通用奖励模型:潜藏于大语言模型内部;LLM不再需要奖励模型?我们已经“预训练“了它!
论文标题: GENERALIST REWARD MODELS: FOUND INSIDE LARGE LANGUAGE MODELS大语言模型(LLM)的对齐高度依赖于昂贵的人类偏好数据训练出的奖励模型。近期研究尝试用 AI 反馈规避这一成本,但缺乏严谨的理论基础。本文发现,任何基于标准“下一个 token 预测”训练的 LLM 内部,已经潜藏了一个强大的通用奖励模型。我们证明,这种内生奖励并非启
论文标题: GENERALIST REWARD MODELS: FOUND INSIDE LARGE LANGUAGE MODELS
论文链接:https://arxiv.org/pdf/2506.23235
- 作者:Yi-Chen Li*, Tian Xu*, Yang Yu†, Xuqin Zhang, Xiong-Hui Chen, Zhongxiang Ling, Ningjing Chao, Lei Yuan, Zhi-Hua Zhou
*Equal contribution;†Corresponding author- 机构:南京大学人工智能学院(School of Artificial Intelligence, Nanjing University)
国家重点实验室(National Key Laboratory for Novel Software Technology)- 时间:2025年6月(arXiv 预印本)
- 关键词:
Endogenous Reward(内生奖励)
Inverse Reinforcement Learning, IRL(逆强化学习)
Reinforcement Learning from Human Feedback, RLHF(人类反馈强化学习)
Reinforcement Learning from AI Feedback, RLAIF(AI反馈强化学习)
LLM Alignment(大模型对齐)
Logits as Q-function(将 logits 看作 Q 函数)
Policy Improvement Bound(策略改进误差界)
Generalist Reward Models(通用型奖励模型)
大语言模型(LLM)的对齐高度依赖于昂贵的人类偏好数据训练出的奖励模型。近期研究尝试用 AI 反馈规避这一成本,但缺乏严谨的理论基础。
本文发现,任何基于标准“下一个 token 预测”训练的 LLM 内部,已经潜藏了一个强大的通用奖励模型。
我们证明,这种内生奖励并非启发式技巧,而是与通过离线逆强化学习(IRL)学到的奖励函数在理论上等价。
该发现使我们无需任何额外训练,即可直接从基础(预训练或监督微调)模型中引出高质量奖励信号。
关键地,我们还证明:使用此内生奖励进行后续强化学习,所得策略在理论上具有比基础模型更严格的误差界。
据我们所知,这是首次在理论上证明强化学习对大语言模型的有效性。
实验验证了理论:我们的方法不仅优于现有“LLM-as-a-judge”方法,甚至超过了专门训练的奖励模型。
这表明奖励建模阶段可被一种从预训练知识中提取奖励的严谨方法所取代,从而带来更高效、更强大、更可扩展的 LLM 及多模态模型对齐范式。
1 引言
1.1 与人类对齐难度和历史对齐方法
将大语言模型(LLMs)与“有用”“诚实”等复杂的人类价值观对齐,仍然是 AI 面临的一个核心挑战。
将大语言模型(LLM)与对齐,仍是 AI 研发的核心难题。
当前主要的方法是基于人类反馈的强化学习(RLHF)。该流程依赖于一个通过人类偏好训练的奖励模型来对模型输出进行评分,最终对齐后的 LLM 的质量在根本上取决于该奖励模型的质量。
因此,创建一个先进的奖励模型需要建立庞大且高质量的人类偏好数据集,而这一过程通常既缓慢、昂贵,又难以扩展。
这种对人类标注数据的依赖促使研究者探索其他对齐方法。
一个重要的研究方向是基于 AI 反馈的强化学习(RLAIF)。该方法利用强大的专有大语言模型生成奖励信号或偏好标签,从而规避人类标注需求。虽然成本效益显著,但这些方法缺乏严谨的理论基础,且容易继承评判模型本身的风格偏差与固有偏见。这引发了一个关键问题:高质量奖励信号是否必须依赖外部来源?
RLHF优化:AI 专家替代派/微调数据优化派/训练过程改造派(RAILF、LIMA、RFT/REFT/PPO/DPO等)
1.2 对齐奖励模型可以挖掘得到,不需要人工标注数据
本文发现,一个强大的通用奖励模型并非需要构建,而是可以挖掘出来的, 因为它已经潜在地存在于通过标准的下一个 Token 预测训练的任何语言模型中,称之为「内源性奖励(endogenous reward)」。
本文的核心贡献是为这一观点提供严格的理论基础。
本文证明了可以从标准的下一个 Token 预测目标中恢复出一种特定形式的离线逆强化学习(IRL)奖励函数,该目标用于预训练和监督微调(SFT)。这一见解能够超越启发式方法,并建立一种原则性的方法,来引出语言模型在训练过程中隐式学习到的奖励函数。
具体来说,本文展示了语言模型的 logits 可以直接解释为 soft Q 函数,通过逆 soft 贝尔曼算子可以从中恢复出奖励函数。
至关重要的是,这一理论联系不仅仅提供了一种奖励提取的方法。
本文还证明了,使用模型自身的内源性奖励进行微调可以使策略在误差界限上优于基线模型。
强化学习过程有效地修正了标准模仿学习(即下一个 Token 预测)中的累积误差,将性能差距从任务视野的二次依赖关系 O (H²) 降低到优越的线性关系 O (H)。
据了解,这是首次理论证明强化学习在 LLM 中的有效性。
广泛实验验证了这一理论,表明这种内源性奖励不仅优于现有的 LLM-as-a-judge 方法,而且可以超越那些通过昂贵的人类标注数据显式训练的奖励模型的表现。
2 预备知识
2.1 LLM 及其 MDP 形式化
大语言模型是一种通过概率建模逐 token 预测序列的生成模型。
形式上,LLM π 从有限词表 V = {1, 2, …, |V|} 选取 token,以自回归方式生成序列。
具体地,在第 h 步,给定上文 (a₁,…,a_{h−1}),LLM 依条件分布 a_h ∼ π(·|a₁,…,a_{h−1}) 生成下一个 token。
该过程持续至遇到 EOS 或达到最大长度 H。
为分析方便,本文假设所有响应长度恰为 H,EOS 后用填充符补齐。
LLM 的 MDP 形式化。
本文从强化学习视角看待 LLM,将语言生成任务形式化为一个 MDP ⟨S, V, r, P, ρ, H⟩。
- 状态空间 S:由 V 中元素拼接而成的所有有限长度字符串集合;
- 动作空间:词表 V;
- 初始状态分布 ρ:采样长度 m 的提示 s₁ = (x₁,…,x_m);
- 每步 LLM 依 π(·|s_h) 选动作 a_h ∈ V;
- 环境确定性转移到 s_{h+1} = s_h ⊕ a_h;
- 即时奖励 r(s_h, a_h) ∈ [0,1];
- 轨迹共 H 步。
- 在 RL 语境下,我们也称 π 为策略。策略质量由价值定义:
Vπ = E_{τ∼π} [∑_{h=1}H r(s_h, a_h)]。
2.2 用“下一个 token 预测”训练 LLM
“下一个 token 预测”是 LLM 的基本训练目标:
- 给定数据集
求解
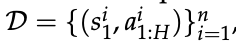
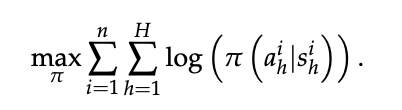
该目标既用于大规模通用网络数据的预训练,也用于高质量人类响应的小规模 SFT。
从模仿学习角度看,它等价于行为克隆 [Pomerleau, 1991]:模型在演示状态上模仿专家动作。
2.3 基于人类反馈的强化学习(RLHF)
虽然“下一个 token 预测”能教会模型模仿高质量演示,但要使行为与人类价值对齐,往往需更直接的反馈。
RLHF 是标准范式,通常包括两个阶段:奖励建模与 RL 微调。
- 奖励建模。
训练一个独立 RM R_φ,以预测人类偏好。
需偏好数据集
其中 y_w 为“胜者”响应,y_l 为“败者”。
依 Bradley-Terry 模型:
参数 φ 通过最小化负对数似然优化。
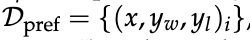
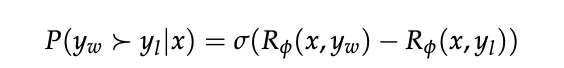
- RL 微调。
以 SFT 模型 π_SFT 为初始策略 π_θ,最大化 RM 给出的期望奖励,同时加入 KL 惩罚防止偏离 SFT 分布:
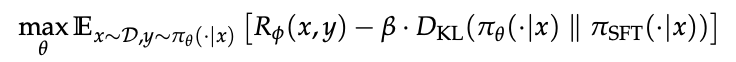
2.4 逆强化学习(IRL)
逆强化学习(IRL)[Ng and Russell, 2000] 是一类基础的模仿学习方法,旨在解决强化学习的“逆问题”。
与在已知奖励函数下学习策略不同,IRL 试图从专家演示中恢复奖励模型,前提假设是这些演示近似最优。
最大熵 IRL 是其中经典方法,它针对“多个奖励函数可解释同一行为”的歧义问题,提出在满足专家演示的同时,对数据未覆盖的行为保持最大不确定性的奖励函数。
该原则导出如下极小极大优化问题
其中:
- E_{τ∼πE} 是基于专家策略 πE 诱导的轨迹分布(用数据集 D 近似);
- E_{τ∼π} 是基于待学习策略 π 的轨迹分布;
- H(π(·|s_h)) = E_{a_h∼π(·|s_h)} [−log π(a_h|s_h)] 为策略熵;
- α>0 为正则系数。
目标是在奖励 r 下,最大化专家期望回报与最优策略(带熵正则)期望回报之间的差距
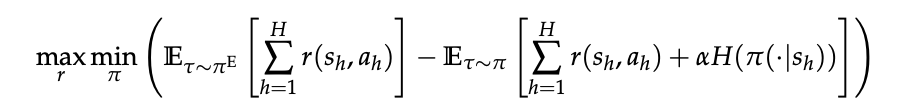
与 RLHF 奖励建模的联系
可将 MaxEnt IRL 目标视为 RLHF 中 BT 模型背后原理在分布层面的一般化。
BT 模型(式 3)通过最大化“胜者”轨迹 y_w 与“败者”轨迹 y_l 的得分差异来学习奖励函数,本质上是样本级成对比较。
而上式则是分布级对应:不再比较两条采样轨迹,而是比较整个专家分布 πE 与在奖励 r 下产生的最优竞争策略 π。
其中 min_π 主动寻找最强竞争策略,max_r 再调整奖励以拉开性能差距。
因此,RLHF 的奖励建模可视为 IRL 原理的一种实用、可计算的实例化:
它不再求解复杂的 min_π,而是直接在偏好数据集上最大化“胜者”与“败者”的奖励差。
BT 模型只是 IRL 所提供的一般理论框架下的特例。
我们的工作回到这一更一般的 IRL 形式,无需显式成对比较即可直接导出奖励函数。
3 在语言模型内部寻找内生奖励
本节给出我们的核心理论结论:
- 对于任何基于标准“下一 token 预测”训练的语言模型,其 logits 本身就可以直接恢复出一条有理论依据的奖励函数。
3.1 基于逆强化学习的奖励学习
正如前文所述,RLHF 中的奖励建模可视为逆强化学习(IRL)这一更根本框架的简化和实用版本。
IRL 被视为从数据中习得奖励函数最自然的规范框架。
这自然引出一个问题:能否摆脱 RLHF 中常见的成对比较启发式,直接采用更基础的 IRL 方法,来恢复最能解释专家数据集 D 的最优奖励函数?
历史上阻碍这种直接做法的主要难点是:大多数 IRL 方法面向在线场景,需要昂贵的交互计算。
一种更直接且实用的做法是用离线 IRL 方法——具体而言,基于逆软 Q-学习(inverse soft Q-learning)[Garg et al., 2021]——来形式化问题。
该方法在给定的静态数据集
中寻找最能解释专家数据的 Q 函数,其优化目标为
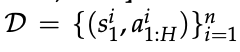
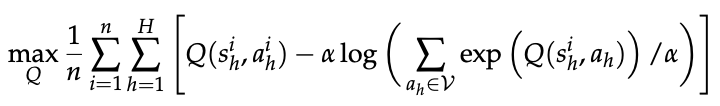
一旦得到最大化上式的最优 Q 函数 Q*,即可通过逆软 Bellman 算子 [Garg et al., 2021] 恢复对应的理想奖励函数
式6:
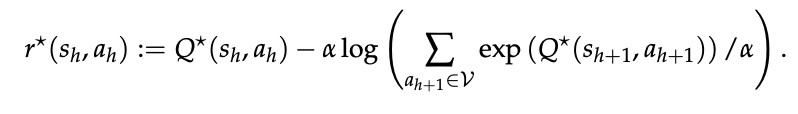
这给出了一个无需交互、有理论依据的奖励函数获取方法。
关键问题是:式 (6) 的最优解 Q^* 究竟是什么?我们能否在不引入额外复杂优化过程的情况下得到它?
3.2 “下一 token 预测”可以恢复 IRL 解
下面我们证明:式 (6) 所要求的 Q^* 根本无需从零计算——它早已隐含于任何以标准“下一 token 预测”目标训练的语言模型的 logits 之中。
为了看清这一点,我们先分析 IRL 目标究竟在寻找怎样的解。
式中 log 内部的比值可视为一条策略
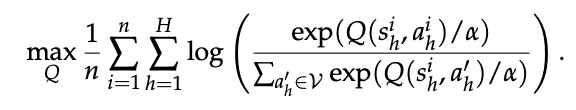
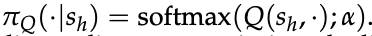
因此,优化问题实质上是寻找这样一个 Q 函数:其诱导的策略 π_Q 在数据集 D 上的专家演示似然最大化。
而这正是“下一 token 预测”训练语言模型的初衷。
训练过程中,语言模型 π̂ 被优化以最大化所示的对数似然;
既然 π̂ 已是最大似然问题的解,其底层 logit f̂ 自然就成为式 (6) 中 IRL 优化问题的一个有效 Q 函数解。
我们将这一直接联系形式化为:
- 命题 1
设 π̂ 为在数据集 D 上通过“下一 token 预测”训练得到的语言模型,策略形式为 π̂(·|s_h)=softmax(f̂(s_h, ·); α),其中 f̂ 为模型 logit。则 logit 函数 f̂ 是式 (6) 所述离线 IRL 目标的一个解。该命题奠定了本文的理论基石:
语言模型的 logit 并非随意分数,而是一个有理论依据的 Q 函数,它隐式地编码了模型训练数据上的最优奖励函数。
这一发现将生成与评价统一起来——模型的策略 π̂ 负责生成,而其 logit f̂(作为 Q 函数)则负责评价。
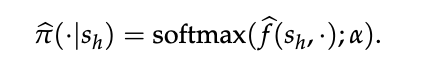
3.3 内生奖励(Endogenous Reward)
命题 1 建立的直接联系,为我们提供了一种无需训练即可获取奖励模型的强有力方法。
对于任何基于“下一 token 预测”训练的语言模型——无论是预训练还是微调——我们只需取其 logit Q̂ = f̂,并代入式 (7) 的逆软 Bellman 算子:
定义值函数
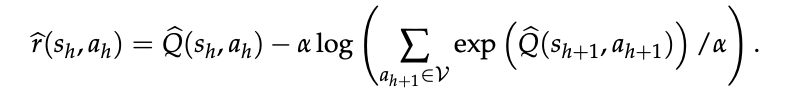
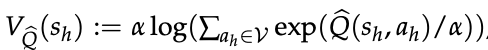
下面从三个角度详细阐述这一内生奖励。
- 奖励塑形(Reward Shaping)
由式 可见,
内生奖励 r̂ 可视为对原始奖励 ê(s_h, a_h) := log π̂(a_h|s_h) 的塑形形式,其中 V_{Q̂} 充当势函数。根据 Ng et al. [1999] 的奖励塑形理论,r̂ 与 ê 诱导相同的最优策略与值函数。因此塑形并不改变策略学习的最终目标
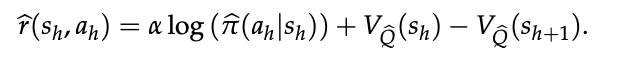
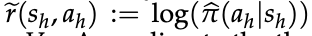
- 结果奖励(Outcome Reward)
对于完整响应 τ = (s_1, a_1, …, s_H, a_H),
其结果奖励为:
表示在策略 π̂ 下从初始提示 s_1 生成整条轨迹 τ 的概率。第二项利用了可消去的边界条件
由此可见,结果奖励等于轨迹上所有 token 的对数概率之和,仅额外加上一个只与初始状态(即提示)有关的项 V{Q̂}(s_1)。
直观地讲,如果某条响应在训练数据中出现得越多,模型赋予它的生成概率就越高,对应的奖励值也就越大
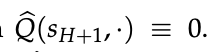
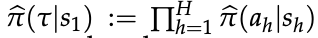
- 现有生成式奖励模型作为特例
下式提供了一个通用框架:利用 LLM 的概率来构造奖励。现有生成式奖励模型 [Mahan et al., 2024; Zhang et al., 2024] 均可视为该框架的特例。
例如,给定问答对 (x, y),Zhang et al. [2024] 的生成式验证器使用提示 P = “Is the answer correct?”,并以单 token “Yes” 的概率 π̂(Yes|x, y, P) 作为奖励。这对应于令 s_1 = (x, y, P)、a_1 = “Yes”,于是
r̂(τ) = α log π̂(Yes|x, y, P),与他们的做法完全一致。
类似地,Mahan et al. [2024] 面向成对比较的生成式奖励模型也可纳入此框架。
因此,命题 1 为这些现有方法提供了理论依据。# 3 内生奖励的提出与理论支撑
4 内生奖励的理论依据
本节从奖励误差与诱导策略误差两方面给出内生奖励的理论证明。
4.1 内生奖励的误差分析
沿用最大熵逆强化学习 [Ziebart et al., 2008] 的设定,假设专家策略 πE 是关于未知真实奖励 r⋆ 的熵正则最优策略。
根据正则化 MDP 理论 [Geist et al., 2019] 有
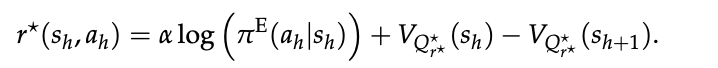
由于奖励歧义性 [Ng et al., 1999]——多个奖励函数可对应同一专家策略——即使完全知道 πE 也无法唯一逼近 r⋆,因此无法给出绝对误差界。
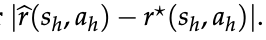
然而,奖励模型的核心用途之一是成对比较 [Ouyang et al., 2022; Bai et al., 2022a; Malik et al., 2025]。
于是转而分析其比较性能。
给定两条完整响应
,奖励 r 诱导的偏好分布为
其中
为sigmoid。
目标是度量真实分布 Pr^⋆ 与内生奖励分布 P{r̂} 之间的距离。
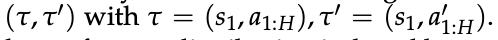
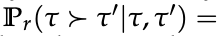
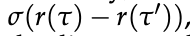
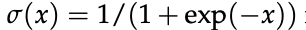
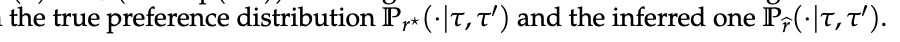
- 定理 1
在未知真实奖励 r⋆ 的 token-level MDP 中,设专家策略 πE 为熵正则最优策略。
令 π̂ 为经下一 token 预测训练的策略,r̂ 为式 (10) 定义的内生奖励如下。
对任意两条响应 τ, τ′ 有以下不等式成立
其中总变差距离为:
其中分布:
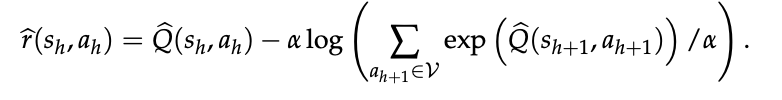
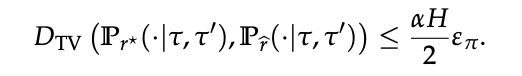
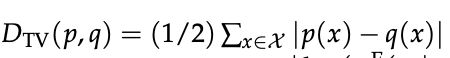
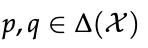
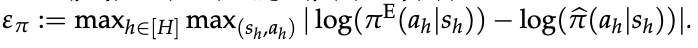
定理 1 表明:
只要用于提取奖励的 LLM π̂ 与专家 πE 在 log-probability 上足够接近,内生奖励诱导的偏好分布就与真实分布足够接近,从而继承了专家性能。
4.2 基于内生奖励微调的 LLM 误差分析
提取奖励函数的最终目的是利用它通过强化学习训练出一个新的、更优的策略。在此,我们分析新学到的策略的表现,并将其与基础策略进行比较。
具体来说,我们分析了两种方法。
第一种方法直接在演示数据上应用“下一个 token 预测”(即行为克隆),从而得到基础策略 π̂。
另一种方法首先基于式 (10) 从基础策略 π̂ 构建内生奖励 r̂,然后使用 r̂ 进行强化学习,得到新的策略 πRL = argmax_π Vπ_{r̂}。
在这里,我们忽略了解最优策略时可能出现的任何优化误差。理论目标是在真实奖励 r* 下分析和比较 πRL 和 π̂ 的次优性。
定理 2
在 token 级别的马尔可夫决策过程(MDP)中,假设存在一个未知的真实奖励函数 r∗,并且专家策略 πE是关于 r∗的熵正则化最优策略。
设 πb是通过“下一个 token 预测”训练得到的策略,而 br是根据式 (10) 提取的奖励函数。
使用提取的奖励 br进行强化学习,以学习新的策略 πRL即
则在真实奖励 r* 下
其中 V r π表示策略 π 在奖励函数 r 下的值
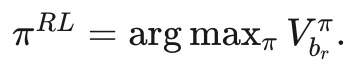
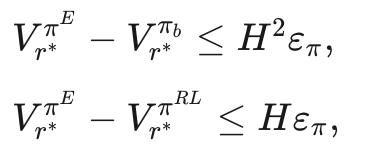
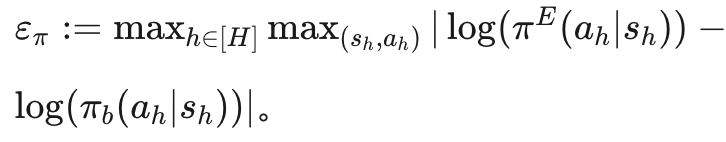
定理 2 的含义
定理 2 表明,使用内生奖励 br进行强化学习得到的策略 πRL在次优性界限上对响应长度 H 的依赖是线性的,而直接通过“下一个 token 预测”(即行为克隆)得到的策略 πb的次优性界限对 H 的依赖是二次的。
这种二次依赖反映了模仿学习中的复合误差问题 [Ross and Bagnell, 2010; Xu et al., 2021],其中单步误差 ε π沿着轨迹累积。
而 πRL所实现的线性依赖揭示了逆强化学习的一个根本优势:与其直接模仿专家行为,不如恢复潜在的奖励函数,并使用这个奖励进行强化学习,从而消除复合误差问题。
作为技术性注释,尽管本文关注的是有限时间范围的设置,但定理 2 可以通过 [Xu et al., 2021] 中开发的分析扩展到无限时间范围的设置
4.3 迭代改进的无效性
一个自然的问题是:能否把改进后的策略 π{RL} 再提取其内生奖励并再做一次 RL,从而获得持续改进?
答案是否定的。
π{RL}已是 r̂ 的最优策略,由其提取的内生奖励正是使 π^{RL} 最优的那条奖励,再次 RL 只会得到相同策略,过程立即收敛。
5 实验
在本节中,通过实验来验证理论主张。
估旨在回答以下三个核心研究问题:
Q1:无需训练的内生奖励模型(EndoRM)在常见的奖励模型基准测试中,与启发式基线和经过明确训练的最先进的奖励模型相比,表现如何?
Q2:内生奖励是否具有强大的指令遵循能力,能够作为可被提示的通用奖励模型发挥作用?
Q3:使用内生奖励进行强化学习是否能够产生更好的策略,实现自我改进,正如我们的理论所预测的那样?
5.1 实验设置
- 数据集:
- 使用 RM-Bench [Liu et al., 2025] 作为测试平台,用于评估不同奖励模型的整体性能(Q1)。
- 为了评估 EndoRM 的指令遵循能力(Q2),使用了包含多样化用户特定偏好的 Multifaceted-Bench [Lee et al., 2024b],以及为不同专业领域提供不同偏好的 Domain-Specific Preference(DSP)数据集 [Cheng et al., 2023]。
- 最后,为了验证使用 EndoRM 进行强化学习是否能够实现自我改进(Q3),使用了 MATH-lighteval [Hendrycks et al., 2021] 作为训练数据集。
- 评估指标:对于 RM-Bench、> - Multifacted-Bench 和 DSP,计算奖励模型在给定提示下对两个响应的分类准确率。对于我们的方法,我们计算每个响应的所有 token 的总奖励和,如附录 C 所示。具有更高奖励和的响应被分类为“选定”。
- 对于强化学习,我们选择了五个广泛使用的数学推理基准测试,包括 AIME 2024、AMC [Li et al., 2024b]、Minerva [Lewkowycz et al., 2022]、OlympiadBench [He et al., 2024] 和 MATH-500 [Hendrycks et al., 2021]。
训练和测试的温度分别设置为 1.0 和 0.6。- 对于 AIME 2024 和 AMC,我们报告 avg@32,对于其他三个基准测试,我们报告 pass@1。
5.2 在多样化偏好对上的奖励准确率(Q1)
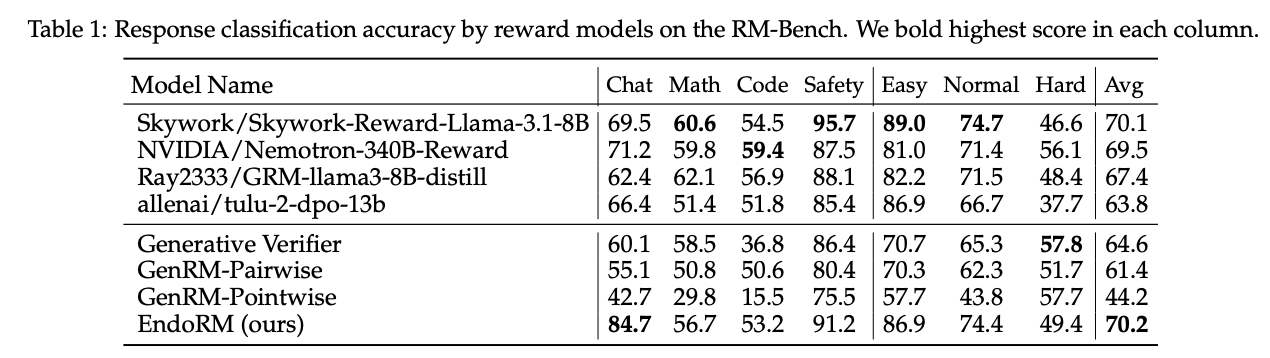
在 RM-Bench 基准数据集上,作者比较了内生奖励(EndoRM)与多个训练型和非训练型奖励模型的表现。实验采用统一的底层语言模型(Qwen2.5-7B-Instruct)以确保公平性。
表 1 的结果显示,EndoRM 不仅显著优于使用相同基础模型的所有无需训练的基线,而且其平均得分还高于最先进的经过明确训练的奖励模型,这表明内生奖励可能比需要昂贵偏好数据整理和训练的奖励模型更有效。
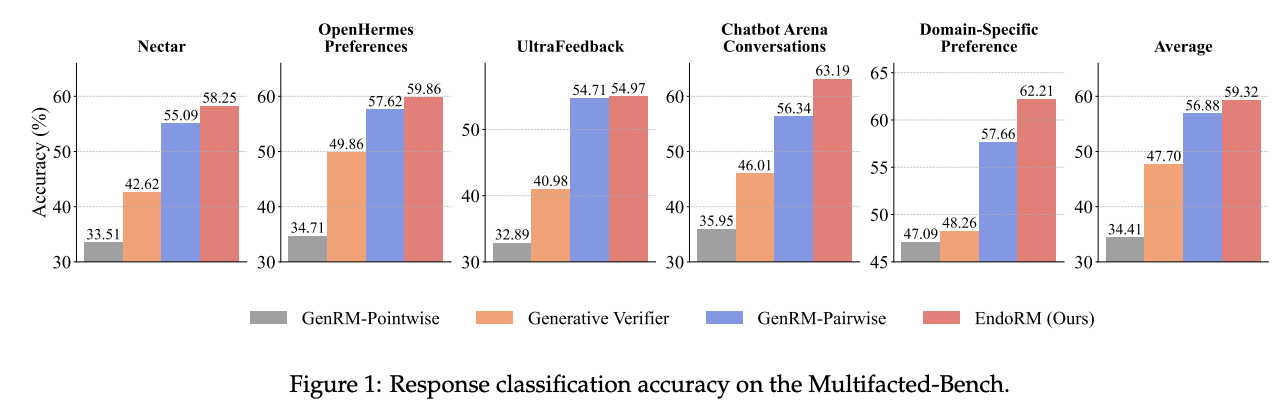
在 Multifaceted-Bench 上,EndoRM 同样展现出良好的跨任务适应能力,准确识别了多种用户偏好设置下的优劣回答。这表明即使在任务复杂性和偏好多样性增加的情况下,EndoRM 也能实现可扩展的稳健性。这支持了我们的核心假设,即强大的奖励信号已经潜藏在基础模型中。
5.3 验证指令遵循能力(Q2)
一个关键的主张是:内生奖励并非静态的,而是可以被提示(prompted)的。
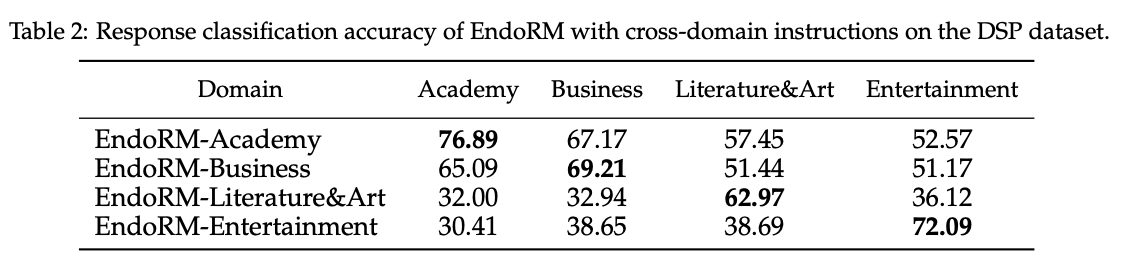
为了验证这一点,我们使用了包含四个不同领域的 Domain-Specific Preference(DSP)数据集。
我们通过简单地将 DSP 论文中对应的系统提示作为输入,创建了四个特定领域的内生奖励版本。
然后,我们在所有四个测试集上测试了每个特定领域内生奖励的响应分类准确率。
为了获得每个领域的内生奖励,奖励模型将采用 Cheng et al. [2023] 论文附录 A 中呈现的系统提示作为输入。
表 2 中的结果显示了一个强烈的对角线模式:每个 EndoRM 在其自身领域上表现最佳。
例如,EndoRM-Academy 在学术数据上达到了最高的准确率(76.89%)。
这证实了内生奖励并非一个固定的评估器,而是一个动态的、可提示的裁判,继承了基础 LLM 强大的指令遵循能力。
5.4 通过强化学习实现自我改进(Q3)
最后,我们验证了定理 2 中的核心理论主张:使用内生奖励进行强化学习(RL)可以改善基础策略,通过减少复合误差来提升性能。
我们使用 Qwen2.5-Math-7B 作为基础模型,并在 MATH-lighteval 数据集上通过强化学习对其进行训练 [Shao et al., 2024]。内生奖励模型同样是 Qwen2.5-Math-7B,其参数在策略学习过程中保持固定。
提示和响应的最大长度均设置为 1024,KL 散度系数设置为 0.01。
表 3 的结果显示,使用内生奖励进行的强化学习微调帮助模型在所有五个基准测试中持续超越基础模型。
我们还在附录 E 中展示了在进行基于内生奖励的优化之前和之后模型的响应示例。
可以看到,对于同一个问题,优化之前,模型未能解决问题,并且随着响应的进行开始胡言乱语,甚至输出了 Python 代码。
相比之下,我们的方法提供了一个清晰简洁的解决方案。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 19
19 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)