部署本地大模型(三)_AnythingLLM
部署本地大模型(三)_AnythingLLM
官方网址:https://anythingllm.com/desktop
一、AnythingLLM安装
1.1 下载windows版本安装包
1.2 具体安装页面步骤
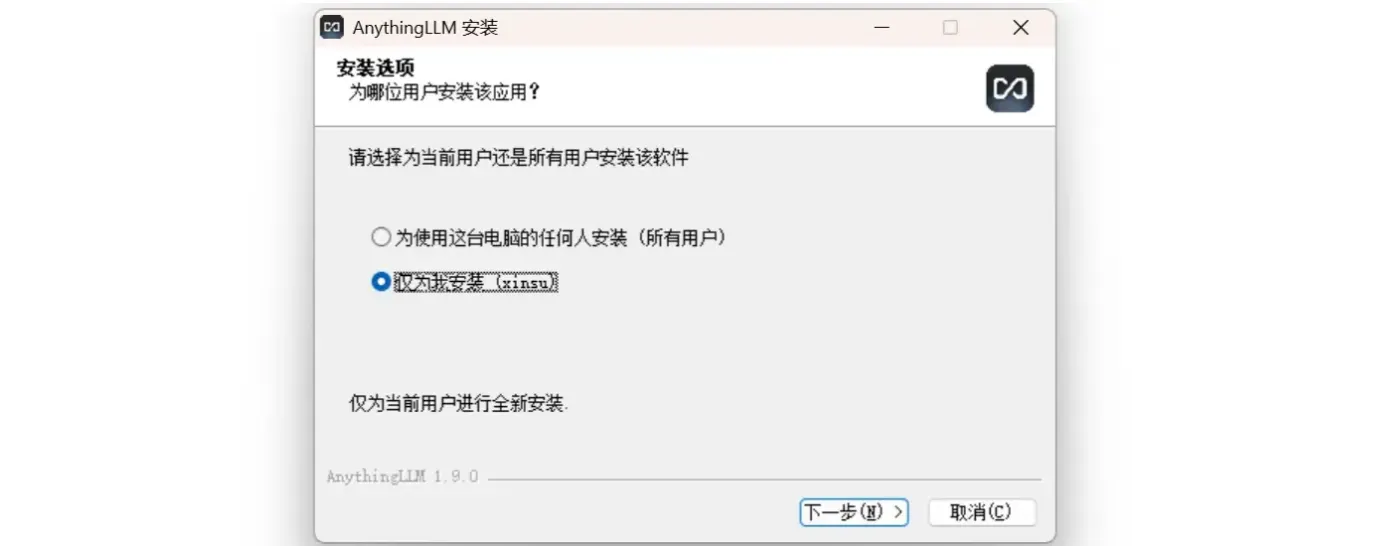
选择路径
安装中
二、新建对话模型配置
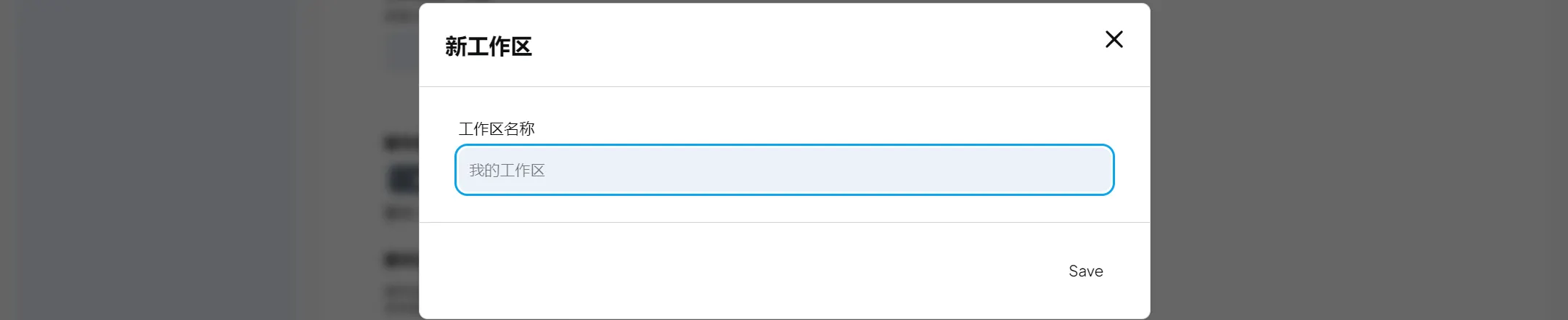
2.1 新建工作区
2.2 聊天设置
(1)选择LLM提供商Ollama
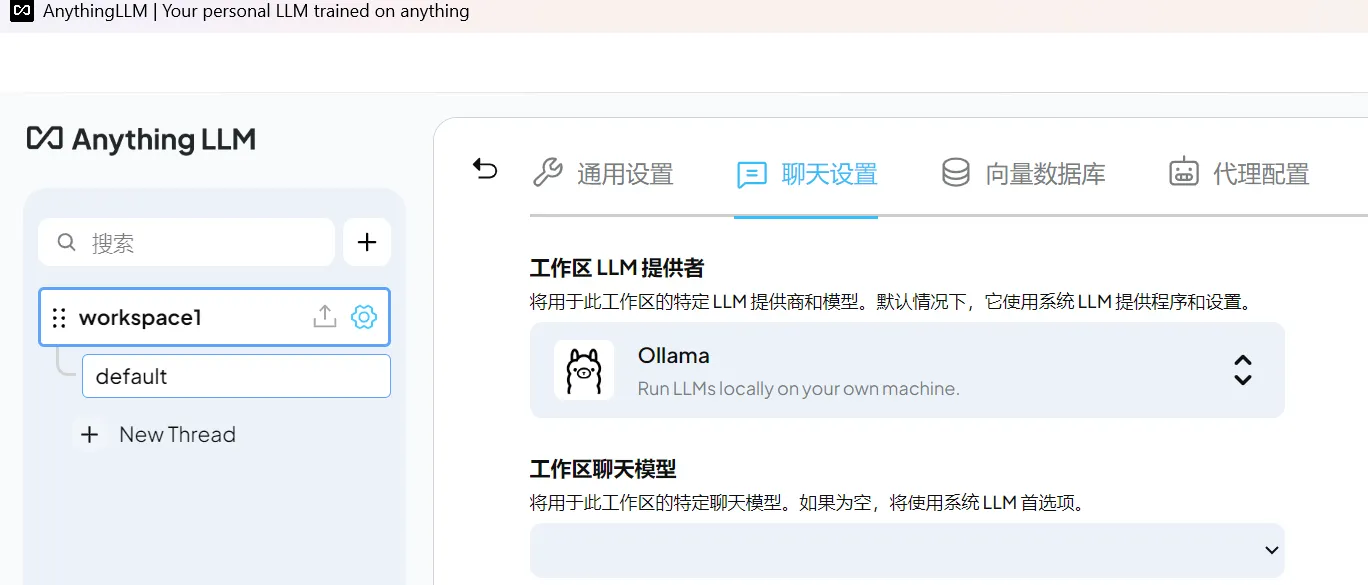
Ollama 是一个本地部署的 LLM 管理工具,支持运行多种大语言模型(如 Llama3、Mistral、Gemma 等),可在本地环境下实现快速、私密的对话推理。
选择 Ollama 作为提供商后,软件会与本地 Ollama 服务进行连接,用于后续的聊天和知识问答功能。
(2)开启Ollama服务
可见工作区聊天模型为空,因未开启Ollama后台服务,详情见 Ollama install 那篇文章。
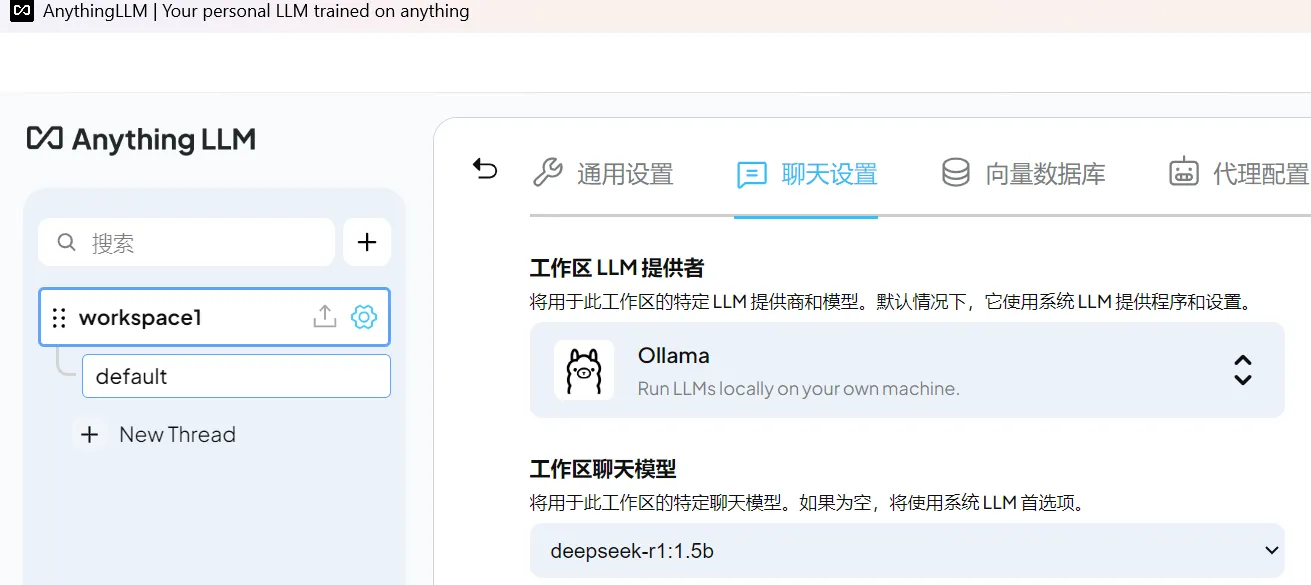
先选别的LLM提供者,后,再点击Ollama则自动识别出已有模型deepseek-r1:1.5b
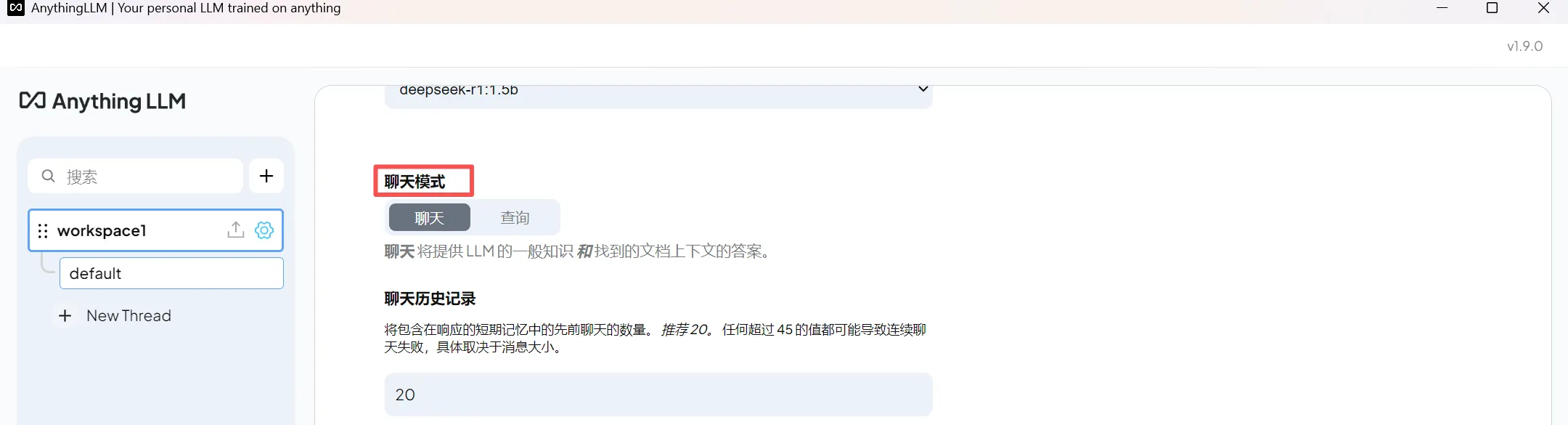
(3)选择聊天模式
聊天:聊天将提供 LLM 的一般知识和找到的文档上下文的答案。
查询:查询将会提供答案仅当找到文档上下文时。
(4)编写系统提示词
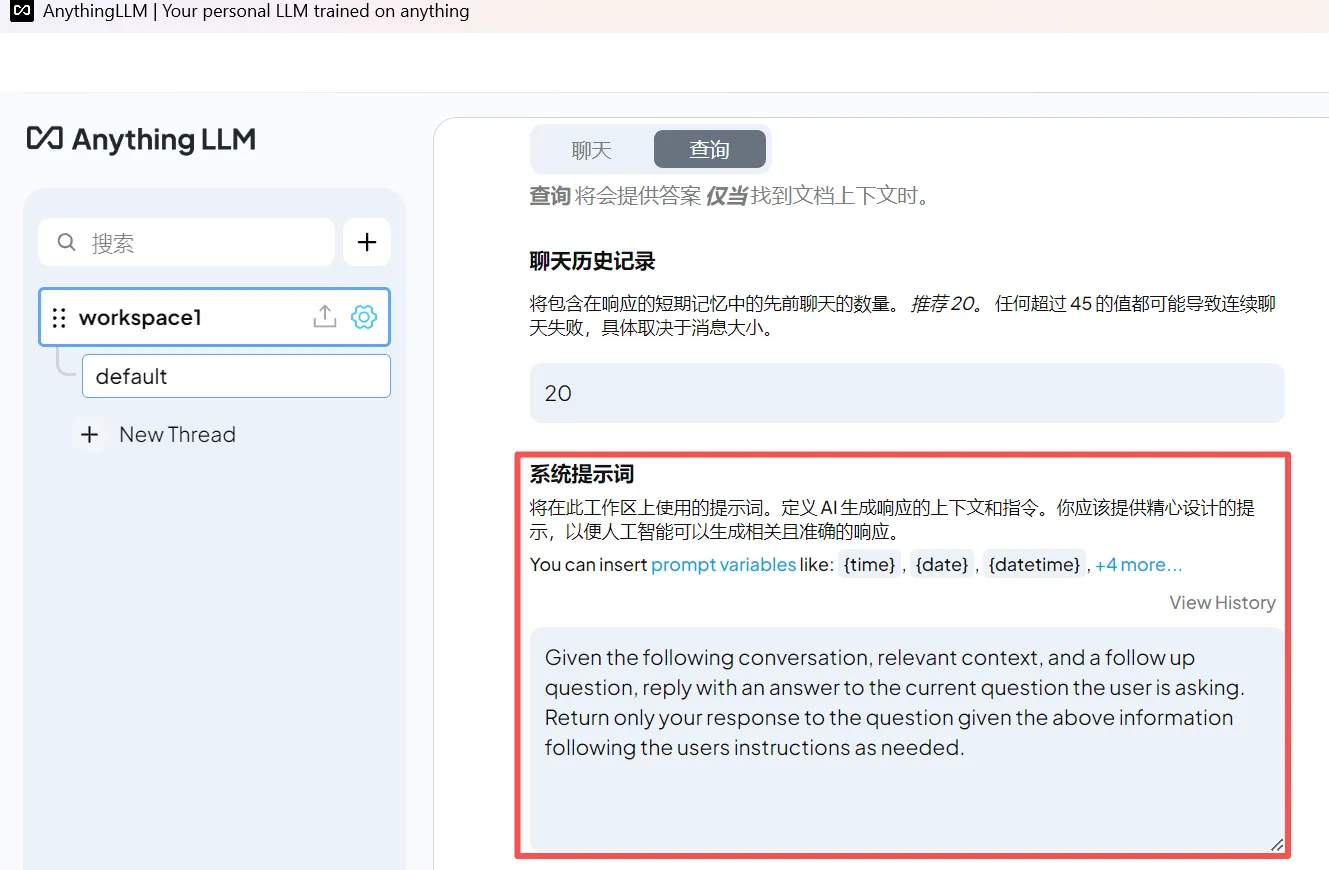
系统提示词(System Prompt)用于为聊天模型设定角色、语气和任务目标,是对模型行为的全局引导。
例如,可以指定模型的身份(如“你是一个专业的文档助手”)或使用场景(如“帮助用户总结PDF内容并生成问答”)。
合理的提示词可以让模型更准确地理解上下文,提高回复的相关性和稳定性。
三、上传文件
3.1 为什么要上传文件
在普通聊天中(比如 ChatGPT 或 Ollama 命令行),模型:
- 只能根据预训练知识回答;
- 对你的项目、公司文档、笔录文件等一无所知;
- 聊天结束后不会“记住”上下文。
而 AnythingLLM 的目标是:
给每个对话一个“专属知识库”,
让大模型在回答时能引用你上传的文件内容。
3.2 工作机制示意(流程)
1、上传文件 → AnythingLLM 解析文本 → 生成语义向量存入数据库
↓
2、提问 → 生成问题向量 → 检索最相关内容
↓
3、系统把检索到的内容和你的问题一起交给大模型
↓
4、模型回答,并标注引用来源
3.3 上传步骤
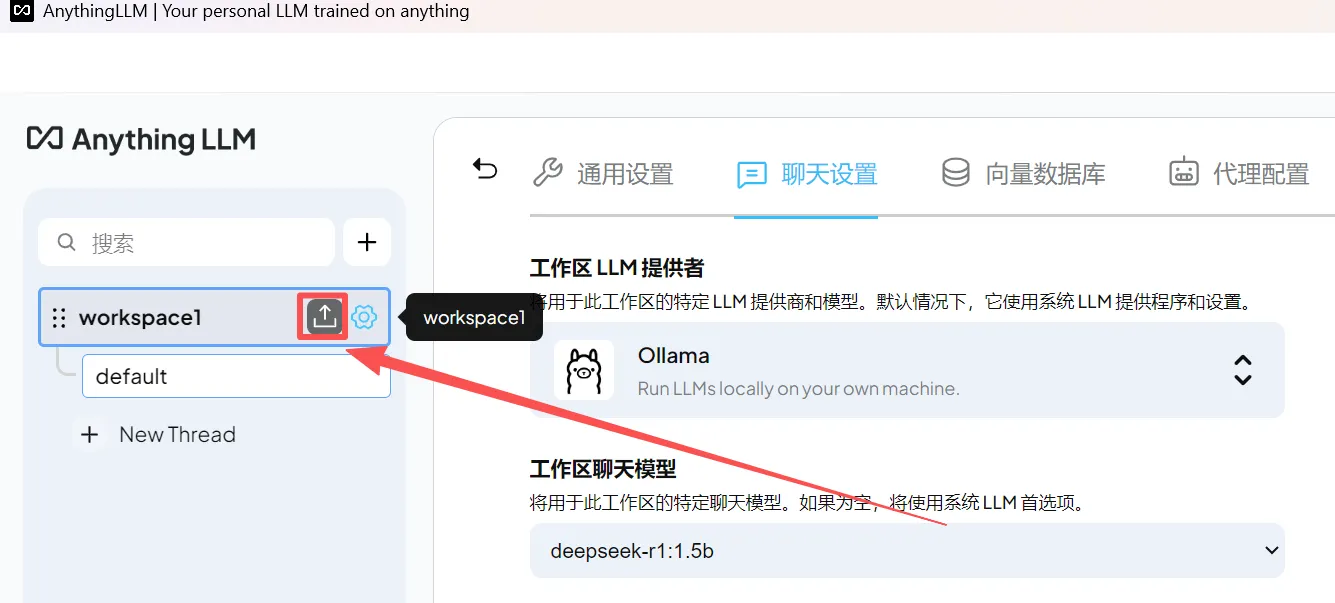
(1)点击工作区的上传
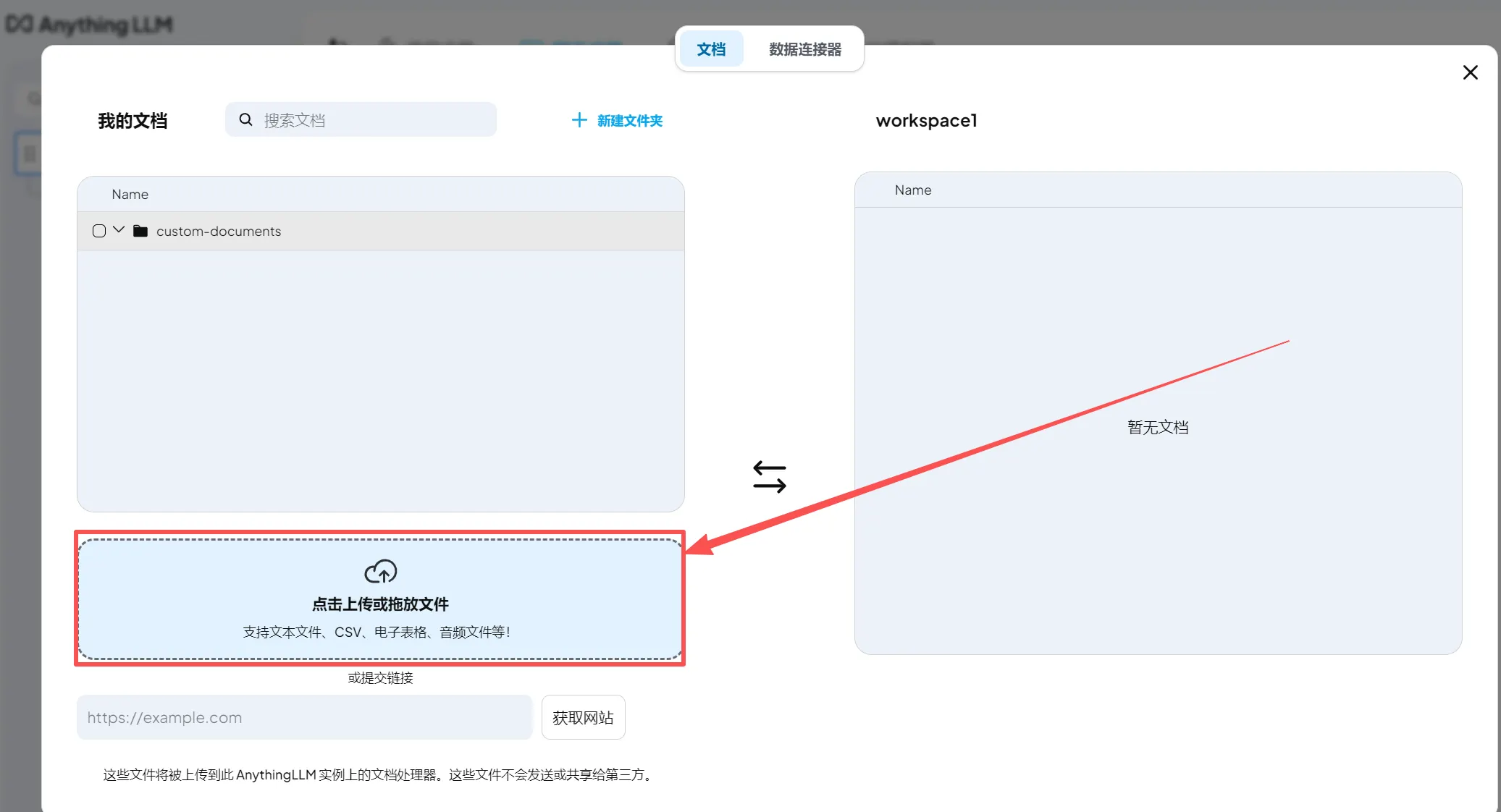
(2)选择上传文件
(3)选中文件移动到工作区
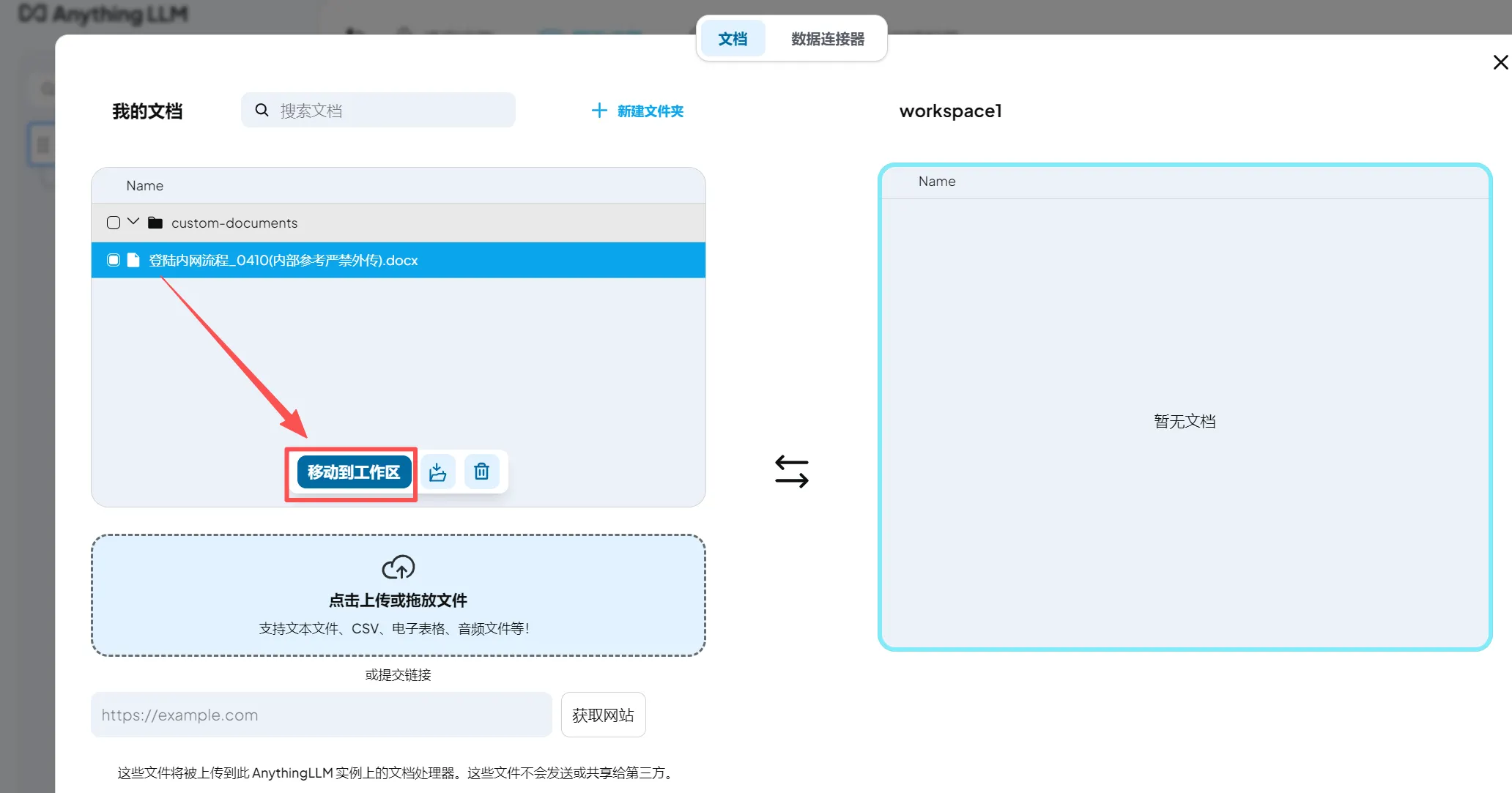
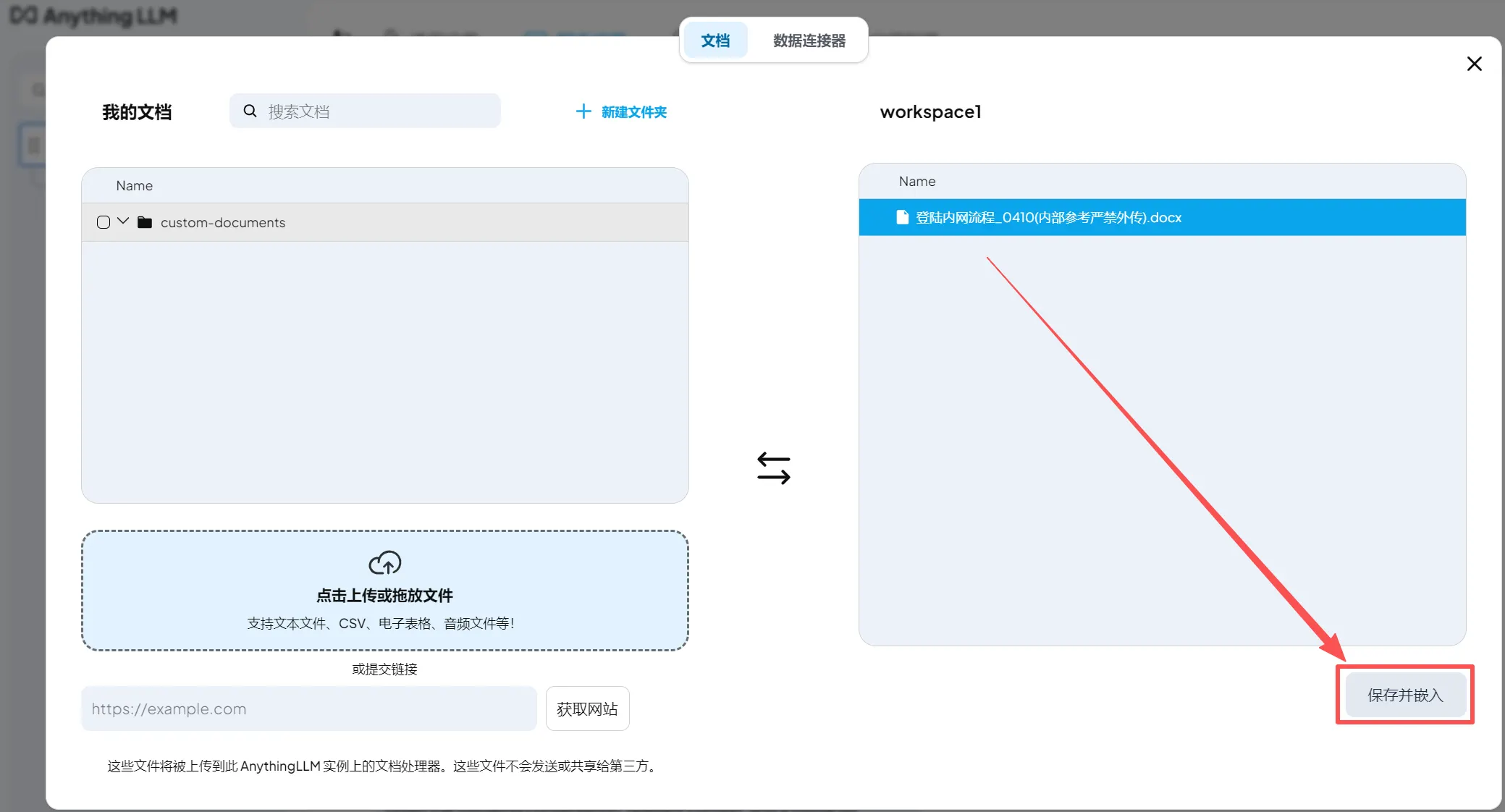
(4)保存并嵌入
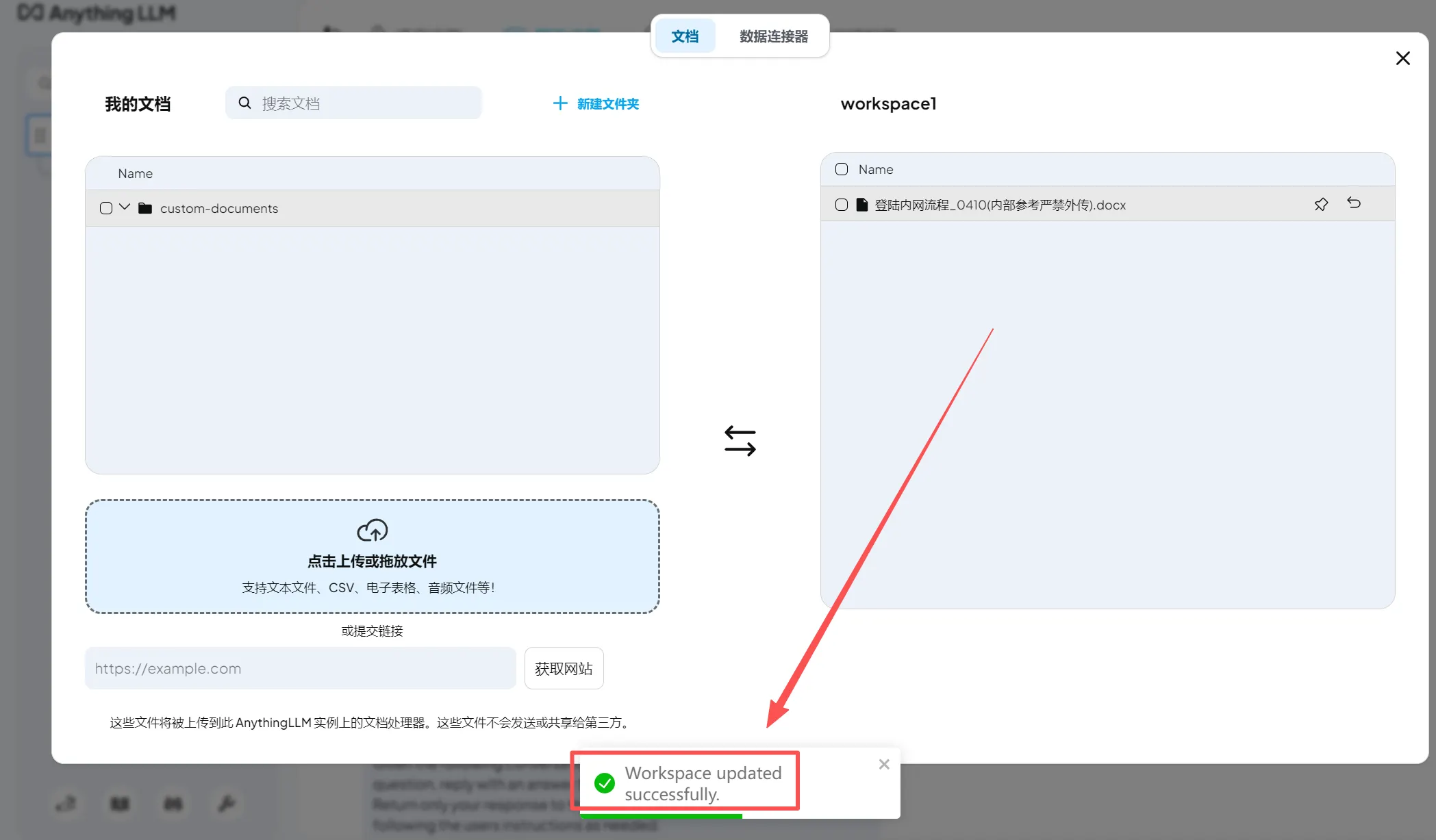
操作成功
四、对话测试
4.1 基础模型对话
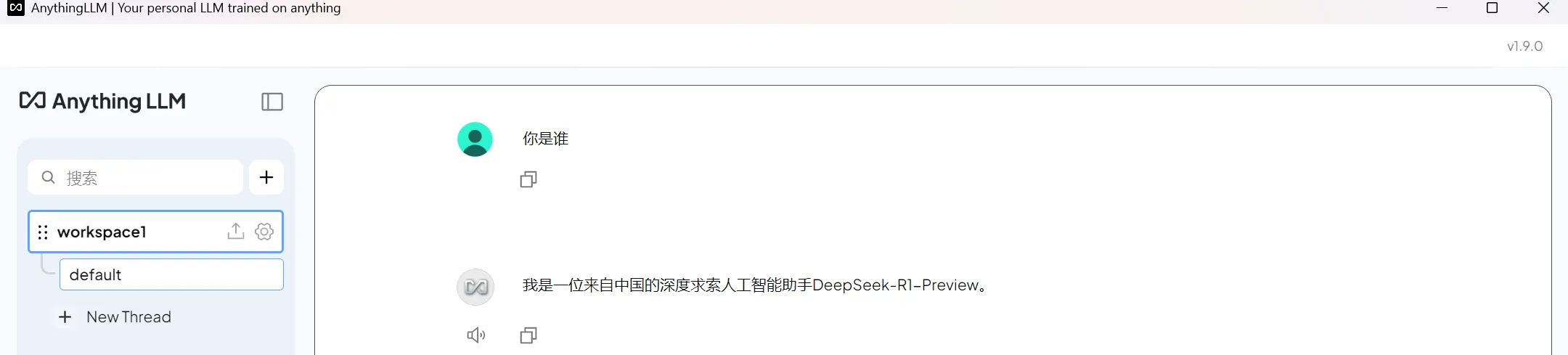
就是速度有点慢,因为本地资源有限。
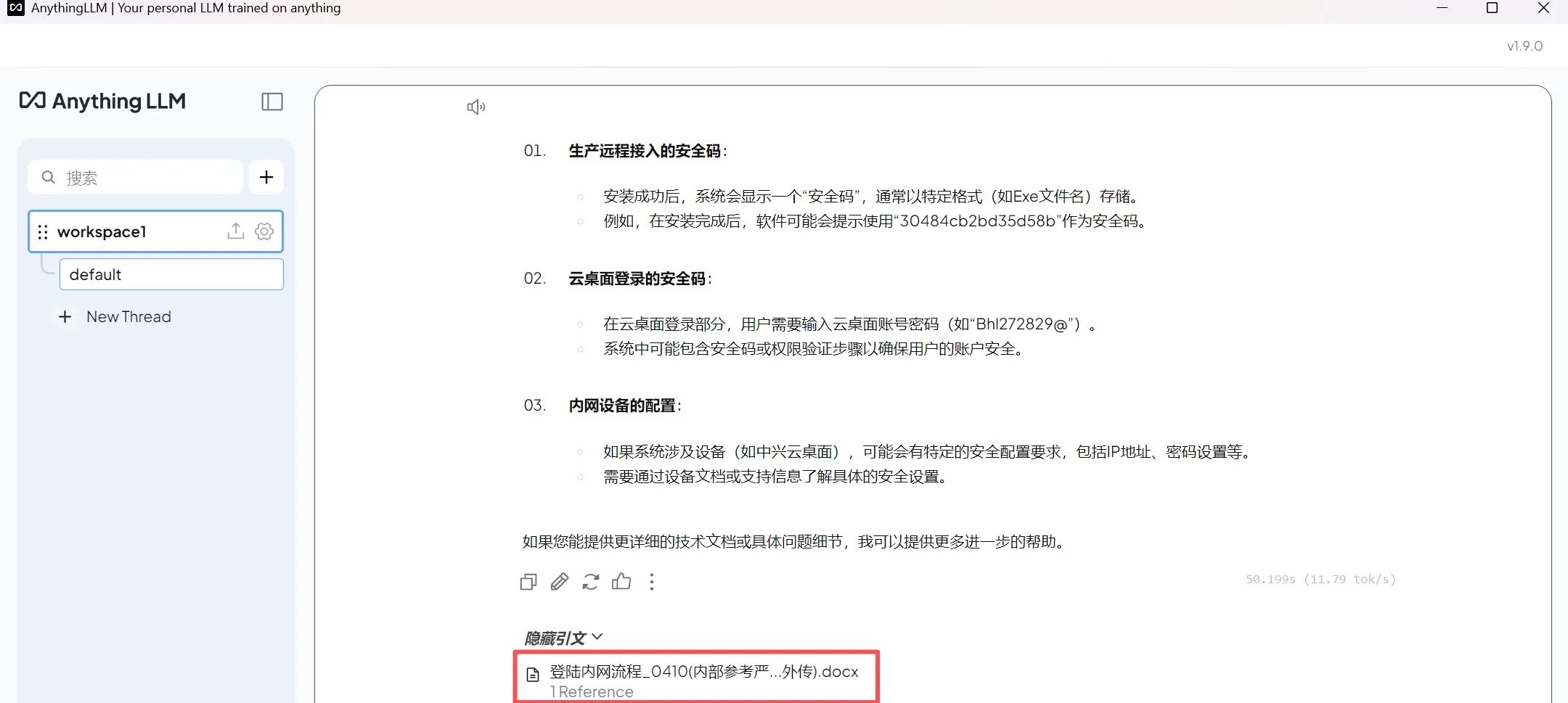
4.2 触发上传文件对话测试
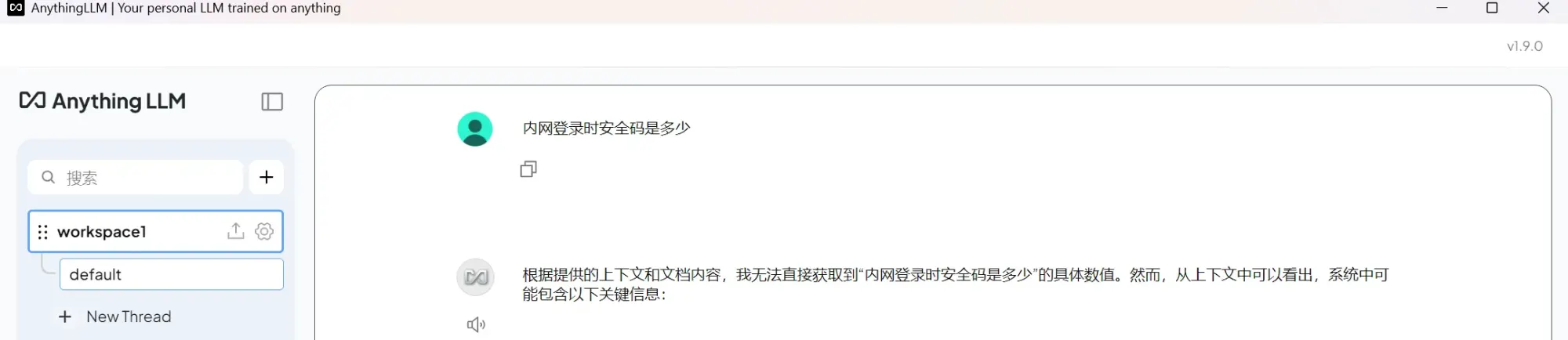
可以查看引文
五、配置向量库模型(可选)
AnythingLLM不会强制要求一定要有外部 embedding 模型。
如果没有配置独立 embedding 模型,它会使用默认方案来替代。但是效果一般。
5.1 安装向量模型
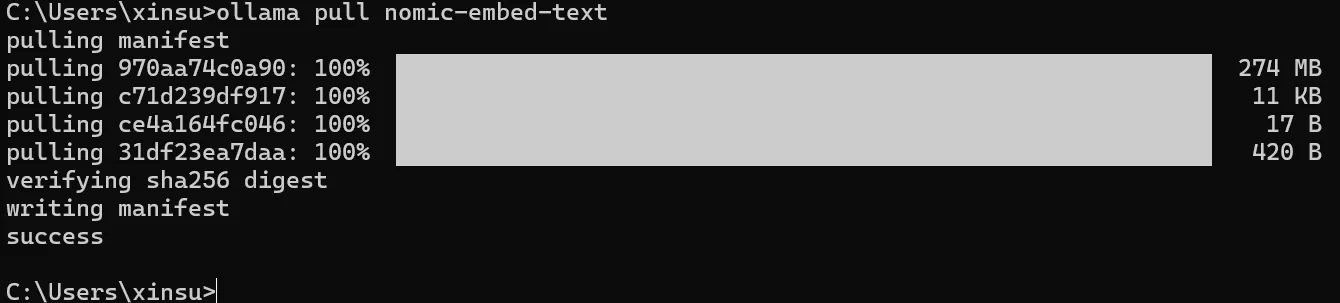
因之前选择的模型提供方是Ollama,所以这里也选择了他们的向量模型
在命令行安装
ollama pull nomic-embed-text

下载完成后
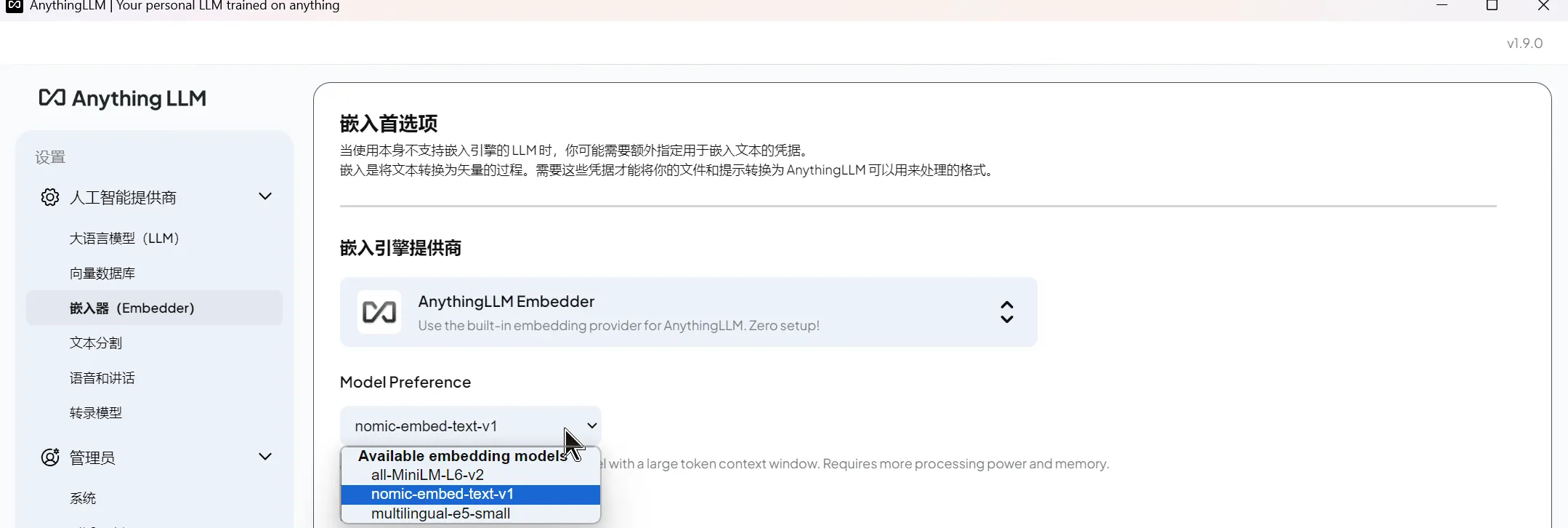
5.2 配置嵌入器
设置-人工智能提供商-嵌入器

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)