大模型具体是如何推理生成的?
详细解读大模型推理输出的全过程
最近发现很多人只是大概知道大模型的推理过程,但对于具体是如何由输入的文字形成最终的输出这一过程细节是不甚了解的,甚至说不出个一二三,所以有必要来详细写一些大模型推理时的全流程。
LLM推理全流程解析
大型语言模型(LLM)的推理过程是指模型根据用户输入的提示(Prompt)生成后续文本的过程。这一过程涉及多个核心步骤,从输入处理到神经网络计算,再到输出优化,每个环节共同作用以实现连贯的文本生成。以下是推理过程的完整解析:
在正式开始之前我们先整体看下用户角度的推理过程是怎样的:
用户输入(prompt):
Quantum mechanics is a fundamental theory in physics that
大模型最终输出:
provides insights into how matter and energy behave at the atomic scale.
接下来,我们站在模型的角度来看下整体的推理过程,如下图所示: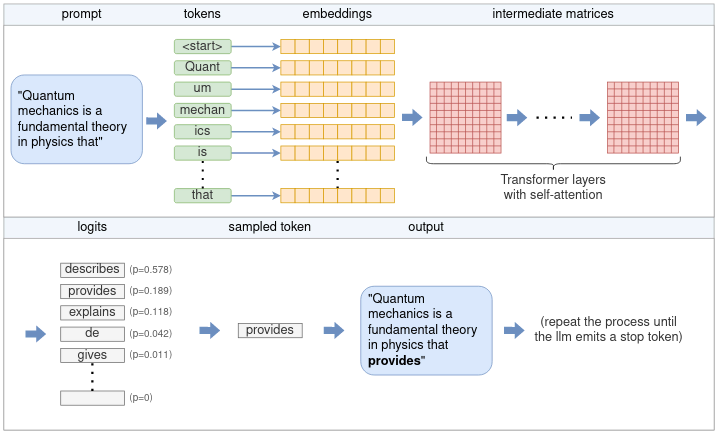
其可以拆解为以下几步:
- tokenizer将输入的prompt分为包含了若干个token的list,你会发现有的单词对应了1个token,而有的单词却被拆分为了2个token,这个取决于你的词表(vocabulary),每一个token都唯一对应一个编号(token_id)。
- 每一个token都会被转化为一个向量,我们叫它嵌入(embedding)向量,它的形状是固定的,这种形式更适合模型去处理,所有的token转化的向量共同组成了嵌入矩阵。
- 上一步形成的嵌入矩阵就是transformer block的输入。大语言模型(LLM)简单来说就是由若干个transformer block堆叠而成的,每一个transformer block的输出就是其下一个block的输入。transformer的核心就是self-attention,这里就不展开了。
- 最后一个transformer block的输出经过softmax会输出一个向量,这个向量的长度等于词表大小,每个位置的值(logits)就代表大模型预测的下一个token概率。
- 有很多采样(sampling)策略来决定从上一步输出的logits向量中选择哪个token作为下一个预测的结果token。
- 选择出来的token就作为当前步(step)的最终输出,将其添加到输出的list中。紧接着重复以上步骤,当我们产生特定长度的输出或输出end-of-sentence(EOS)token时停止。
下面,让我们来详细看下每一步中都包含了哪些操作,有哪些技术/算法是值得我们关注的。
1. 输入处理:分词(Tokenization)
目标:将用户输入的文本(prompt)转换为模型可处理的合法Token。
- 方法:使用子词分词(Subword Tokenization),典型算法如字节对编码(byte-pair-encoding,BPE)。
- 首先将文本拆分为单个字符或子词单元,逐步合并高频组合形成最终词汇表。
- 例如,单词“Quantum”可能被拆分为“Quant”和“um”,空格用特殊符号“▁”表示。
- 输出:生成Token列表,每个Token对应词汇表中的唯一token id。
- 示例:输入“Quantum mechanics is…”分词后为
["Quant", "um", "▁mechan", "ics", ...],转换为整数序列[22746, 398, 123, 456, ...]。
- 示例:输入“Quantum mechanics is…”分词后为
- 关键作用:
- 允许模型可以学习到一些不常见单词(比如quantum)意思的同时,还可以通过使用常见的前缀和后缀来表示独立的token来保持词表大小的规模相对较小。
- 平衡词汇表大小与覆盖率,处理低频词,罕见词甚至代码的变量名(如代码变量名“model_size”拆分为“model|_|size”)。
- 适配多语言场景,避免依赖语言特定规则。
在这里可以简单展开讲下BPE这个分词法具体是如何进行分词的,它开始会将每个单词拆分为单独的字母,然后不断地迭代合并相邻的字母,只要它是对应于词表中的某个单词,详细过程如下:
Q|u|a|n|t|u|m|▁|m|e|c|h|a|n|i|c|s|▁|i|s|▁a|▁|f|u|n|d|a|m|e|n|t|a|l|
Qu|an|t|um|▁m|e|ch|an|ic|s|▁|is|▁a|▁f|u|nd|am|en|t|al|
Qu|ant|um|▁me|chan|ics|▁is|▁a|▁f|und|am|ent|al|
Quant|um|▁mechan|ics|▁is|▁a|▁fund|ament|al|
Quant|um|▁mechan|ics|▁is|▁a|▁fund|amental|
Quant|um|▁mechan|ics|▁is|▁a|▁fundamental|
其中每一步的中间表示单词都属于词表中的合法token,最终合并结果就是embedding的输入token list。
2. 嵌入层:Token到向量的映射(Embedding)
目标:将离散Token转换为连续向量,捕捉语义信息。
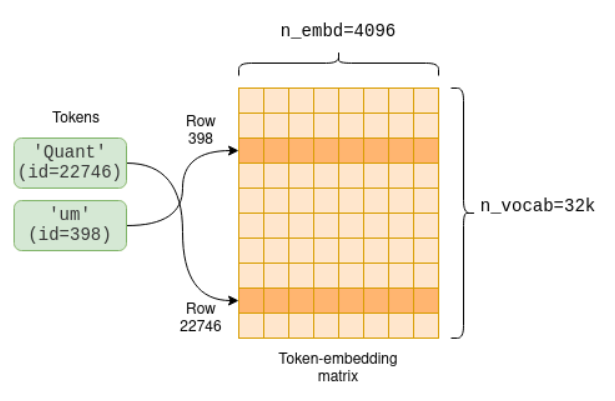
- 实现:通过嵌入矩阵(Embedding Matrix)完成映射。
- 形状是固定的,矩阵形状为
[词汇表大小 × 模型维度],例如LLaMA-7B的词表大小为32000,模型维度为4096,那么该矩阵形状就是32000 × 4096。 - 每个Token对应矩阵中的一行,输出为固定维度的向量(如4096维)。
- 形状是固定的,矩阵形状为
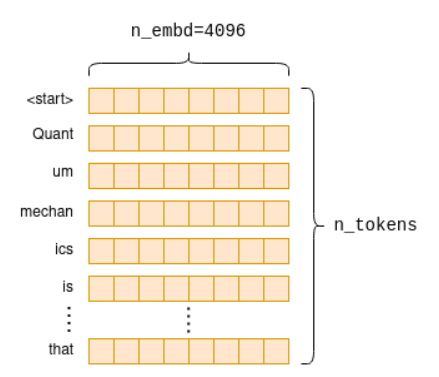
- 输出:嵌入矩阵
[n_tokens × n_embd],其中n_tokens为输入Token数,n_embd为模型维度。- 示例:11个Token输入生成
11 × 4096的矩阵,每一行代表一个Token的语义向量。
- 示例:11个Token输入生成
- 关键作用:将符号化输入转换为神经网络可处理的数值表示,为后续语义关联计算奠定基础。
3. 核心推理:Transformer架构
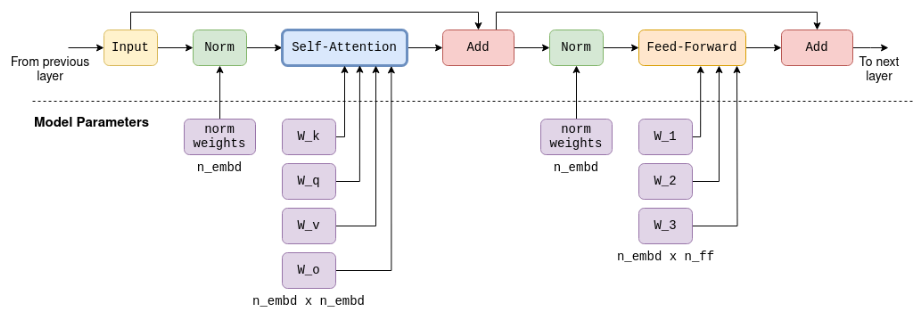
Transformer是LLM的核心神经网络结构,通过多层堆叠实现复杂语义建模。这里已经是老生常谈的话题了,只要是学过深度学习的,这里都不应该有任何的不清楚。主要介绍下每个transformer block的关键组件:
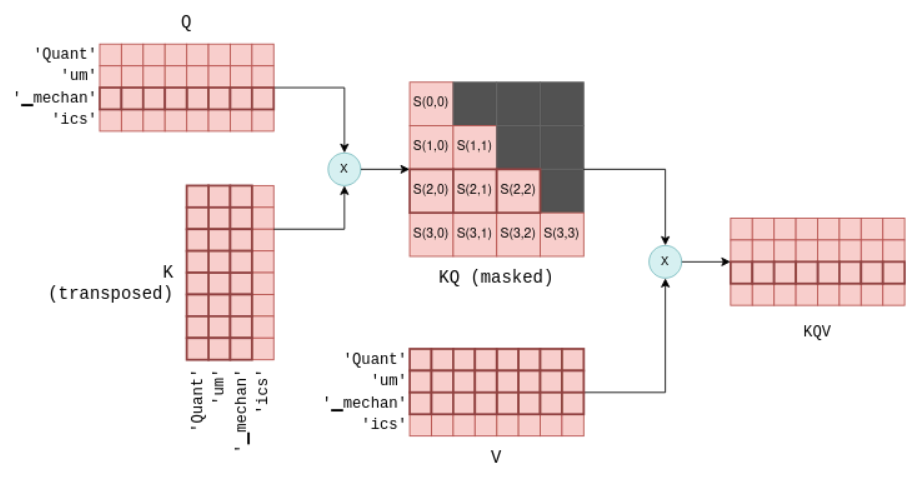
3.1 自注意力机制(Self-Attention)
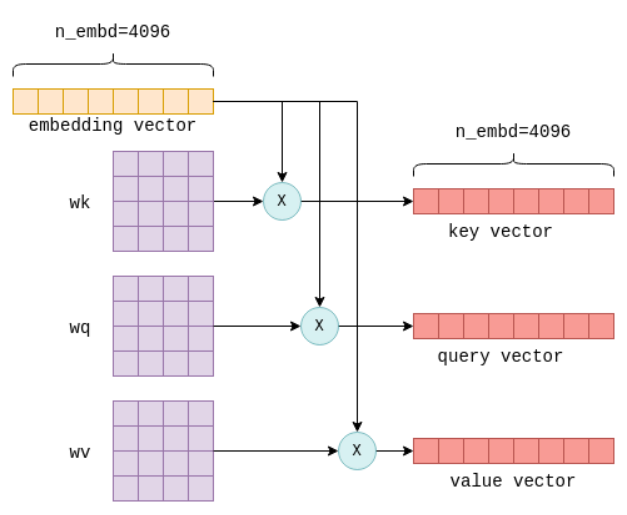
目标:计算输入序列中Token间的语义关联,捕捉长距离依赖。
- 输入:嵌入矩阵
Q(查询向量)、K(键向量)、V(值向量),三者均由嵌入向量通过线性变换生成:- Q = Embedding×WqEmbedding \times W_qEmbedding×Wq , K = Embedding×WkEmbedding \times W_kEmbedding×Wk, V = Embedding×WvEmbedding \times W_vEmbedding×Wv
- 形状均为
[n_tokens × n_embd]。
- 计算流程:
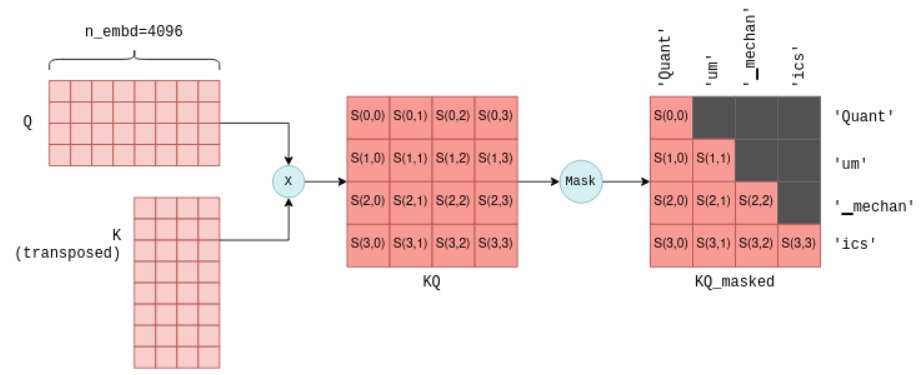
-
相似度得分:计算查询向量与所有键向量的点积,得到注意力分数矩阵 S = Q×KTQ \times K^TQ×KT,形状为
[n_tokens × n_tokens]。 -
掩码(Masking):屏蔽未来Token的得分(仅保留当前Token及之前的得分),确保自回归特性(只能依赖已生成的Token)。
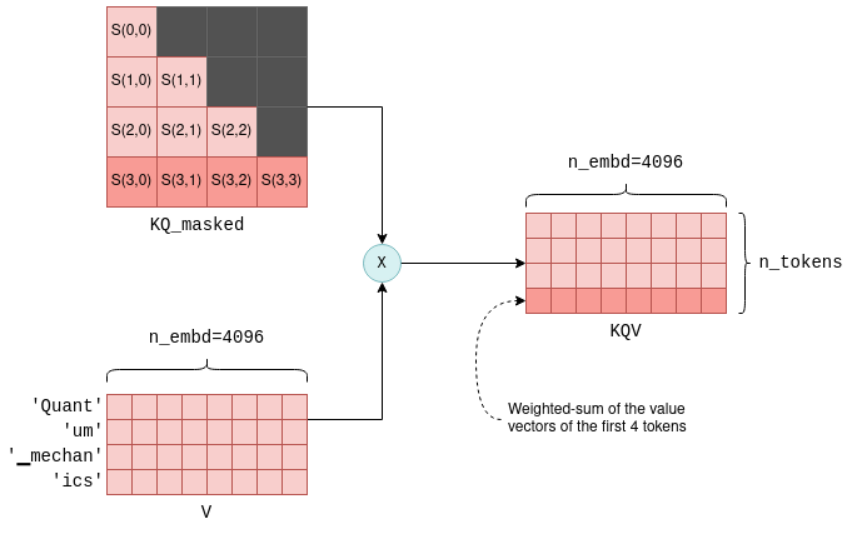
-
归一化与加权求和:
- 对得分矩阵应用Softmax归一化,得到概率矩阵
P。 - 计算加权和Z = P×VP \times VP×V,输出为
[n_tokens × n_embd]的矩阵,融合了上下文信息。
- 对得分矩阵应用Softmax归一化,得到概率矩阵
-
- 关键作用:动态分配每个Token对当前Token的重要性权重,实现语义理解与关联建模。
3.2 前馈神经网络(Feed-Forward Network, FFN或MLP)
目标:对自注意力输出进行非线性变换,增强模型表达能力。
- 结构:两层线性变换+激活函数(如ReLU)。
- 第一层:
n_embd → n_ff(如LLaMA-7B中4096 → 11008)。 - 第二层:
n_ff → n_embd,输出与输入维度一致。
- 第一层:
- 作用:在每个Token的向量空间内进行特征变换,捕获局部语义。
3.3 层归一化与残差连接
- 层归一化(Layer Normalization):对每层输入进行归一化,稳定训练与推理过程。
- 残差连接(Residual Connection):缓解深层网络梯度消失问题,允许梯度直接流经浅层网络。
3.4 多层堆叠
- 典型配置:LLaMA-7B包含32层Transformer,每层独立进行自注意力和前馈计算。
- 信息流动:
- 第1层输入为嵌入层,输出为初步编码的上下文向量。
- 后续每层以之前层的输出为输入,逐步提炼抽象语义,最终输出包含全局上下文信息的向量序列。
4. 输出处理:计算对数概率(Logits)
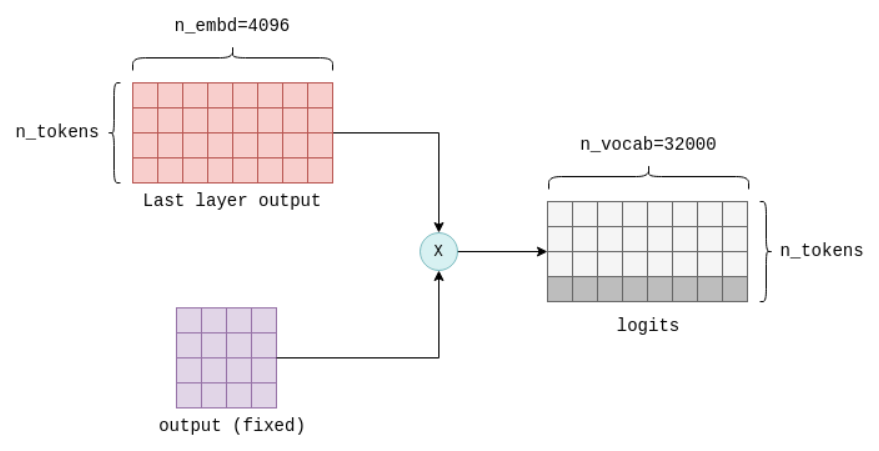
目标:将Transformer输出转换为下一个Token的概率分布。
实现:通过线性层将Transformer最后一层输出[n_tokens × n_embd]映射到词汇表维度:
- 权重矩阵形状为
[n_embd × 词汇表大小],计算Logits = Transformer输出×WoutputTransformer_{输出} \times W_{output}Transformer输出×Woutput。 - 输出形状为
[n_tokens × 词汇表大小],仅取最后一个Token对应的行(形状[1 × 词汇表大小])用于生成下一个Token。
意义:Logits值越高,对应Token为下一个输出的概率越大。
5. 采样策略:生成下一个Token
目标:根据Logits选择下一个Token,平衡准确性与多样性。
5.1 贪心采样(Greedy Sampling)
- 方法:直接选择Logits最大的Token。
- 示例:若Logits最高的Token为“▁describes”(概率57.8%),则强制选择该Token。
- 适用场景:需要确定性输出(如代码生成)。
5.2 温度采样(Temperature Sampling)
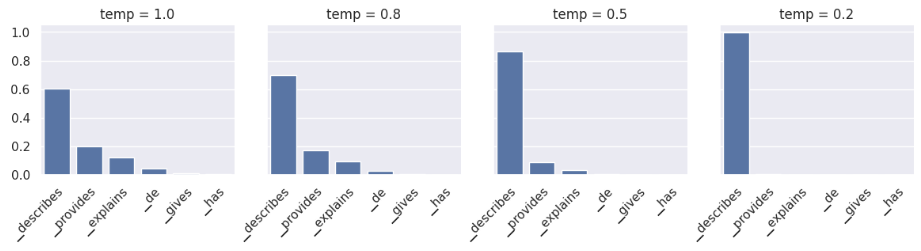
- 方法:
- 对Logits应用Softmax生成概率分布。
- 基于温度参数
T调整分布平滑度:- T →\to→ 0 :分布尖锐,接近贪心采样(低随机性)。
- T →\to→ 1 :分布平滑,允许低概率Token被采样(高随机性)。
- 可选核采样(Nucleus Sampling):仅保留累计概率超过阈值(如95%)的Token,再从中随机采样。
- 示例:温度
T=0.8时,“▁describes”(60%)和“▁provides”(20%)等Token均有机会被选中。
6. 推理优化:KV缓存(KV Cache)
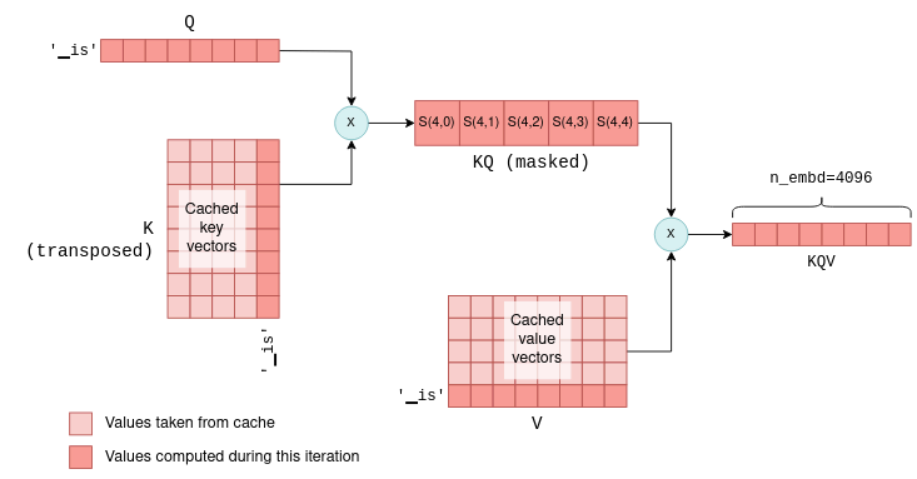
目标:加速长序列生成,避免重复计算历史Token的键值向量。
- 核心思想:
- 首次生成时,缓存所有Token的键向量(K)和值向量(V)。
- 后续生成时,仅计算新Token的K、V,与缓存中的历史K、V拼接,避免重复计算。
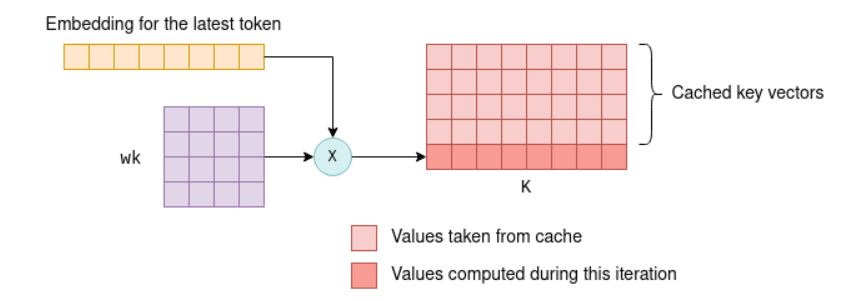
- 流程:
- 初始迭代:计算所有Token的K、V,存入缓存(如大小为512的缓存)。
- 后续迭代:
- 新增1个Token,仅计算其K、V。
- 从缓存中读取历史K、V,与新K、V拼接为完整矩阵
[n_past+1 × n_embd]。 - 利用拼接后的矩阵进行自注意力计算,仅生成新Token对应的输出行。
- 效果:将自注意力计算复杂度从( O(n^2) )降为( O(n) )(n为总Token数),显著提升长文本生成效率。
7. 迭代生成:自回归循环
- 过程:
- 初始输入:用户Prompt,分词后为
[Token_1, Token_2, ..., Token_n]。 - 首次推理:生成下一个Token
Token_{n+1},概率基于Prompt的完整上下文。 - 循环:将Tokenn+1Token_{n+1}Tokenn+1添加到输入序列,重复上述流程,直至生成结束符(如
</s>)或达到指定长度。
- 初始输入:用户Prompt,分词后为
- 关键点:
- 每次迭代仅生成一个Token,依赖历史所有Token的上下文。
- KV缓存随迭代逐步积累历史K、V,避免重复计算开销。
总结:推理流程的核心逻辑
LLM推理是一个自回归生成过程,通过以下步骤实现:
- 输入解析:分词将文本转换为Token序列,嵌入层生成语义向量。
- 语义建模:Transformer通过自注意力和前馈网络逐层提取上下文关联。
- 概率预测:线性层将特征映射为Token概率,采样策略平衡生成的确定性与多样性。
- 效率优化:KV缓存复用历史计算结果,加速长序列生成。
参考文献:https://www.omrimallis.com/posts/understanding-how-llm-inference-works-with-llama-cpp/

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 32
32 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)