图解机器学习第十七章监督降维——局部Fisher判别分析
【代码】图解机器学习第十七章监督降维——局部Fisher判别分析。
·
n=100;
x=randn(n,2);
x(1:n/2,1)=x(1:n/2,1)-4;
x(n/2+1:end,1)=x(n/2+1:end,1)+4;
x=x-repmat(mean(x),[n,1]);
y=[ones(n/2,1);2*ones(n/2,1)];
Sw=zeros(2,2);
Sb=zeros(2,2);
for j=1:2
p=x(y==j,:);
p1=sum(p);
p2=sum(p.^2,2);
nj=sum(y==j);
W=exp(-(repmat(p2,1,nj)+repmat(p2',nj,1)-2*p*p'));
G=p'*(repmat(sum(W,2),[1 2]).*p)-p'*W*p;
Sb=Sb+G/n+p'*p*(1-nj/n)+p1'*p1/n;
Sw=Sw+G/nj;
end
[t,v]=eigs((Sb+Sb')/2,(Sw+Sw')/2,1);
figure(1);
clf;
hold on;
axis([-8 8 -6 6]);
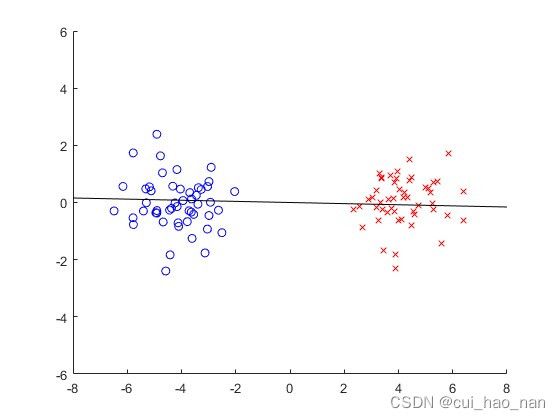
plot(x(y==1,1),x(y==1,2),'bo');
plot(x(y==2,1),x(y==2,2),'rx');
plot(99*[-t(1) t(1)],99*[-t(2) t(2)],'k-');
这里是对代码中每个参数的解释:
n: 样本数量,这里设置为100。
x: 大小为n×2的随机样本矩阵,其中每一行表示一个样本,有两个特征。
x(1:n/2,1) = x(1:n/2,1) - 4;:将第一列中前一半的样本减去4。
x(n/2+1:end,1) = x(n/2+1:end,1) + 4;:将第一列中后一半的样本加上4。
x = x - repmat(mean(x), [n,1]);:对整个样本矩阵进行均值归零化,即减去样本均值。
y = [ones(n/2,1); 2*ones(n/2,1)];:标签向量,长度为n,前一半为1,后一半为2,表示两个类别。
Sw:类内散布矩阵(Within-Class Scatter Matrix),初始化为2×2的零矩阵。
Sb:类间散布矩阵(Between-Class Scatter Matrix),初始化为2×2的零矩阵。
for j = 1:2:循环遍历两个类别。
p = x(y == j, :);:选择第j个类别的样本子集。
p1 = sum(p);:计算样本子集p中每个特征的总和。
p2 = sum(p.^2, 2);:计算样本子集p中每个样本的特征平方和。
nj = sum(y == j);:计算第j个类别的样本数量。
W = exp(-(repmat(p2, 1, nj) + repmat(p2', nj, 1) - 2*p*p'));:计算权重矩阵W,其中W的元素根据样本之间的距离进行计算。
G = p'*(repmat(sum(W,2), [1 2]).*p) - p'*W*p;:计算类间散布矩阵的贡献项G。
Sb = Sb + G/n + p'*p*(1 - nj/n) + p1'*p1/n;:将类间散布矩阵的贡献项G累积到Sb中。
Sw = Sw + G/nj;:将类内散布矩阵的贡献项G累积到Sw中。
[t, v] = eigs((Sb+Sb')/2, (Sw+Sw')/2, 1);:通过求解广义特征值问题,得到最大广义特征值对应的特征向量t。
figure(1);:创建一个图形窗口。
plot(x(y == 1, 1), x(y == 1, 2), 'bo');:绘制类别1的样本点,蓝色圆圈。
plot(x(y == 2, 1), x(y == 2, 2), 'rx');:绘制类别2的样本点,红色叉叉。
plot(99*[-t(1) t(1)], 99*[-t(2) t(2)], 'k-');:绘制投影方向的直线,黑色实线。
重难点:
G表示类间散布矩阵(Between-Class Scatter Matrix)的贡献项
G = p' * (repmat(sum(W,2), [1 2]) .* p) - p' * W * p;
让我们逐步解释这个计算过程:
p 是一个包含特定类别 j 的样本子集。
sum(W,2) 计算了 W 的每一行的和,结果是一个列向量。它表示了每个样本与其他样本的权重之和。
repmat(sum(W,2), [1 2]) 将 sum(W,2) 的列向量复制为一个矩阵,维度与样本矩阵 p 相同。这样做是为了后续的矩阵相乘操作。
p' * (repmat(sum(W,2), [1 2]) .* p) 这部分是计算类间散布矩阵的贡献项。首先,通过点乘操作 repmat(sum(W,2), [1 2]) .* p 将每个样本乘以对应的权重。然后,将结果与样本矩阵 p 进行转置相乘,得到一个贡献项矩阵。
p' * W * p 是计算类内散布矩阵的贡献项。它表示将样本矩阵 p 与权重矩阵 W 相乘后的结果。
G = p' * (repmat(sum(W,2), [1 2]) .* p) - p' * W * p 将类间散布矩阵和类内散布矩阵的贡献项相减,得到最终的 G。
通过循环遍历每个类别,并累积每个类别的 G,代码将计算出完整的类间散布矩阵 Sb 的贡献项。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)