带你从入门到精通——Python数据处理(四. Pandas入门)
Python在数据处理上独步天下,有着代码灵活、开发快速的优势,尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势。Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据1. 底层是基于NumPy构建的,因此运行速度特别的快。2. 有专门的处理缺失数据的API。3. 强大而灵活的分组、聚合、转换功能1. 数据量大到Excel严重卡
建议先阅读我之前的Python数据处理以及Python专栏中的博客,掌握一定的Python前置知识后再阅读本文,链接如下:
带你从入门到精通——Python数据处理(一. 环境介绍与NumPy入门)-CSDN博客
带你从入门到精通——Python数据处理(二. NumPy中数组的基本操作)-CSDN博客
带你从入门到精通——Python数据处理(三. NumPy中数组的运算)-CSDN博客
目录
四. Pandas入门
4.1 Pandas简介
Python在数据处理上独步天下,有着代码灵活、开发快速的优势,尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势。
Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析,其在数据处理方面的优势如下:
1. 底层是基于NumPy构建的,因此运行速度特别的快。
2. 有专门的处理缺失数据的API。
3. 强大而灵活的分组、聚合、转换功能
Pandas的适用场景如下:
1. 数据量大到Excel严重卡顿,且又都是单机数据的时候使用Pandas。
2. 在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用Pandas。
4.2 Pandas的数据结构
4.2.1 Series对象
4.2.1.1 Series对象的定义
Series是Pandas中的最基本的数据结构对象,它是一种类似于一维数组的对象,由下面两个部分组成:

其中values表示一组数据(numpy.ndarray类型),而index表示相关的数据索引标签,如果没有为数据指定索引,则会自动创建一个0到N-1(N为数据的长度)的整数型索引。
注意:可以使用set()、list()、tuple()等强制转换函数将Series对象中的元素转换为对应类型的数据。
4.2.1.2 Series对象的创建
Series对象可以通过传入一个元组、列表或者数组来创建,示例如下:
import pandas as pd
# 使用列表创建Series对象并使用默认自增索引
s1 = pd.Series([1, 2, 3])
print(s1)
# 使用元组创建Series对象并自定义索引值
s2 = pd.Series((1, 2, 3), ['A', 'B', 'C'])
print(s2)
# 使用数组创建Series对象并自定义索引值
s3 = pd.Series(np.arange(3), index=['a', 'b', 'c'])
print(s3)输出如下:



注意,我们可以使用index参数自定义索引。
此外,还可以使用字典创建Series对象,默认以键为索引值,以值为数据,示例和输出结果如下:
dirs = {'A':1,'B':2,'C':3,'D':4,'E':5,'F':6}
print(pd.Series(dirs))
4.2.1.3 Series对象的属性
Series对象的属性主要有index、name、shape以及values:
index用于获取Series对象的索引列。
name用于获取Series对象的数据列的列名。
values用于获取Series对象的数据列。
shape用于获取Series对象的形状,返回值被封装在一个元组中。
Series对象还支持使用正负两套索引下标来完成索引和切片操作,索引和切片的具体细节可以看我之前的博客,此外,Series对象还能够通过索引值进行索引和切片操作,注意:使用索引值进行切片时是包含结束位置的。
4.2.2 DataFrame对象
4.2.2.1 DataFrame对象的定义
DataFrame对象是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引,其中行索引表示不同的行,也称横向索引、index、第0轴;列索引表示不同列,也称纵向索引、columns、第1轴。一个DataFrame对象可以视为由多个Series对象构成,因此,Series对象是DataFrame对象的列对象。
DataFrame对象的结构如下所示:
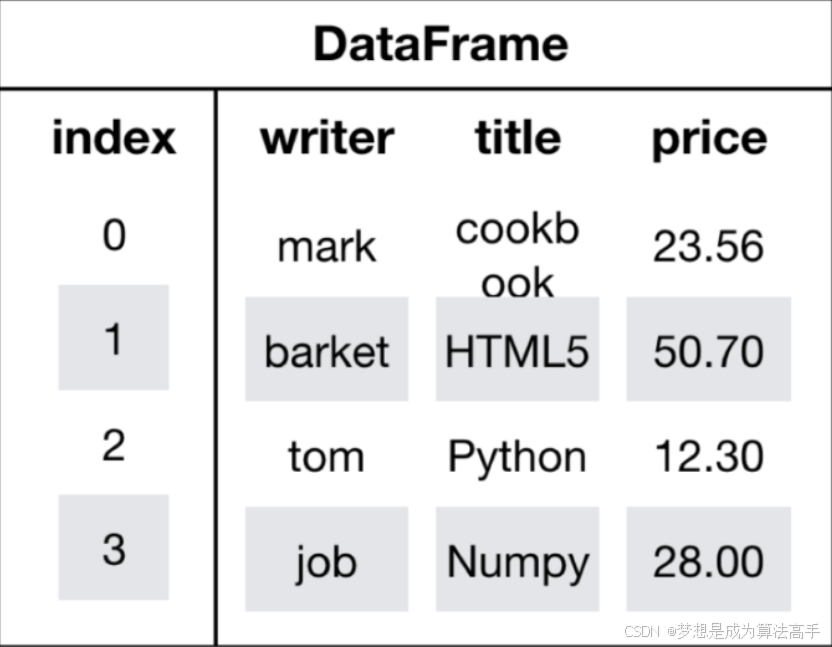
注意:可以使用set()、list()、tuple()等强制转换函数将DataFrame对象中的Series对象转换为对应类型的数据。
4.2.2.2 DataFrame对象的创建
DataFrame对象的创建也有多种方式,第一种方式是使用字典嵌套列表/元组的形式创建DataFrame对象,示例如下:
df1_data = {
'日期': ['2021-08-21', '2021-08-22', '2021-08-23'],
'温度': [25, 26, 50],
'湿度': [81, 50, 56]
}
df1 = pd.DataFrame(data=df1_data)
df1如果使用这种方式创建DataFrame对象,默认将键作为DataFrame对象的列名,值作为每列中的数据,最终输出结果如下:
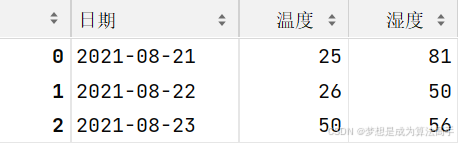
第二种方式是使用列表/元组加列表/元组创建DataFrame对象,示例如下:
df2_data = [
('2021-08-21', 25, 81),
('2021-08-22', 26, 50),
('2021-08-23', 27, 56)
]
df2 = pd.DataFrame(
data=df2_data,
columns=['日期', '温度', '湿度'],
index = ['row_1','row_2','row_3'] # 手动指定索引
)
df2如果使用这种方式创建DataFrame对象,默认将列表/元组中的每个元素作为一行数据,此外,我们可以使用columns参数来指定列名,使用index参数来指定索引值。
输出结果如下:
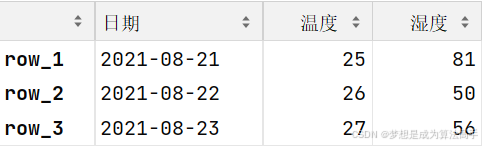
第三种方式是使用二维数组来创建DataFrame对象,示例和输出结果如下:
arr = np.random.randint(40, 100, (3, 4))
df3 = pd.DataFrame(arr)
df3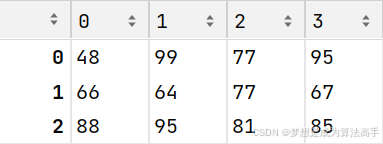
如果使用这种方式创建DataFrame对象,默认将二维数组中的各个元素按位置一一对应到DataFrame对象的各个行列中。
4.2.2.3 DataFrame对象的常用属性
DataFrame对象的常用属性主要有index、columns、shape、values以及T:
index用于获取DataFrame对象的索引列。
columns用于获取DataFrame对象的各个数据列的列名。
values用于获取DataFrame对象的各个数据列。
shape用于获取DataFrame对象的形状,返回值被封装在一个元组中。
T属性用于获取DataFrame对象转置后的新DataFrame对象。
4.2.2.4 DataFrame对象的常用方法
DataFrame对象的head(n)方法,用于显示前n行内容,如果不传入n参数则默认显示前5行。
DataFrame对象的tail(n)方法,用于显示后n行内容,如果不传入n参数则默认显示后5行。
DataFrame对象的reset_index(drop)方法,用于重设索引(即将索引设置为0-n的默认索引,n为DataFrame对象的行数),如果传入drop=True,则会丢弃原索引列,如果传入drop=Fasle,则不会丢弃原索引列,会将原索引列作为一个新列加入到DataFrame对象中,且列名为'index',drop参数的默认值为False。
DataFrame对象的set_index(keys,drop)方法,会将keys中的列设置为新的索引列,参数keys为列索引名或者由列索引名构成的列表,该方法会将keys中的列作为新的索引列(支持复合索引),drop表示是否丢弃keys中的列,默认为True,如果传入drop=Fasle,则不会丢弃keys中的列,会将keys中的列保留在DataFrame对象中。
注意:修改索引还可以直接通过df.index获取索引属性后直接使用=号赋值的方法完成,可以直接使用列表、元组或者数组完成赋值,该方式必须整体修改整个索引,不能单独修改某一行的索引值。
4.2.3 Series对象转DataFrame对象
可以使用to_frame(name)方法将Series对象转DataFrame对象,参数name用于指定转换后的DataFrame对象的列名,如果不指定则默认使用原Series对象的name属性名,具体使用方式和输出结果如下:
import pandas as pd
s = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'], name='values')
df = s.to_frame(name='val')
df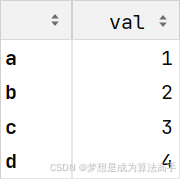
4.3 Pandas中元素的数据类型
4.3.1 数据类型简介
Pandas中元素的数据类型与Python中的数据类型不尽相同,但大部分都有相对应的类型,具体对应关系如下:
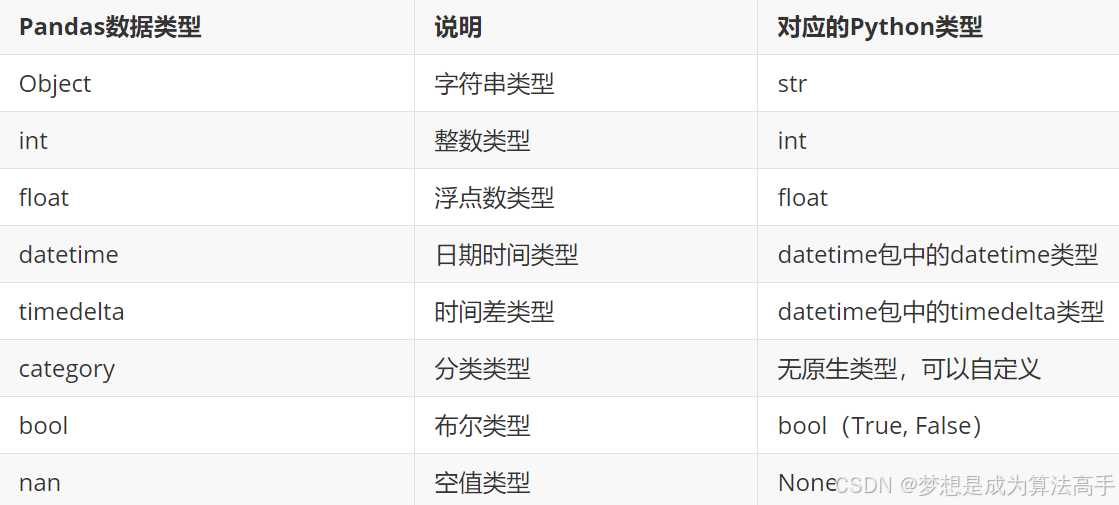
Pandas中元素的数据类型可以使用s对象或者df对象的dtypes属性,或者info()方法查看,具体示例如下:
import pandas as pd
df = pd.DataFrame({'等级':['A', 'B', 'C'], '姓名':['张三', '李四', '王五']})
print(df.info())
'''
输出结果如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 等级 3 non-null object
1 姓名 3 non-null object
dtypes: object(2)
memory usage: 180.0+ bytes
'''
print(df.dtypes)
'''
输出结果如下:
等级,object
姓名,object
'''
4.3.2 特殊数据类型创建示例
datetime类型的元素创建示例如下:
# 创建一组datetime类型的元素,可以使用该组元素创建df对象或者s对象
datas = pd.to_datetime(['2024-09-01', '2023-10-01'])
print(type(datas)) # 输出 <class 'pandas.core.indexes.datetimes.DatetimeIndex'>
df = pd.DataFrame(datas)
print(df)
'''
输出结果如下:
0,2024-09-01
1,2023-10-01
'''
print(df.dtypes) # 输出 datetime64[ns]timedelta类型的元素创建示例如下:
import pandas as pd
start_date = pd.to_datetime('2024-09-01') # 该方法创建的是一个时间戳类型的数据
print(start_date)
print(type(start_date))
'''
2024-09-01 00:00:00
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
'''
end_date = pd.to_datetime('2024-10-05')
delta = end_date - start_date
print(delta)
print(type(delta))
'''
输出结果如下:
34 days 00:00:00
<class 'pandas._libs.tslibs.timedeltas.Timedelta'>
'''category类型是一种特殊的dtype,用于表示分类数据,它特别适合处理具有有限数量的唯一值(类别)的数据列,如性别、颜色、国家等,使用 category 类型的主要优势如下:
节省内存:对于具有大量重复值的列,category 类型可以显著减少内存占用。
提高性能:在排序、分组等操作中,category 类型通常比字符串类型更快。
category类型的元素创建示例如下:
import pandas as pd
# 创建一个category类型的Series
categories = pd.Series(['apple', 'banana', 'apple', 'orange'], dtype='category')
print(categories)
'''
输出结果如下:
0 apple
1 banana
2 apple
3 orange
dtype: category
Categories (3, object): ['apple', 'banana', 'orange']
'''
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 35
35 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)