微调openpi基础模型
openpi的开源提供了基于libero数据集微调模型的方法,但光靠上面的指令,还是有很多地方需要调整,避免走坑。
openpi的开源提供了基于libero数据集微调模型的方法,但光靠上面的指令,还是有很多地方需要调整,避免走坑。
一.lerobot数据集
可以按照官方提供的方法,首先下载原始libero数据集,然后再转换为lerobot数据集。也可以直接下载转换后的lerobot数据集。
方法一:
使用huggingface-cli下载数据集。首先安装huggingface_hub,然后登录huggingface-cli。
pip install huggingface_hub
huggingface-cli login这时会让你输入token,这里进入huggingface官方网站,创建一个token,复制进去就行。
然后运行下述指令下载数据集,注意--repo-type dataset这个参数,下载数据集需要加上,下载模型就不用。--local-dir后面跟自己的路径。更多用法可以参考这里。
huggingface-cli download --repo-type dataset openvla/modified_libero_rlds --local-dir /yourpath下载完成后,在项目文件夹开启终端运行
uv run examples/libero/convert_libero_data_to_lerobot.py --data_dir /path/to/your/libero/data也可以修改代码中REPO_NAME的值,保存在自己的文件夹之中。
方法二:
这里我操作到后面才发现openpi已经把转换后的数据提交到了huggingface上,直接运行
huggingface-cli download --repo-type dataset physical-intelligence/libero --local-dir /yourpath二.定义训练配置并运行训练
这里主要修改src/openpi/training/config.py文件。找到trainconfig里name为pi0_fast_libero的代码,将local_files_only修改为True,只加载本地数据集,不然在服务器上也要重新下载。后面的checkpoints也可以修改为自己的路径。
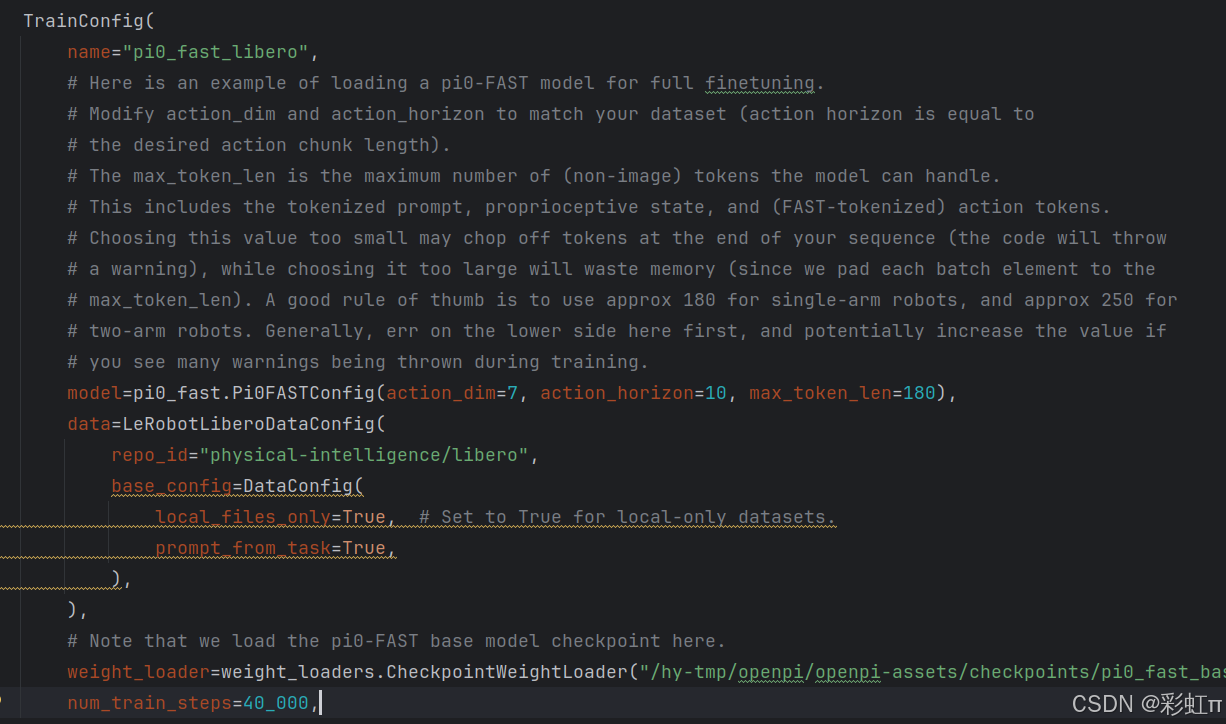
注意,重要的来了,我这里运行一直提示No such file or directory: '/root/.cache/huggingface/lerobot/physical-intelligence/libero/meta/info.json。因为在服务器上root路径的空间很少,不足以放30G的数据,所以我想改路径。刚开始我是认为修改$HF_HOME的地址,于是我输入export HF_HOME="/hy-tmp",然后运行还是出现同样的错误。我翻遍了config.py,compute_norm_stats.py和compute_norm_stats.py,还是没有找到路径修改的方法。
到后面我查看步骤一里面的convert_libero_data_to_lerobot.py代码,发现from lerobot.common.datasets.lerobot_dataset import LEROBOT_HOME里面有个路径LEROBOT_HOME,也对应了为什么physical-intelligence/libero前面有个lerobot,然后我查看该路径,也没有指向任何值,后面修改LEROBOT_HOME的路径,果然就是这个东西在作祟。
export LEROBOT_HOME="/yourpath"然后就可以运行,在此之前还需要更改HF_HOME的环境变量,否则运行下面的代码,会生成同样的数据在/root/.cache/huggingface路径下。
export HF_HOME="/yourpath"uv run scripts/compute_norm_stats.py --config-name pi0_fast_libero最后可以开始训练
---更新3.22---
更改参数设置,这里微调需要的显存如下。
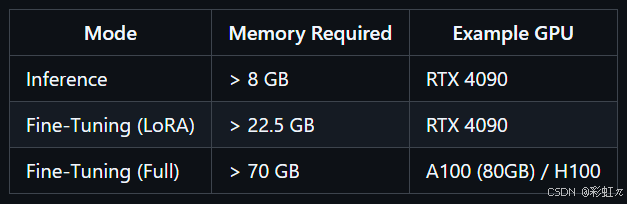
一个batch_size需要的显存就需要22.5GB,我这里有两个4090,batch_size的大小我设置为2,微调时显存占用为45G左右。同时需要更改trainconfig的参数。(这里不用更改,其实下面的pi0_fast_libero_low_mem_finetune提供了lora微调的版本)
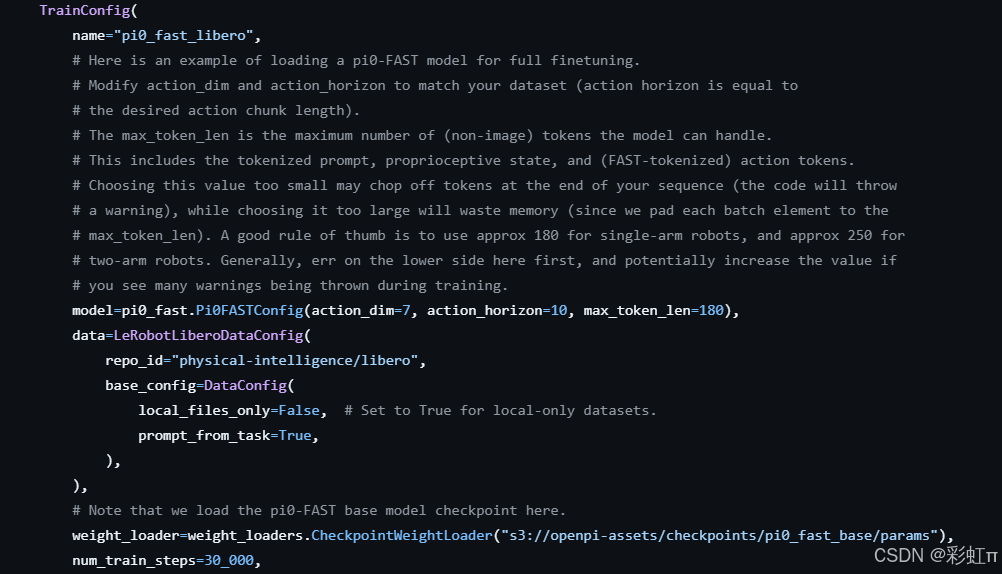
model=pi0_fast.Pi0FASTConfig(action_dim=7, action_horizon=10, max_token_len=180, paligemma_variant="gemma_2b_lora"),上面的trainconfig有参考,可以根据上面的修改。主要pi0_fast.py的下面没用到action_expert_variant。再在后面添加这行代码。
freeze_filter=pi0_fast.Pi0FASTConfig(
paligemma_variant="gemma_2b_lora"
).get_freeze_filter(),
# Turn off EMA for LoRA finetuning.
ema_decay=None,lora微调的设置就成功了,如果有大显存也可以不修改这里。然后运行
XLA_PYTHON_CLIENT_MEM_FRACTION=0.9 uv run scripts/train.py pi0_fast_libero --exp-name=my_experiment --overwrite我这里设置40000步,大概需要10个小时。

三.启动策略服务器并进行推理
---3.24更新---
首先下载libero数据集(原版的,这里感觉好混乱,已经下载了两个libero数据集了),可以选择性下载,我这里下载了两个libero_10和libero_spatial, --include后面跟文件夹名称。
huggingface-cli download --repo-type dataset yifengzhu-hf/LIBERO-datasets --local-dir /hy-tmp/huggingface/libero-datasets/datasets/ --include "libero_spatial/"根据openpi提供的示例,先安装依赖。
# Create virtual environment
uv venv --python 3.8 examples/libero/.venv
source examples/libero/.venv/bin/activate
uv pip sync examples/libero/requirements.txt third_party/libero/requirements.txt --extra-index-url https://download.pytorch.org/whl/cu113 --index-strategy=unsafe-best-match
uv pip install -e packages/openpi-client
uv pip install -e third_party/libero
export PYTHONPATH=$PYTHONPATH:$PWD/third_party/libero
# Run the simulation
python examples/libero/main.py后面的程序先不要运行。先修改scripts/serve_policy.py文件,主要修改点就是下面的几行代码。我这里num_trials_per_task: int = 3,提供的是50,但是推理一次libero_10需要10分钟。10个任务,每个任务推理50次,大概就需要100小时,太漫长了。
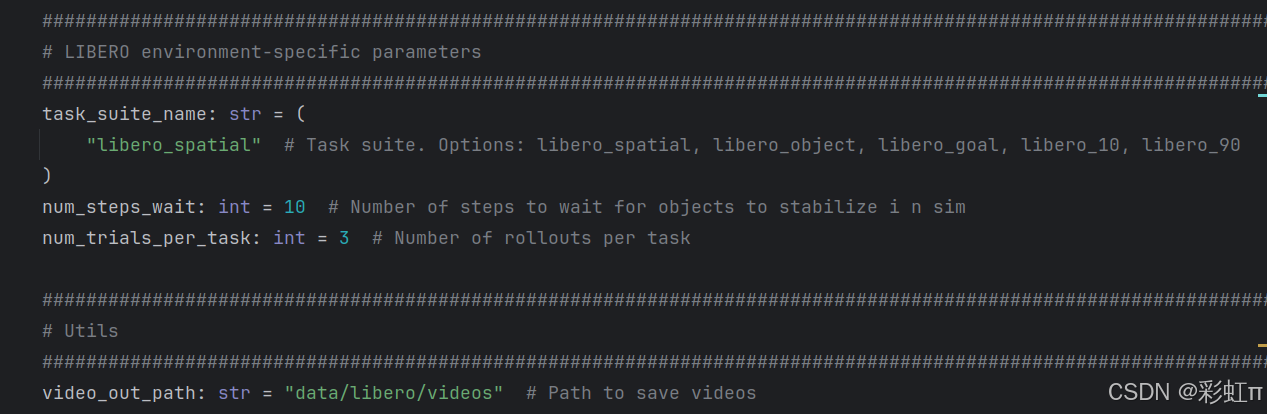
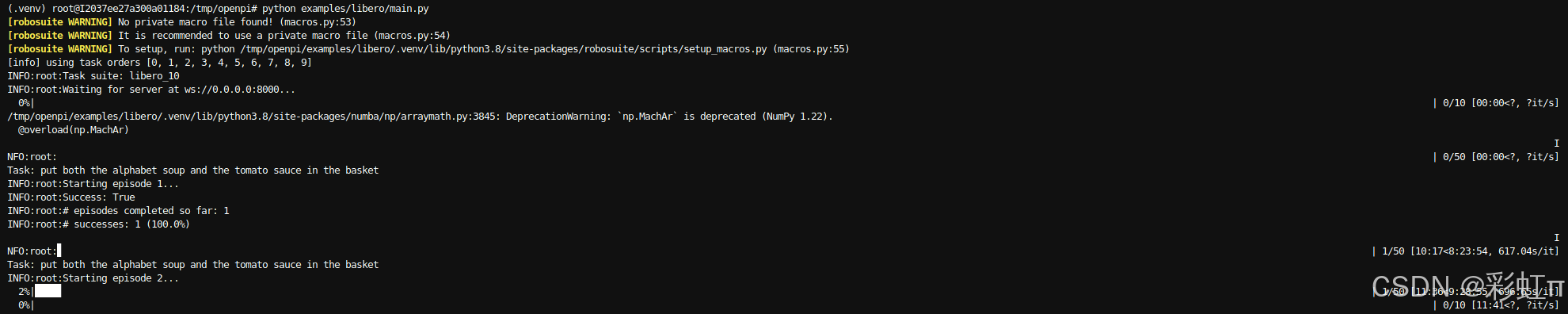 先启动服务,我这里使用迭代39999的检查点。之前训练时设置的num_train_steps。
先启动服务,我这里使用迭代39999的检查点。之前训练时设置的num_train_steps。
uv run scripts/serve_policy.py policy:checkpoint --policy.config=pi0_fast_libero --policy.dir=/hy-tmp/checkpoints/pi0_fast_libero/my_experiment/39999终端输出INFO:websockets.server:server listening on 0.0.0.0:8000就启动成功了,然后在另一个终端运行上面的main函数。
python examples/libero/main.py成功运行,总体大概需要2小时。

如果运行main函数提示AttributeError: 'NoneType' object has no attribute 'eglQueryString'。则运行
sudo apt update
sudo apt install -y libegl1 libegl1-mesa libgles2-mesa-dev libgl1-mesa-glx

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)