【全网唯一】冰狐智能辅助Android版纯本地离线文字识别插件
本文介绍了冰狐智能辅助Android版TomatoOCR离线文字识别插件的使用方法。主要内容包括:1)准备工作,需下载安装冰狐客户端和TomatoOCR插件;2)插件集成方法,将插件重命名为TomatoOCR.apk并放置到设备中;3)调用方式,通过JavaScript脚本加载插件并设置参数,支持多语言识别、多种返回格式、坐标定位等功能;4)方法说明,详细介绍了setLicense、setRecT
目的
冰狐智能辅助是简单、快捷、全面的一站式自动化脚本解决方案仅需极少时间、极低成本即可快速实现各种自动化脚本功能。本篇文章主要讲解下冰狐智能辅助Android版TomatoOCR纯本地离线文字识别插件如何使用和集成。
准备工作
- 下载并安装「冰狐智能辅助」客户端程序
2、下载对应的TomatoOCR插件:下载插件

- 目前插件支持中英文、繁体字、日语、韩语识别;
- 支持小图、区域图和单行文字识别,准确率高达99%;
- 支持多种返回格式,json\文本\数字\自定义;
- 支持二值化;
- 支持找字返回坐标并点击;
- 超高的稳定性,速度快;
- 支持多线程
- 支持滤色
插件集成
插件放置
下载插件后将名字改成TomatoOCR.apk,放到手机或模拟器中的任意位置。
调用方式
在冰狐官网中,先将设备改成调试模式,然后在移动端脚本中新建脚本
以下代码拷贝到js中,配置license后,点击运行
function main() {
requestScreenShot();
ocr_init(); // 全局只调用一次
// 开始识别
ocr_start(0,0,300,200);
}
function ocr_init(){
// 加载插件
var plugin = loadPlugin('/mnt/shared/Pictures/bh/TomatoOCR.apk')
console.log('plugin:', plugin)
// 创建插件中的对象
tmo_ocr = plugin.newObject('com.tomato.ocr.bh.OCRApi')
tmo_ocr.setContext(rsContext);
var license = "" // 设置license,见授权码获取
var remark = "测试" // 设置备注,可在控制台的列表中查看
var flag = tmo_ocr.setLicense(license, remark);
console.log('flag:', flag)
}
function ocr_start(x1, y1, x2, y2){
// 以下方法详细介绍,见文档:方法介绍
tmo_ocr.setRecType("ch-3.0")
// 注:ch、ch-2.0、ch-3.0版可切换使用,对部分场景可适当调整
// "ch":普通中英文识别,1.0版模型
// "ch-2.0":普通中英文识别,2.0版模型
// "ch-3.0":普通中英文识别,3.0版模型
// "cht":繁体,"japan":日语,"korean":韩语
tmo_ocr.setDetBoxType("rect")
// 调整检测模型检测文本参数- 默认"rect": 由于手机上截图文本均为矩形文本,从该版本之后均改为rect,"quad":可准确检测倾斜文本
tmo_ocr.setDetUnclipRatio(1.9) // 文字识别错误,可尝试将这个值调大点
// 调整检测模型检测文本参数 - 默认1.9: 值范围1.6-2.5之间
tmo_ocr.setRecScoreThreshold(0.3)
// 识别得分过滤 - 默认0.1,值范围0.1-0.9之间
tmo_ocr.setReturnType("json")
// 返回类型 - 默认"json": 包含得分、坐标和文字;
// "text":纯文字;
// "num":纯数字;
// 自定义输入想要返回的文本:".¥1234567890",仅只返回这些内容
tmo_ocr.setBinaryThresh(0)
// 二值化设定,非必须
tmo_ocr.setRunMode("slow")
// 默认“slow”;“fast”:小图识别上会加速,但准确率会降低,推荐用默认值“slow”
//tmo_ocr.setFilterColor("", "black"); // 设置滤色值和背景色(black\white),滤色值默认是空的,详细使用见方法说明
var type = 3
// type=-1 : 检测 + 方向分类 + 识别
// type=0 : 只检测
// type=1 : 方向分类 + 识别
// type=2 : 只识别
// type=3 : 检测 + 识别
// 只检测文字位置:type=0
// 全屏识别: type=3或者不传type
// 截取单行文字识别:type=1或者type=2
// 例子一
var ret = screenShot('pic.png',"", [x1, y1, x2, y2]);
console.log('ret:' + ret);
let result1 = tmo_ocr.ocrFile(ret, type);
console.log("result1: ", result1);
if (result1 != "") {
// var json_result = JSON.parse(result) // setReturnType为“json”时,返回的是json字符串,需要使用JSON.parse进行解析
// 自行解析
}
// 例子二
var bitmap = screenShot('',"", [x1, y1, x2, y2]);
console.log('bitmap:' + bitmap);
let result2 = tmo_ocr.ocrBitmap(bitmap, type);
console.log("result2: ", result2);
if (result2 != "") {
// var json_result = JSON.parse(result) // setReturnType为“json”时,返回的是json字符串,需要使用JSON.parse进行解析
// 自行解析
}
// 找字返回中心点,找不到返回“”空字符串
var point = tmo_ocr.findTapPoint("冰狐")
if (point != "") {
var json_point = JSON.parse(point)
var center_x = json_point[0] + x1
var center_y = json_point[1] + y1
console.log(center_x, center_y);
}
// 找字返回所有相匹配的中心点坐标,找不到返回“”空字符串
var points = tmo_ocr.findTapPoints("冰狐")
if (points != "") {
var tmp = JSON.parse(points)
for(var i = 0; i< tmp.length; i++) {
var data = tmp[i]
var words = data.words
var point = data.point
var center_x = point[0] + x1
var center_y = point[1] + y1
console.log(center_x, center_y, words);
}
}
}其中的方法说明如下
| 方法名 | 说明 |
| setLicense | 设置授权 |
| setRecType |
设置识别语言,默认ch-3.0: ch、ch-2.0、ch-3.0版可切换使用,对部分场景可适当调整 |
| setDetBoxType |
调整检测模型检测文本参数-,默认"rect": 由于手机上截图文本均为矩形文本,从该版本之后均改为rect,"quad":可准确检测倾斜文本 |
setDetUnclipRatio |
调整检测模型检测文本参数,默认1.9: 值范围1.6-2.5之间,如果文字的检测框太小,可调整改参数,一般往大调整 |
setRecScoreThreshold |
设置识别得分过滤,默认0.1: 值范围0.1-0.9之间 |
setReturnType |
设置返回类型,默认"json",包含得分、坐标和文字; "text":纯文字; "num":纯数字; 自定义输入想要返回的文本:".¥1234567890",仅只返回这些内容 |
setBinaryThresh |
默认值0,对图片进行二值化处理,非必须,正常情况下可以不用写 |
ocrFile/ocrBase64 |
两个参数,图片路径和类型,一般类型传3: type=-1 : 检测 + 方向分类 + 识别 type=0 : 只检测 type=1 : 方向分类 + 识别 type=2 : 只识别(单行识别) type=3 : 检测 + 识别 只检测文字位置:type=0 全屏识别: type=3或者不传type 截取单行文字识别:type=1或者type=2 如果识别为不到时,返回的数据为“”字符串 |
findTapPoint |
找字,返回传入字的中心点坐标,方便进行点击,找不到字时,返回“”空字符串 |
findTapPoints |
找字,找出所有相匹配的字,找不到字时,返回“”空字符串 |
运行结果
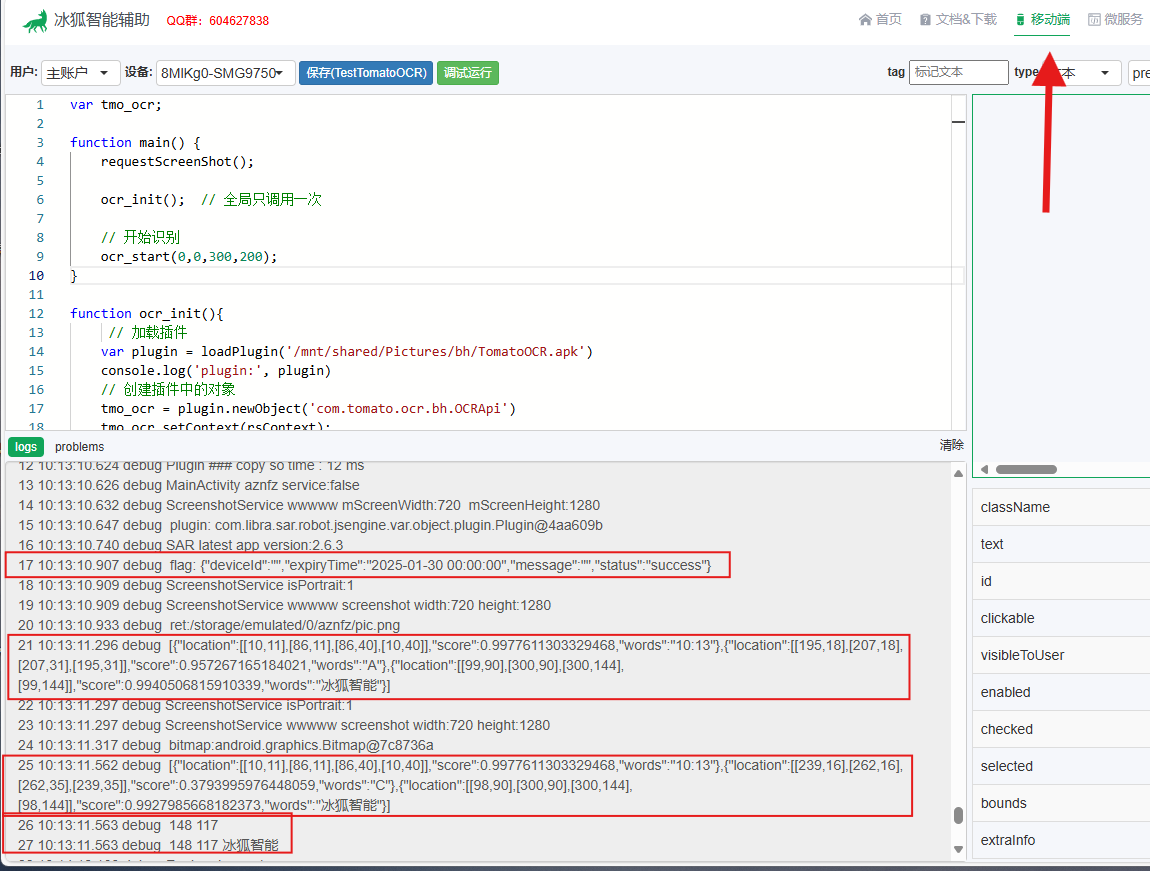
完毕
相对来说,在冰狐进行插件开发还是比较困难的,官方提供的功能太少,原生插件集成无法采用直连的方式,但相比部署在服务器上,还是减少了很多资源占用情况,更加方便便捷。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 18
18 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)