深度学习模型部署(一)——onnxruntime
ONNX是一种开放的模型交换格式,主要解决不同框架间的模型兼容性问题,支持将PyTorch、TensorFlow等框架模型转换为标准中间格式,实现跨平台迁移。该模式首先将模型转换为ONNX格式,再通过TensorRT生成优化后的.engine文件,结合两者的优势实现部署流程标准化与性能最大化。TensorRT是NVIDIA推出的高性能推理SDK,专为GPU优化,通过层融合、内核自动调优、量化压缩等
一、ONNX(Open Neural Network Exchange)部署
1、ONNX
ONNX是一种开放的模型交换格式,主要解决不同框架间的模型兼容性问题,支持将PyTorch、TensorFlow等框架模型转换为标准中间格式,实现跨平台迁移。
优点:通用性强,支持CPU/NPU/GPU多硬件,便于跨框架写作
缺点:原生推理性能一般,需借助ONNX Runtime等推理引擎加速
onnx部署流程:
torch.nn.Module转onnx文件——>模型校验netron.app——>onnxruntime推理
2、软件站
ONNX是一种文本,无法在硬件设备上运行。软件站可以加载ONNX文件后在硬件上进行推理。软件站有各家GPU/CPU厂家自己开发的,如NIVIDA的TensorRT、Intel的OpenVINO、高通的SNEP、苹果的Core ML、华为的CANN,这类软件站的优势是可以发挥自家芯片的优势,缺点是不具备普适性。通用软件站有ONNXRUNTIME、TVM等。
二、pytorch转ONNX文件
1、下载onnx模块
pip install onnx
2、onnx文件导出
torch.nn.Module ——> onnx步骤:
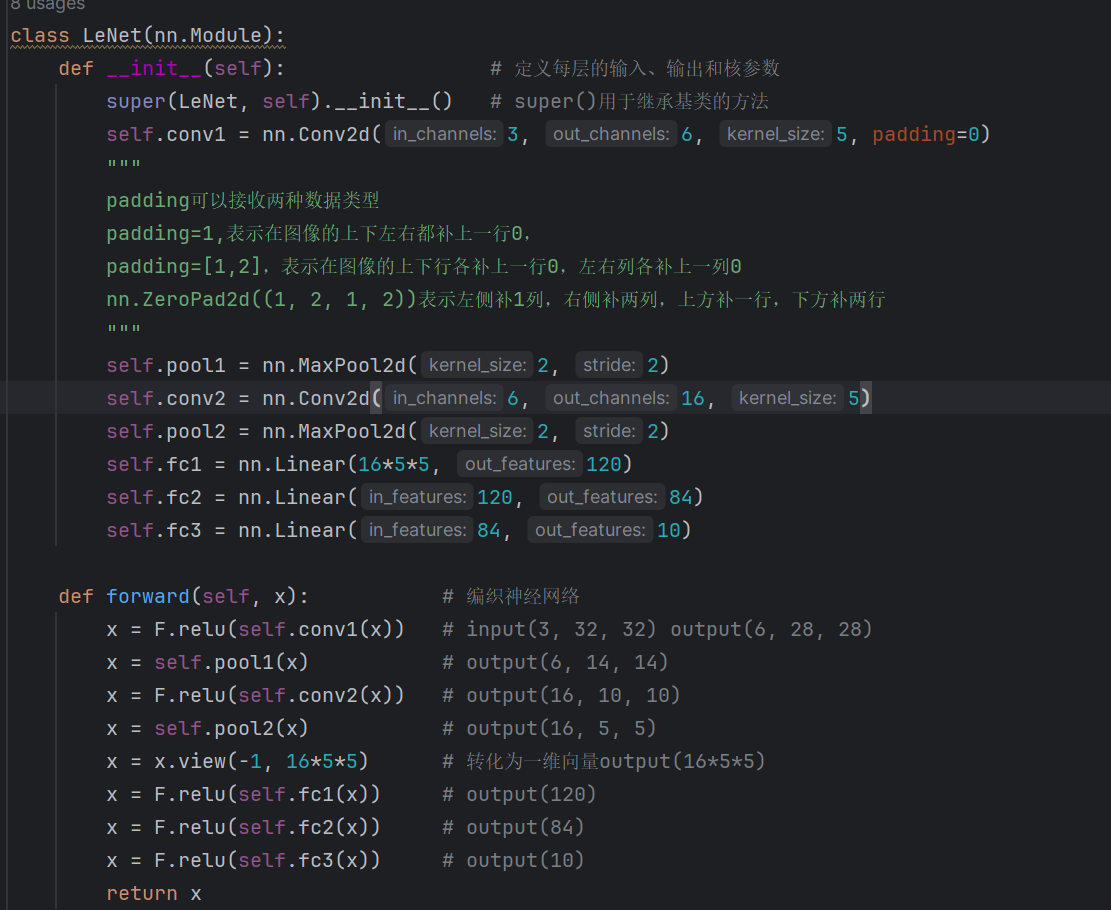
1)模型实例化
2)加载pt文件
3)eval模式
4)定义输入input_data的shape
5)torch.onnx.export(model, input_data, onnx_file_name, opset_version=11, input_name=[‘input’], output_name=[‘ouput’], dynamic_axes={‘input’:{0:‘batch_size’}, ‘output’:{0:‘batch_size’}})
【注1】:固定输入onnx的输入时,需要定义输入数据,数据形状根据模型的输入设置
【注2】:可设置动态输入,配置dynamic_axes参数
import torch
from model import LeNet
# 1、实例化模型
net = LeNet()
net.eval()# 设置模型在测试模式下
# 2、设置输入
x = torch.rand(size=(1, 3, 32, 32), dtype=torch.float32)
# 3、导出onnx文件
torch.onnx.export(net, x, f='lenet.onnx', input_names=['input'], output_names=['output'], opset_version=11)
'''
def export(
**model**: Union[torch.nn.Module, torch.jit.ScriptModule, torch.jit.ScriptFunction], 需要导出的模型对象
**args**: Union[Tuple[Any, ...], torch.Tensor], 模型的输入,可以是Tuple也可以是Tensor
**f**: Union[str, io.BytesIO], 字符串格式,模型存储的路径,包含模型名称
**export_params**: bool = True, 默认值为True,表示所有参数都被输出;如果设为False,则导出的是一个未经训练的模型
**verbose**: bool = False, 如果设为True, 将打印导出到 stdout 的模型描述。此外,最终的 ONNX 图将包括从导出模型中提取的 ``doc_string`` 字段,该字段提到 ``model`` 的源代码位置。如果为 True,将开启 ONNX 导出器日志记录。
**training**: _C_onnx.TrainingMode = _C_onnx.TrainingMode.EVAL,
* ``TrainingMode.EVAL``: 导出推理模型
* ``TrainingMode.PRESERVE``: 如果model.training=False 导出推理模型;如果model.training=True导出训练模型
* ``TrainingMode.TRAINING``: 导出训练模型
**input_names**: Optional[Sequence[str]] = None, 可视化,给onnx图的输入节点设置名称
**output_names**: Optional[Sequence[str]] = None, 可视化, 给onnx图的输出节点设置名称
**operator_export_type**: _C_onnx.OperatorExportTypes = _C_onnx.OperatorExportTypes.ONNX,
**opset_version**: Optional[int] = None, ai.onnx的版本,需要大于7并小于17,版本向下兼容,不同版本支持的API不同
**do_constant_folding**: bool = True, 应用常量折叠优化。常量折叠将用预计算的常量节点替换一些所有输入都是常量的操作。
**dynamic_axes**: Optional[
Union[Mapping[str, Mapping[int, str]], Mapping[str, Sequence[int]]]
] = None, # 可接收动态输入, 字典结构,key(str):输入/输出名,每个名字必须被input_name和output_name定义;value(dict或list):如果value是dict,key应该是轴的索引,value是轴的名称;如果是list,每个元素应该是轴的索引编号,如:torch.onnx.export(
SumModule(),
(torch.ones(2, 2),),
"onnx.pb",
input_names=["x"],
output_names=["sum"],
dynamic_axes={
# dict value: manually named axes
"x": {0: "my_custom_axis_name"},
# list value: automatic names
"sum": [0],
}
)
**keep_initializers_as_inputs**: Optional[bool] = None, 如果为True:导出图中的所有初始化值将被添加到图的输入中;如果为False:初始化值不会被添加到图的输入中,只有非参数的输入被添加到图的输入中。如果为None:自动选择行为,如果operator_export_type=OperatorExportTypes.ONNX等同于设置这个值为false,否则设置为True
**custom_opsets**: Optional[Mapping[str, int]] = None,
**export_modules_as_functions**: Union[bool, Collection[Type[torch.nn.Module]]] = False,
**autograd_inlining**: Optional[bool] = True,
)
'''
三、可视化onnx文件
netron.app网页可以打开onnx文件
onnx模型和torch模型几乎一致,onnx中的conv和maxpool层与torch模型中的conv和maxpool,onnx中的Gemm指代的是torch中的全连接层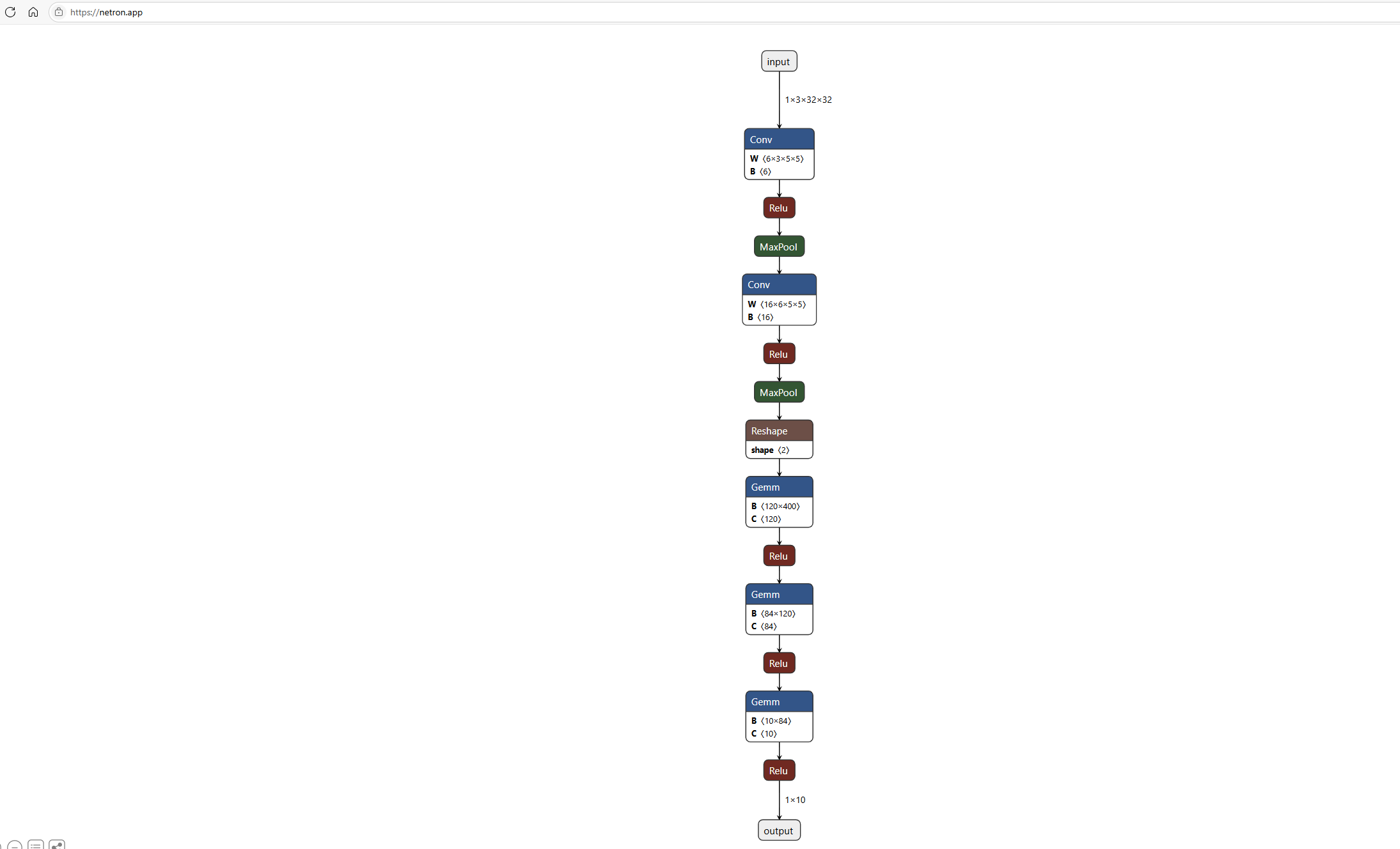
四、onnx算子手册
https://onnx.ai/onnx/operators/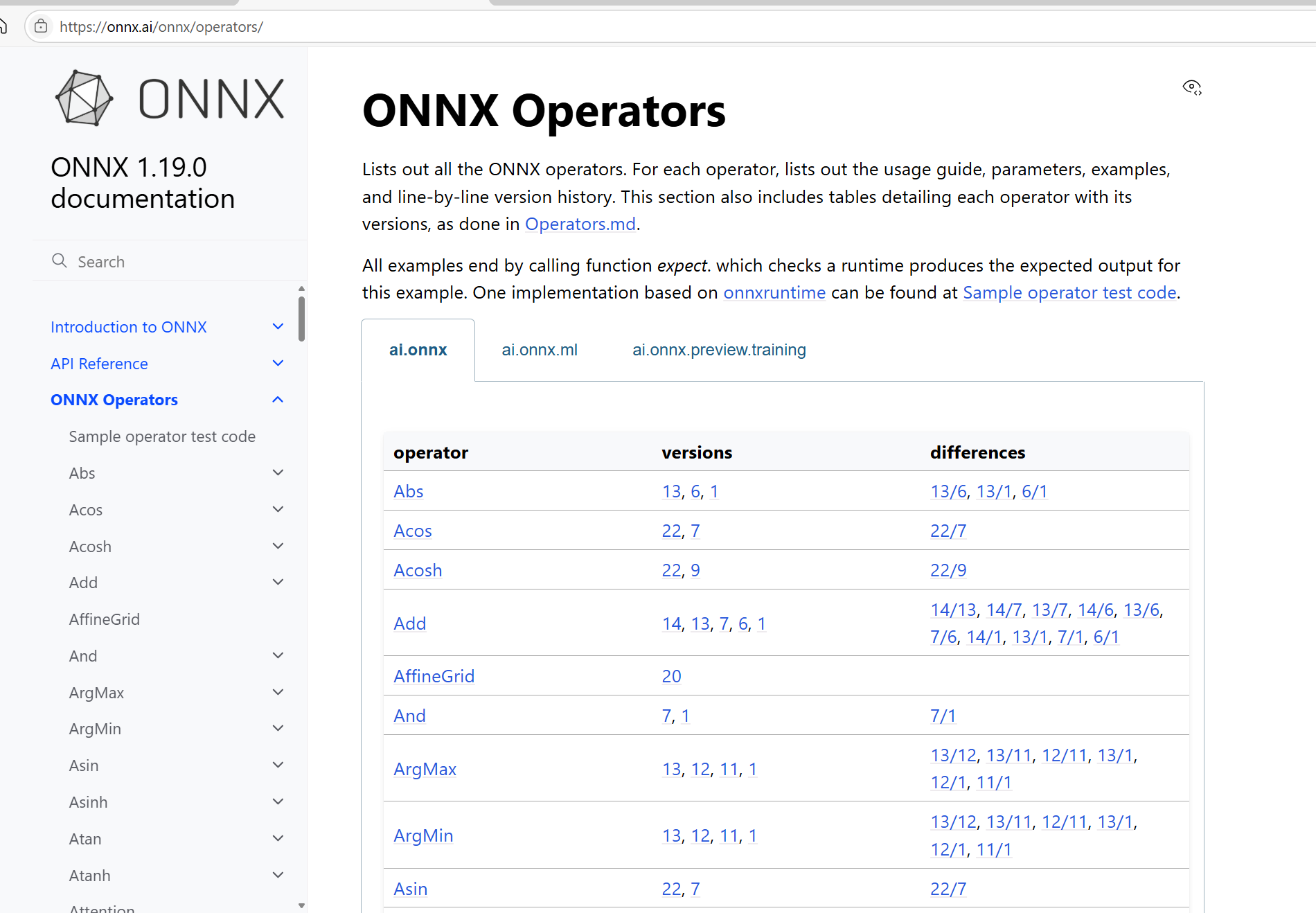
五、onnxruntime推理
1、安装
当只需要CPU推理时,下载命令为:
pip install onnxruntime
当需要GPU推理时,需要下载onnxruntime-gpu,并且需要注意cuda、cudnn和onnxruntime-gpu的版本对应。
安装指令为:
pip install onnxruntime==1.15
https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements该网页可以查询版本对应
cuda 12.x: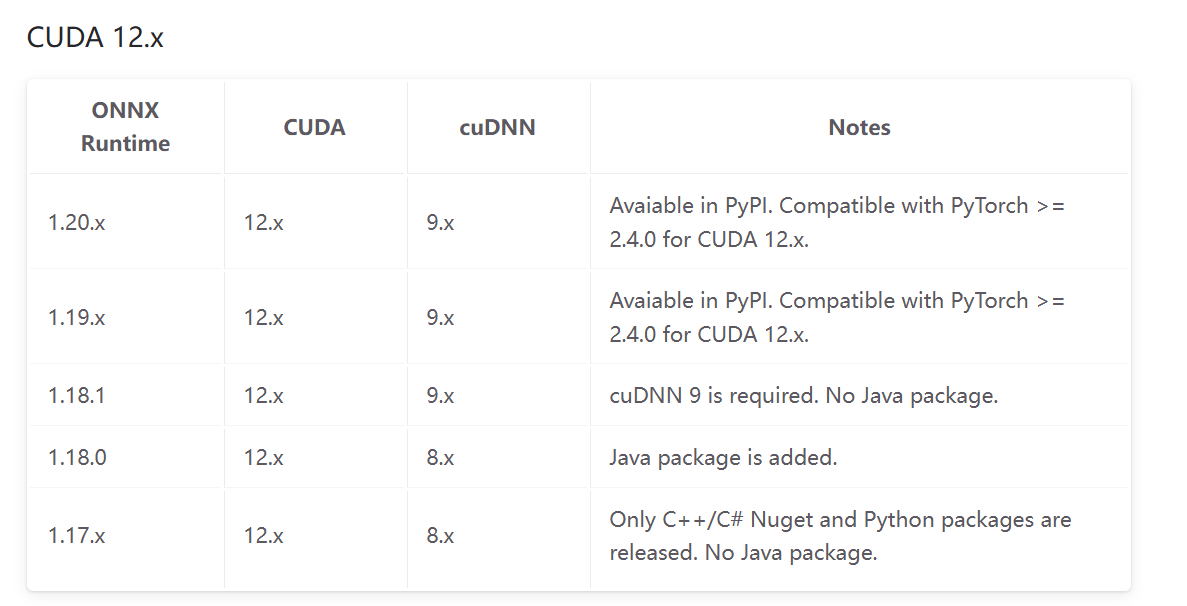
cuda 11.x(只截取了部分):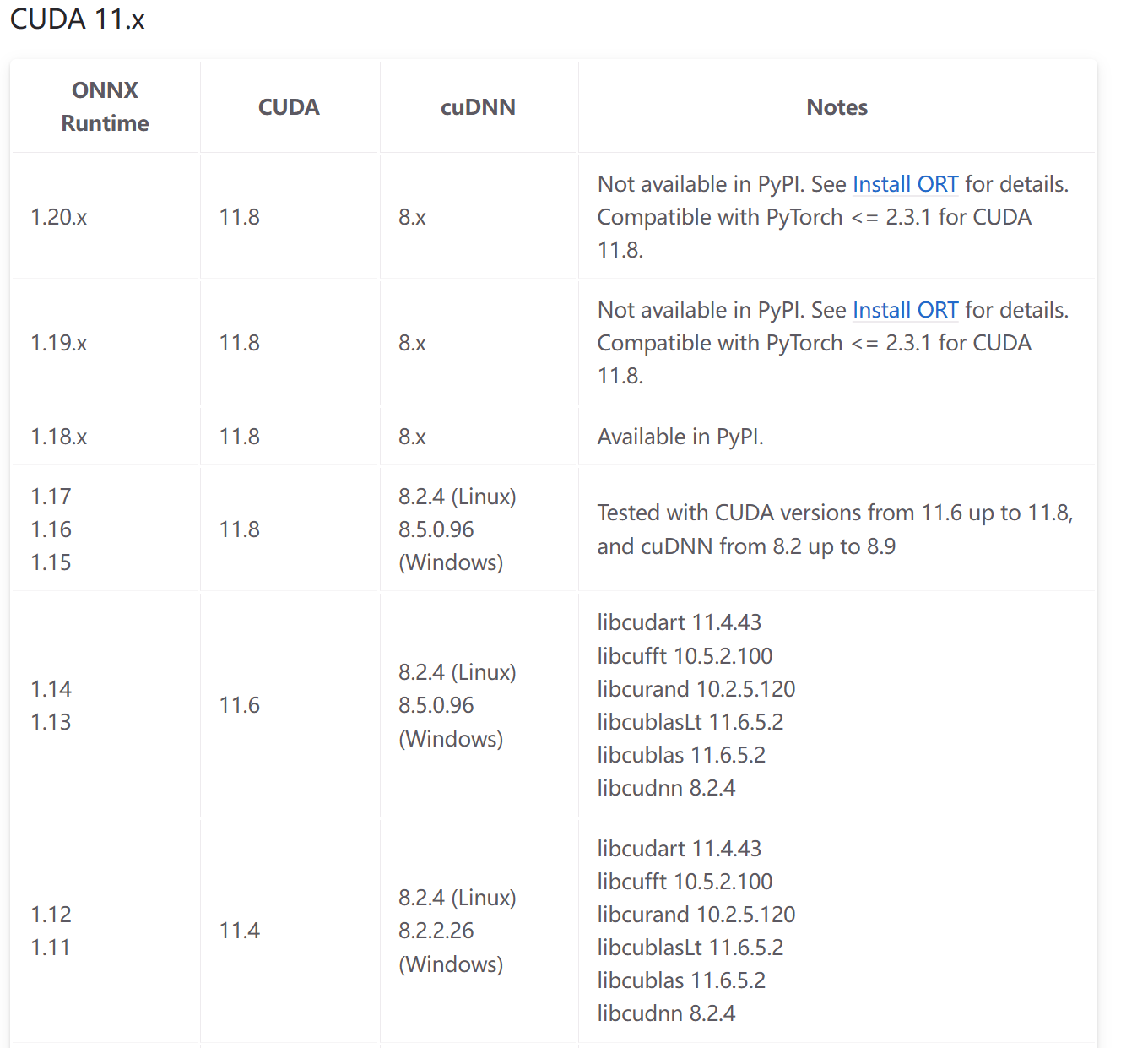
2、推理步骤
1)模型加载,定义session = ort.InferenceSession(‘yourmodel.onnx’, providers=[‘CPUExecutionProvider’]),如果使用GPU推理,providers=[‘CUDAExecutionProvider’]
2)数据预处理,因模型输入归一化、颜色变化等,需要预处理输入,
**【注】**pytorch的模型输入为tensor的(b, c, h, w), 而onnx为支持多种平台,它的数据输入必须为array数据格式,形状为(b, c, h, w)
3)执行推理调用session.run
4)推理结果后处理
3、data on CPU
输入和输出都在CPU上
import onnxruntime as ort
import torch
import numpy as np
from torchvision import transforms
import cv2
# 模型加载
session = ort.InferenceSession('lenet.onnx', providers=['CPUExecutionProvider'])
'''
class onnxruntime.InferenceSession(path_or_bytes: str | bytes | os.PathLike, sess_options: onnxruntime.SessionOptions | None = None, providers: Sequence[str | tuple[str, dict[Any, Any]]] | None = None, provider_options: Sequence[dict[Any, Any]] | None = None, **kwargs)
*path_or_bytes*:文件名
*sess_options*:Session选项
*providers*:提供器的可选序列,值可以设置为提供器名称,也可以是一个tuple格式包含多个提供器。如果不设置,则默认使用所有可以获得的提供器
*provider_options*:与providers中列出的提供程序相对应的可选选项字典序列。
'''
# 数据预处理
data_transform = transforms.Compose(
[transforms.ToPILImage(),
transforms.Resize((32, 32)), # 输入图像的尺寸须与cifar10的图像尺寸一致
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
# 加载图像,并转换成tensor
input_data = cv2.imread('E:\\MyWorkSpace\\Program\\python\\myPractices\\CNN\\image\\cat.png')
input_data = data_transform(input_data)
input_data = torch.unsqueeze(input_data, dim=0) # tensor (1,3,32,32)
# 转换为Numpy数组,并验证数据形状须为(1,3,32,32)
input_np = input_data.detach().numpy()
print("Input shape:", input_np.shape)
# 执行推理
input_name = session.get_inputs()[0].name # 获取onnx图中的输入name
'''
get_input(): 返回输入元数据作为onnxruntime.Nodearg的列表
onnxruntime.Nodearg;用于输入/输出的节点参数定义,包括参数名称、参数类型(包括类型和形状)
'''
output_name = session.get_outputs()[0].name # # 获取onnx图中的输出name
'''
get_output(): 返回输出元数据作为onnxruntime.Nodearg的列表
'''
pred = session.run([output_name], {input_name: input_np})[0]
'''
run(output_names, input_feed, run_options=None)
*output_names*: 输出名称
*input_feed*: 字典{input_name: input_value}
*run_options*:
返回结果列表,每个结果要么是numpy数组,要么是稀疏张量,要么是列表或字典。.
调用示例
sess.run([output_name], {input_name: x})
'''
pred_score = np.max(pred, axis=1)[0]
pred_label = np.argmax(pred, axis=1)[0]
print(pred_score, pred_label)
4、data on device
ONNX Runtime支持自定义数据结构,即IOBinding,该结构支持所有ONNX数据格式,允许用户将数据放置在设备上,如CUDA。为使用IOBinding,需要使用InferenceSession.run_with_iobinding()代替InferenceSession.run()。onnx图在CUDA上执行后,将推理结果再copy到CPU上。官方代码如下:
4.1 输入数据位于CPU上
推理是在CUDA上执行,结果也首先位于CUDA上,最后需要将结果转移到CPU上显示。
# X is numpy array on cpu
session = onnxruntime.InferenceSession(
'model.onnx',
providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
)
io_binding = session.io_binding()
'''
io_binding():返回iobinding对象
'''
# OnnxRuntime will copy the data over to the CUDA device if 'input' is consumed by nodes on the CUDA device
io_binding.bind_cpu_input('input', X)
'''
bind_cpu_input(name, arr_on_cpu): 将输入绑定到CPU上的数组
*name*:input name,
*arr_on_cpu*:输入值作为CPU上的python数组
'''
io_binding.bind_output('output')
'''
bind_output(name, device_type='cpu', device_id=0, element_type=None, shape=None, buffer_ptr=None)
*name*: output name
*device_type*: 设备类型,如cpu(默认值), cuda,cann等
*device_id*: 设备id,默认值为0
*element_type*: 输出元素的数据类型
*shape*: 输出数据的形状
*buffer_ptr*: 输出数据的内存指针
'''
session.run_with_iobinding(io_binding)
Y = io_binding.copy_outputs_to_cpu()[0]
'''
copy_outputs_to_cpu():复制结果到CPU
'''
4.2 输入输出都放置在CUDA上
#X is numpy array on cpu
X_ortvalue = onnxruntime.OrtValue.ortvalue_from_numpy(X, 'cuda', 0)
Y_ortvalue = onnxruntime.OrtValue.ortvalue_from_shape_and_type([3, 2], np.float32, 'cuda', 0) # Change the shape to the actual shape of the output being bound
session = onnxruntime.InferenceSession(
'model.onnx',
providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
)
io_binding = session.io_binding()
io_binding.bind_input(
name='input',
device_type=X_ortvalue.device_name(),
device_id=0,
element_type=np.float32,
shape=X_ortvalue.shape(),
buffer_ptr=X_ortvalue.data_ptr()
)
'''
bind_input(name, device_type='cpu', device_id=0, element_type=None, shape=None, buffer_ptr=None)
*name*: input name
*device_type*: 设备类型,如cpu(默认值), cuda,cann等
*device_id*: 设备id,默认值为0
*element_type*: 输入元素的数据类型
*shape*: 输入数据的形状
*buffer_ptr*: 输入数据的内存指针
'''
io_binding.bind_output(
name='output',
device_type=Y_ortvalue.device_name(),
device_id=0,
element_type=np.float32,
shape=Y_ortvalue.shape(),
buffer_ptr=Y_ortvalue.data_ptr()
)
session.run_with_iobinding(io_binding)
'''
run_with_iobinding(iobinding, run_options=None)
*iobinding*: 包含输入、输出绑定的iobing对象
*run_options*:
'''
4.3 输入输出都是pytorch的tensor格式
#X is numpy array on cpu
X_ortvalue = onnxruntime.OrtValue.ortvalue_from_numpy(X, 'cuda', 0)
Y_ortvalue = onnxruntime.OrtValue.ortvalue_from_shape_and_type([3, 2], np.float32, 'cuda', 0) # Change the shape to the actual shape of the output being bound
session = onnxruntime.InferenceSession(
'model.onnx',
providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
)
io_binding = session.io_binding()
io_binding.bind_input(
name='input',
device_type=X_ortvalue.device_name(),
device_id=0,
element_type=np.float32,
shape=X_ortvalue.shape(),
buffer_ptr=X_ortvalue.data_ptr()
)
io_binding.bind_output(
name='output',
device_type=Y_ortvalue.device_name(),
device_id=0,
element_type=np.float32,
shape=Y_ortvalue.shape(),
buffer_ptr=Y_ortvalue.data_ptr()
)
session.run_with_iobinding(io_binding)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)