机器学习车辆轨迹预测
机器学习车辆轨迹预测本研究旨在对车辆轨迹预测进行深入分析与探讨,比较传统机器学习方法和基于注意力机制的方法在轨迹预测中的性能表现。首先,通过对交通数据集进行预处理,提取出关键特征,并构建了多个用于预测车辆未来位置的机器学习模型,包括随机森林算法、支持向量机算法(SVM)和BP神经网络。详细描述了各算法的构建过程和训练方法,并在同一数据集上进行了实验。此外,实现了基于注意力机制的长短期记忆网络(LS
机器学习车辆轨迹预测
本研究旨在对车辆轨迹预测进行深入分析与探讨,比较传统机器学习方法和基于注意力机制的方法在轨迹预测中的性能表现。首先,通过对交通数据集进行预处理,提取出关键特征,并构建了多个用于预测车辆未来位置的机器学习模型,包括随机森林算法、支持向量机算法(SVM)和BP神经网络。详细描述了各算法的构建过程和训练方法,并在同一数据集上进行了实验。
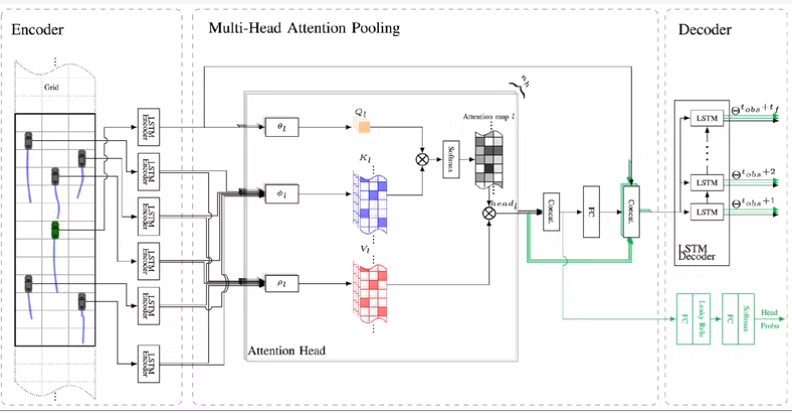
此外,实现了基于注意力机制的长短期记忆网络(LSTM),包括卷积社交池化、MHA-LSTM和MHA-LSTM(+f)多头注意力机制模型。卷积社交池化模型通过卷积操作捕捉车辆间的相互依赖关系,增强了模型的泛化能力。MHA-LSTM(+f)模型相对MHA-LSTM模型增加了速度、加速度和车辆类型的输入,通过多头注意力机制有效地捕捉车辆间的相互作用和时空特征,特别适用于处理复杂交通场景。为了全面评估模型的性能,计算了均方根误差(RMSE),并对比了不同模型在预测精度和鲁棒性方面的表现。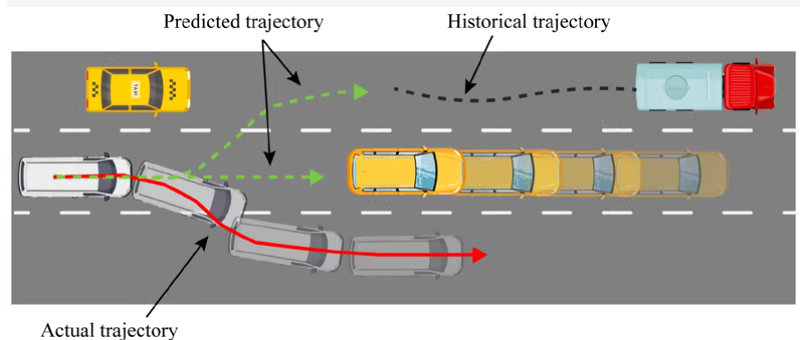
车辆轨迹预测是自动驾驶、智能交通系统中的一个重要研究方向。通过机器学习方法,可以基于历史轨迹数据预测车辆未来的运动路径。常用的方法包括传统的机器学习算法(如线性回归、支持向量机)和深度学习模型(如LSTM、GRU、Transformer等)。
使用深度学习模型(LSTM)进行车辆轨迹预测的代码示例:
数据准备
假设我们有一组车辆的历史轨迹数据,格式为 (x, y) 坐标点序列。我们需要将这些数据划分为输入序列和目标序列。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 示例数据:生成一些模拟的车辆轨迹数据 (x, y)
np.random.seed(42)
num_samples = 1000
seq_length = 20 # 输入序列长度
data = []
for _ in range(num_samples):
x = np.cumsum(np.random.randn(seq_length)) # 随机生成x坐标
y = np.cumsum(np.random.randn(seq_length)) # 随机生成y坐标
trajectory = np.column_stack((x, y)) # 组合成 (x, y) 轨迹
data.append(trajectory)
data = np.array(data)
# 划分输入和目标
X = data[:, :-1, :] # 输入序列 (前 seq_length-1 个点)
y = data[:, -1, :] # 目标序列 (最后一个点)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 归一化数据
mean = X_train.mean(axis=(0, 1))
std = X_train.std(axis=(0, 1))
X_train = (X_train - mean) / std
X_test = (X_test - mean) / std
构建 LSTM 模型
# 构建LSTM模型
model = Sequential([
LSTM(64, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=False),
Dense(32, activation='relu'),
Dense(2) # 输出 (x, y) 坐标
])
# 编译模型
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
# 模型摘要
model.summary()
训练模型
# 训练模型
history = model.fit(
X_train, y_train,
validation_data=(X_test, y_test),
epochs=50,
batch_size=32
)
评估模型
# 评估模型性能
loss, mae = model.evaluate(X_test, y_test)
print(f"Test Loss: {loss:.4f}, Test MAE: {mae:.4f}")
# 可视化训练过程
import matplotlib.pyplot as plt
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
测试预测
# 使用测试集进行预测
y_pred = model.predict(X_test)
# 可视化真实值与预测值
plt.figure(figsize=(10, 6))
plt.scatter(y_test[:, 0], y_test[:, 1], color='blue', label='True Trajectory', alpha=0.5)
plt.scatter(y_pred[:, 0], y_pred[:, 1], color='red', label='Predicted Trajectory', alpha=0.5)
plt.xlabel('X Coordinate')
plt.ylabel('Y Coordinate')
plt.legend()
plt.title('True vs Predicted Vehicle Trajectory')
plt.show()
总结
代码展示了如何使用 LSTM 模型来预测车辆轨迹。根据实际需求调整模型结构、超参数和数据预处理方式。对于更复杂的场景,例如多车交互或动态环境下的轨迹预测,可以考虑引入图神经网络(GNN)或 Transformer 等高级模型。
示例代码有辅助创作,仅供参考。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)