YOLOv11路面坑洼人工智能识别项目(本文提供完整数据集、项目代码、英伟达4090D显卡服务器环境)
路面坑洼人工智能识别项目(本文提供完整数据集、项目代码、英伟达4090D显卡服务器环境)。深度学习框架、YOLOv8、YOLOv11、DeepSeek、Llame项目实战。
YOLOv11路面坑洼人工智能识别项目课程
- 路面坑洼人工智能识别项目课程
- 路面坑洼人工智能识别项目课程阐述
- 路面坑洼人工智能识别项目课程实战
_ 初始化启动并创建
_ 进入实训平台,并启动打开进入实操界面
_ 导入所需库文件并验证环境
_ 读取数据
_ 读取待训练数据集并展示
_ 输出数据集的大小和数量
_ 展现详细数据格式
_ 展示数据图片
_ 开始训练
_ 设置训练参数
_ 推理
_ 将模型保存至本地 * 获取视频流并推理
路面坑洼人工智能识别项目课程阐述
背景与意义
现代城市路网作为交通系统的核心载体,其路面健康状况直接影响交通安全与运营效率。据交通运输部统计,我国每年因路面坑洼导致的交通事故超 8.7 万起,造成直接经济损失逾 30 亿元(2022 年度道路养护报告)。传统人工巡检模式存在检测周期长(平均 7-10 天/次)、夜间盲区多、微小病害漏检率高等突出问题,导致 60%以上的道路损坏未能实现及时修复(中国公路学会数据,2023)。在此背景下,基于机器视觉与深度学习技术的智能检测系统,为破解道路养护"发现滞后、处置延迟"的行业难题提供了突破性方案。
技术应用价值
智能路面坑洼检测系统通过车载摄像头、无人机航拍与边缘计算设备的协同部署,可实现三大核心功能突破:
- 全时域动态监测:支持白天/夜间、雨雪雾等复杂气象条件下的连续检测
- 毫米级精度识别:采用高清摄像头精准识别定位
- 智能分级预警:依据坑洼尺寸、位置等参数自动生成养护优先级评估
- 多模态数据融合:整合 GPS 定位、惯性导航与视觉数据,构建道路数字孪生模型
系统可将病害识别响应时间从传统模式的 72 小时缩短至 10 分钟以内,检测成本降低约 85%。在某省会城市试点中,系统使道路养护及时率从 58%提升至 94%,相关交通事故同比下降 41%(2023 年市政工程年报)。
行业推动作用
路面智能检测技术的普及应用正在引发道路养护领域的范式变革:
- 养护模式升级:推动"预防性养护"取代"被动式维修",延长道路使用寿命 30%-40%
- 资源优化配置:通过 AI 算法优化养护路线规划,降低燃油消耗与碳排放 20%以上
- 智慧城市赋能:构建城市级道路健康监测平台,为自动驾驶高精地图提供实时动态图层
- 标准体系重构:催生《智能道路检测技术规范》(JT/T 1343-2023)等新标准,引导行业数字化转型
该技术不仅提升了道路基础设施的服役性能,更通过构建"感知-分析-决策-执行"的智能闭环,为新型智慧交通系统的建设提供了关键性技术支撑。随着 5G-V2X 与车路协同技术的深度融合,路面状态实时感知将成为未来交通基础设施的标配能力。
路面坑洼人工智能识别项目课程实战
初始化启动并创建
进入"人工智能教学实训平台",并启动打开进入实操界面
首先进入https://www.lswai.com “机器视觉工作室” 并找到“实例分割”栏目进入路面坑洼项目收藏项目 这样我们就会在我的数据集内找到。
随后我们进入机器视觉工作室栏目 打开目标检测算法。
找到我们的里面坑洼项目,并开启训练。
并等待分配 GPU。
分配完成后请打开并等待数据转载。
请调整 GPU 使用时间 为 50 分钟
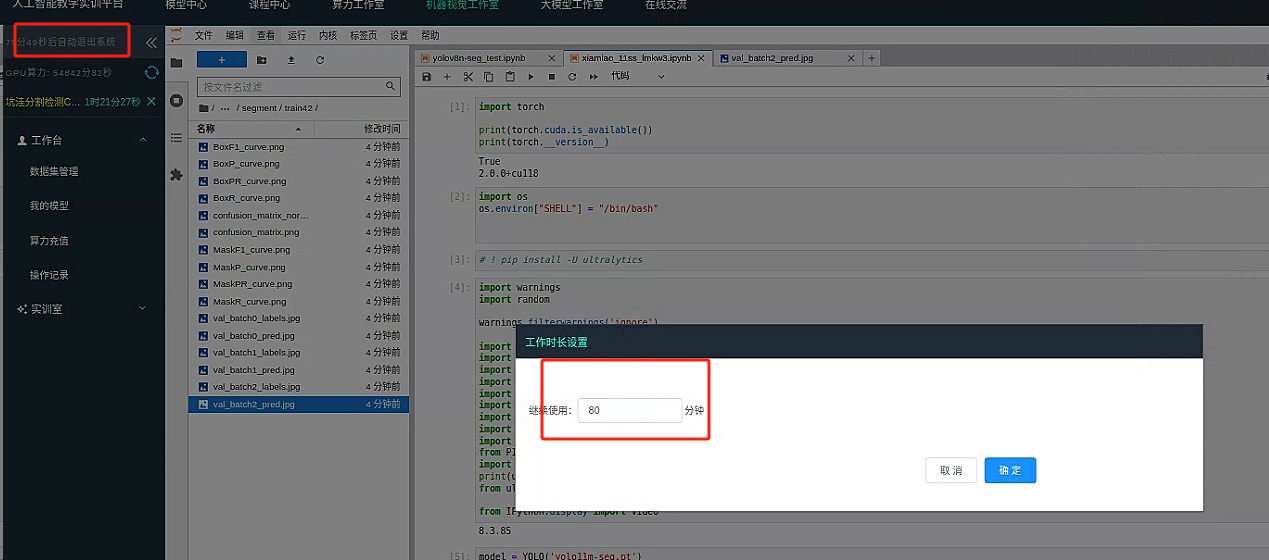
千万注意,如果 实例内部未曾打开过任何
jupyter notebook则可能会在一段时间后判定为 空闲服务器, 或者jupyter notebook距离上次活动 时间超过 25 分钟则也会被判定为空闲服务器 (保存,运行,创建新代码块,编写代码,等操作视为活跃) 如果需要使用纯命令行 ,请启动一个jupyter notebook并编写一个无限循环等待200s注意次此操作可能会造成服务器长期运行,浪费时长产生损失,实例一旦关闭会销毁所有数据无法恢复。
打开 示例代码运行即可测试环境。
导入所需库文件并验证环境
从现在开始 我们正式开始构建 里面坑洼项目 从数据到训练及最后的部署
示例代码可以忽略 也可使用 本教程,视为从新开发
验证环境 并导入一些可能用到的包
import torch
print(torch.cuda.is_available())
print(torch.__version__)
import warnings
import random
warnings.filterwarnings('ignore')
import os
import shutil
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import cv2
import yaml
from PIL import Image
from ultralytics import YOLO
from IPython.display import Video
- 读取数据
- 读取待训练数据集并展示
- 清理数据集
- 展示部分数据集
读取数据
读取待训练数据集并展示
dataset_path = '/root/data_yaml' # 平台数据集文件地址
yaml_file_path = os.path.join(dataset_path, 'data.yaml')
# 加载并打印 YAML 文件的内容
with open(yaml_file_path, 'r') as file:
yaml_content = yaml.load(file, Loader=yaml.FullLoader)
print(yaml.dump(yaml_content, default_flow_style=False))
输出数据集的大小和数量
# 设置训练和验证图像集的路径
train_images_path = os.path.join(dataset_path, 'train', 'images')
# valid_images_path = os.path.join(dataset_path, 'valid', 'images')
valid_images_path = os.path.join(dataset_path, 'valid', 'images')
# 初始化图像数量的计数器
num_train_images = 0
num_valid_images = 0
# 初始化集以保存图像的唯一大小
train_image_sizes = set()
valid_image_sizes = set()
# Check train images sizes and count
for filename in os.listdir(train_images_path):
if filename.endswith('.jpg'):
num_train_images += 1
image_path = os.path.join(train_images_path, filename)
with Image.open(image_path) as img:
train_image_sizes.add(img.size)
# 检查验证图像大小和数量
for filename in os.listdir(valid_images_path):
if filename.endswith('.jpg'):
num_valid_images += 1
image_path = os.path.join(valid_images_path, filename)
with Image.open(image_path) as img:
valid_image_sizes.add(img.size)
# 打印结果
print(f"Number of training images: {num_train_images}")
print(f"Number of validation images: {num_valid_images}")
# 检查训练集中的所有图像是否具有相同的大小
if len(train_image_sizes) == 1:
print(f"All training images have the same size: {train_image_sizes.pop()}")
else:
print("Training images have varying sizes.")
# 检查验证集中的所有图像是否具有相同的大小
if len(valid_image_sizes) == 1:
print(f"All validation images have the same size: {valid_image_sizes.pop()}")
else:
print("Validation images have varying sizes.")
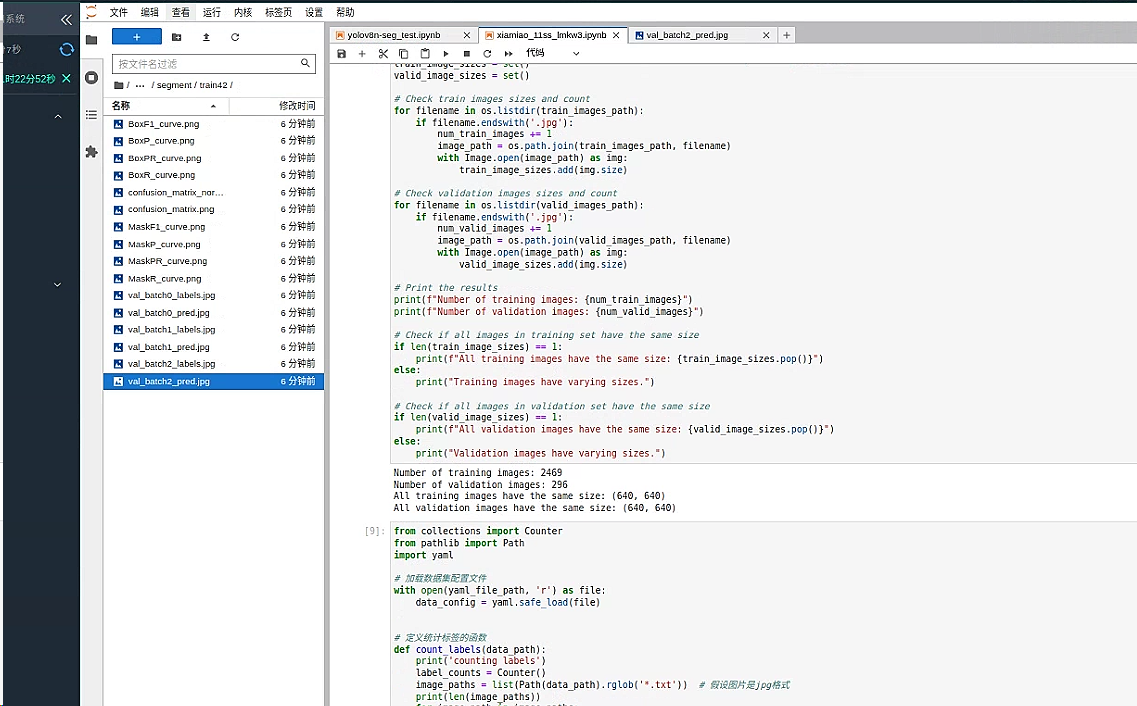
我们可以看到 有 2469 张训练集图片以及 296 个验证集图片,并且大小都统一为 640。
展现详细数据格式
读取全部的数据集 并计算标签构成
from collections import Counter
from pathlib import Path
# 加载数据集配置文件
with open(yaml_file_path, 'r') as file:
data_config = yaml.safe_load(file)
# 定义统计标签的函数
def count_labels(data_path):
print('counting labels')
label_counts = Counter()
image_paths = list(Path(data_path).rglob('*.txt')) # 假设图片是jpg格式
print(len(image_paths))
for image_path in image_paths:
label_path = image_path.with_suffix('.txt')
if label_path.exists():
# print(label_path)
with open(label_path, 'r') as file:
labels = file.readlines()
for label in labels:
label_class = int(label.split()[0])
label_counts[label_class] += 1
return label_counts
print('data_config labels', data_config)
print('data_config yaml_file_path+data_config', dataset_path + "/test")
# 统计每个数据集(训练、验证、测试)的标签
train_counts = count_labels(dataset_path + "/test/labels")
val_counts = count_labels(dataset_path + "/valid/labels")
test_counts = count_labels(dataset_path + "/train/labels")
print(train_counts, val_counts, test_counts)
# 获取每个类别的名称
class_names = data_config['names']
# 合并所有统计结果
total_counts = train_counts + val_counts + test_counts
print('total_counts', total_counts)
# 输出每个类别的标签数量
for class_id, count in total_counts.items():
print(f"类别 {class_names[class_id]} 有 {count} 个标签")
从输出结果可以看出来 只有 1 个标签
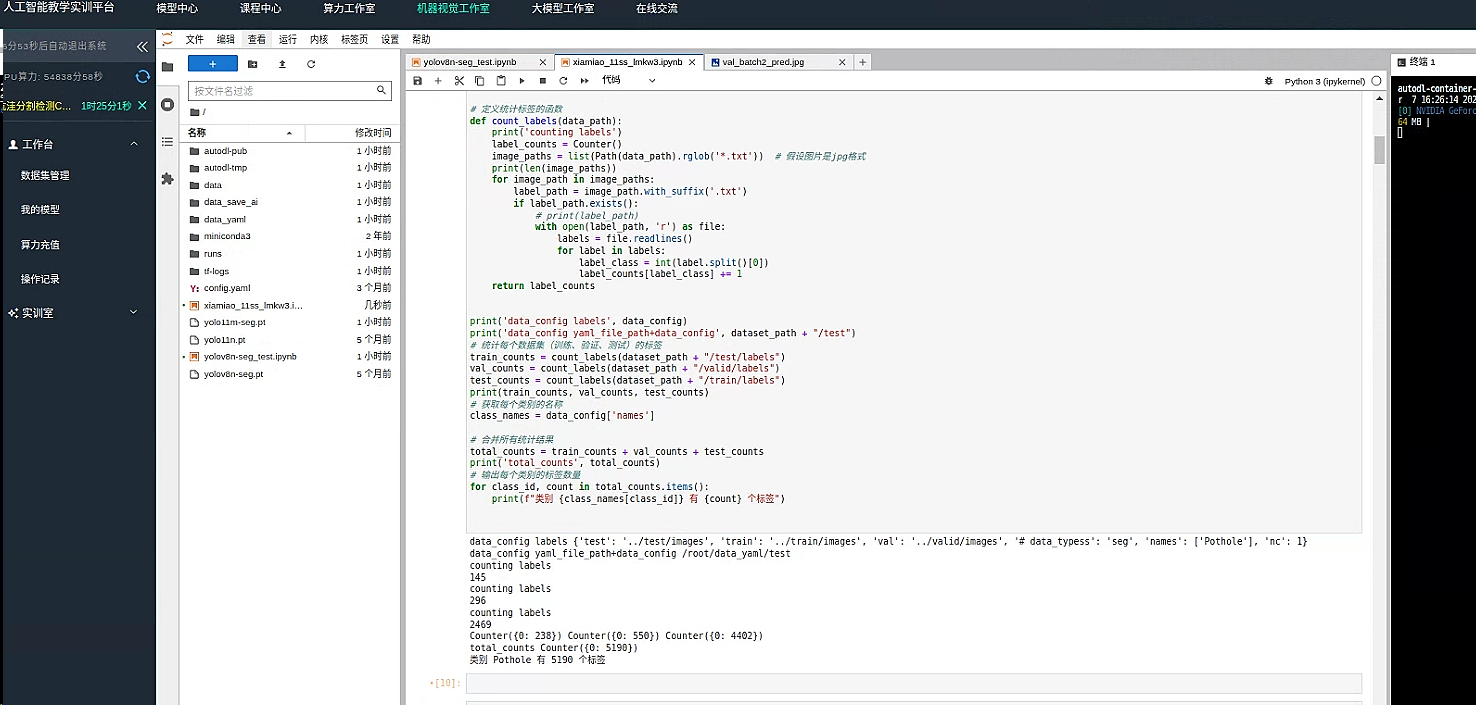
类别 Pothole 有 5190 个标签
因为我们需要使用大量正常路面构成反例 因此会有许多 图片的标签文件夹内是空的因为在 yolo 中空标签文件代表着反例 但如果没有 标签文件 只有图片 yolo 会忽略这个数据
展示数据图片
我们使用 plt 展示一部分数据集确保数据图片正确读取
# List all jpg images in the directory
image_files = [file for file in os.listdir(train_images_path) if file.endswith('.jpg')]
# Select 8 images at equal intervals
num_images = len(image_files)
selected_images = [image_files[i] for i in range(0, num_images, num_images // 13)]
# Create a 2x4 subplot
fig, axes = plt.subplots(3, 4, figsize=(20, 11))
# Display each of the selected images
for ax, img_file in zip(axes.ravel(), selected_images):
img_path = os.path.join(train_images_path, img_file)
image = Image.open(img_path)
ax.imshow(image)
ax.axis('off')
plt.suptitle('Sample Images from Training Dataset', fontsize=20)
plt.tight_layout()
plt.show()
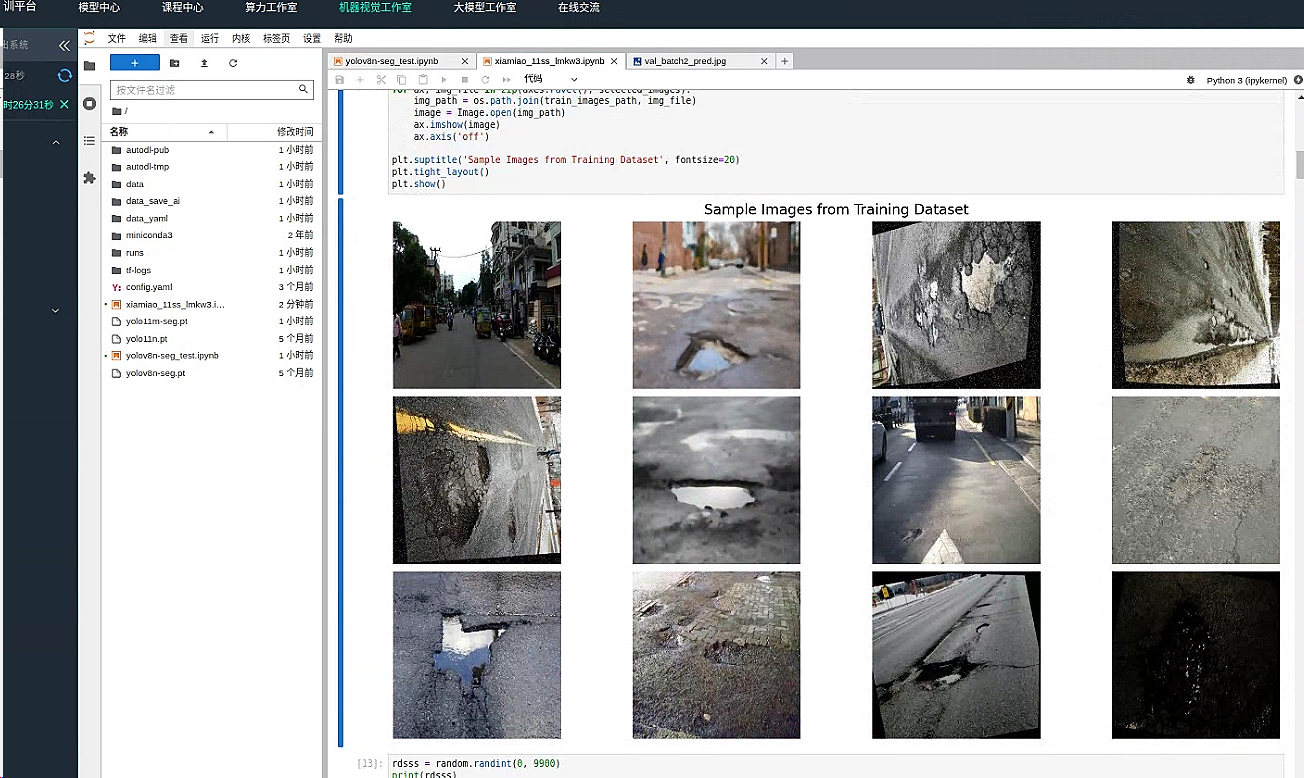
开始训练
设置训练参数
读取 模型框架 yolo11m-seg.pt
读取模型
model = YOLO('yolo11m-seg.pt')
print(model.info())
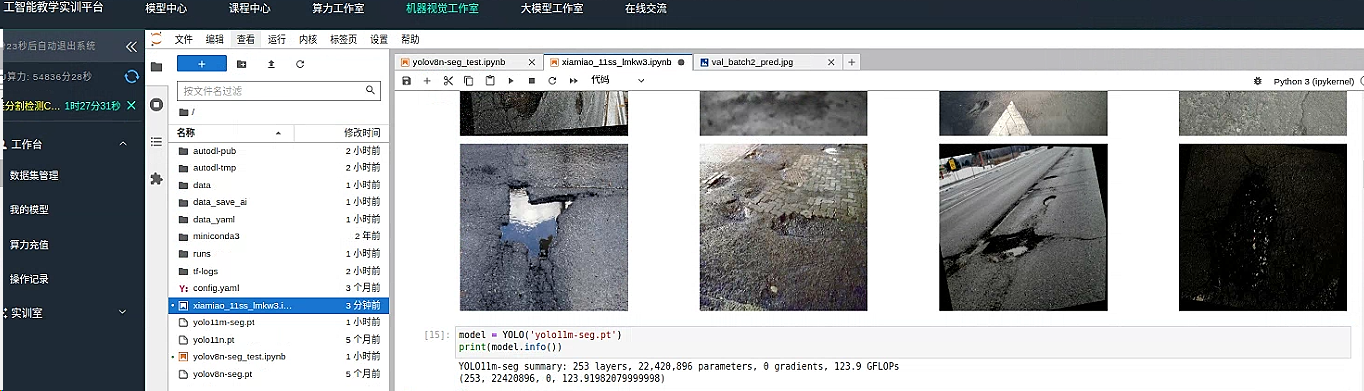
设置训练参数
rdsss = random.randint(0, 9900)
print(rdsss)
results = model.train(
data=yaml_file_path, # 数据集配置文件路径
epochs=100, # 延长训练周期
batch=20, # 根据显存情况适当调整 batch size
imgsz=768, # 提高输入分辨率
device=0,
patience=20, # 提高 Early Stopping 容忍度
optimizer='SGD', # 可试用 SGD(或者保持 auto,看哪种更适合分割任务)
lr0=0.003, # 降低初始学习率,确保稳定收敛
lrf=0.01,
weight_decay=5e-4, # 添加权重衰减,防止过拟合
# 数据增强参数(针对分割任务建议适当降低部分增强强度)
copy_paste=0.3, # 降低复制粘贴增强的比例
mixup=0.1, # 降低混合增强
mosaic=0.75, # 适度使用马赛克
close_mosaic=10, # 更早关闭马赛克增强,减少对边界的干扰
perspective=0.005, # 略微加大透视变换
flipud=0.2, # 垂直翻转适当降低
fliplr=0.5, # 水平翻转保持
degrees=20.0, # 稍微增大旋转角度
translate=0.2, # 增加平移幅度
scale=0.4, # 调整缩放范围,避免过大缩放导致细节丢失
)
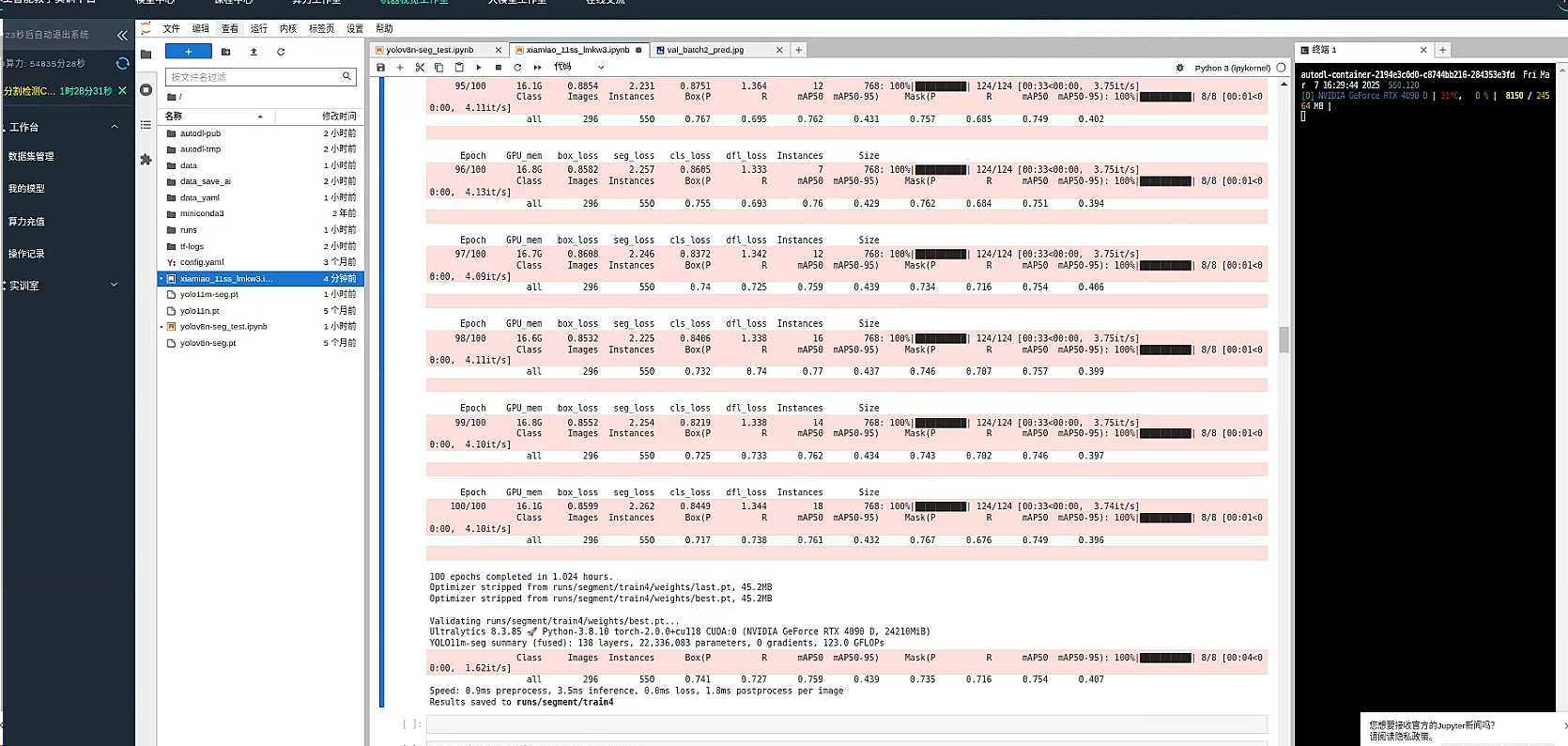
等待训练完成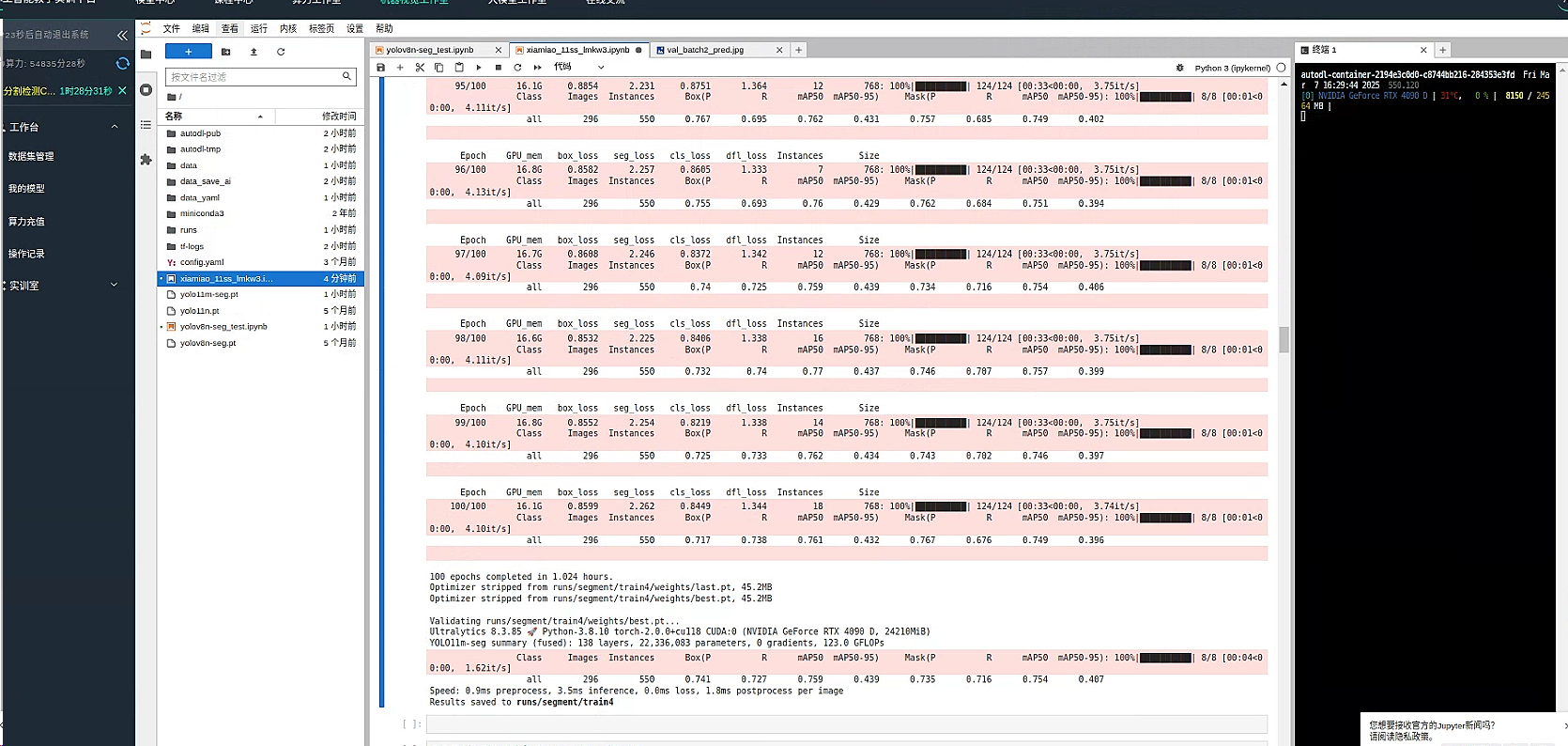
可以在 新建一个命令行 类似标签页一般 分屏使用 输入 gpustat -i 即可查看实时 GPU 使用量
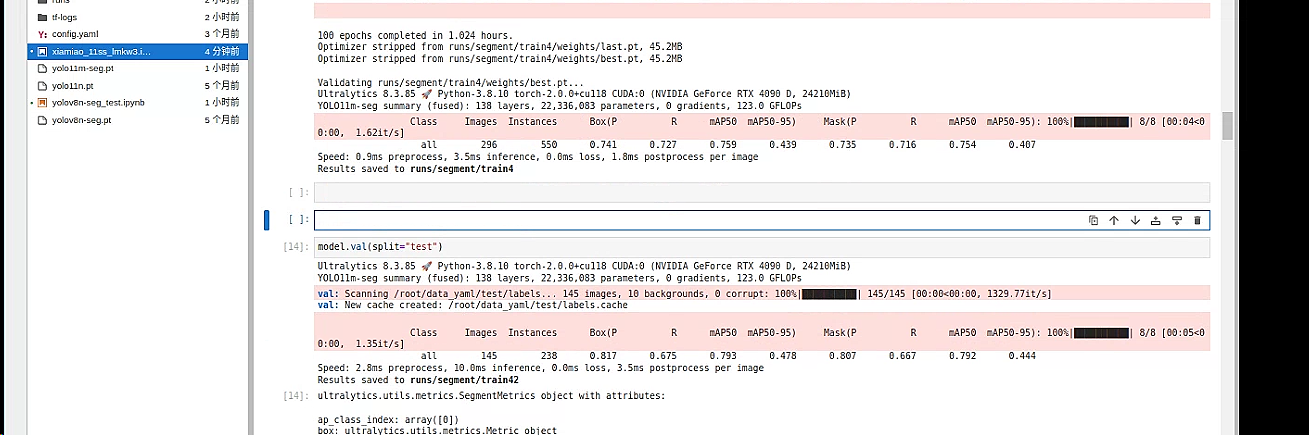
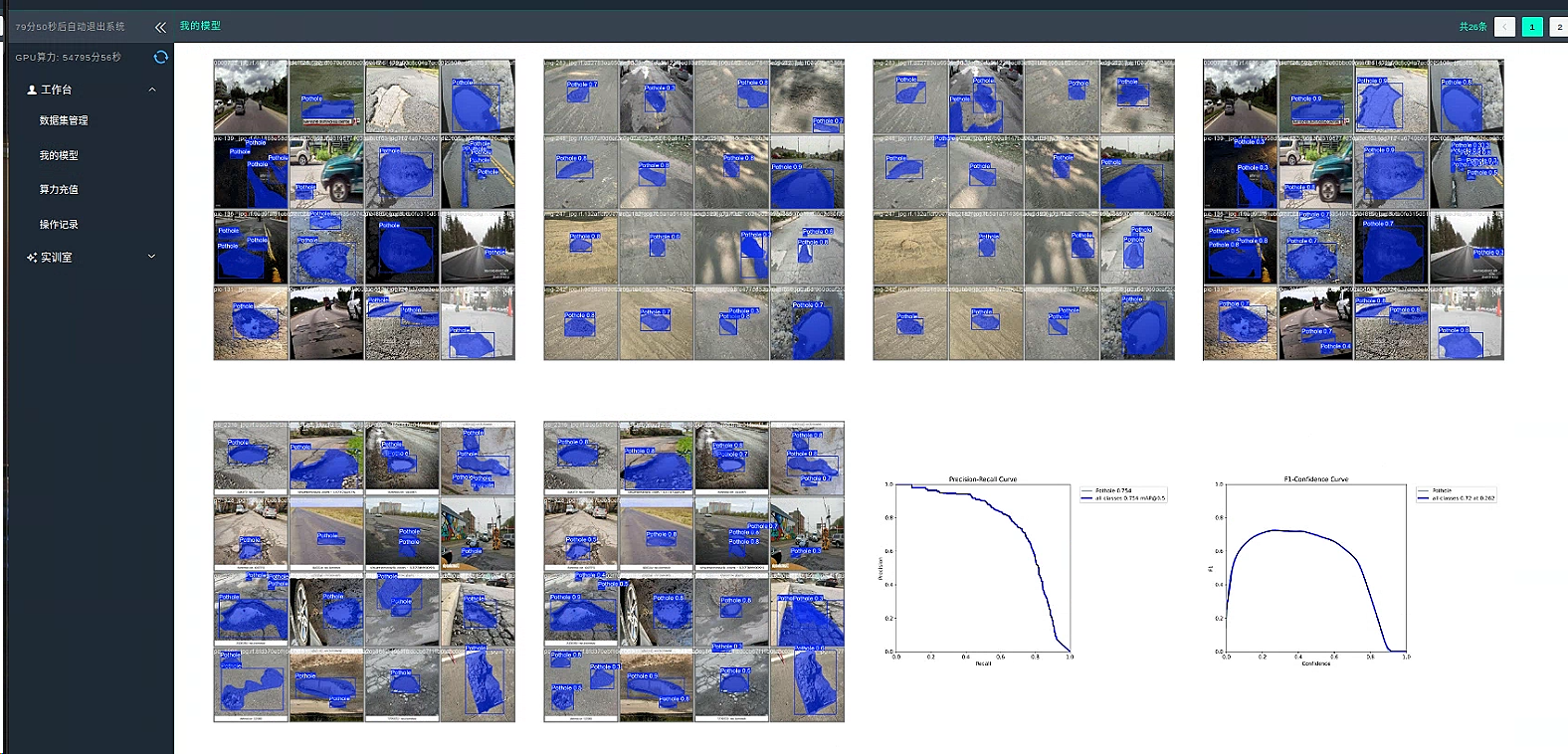
效率效果似乎还不错,整体来看,训练结果表现尚可,各项指标均表现平稳:
- 检测准确性与召回率: 整体(all 类别)的检测精度为 0.817,召回率为 0.675,说明大部分目标能被正确检测到,但在漏检方面仍有提升空间。
- mAP 指标: 检测任务中,mAP50 达到 0.793,表明在较宽松的 IoU 阈值下模型表现中规中矩;而 mAP50-95 仅为 0.478,说明在严格条件下效果还有较大提升余地。
- 推理速度: 每张图片预处理耗时约 2.8ms,推理时间约 10.0ms,后处理耗时约 3.5ms,总体运行效率较高,适合实时或近实时应用,但仍可针对推理流程进行进一步优化。
推理
训练完成了 我们开始开始 部署推理应用
预测试一下模型可用性
编写一个推理程序
import os
import random
import matplotlib.pyplot as plt
from ultralytics import YOLO
model = YOLO('runs/segment/train4/weights/best.pt')
print(model.info())
# 指定图片所在的文件夹路径
folder_path = '/root/data_yaml/test/images' # 修改为你的图片文件夹路径
# 支持的图片后缀
image_extensions = ('.jpg', '.jpeg', '.png')
# 获取文件夹中所有图片路径
image_files = [os.path.join(folder_path, f) for f in os.listdir(folder_path)
if f.lower().endswith(image_extensions)]
# 如果图片数量不足 12 张,则使用全部图片
num_images = min(12, len(image_files))
# 随机抽取 12 张图片(或不足 12 张时全部抽取)
selected_files = random.sample(image_files, num_images)
# 用于保存推理结果的列表
results_list = []
# 对每张图片进行推理
for img_file in selected_files:
result = model.predict(
source=img_file, # 输入图片文件
conf=0.35, # 置信度阈值
iou=0.45, # NMS IoU 阈值
imgsz=640, # 输入尺寸,与你训练时一致
# 如果模型需要区分任务类型(比如实例分割),可增加如下参数:
task='segment', # 指定任务为实例分割(依据你模型的 API)
stream=True,
verbose=False,
save=False # 此处不保存单独的结果文件,直接展示
)
results_list.append(result)
# 在 Jupyter Notebook 中展示推理结果
for gen in results_list:
# 对每个生成器中的所有结果进行迭代
for result in gen:
annotated_img = result.plot() # 假设 result 对象具有 plot 方法
plt.figure(figsize=(10, 10))
plt.imshow(annotated_img)
plt.axis('off')
plt.show()
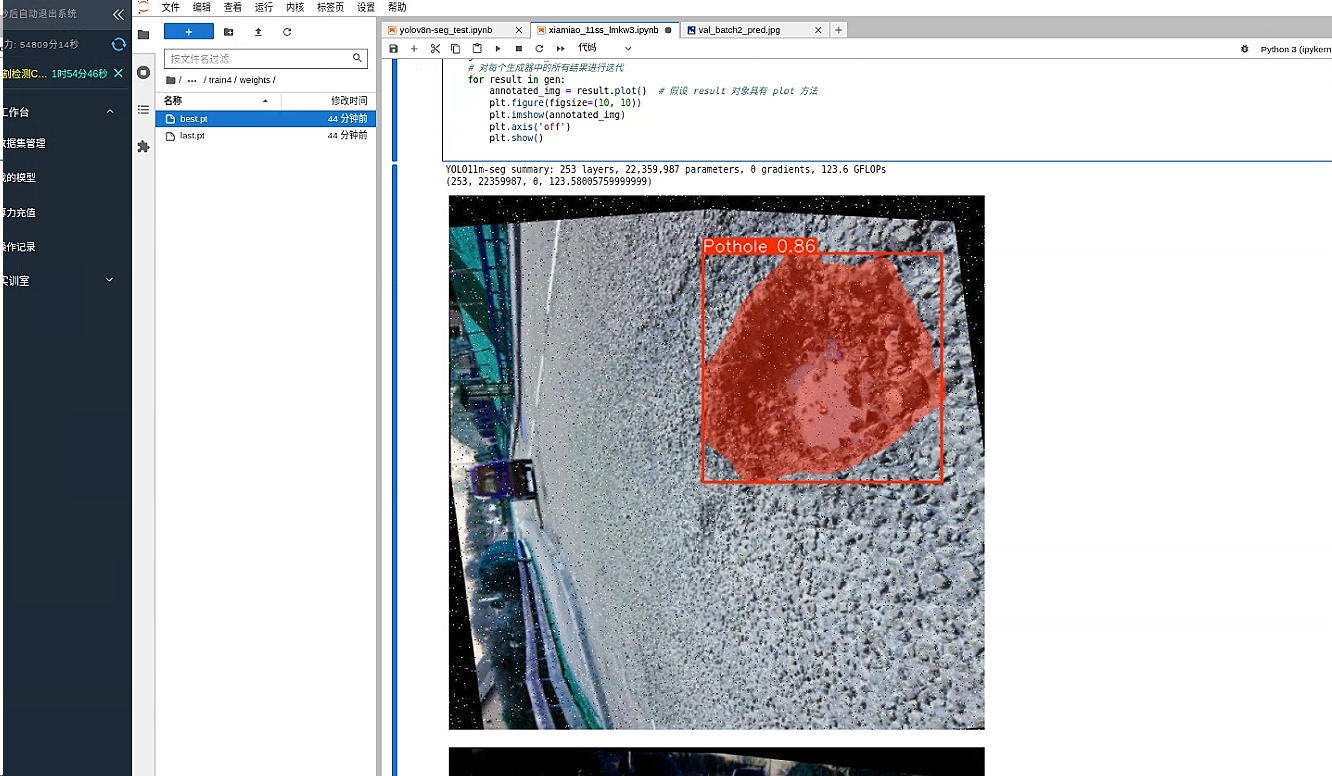
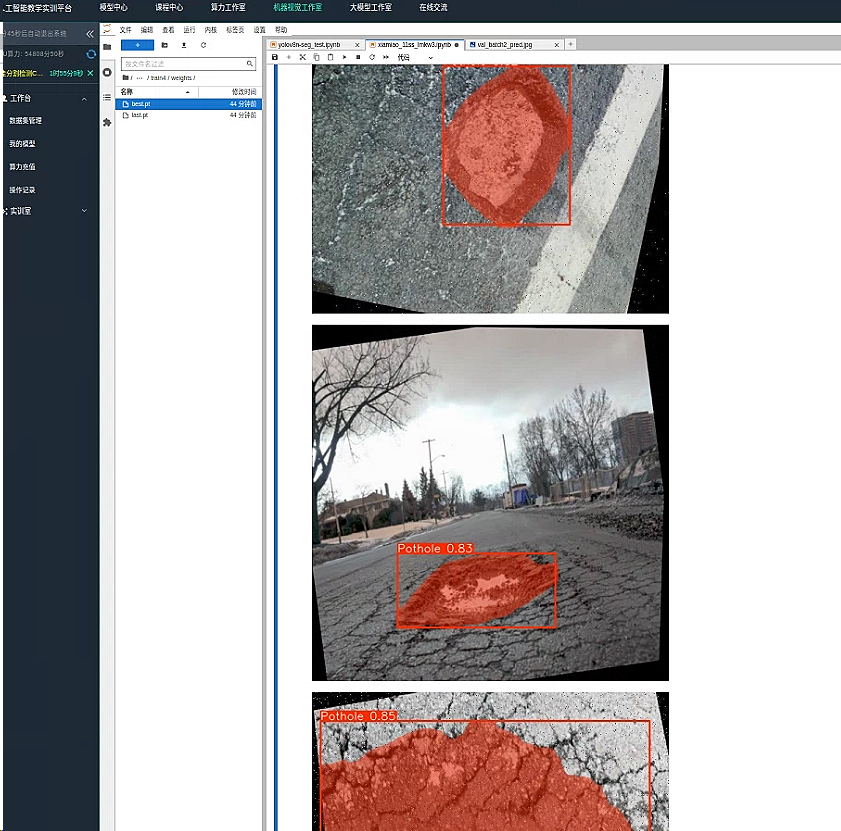
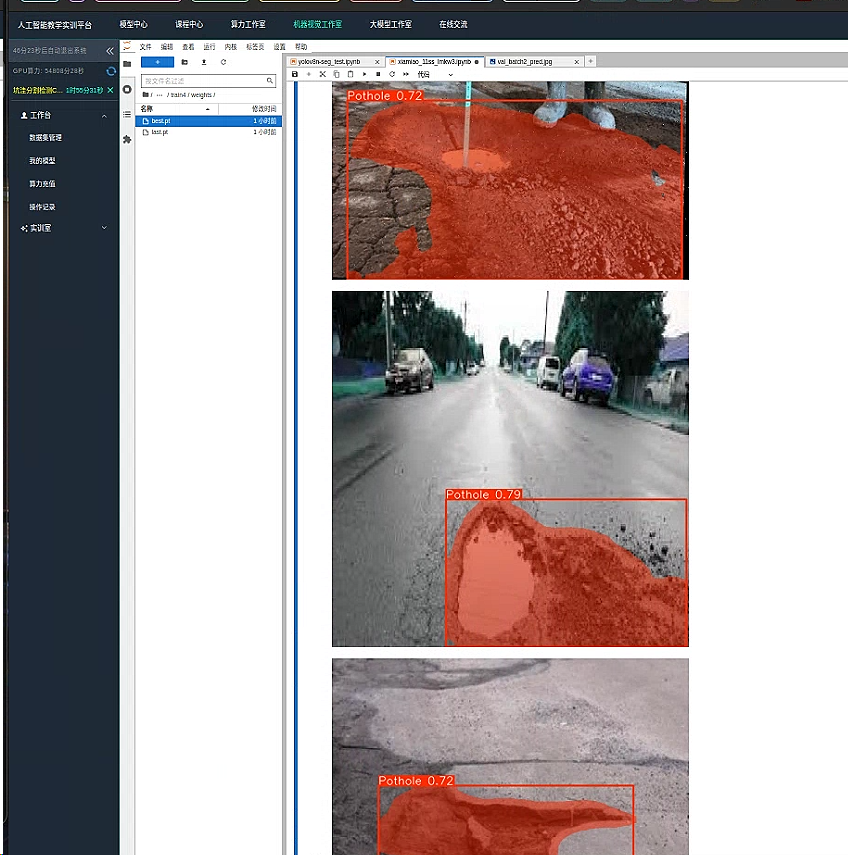
模型效果还不错 基本精确识别出了坑洼的位置
将模型保存至本地
首先我们将 pt 模型 转换未 cpu 可以使用的轻量级,根据训练时的数据量不一样可以考虑转换未 tensorRT 模型使用 GPU 进行推理
我们此处至使用单路视频流 因此使用 cpu 推理模式 即 onnx 格式模型.
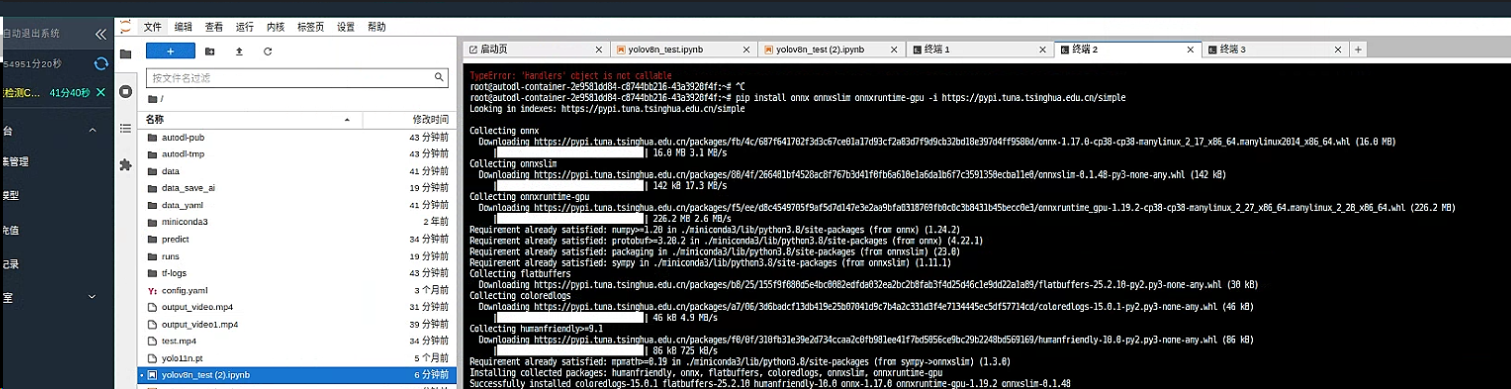
我们再次 进入命令行安装 onnx 库
pip install onnx onnxslim onnxruntime-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
转换 模型格式
from ultralytics import YOLO
# Load a model
model = YOLO("runs/segment/train4/weights/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
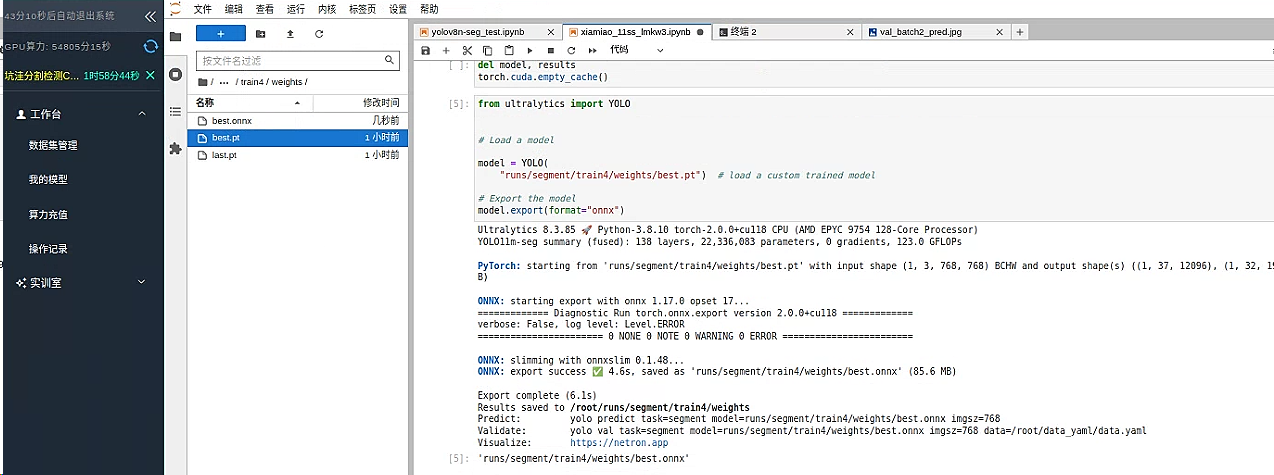
找到 runs 文件夹 下找到刚刚训练模型 runs/segment/train4/weights/best.pt
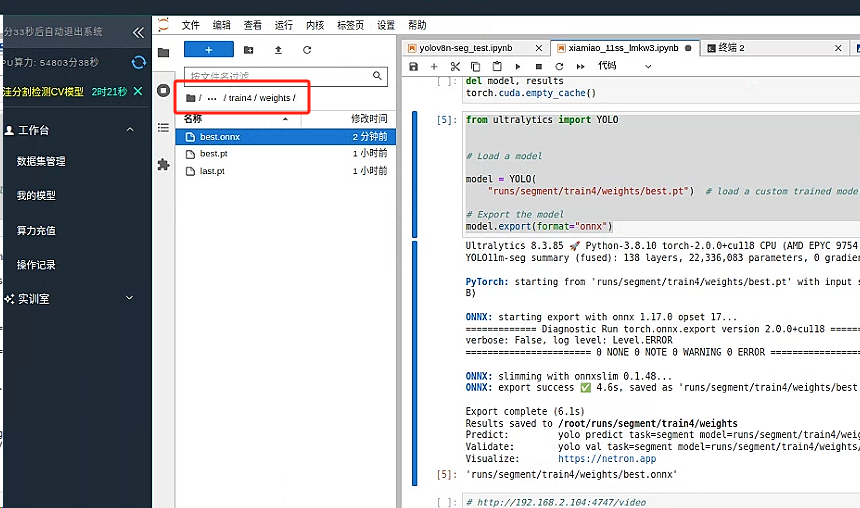
将其保存至 data_save_ai 文件夹下 或者等待 平台会将 runs 最后一次训练完成的模型数据保存至我的模型栏目 可以进入查看以及下载
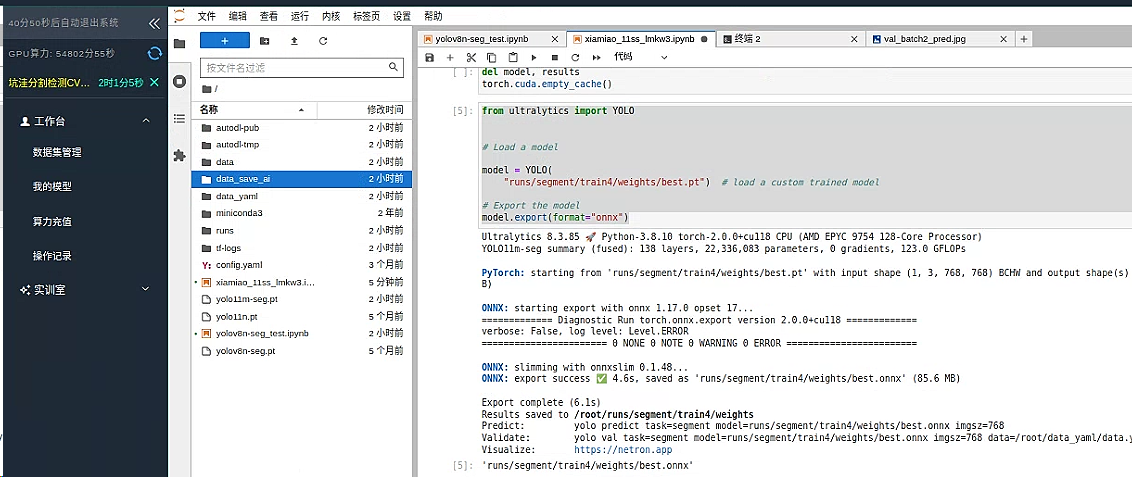
或者找到该文件夹内的模型将其下载至本地即可
进入 我的模型栏目 找到刚刚训练的模型
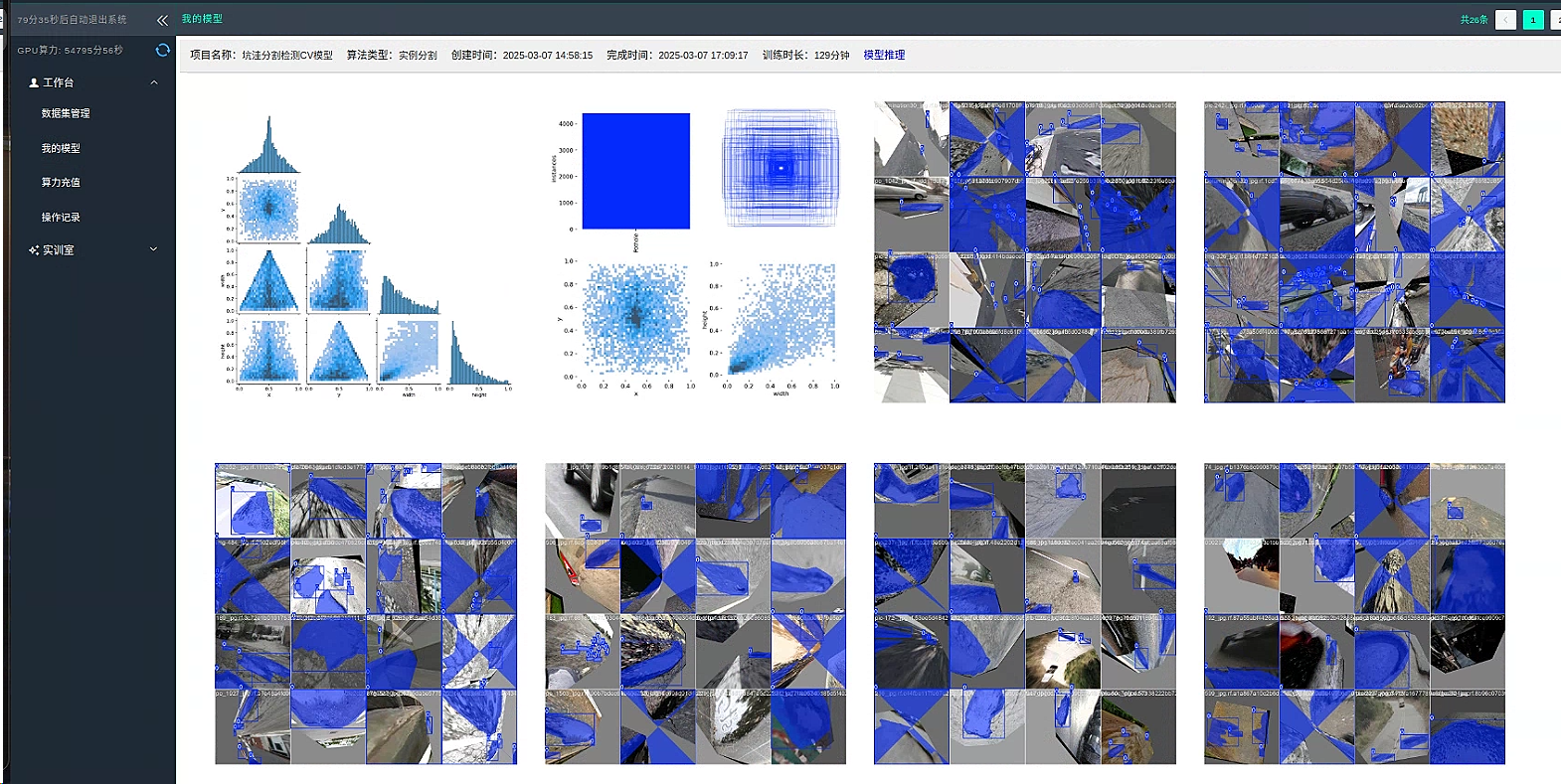
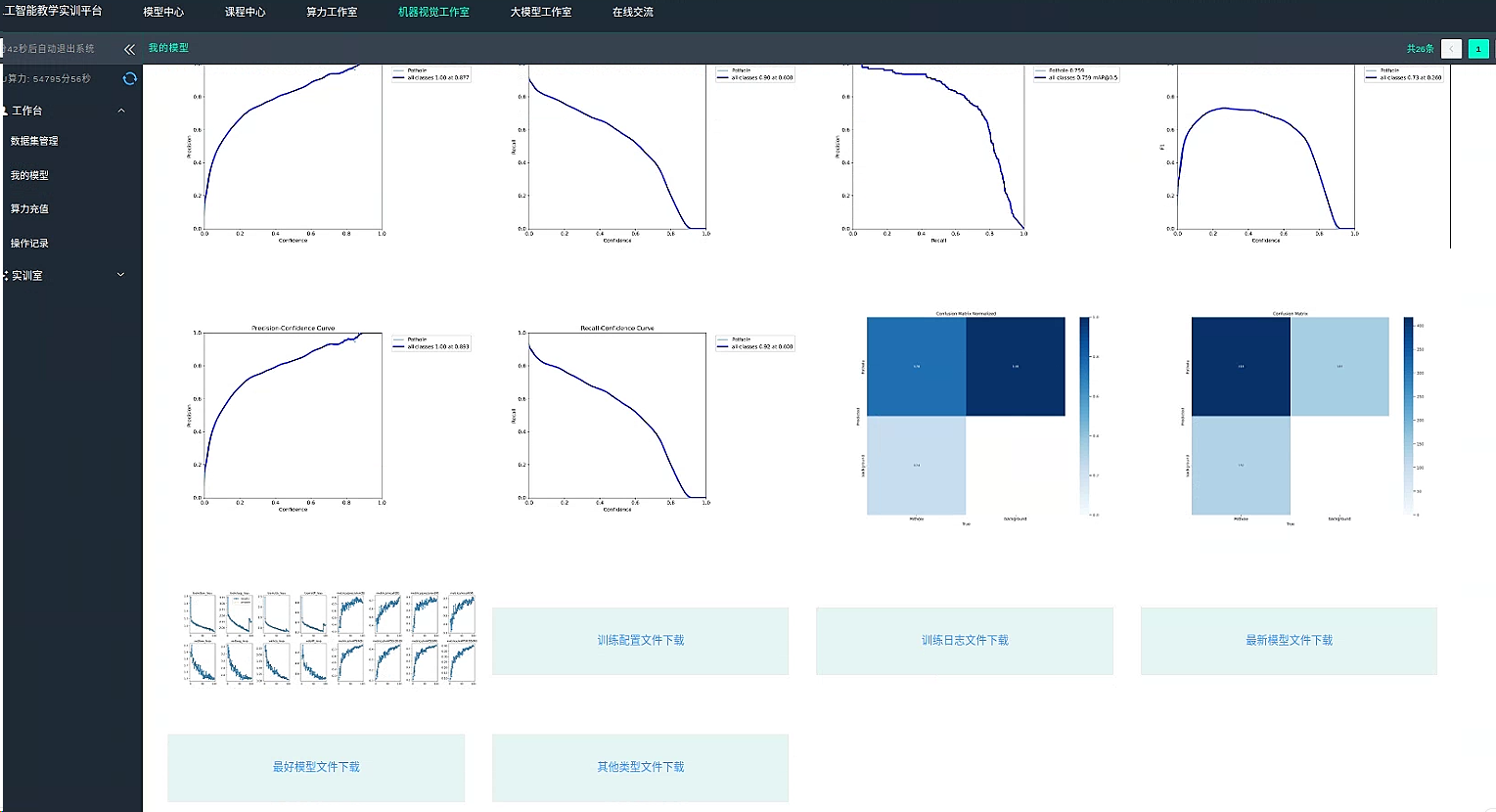
下载最好模型 best.pt 或者下载 其他类型文件 best.onnx
我们现在需要 其他类型文件 点击即可下载 ,我们下载后即可得到文件,自此 路面坑洼项目结束了。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)