YOLOv11猫猫人工智能分类识别项目课程(本文提供完整数据集、项目代码、英伟达4090D显卡服务器环境)
深度学习框架、YOLOv8、YOLOv11项目实战。
YOLOv11猫猫人工智能分类识别项目课程
猫猫分类别项目阐述
背景与意义
现代宠物经济的高速发展催生了精细化养宠需求,其中猫品种识别已成为宠物医疗、血统认证、智能养宠等领域的核心基础能力。据《2023 年中国宠物行业白皮书》显示,我国城镇养猫家庭已突破 7600 万户,能准确识别国际猫协(TICA)认证的 71 个标准品种的饲主不足 23%。传统人工鉴别模式存在专业门槛高(需掌握毛色纹理、面部结构等 300 余项特征)、幼猫识别误差大(幼年期品种特征显性率不足 40%)等痛点,导致宠物医院误诊率超 18%(中国兽医协会数据,2023),社交平台"云吸猫"内容分类准确率仅为 65%。在此背景下,基于深度学习的猫猫智能分类系统,为构建标准化、智能化的猫科动物识别体系提供了创新解决方案。
技术应用价值
智能猫猫分类系统通过整合生物特征识别技术,实现突破:
- 多维特征解析:运用卷积神经网络提取眼耳轮廓、毛色分布、面部比例等关键形态特征
- 动态识别优化:支持不同光照条件、拍摄角度、成长阶段的精准分类
- 轻量化部署:开发远程推理功能、实现无需适配安卓端的开发独立推理功能。
行业推动作用
猫科动物智能识别技术的应用正在重构宠物产业生态:
- 医疗诊断革新:通过品种特征库关联遗传疾病数据库,实现精准化预防医疗
- 繁育体系升级:建立数字化血统追溯系统,规范品种繁育标准
- 智能硬件赋能:集成于智能猫窝、喂食器等设备,提供个性化养护方案
- 动物保护增效:助力流浪猫品种识别与领养匹配,领养率提升 35%
该技术不仅推动了宠物服务的智能化转型,更通过构建"生物特征-行为数据-健康管理"的全链路数字化平台,为动物遗传学研究提供了重要数据支撑。随着联邦学习技术的应用突破,分布式猫科特征数据库的建立将加速全球猫品种识别标准的统一化进程。预计到 2025 年,智能识别模块将嵌入 90%以上宠物智能设备,成为新一代"智慧养宠"生态的核心技术组件。
猫猫人工智能分类识别项目课程实战
初始化启动并创建
进入实训平台,并启动打开进入实操界面
首先我们需要进入平台搜索并找到猫猫分类识项目收藏项目 这样我们就会在我的数据集内找到。
随后我们进入机器视觉工作室栏目 打开图像分类算法。
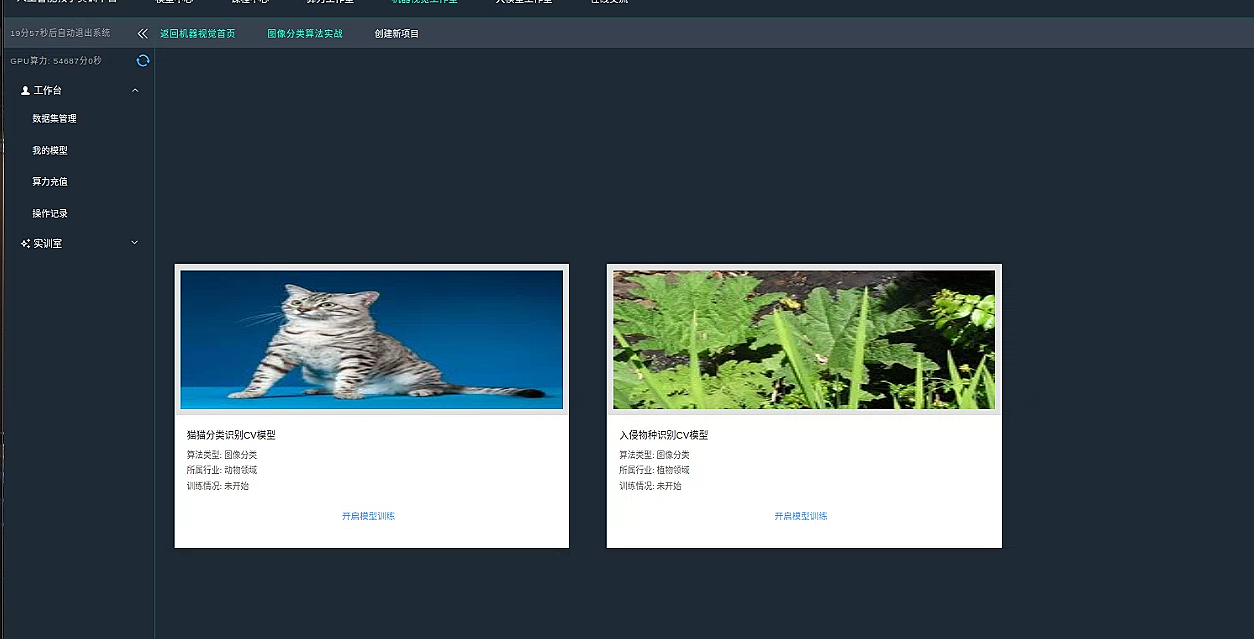
找到我们的里面猫猫分类项目,并开启训练。
并等待分配 GPU。
分配完成后请打开并等待数据转载。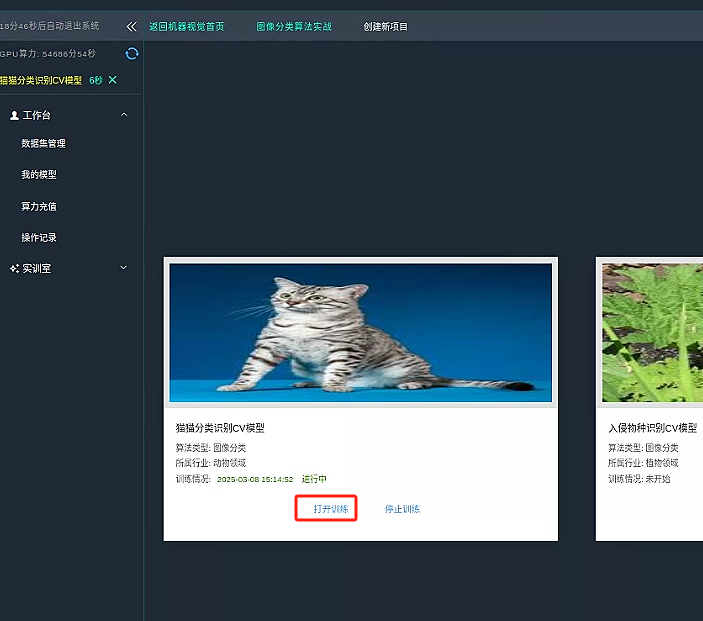
请调整 GPU 使用时间 为 50 分钟

千万注意,如果 实例内部未曾打开过任何
jupyter notebook则可能会在一段时间后判定为 空闲服务器, 或者jupyter notebook距离上次活动 时间超过 25 分钟则也会被判定为空闲服务器 (保存,运行,创建新代码块,编写代码,等操作视为活跃) 如果需要使用纯命令行 ,请启动一个jupyter notebook并编写一个无限循环等待200s注意次此操作可能会造成服务器长期运行,浪费时长产生损失,实例一旦关闭会销毁所有数据无法恢复。
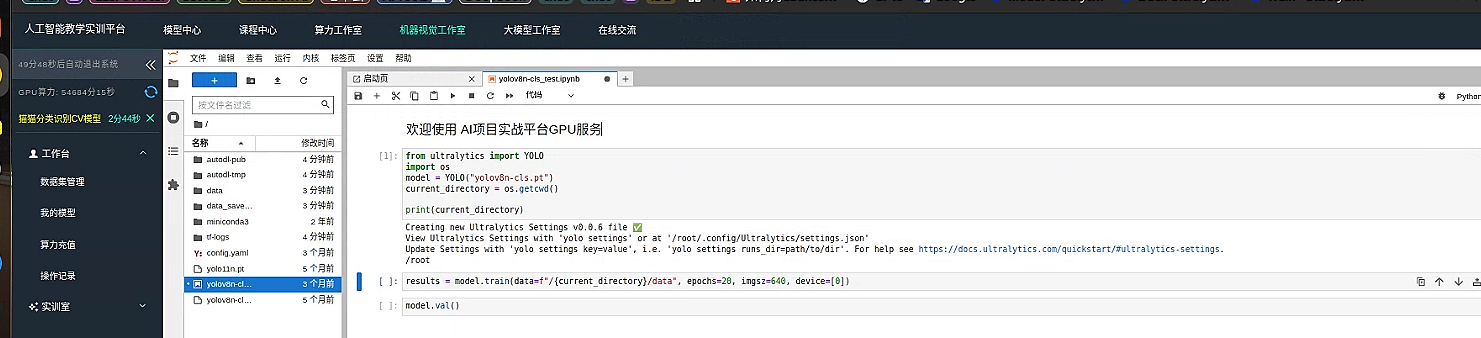
打开 示例代码运行即可测试环境。
导入所需库文件并验证环境
从现在开始 我们正式开始构建项目 从数据到训练及最后的部署
我们打开 data 文件夹 我们可以看到
有 3 个文件夹 分别是 train val 以及 test
它们分别是我们的 训练集 验证集 和测试集
再次打开我们可以看见一些子文件夹
他们分别是我们的分类类别名称 这代表着我们分类的数量以及分类的类名,我们区分 12 种猫咪和一种其他类别动物
阿比西尼亚猫 孟加拉猫 缅甸猫 孟买猫 英国短毛猫 埃及猫 缅因猫 其他 波斯布偶猫 俄罗斯蓝猫 暹罗猫 斯芬克斯猫
我们可以继续查看 打开这些图片下图是暹罗猫分类的验证集
随后我们直接使用 右侧代码启动训练并
等待训练完成
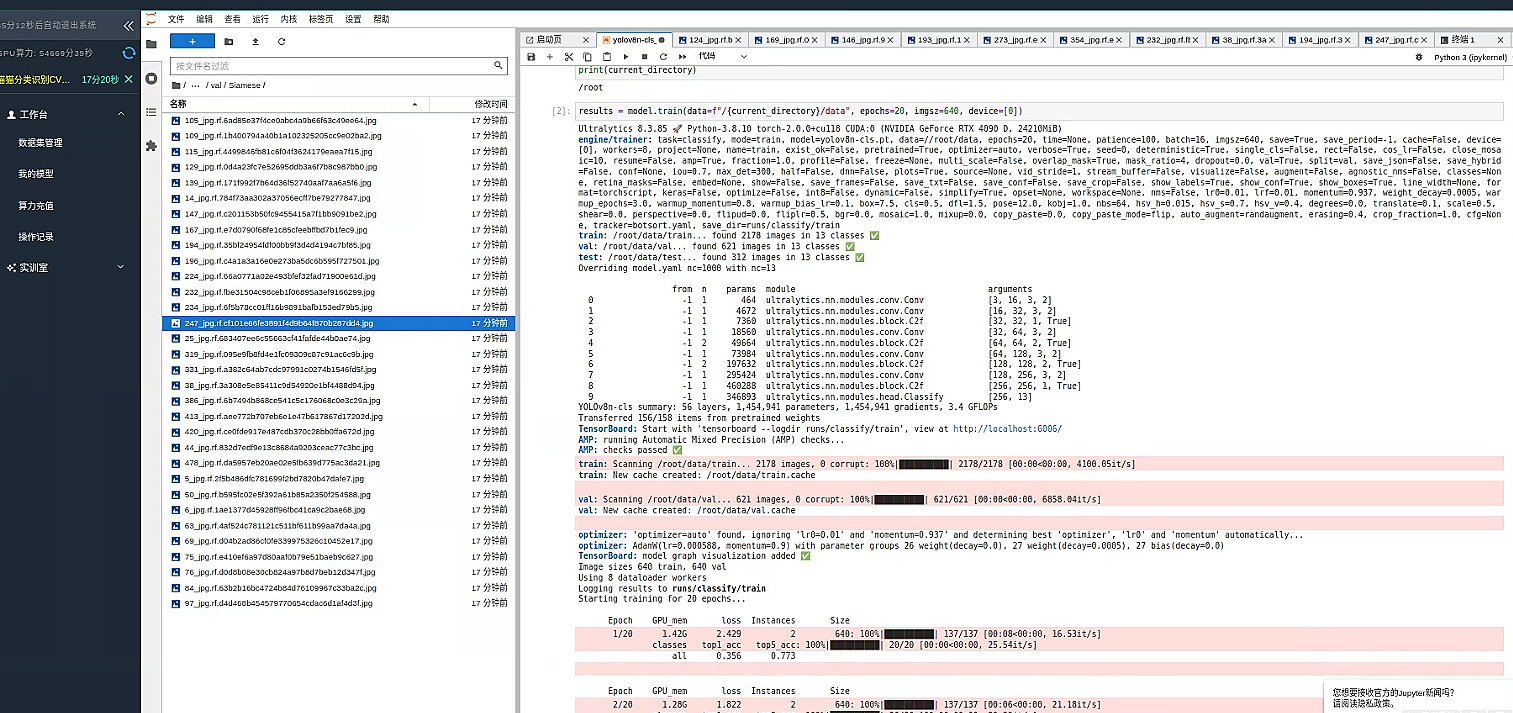
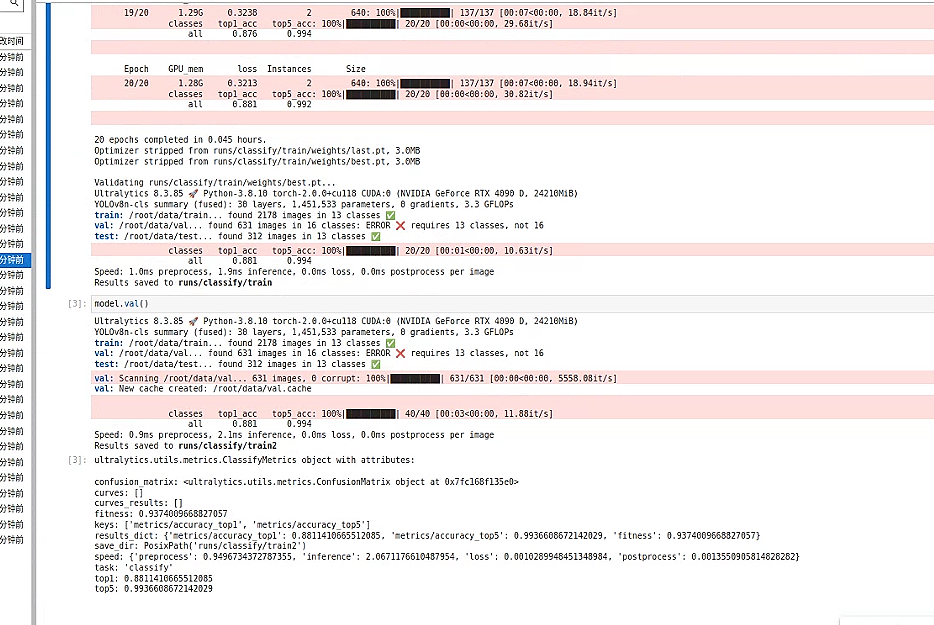
1. 检测指标分析
-
检测准确性与召回率:
模型对所有类别的检测精度为 0.817,召回率为 0.675。这说明大部分目标能够被正确检测到,但漏检问题仍存在,后续可以在数据增强或模型结构上进一步改进召回率。 -
mAP 指标:
在检测任务中,mAP50 达到 0.793,表明在宽松的 IoU 条件下模型的检测表现较为中规中矩;而 mAP50-95 仅为 0.478,说明在更严格的检测要求下效果还有较大的提升空间。
2. 分类指标与速度表现
-
分类准确率:
在验证集上,模型的 top1 准确率为 0.881,top5 准确率高达 0.994,说明在大多数情况下,模型能够将正确类别排在前列,分类性能表现优异。 -
推理速度:
- 每张图片预处理耗时约 0.9ms
- 推理时间约 2.1ms
- 后处理耗时近乎为 0ms
整体来看,极低的处理时延使得模型非常适合实时或近实时的应用场景。
推理
训练完成了 我们开始开始 部署推理应用
预测试一下模型可用性
编写一个推理程序
import os
import random
import glob
import cv2
import matplotlib.pyplot as plt
from ultralytics import YOLO
# 确保在 Notebook 中内嵌显示图像
%matplotlib inline
# 定义随机读取图片的函数
def get_random_image(root_dir):
"""
在指定的根文件夹下随机选择一个子文件夹,然后在该子文件夹中随机选取一张图片
"""
# 获取所有子文件夹
subfolders = [os.path.join(root_dir, d) for d in os.listdir(root_dir) if os.path.isdir(os.path.join(root_dir, d))]
if not subfolders:
raise ValueError("根文件夹中没有子文件夹,请检查路径!")
chosen_subfolder = random.choice(subfolders)
# 查找该子文件夹下所有图片(这里只支持常见图片格式)
image_files = glob.glob(os.path.join(chosen_subfolder, '*'))
image_files = [f for f in image_files if f.lower().endswith(('.jpg', '.jpeg', '.png', '.bmp'))]
if not image_files:
raise ValueError(f"在子文件夹 {chosen_subfolder} 中没有找到图片文件!")
chosen_image = random.choice(image_files)
return chosen_image
# 加载模型(确保 yolov8-cls.pt 文件在工作目录下或者给出正确的路径)
model = YOLO("/root/runs/classify/train/weights/best.pt")
# 设置根文件夹(请替换为你的图片文件夹路径)
root_folder = "/root/data/test" # 修改为你的文件夹路径
# 随机选取一张图片
image_path = get_random_image(root_folder)
print("选取的图片路径:", image_path)
# 读取图片(使用 cv2 读取,然后转换为 RGB 格式以便 matplotlib 显示)
img = cv2.imread(image_path)
if img is None:
raise ValueError("图片读取失败,请检查图片路径或格式!")
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 在 Jupyter 中显示图片和预测结果
plt.figure(figsize=(8, 6))
plt.imshow(img_rgb)
plt.title(f"cls: {pred_label}\n acc: {pred_conf:.2f}")
plt.axis("off")
plt.show()
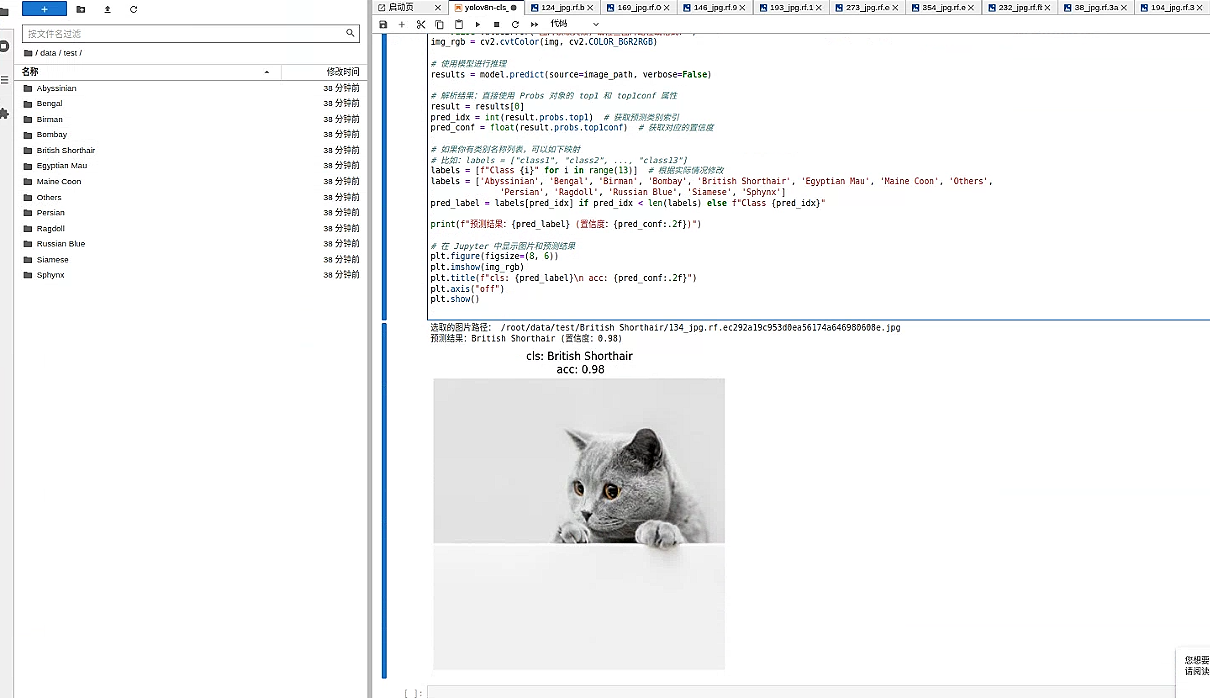
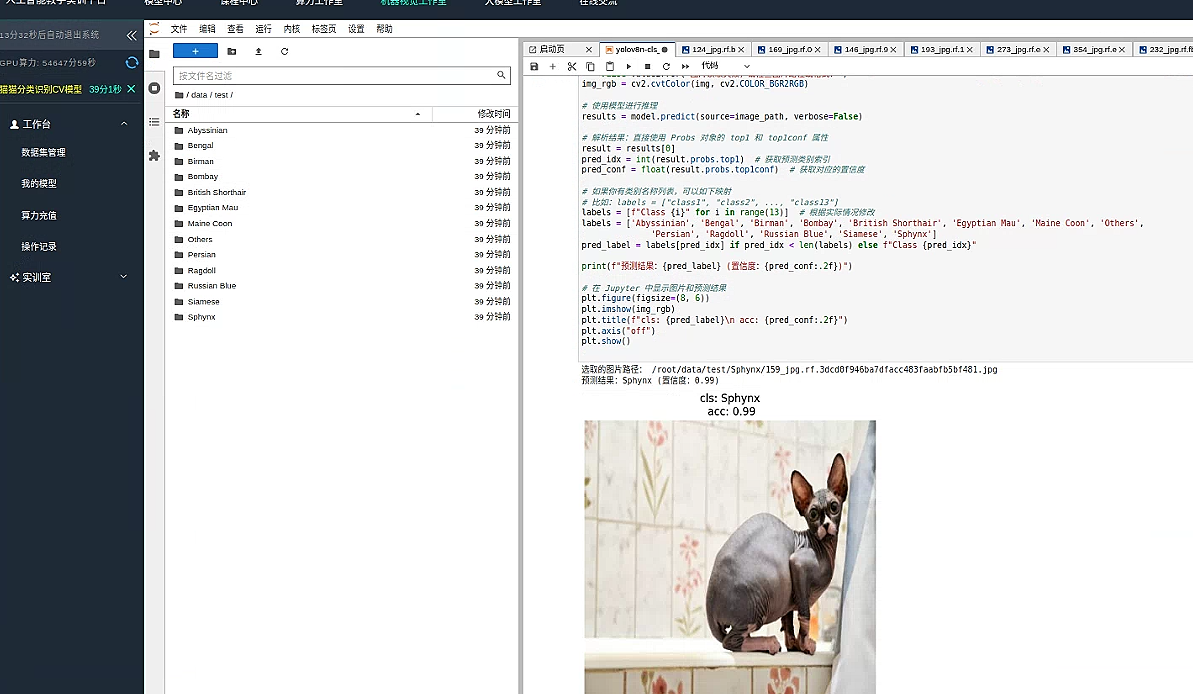
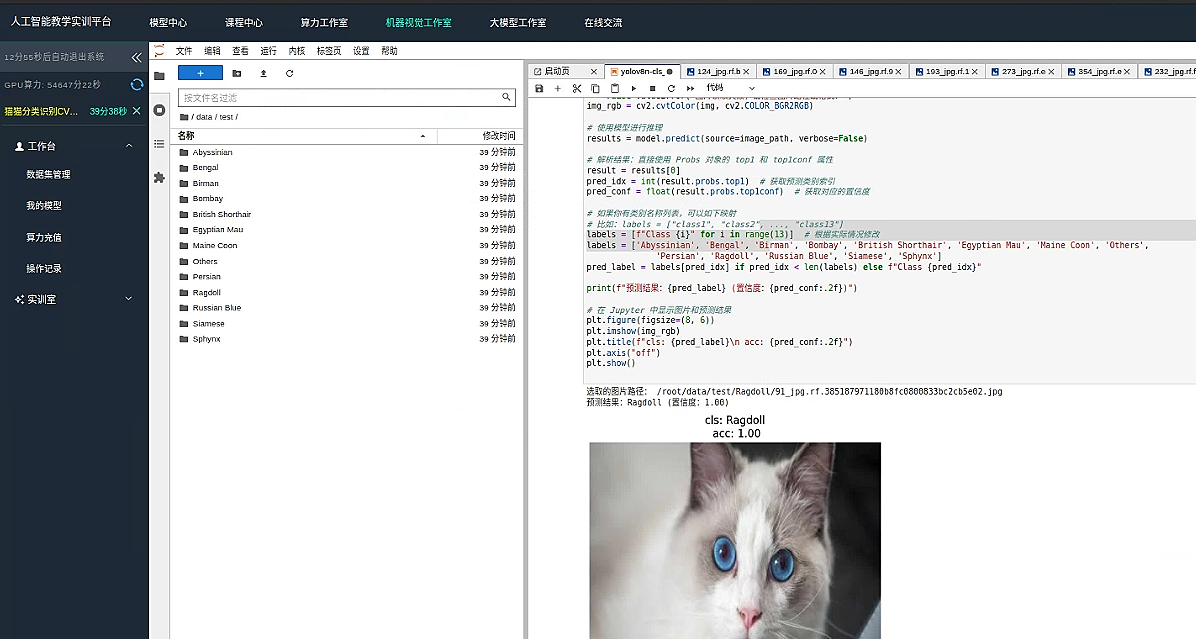
模型效果还不错 基本精确识别出了猫猫的种类
将模型保存至本地
找到 runs 文件夹 下找到刚刚训练模型 runs/classify/train/weights/best.pt

将其保存至 data_save_ai 文件夹下 或者等待 平台会将 runs 最后一次训练完成的模型数据保存至我的模型栏目 可以进入查看以及下载
或者找到该文件夹内的模型将其下载至本地即可
进入 我的模型栏目 找到刚刚训练的模型
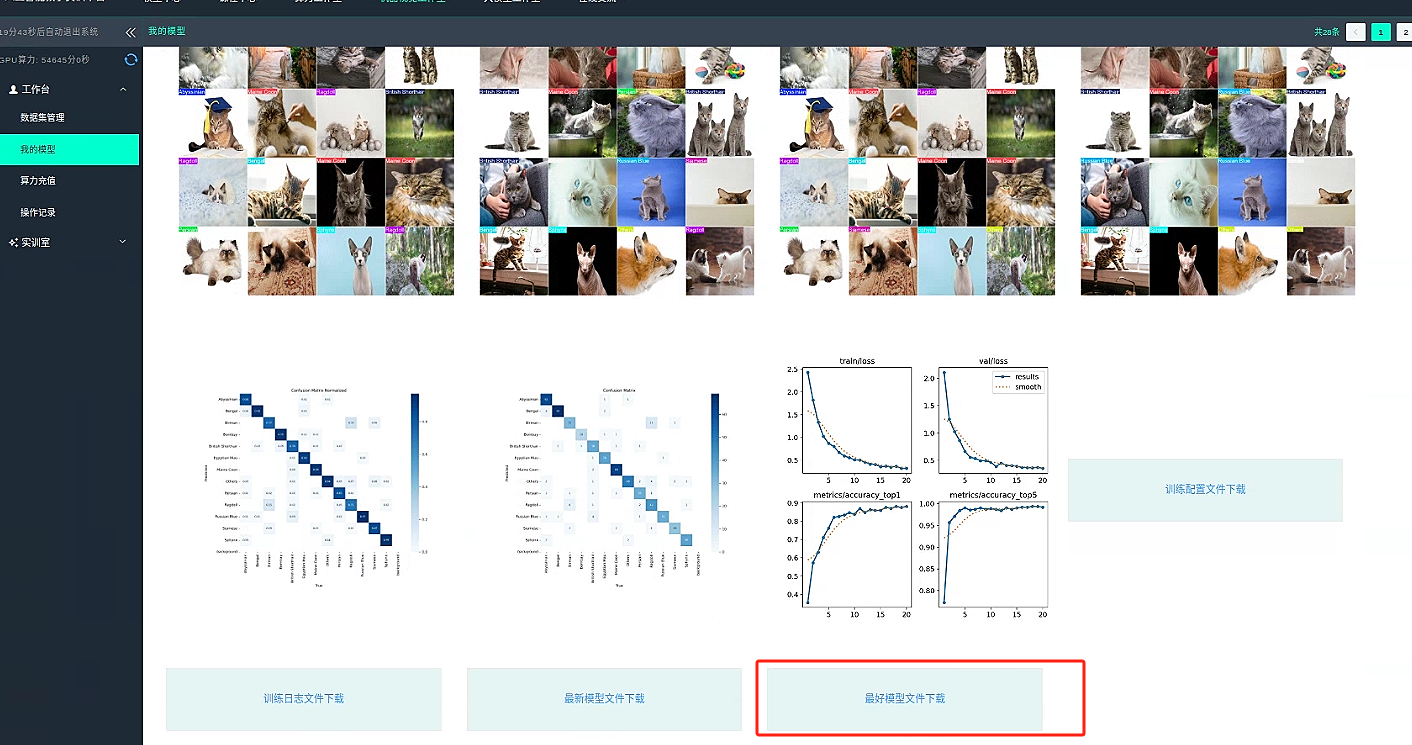
下载最好模型 best.pt 或者下载
我们现在需要 下载最好模型 点击即可下载 ,我们下载后即可得到文件
本地部署推理 api 并推理
首先我们构建一个 flask 服务器 启动推理接口
import os
import base64
from flask import Flask, request, render_template, url_for
from werkzeug.utils import secure_filename
from ultralytics import YOLO
# 创建 Flask 应用
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = 'uploads'
# 如果 uploads 文件夹不存在则创建
os.makedirs(app.config['UPLOAD_FOLDER'], exist_ok=True)
# 允许的文件扩展名
ALLOWED_EXTENSIONS = {'png', 'jpg', 'jpeg', 'bmp'}
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
# 加载 YOLO 分类模型
model = YOLO("best.pt")
@app.route('/cls_mm', methods=['GET', 'POST'])
def cls_mm():
if request.method == 'POST':
# 判断请求中是否包含文件
if 'file' not in request.files:
return render_template('index.html', error="未找到上传文件!")
file = request.files['file']
if file.filename == '':
return render_template('index.html', error="未选择文件!")
# GET 请求返回上传页面
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)
我们在编写两个简单前段网页实现推理上传和结果展示
index.html 前端上传页
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>图片上传与分类</title>
</head>
<body>
<h1>上传图片进行分类推理</h1>
{% if error %}
<p style="color:red;">{{ error }}</p>
{% endif %}
<form method="POST" enctype="multipart/form-data">
<input type="file" name="file" accept="image/*" />
</form>
</body>
</html>
result.html 前段展示页
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>推理结果</title>
</head>
<body>
<h1>推理结果</h1>
<p>预测类别:<strong>{{ pred_label }}</strong></p>
<br /><br />
<a href="{{ url_for('cls_mm') }}">返回上传页面</a>
</body>
</html>
目录结构如图所示
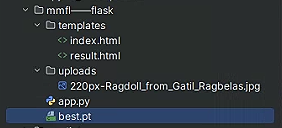
我们运行 app.py 开始测试
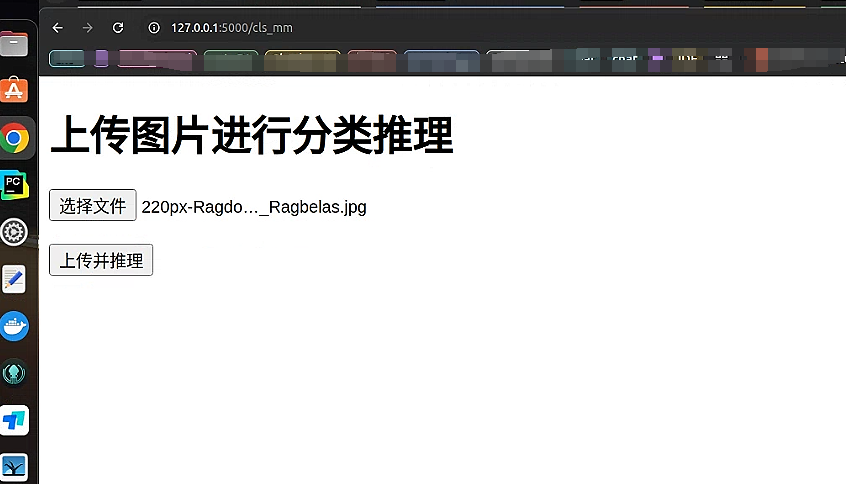
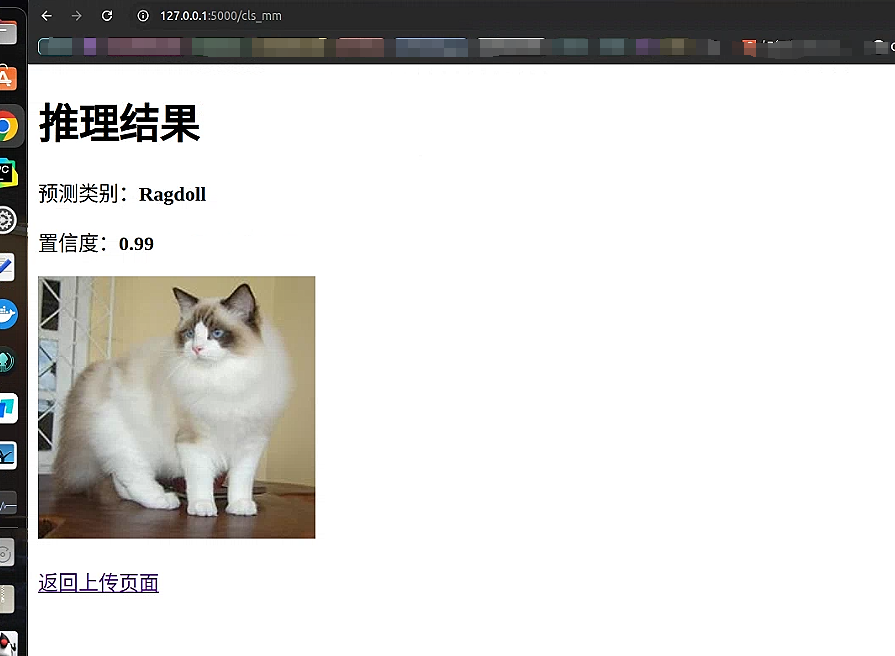
从结果来看精准的识别到了 布偶猫的结果 并且达到了 99% 的可能性
自此 猫猫分类项目结束了。
完整项目代码实战操作,请进入“人工智能教学实训平台”https://www.lswai.com 体验完整操作流程。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)