文本生成指标评估--下游准确度,相似度(余弦), 翻译质量(BLEU,ROUGE、ROUGE-N,-L, -W,-S,-SU)/ 多样性(self-bleu,MMD,distinct)
余弦相似度::::忠实度(即生成的数据样本是否接近原始样本)TransRate::::紧凑度(即每个类的样本是否足够紧凑以进行良好区分)生成的样本与label的紧凑度Z为生成的文本embedding, Y 为label"
1 下游任务上的准确度
2 生成样本与label的相似度[余弦,transrate]
余弦相似度::::忠实度(即生成的数据样本是否接近原始样本)
AugGPT: Leveraging ChatGPT for Text Data Augmentation
TransRate::::紧凑度(即每个类的样本是否足够紧凑以进行良好区分)生成的样本与label的紧凑度
TransRate = H(Z) - H(Z|Y)
Z为生成的文本embedding, Y 为label"
AugGPT: Leveraging ChatGPT for Text Data Augmentation
3 翻译质量[transrate]
在机器翻译任务中,BLEU 和 ROUGE 是两个常用的评价指标,
BLEU 根据精确率(Precision)衡量翻译的质量,
而 ROUGE 根据召回率(Recall)衡量翻译的质量
缺点是这种方法只能在单词、短语的角度去衡量两个句子的形似度。并不能支持同义词、近义词等语意级别去衡量。比如:
3.1 BLEU
BLEU(Bilingual Evaluation Understudy): BLEU是一种用于评估机器翻译结果质量的指标。它主要侧重于衡量机器翻译输出与参考翻译之间的相似程度,着重于句子的准确性和精确匹配。
BLEU通过计算N-gram(连续N个词)的匹配程度,来评估机器翻译的精确率(Precision)。
3.1.1 计算公式,短文本惩罚,精确度计算
BLEU 的全称是 Bilingual evaluation understudy,BLEU 的分数取值范围是 0~1,分数越接近1,说明翻译的质量越高。
BLEU 需要计算译文 1-gram,2-gram,…,N-gram 的精确率,一般 N 设置为 4 即可,公式中的 Pn 指 n-gram 的精确率。
Wn 指 n-gram 的权重,一般设为均匀权重,即对于任意 n 都有 Wn = 1/N。
BP 是惩罚因子,如果译文的长度小于最短的参考译文,则 BP 小于 1。
BLEU 的 1-gram 精确率表示译文忠于原文的程度,而其他 n-gram 表示翻译的流畅程度。

假设机器翻译的译文C和一个参考翻译S1如下:
C: a cat is on the table
S1: there is a cat on the table
- 直接这样子计算 Precision 会存在一些问题,例如:
C: there there there there there
S1: there is a cat on the table
这时候机器翻译的结果明显是不正确的,但是其 1-gram 的 Precision 为1,因此 BLEU 一般会使用修正的方法。给定参考译文S1,S2, …,Sm,可以计算C里面 n 元组的 Precision,计算公式如下:

3.1.2 BLEU指标计算过程:
- a. 首先,我们将参考翻译和系统生成的翻译拆分成n-gram序列。n-gram是连续n个词的组合。
参考翻译的1-gram:[“今天”, “天气”, “晴朗”, “。”]
系统生成的翻译的1-gram:[“今天”, “的”, “天气”, “是”, “晴朗”, “的”, “。”]- b. 接下来,我们计算系统生成的翻译中n-gram与参考翻译中n-gram的匹配数。例如,1-gram中有4个匹配:[“今天”, “天气”, “晴朗” "。”]
- c. 计算BLEU的精确度(precision):将系统生成的翻译中的匹配数除以系统生成的翻译的总n-gram数。在这里,精确度为4/7。
- d. 由于较长的翻译可能具有较高的n-gram匹配,我们使用短文本惩罚(brevity penalty)来调整精确度。短文本惩罚可以防止短翻译在BLEU中得分过高。
- e. 最后,计算BLEU得分:BLEU = 短文本惩罚 * exp(1/n * (log(p1) + log(p2) + … + log(pn)))
其中,p1, p2, …, pn是1-gram, 2-gram, …, n-gram的精确度,n是n-gram的最大长度。
3.2 ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation): ROUGE是一种用于评估文本摘要(或其他自然语言处理任务)质量的指标。与BLEU不同,ROUGE主要关注机器生成的摘要中是否捕捉到了参考摘要的信息,着重于涵盖参考摘要的内容和信息的完整性。ROUGE通过计算N-gram的共现情况,来评估机器生成的摘要的召回率(Recall)。
3.2.1 ROUGE_N 计算
ROUGE-N 主要统计 N-gram 上的召回率,对于 N-gram,可以计算得到 ROUGE-N 分数,计算公式如下
公式的分母是统计在参考译文中 N-gram 的个数,而分子是统计参考译文与机器译文共有的 N-gram 个数。
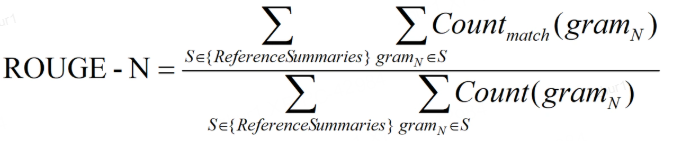
3.2.2 多个参考译文时
如果给定多个参考译文 Si,Chin-Yew Lin 也给出了一种计算方法,假设有 M 个译文 S1, …, SM。ROUGE-N 会分别计算机器译文和这些参考译文的 ROUGE-N 分数,并取其最大值,公式如下。这个方法也可以用于 ROUGE-L,ROUGE-W 和 ROUGE-S。
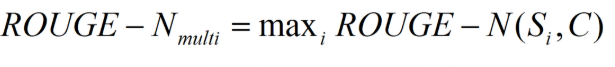
3.2.3 ROUGE-L最长公共子序列
ROUGE-L 中的 L 指最长公共子序列 (longest common subsequence, LCS),ROUGE-L 计算的时候使用了机器译文C和参考译文S的最长公共子序列,计算公式如下:
公式中的 RLCS 表示召回率,而 PLCS 表示精确率,FLCS 就是 ROUGE-L。一般 beta 会设置为很大的数,因此 FLCS 几乎只考虑了 RLCS (即召回率)。注意这里 beta 大,则 F 会更加关注 R,而不是 P,可以看下面的公式。如果 beta 很大,则 PLCS 那一项可以忽略不计。
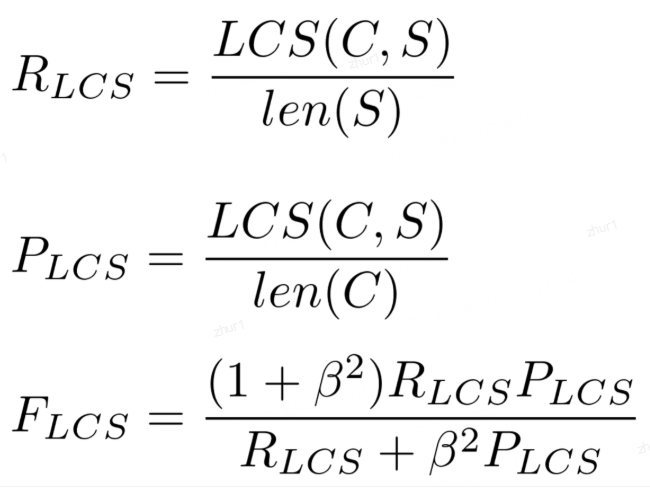
3.2.3 ROUGE-W是 ROUGE-L 的改进版
ROUGE-W 是 ROUGE-L 的改进版,考虑下面的例子,X表示参考译文,而Y1,Y2表示两种机器译文
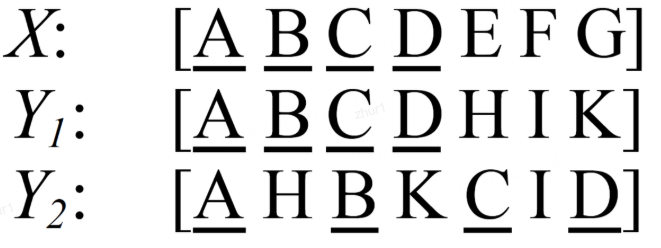
在这个例子中,明显 Y1的翻译质量更高,因为 Y1 有更多连续匹配的翻译。但是采用 ROUGE-L 计算得到的分数确实一样的,即 ROUGE-L(X, Y1)=ROUGE-L(X, Y2)。
因此作者提出了一种加权最长公共子序列方法 (WLCS),给连续翻译正确的更高的分数,具体做法可以阅读原论文《ROUGE: A Package for Automatic Evaluation of Summaries》。
3.2.4 ROUGE-S
Rouge-S的S表示:Skip-Bigram Co-Occurrence Statistics,这其实是Rouge-N的一种扩展,N-gram是连续的,Skip-bigram是允许跳过中间的某些词,同时结合了Rouge-L的计算方式。
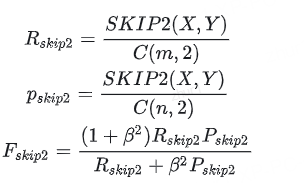
例如:
S1(ref):police killed the gunman
S2(hyp):police kill the gunman
S3(hyp):the gunman kill police
S4(hyp):the gunman police killed
S5(hyp):gunman the killed police
其中c(m,2)、c(n,2)分别表示reference、hypothesis句子中,skip-bigram的组合的个数。对于S1,S2来说
,具体组合为:
【S1】:police killed、police the、police gunman、killed the、killed gunman、the gunman
【S2】:police kill、police the、police gunman、kill the 、kill gunman、the gunman
两句话的skip-bigram都是6个(c(4,2)=6),共同的部分为 " police the", “police gunman”, “the gunman”,所以SKIP2(S1,S2)=3,。所以当beta=1时,代入上面的公式:
有一个比较特别的情况,可以看到S5,它与S1出现的单词是一样的,但由于顺序不同,其SKIP2(S1,S5)=0
,为了区分S5这种情况和没有单个单词与S1共现的情况,提出了Rouge—SU。Rouge—SU,Extension of Rouge-s,在Rouge-S的基础上增加了unigram。
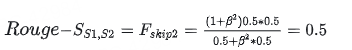
3.2.5 ROUGE-SU
3.2.6 ROUGE指标计算过程
着重于信息完整性和涵盖程度
- a. ROUGE指标是用于评估文本摘要任务的,因此我们将参考翻译和系统生成的翻译视为两个文本摘要。
- b. 首先,我们计算系统生成的翻译中包含的n-gram在参考翻译中出现的次数。
- c. 接下来,计算召回率(recall):将匹配的n-gram总数除以参考翻译中的总n-gram数。例如,1-gram中有3个匹配,参考翻译总共有4个1-gram,因此召回率为3/4。
- d. ROUGE得分可以根据需要使用不同的n-gram大小,通常使用ROUGE-1、ROUGE-2和ROUGE-L。
ROUGE-1 = 召回率(系统生成的1-gram匹配数 / 参考翻译中的1-gram总数)
ROUGE-2 = 召回率(系统生成的2-gram匹配数 / 参考翻译中的2-gram总数)
ROUGE-L = 最长公共子序列(Longest Common Subsequence,LCSS)的长度 / 参考翻译的总长度
4 生成样本的多样性[self-bleu, MMD,Distinct]
Self-BLEU Metric
Self-BLEU的计算方法是,对于每个生成文本,计算它与其他生成文本的BLEU分数,然后对所有生成文本的BLEU分数取平均值。
Self-BLEU的取值范围在0到1之间,分数越低表示生成文本的多样性越高,分数越高表示生成文本的相似性越高。
Self-BLEU常用于无条件语言生成、对话生成、文本摘要等任务中。
VARIATIONAL TEMPLATE MACHINE FOR DATA-TOTEXT GENERATION
横轴是 self-BLEU,是用来衡量同一个方法生成的不同句子之间的相关性,我们希望同一个方法生成的句子,相互之间相关性越小越好。
MMD:原始样本和增广样本的CLS embedding之间的最大均值差异(Maximum Mean Discrepancy, MMD[9]), 用以度量多样性.
CODA: CONTRAST-ENHANCED AND DIVERSITYPROMOTING DATA AUGMENTATION FOR NATURAL LANGUAGE UNDERSTANDING
Diversity ngram的unique个数 Submodular Optimization-based Diverse Paraphrasing and its Effectiveness in Data Augmentation https://aclanthology.org/N19-1363.pdf
Distinct Metric
Distinct用于衡量对话生成中生成文本序列的多样性。它计算生成文本中不同单词和二元组的数量,以反映多样性程度。为避免偏好较长的序列,该值还会根据生成的tokens总数进行缩放。
A Diversity-Promoting Objective Function for Neural Conversation Models
Diversifying Dialogue Generation with Non-Conversational Text
Expectation Adjusted Distinct "Rethinking and Refining the Distinct Metric
数据覆盖度(Coverage)、表达多样性(Distinct-4和Repetition-4)、语法性(Grammaticality)、一致性(Coherence
Long and Diverse Text Generation with Planning-based Hierarchical Variational Model
亲和力【图像】 增强数据对模型学习的训练数据分布的偏移程度 Affinity and Diversity: Quantifying Mechanisms of Data Augmentation https://arxiv.org/abs/2002.08973
多样性【图像】 增强数据相对于模型和学习过程的复杂性。 Affinity and Diversity: Quantifying Mechanisms of Data Augmentation https://arxiv.org/abs/2002.08973

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)