【机器学习】逻辑化搭建机器学习框架
在数据分析建模的时候时常看到机器学习、监督学习、深度学习、半监督学习等等(超级多学习),所以这写“学习”之间到底有什么关系呢?说这些“学习”究竟是算法还是模型呢?到底研究的是哪些问题呢?这篇文章不讲原理,先系统的搭建小编自己的学习框架及思路,并且来讲讲这些“学习”的区别及基础知识框架。
在数据分析建模的时候时常看到机器学习、监督学习、深度学习、半监督学习等等(超级多学习),所以这写“学习”之间到底有什么关系呢?说这些“学习”究竟是算法还是模型呢?到底研究的是哪些问题呢?
这篇文章不讲原理,先系统的搭建小编自己的学习框架及思路,并且来讲讲这些“学习”的区别及基础知识框架。
第一次更新:2024/4/7
一.机器学习
1.基本概念
首先我们先来看看“机器学习”这一名称代表着什么,其中“机器(machine)”代表着的就是我们的计算机;而“学习(learning)”可以用赫尔伯特·西蒙给出的定义理解一下,即“如果一个系统能够通过指性某个过程来改进它的性能,这就是学习。”,所以在我们的机器学习领域就可以将它理解为计算机通过运用一些方法来不断优化模型,改进性能以达到我们想要的结果的手段。我们看西蒙给出的学习的定义也可以联想一下,我们实际生活中的学习也是一种通过执行各种过程,不断优化我们的学习能力,锻炼大脑活跃度提高认知的过程(这么看给出“学习”这一定义的科学家真的好厉害,能够一眼看到各个领域事物的本质)。
了解概念以后我们进一步提问,“学习”这一定义中的“它”是指谁?“性能”如何改善?
针对于第一个问题我们需要明确的是机器学习所研究的对象到底是谁?而李航在《机器学习方法》中明确给出:机器学习以数据为研究对象,是数据驱动的学科。所以机器学习的定义可以理解为计算机系统从数据本身出发,提取数据特征来建构模型,通过不断优化来提高数据预测的性能。但需要明确的是,机器学习研究的数据必须要是同类数据,如都是中文文本,都是数据库数据等等。只有在同一类数据中我们才能够分析出数据的统计规律,将其运用到数据分析预测中。
针对于第二个问题在《机器学习方法》中也指明了思路,性能的改善依赖于两个方面,即“”学习什么模型“与如何学习模型”。机器学习所学习的模型主要为概率统计模型,尝试运用分布函数、条件概率分布、决策函数等等手段来寻找数据规律。而如何学习包含三要素:模型(model)、策略(strategy)和算法(algorithm)。
2.实现方法
机器学习方法的三要素即模型(model)、策略(strategy)和算法(algorithm)。
模型即模型的假设空间(hypothesis space),即从需要训练的数据出发,假设我们需要学习的模型属于某个函数的集合,这个集合就是假设空间。
策略即评价准则(evaluation criterion),即在按照这个评价准则在假设空间中选择最优模型,以达到使用该模型分析预测效果最好。
算法即实现手段,算法本质上就是一个计算器,通过代码将我们的思路应用到数据,求得模型结果。
所以整体上看机器学习的实现方法即:
(1)得到一个有限的训练数据集合;
(2)确定包含所有可能性的模型的假设空间;——模型
(3)确定最优模型选择的准则;——策略
(4)实现求解最优模型的算法;——算法
(5)选择最优模型;
(6)利用最优模型进行数据分析及预测。
进一步对策略补充:
策略是用来确定最优模型的,不难想到——控制误差是一个非常好的选定模型的方式。根据误差的来源及种类,通常划分为以下几种:
(1)损失函数与风险函数
(2)经验风险最小化和结构风险最小化
经验风险最小化(Empirical Risk Minimization,ERM)是机器学习中一个常见的问题框架,用于构建和训练模型以最小化在训练数据集上的损失函数。该框架的目标是通过最小化训练数据上的经验风险来选择和调整模型的参数,以期望在未见数据上获得良好的性能。
数学表达式为:
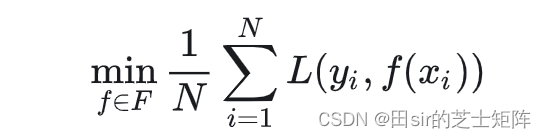
结构风险最小化(structural minimization, SRM)是为了防止过拟合提出的策略。结构风险最小化等价于正则化(regularization)。结构风险在经验风险上加上表示模型复杂度的正则化项(regularizer)或罚项(penalty term)。
将结构风险定义为:
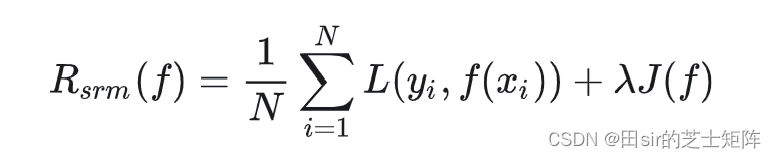
3.机器学习分类
在机器学习实现方法的每一步中,不同的实现选择可以划分出不同的“学习方法”。
根据数据是否有标签可以细分为监督学习、无监督学习、半监督学习。
监督学习(supervised learning)主要指从标注数据中学习预测模型的机器学习问题,这里的标注数据指的是人为标注数据的输入输出关系,其本质在于挖掘输入输出数据之间的映射关系。在数据描述中,通常把样本描述为实例(instance),通常由特征向量(feature vector)表示,通常来讲将输入变量记作X,输出变量记作Y。
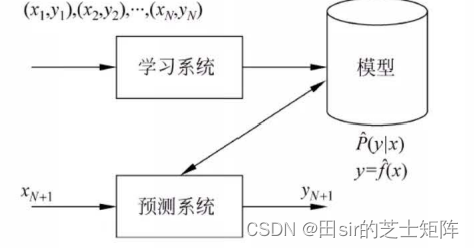
监督学习分为学习和预测两个过程,在图1中描述为由学习系统和预测系统完成。在学习系统中,通过训练数据集得打输入输出变量之间的最优映射模型;在预测过程中,预测系统将给定数据集中的输入数据代入,得到我们想要的对应输出数据。在李航的《机器学习方法》中详细介绍了10种监督学习算法,即感知机、k 近邻、朴素贝叶斯、决策树、逻辑回归与最大熵模型、支持向量机、提升方法、EM 算法、隐马尔可夫模型和条件随机场。
无监督学习(unsupervised learning)是指从无标注数据中学习预测模型的机器学习问题,这里的无标注数据也就是自然数据,是不知道输入输出关系的自然数据。无监督学习的本质是挖掘数据内部本身的统计规律及潜在结构,无监督学习预测可以完成是聚类(将相似的数据点分为一组)、降维(将高维数据映射到低维空间)和异常检测(识别数据中的离群点)等任务。
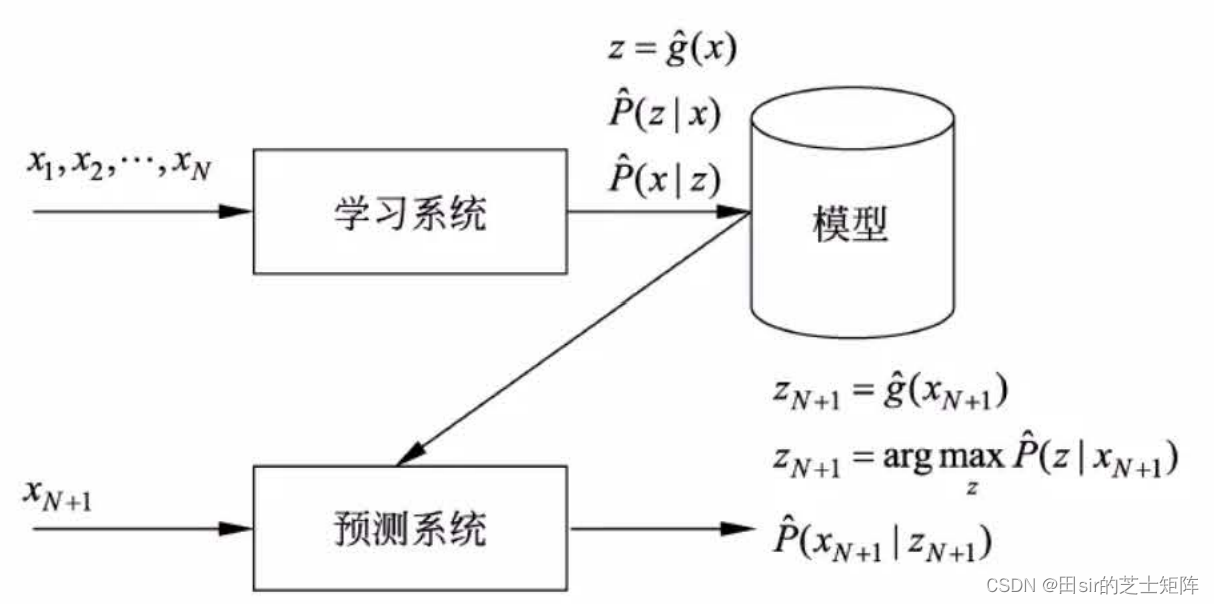
其中z表示的是数据内部的隐式结构关系,同时也是无监督学习的输出数据。
半监督学习(semi-supervised learning)是一种介于监督学习和无监督学习之间的机器学习方法。它的基本思想是利用少量的有标签数据和大量的无标签数据来进行模型训练,从而提高模型的性能。根据学习场景的不同,半监督学习又可以细分为半监督分类、半监督回归、半监督聚类和半监督降维四大类。
具体原理可以看另一位博主的分享:【机器学习】之第十三章——半监督学习_未标记样本-CSDN博客
强化学习(reinforcement learning,RL)也是常见的机器学习类别,强化学习讨论的问题是智能体(agent)如何在复杂、不确定的环境(environment)中最大化它能获得的奖励。强化学习由两部分组成:智能体和环境。在强化学习过程中,智能体与环境一直在交互。智能体在环境中获取某个状态后,它会利用该状态输出一个动作 (action),这个动作也称为决策(decision)。然后这个动作会在环境中被执行,环境会根据智能体采取的动作,输出下一个状态以及当前这个动作带来的奖励。智能体的目的就是尽可能多地从环境中获取奖励。
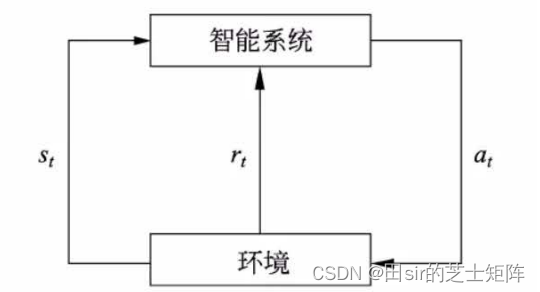
智能系统每观测到环境中的一个状态与奖赏
便会采取一个相应行动
。
依据模型差异还可以将机器学习分为概率模型与非概率模型,线性模型与非线性模型等等,具体更多的分类方式可以参考《机器学习方法》。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)