目标检测之Faster R-CNN
阶段任务分类损失回归损失是否只对正样本回归RPN二分类交叉熵损失Smooth L1✅ 是Fast R-CNN多分类Softmax + 交叉熵Smooth L1(多类)✅ 是这种设计是 Faster R-CNN 成功的重要原因之一,为后续如 Mask R-CNN、RetinaNet 等提供了统一思路。
1. 引言
1.1 背景与发展脉络
目标检测是计算机视觉领域中的重要任务,它的目标是回答两个问题:图中有什么?这些物体在哪里?。这不仅要求模型能够识别目标的类别,还需要精确地定位目标的位置(即边框坐标)。相比图像分类任务,目标检测的难度显然更高。
早期的方法如 DPM(Deformable Part-based Model)基于手工特征和滑动窗口策略,计算量大、效果有限。随着深度学习的兴起,R-CNN 系列彻底改变了目标检测的发展路径。
1.2 从 R-CNN 到 Fast R-CNN 的演进简述
-
R-CNN(2014):首次将卷积神经网络(CNN)引入目标检测。它使用 Selective Search 提取候选框,然后对每个框进行特征提取和分类。但其最大问题是速度慢,因为每个候选框都要单独跑一次 CNN。
-
Fast R-CNN(2015):改进了 R-CNN 的结构,将整张图像只通过一次 CNN,然后使用 RoI Pooling 层从特征图中提取每个候选区域的特征。这样大大加快了速度。但它依然依赖 Selective Search 来生成候选框,仍然不是端到端的结构。
于是,Faster R-CNN 在此基础上进一步发展,成为第一个真正意义上的端到端目标检测框架,引入了自己的区域提议机制——RPN(Region Proposal Network),实现了速度与精度的双提升。
2. 整体架构概览
2.1 Faster R-CNN 的总体流程图
Faster R-CNN 的整体结构可以分为两个主要阶段:
- 特征提取 + 候选区域生成(RPN)
- 候选区域分类与边框回归
简要流程如下: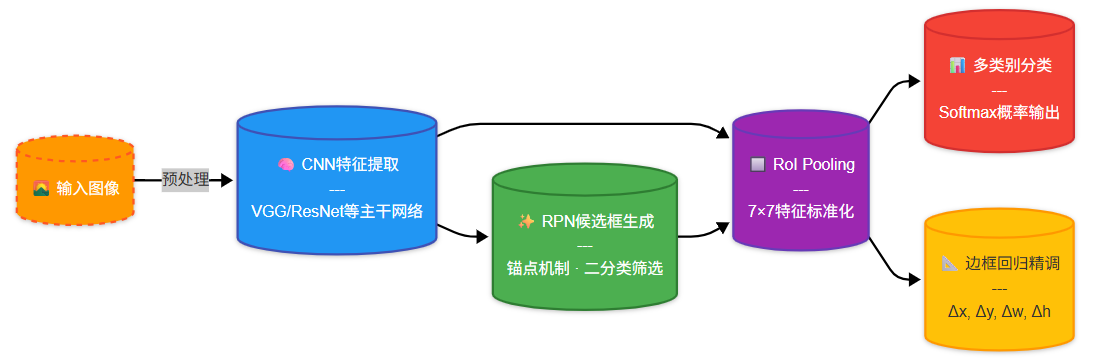
2.2 模块划分与任务职责
-
卷积神经网络(Backbone)
- 任务:提取整张图像的深度特征
- 常用模型:VGG16、ResNet 等
-
区域建议网络(RPN)
- 任务:在特征图上滑动窗口,生成一系列潜在的目标候选框(称为 Anchor)
- 创新点:用 CNN 学出哪些 Anchor 有可能是目标,而不是靠人工规则(RPN网络替代传统Selective Search)。
-
RoI Pooling 层
- 任务:将不同大小的候选区域统一成固定大小的特征块,方便后续分类和回归
-
分类与回归分支
- 任务:判断每个候选区域属于哪个类别(分类),并微调它的边框位置(回归)
总结一句话:Faster R-CNN 把“找目标”和“认目标”都集成进了一个统一的深度学习模型中,结构清晰、性能强大。
3. 核心模块解析
在 Faster R-CNN 中,整个目标检测流程由多个关键模块组成。每个模块都有特定的功能,共同完成从图像输入到目标识别与定位的任务。本节将依次介绍这四个核心模块。
3.1 特征提取网络(Backbone)
特征提取网络是 Faster R-CNN 的第一步,它的任务是将原始图像转化为高维的特征图。这些特征图保留了图像中的语义信息(例如:边缘、纹理、形状等),是后续目标检测模块的基础。
- 常用的 Backbone 网络包括:
- VGG16:结构简单,效果稳定,是早期常用的网络结构。
- ResNet(如 ResNet-50、ResNet-101):引入了残差连接(Residual Connection),能够训练更深的网络,提取更强的特征。
举个例子:如果把整张图像比作一幅风景画,Backbone 网络就像是一位画家,通过观察提炼出“山、河、人”的轮廓和位置,方便后续处理。
3.2 区域建议网络(Region Proposal Network, RPN)
RPN 是 Faster R-CNN 的核心创新之一。它的任务是从特征图中自动生成一组可能包含目标的候选区域(Region Proposals),而不再依赖传统的 Selective Search 方法。
🧩 Anchor 机制
- Anchor 是指预设的一组固定大小和长宽比的矩形框。
- 每个位置点上都生成多个 Anchor(比如 3 个尺度 × 3 种比例 = 9 个 Anchor)。
- RPN 会对每个 Anchor 判断两个问题:
- 这个框是不是目标?(分类任务)
- 如果是目标,它的位置应该如何微调?(回归任务)
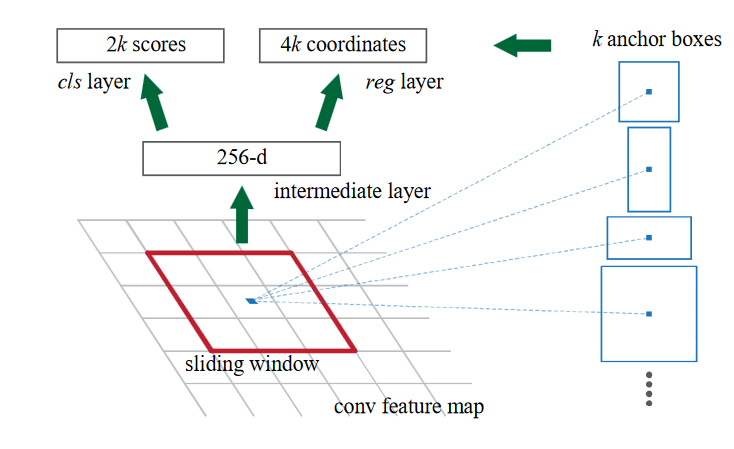
🔍 Softmax + Bounding Box Regression
- Softmax:对每个 Anchor 进行前景/背景分类。
- Bounding Box Regression:对 Anchor 的坐标进行微调,使之更贴近真实目标边框。
通俗理解:RPN 就像一位侦察兵,在地图上标出可能藏有“敌人”的区域,后面的模块再进一步确认和精确定位。
3.3 RoI Pooling 层
RPN 提供的候选框大小不一,而分类和回归模块要求输入是固定尺寸的。因此,需要将这些不同大小的区域,统一映射成相同尺寸的特征。
🎯 RoI Pooling
- 将每个候选框映射到特征图上,然后划分成固定网格(如 7×7)。
- 对每个网格区域进行 max pooling,最终得到固定维度的特征向量。
✅ RoI Align(Faster R-CNN 原始版本用的是 RoI Pooling,RoI Align 是后来的改进)
- 消除了 RoI Pooling 中的量化误差。
- 使用双线性插值保留更多位置信息,常用于 Mask R-CNN 中。
打个比方:RoI Pooling 就像是把不同大小的照片剪裁后放入同样大小的相框中,以便后面统一处理。
3.4 分类与回归子网络
在 RoI Pooling 层之后,提取到的固定维度特征会送入两个不同的分支:
🧠 分类分支(Classification Branch)
- 判断每个区域属于哪个类别(如:人、车、猫、狗等)。
- 使用 softmax 输出多个类别的概率分布。
📦 回归分支(Bounding Box Regression Branch)
- 精确调整目标框的位置和大小,使预测框尽量接近真实框(ground truth)。
- 输出为四个回归参数(中心点偏移、宽高缩放等)。
4. 关键创新点
Faster R-CNN 之所以在目标检测领域具有里程碑意义,核心原因就在于其提出的一系列创新,极大地提升了检测的速度与精度。本节我们将逐一讲解这些关键点。
4.1 引入 RPN:替代 Selective Search 的端到端建议区域生成
在传统的 R-CNN 或 Fast R-CNN 中,我们需要使用 Selective Search 来生成候选区域(Region Proposals),但它是一个独立的、耗时且不可学习的模块。
Faster R-CNN 直接在网络中引入了一个新的子网络——区域建议网络(Region Proposal Network, RPN),能够:
- 端到端地生成候选框
- 与检测网络共享卷积特征图
- 速度极快,每张图可生成上千个候选框,且几乎不增加计算开销
✅ 通俗理解: 以前我们要靠人工手动挑选“可疑区域”,现在让神经网络自己学会“哪里可能有目标”。
4.2 网络共享特征图:提速与优化
Faster R-CNN 中的 RPN 与后续分类/回归网络共享卷积层,也就是说:
- 整张图只做一次卷积提特征
- RPN 和 Fast R-CNN (这里的Fast R-CNN指ROIHead部分)基于同一特征图工作
这种结构有两个好处:
- 加快速度:大大减少重复计算
- 端到端训练:整个网络可以联合优化,更准确
✅ 类比解释: 就像一个城市地图被扫描一遍后,交警、快递员和导游都用这张地图做各自的任务,而不是每人重新绘一遍。
4.3 Anchor-Based 区域建议机制
在 RPN 中,Faster R-CNN 引入了 Anchor(锚框)机制,它的思路是:
- 在特征图的每个位置,预设多个不同尺度和长宽比的矩形框(anchor)
- 网络学习每个 anchor 是否包含目标,并对其进行微调(regression)
Anchor 的出现解决了:
- 不同目标大小不一的问题
- 替代了滑动窗口的暴力搜索方式
✅ 打个比方: 就像在每个格子上放几个不同尺寸的相框,问网络“这几个框哪个最可能框到一个目标?”然后再微调到最合适的位置。
4.4 多任务损失函数的设计(分类 + 边框回归)
Faster R-CNN 的一个关键创新点在于使用了多任务损失函数,它将**目标分类(classification)和边框回归(bounding box regression)**结合在一个统一的损失函数中,进行端到端的训练。
该损失函数在两个阶段中都存在:
- RPN 阶段:生成候选区域 proposal
- Fast R-CNN 阶段:对 proposal 进行分类与回归精调
🔹 第一阶段:RPN 多任务损失函数
RPN 的任务是:
- 判断每个 anchor 是否包含物体(分类,前景/背景)
- 对每个正样本 anchor 回归调整其位置(边框回归)
其损失函数如下:
L RPN ( p i , t i ) = 1 N cls ∑ i L cls ( p i , p i ∗ ) + λ ⋅ 1 N reg ∑ i p i ∗ L reg ( t i , t i ∗ ) L_{\text{RPN}}(p_i, t_i) = \frac{1}{N_{\text{cls}}} \sum_i L_{\text{cls}}(p_i, p_i^*) + \lambda \cdot \frac{1}{N_{\text{reg}}} \sum_i p_i^* L_{\text{reg}}(t_i, t_i^*) LRPN(pi,ti)=Ncls1i∑Lcls(pi,pi∗)+λ⋅Nreg1i∑pi∗Lreg(ti,ti∗)
这个公式结构与 Fast R-CNN 类似,表示为:
- L cls L_{\text{cls}} Lcls:二分类交叉熵损失(前景 / 背景)
- L reg L_{\text{reg}} Lreg:Smooth L1 损失函数
- p i ∗ p_i^* pi∗:Anchor 的标签(1 表示前景,0 表示背景)
- t i ∗ , t i t_i^*, t_i ti∗,ti:Ground truth 与预测的边框调整值(tx, ty, tw, th)
其中,边框回归目标 t ∗ t^* t∗ 的计算方式如下:
t x ∗ = x ∗ − x a w a , t y ∗ = y ∗ − y a h a , t w ∗ = log ( w ∗ w a ) , t h ∗ = log ( h ∗ h a ) \begin{aligned} t_x^* &= \frac{x^* - x_a}{w_a}, \quad & t_y^* &= \frac{y^* - y_a}{h_a}, \\ t_w^* &= \log\left(\frac{w^*}{w_a}\right), \quad & t_h^* &= \log\left(\frac{h^*}{h_a}\right) \end{aligned} tx∗tw∗=wax∗−xa,=log(waw∗),ty∗th∗=hay∗−ya,=log(hah∗)
其中:
- ( x ∗ , y ∗ , w ∗ , h ∗ ) (x^*, y^*, w^*, h^*) (x∗,y∗,w∗,h∗):GT 边框坐标
- ( x a , y a , w a , h a ) (x_a, y_a, w_a, h_a) (xa,ya,wa,ha):Anchor 的中心与尺寸
- 目标:预测 t i t_i ti接近 t i ∗ t_i^* ti∗
注意:
- 只有正样本 anchor(即 p i ∗ = 1 p_i^* = 1 pi∗=1)参与回归损失计算。
- 每张图通常只随机选取 256 个 anchor 参与训练,以保证正负样本的平衡。
🔸 第二阶段:Fast R-CNN 多任务损失函数
Fast R-CNN 接收 RPN 提供的 proposal,对每个 proposal 进行更细粒度的分类和回归,使用如下损失:
L FastRCNN ( p i , t i ) = 1 N cls ∑ i L cls ( p i , p i ∗ ) + λ ⋅ 1 N reg ∑ i p i ∗ L reg ( t i , t i ∗ ) L_{\text{FastRCNN}}(p_i, t_i) = \frac{1}{N_{\text{cls}}} \sum_i L_{\text{cls}}(p_i, p_i^*) + \lambda \cdot \frac{1}{N_{\text{reg}}} \sum_i p_i^* L_{\text{reg}}(t_i, t_i^*) LFastRCNN(pi,ti)=Ncls1i∑Lcls(pi,pi∗)+λ⋅Nreg1i∑pi∗Lreg(ti,ti∗)
这里:
- 分类是多类 softmax 分类(如“猫”,“狗”,“人”以及背景)
- 回归是对每一类都预测一个框(多类回归)
其中:
- L cls ( p i , p i ∗ ) = − log ( p i ( p i ∗ ) ) L_{\text{cls}}(p_i, p_i^*) = -\log(p_i^{(p_i^*)}) Lcls(pi,pi∗)=−log(pi(pi∗)) 是交叉熵损失
- L reg L_{\text{reg}} Lreg 是 Smooth L1 损失,对 ( x , y , w , h ) (x, y, w, h) (x,y,w,h) 分量分别求和
- p i ∗ ∈ { 1 , . . . , K } p_i^* \in \{1, ..., K\} pi∗∈{1,...,K}是真实类别编号,背景为 0
⚖️ 多任务损失的设计哲学
Faster R-CNN 的多任务损失设计带来以下好处:
- 分类与回归可以协同优化,提升检测性能;
- 两阶段结构保持一致,统一训练框架;
- 正负样本处理机制清晰,防止回归训练污染。
🧠 总结
Faster R-CNN 的两阶段多任务损失函数设计如下:
| 阶段 | 任务 | 分类损失 | 回归损失 | 是否只对正样本回归 |
|---|---|---|---|---|
| RPN | 二分类 | 交叉熵损失 | Smooth L1 | ✅ 是 |
| Fast R-CNN | 多分类 | Softmax + 交叉熵 | Smooth L1(多类) | ✅ 是 |
这种设计是 Faster R-CNN 成功的重要原因之一,为后续如 Mask R-CNN、RetinaNet 等提供了统一思路。
5. 参考文献
https://zhuanlan.zhihu.com/p/32404424
https://proceedings.neurips.cc/paper_files/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)