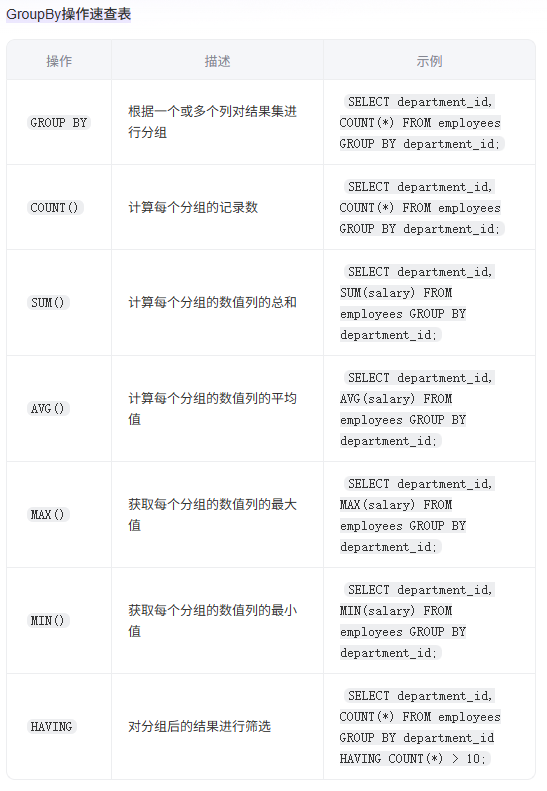
Python数据分析实战:深度解析Pandas GroupBy操作精髓 1
它像一把精准的手术刀,能将杂乱数据按规则切片,用聚合、转换等操作挖掘价值,从电商销售的区域洞察到用户行为的复购分析,处处都有它的身影。2. 需处理多层索引(如多列分组),用 reset_index()转成普通列,或学习 MultiIndex的高级索引(如 loc[('北京', '2025-01-01')])。举个例子:分析全国销售数据时,按“地区”拆分后,计算每个地区的“总销售额”,最后合并成地区
一、开篇:
在Python数据分析的工具箱里,Pandas的 GroupBy 堪称“灵魂操作”。它像一把精准的手术刀,能将杂乱数据按规则切片,用聚合、转换等操作挖掘价值,从电商销售的区域洞察到用户行为的复购分析,处处都有它的身影。今天,我们将从原理到实战,拆解 GroupBy 的核心逻辑,还会重点梳理易踩的“坑”与避坑指南,带你真正吃透这个数据分析必备技能。
二、GroupBy核心逻辑:
Split-Apply-Combine
1. 流程拆解
GroupBy 的本质是 “拆分-应用-合并” 三部曲:
1.拆分(Split):按“键”(列名、函数、多条件组合)把数据集拆成若干子组。比如电商数据按“地区”拆,每个地区就是独立子组。
2.应用(Apply):对子组执行函数,可简单(求和、均值)可复杂(自定义算法、模型预测)。
3.合并(Combine):把各子组的计算结果整合,还原成规整的DataFrame/Series。
举个例子:分析全国销售数据时,按“地区”拆分后,计算每个地区的“总销售额”,最后合并成地区-销售额的结果表,这就是典型的GroupBy流程。
2. 底层实现机制
在Pandas内部, GroupBy 操作通过 GroupBy 对象实现,该对象维护着分组信息和数据块引用。当调用聚合方法时,Pandas会遍历分组数据块,在内存中高效执行计算。理解这一机制有助于我们更好地进行性能优化,例如减少不必要的中间数据复制。
3. 直观理解
想象你是老师,要统计班级(分组键)里每个同学的数学成绩(数据列)平均分(应用函数)。你会先按班级把学生分组(拆分),再逐个班级算平均分(应用),最后把各班平均分汇总成表(合并)——这就是 GroupBy 的生活化映射。
三、GroupBy基础用法:从简单到多场景
1. 单列分组聚合
场景:分析各地区平均销售额代码:

输出:以“地区”为索引的Series,直接呈现各地区平均销售额,简洁明了。
2. 多列分组聚合
场景:统计各地区每天的订单量(需同时按“地区”+“订单日期”分组)
代码:
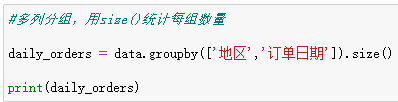
输出: MultiIndex Series (多层索引),第一层是“地区”,第二层是“日期”,值为对应组的订单数。可通过 daily_orders.loc[('北京', '2025-01-01')] 精准查询某地区某天的数据。
3. 多聚合函数应用
场景:想同时看各地区销售额的“总和、均值、最大值”
代码:

输出:DataFrame,列是 sum / mean / max ,行是各地区,对比分析超方便。
四、高级玩法:自定义与Transform的妙用
1. 自定义聚合函数
场景:计算各地区销售额的变异系数(标准差/均值,衡量数据离散度)
代码:

关键:函数里的 x 是分组后的Series,需考虑边界情况(如均值为0),用 apply 执行自定义逻辑。
2. Transform:让结果“适配原数据”
场景:给每条订单标记所属地区的平均销售额(需保留原数据行数,用于后续分析)
代码:

对比:若用 apply / agg ,结果是分组后的聚合值(行数少),无法直接和原数据拼接; transform 保证每行都有对应值,适合特征工程(如标准化、异常值标记)。
五、筛选与过滤:Filter的正确打开方式
场景:筛选出平均销售额>1000的地区的所有原始订单
代码:

易错点:很多人误以为 filter 返回聚合结果,实际它保留符合条件分组的所有原始行。若要筛选聚合结果,需先聚合再过滤(如 agg_results[agg_results['mean']>1000] )。
六、实战案例:电商用户复购分析
需求:从订单数据中,找出复购率最高的前10%用户(复购:订单数≥2)
步骤拆解:
1. 统计每个用户的订单数:
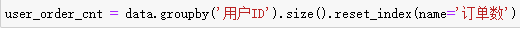
2. 筛选复购用户(订单数≥2):

3. 取前10%复购率高的用户:

延伸:可结合用户信息表,分析这些高复购用户的特征(如消费习惯、地域分布),指导运营策略。
七、必避的5大错误与解决方案
1. 键值错误(KeyError)
错误场景:分组列名拼写错(如 groupby('region') ,实际列名是 '地区' ),或多列分组时列名漏写/错写。
解决方案:1.用 print(data.columns) 核对列名,确保分组键100%匹配;2.多列分组时,逐个检查 ['地区', '订单日期'] 里的列名。
2. 索引混乱(MultiIndex/非预期索引)
错误场景:分组后默认把分组键设为索引,后续取数报错(如 agg_results[0] ,但索引是地区名)。
解决方案:1.不需要索引时,加 as_index=False ,如 groupby('地区', as_index=False) ,让分组键变回普通列;2. 需处理多层索引(如多列分组),用 reset_index() 转成普通列,或学习 MultiIndex 的高级索引(如 loc[('北京', '2025-01-01')] )。
3. 自定义函数“水土不服”
错误场景:自定义函数没考虑分组数据的类型(如以为 x 是单个值,实际是Series),或依赖外部变量未传递。
解决方案: 1.函数内用 print(type(x)) print(x.head()) 调试,确认数据结构;2.依赖外部变量时,通过参数传递(如 def func(x, var): ... ,再用 apply(lambda x: func(x, var)) )。
4. Transform与Apply混淆
错误场景:需要填充原数据时用了 apply (返回聚合结果,行数少),或需要聚合时用了 transform (返回同形状结果,数据冗余)。
解决方案: 1.要“广播”结果到原数据每行 → 用 transform ;2.要自定义聚合逻辑(返回单个值/小结果) → 用 apply 。
5. Filter功能误解
错误场景:想用 filter 筛选聚合结果(如“平均销售额>1000的地区的均值” ),但 filter 实际返回原始行。
解决方案: 1.若要筛选聚合结果 → 先 agg 得到结果表,再用布尔索引过滤(如 agg_results[agg_results['mean']>1000] );2.若要保留原始行 → 用 filter (如筛选出高销售地区的所有订单)。
八、GroupBy性能优化:大数据场景下的提速技巧
1. 场景痛点
当处理百万级、千万级数据时,GroupBy默认操作可能变慢,尤其是自定义函数或多列分组场景。比如分析某大型电商平台全年订单(上亿行),按“地区+商品分类”分组聚合,常规方法可能超时。
2. 优化方案
1. 利用Pandas内置优化
·避免链式操作:比如 data.groupby(...).mean().reset_index() ,可合并为 data.groupby(..., as_index=False).mean() ,减少中间对象创建。
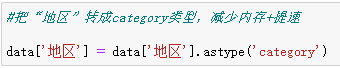
·指定数据类型:分组前用 astype() 把列转成更高效类型(如 int32 替代 int64 , category 类型存分组键)。示例:
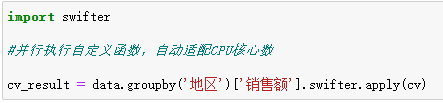
2. 并行计算加速
·Swifter库结合Apply:Swifter自动判断是否并行,适合自定义函数场景。安装 pip install swifter 后使用:
· Dask库分布式处理:处理超大规模数据(如内存装不下),用Dask的 groupby ,语法类似Pandas但支持并行+分块计算。
3. 预处理减少计算量
·过滤无效数据:分组前用 query() 或布尔索引,去掉无关行(如销售额为0的无效订单),减少分组规模。
·预排序分组键:若分组键是无序的(如随机字符串),先排序( data.sort_values('地区') )可提升分组效率(Pandas对有序数据分组更快 )。
九、GroupBy与其他工具联动:拓展数据分析边界
1.结合Matplotlib可视化
分组后的数据可直接用Matplotlib绘图,快速呈现规律。示例:分析各地区销售额分布

2.对接机器学习模型
分组后的数据可作为模型输入,比如:
·按“用户ID”分组,提取每个用户的消费特征(均值、方差等),作为用户画像输入分类模型(预测用户忠诚度);
·按“时间”分组,生成时间序列特征,用于时序预测(如ARIMA、Prophet)。
3.与SQL协同分析
若数据存于数据库,可先用SQL做初步分组(减少数据量),再用Pandas的GroupBy细化分析。示例(用SQLAlchemy连接数据库):

高级应用:在复杂业务场景中,结合SQL的窗口函数(如 ROW_NUMBER() 、 SUM() OVER() )与Pandas的GroupBy,实现更灵活的数据分析。例如,先用SQL计算每个地区每日销售额的累计占比,再用Pandas对结果进行进一步的聚合和可视化,挖掘数据背后的业务趋势。
十、行业案例剖析:GroupBy在真实场景中的价值体现
1. 金融风控领域
在银行信贷数据分析中,需要评估不同信用等级用户的违约风险。通过GroupBy按“信用等级”分组,计算每组用户的平均贷款金额、逾期率等指标,结合机器学习模型构建违约预测系统,帮助银行精准识别高风险客户,降低坏账率。
2. 社交媒体分析
对于社交平台的用户行为数据,按“用户年龄段”和“使用时段”分组,分析不同群体的活跃时间、互动频率等特征,为广告投放和内容推荐策略提供数据支持,提升用户活跃度和广告转化率。
3. 医疗数据分析
在医院电子病历系统中,按“疾病类型”分组统计患者的治疗周期、费用分布等信息,帮助医院优化资源配置,制定更合理的诊疗方案,同时为医保政策制定提供参考依据。
十一、总结:掌握GroupBy,让数据分析“开挂”
Pandas的 GroupBy 是数据分析的“核心武器”,从基础聚合到自定义函数,从Transform的灵活填充到Filter的精准筛选,每一步都在解决实际业务问题。记住 “拆分-应用-合并” 的逻辑,避开索引、函数、方法混淆的坑,你就能用它轻松处理:
·电商数据的区域/时间维度分析;
·用户行为的复购、留存挖掘;
·金融数据的分组统计与风险识别……
建议多找真实数据集练习(如Kaggle的销售数据、用户行为数据),把 GroupBy 和实际业务需求结合,才能真正让这个工具“为你所用”。当你能熟练用它拆解复杂问题时,就会发现:原来数据分析的效率与深度,真的可以“一键提升”!
附录:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)