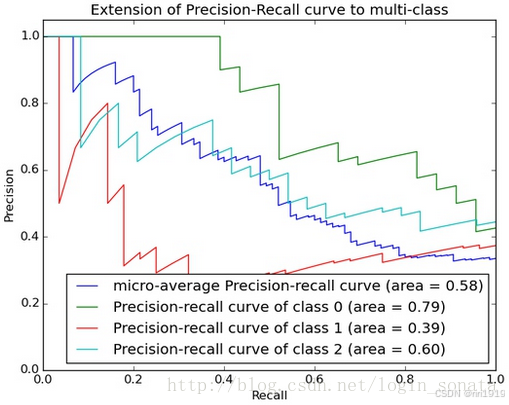
-
适用场景:
二分类任务
-
数据不平衡时比 ROC 更实用!
比如少数类别(如欺诈检测)特别关键时
8. 表格对比
| 指标 | 含义 | 适用场景 |
|---|---|---|
| Accuracy | 总体正确率 | 类别均衡、对误差容忍高 |
| Precision | 预测为正中真正的比例 | 错杀成本高(如垃圾邮件、广告点击) |
| Recall | 实际为正中被预测出来的比例 | 漏判成本高(如疾病识别、欺诈检测) |
| F1 Score | Precision 和 Recall 的调和平均 | 样本不平衡、需权衡查准与查全 |
| AUC (ROC AUC) | ROC 曲线下的面积,反映模型区分能力 | 二分类概率模型,样本不平衡时仍适用 |
| PR 曲线 & AP | 精确率-召回率之间的权衡曲线 & 平均精度 | 极度不平衡样本(如恶意行为、异常检测) |
| Confusion Matrix | 展示 TP/FP/FN/TN 的二维矩阵 | 分析模型在哪些类型上容易出错 |
三、用 KNN 模型绘制ROC曲线和PR曲线
1.代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import precision_recall_curve, roc_curve, auc, accuracy_score, confusion_matrix
# Step 1: 生成二分类数据集
def generate_data():
"""
生成一个用于二分类任务的模拟数据集,包含3个特征,其中2个是信息性特征。
"""
X, y = make_classification(n_samples=4000, n_features=3, n_classes=2,
n_informative=2, n_redundant=0, random_state=0)
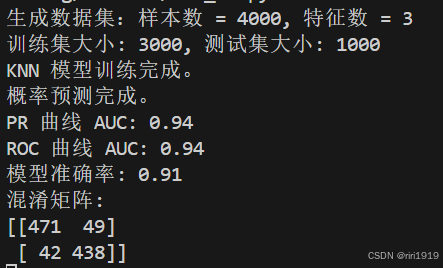
print(f"生成数据集:样本数 = {X.shape[0]}, 特征数 = {X.shape[1]}")
return X, y
# Step 2: 数据分割为训练集和测试集
X, y = generate_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
print(f"训练集大小: {X_train.shape[0]}, 测试集大小: {X_test.shape[0]}")
# Step 3: 初始化KNN模型并训练
knn_model = KNeighborsClassifier(n_neighbors=5) # 选择KNN分类器,邻居数设为5
knn_model.fit(X_train, y_train) # 训练模型
print("KNN 模型训练完成。")
# Step 4: 预测测试集的概率
y_scores = knn_model.predict_proba(X_test)[:, 1] # 预测正类的概率
print("概率预测完成。")
# Step 5: 计算 Precision-Recall 曲线数据
precision, recall, _ = precision_recall_curve(y_test, y_scores)
pr_auc = auc(recall, precision) # 计算 Precision-Recall 曲线下的AUC值
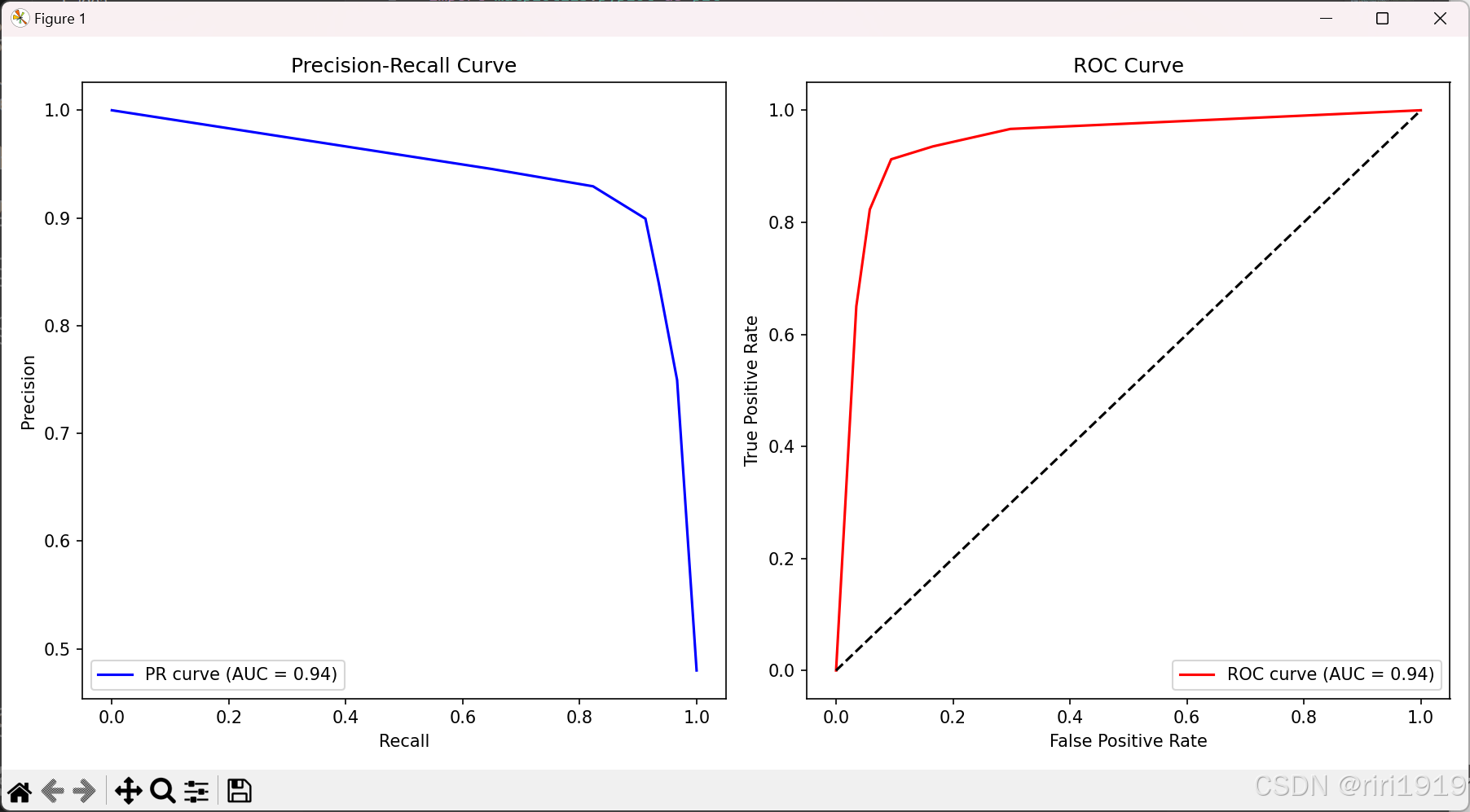
print(f"PR 曲线 AUC: {pr_auc:.2f}")
# Step 6: 计算 ROC 曲线数据
fpr, tpr, _ = roc_curve(y_test, y_scores)
roc_auc = auc(fpr, tpr) # 计算 ROC 曲线下的AUC值
print(f"ROC 曲线 AUC: {roc_auc:.2f}")
# Step 7: 模型评估 - 计算准确率和混淆矩阵
y_pred = knn_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")
print("混淆矩阵:")
print(cm)
# Step 8: 绘制 Precision-Recall 和 ROC 曲线
plt.figure(figsize=(12, 6))
# 绘制 ROC 曲线
plt.subplot(1, 2, 2)
plt.plot(fpr, tpr, color='r', label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--') # 参考线
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc='lower right')
# 绘制 PR 曲线
plt.subplot(1, 2, 1)
plt.plot(recall, precision, color='b', label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc='lower left')
# Step 9: 显示图形
plt.tight_layout()
plt.show()
# Step 10: 结果解释
# print(f"1. PR 曲线 AUC:PR 曲线 AUC 值接近1表示模型性能好,AUC越大,模型表现越好。")
# print(f"2. ROC 曲线 AUC:ROC 曲线 AUC 值接近1表示模型能更好地区分正负样本。")
# print(f"3. 准确率:这是模型分类的基本评价指标,考虑了正负类样本的分布。")
# print(f"4. 混淆矩阵:混淆矩阵提供了模型在测试集上的预测结果分布,帮助我们理解误分类的类型。")
2.运行结果
四、总结
模型评估不仅是为了看模型得分高不高,更重要的是找出模型的问题在哪,比如有没有过拟合、欠拟合,或者预测是否偏向某一类。为了更全面地了解模型表现,我们不能只看一个指标,而是要结合多种指标一起分析。比如在样本不平衡的情况下,Accuracy(准确率)可能会很高,但模型其实没学会真正有用的东西。这时候,Precision(精确率)、Recall(召回率)和 F1 分数就能帮我们判断模型是否真的有效。ROC 曲线和 PR 曲线可以让我们直观看出模型在不同阈值下的表现变化,帮助我们选择更合适的决策边界。而混淆矩阵则像一张成绩单,把预测正确和错误的情况一一列出,让我们知道模型具体错在哪。通过这些工具,我们才能真正了解模型的强项和弱点,为后续优化打下基础。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)