Python进阶篇:Scikit-Learn 机器学习流程详解
·
一、Scikit-Learn 核心模块概述
1.1 Scikit-Learn 主要组件
二、数据集加载
Scikit-Learn 提供了多种内置数据集:
2.1 加载具体数据集
# 加载波士顿房价数据集(注意:新版scikit-learn已移除波士顿数据集,此处仅为示例)
# from sklearn.datasets import load_boston
# boston = load_boston() # 括号不能少
# 新版替代方案 - 加载糖尿病数据集
from sklearn.datasets import load_diabetes
# 加载数据集
diabetes = load_diabetes()
# 查看数据集信息
print("特征名称:", diabetes.feature_names)
print("目标值名称:", diabetes.target_names)
print("特征数据形状:", diabetes.data.shape)
print("目标值形状:", diabetes.target.shape)2.2 从总模块导入数据集
from sklearn import datasets
# 加载糖尿病数据集
diabetes = datasets.load_diabetes()
# 加载鸢尾花数据集
iris = datasets.load_iris()
# 加载手写数字数据集
digits = datasets.load_digits()三、数据预处理
3.1 常用预处理方法
from sklearn.preprocessing import (
Normalizer, # 正则化(按样本单位向量化)
MinMaxScaler, # 归一化(缩放到[0,1]区间)
StandardScaler, # 标准化(均值为0,方差为1)
LabelBinarizer # 标签二值化
)3.2 预处理示例
import numpy as np
from sklearn.preprocessing import MinMaxScaler, StandardScaler, Normalizer
# 示例数据
data = np.array([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
# 1. 归一化 - 缩放到[0,1]范围
minmax_scaler = MinMaxScaler()
minmax_scaled = minmax_scaler.fit_transform(data)
print("\n归一化结果:\n", minmax_scaled)
# 2. 标准化 - 使均值为0,方差为1
standard_scaler = StandardScaler()
standard_scaled = standard_scaler.fit_transform(data)
print("\n标准化结果:\n", standard_scaled)
# 3. 正则化 - 按样本转换为单位向量
normalizer = Normalizer()
normalized = normalizer.fit_transform(data)
print("\n正则化结果:\n", normalized)
# 4. 标签二值化 - 将类别标签转为二进制形式
from sklearn.preprocessing import LabelBinarizer
labels = ['猫', '狗', '猫', '狗', '鸟']
binarizer = LabelBinarizer()
binary_labels = binarizer.fit_transform(labels)
print("\n标签二值化结果:\n", binary_labels)
print("类别:", binarizer.classes_)四、数据集划分
4.1 数据集划分方法
from sklearn.model_selection import train_test_split
# 示例划分参数:
# test_size: 测试集比例
# train_size: 训练集比例(不常用)
# random_state: 随机种子(确保结果可复现)
# shuffle: 是否打乱数据顺序
# stratify: 按指定列进行分层抽样4.2 划分示例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 目标变量
# 划分数据集 (70%训练, 30%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.3, # 测试集占30%
random_state=42, # 随机种子
shuffle=True, # 打乱数据
stratify=y # 分层抽样,保持类别比例
)
# 检查划分结果
print(f"训练集样本数: {len(X_train)} ({len(X_train)/len(X):.1%})")
print(f"测试集样本数: {len(X_test)} ({len(X_test)/len(X):.1%})")五、模型评估
5.1 常用评估指标
from sklearn import metrics
# 分类任务指标
metrics.accuracy_score(y_true, y_pred) # 准确率
metrics.precision_score(y_true, y_pred) # 精确率
metrics.recall_score(y_true, y_pred) # 召回率
metrics.f1_score(y_true, y_pred) # F1分数
metrics.confusion_matrix(y_true, y_pred) # 混淆矩阵
metrics.classification_report(y_true, y_pred) # 综合评估报告
# 回归任务指标
metrics.mean_absolute_error(y_true, y_pred) # 平均绝对误差(MAE)
metrics.mean_squared_error(y_true, y_pred) # 均方误差(MSE)
metrics.r2_score(y_true, y_pred) # R²决定系数5.2 分类评估示例
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
# 加载乳腺癌数据集
data = load_breast_cancer()
X, y = data.data, data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林分类器
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 1. 混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
# 2. 各项指标
print("\n分类报告:\n", classification_report(y_test, y_pred))
# 3. 单个指标
print("\n准确率:", accuracy_score(y_test, y_pred))
print("精确率:", metrics.precision_score(y_test, y_pred))
print("召回率:", metrics.recall_score(y_test, y_pred))
print("F1分数:", metrics.f1_score(y_test, y_pred))5.3 回归评估示例
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 加载糖尿病数据集
diabetes = load_diabetes()
X, y = diabetes.data, diabetes.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 1. 均方误差(MSE)
mse = mean_squared_error(y_test, y_pred)
print("均方误差(MSE):", mse)
# 2. R²决定系数
r2 = r2_score(y_test, y_pred)
print("R²决定系数:", r2)
# 3. 平均绝对误差(MAE)
mae = metrics.mean_absolute_error(y_test, y_pred)
print("平均绝对误差(MAE):", mae)六、完整机器学习流程示例
# =========== 完整机器学习流程 ===========
# 1. 导入库
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 2. 加载数据集
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
# 3. 划分数据集 (80%训练, 20%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42
)
# 4. 数据预处理 (标准化)
scaler = StandardScaler()
# 在训练集上拟合并转换
X_train_scaled = scaler.fit_transform(X_train)
# 在测试集上仅进行转换 (使用训练集的参数)
X_test_scaled = scaler.transform(X_test)
# 5. 选择并训练模型
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# 6. 预测结果
y_train_pred = model.predict(X_train_scaled)
y_test_pred = model.predict(X_test_scaled)
# 7. 评估模型
print("======== 训练集性能 ========")
print("训练集均方误差:", mean_squared_error(y_train, y_train_pred))
print("训练集R²分数:", r2_score(y_train, y_train_pred))
print("\n======== 测试集性能 ========")
print("测试集均方误差:", mean_squared_error(y_test, y_test_pred))
print("测试集R²分数:", r2_score(y_test, y_test_pred))
# 8. 查看模型系数
print("\n回归系数:", model.coef_)
print("截距:", model.intercept_)七、机器学习技巧与最佳实践
7.1 预处理注意事项
-
拟合-转换顺序:
fit_transform()仅在训练集使用transform()在测试集使用(使用训练集的参数)
-
特征重要性:
# 对于支持特征重要性的模型(如随机森林)
importances = model.feature_importances_
sorted_idx = importances.argsort()[::-1]
# 打印特征重要性
print("特征重要性排序:")
for i in sorted_idx:
print(f"{diabetes.feature_names[i]}: {importances[i]:.4f}")7.2 类别不平衡处理
from sklearn.utils.class_weight import compute_class_weight
# 自动计算类别权重
classes = np.unique(y_train)
weights = compute_class_weight('balanced', classes=classes, y=y_train)
class_weights = dict(zip(classes, weights))
# 使用权重训练模型
model = RandomForestClassifier(class_weight=class_weights)
model.fit(X_train, y_train)7.3 模型保存与加载
import joblib
# 保存模型
joblib.dump(model, 'diabetes_model.pkl')
# 加载模型
loaded_model = joblib.load('diabetes_model.pkl')八、总结
Scikit-Learn 的基本使用流程:
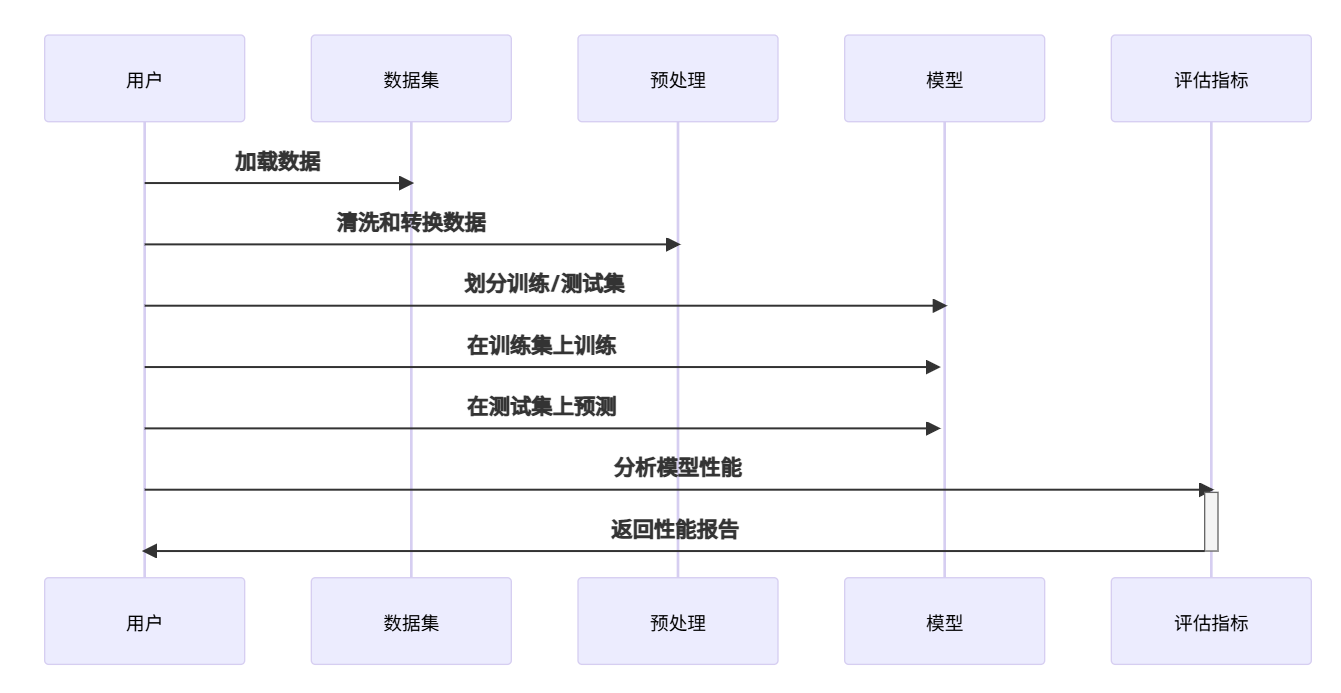
关键要点:
- 了解数据集结构(特征/目标变量)
- 正确处理数据预处理(特别是归一化/标准化)
- 始终使用独立的测试集评估模型
- 根据任务类型选择合适的评估指标
- 保存重要参数(如随机种子)确保结果可复现

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)