【数据结构 堆】超详细理解&&例题&&错题
数据结构 堆
你好,这里是新人 Sunfor
这篇是我最近对于数据结构 堆的学习心得和错题整理
有任何错误欢迎指正,欢迎交流!
会持续更新,希望对你有所帮助,我们一起学习,一起进步

前言
引言
在计算机科学中,堆(Heap)是一种高效管理动态数据的树形结构,尤其擅长快速获取极值。无论是在操作系统的任务调度、游戏中的优先级处理,还是大数据场景下的TopK问题,堆都扮演着重要的角色。本文将从基本概念到应用场景,全面解析堆的设计思想与实现技巧,并通过对比其他数据结构揭示其独特优势
一、堆的基本概念
1.1 堆的性质
堆是一种完全二叉树,满足以下性质
- 堆序性:每个节点的值与其子节点满足特定关系
- 最大堆:父节点值 >= 子节点值(堆顶为最大值)
- 最小堆:父节点值 <= 子节点值(堆顶为最小值)
- 完全二叉树性质:除最后一层外,其他层节点全满,且最后一层节点从左到右填充
1.2 堆的表示
数组表示
堆通常可以通过数组实现,利用完全二叉树的性质快速定位父子节点
优点:
- 节省存储空间(不需要存储指针)
- 直接计算父节点和字节点索引(避免递归或额外查找操作)
- 构建和操作更方便(可以高效地进行堆调整)
代码演示
#include<stdio.h>
#include<stdlib.h>
#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE];
int size;
}Heap;
父子索引关系
父节点索引 i --> 左子节点 2i+1 右子节点 2i+2
子节点索引 i --> 父节点 (i-1)/2
二、堆的实现方式
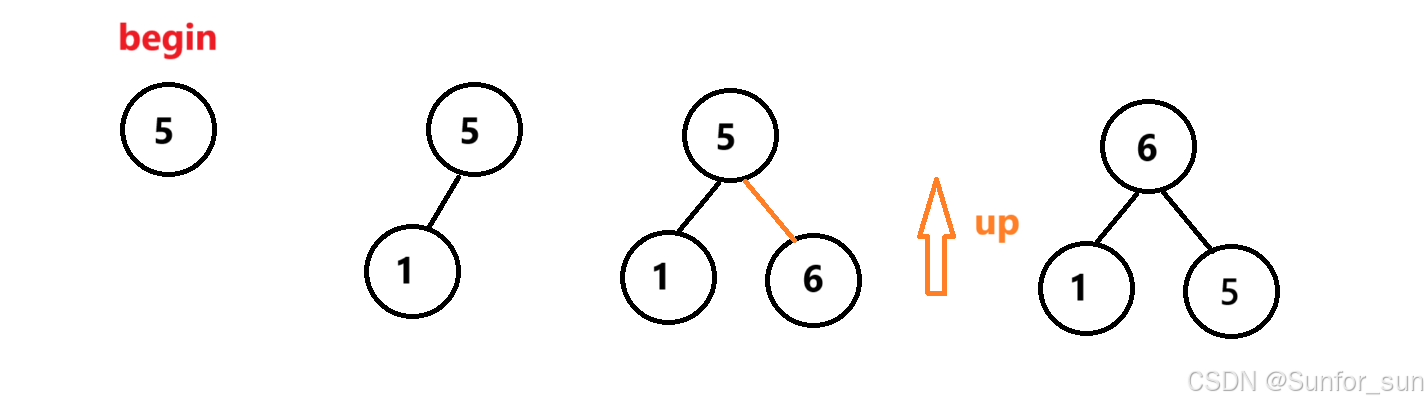
2.1 自顶向下
void swap(int* a, int* b)
{
int* tmp = *a;
*a = *b;
*b = tmp;
}
//自底向上调整
void heapify_up(int heap[], int index)
{
int parent = (index - 1) / 2;
while (index > 0 && heap[index] > heap[parent])
{
swap(&heap[index], &heap[parent]);
index = parent;
parent = (index - 1) / 2;
}
}
//自顶向下建堆
void build_heap_top_down(int heap[], int n)
{
for (int i = 1; i < n; i++)
{
heapify_up(heap, i);
}
}
图像演示
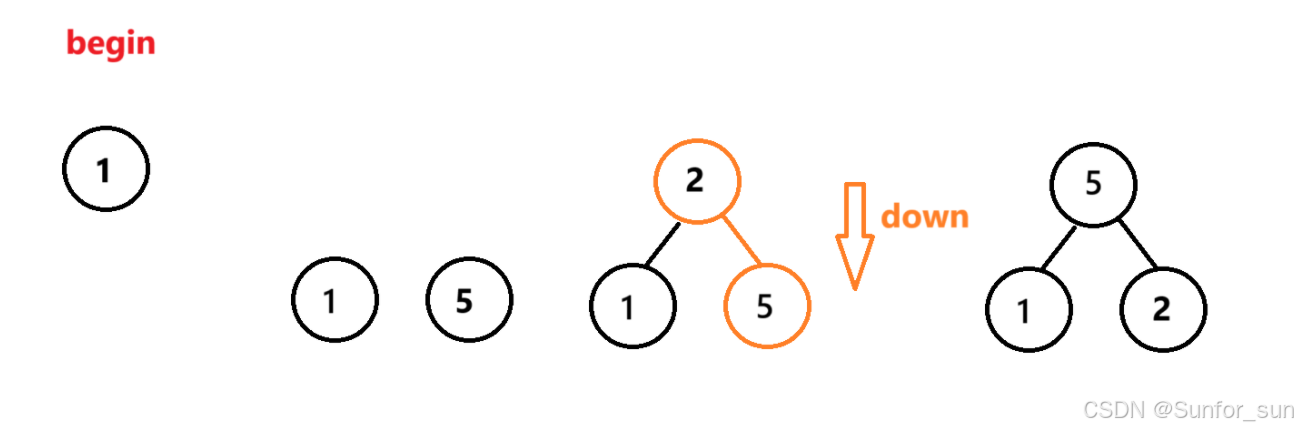
2.2 自底向上
//自顶向下堆化
void heapify_down(int heap[], int i, int n)
{
int largest = i;
int right = 2 * i + 1;
int left = 2 * i + 2;
if (left < n && heap[left] > heap[largest])
{
largest = left;
}
if (right < n && heap[right] > heap[largest])
{
largest = right;
}
if (largest != i)
{
swap(&heap[i], &heap[largest]);
heapify_down(heap, largest, n);
}
}
//自底向上建堆
void build_heap_down_up(int heap[], int n)
{
for (int i = n / 2 - 1; i >= 0; i--)
{
heapify_down(heap,i, n);
}
}
图像演示
三、堆的应用场景
3.1 优化队列
为什么用堆来优化队列?
普通队列只能按照入队顺序出队,无法做到优先级出队,而堆实现的队列可以做到一下优点
- 插入元素(使用向上调整)时间复杂度O(log N)
- 获取最大/小元素(直接返回堆顶)时间复杂度O(1)
- 删除最大/小元素(删除堆顶后向下调整) 时间复杂度O(log N)
代码演示
#include<stdio.h>
#define MAX_SIZE 100
typedef struct
{
int data[MAX_SIZE];
int size;
}PrioritQueue;
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void heapify_up(PrioritQueue* pq, int index)
{
while (index > 0)
{
int parent = (index - 1) / 2;
if (pq->data[parent] >= pq->data[index])
break;
swap(&pq->data[parent], &pq->data[index]);
index = parent;
}
}
void heapify_down(PrioritQueue *pq,int index)
{
int left, right,largest;
while (index * 2 + 1 < pq->size)
{
left = 2 * index + 1;
right = 2 * index + 2;
largest = index;
if (left < pq->size && pq->data[left] > pq->data[largest])
{
largest = left;
}
if (right < pq->size && pq->data[right] > pq->data[largest])
{
largest = right;
}
if (largest == index)
{
break;
}
swap(&pq->data[index], &pq->data[largest]);
index = largest;
}
}
//插入元素
void push(PrioritQueue* pq, int value)
{
if (pq->size >= MAX_SIZE)
{
printf("队列已满,无法插入!\n");
return;
}
pq->data[pq->size] = value;
heapify_up(pq, pq->size);
pq->size++;
}
//获取栈顶元素
int top(PrioritQueue* pq)
{
if (pq->size == 0)
{
printf("队列为空!\n");
return -1;
}
return pq->data[0];
}
//删除堆顶元素
void pop(PrioritQueue* pq)
{
if (pq->size == 0)
{
printf("队列为空!\n");
return;
}
pq->data[0] = pq->data[pq->size - 1];
pq->size--;
heapify_down(pq, 0);
}
void print_heap(PrioritQueue* pq) {
printf("当前优先队列: ");
for (int i = 0; i < pq->size; i++) {
printf("%d ", pq->data[i]);
}
printf("\n");
}
// 测试代码
int main() {
PrioritQueue pq = { .size = 0 };
push(&pq, 5);
push(&pq, 10);
push(&pq, 3);
push(&pq, 8);
push(&pq, 7);
print_heap(&pq);
printf("堆顶元素: %d\n", top(&pq));
pop(&pq);
print_heap(&pq);
return 0;
}
3.2 堆的排序
堆排序我们在之前的例子中就在不断运用,接下来我们一起通过一道题体现一下
void CreateNDate()
{
// 造数据
int n = 10000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (size_t i = 0; i < n; ++i)
{
int x = rand() % 1000000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
//利用堆排序在文件中找TopK
void PrintTopK(int k);
思路:
读取前K个元素建堆:首先从文件中读取前K个元素,建立一个最小堆。堆顶是这K个元素中的最小值。
处理剩余元素:继续读取文件中的剩余元素,对于每个元素,如果它大于堆顶元素,则替换堆顶,并调整堆结构以维持最小堆的性质。
排序并输出结果:最后,将堆中的K个元素进行降序排序,输出结果
具体解决代码
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void swap(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 调整最小堆
void adjustHeap(int* heap, int i, int size) {
int smallest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < size && heap[left] < heap[smallest]) {
smallest = left;
}
if (right < size && heap[right] < heap[smallest]) {
smallest = right;
}
if (smallest != i) {
swap(&heap[i], &heap[smallest]);
adjustHeap(heap, smallest, size);
}
}
// 用于qsort的比较函数,降序排列
int compare(const void* a, const void* b) {
return (*(int*)b - *(int*)a);
}
void PrintTopK(int k) {
FILE* fp = fopen("data.txt", "r");
if (fp == NULL) {
perror("fopen error");
return;
}
int* heap = (int*)malloc(k * sizeof(int));
if (heap == NULL) {
perror("malloc error");
fclose(fp);
return;
}
// 读取前k个数
int count = 0;
while (count < k && fscanf(fp, "%d", &heap[count]) == 1) {
count++;
}
// 如果文件中的数不足k个,调整k的值
if (count < k) {
k = count;
if (k == 0) {
free(heap);
fclose(fp);
return;
}
}
// 建立最小堆
for (int i = k / 2 - 1; i >= 0; --i) {
adjustHeap(heap, i, k);
}
// 处理剩余元素
int num;
while (fscanf(fp, "%d", &num) == 1) {
if (num > heap[0]) {
heap[0] = num;
adjustHeap(heap, 0, k);
}
}
// 对堆中的元素进行降序排序
qsort(heap, k, sizeof(int), compare);
// 输出结果
for (int i = 0; i < k; ++i) {
printf("%d ", heap[i]);
}
printf("\n");
free(heap);
fclose(fp);
}
// 测试代码
int main() {
// 生成数据
CreateNDate();
// 打印Top 10
PrintTopK(10);
return 0;
}
四、堆与其他数据结构的对比
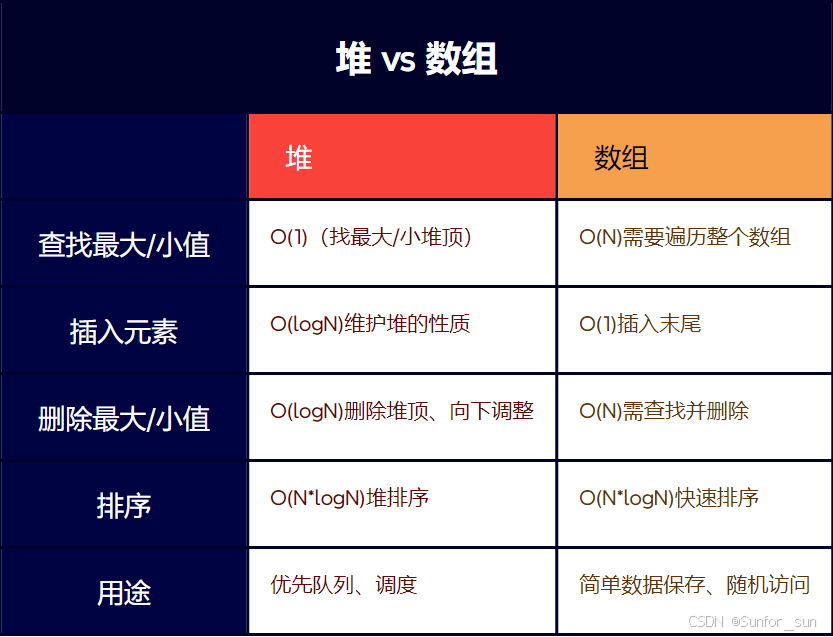
4.1 堆vs数组
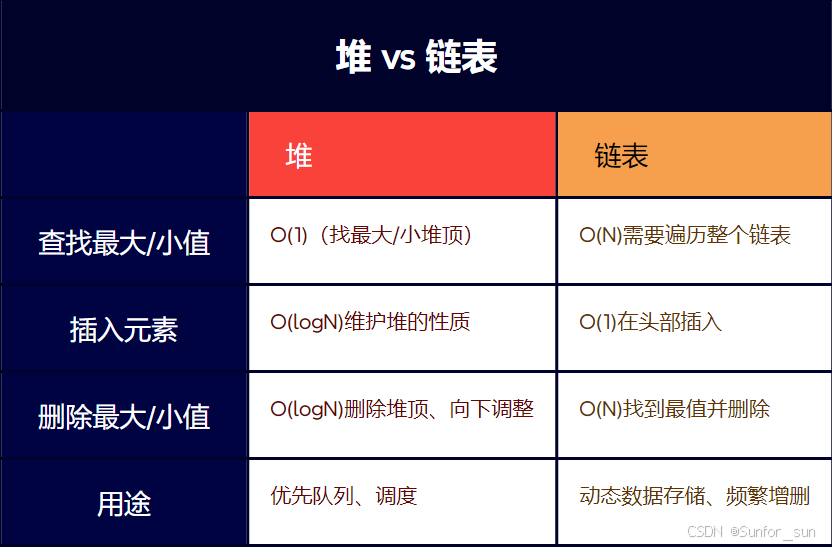
4.2 堆 vs 链表
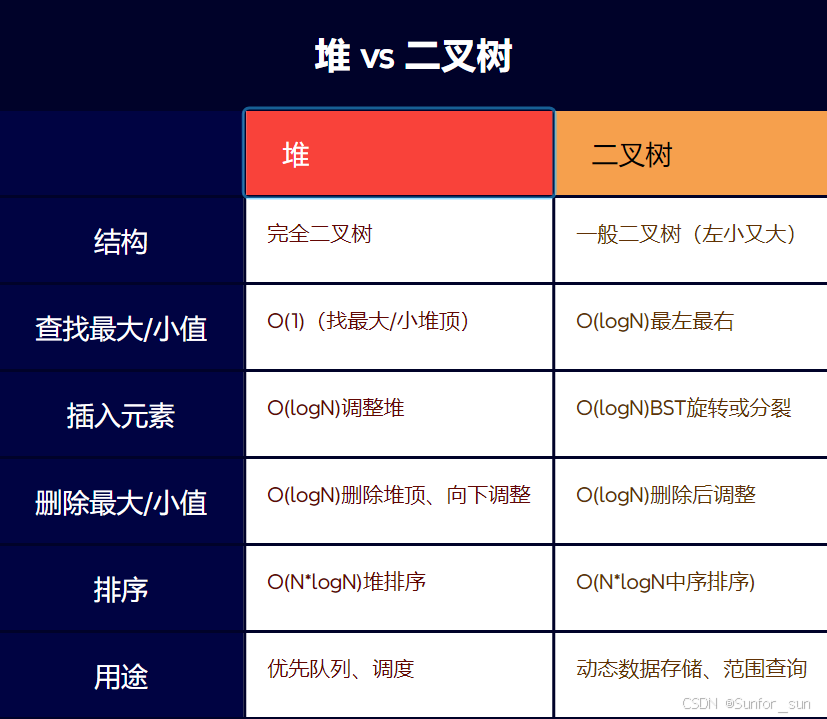
4.3 堆 vs 二叉树
小结
堆凭借其 极值访问O(1)和动态调整O(log n) 的特性,在数据处理中占据独特地位。无论是排序、压缩,还是实时调度,堆都能以优雅的方式解决问题。理解堆的底层逻辑后,你甚至可以定制自己的堆结构(如支持动态权值的堆),以应对更复杂的场景。
后面还会陆续更新数据结构和C++学习的内容及心得,可以持续关注~

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 60
60 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)