机器学习实验7——支持向量机
本次实验涉及支持向量机的相关知识,支持向量机可用于二分类与回归问题上,相关概念并不复杂,但是如何找到最优超平面是很重要的问题,一般我们使用最大间隔来找到最优超平面,同时使用拉格朗日乘子法来简化推导过程。同时在划分过程中往往会发现一个超平面不能完全将数据集划分,这是我们可以使用软间隔,增加一定的容错,如果一个数据集是非线性的,那我们可以使用核函数,将数据集映射到更高维度的空间中,这样就可以进行分割。
一.算法概述
1.算法简介
支持向量机(Support Vector Machine, SVM)是一种强大的机器学习算法,可用于解决数据分类(二分类)和回归问题。在分类问题上,SVM的核心思想是在特征空间中找到一个最优的超平面,这个超平面能够最大化地分开不同类别的数据点。如在平面上有两个数据集,我们希望找到一条直线能够完美地分开这两个数据集,以此达到分类的效果。其中我们将不同数据类的y值设置为1与-1用于区分。
2.基于最大间隔分隔数据
但是在划分的过程中,能够较为完美地划分数据集的直线可能不仅一条,如下图所示,这三条直线都能较为完美地划分两个不同的数据集,但是如何确定哪一个是最优的直线呢。这时候我们需要寻找最大间距。
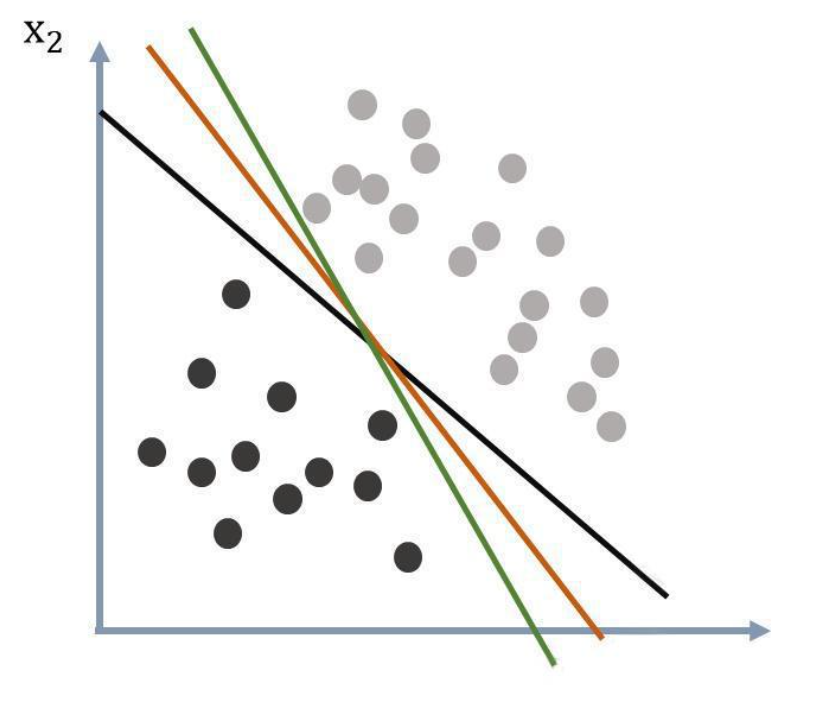
划分超平面可以通过来表示,因此在样本空间中,划分超平面可以通过线性方程来描述:
,其中
为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离。样本空间中任意点x到超平面(w,b)的距离表示为
,所以两个两个异类支持向量(距离超平面最近的两个异类点)到超平面的距离之和为
,被称为“间隔”。只要找出相对的w与b能使得
最大即使得
最小就能求出最优的超平面。
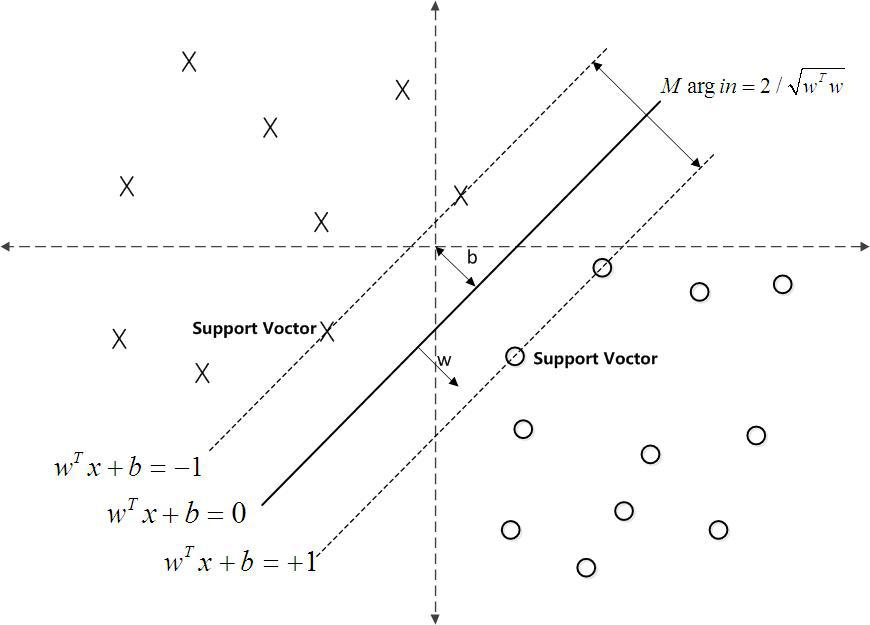
若能成功分类那函数最优解一般满足。
3.对偶问题
为了使得最小化,我们可以使用拉格朗日乘子法来求得,即对公式中每条约束添加拉格朗日乘子
≥0,则该问题的拉格朗日函数可写为
![]()
通过推导可求出
![]()
![]()
![]()
解出α后,可得最终模型:![]()
4.软间隔
如果假定训练样本在样本空间或特征空间中是线性可分的,即存在一个超平面能将不同类的样本完全划分开。然而,在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分。退一步说,即使恰好找到了某个核函数使训练样本在特征空间中线性可分,也很难判定这个貌似线性可分的结果不是由于过拟合造成的。缓解该问题的方法就是要引入“软间隔”概念,即允许支持向量机在一些样本上出错。
若所有样本全部分类正确则,这个称为“硬间隔”。所谓“软间隔”就是要求不要那么严格,允许出现少量的样本会分类错误。当然也不能太“软“”,所以软间隔支持向量机的目标是最大化间隔的同时分错的点尽可能少,即目标函数为:
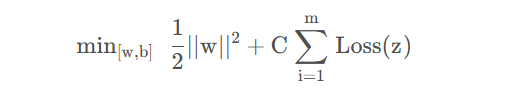
软间隔SVM模型为:
二.算法实现
使用SVMs建立自己的垃圾邮件过滤器。首先需要将每个邮件x变成一个n维的特征向量,并训练一个分类器来分类给定的电子邮件x是否属于垃圾邮件(y=1)或者非垃圾邮件(y=0)。
1.处理邮件
先替换文件中的符号、数字等非字母字符,再将剩下的非字母符号去除,并进行字母提取
def process_email(email_contents):
"""预处理电子邮件内容,返回词索引列表"""
email_contents = email_contents.lower()# 转换为小写
email_contents = re.sub(r'<[^<>]+>', ' ', email_contents)# 移除HTML标签
email_contents = re.sub(r'(http|https)://[^\s]*', 'httpaddr', email_contents)# 处理URLs
email_contents = re.sub(r'[^\s]+@[^\s]+', 'emailaddr', email_contents)# 处理电子邮件地址
email_contents = re.sub(r'[$]+', 'dollar', email_contents)# 处理美元符号
email_contents = re.sub(r'[0-9]+', 'number', email_contents)# 处理数字
words = re.split(r'[@$/#.-:&*+=\[\]?!(){},\'\'\">_<;%\s\n\r\t]+', email_contents)# 分词
# 词干提取和去除非字母字符
stemmer = PorterStemmer() #词干提取
word_indices = []
for word in words:
word = re.sub(r'[^a-zA-Z0-9]', '', word)
if len(word) < 1:
continue
stemmed = stemmer.stem(word)
word_indices.append(stemmed)
return word_indices2.读取词汇文件
def get_vocab_dict(reverse=False): #读取词汇表文件,返回词汇字典
vocab_dict = {}
with open('vocab.txt') as f:
for line in f:
(val, key) = line.split()
if not reverse:
vocab_dict[key] = int(val)
else:
vocab_dict[int(val)] = key
return vocab_dict3.将词索引转换为特征向量
def email_features(word_indices): #将词索引转换为特征向量
vocab_dict = get_vocab_dict()
n = len(vocab_dict)
features = np.zeros((n, 1))
for word in word_indices:
if word in vocab_dict:
features[vocab_dict[word]] = 1
return features4.训练SVM模型并评估性能
def train_svm_model(): #训练SVM模型并评估性能
data = loadmat('spamTrain.mat') #加载训练数据
X = data['X']
y = data['y'].flatten()
C = 0.1 #训练SVM模型
model = SVC(C=C, kernel='linear')
model.fit(X, y)
# 训练集准确率
p = model.predict(X)
print(f'训练集准确率: {np.mean(p == y) * 100:.2f}%')
# 加载测试数据
test_data = loadmat('spamTest.mat')
Xtest = test_data['Xtest']
ytest = test_data['ytest'].flatten()
# 测试集准确率
p_test = model.predict(Xtest)
print(f'测试集准确率: {np.mean(p_test == ytest) * 100:.2f}%')
return model5.预测邮件是否为垃圾邮件
def predict_new_email(model, email_path): #预测新邮件是否为垃圾邮件
with open(email_path, 'r') as f:
email_contents = f.read()
word_indices = process_email(email_contents)
x = email_features(word_indices).reshape(1, -1)
prediction = model.predict(x)
print(f'预测结果: {"垃圾邮件" if prediction[0] == 1 else "非垃圾邮件"}')
# 预测概率
confidence = np.abs(model.decision_function(x))
print(f'预测置信度: {confidence[0]:.4f}')完整代码:
import numpy as np
import re
from nltk.stem import PorterStemmer
from scipy.io import loadmat
from sklearn.svm import SVC
import matplotlib.pyplot as plt
def process_email(email_contents):
"""预处理电子邮件内容,返回词索引列表"""
email_contents = email_contents.lower()# 转换为小写
email_contents = re.sub(r'<[^<>]+>', ' ', email_contents)# 移除HTML标签
email_contents = re.sub(r'(http|https)://[^\s]*', 'httpaddr', email_contents)# 处理URLs
email_contents = re.sub(r'[^\s]+@[^\s]+', 'emailaddr', email_contents)# 处理电子邮件地址
email_contents = re.sub(r'[$]+', 'dollar', email_contents)# 处理美元符号
email_contents = re.sub(r'[0-9]+', 'number', email_contents)# 处理数字
words = re.split(r'[@$/#.-:&*+=\[\]?!(){},\'\'\">_<;%\s\n\r\t]+', email_contents)# 分词
# 词干提取和去除非字母字符
stemmer = PorterStemmer() #词干提取
word_indices = []
for word in words:
word = re.sub(r'[^a-zA-Z0-9]', '', word)
if len(word) < 1:
continue
stemmed = stemmer.stem(word)
word_indices.append(stemmed)
return word_indices
def get_vocab_dict(reverse=False): #读取词汇表文件,返回词汇字典
vocab_dict = {}
with open('vocab.txt') as f:
for line in f:
(val, key) = line.split()
if not reverse:
vocab_dict[key] = int(val)
else:
vocab_dict[int(val)] = key
return vocab_dict
def email_features(word_indices): #将词索引转换为特征向量
vocab_dict = get_vocab_dict()
n = len(vocab_dict)
features = np.zeros((n, 1))
for word in word_indices:
if word in vocab_dict:
features[vocab_dict[word]] = 1
return features
def train_svm_model(): #训练SVM模型并评估性能
data = loadmat('spamTrain.mat') #加载训练数据
X = data['X']
y = data['y'].flatten()
C = 0.1 #训练SVM模型
model = SVC(C=C, kernel='linear')
model.fit(X, y)
# 训练集准确率
p = model.predict(X)
print(f'训练集准确率: {np.mean(p == y) * 100:.2f}%')
# 加载测试数据
test_data = loadmat('spamTest.mat')
Xtest = test_data['Xtest']
ytest = test_data['ytest'].flatten()
# 测试集准确率
p_test = model.predict(Xtest)
print(f'测试集准确率: {np.mean(p_test == ytest) * 100:.2f}%')
return model
def predict_new_email(model, email_path): #预测新邮件是否为垃圾邮件
with open(email_path, 'r') as f:
email_contents = f.read()
word_indices = process_email(email_contents)
x = email_features(word_indices).reshape(1, -1)
prediction = model.predict(x)
print(f'预测结果: {"垃圾邮件" if prediction[0] == 1 else "非垃圾邮件"}')
# 预测概率
confidence = np.abs(model.decision_function(x))
print(f'预测置信度: {confidence[0]:.4f}')
if __name__ == "__main__":
model = train_svm_model() #训练模型
predict_new_email(model, 'emailSample1.txt') #预测示例邮件运行结果:

三.实验总结
本次实验涉及支持向量机的相关知识,支持向量机可用于二分类与回归问题上,相关概念并不复杂,但是如何找到最优超平面是很重要的问题,一般我们使用最大间隔来找到最优超平面,同时使用拉格朗日乘子法来简化推导过程。同时在划分过程中往往会发现一个超平面不能完全将数据集划分,这是我们可以使用软间隔,增加一定的容错,如果一个数据集是非线性的,那我们可以使用核函数,将数据集映射到更高维度的空间中,这样就可以进行分割。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)