Linux内核网路协议栈——系统的初始化(inet_init主要数据结构)
网络初始化申请了两块skb高速缓存和创建了一个/proc/net/protocols文件,现在开始重头戏,网络协议栈的初始化。这篇文章主要介绍网络栈中使用到的主要数据结构。网络协议栈的内核实现和理论上的分层有些不一样,在代码里面的分层如下图:开始前,先回顾一下应用层socket函数的调用,它会创建一个socket并返回对应的描述符:int <strong&g...
网络初始化申请了两块skb高速缓存和创建了一个/proc/net/protocols文件,现在开始重头戏,网络协议栈的初始化。这篇文章主要介绍网络栈中使用到的主要数据结构。
网络协议栈的内核实现和理论上的分层有些不一样,在代码里面的分层如下图:
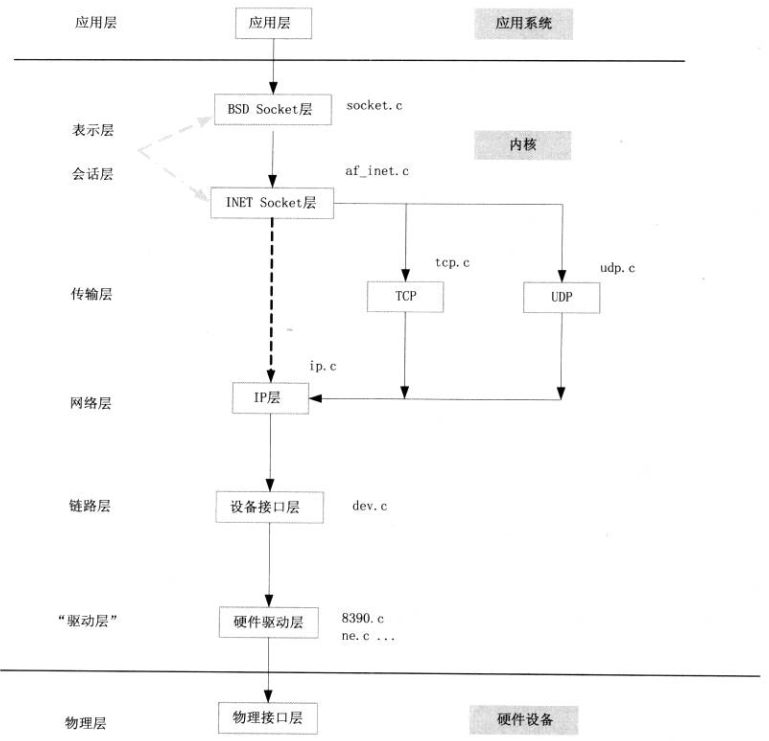
开始前,先回顾一下应用层socket函数的调用,它会创建一个socket并返回对应的描述符:
int <strong>socket</strong>(int domain, int type, int protocol);socket函数对应于普通文件的打开操作。普通文件的打开操作返回一个文件描述字,而socket()用于创建一个socket描述符(socket descriptor),它唯一标识一个socket。这个socket描述字跟文件描述字一样,后续的操作都有用到它,把它作为参数,通过它来进行一些读写操作。
正如可以给fopen的传入不同参数值,以打开不同的文件。创建socket的时候,也可以指定不同的参数创建不同的socket描述符,socket函数的三个参数分别为:
- domain:即协议域,又称为协议族(family)。常用的协议族有,AF_INET、AF_INET6、AF_LOCAL(或称AF_UNIX,Unix域socket)、AF_ROUTE等等。协议族决定了socket的地址类型,在通信中必须采用对应的地址,如AF_INET决定了要用ipv4地址(32位的)与端口号(16位的)的组合、AF_UNIX决定了要用一个绝对路径名作为地址。
- type:指定socket类型。常用的socket类型有,SOCK_STREAM、SOCK_DGRAM、SOCK_RAW、SOCK_PACKET、SOCK_SEQPACKET等等(socket的类型有哪些?)。
- protocol:故名思意,就是指定协议。常用的协议有,IPPROTO_TCP、IPPTOTO_UDP、IPPROTO_SCTP、IPPROTO_TIPC等,它们分别对应TCP传输协议、UDP传输协议、STCP传输协议、TIPC传输协议(这个协议我将会单独开篇讨论!)。
注意:并不是上面的type和protocol可以随意组合的,如SOCK_STREAM不可以跟IPPROTO_UDP组合。当protocol为0时,会自动选择type类型对应的默认协议。
当我们调用socket创建一个socket时,返回的socket描述字它存在于协议族(address family,AF_XXX)空间中,但没有一个具体的地址。如果想要给它赋值一个地址,就必须调用bind()函数,否则就当调用connect()、listen()时系统会自动随机分配一个端口。
1. static struct net_proto_family *net_families[NPROTO]
~/linux-4.12/include/linux/net.h
struct net_proto_family {
int family; //地址族类型
int (*create)(struct net *net, struct socket *sock, //套接字的创建方法
int protocol, int kern);
struct module *owner;
};
socket.c
#define AF_MAX 44 /* For now.. */
#define NPROTO AF_MAX
static const struct net_proto_family __rcu *net_families[NPROTO] __read_mostly;
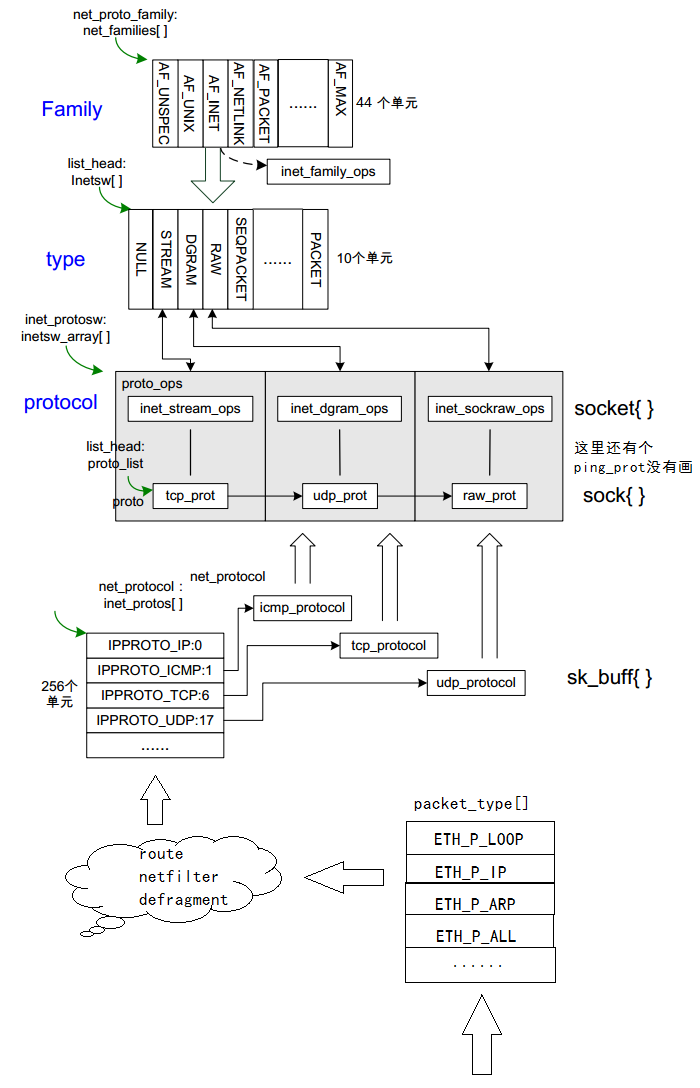
第一个重要的结构体是 net_proto_family。
在这之前必须知道 一些概念——地址族和套接字类型。 大家都知道所谓的套接字都有地址族,实际就是套接字接口的种类, 每种套接字种类有自己的通信寻址方法。 Linux 将不同的地址族抽象统一为 BSD 套接字接口,应用程序 关心的只是 BSD 套接字接口,通过参数来指定所使用的套接字地址族。
Linux 内 核 中 为 了 支 持 多 个 地 址 族 , 定 义 了 这 么 一 个 变 量 : static struct net_proto_family *net_families[NPROTO], NPROTO 等于 44, 也就是说 Linux 内核支持最多 44种地址族。不过目前已经 够用了, 我们常用的不外乎就是 PF_UNIX( 1)、 PF_INET( 2)、 PF_NETLINK( 16), Linux 还有一个自 有的 PF_PACKET( 17),即对网卡进行操作的选项。所以这个链表里面存放的是应用层socket()的第一个参数,它决定了这个参数可以取哪些值。当系统调用socket转到内核处理的时候,它首先会用第一个参数查找需要在哪个域里面创建套接字。
在网络子系统中,net_families[NPROTO]是一个全局的链表,它存放的是不同的地址族,不同地址族套接字有不同的创建方法,下面我们关注的是PF_INET地址族的注册。
在inet_init()中会调用这个函数注册地址族:(void)sock_register(&inet_family_ops); 其中inet_family_ops是struct net_proto_family的结构体对象
static const struct net_proto_family inet_family_ops = {
.family = PF_INET,
.create = inet_create,
.owner = THIS_MODULE,
};结构体的内容比较简单,一个是地址族的标号,一个是在该地址族里创建socket时调用的创建函数inet_create。当我们通过系统调用socket()创建PF_INET地址族的套接字时,内核使用的创建函数时inet_create,这里只需要记住,后面会分析创建过程。
下面是sock_register的实现过程
int sock_register(const struct net_proto_family *ops)
{
int err;
if (ops->family >= NPROTO) {
pr_crit("protocol %d >= NPROTO(%d)\n", ops->family, NPROTO);
return -ENOBUFS;
}
spin_lock(&net_family_lock);
if (rcu_dereference_protected(net_families[ops->family],
lockdep_is_held(&net_family_lock)))
err = -EEXIST;
else {
rcu_assign_pointer(net_families[ops->family], ops); //将inet_family_ops对象添加到net_families全局数组里面,就完成了初始化
err = 0;
}
spin_unlock(&net_family_lock);
pr_info("NET: Registered protocol family %d\n", ops->family);
return err;
}
EXPORT_SYMBOL(sock_register);2. static struct inet_protosw inetsw_array[]
/* This is used to register socket interfaces for IP protocols. */
struct inet_protosw {
struct list_head list;
/* These two fields form the lookup key. */
unsigned short type; /* This is the 2nd argument to socket(2). */
unsigned short protocol; /* This is the L4 protocol number. */
struct proto *prot;
const struct proto_ops *ops;
unsigned char flags; /* See INET_PROTOSW_* below. */
};
#define INET_PROTOSW_REUSE 0x01 /* Are ports automatically reusable? */
#define INET_PROTOSW_PERMANENT 0x02 /* Permanent protocols are unremovable. */
#define INET_PROTOSW_ICSK 0x04 /* Is this an inet_connection_sock? */
前面一直疑惑inet_protosw中的sw表示什么意思,后来才知道,原来是switch的缩写,表示inet层的协议切换,inetsw串联着PF_INET地址族所支持的协议类型,比如tcp, udp等。
这个函数起着承上启下的作用,它上层对应的是BSD层,下层对应的是inet层,它在网络协议栈的最上两层扮演着重要的角色。
这个结构体每个注释已经比较清楚了,但是这里还是再讲一下:
1. type和protocol两个域组成了socket的查找key,他们分别对应着应用层socket函数的第二和第三个参数,通过这两个参数来确定使用的是哪种socket类型。查找的时候主要是查找type,protocol只是用来防止初始化好的协议被再次初始化,比如开机的时候已经初始化好了TCP协议,如果应用层又调用了该协议的初始化函数,将直接退出。
2. prot表示的是该协议相关的处理函数,比如tcp_v4_connect和tcp_v4_init_sock等相关的协议具体处理函数
3. ops表示的是该socket类型的套接字的管理函数,比如处理inet_bind和inet_accept等对inet层的套接字调用
prot和ops都是操作函数的集合,非常重要,我们会在后面进一步分析
4. flags用来标识该协议的一些特性,比如TCP协议的端口是否可自动重用,该协议是否可以被移除,也就是说该协议是否可以从inetsw_arry全局数组中删除,当然对于TCP,UDP这些必备的协议是不能被移除的
static struct list_head inetsw[SOCK_MAX];
inetsw是一个数组,它里面存放的对象是inet_protosw,也就是说PF_INET地址族中所支持的socket类型都存放在这个数组中,当socke调用的时候,将使用第二个参数type到这个数组中查找对应的inet_protosw对象。
/* Upon startup we insert all the elements in inetsw_array[] into
* the linked list inetsw.
*/
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_ICMP,
.prot = &ping_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
},
{
.type = SOCK_RAW,
.protocol = IPPROTO_IP, /* wild card */
.prot = &raw_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
}
};
#define INETSW_ARRAY_LEN ARRAY_SIZE(inetsw_array)inetsw_array只在初始化的时候用到,这个数组里面写死了初始化的时候哪些协议和套接字类型是必须支持的,在初始化的时候,这些套接字类型都会添加到inetsw数组中:
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
3. struct proto_ops
这个结构体的定义就不贴上来了,我们直接看一下它初始化好的一个对象就知道怎么回事了:
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
.release = inet_release,
.bind = inet_bind,
.connect = inet_stream_connect,
.socketpair = sock_no_socketpair,
.accept = inet_accept,
.getname = inet_getname,
.poll = tcp_poll,
.ioctl = inet_ioctl,
.listen = inet_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
.mmap = sock_no_mmap,
.sendpage = inet_sendpage,
.splice_read = tcp_splice_read,
.read_sock = tcp_read_sock,
.peek_len = tcp_peek_len,
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_sock_common_setsockopt,
.compat_getsockopt = compat_sock_common_getsockopt,
.compat_ioctl = inet_compat_ioctl,
#endif
};
EXPORT_SYMBOL(inet_stream_ops);可以看到,这个proto_ops存放的是不同套接字类型的套接字管理函数集,也就是socket函数的第二个参数指定的type,不同的套接字类型有不同的管理函数集,我们常常接触到的套接字类型有以下类型:
/** sock_type - Socket types
*
* Please notice that for binary compat reasons MIPS has to
* override the enum sock_type in include/linux/net.h, so
* we define ARCH_HAS_SOCKET_TYPES here.
*
* @SOCK_DGRAM - datagram (conn.less) socket
* @SOCK_STREAM - stream (connection) socket
* @SOCK_RAW - raw socket
* @SOCK_RDM - reliably-delivered message
* @SOCK_SEQPACKET - sequential packet socket
* @SOCK_PACKET - linux specific way of getting packets at the dev level.
* For writing rarp and other similar things on the user level.
*/
enum sock_type {
SOCK_DGRAM = 1,
SOCK_STREAM = 2,
SOCK_RAW = 3,
SOCK_RDM = 4,
SOCK_SEQPACKET = 5,
SOCK_DCCP = 6,
SOCK_PACKET = 10,
};所以不同的套接字类型都有不同的套接字管理函数集体,在初始化的时候,会将proto_ops对象赋值给net_protosw结构体中的ops指针,从而建立两者的联系
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
4. struct proto
这个结构体里面存放的是不同协议的操作函数集,也就是具体协议的实现。这里需要注意和proto_ops的区分,struct proto_ops是根据套接字的类型(参数二type: SOCK_STREAM, SOCK_DGRAM...)不同而组成不同的套接字管理函数集,它面向的是套接字的管理; struct proto是根据套接字的协议类型(参数三protocol: IPPROTO_TCP, IPPROTO_UDP,)不同而组成的不同协议管理函数集,它面向的是具体协议的实现。
enum {
IPPROTO_IP = 0, /* Dummy protocol for TCP */
#define IPPROTO_IP IPPROTO_IP
IPPROTO_ICMP = 1, /* Internet Control Message Protocol */
#define IPPROTO_ICMP IPPROTO_ICMP
IPPROTO_IGMP = 2, /* Internet Group Management Protocol */
#define IPPROTO_IGMP IPPROTO_IGMP
IPPROTO_IPIP = 4, /* IPIP tunnels (older KA9Q tunnels use 94) */
#define IPPROTO_IPIP IPPROTO_IPIP
IPPROTO_TCP = 6, /* Transmission Control Protocol */
#define IPPROTO_TCP IPPROTO_TCP
IPPROTO_EGP = 8, /* Exterior Gateway Protocol */
#define IPPROTO_EGP IPPROTO_EGP
IPPROTO_PUP = 12, /* PUP protocol */
#define IPPROTO_PUP IPPROTO_PUP
IPPROTO_UDP = 17, /* User Datagram Protocol */
#define IPPROTO_UDP IPPROTO_UDP
....下面主要贴上TCP和UDP的实例,篇幅有点多,但是很重要,真的很重要!
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.unhash = inet_unhash,
.get_port = inet_csk_get_port,
.enter_memory_pressure = tcp_enter_memory_pressure,
.stream_memory_free = tcp_stream_memory_free,
.sockets_allocated = &tcp_sockets_allocated,
.orphan_count = &tcp_orphan_count,
.memory_allocated = &tcp_memory_allocated,
.memory_pressure = &tcp_memory_pressure,
.sysctl_mem = sysctl_tcp_mem,
.sysctl_wmem = sysctl_tcp_wmem,
.sysctl_rmem = sysctl_tcp_rmem,
.max_header = MAX_TCP_HEADER,
.obj_size = sizeof(struct tcp_sock),
.slab_flags = SLAB_TYPESAFE_BY_RCU,
.twsk_prot = &tcp_timewait_sock_ops,
.rsk_prot = &tcp_request_sock_ops,
.h.hashinfo = &tcp_hashinfo,
.no_autobind = true,
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_tcp_setsockopt,
.compat_getsockopt = compat_tcp_getsockopt,
#endif
.diag_destroy = tcp_abort,
};
EXPORT_SYMBOL(tcp_prot);
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
.close = udp_lib_close,
.connect = ip4_datagram_connect,
.disconnect = udp_disconnect,
.ioctl = udp_ioctl,
.init = udp_init_sock,
.destroy = udp_destroy_sock,
.setsockopt = udp_setsockopt,
.getsockopt = udp_getsockopt,
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,
.sendpage = udp_sendpage,
.release_cb = ip4_datagram_release_cb,
.hash = udp_lib_hash,
.unhash = udp_lib_unhash,
.rehash = udp_v4_rehash,
.get_port = udp_v4_get_port,
.memory_allocated = &udp_memory_allocated,
.sysctl_mem = sysctl_udp_mem,
.sysctl_wmem = &sysctl_udp_wmem_min,
.sysctl_rmem = &sysctl_udp_rmem_min,
.obj_size = sizeof(struct udp_sock),
.h.udp_table = &udp_table,
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_udp_setsockopt,
.compat_getsockopt = compat_udp_getsockopt,
#endif
.diag_destroy = udp_abort,
};
EXPORT_SYMBOL(udp_prot);所以不同的协议类型都有不同的协议实现函数集体,在初始化的时候,会将proto对象赋值给net_protosw结构体中的prot指针,从而建立两者的联系
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},不仅如此, stuct_proto对象自己也维护了一个链表,串连在proto_list全局链表后面, 下面来看看它是怎么做的
static LIST_HEAD(proto_list);static int __init inet_init(void)
{
struct inet_protosw *q;
struct list_head *r;
int rc = -EINVAL;
sock_skb_cb_check_size(sizeof(struct inet_skb_parm));
<strong>rc = proto_register(&tcp_prot, 1);</strong>
if (rc)
goto out;int proto_register(struct proto *prot, int alloc_slab)
{
if (alloc_slab) {
prot->slab = kmem_cache_create(prot->name, prot->obj_size, 0,
SLAB_HWCACHE_ALIGN | prot->slab_flags,
NULL);
if (prot->slab == NULL) {
pr_crit("%s: Can't create sock SLAB cache!\n",
prot->name);
goto out;
}
if (req_prot_init(prot))
goto out_free_request_sock_slab;
if (prot->twsk_prot != NULL) {
prot->twsk_prot->twsk_slab_name = kasprintf(GFP_KERNEL, "tw_sock_%s", prot->name);
if (prot->twsk_prot->twsk_slab_name == NULL)
goto out_free_request_sock_slab;
prot->twsk_prot->twsk_slab =
kmem_cache_create(prot->twsk_prot->twsk_slab_name,
....
}
mutex_lock(&proto_list_mutex);
<strong>list_add(&prot->node, &proto_list);</strong>
assign_proto_idx(prot);
mutex_unlock(&proto_list_mutex);
return 0;
.....
}
EXPORT_SYMBOL(proto_register);我们可以看到,在inet_inet函数刚开始就调用了proto_register注册struct proto对象,第一个参数传的是协议,第二个传的是内存分配方式,如果是1表示在高速缓存中分配空间,0则在内存中分配。因为tcp这些协议经常使用,所以分配在高速缓存里面比较合适。
从proto_register的实现可以看出,申请好空间以后,则将tcp_proto对象添加到全局链表proto_list里面,方便后面的查找。其他协议也一样,比如tcp_prot、udp_proto、raw_proto、ping_proto都会在初始化的时候添加到proto_list链表里面,初始化时候添加的都是不可卸载的,然而关于其他的一些协议则会在开机完后通过注册的方式,动态注册添加或卸载。
5. struct net_protocol
/* This is used to register protocols. */
struct net_protocol {
void (*early_demux)(struct sk_buff *skb);
void (*early_demux_handler)(struct sk_buff *skb);
int (*handler)(struct sk_buff *skb);
void (*err_handler)(struct sk_buff *skb, u32 info);
unsigned int no_policy:1,
netns_ok:1,
/* does the protocol do more stringent
* icmp tag validation than simple
* socket lookup?
*/
icmp_strict_tag_validation:1;
};
这个结构体比较简单,但他是inet层和网络层(IP层)之间的连接,所以也很重要。
1. 第一个和第二个参数是查找基于包多路径选路,对于需要打了转包的设备,还是需要关闭这个功能,可以查看这里了解它
2. handler表示对应协议包的收包处理函数,当收到一个包的时候,在IP层将会判断这个包的协议,然后根据协议类型调用该结构中的收包函数,进而将包传给传输层处理
3. netns_ok表示是否支持虚拟网络? namespace?
下面列以下该对象的一些实例:
#ifdef CONFIG_IP_MULTICAST
static const struct net_protocol igmp_protocol = {
.handler = igmp_rcv,
.netns_ok = 1,
};
#endif
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
};
static struct net_protocol udp_protocol = {
.early_demux = udp_v4_early_demux,
.early_demux_handler = udp_v4_early_demux,
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};
static const struct net_protocol icmp_protocol = {
.handler = icmp_rcv,
.err_handler = icmp_err,
.no_policy = 1,
.netns_ok = 1,
};这些实例在inet_init函数中,通过以下代码将不同的协议接收函数添加到inet_protos[protocol] 全局链表中,从而完成IP层和传输层的衔接
/*
* Add all the base protocols.
*/
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
#ifdef CONFIG_IP_MULTICAST
if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0)
pr_crit("%s: Cannot add IGMP protocol\n", __func__);
#endif
struct net_protocol __rcu *inet_protos[MAX_INET_PROTOS] __read_mostly;
const struct net_offload __rcu *inet_offloads[MAX_INET_PROTOS] __read_mostly;
EXPORT_SYMBOL(inet_offloads);
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol)
{
if (!prot->netns_ok) {
pr_err("Protocol %u is not namespace aware, cannot register.\n",
protocol);
return -EINVAL;
}
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],
NULL, prot) ? 0 : -1;
}
EXPORT_SYMBOL(inet_add_protocol);5. struct packet_type ptype_base[]
以上是关于协议栈框架的搭建,对于传输层以上的协议实现来说,已经差不多初始化好了,但是对于 IP 层接收流程,则还不够。因为对于 发送过程,直接调用 的是IP 层函数;而对于内核接收过程则分为 2 层: 上层需要有一个接收函数解复用传输 协议报文,我们已经介绍了, 而下层需要一个接收函数解复用网络层报文。对报文感兴趣的底层(IP层)协议目 前有两个,一个是 ARP,一个是 IP, 报文从设备层送到上层之前,必须区分是 IP 报文还是 ARP 报文。 然后才能往上层送。 这个过程由一个数据结构来抽象,叫 packet_type{},定义在linux/netdevice.h
struct packet_type {
__be16 type; /* This is really htons(ether_type). */
struct net_device *dev; /* NULL is wildcarded here */
int (*func) (struct sk_buff *,
struct net_device *,
struct packet_type *,
struct net_device *);
bool (*id_match)(struct packet_type *ptype,
struct sock *sk);
void *af_packet_priv;
struct list_head list;
};1. type:网络层的报文类型,目前主要是IP和ARP
2. dev:指向我们希望接收到包的那个接口的 net device 结构。如果是 NULL,则我们会从任何一个网络接口上收到包
3. af_packet_priv: 如果某个 packet_type{}被注册到系统中, 那么它就被挂接到全局链表中( 有 2 个,见下面的解说),list 就是代表链表节点
如果某个 packet_type{}被注册到系统中, 那么它就被挂接到全局链表中( 有 2 个,见下面的解说),list 就是代表链表节点inet_init 函数最后调用了一个 dev_add_pack 函数,不仅是 inet_init 函数调用,有一个很很重要的模块也调用了它,就是 ARP 模块,我们会在后面的章节看到它是如何调用 dev_add_pack 函数的。也就是说在网络栈初始化的时候,会添加IP协议到链表中,在ARP初始化的时候,会将ARP协议也添加到这个链表中
下面来看看他的初始化过程:
~/linux-4.12/include/uapi/linux/if_ether.h
#define ETH_P_LOOP 0x0060 /* Ethernet Loopback packet */
#define ETH_P_PUP 0x0200 /* Xerox PUP packet */
#define ETH_P_PUPAT 0x0201 /* Xerox PUP Addr Trans packet */
#define ETH_P_TSN 0x22F0 /* TSN (IEEE 1722) packet */
#define ETH_P_IP 0x0800 /* Internet Protocol packet */
#define ETH_P_X25 0x0805 /* CCITT X.25 */
#define ETH_P_ARP 0x0806 /* Address Resolution packet */
#define ETH_P_ALL 0x0003 /* Every packet (be careful!!!) */ 抓包模式
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};
dev_add_pack(&ip_packet_type);
/*
* Add a protocol ID to the list. Now that the input handler is
* smarter we can dispense with all the messy stuff that used to be
* here.
*
* BEWARE!!! Protocol handlers, mangling input packets,
* MUST BE last in hash buckets and checking protocol handlers
* MUST start from promiscuous ptype_all chain in net_bh.
* It is true now, do not change it.
* Explanation follows: if protocol handler, mangling packet, will
* be the first on list, it is not able to sense, that packet
* is cloned and should be copied-on-write, so that it will
* change it and subsequent readers will get broken packet.
* --ANK (980803)
*/
static inline struct list_head *ptype_head(const struct packet_type *pt)
{
if (pt->type == htons(ETH_P_ALL))
return pt->dev ? &pt->dev->ptype_all : &ptype_all;
else
return pt->dev ? &pt->dev->ptype_specific :
&ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
/**
* dev_add_pack - add packet handler
* @pt: packet type declaration
*
* Add a protocol handler to the networking stack. The passed &packet_type
* is linked into kernel lists and may not be freed until it has been
* removed from the kernel lists.
*
* This call does not sleep therefore it can not
* guarantee all CPU's that are in middle of receiving packets
* will see the new packet type (until the next received packet).
*/
void dev_add_pack(struct packet_type *pt)
{
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
EXPORT_SYMBOL(dev_add_pack);在~/linux-4.12/include/uapi/linux/if_ether.h这个文件里面有定义不同网络层的协议,其中包括IP、ARP、RARP,IPX,IPV6等等协议,每一种协议通过向ptype_base[]数组张注册一个元素进行登记,当然不是每个协议都会进行登记,有用到的才会。这样就维护了一张全局的ptype_base[]数组,每一个包网络层使用的是哪种协议都可以来这里来查,查到匹配的协议以后,就调用对应的处理函数。
比如下面这个是pcket_type结构体指定的IP协议的实例,名字是ip_packet_type.
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};inet_init函数通过调用dev_add_pack(&ip_packet_type)将IP协议添加到ptype_base[]数组中而成为一员,而且对应的处理函数是ip_rcv. 当网络层收到一个包时,它检查完包的合理性后,查看这个包的网络层协议是哪个,匹配到是ETH_P_IP后,就调用ip_rcv函数进行处理,这样一个包就从设备接口层进入到了IP层。
那一个包是怎么从IP层进入到传输层的呢?这个我们后面分析。
6.总结

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)