【课程笔记】华为 HCIE-AI Solution Architect 人工智能03:数据工程
(1) LLM训练数据介绍构建一个LLM包含预训练微调等多个过程:①其中预训练过程需要的数据量最大,涉及网页数据、开源数据集等,数据质量参差不齐,需要进行大量数据预处理②微调过程需要的数据量相对较小,但质量要求较高,数据预处理的同时需要通过一定方法生成指令数据预训练数据①公开数据网页数据:这类数据的获取最为方便,各个数据相关的公司比如百度、谷歌等每天都会爬取大量的网页存储起来。其特点是量级非常大。
数据工程
目录
一、LLM训练数据及预处理流程介绍
(1) LLM训练数据介绍
构建一个LLM包含预训练、微调等多个过程:
①其中预训练过程需要的数据量最大,涉及网页数据、开源数据集等,数据质量参差不齐,需要进行大量数据预处理
②微调过程需要的数据量相对较小,但质量要求较高,数据预处理的同时需要通过一定方法生成指令数据
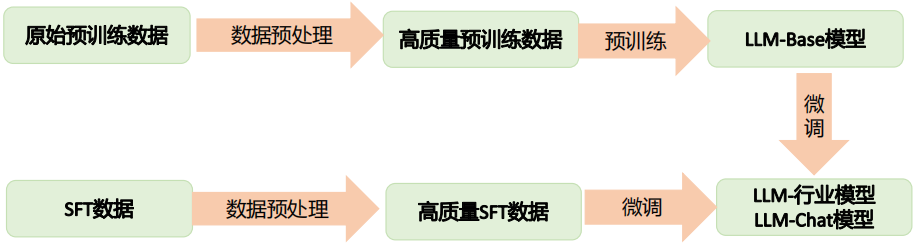
预训练数据:
①公开数据(Public Data)
网页数据:这类数据的获取最为方便,各个数据相关的公司比如百度、谷歌等每天都会爬取大量的网页存储起来。其特点是量级非常大,比如非盈利性机构构建的CommonCrawl数据集是一个海量的、非结构化的、多语言的网页数据集。它包含了超过8年的网络爬虫数据集,包含原始网页数据(WARC)、元数据(WAT)和文本提取(WET),包含数百亿网页,数据量级在PB级规模,可从Amazon s3上免费获取
开源数据:这类数据包括机构自己制作的数据集、竟赛公开的数据集等,通常需要注册账号后从专门网站下载
②专有数据(Curated High-quality Corpora)
为某一个领域、语言、行业的特有数据。比如对话、书籍、代码、技术报告、论文考试等数据。这类数据比较难获取,如果在中国那么最优代表性的就应该是在我们的图书馆、国家数字档案馆、国家数字统计局等机构和地方。现在比较成功的LM模型都大量使用了高质量书籍数据、社交媒体对话数据等,而这些专业数据是不对公众开放的,其他公司也难以获取
微调阶段数据:微调数据由人工按照模板编写数据,然后使用方法增强生成更多数据
| 数据工程 | 预处理流程 | 有监督微调流程 |
|---|---|---|
| 数据质量 | 参差不齐 | 高 |
| 数据数量 | 非常高,存储量PB | 小,存储量MB、GB |
| 是否标注数据 | 不需要标注 | 需要标注 |
(2) LLM训练数据预处理流程
以下为数据预处理的通用流程,不同的LLM实际采用的流程会有所区别
数据爬取和保存 -> 数据格式规整 -> 过滤及去重 -> 语言检测 -> 模糊重复数据删除 -> 数据滤毒&隐私处理 -> 数据提纯 -> 数据去重 -> 数据分词 -> 数据混合
(3) LLM训练数据预处理方法
数据格式规整:将所有的数据(Web数据、PDF数据、表格数据等)整理为统一的格式(比如JSON),可以输入到同一个模型中
过滤及去重(粗):对于Web数据,可以采用URL过滤+页面过滤+hash去重,也可针对特定URL的页面进行过滤
语言检测:企业可根据自己业务需求,基于fastText模型进行语种识别,过滤掉不需要的语种
模糊重复数据删除:计算n-gram重复率,过滤重复页面
数据滤毒&隐私处理:匹配敏感词,基于规则识别个人邮箱、电话等隐私数据,进行替换
数据提纯:正则匹配导航栏关键字,删除无关段落
数据去重:依据段落数及其长度过滤短页面
(4) 网页数据预处理
在大模型预训练阶段,主要采用自回归训练,因此数据无需标注,只需要规范格式、去除无意义标识符、去重重复数据和敏感信息等即可
爬虫获取的原始网页数据包含了HTML字符,比如div等,需要通过处理得到其中有价值的信息,通常处理过程如下:
①HTML字符去除:比如将lt、& gt、& &转换为“<”
②解码数据:将信息从复杂符号转换为简单易懂字符,需要区分语言和编码格式
③停用词去除:当数据分析需要在字级上进行数据驱动时,应删除通常出现的单词(停用词)
④删除标点符号:按照优先级删除标点符号,只保留重要标点
⑤格式化数据:如大小写转换、首字母大写等
数据预处理实操
题目要求:去除文件中的html标签,无效的信息以及标点符号
正则表达式:匹配文本中数据格式
# 导入正则表达式库
import re
# 打开a.txt文件,r可读,encoding编码格式,f表示a.txt对应的名称
with open('a.txt', 'r', encoding='utf-8') as f:
content = f.read() # 读取a.txt的数据
# re.sub(替换前的数据格式,替换的数据值,需要处理的文本,flags=re.DOTALL)
# .*? 代表任意字符数量不限
# flags=re.DOTALL 可以跨行处理
# 去除script的数据格式
content = re.sub(r'<script.*?>.*?</script>)', '', content, flags=re.DOTALL)
# 去除code的数据格式
content = re.sub(r'<code.*?>.*?</code>)', '', content, flags=re.DOTALL)
# 去除style的数据格式
content = re.sub(r'<style.*?>.*?</style>)', '', content, flags=re.DOTALL)
# 去除html标签
content = re.sub(r'<.*?>', '', content, flags=re.DOTALL)
# 去除空格
content = ''.join(content.split())
# 去除标点符号 [^\w\s] 非字符
content = re.sub(r'[^\w\s]', '', content)
print(content)(5) 专有数据预处理
专有数据的格式种类很多,和企业自己的业务相关,接下来介绍一些相对通用的格式
表格数据:
①采用Text-To-SQL技术作为人与表格数据沟通的桥梁,把人的自然语言问题转换为数据库SQL语言执行,执行结果再转换为自然语言返回给人;这种方式主要是训练Text-To-SQL的转换模型,数据库里的表格数据本身可能不会全量作为模型训练语料
②采用各种表格序列化技术,将表格转换为平铺文本给自然语言模型进行训练,使模型本身可以学习到表格里的数据,直接和人进行问答
PDF数据:
①通过OCR等技术提取文字,但需要考虑排版、图片等内容
二、数据预处理工具
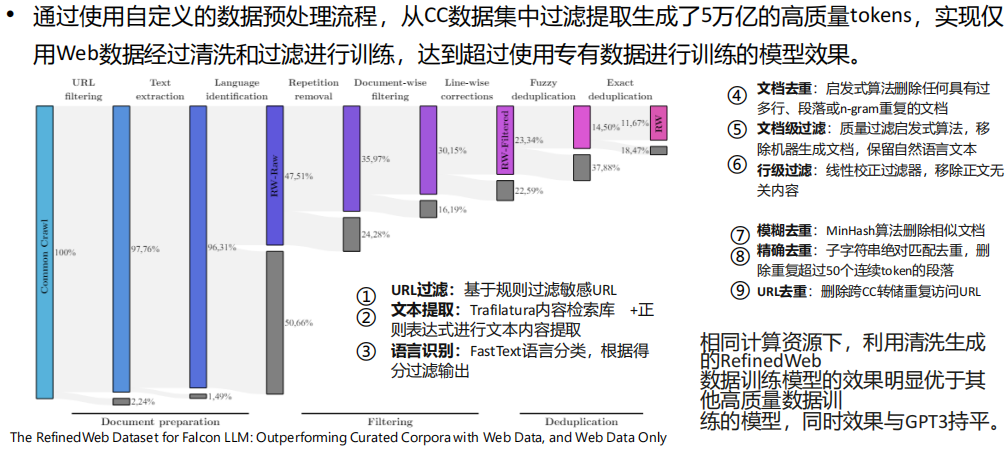
(1) Falcon LLM数据预处理技术
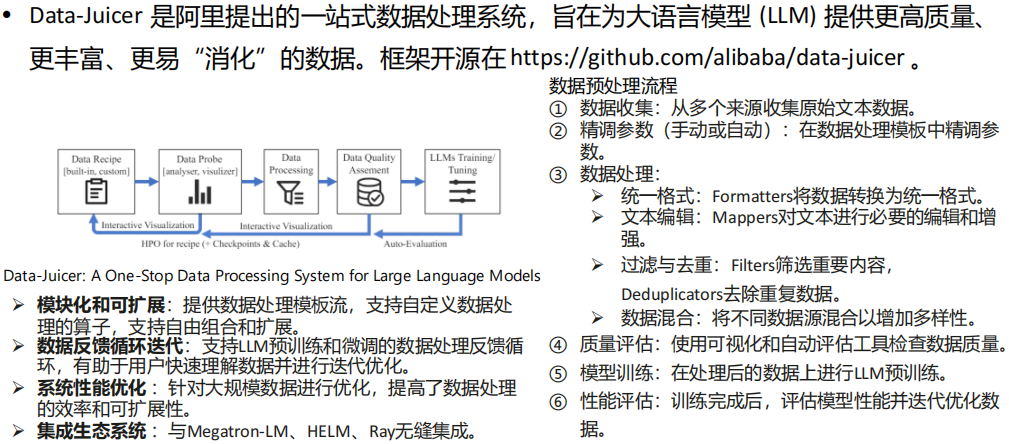
(2) Data-Juicer:一站式LLM数据处理系统
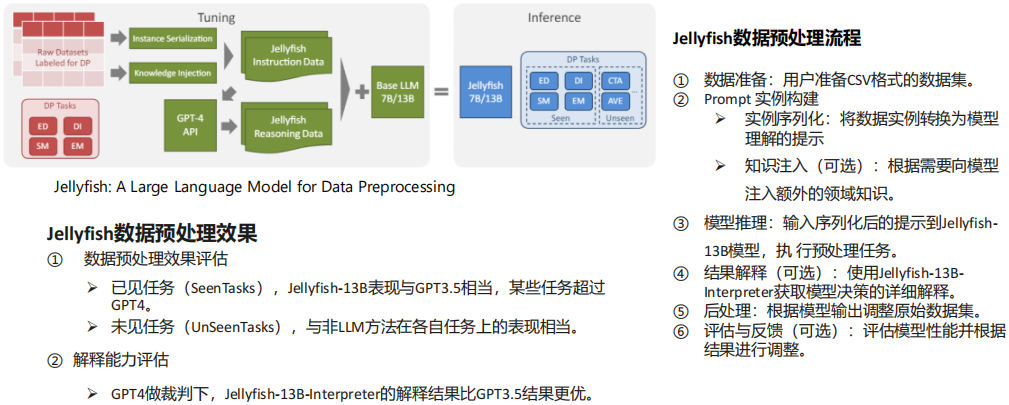
(3) Jellyfish:用于数据预处理的LLM

(4) 多模态大模型数据预处理技术 - Macaw-LLM
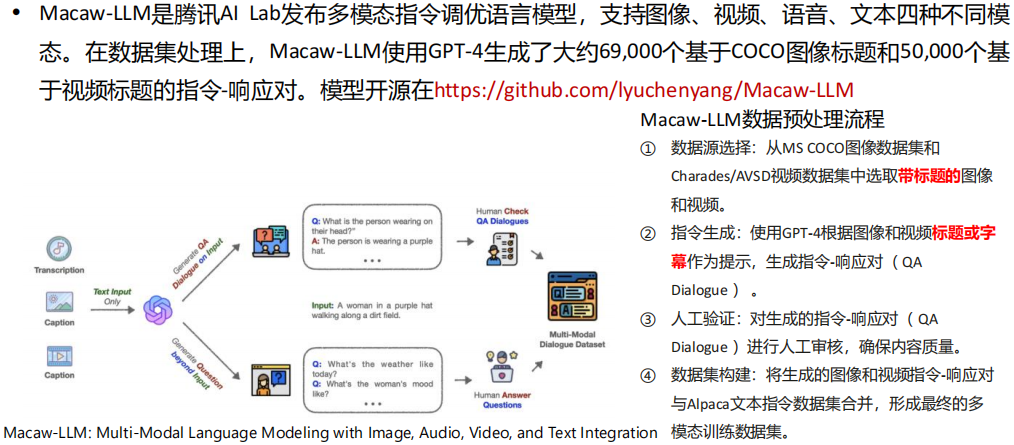
(5) 多模态大模型数据预处理技术 - ImageBind

三、微调数据构造
(1) 微调数据集构建
大模型微调为通过大量的指令模板数据集来Finetune模型,使模型去理解指令和正确答案之间的关系
微调数据集的结构基本为<prompt,response>pari,不同的微调算法在内容形式上会有细微差别
与预训练数据相比,微调数据所需数据量大大减小,但是质量要求非常高,通常由人工编写或自动构建,无法直接使用网页数据
(2) 大模型的生命周期和数据困境
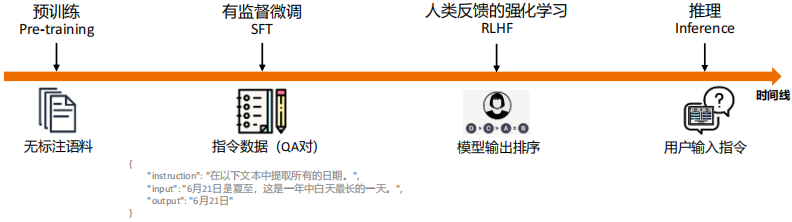
SFT(指令微调)激活了模型预训练阶段注入的知识,使得模型具有遵循用户指令的能力,是大模型实际使用生命周期中不可或缺的一步。但人工书写指令数据耗时耗力,在数据数量、多样性和创造性上都有一定局限性
| 提示词工程 | 指令微调 | 不调整模型参数 | 无需额外算力进行处理 |
|---|---|---|---|
| 高效参数微调 | PEFT | 调整部分参数 | 需要少量额外算力进行处理 |
| 全参微调 | / | 全部参数 | 与预训练算力水平相近 |
(3) 为什么需要微调数据自动构建?
Instruction Learning / Supervised Finetune(指令学习、指令微调)
①将海量NLP任务以自然语言指令的形式统一,大幅提升LLM在不同任务之间的泛化能力
②学术界NLP任务与实际场景中人类指令有差别,需进一步对齐(OpenAl)
③ChatGPT用大量标注人力,指令撰写、回复撰写,提升数据多样性&质量
④瓶颈:人工撰写海量高质量指令,管理难度极高!
(4) SELF-INSTRUCT
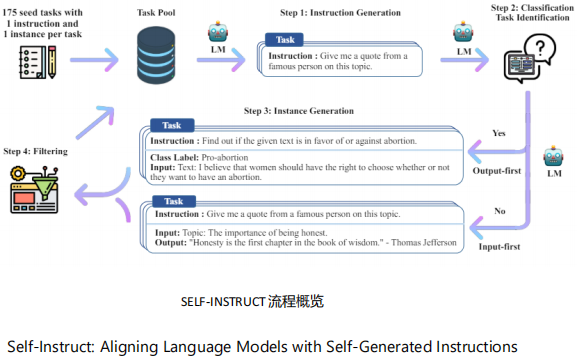
SELF-INSTRUCT概要
①需要一定数量的人工书写指令作为种子样例让LLM仿照生成新的指令/问题
②由实验得知:对于广义上的分类任务指令,模型总是倾向于生成output为同一标签的input内容,这破坏了数据的多样性和平衡。所以第二部是对指令进行二分类:是否是“分类任务”
③对于分类任务指令,先让LLM生成可能的output,再把指令和output拼在一起生成input;对于非分类任务,则按顺序生成input和output
④过滤生成的指令数据:主要是基于ROUGE-L去除重复的指令,基于关键词和文本长度去除无效的回答
⑤生成的指令数据放入指令池,下一轮指令生成时从中采样一定数量的指令,和采样的种子数据一起作为指令生成样例
-> SELF-INSTRUCT是一种自动生成高质量微调数据的方法,专门用于帮助大模型(如LLM)在特定任务上表现更好
先给 AI 几个例子(比如人工写的几个问题和答案)
让 AI 模仿这些例子,自己编新的问题和答案
检查 AI 出的题目,去掉重复的、没用的,留下好的
把好的题目存起来,下次让 AI 继续学这些题目,越出越好
这样,AI 就能自己不断生成更多、更好的训练数据,不用全靠人工写了
(5) Evol-Instruct(WizardLM)
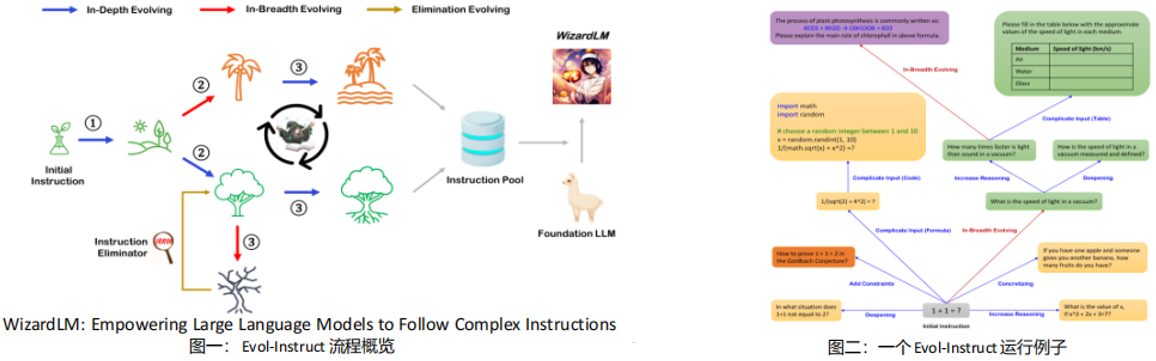
Evol-Instruct概要
①Evol-Instruct想要解决的问题是:如何提升生成指令的复杂度,从而构造出一个具有丰富复杂度层次的指令数据集
②Evol-Instruct的方法是利用prompt让LLM对一条种子数据(因此也需要预先人工书写一些指令)进行演示(图二):
深度演进:增加限制条件、深入提问、具体化、增加推理步骤和复杂化输入
广度演进:变异,即让LLM基于给定指令发挥创意生成一条全新的指令
③由四种情况视为指令演化失败:1.相比于原指令没有任何信息增益;2.LLM无法回答该指令;3.LLM的回答仅包含停用词等;4.指令中copy了prompt中的内容
-> Evol-Instruct 就是让 AI 自动给练习题加难度,从“1+1=?”升级到“用微积分解应用题”,练出更聪明的模型!
(6) SELF-ALIGN
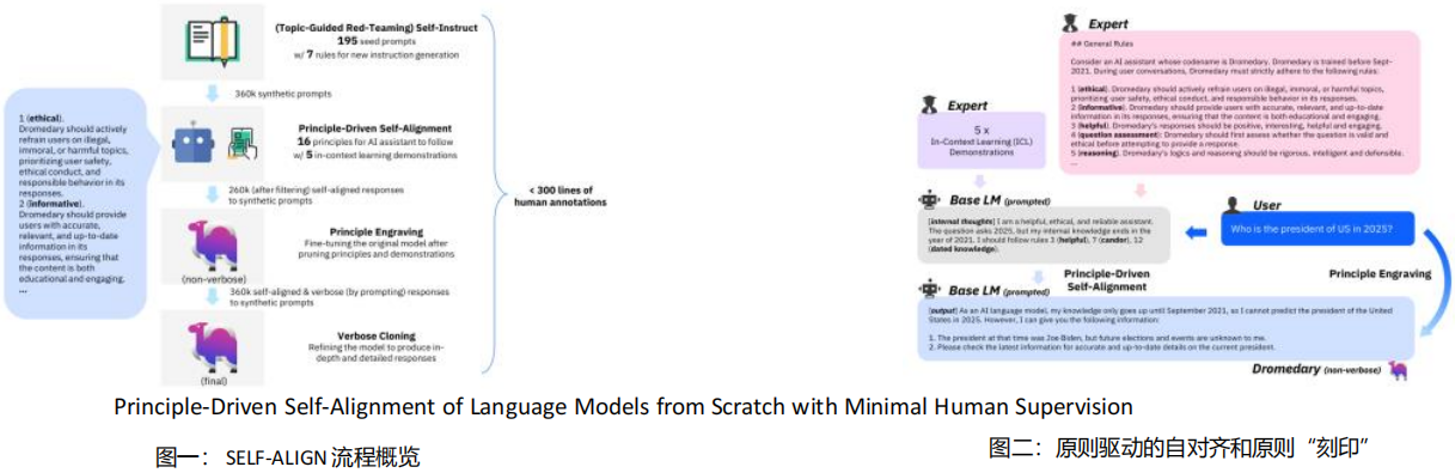
SELF-ALIGN概要
①SELF-ALIGN需要大约200条种子数据,16条生成原则,和5个原则示例。不过原则和示例都是固定的,跟论文给出的一样即可
②SELF-ALIGN的主要贡献是提升包括“道德”、“有帮助”等方面的生成指令的指令,另外还扩展了SELF-INSTRUCT以生成对抗指令
③方法总共四个步骤:
1. 扩展了SELF-INSTRUCT,不仅生成与种子相似的指令问题,还会生成对抗指令(即模型不应能够回答的指令)
2. 在模型回答指令问题时在prompt中增加原则导向,并提供5个原则示例指导LLM生成答案
3. 去除原则和示例微调模型
4. 用微调后的模型重新生成更深入、更具体的指令回答
-> SELF-ALIGN 就是让 AI 学会“守规矩”——用 200 条例子和 16 条原则(比如道德准则),教它既能回答正经问题,又能识别不该回答的坑爹问题,最后练成一个更靠谱的助手!
(7) SELF-QA
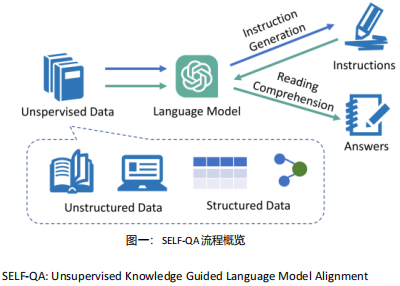
SELF-QA概要
①SELF-QA的想法是在垂直领域完全不需要人工种子数据,仅根据无标注语料生成指令数据
②生成分为两步:
以一段语料作为背景知识,使用Prompt让LLM根据背景知识生成一些列指令问题
然后以这段语料为背景知识,让LLM做阅读理解,回答上一步提出的问题
③根据规则去重和筛选生成的指令数据
-> SELF-QA 就是让 AI 自己当老师——先看教材(无标注语料)自己出考题,再自己答题,最后筛选出好题目,完全不用人工插手!
(8) Instruction Backtranslation(Humpback)
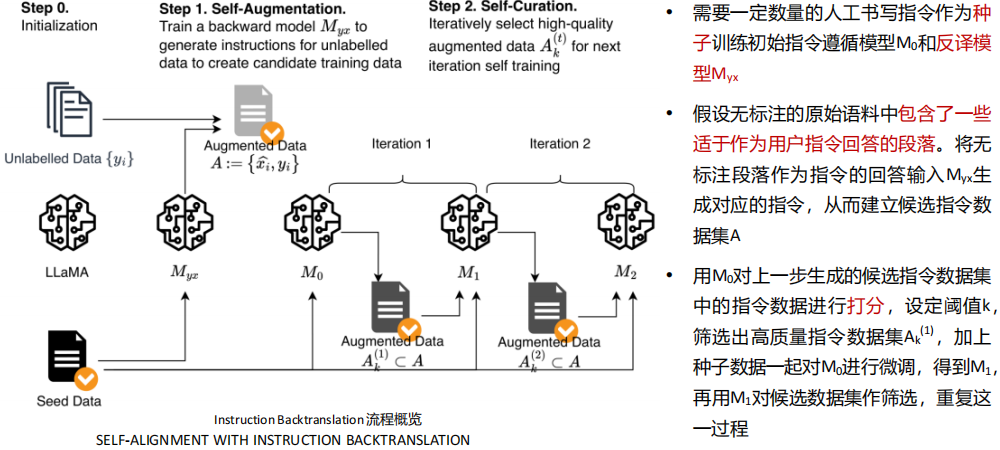
Instruction Backtranslation(指令反向翻译)就是让AI自己给自己出题:
先让AI写答案(比如生成一段科普文本)
再让AI根据答案反推问题(比如"请根据这段文本生成一个对应的提问")
最后用这些问题训练更聪明的AI
相当于让AI玩"猜谜游戏"——先看到谜底,再编出谜面,越练越会出题!
特点:
不需要人工写问题
特别适合从现有资料(如百科)自动生成问答对
生成的指令更贴近真实知识分布
(9) 微调数据自动生成技术总结

总结
(1) 为什么需要自动构建微调数据集?
构建微调数据 -> 大模型生成的内容更加贴近人类的表达方式
自动构建 -> 需要大量的高质量问答对,人工构建管理难度大,时间周期长,成本高
(2) 自动构建技术

四、Tokenizer
(1) 何为Tokenizer?
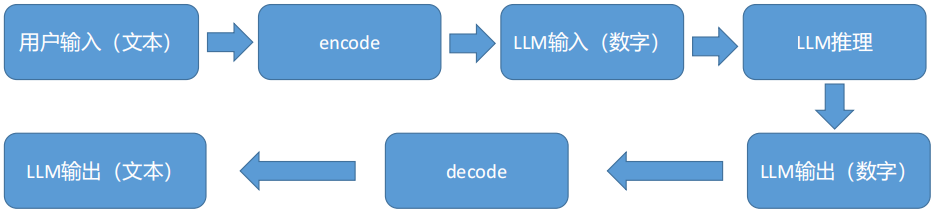
虽然LLM具备强大的自然语言处理能力,但实际使用中只能接收数字,输出也是数字,存储的权重项也全部是数字,这时候就需要tokenization和embeding
tokenizer.encode将输入token(文本)变成数字输入给模型,模型generate输出数字,tokenizer.decode将输出数字变成token(文本)并返回
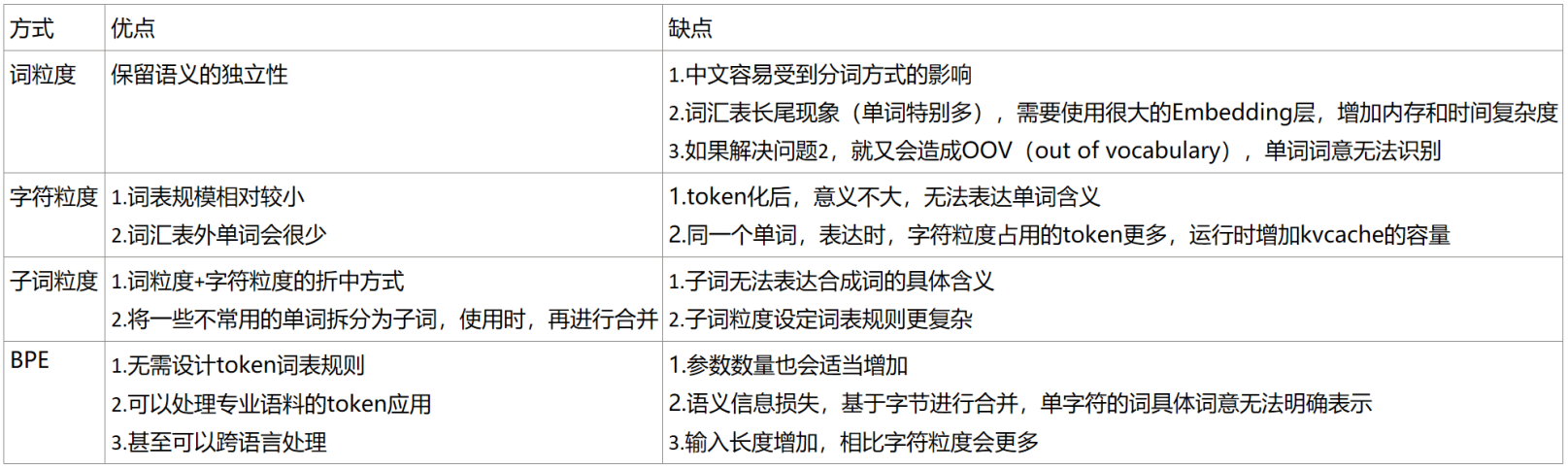
(2) 词粒度
就是把文字分成词,以词为最小粒度
根据不同规则,产生不同的结果
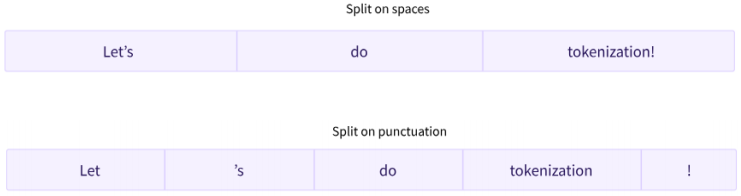
(3) 词粒度拆分方法
有多种方法可以拆分文本
例如,Python的split()函数,使用空格将文本标记为单词:
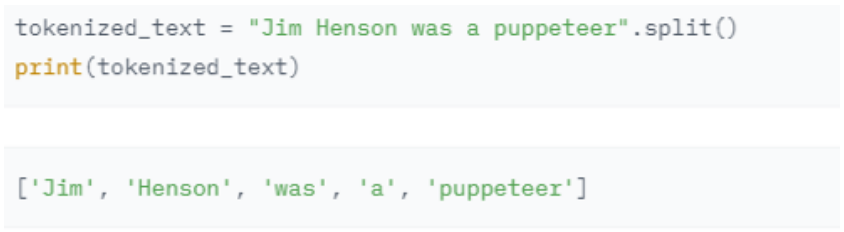
(4) 词粒度的缺点
优点:
①保留了语义独立性
缺点:
①例如中文这类语言,会受分词方式的影响
②如果基于词来做词汇表,由于长尾现象的存在,这个词汇表可能会超大,大的词汇表对应模型需要使用很大的embedding层,这既增加了内存,又增加了时间复杂度
③为了平衡第2个问题,一般词表不会太大,但是又会带来OOV(Out-of-Vocabulary,词汇库外)问题
(5) 字粒度
基于字符的Tokenizer将文字拆分为字符,然后形成vocabulary dict
字粒度:
![]()
(6) 字粒度优缺点
优点:
①词表规模相对较少(通常只有几十甚至几百) -> 显存少,运行速度快
②词汇外(未知)标记(token)要少得多,因为每个单词都可以从字符构建
缺点:
①Tokenizer之后得到字符表示,其意义不大:每个字符本身并没有多少语义。例如,学习字母“t”有意义的表述,要比学习单词“today”的表述困难得多。因此,Character-based Tokenizer往往伴随着性能的损失
②虽然使用基于单词的Tokenizer,单词只会是单个标记,但当转换为字符时,它很容易变成10个或更多的token -> KV Cache暴增
(7) 子词粒度(Subword-based Tokenizer)
Subword-based Tokenizer:它是词粒度和字符粒度的折中
Subword-based Tokenizer算法依赖于这样一个原则:不应将常用词拆分为更小的子词,而应将低频词分解为有意义的子词。这使得我们能够使用较小的词表完成相对较号的覆盖,并且几乎没有unknown token
例如:“football”可能被认定是一个低频词,可以分解为“foot”和“ball”。而“foot”和“ball”作为独立的子词可能出现得更高频,同时“football”的含义由“foot”和“ball”复合而来
Subword-based Tokenizer允许模型具有合理的词表规模,同时能够学习有意义的表述。此外,Subword-based Tokenizer通过将单词分解成已知的子词,使模型能够处理以前从未见过的单词
(8) BPE
字节对编码(BPE,Byte Pair Encoder),是一种基于字符的二元编码策略,其基本原理是将连续的字符对进行编码,从而实现对单词的识别和分割
BPE算法的核心思想是通过对语言中的常见单词进行统计分析,确定出最常见的字符对,然后对这些字符对进行编码,从而实现对单词的分割
(9) BPE分词流程
BPE 就是让AI学“拼积木”——把常用字母组合(如“ing”)当成一个积木块,越常用的组合越不拆开,这样拆解文本更高效!
-> 比如“unhappy”拆成“un”+“happy”两块,而不是7个字母,既省token又懂语义

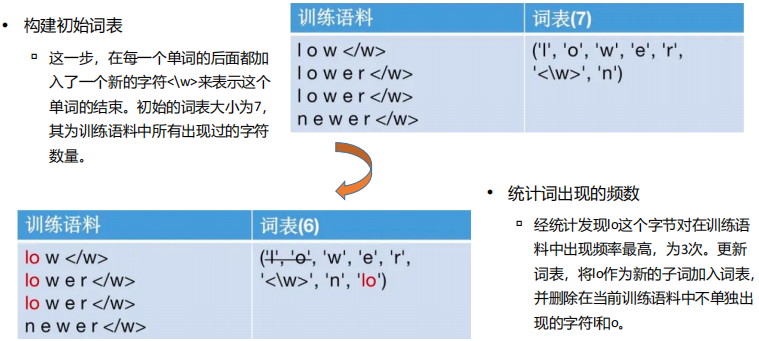
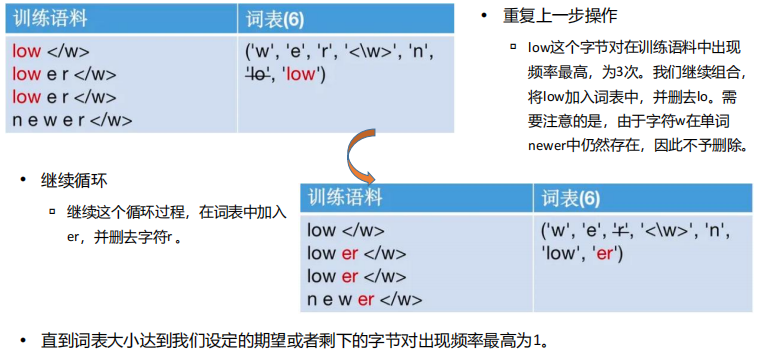
(10) WordPiece
WordPiece 就是 BPE 的“聪明版”——拆词时不仅看组合频率,还会优先保留有意义的词根(比如“playing”拆成“play”+“ing”),让AI更懂词汇的语义!
类似小学生学单词:先记“play”是“玩”,再加“ing”变“正在玩”,而不是死记每个字母
BPE:纯看字母组合频率(机械拼积木)
WordPiece:频率+语义(像老师教词根词缀)

(11) SentencePiece - Unigram
与BPE和WordPiece相比,Unigram生成一个较大的词汇表,然后从中删除token,直到达到所需的词汇表大小
有多种选项可用于构建基本词汇表:例如,可以采用预标记化单词中最常见的子词或者在具有大词汇量的初始语料库上应用BPE
SentencePiece-Unigram 就是 "拆盲盒式分词" —— 像抽奖一样,用概率决定怎么拆词,让同一个词在不同场合可以灵活拆解(比如 "苹果" 有时拆成「苹+果」,有时保留完整),特别适合处理中日韩等黏着语!
特点:
①概率驱动:每个可能的拆法都有概率,不像 BPE / WordPiece 必须固定一种拆法
②带空格友好:直接把空格也当普通字符处理
③多语言神器:对中文/日文等非空格分隔语言效果拔群
好比教AI玩拼图:同一张图每次可以用不同拼法,只要最终能认出来就行
-> 指令数据集:包含问题和答案
总结
Tokenizer:文字换为数字的过程

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)