阿里SenseVoice -语音识别模型本地部署
SenseVoice是一款多功能语音基础模型,支持语音识别(ASR)、语言识别(LID)、情感识别(SER)和事件检测(AED)。提供大小两个版本:Small版轻量高效,推理速度比Whisper快7-17倍;Large版支持更多语言且识别更精准。推荐使用RTX2080Ti及以上显卡部署,实测RTX4060Ti16G运行良好。该模型在智能客服、医疗转录、教育司法等领域有广泛应用,支持中英日韩及粤语识
·
目录
2.2.SenseVoice-Large和SenseVoice-Small模型对比
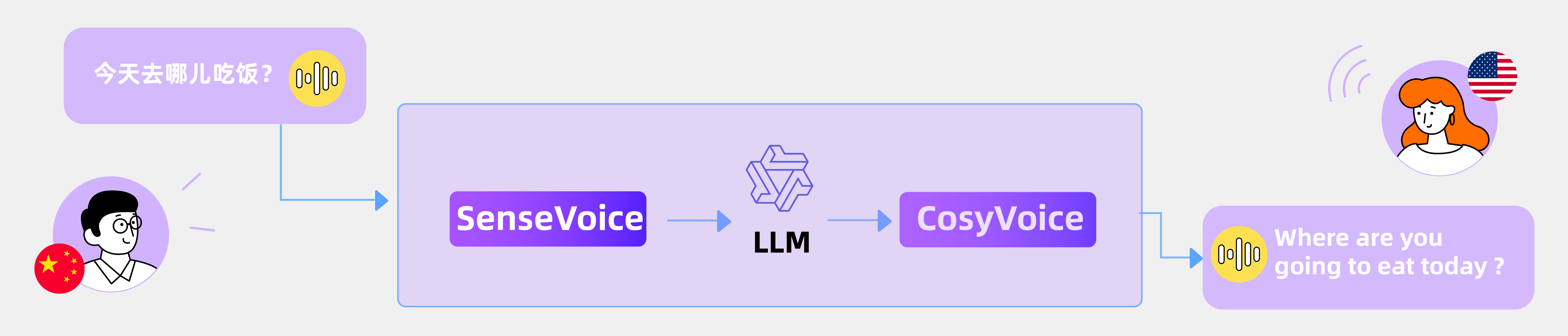
1.基本介绍
1.1 功能介绍
SenseVoice 是一个具有多种语音理解能力的语音基础模型,包括语音识别(ASR)、语言识别(LID)、语音情感识别(SER)和语音事件检测(AED) 。
目前SenseVoice 提供两个主要版本, 支持中文、英文、粤语、日语、韩语识别:
|
模型 |
架构 |
特点 |
|
SenseVoice-Small |
仅含编码器 |
轻量级、推理极快,适合实时场景 |
|
SenseVoice-Large |
编码器+解码器 |
支持更多语言,识别更精准 |
整体架构:
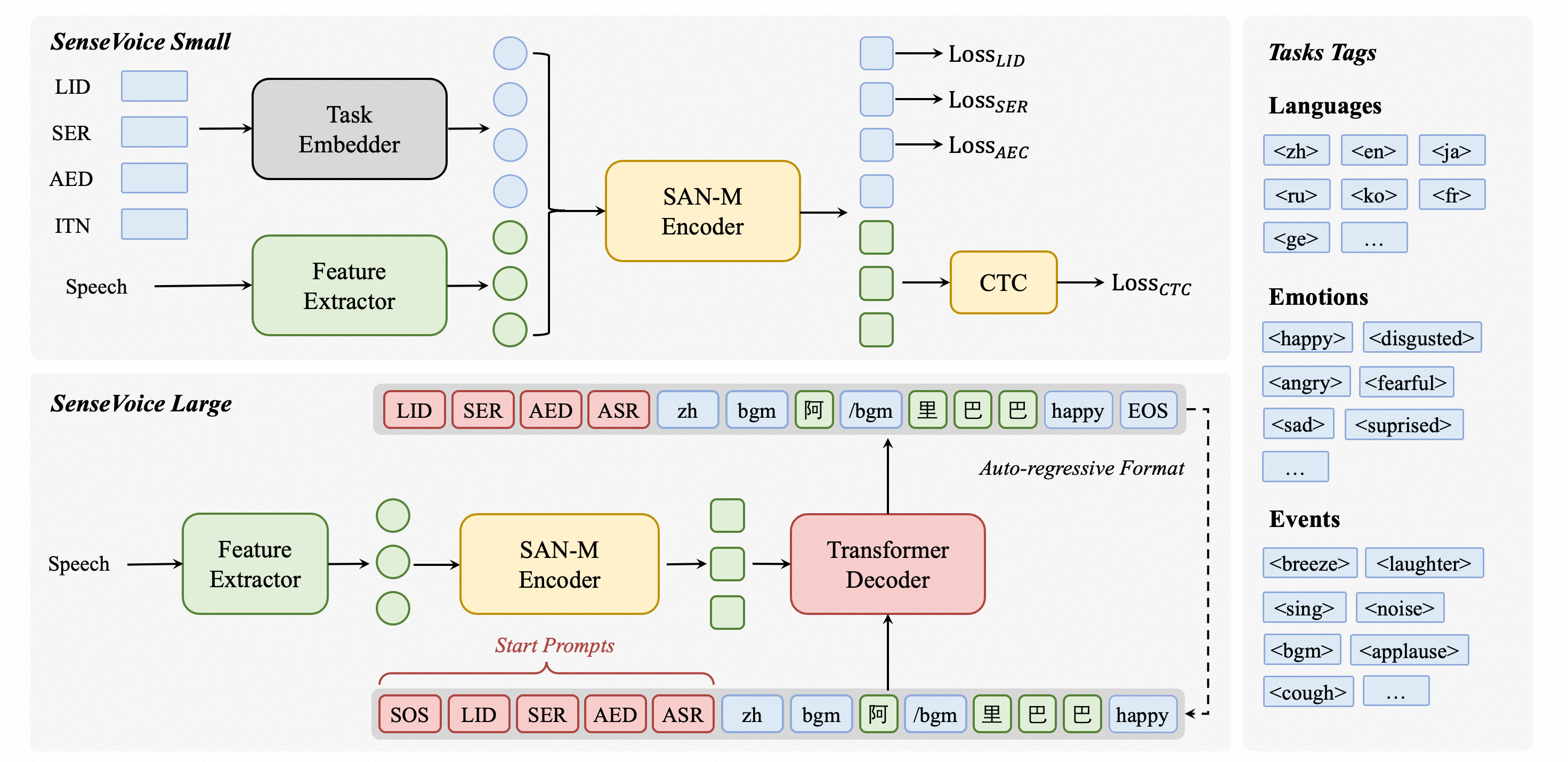
1.2 电脑配置要求:
推荐配置
- 显卡:NVIDIA GeForce RTX 2080 Ti 或更高
- 显存:至少 12GB(实测 RTX 4060 Ti 16G 完美运行)
1.3 地址:
官网地址:
开源项目地址:
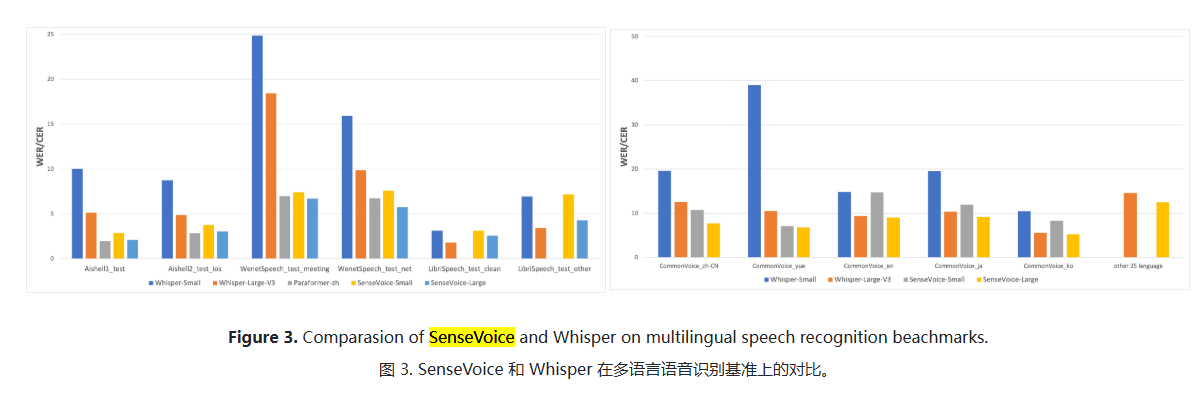
2.效果对比
2.1.与Whisper对比
对比了 SenseVoice 和 Whisper 在开源基准数据集上的多语言识别性能和推理效率,包括 AISHELL-1、AISHELL-2、Wenetspeech、Librispeech 和 Common Voice。推理效率评估使用 A800 机器进行。SenseVoice-small 采用非自回归端到端架构,导致推理延迟极低—— 比 Whisper-small 快 7 倍,比 Whisper-large 快 17 倍。
2.2.SenseVoice-Large和SenseVoice-Small模型对比

3.安装部署
本文使用windows部署,部署 SenseVoice-Small,显卡4060TI 16G
3.1 安装python环境
#创建python虚拟环境
cd SenseVoice/
# 创建一个名为venv 的虚拟环境。
python -m venv .venv
#进入虚拟环境
.venv\Scripts\activate
#安装依赖
pip install -r requirements.txt3.2 模型下载
modelscope download --model iic/SenseVoiceSmall --local_dir model/iic/SenseVoiceSmall
modelscope download --model iic/speech_fsmn_vad_zh-cn-16k-common-pytorch --local_dir model/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch3.3 部署成功
#切换到虚拟环境才能运行
.\.venv\Scripts\activate
#运行webui用这个
python webui.py
#运行demo用这个
#python demo1.py
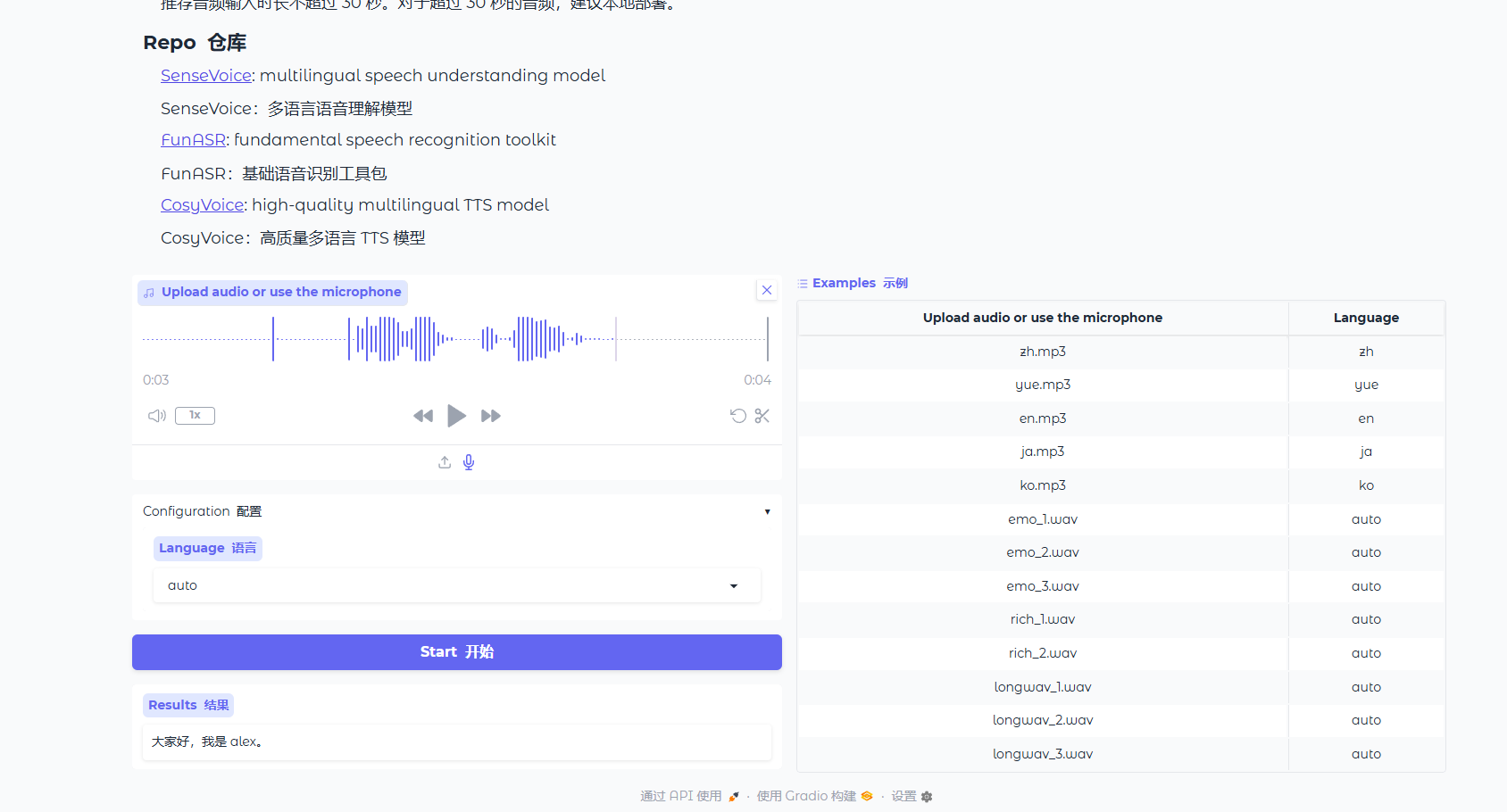
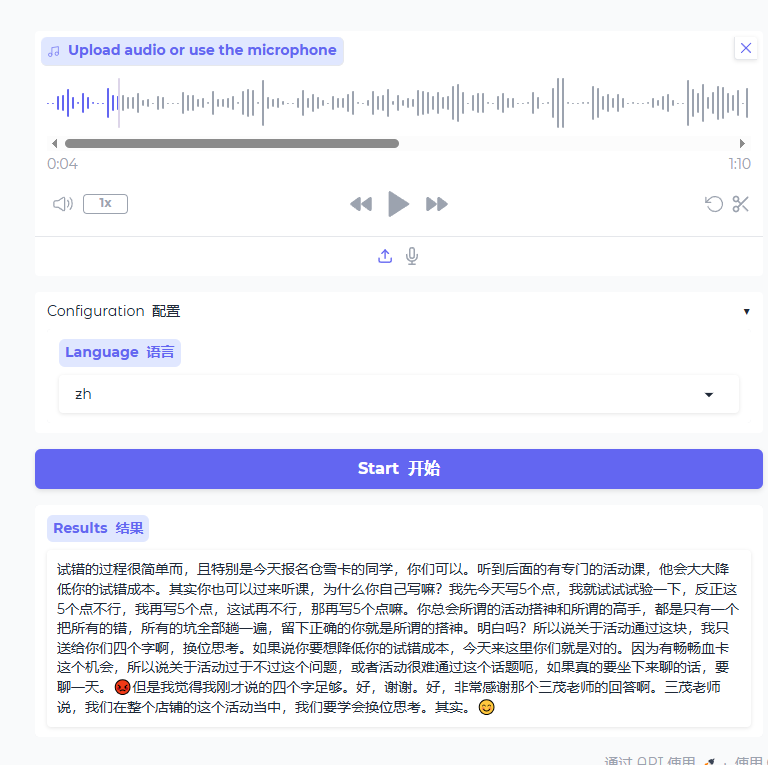
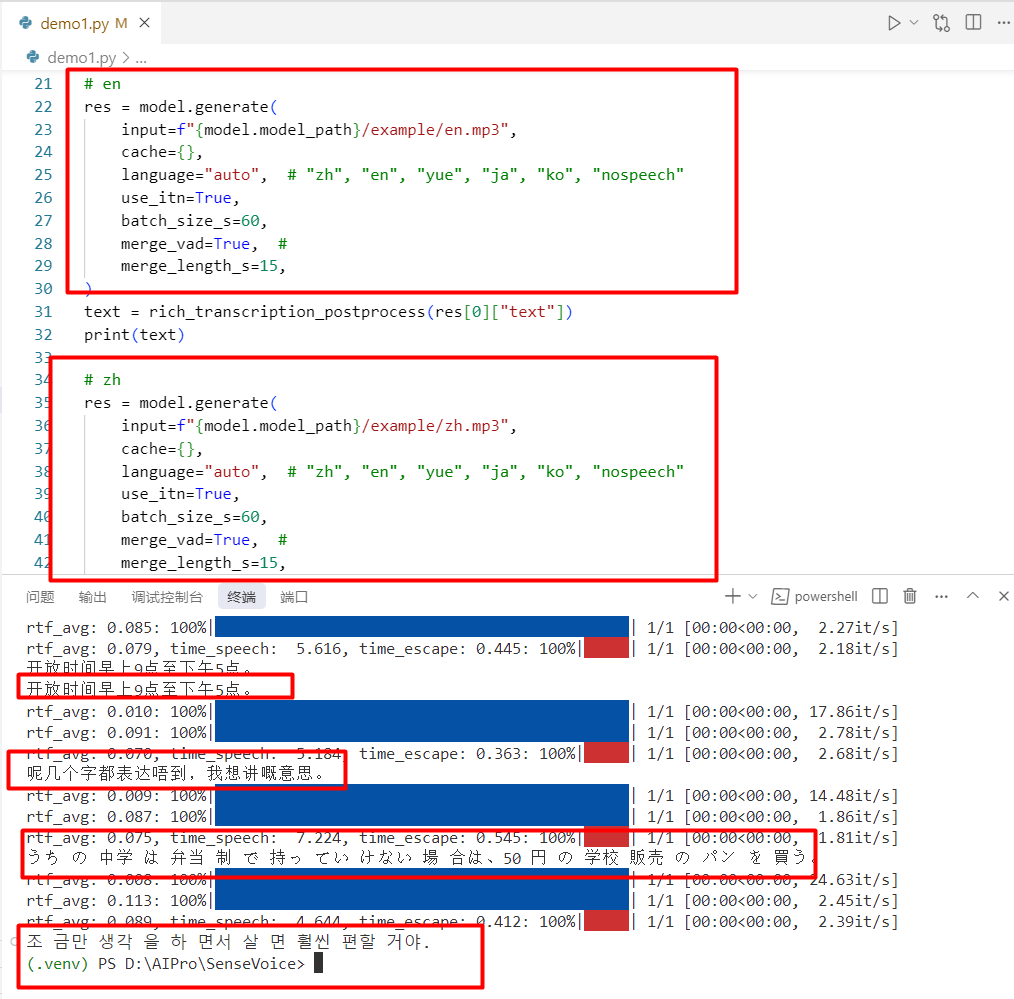
4.使用效果
效果总结:
1.语音内容大部分都能识别,但有些上下文特殊内容识别错误
2.语音识别速度很快,1秒内识别成功
3.支持主流语言(中、英、日、韩)和粤语
5.应用场景
SenseVoice 的多功能集成使其在多个行业具有广泛应用前景:
- 智能客服:自动质检 + 情绪分析,提升服务质量
- 医疗录音:快速转录病历、问诊记录
- 教育领域:课堂语音转文字
- 司法庭审:高效生成庭审笔录
- 媒体内容生产:自动字幕生成、音视频内容结构化

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)