数据结构:先进排序方法之快速排序
快速排序(quick sort)是从起泡排序改进而得的一种“交换”排序方法。它的基本思想是通过一趟排序将待排记录分割成相邻的两个区域,其中一个区域中记录的关键字均比另一区域中记录的关键字小(区域内不见得有序).则可分别对这两人区域的记录进行再排序,以达到整个序列有序。
假设待排序的原始记录序列为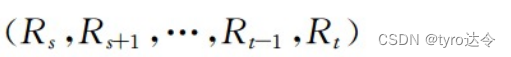
则一趟快速排序的基本操作是:任选一个记录(通常选记录 Rs),以它的关键字作为“枢轴”,凡序列中关键字小于枢轴的记录均移动至该记录之前;反之,凡序列中关键字大于枢轴的记录均移动至该记录之后。致使一趟排序之后,记录的无序序列 R[s…t]将分割成两部分:R[s…i-1]和 R[i+1…t],且使
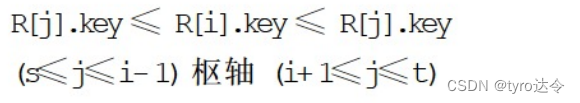
具体操作过程描述如下:假设枢轴记录的关键字为 pivotkey,附设两个指针 low 和 high,它们的初值分别为 s 和 t。首先将枢轴记录移至临时变量,之后检测指针 high 所指记录,若R[high].key>=pivotkey,则减小 high,否则将 R[high]移至指针 low 所指位置,之后检测指针 low 所指记录,若 R[low].key<=pivotkey,则增加 low,否则将 R[low]移至指针 high 所指位置,重复进行上述两个方向的检测,直至 high 和 low 两个指针指向同一位置重合为止,算法如下所示:


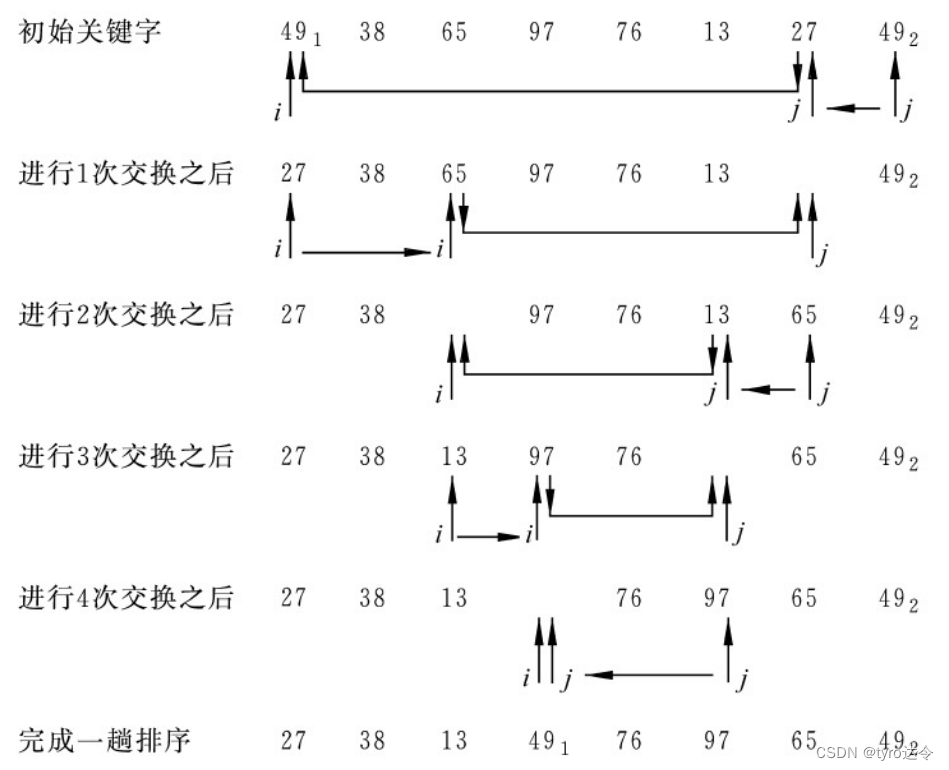
例如:将关键字序列(491,38,65,97,76,13,27,492)调整为(27,38,13,(491),76,97,65,49,)(其中(491)为枢轴记录的关键字)的过程如下图所示。
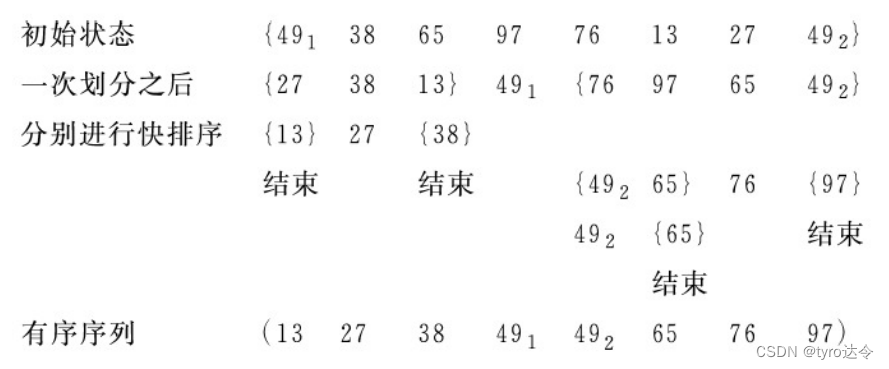
一趟快速排序的过程又称“一次划分”。对枢轴两侧的左右区域继续如法炮制,即整个快速排序的过程可递归进行。若待排的原始记录序列中只有一个记录,则显然已有序,不再需要进行排序;否则首先对该记录序列进行“一次划分”,之后分别对分割所得两个子序列“递归”进行快速排序,如下图所示:
快速排序算法如下所示:

上述算法中使用了一对参数 s 和 t 作为待排序区域的上下界。在算法的递归调用过程执行中,这两个参数随着“区域的划分”而不断变化。在对顺序表 L 进行快速排序调用算法上述时,s 和 t 的初值应分别置为 1和 L.length,算法如下所示:

快速排序在一般情况下是效率很高的排序方法。可推导证得,快速排序的平均时间复杂度为 O(nlogn)。快速排序目前被认为是同数量级(O(nlogn))中最快的内部排序方法,这是由于对区域不断“一分为二”所带来的效益,但这仅就平均性能而言。如果待排序的原始记录序列已按关键字有序或“基本有序”排列时,快速排序的时间复杂度将蜕化为 O(n2).因为在这种情况下经常会发生这样的情况。即长度为n的记录序列经一次划分后得到的两个子序列的长度分别为 0 和 n-1,也就是说未能进行“一分为二”的划分,从而失去了快速排序的优势。为避免出现“蜕化”情形,通常依“三者取中”的规则选取枢轴记录,即对R[s].key、R[t].key 和 R[(s+t)/2].key 三者进行比较,以它们中取“中值”的记录为枢轴记录。只要将它和 R[s]互换,之后仍然可按算法进行一次划分。经验证,采用三者取中规则可以大大改善快速排序在最坏情况下的性能。然而,即使如此,也不能使快速排序在待排记录序列已经有序的情况下达到和起泡排序相同的时间复杂度为 O(n) 的结果。快速排序的空间复杂度在一般情况下为 O(logn),最坏情况下为 O(n2)。
快速排序是不稳定的排序方法。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)