【医学影像 AI】nnU-Net:一种用于生物医学图像分割的深度学习方法
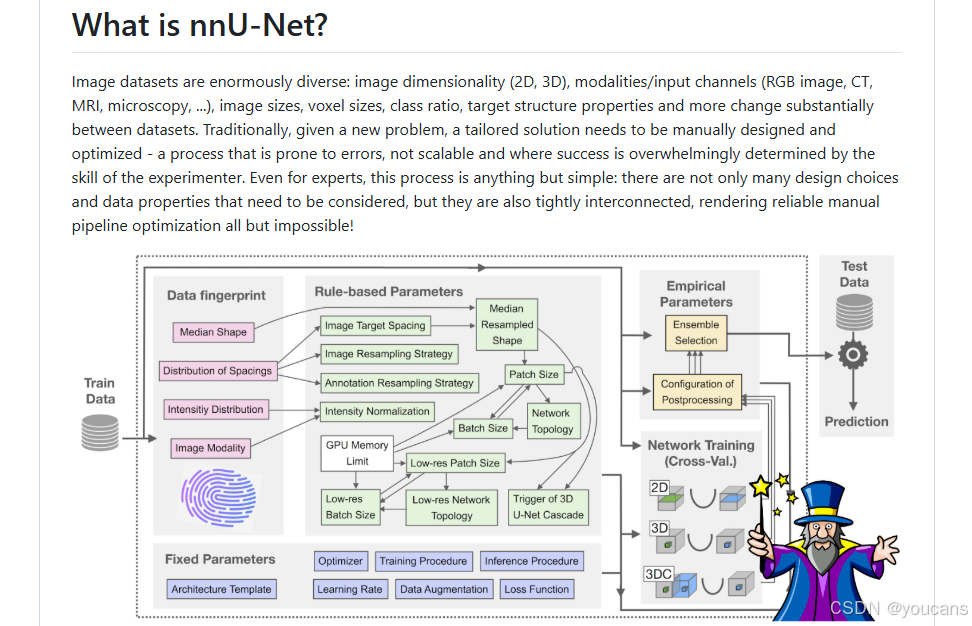
nnU-Net,一种用于生物医学图像分割的深度学习方法,它可以为任何新任务自动配置。关键的创新在于将复杂的手动方法配置流程系统化为固定参数、基于数据集属性的规则参数以及最少的经验参数进行优化。通过自动配置, nnU-Net极大地降低了将深度学习应用于生物医学图像分割任务的门槛。
【医学影像 AI】nnU-Net:一种用于生物医学图像分割的深度学习方法
0. 论文简介
0.1 基本信息
2020 年 Isensee, F. 等在 Nature Methods 发表论文 “nnU-Net:一种用于生物医学图像分割的深度学习方法(nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation)”。
本文提出了nnU-Net,一种用于生物医学图像分割的深度学习方法,它可以为任何新任务自动配置。nnU-Net 在许多国际分割挑战中都能达到最先进的性能,超越了专门为这些任务开发的特化流水线。
关键的创新在于将复杂的手动方法配置流程系统化为固定参数、基于数据集属性的规则参数以及最少的经验参数进行优化。总的来说, 通过自动配置, nnU-Net极大地降低了将深度学习应用于生物医学图像分割任务的门槛。
论文下载: nature
项目下载:github-nnUNet
引用格式:
Isensee, F., Jaeger, P. F., Kohl, S. A., Petersen, J., & Maier-Hein, K. H. (2021). nnU-Net: a self-configuring
method for deep learning-based biomedical image segmentation. Nature methods, 18(2), 203-211. https://doi.org/10.1038/s41592-020-01008-z
数据可用性
本研究中使用的所有23个数据集均公开可用,并可通过各自的挑战网站访问。D1-D10 医学分割十项挑战,http://medicaldecathlon.com/;D11 超颅骨(BCV)-腹部,https://www.synapse.org/#!Synapse:syn3193805/wiki/;D12 PROMISE12,https://promise12.grand-challenge.org/;D13 ACDC,https://acdc.creatis.insa-lyon.fr/;D14 LiTS,https://competitions.codalab.org/competitions/17094;D15 MSLes,https://smart-stats-tools.org/lesion-challenge;D16 CHAOS,https://chaos.grand-challenge.org/;D17 KiTS,https://kits19.grand-challenge.org/;D18 SegTHOR,https://competitions.codalab.org/competitions/21145;D19 CREMI,https://cremi.org/;D20-D23 细胞追踪挑战,http://celltrackingchallenge.net/。
代码可用性
nnU-Net 代码库作为补充软件提供。更新版本可在 https://github.com/mic-dkfz/nnunet 获取。本研究中使用的所有数据集的预训练模型均可在 https://zenodo.org/record/3734294 下载。

0.2 论文速览
本文内容
- 本文提出了nnU-Net,这是一种用于生物医学图像分割的深度学习方法,它可以为任何新任务自动配置自己。
- nnU-Net在许多国际分割挑战中都能达到最先进的性能,超越了专门为这些任务开发的特化流水线。
- 关键的创新在于将复杂的手动方法配置流程系统化为固定参数、基于数据集属性的规则参数以及最少的经验参数进行优化。
- nnU-Net使用了一个简单的U-Net架构,但通过良好的配置超过了更复杂的方法。
- 在nnU-Net的开发和评估中使用了23个公开的生物医学图像数据集,包含了广泛的成像模式、目标结构和图像属性。
- 作为一个开源工具,nnU-Net可以开箱即用,无需专业知识去适配和优化流水线,就可以进行最先进的分割。
- 总的来说, 通过自动配置, nnU-Net极大地降低了将深度学习应用于生物医学图像分割任务的门槛。
方法流程
nnU-Net的方法流程可以简述如下:
- 从训练数据中提取数据集特征(fingerprint),包括图像大小、体素间距、模态等信息。
- 根据数据集特征,使用一系列经验规则自动配置分割流水线的参数,如预处理、网络拓扑结构、训练策略等。这些规则参数编码了领域知识。
- 将未涵盖的少量参数(如模型选择、后处理)设置为在训练中经验优化。
- 使用默认的U-Net网络架构模板训练多个模型。
- 通过交叉验证,从训练好的多个模型中经验选择表现最好的单模型或模型组合。
- 如果后处理能提高验证性能,则应用后处理。
- 最终获得自动配置的、适用于该特定任务的分割流水线。
- 将流水线应用于测试数据,获得分割结果。
整个流程全自动完成,不需要人工干预。
0.3 摘要
生物医学成像是科学研究的驱动力,是医疗护理的核心组成部分,并受到深度学习领域的推动。虽然语义分割算法在许多应用中实现了图像分析和量化,但针对特定任务设计相应的专门解决方案并不简单,且高度依赖于数据集特性以及硬件条件。
我们开发了 nnU-Net,这是一种基于深度学习的分割方法,能够自动配置包括预处理、网络架构、训练和后处理在内的所有内容,适用于任何新任务。
在这个过程中,关键的设计选择被建模为一组固定的参数、相互依赖的规则和经验性决策,无需人工干预。
nnU-Net 超越了大多数现有方法,包括在国际生物医学分割竞赛中使用的 23 个公开数据集中的高度专门化解决方案。
我们公开发布了 nnU-Net,作为一种即用型工具,通过要求无需专家知识且仅需标准网络训练所需的基本计算资源,使最先进的分割技术对广泛的用户群体变得可用。
1. 引言
语义分割将原始的生物医学图像数据转化为有意义的空间结构信息,因此在科学研究中扮演着至关重要的角色[1,2]。同时,语义分割是众多临床应用的重要组成部分[3,4],包括人工智能在诊断支持系统[5,6]中的应用、治疗计划支持[7]、术中辅助[2]以及肿瘤生长监测[8]。对自动分割方法的高兴趣体现在生物医学领域国际图像分析竞赛中蓬勃发展的研究景观上,这些竞赛中有70%与自动分割方法相关[9]。
尽管基于深度学习的分割方法取得了近期的成功,但这些方法在特定用户图像分析问题中的应用往往受到限制。针对特定任务的方法设计和配置需要高水平的专业知识和经验,即使是小的错误也可能导致性能大幅下降[10]。特别是在三维(3D)生物医学成像中,由于成像模态、图像大小、(各向异性)体素间距和类别比例等数据集特性差异巨大,这一过程可能变得复杂,从一个数据集的成功配置很少能直接应用于另一个数据集[10]。在适应和训练神经网络时涉及的众多专家决策范围从精确的网络架构到训练计划和数据增强或后处理方法。每个相互依赖的子组件都由诸如学习率、批量大小或类别采样策略等关键参数控制[10]。整体设置中的额外复杂性来自于可用于训练和推理的硬件[11]。在自动机器学习(AutoML)领域之前的研究中提出的纯粹经验优化方法,在高维空间中大幅增加了所需训练案例的数量以及计算资源的数量,并且通常仅覆盖分割流水线的一小部分(如架构或数据增强),将很大一部分配置留给实验者[12]。此外,将AutoML应用于新数据集时,还需要做出一系列专家选择,例如当考虑构建合理的问题特定搜索空间时[12]。根据我们对国际生物医学分割挑战现状的分析(结果),这些实际限制通常使用户在方法设计过程中处于手动和迭代的试错过程之中,这一过程主要由个人经验驱动,很少有详细的记录,往往导致次优的分割流水线[10,13]。
在本工作中,我们概述了一条从生物医学分割中主要依赖专家驱动的方法配置到完全依赖数据驱动的AutoML方法之间的新路径。具体而言,我们定义了一种后续的配方,该配方在任务无关的层面上系统化了配置过程,并在给定新任务时大幅减少了经验性设计选择的搜索空间。
- 收集不需要在数据集之间进行调整的设计决策,并确定一个稳健的通用配置(“固定参数”)。
- 尽可能多地为剩余的决策,以特定数据集属性(“数据指纹”)和设计决策(“流水线指纹”)之间的显式依赖关系的形式,制定启发式规则,以允许几乎即时的应用(“基于规则的参数”)。
- 仅从数据中经验性地学习剩余的决策(“经验性参数”)。
我们的实现是在医学分割十项全能提供的十个数据集上开发和验证的。由此产生的分割方法,我们称之为nnU-Net,能够对任意新的数据集进行自动配置。与现有研究方法不同,nnU-Net 是全面的,即其自动配置覆盖了整个分割流水线(包括网络架构的关键拓扑参数),没有任何手动决策。此外,nnU-Net 的自动配置速度快,仅需简单的规则执行和少量的经验性选择,因此只需要基本的标准模型训练所需的计算资源。最后,nnU-Net 是数据高效的;基于大量多样化的数据池编码的设计选择作为应用到训练数据有限的数据集的强大归纳偏置。 nnU-Net 的自动配置在额外的 13 个数据集上得到了验证。总共,我们在 53 个分割任务上报告了结果,涵盖了前所未有的目标结构、图像类型和图像属性的多样性。作为开源工具,nnU-Net 可以简单地训练以生成最先进的分割结果。
2. 结果
nnU-Net 是一种基于深度学习的分割方法,能够自动配置包括预处理、网络架构、训练和后处理在内的任意新生物医学任务。
图1展示了由 nnU-Net 生成的多种数据集的示例分割结果。
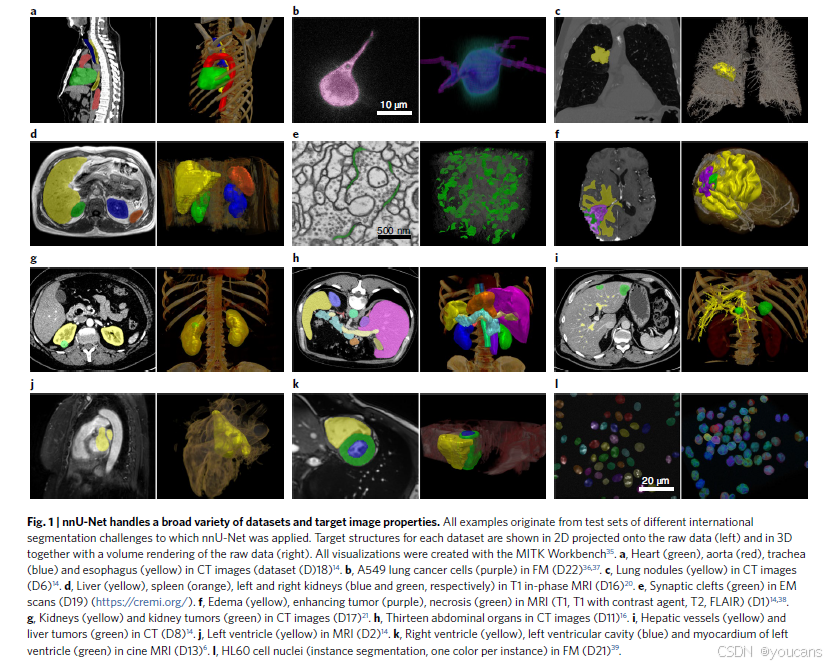
图1 | nnU-Net 处理广泛类型的数据集和目标图像属性。所有示例均来自 nnU-Net 应用的不同国际分割挑战的测试集。每个数据集的目标结构在原始数据上以 2D 投影(左)和与原始数据的体绘制一起以 3D 形式(右)显示。所有可视化均使用 MITK Workbench35 创建。
a,CT 图像(数据集 (D)18)14 中的心脏(绿色)、主动脉(红色)、气管(蓝色)和食道(黄色)。
b,FM 数据集 (D22)36,37 中的 A549 肺癌细胞(紫色)。
c,CT 图像(数据集 D6)14 中的肺结节(黄色)。
d,T1 相位 MRI(数据集 D16)20 中的肝脏(黄色)、脾脏(橙色)、左肾(蓝色)和右肾(绿色)。
e,EM 扫描(数据集 D19)(https://cremi.org/)中的突触间隙(绿色)。
f,MRI(T1,T1 加对比剂,T2,FLAIR)(数据集 D1)14,38 中的水肿(黄色)、增强肿瘤(紫色)、坏死(绿色)。
g,CT 图像(数据集 D17)21 中的肾脏(黄色)和肾肿瘤(绿色)。
h,CT 图像(数据集 D11)16 中的十三个腹部器官。
i,CT(数据集 D8)14 中的肝血管(黄色)和肝肿瘤(绿色)。
j,MRI(数据集 D2)14 中的左心室(黄色)。
k,MRI(数据集 D13)6 中的右心室(黄色)、左心室腔(蓝色)和左心室心肌(绿色)。
l,FM 数据集 (D21)39 中的 HL60 细胞核(实例分割,每个实例一种颜色)。
1. nnU-Net 可自动适应任意新的数据集。
图2展示了 nnU-Net 如何系统地解决整个分割流水线的配置问题,并提供了最相关设计选择的可视化和描述。
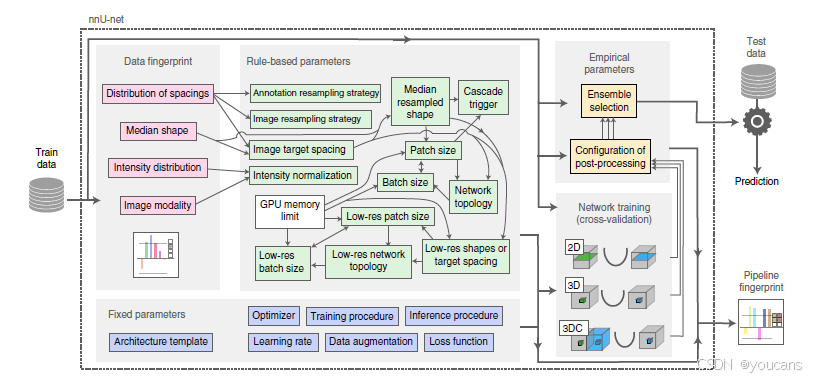
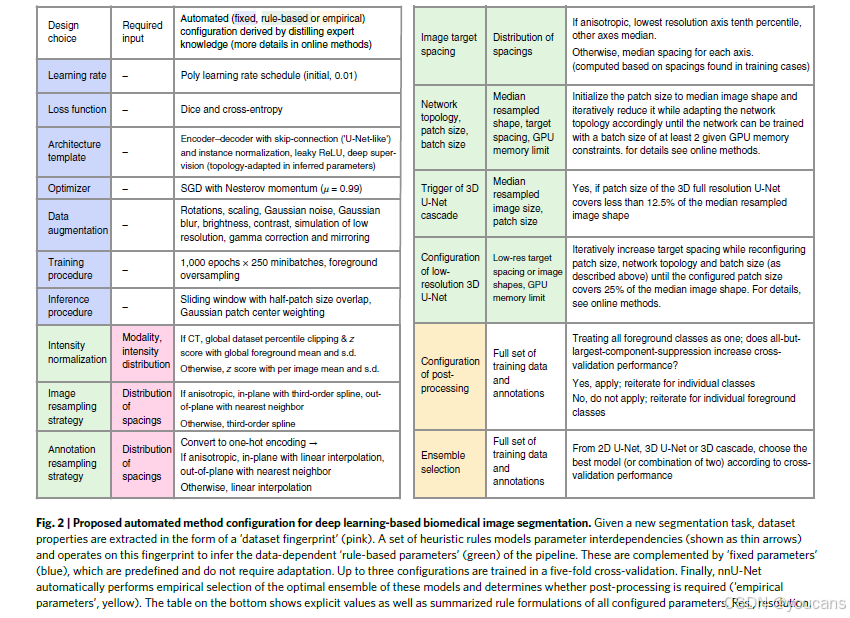
图2 | 基于深度学习的生物医学图像分割的提议自动方法配置。
给定一个新的分割任务,提取数据集属性以形成“数据指纹”(粉色)。
一组启发式规则模型参数间的依赖关系(以细箭头表示),并在此指纹上操作以推断出数据依赖的“基于规则的参数”(绿色)。这些参数由“固定参数”(蓝色)补充,这些参数是预定义的且不需要调整。
最多可训练三种配置,在五折交叉验证中。
最后,nnU-Net 自动执行经验性选择以确定这些模型的最佳组合,并确定是否需要后处理(“经验性参数”黄色)。
底部表格显示了所有配置参数的具体值以及总结的规则表述。Res., 分辨率。
nnU-Net 的开发。
nnU-Net 的自动配置基于将领域知识提炼为三个参数组:固定参数、基于规则的参数和经验参数。
首先,我们收集所有不需要在数据集之间进行调整的设计选择(例如将架构模板设置为“类似U-Net”),并优化它们的联合配置以在我们的开发数据集上实现稳健的一般化。
其次,尽可能多地为剩余的决策制定“数据指纹”与“管道指纹”之间的显式依赖关系,“数据指纹”是一个标准化的数据集表示,包含关键属性如图像尺寸、体素间距信息或类别比例,“管道指纹”定义为方法设计过程中所做的所有选择。依赖关系以相互依赖的启发式规则的形式建模,这些规则几乎可以在应用时立即执行。例如,批量大小、补丁大小和网络拓扑的相互依赖配置基于以下三个原则。
- 较大的批量大小允许更准确的梯度估计,因此在实践中更可取(尽管在我们的领域通常不会达到最佳值),但在实践中,任何大于一个的批量大小都会导致稳健的训练。
- 训练过程中较大的补丁大小增加了网络吸收的上下文信息,因此对于性能至关重要。
- 网络的拓扑应足够深,以确保有效的感受野大小至少与补丁大小相同,从而避免丢弃上下文信息。
将这些知识提炼为成功的算法设计,得出以下启发式规则:“将补丁大小初始化为图像中位形状,并在适应网络拓扑(包括网络深度、每个轴向上的池化操作次数及位置、特征图大小和卷积核大小)的同时逐步减小补丁大小,直到在给定GPU内存约束的情况下,网络可以使用至少两个批次大小进行训练。”所有启发式规则的详细描述提供在在线方法中,而用于规则推导的指导原则的汇总则提供在补充说明2中。
第三,我们仅将剩余的设计选择,即模型选择和后处理,基于应用时的训练数据进行经验决定。我们称之为nnU-Net的实现,仅在来自医学十项全能分割挑战的十个开发数据集上进行开发。
nnU-Net 的应用。
当将 nnU-Net 应用于新数据集时,nnU-Net 的自动配置无需人工干预。
因此,除了少数剩余的经验选择外,不需要额外的计算成本,只需标准的网络训练过程即可。nnU-Net 的自动化方法配置始于数据指纹的提取和随后执行启发式规则。默认情况下,nnU-Net 生成三种不同的 U-Net15 配置:二维(2D)U-Net、全分辨率工作的三维(3D)U-Net 以及第一级 U-Net 在下采样图像上工作的 3D U-Net 集成,第二级则训练以在全分辨率上细化前一级生成的分割图。经过交叉验证后,nnU-Net 经验性地选择性能最佳的配置或集成。最后,如果测量到性能提升,nnU-Net 经验性地选择“非最大组件抑制”作为后处理步骤。nnU-Net 自动配置和训练过程的输出是完全训练好的模型,可以部署到未知图像上进行预测。我们通过将其应用于 13 个额外的数据集,展示了嵌入在 nnU-Net 固定、基于规则和经验参数中的设计选择的一般化能力。
nnU-Net 方法背后的详细方法论以及其总体设计原则分别提供在“材料与方法”和补充说明2中。对于所有数据集生成的分割管道提供在补充说明6中。
- nnU-Net 能处理各种各样的目标结构和图像属性。
我们通过将其应用于包含 23 个不同数据集和 53 个分割任务的 11 个国际生物医学图像分割挑战,展示了 nnU-Net 作为开箱即用分割工具的价值(6,14,16-24, https://cremi.org)。这一选择包括了 2D 和 3D 图像中的各种器官、器官亚结构、肿瘤、病变和细胞结构,这些图像分别由磁共振成像(MRI)、计算机断层扫描(CT)、电子显微镜(EM)和荧光显微镜(FM)获取。‘挑战’是旨在在标准化环境中评估多个算法性能的国际竞赛(9)。在所有分割任务中,nnU-Net 仅使用提供的挑战数据从头进行训练。从定性的角度来看,我们观察到 nnU-Net 能够处理数据集属性和目标结构多样性之间的巨大差异;即生成的管道配置与人类专家认为合理或合理的设置相符(补充说明3,第1节和第2节)。nnU-Net 生成的分割结果示例见图1。
- nnU-Net 在多种多样任务中优于专门的管道。
图3提供了 nnU-Net 和竞争挑战团队在所有 53 个分割任务中取得的定量结果概述。尽管其具有通用性,但 nnU-Net 在大多数现有的分割解决方案中表现出色,即使后者针对特定任务进行了专门优化。总体而言,nnU-Net 在 53 个目标结构中的 33 个中设定了新的最先进的状态,否则其性能与或接近排行榜的顶级条目。
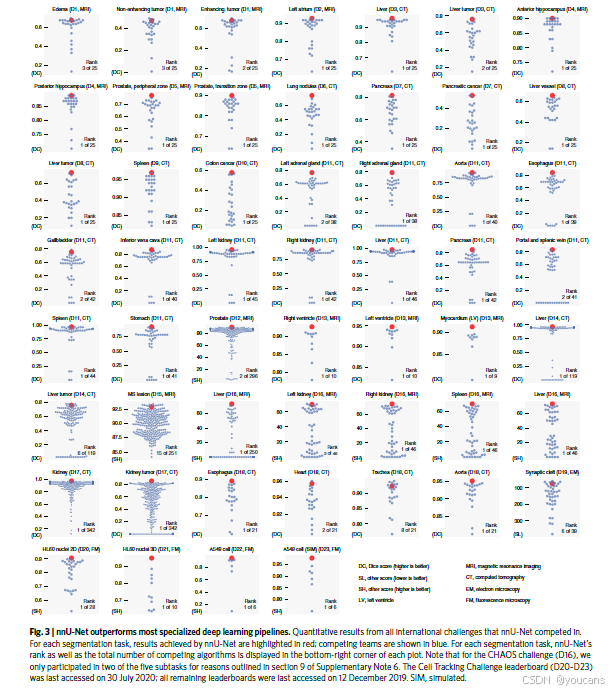
图3 | nnU-Net 在大多数专门的深度学习管道中表现更优。nnU-Net 参与的所有国际挑战的定量结果。对于每个分割任务,nnU-Net 的结果用红色突出显示;竞争团队用蓝色显示。对于每个分割任务,nnU-Net 的排名以及参与的总算法数量在每个图表的右下角显示。请注意,对于 CHAOS 挑战(D16),我们仅参加了五个子任务中的两个,原因在补充说明第6节的第9部分中有说明。细胞追踪挑战排行榜(D20-D23)最后访问日期为2020年7月30日;所有其他排行榜最后访问日期为2019年12月12日。SIM,模拟。
- 方法配置的细节比架构变化对性能的影响更大。
为了更深入地了解基于深度学习的生物医学图像分割的当前实践,我们以最近由医学成像与计算机辅助干预学会(MICCAI)举办的肾脏和肾脏肿瘤分割(KiTS)2019 挑战赛中参赛的算法为例进行分析(25)。MICCAI 学会一直持续举办至少 50% 的年度生物医学图像分析挑战赛(9)。超过 100 个竞争对手的 KiTS 挑战赛是 MICCAI 2019 中规模最大的比赛。第一个观察结果是,自动机器学习(AutoML)方法在排行榜上明显缺席。仅有一个提交(排名100中的第18名)报告了“通过网格搜索选择少数超参数”(http://results.kits-challenge.org/miccai2019/manuscripts/peekaboo_2.pdf),而手动试验和错误优化代表了不可否认的现状。值得注意的是,这一观察结果并不局限于 KiTS;我们不知道有任何成功的生物医学图像分割竞赛使用了 AutoML。图4a提供了 KiTS 排行榜的总体概述(http://results.kits-challenge.org/miccai2019),揭示了基于深度学习的分割方法设计当前景观的进一步见解。首先,前15种方法源自2016年的(3D)U-Net架构(参考文献15,26),证实了其对生物医学图像分割领域的影响力。其次,使用相同类型网络的贡献在排行榜上表现出不同的性能。第三,在检查前15种方法时,没有常用的架构修改(例如,残差连接27,28,密集连接29,30,注意力机制31或膨胀卷积32,33)是 KiTS 任务良好性能的必要条件。
图4b强调了找到合适方法配置的重要性。它展示了所有使用与挑战获胜贡献相同架构变体的算法的分析,即带有残差连接的3D U-Net。虽然其中一个方法赢得了挑战,但基于相同原理的其他贡献覆盖了整个评估得分和排名范围。关键配置参数是从各自的管道指纹中选择的,展示了每个团队在方法配置过程中做出的相互依赖的设计选择。参赛者提交的大幅变化的配置表明,在为生物医学图像分割配置深度学习方法时隐含的高维优化问题的复杂性。
nnU-Net 实验性地强调了在 KiTS 数据集上方法配置相对于架构变化的相对重要性,通过在开放排行榜上取得新的最先进的状态(nnU-Net 在原挑战结束后提交到排行榜,因此未包含在原排行榜分析中。图4中分析的方法也在开放排行榜中列出)来实现,仅使用简单的3D U-Net架构。这一观察结果与我们在22个额外数据集上的结果(图3)一致。
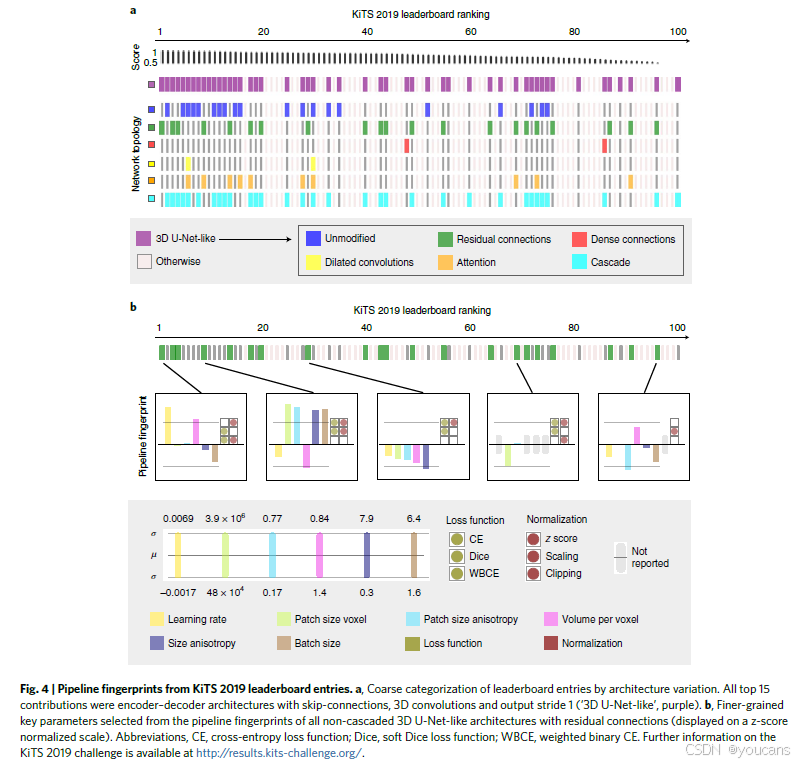
图4 | KiTS 2019 排行榜条目的管道指纹。a,按架构变化进行粗略分类的排行榜条目。所有前15种贡献均为带有跳连接、3D 卷积和输出步幅1(“3D U-Net 类似”,紫色)的编码-解码架构。b,从所有带有残差连接的非级联3D U-Net 类似架构的管道指纹中选择的更精细的关键参数(在z分数标准化尺度上显示)。缩写,CE,交叉熵损失函数;Dice,软Dice损失函数;WBCE,加权二进制CE。有关KiTS 2019挑战的更多信息,请参见http://results.kits-challenge.org/。
- 不同的数据集需要不同的管道配置。
我们提取了23个生物医学分割数据集的数据指纹。如图5所示,这揭示了生物医学成像中的数据集多样性,并揭示了缺乏开箱即用分割算法的根本原因:方法配置的复杂性被适配的管道设置直接或间接依赖于数据指纹的复杂关系所放大。因此,适用于一个数据集(如KiTS,见上文)的最佳管道设置可能不适用于其他数据集,导致每个单独的数据集都需要重新优化。nnU-Net 通过识别稳健的设计决策并明确建模关键的相互依赖关系(图2)来应对这一挑战。
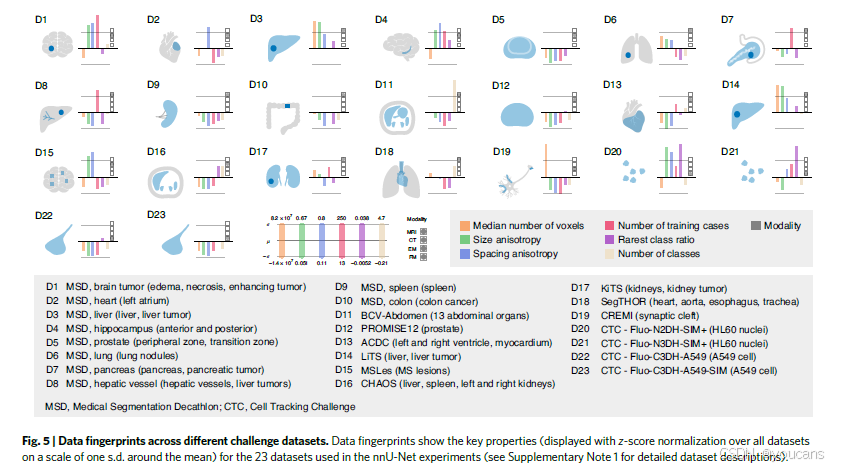
图5 | 不同挑战数据集的数据指纹。数据指纹显示了23个用于nnU-Net实验的数据集的关键属性(在所有数据集上使用均值周围一个标准差的z分数标准化显示,参见补充说明第1节以获取详细的数据集描述)。
- 多个任务可以支持稳健的设计决策。
nnU-Net 的自动方法配置可以供研究人员用于新分割方法的开发。新的想法可以轻松地集成到 nnU-Net 中,并因此可以在多个数据集上进行测试,而无需为每个数据集手动重新配置整个管道。为了展示这种方法的优势,并支持 nnU-Net 中的一些核心设计选择,我们系统地测试了常见管道变化的性能,通过系统地修改 nnU-Net 的某些固定参数来进行。以下变化在十个不同的数据集上进行了评估,并与作为这些实验基准的默认 nnU-Net 配置进行了比较(图6)。不同数据集之间排名的波动性表明,单个设计选择如何根据数据集影响分割性能。结果清楚地表明,当评估基于不足数量的数据集时,从评估中得出方法结论时需要谨慎。虽然九种变体中有五种在至少一个数据集中获得了第一名,但它们在十个任务中均未表现出一致的改进。原始的 nnU-Net 配置显示了最佳的一般化性能,当汇总所有数据集的结果时排名第一。
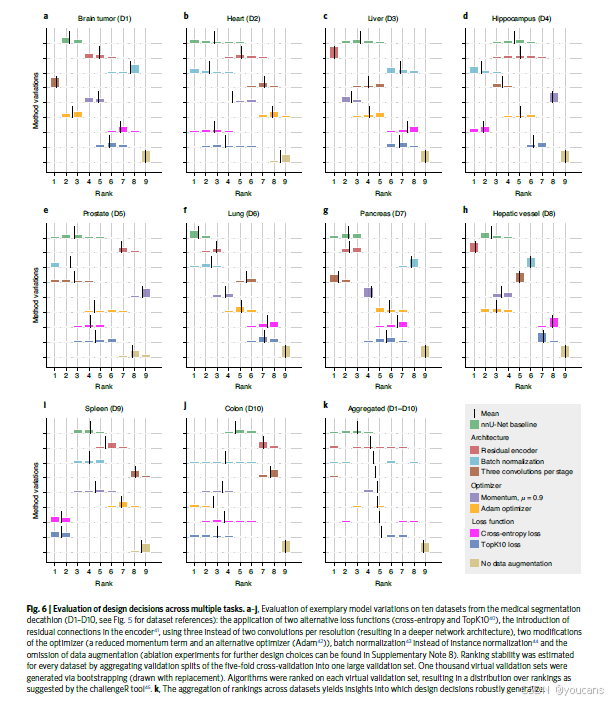
图6 | 多个任务中设计决策的评估。a-j,对医学分割十项挑战(D1-D10,参见图5中的数据集引用)的十个数据集上进行的模型变化评估示例:两种替代损失函数(交叉熵和TopK)的应用,编码器中引入残差连接(41),每个分辨率使用三个而不是两个卷积(导致更深的网络架构),优化器的两种修改(减小动量项和替代优化器(Adam42)),使用批标准化(43)而不是实例归一化(44),以及省略数据增强(进一步设计选择的消融实验可以在补充说明第8节中找到)。通过自助法(有放回抽样)生成一千个虚拟验证集,将五折交叉验证的验证分割聚合为一个大型验证集,以估计每个数据集的排名稳定性。通过生成的每个虚拟验证集对算法进行排名,从而得到挑战R工具(challengeR tool45)建议的排名分布。k,不同数据集排名的聚合揭示了哪些设计决策能够稳健地泛化。
3. 讨论
我们提出了一种基于深度学习的分割方法——nnU-Net,该方法可以自动配置包括预处理、网络架构、训练和后处理在内的所有内容,适用于生物医学领域的任何新任务。对于评估的大多数任务,nnU-Net均达到了新的最佳状态,优于所有相应的专门处理管道。nnU-Net的强大性能并非通过新的网络架构、损失函数或训练方案(因此命名为nnU-Net,“没有新网络”)实现,而是通过系统化复杂的手动方法配置过程,该过程之前要么通过繁琐的手动调整,要么通过纯粹的经验方法解决,而这些方法具有实际限制。我们假设nnU-Net达到最佳性能的原因在于从大量数据集中提炼出的知识被转化为一组稳健的设计选择,这些选择在应用于新数据集时会产生强大的归纳偏置,从而使其具有超越单个数据集配置模型的泛化能力。此外,通过将领域知识凝练为一组固定的、基于规则的和经验参数,我们提出了一个新的自动化方法配置路径,该路径在计算上是可行的,同时涵盖了整个分割管道,包括网络架构的关键拓扑参数。nnU-Net是一种无需用户干预即可应用于广泛生物医学成像数据集的新型分割工具,因此对于需要访问语义分割方法但缺乏专业知识、时间、数据或计算资源的用户来说,它是理想的选择。
我们的KiTS排行榜分析揭示了生物医学图像分割中手动且不够系统的方法配置现状,并突显了当前研究领域的几个重要影响。例如,我们观察到使用相同类型的网络的贡献在排行榜上表现出不同的性能(图4)。这一观察与Litjens等人在他们的综述中发现的结果一致,他们指出“许多研究者使用相同的架构,但结果却大相径庭”(参考文献10)。文献中基于架构扩展提出的性能改进可能不适用于所有数据集的几个可能原因如下:首先,生物医学领域的数据集多样性需要专门的方法配置(图5)。因此,新数据集的方法配置质量可能会掩盖评估的架构修改效果。这一解释与Litjens等人的一项观察相符,他们得出结论:“确切的架构并不是获得良好解决方案的最重要因素”(参考文献10),并且这一结论得到了基于强大方法配置的简单U-Net架构的nnU-Net的最新结果的支持。其次,在当前的研究实践中,评估通常仅在两个数据集上进行,即使在这些数据集之间也具有大量重叠的特性(例如,都是腹部CT扫描)。正如我们在多数据集研究中所展示的(图6),这种评估不适合得出一般方法结论。我们将缺乏足够的广泛评估与手动调整提议方法及其现有管道(即基线)配置到个别数据集所需的巨大努力相关联。至关重要的是,这一繁琐的过程也可能导致基线配置不当,从而在文献中造成潜在偏差。nnU-Net能够缓解当前研究中的这些瓶颈。一方面,nnU-Net代表了一种无需手动任务特定调整的新方法,因此可以作为任何新分割任务的强大且标准化的基线。另一方面,nnU-Net可以通过作为可扩展的实验框架来帮助研究人员轻松实现方法学修改,从而增加用于评估的数据集数量。
尽管nnU-Net在新数据集上稳健地找到了高质量的配置,特定任务的经验优化可能进一步提高分割性能。然而,正如在引言中所阐述的,当前经验AutoML方法的实际限制阻碍了其在生物医学图像分割中的应用。另一个限制是与基于数据驱动的优化(“黑盒算法”(参考文献12))相比,nnU-Net由于其底层使用指导原则,每个设计决策都可以追溯到特定的数据集属性或一组有限的经验实验。展望未来,我们认为我们的工作与经验AutoML研究互补;nnU-Net可以作为基于经验优化选定设计决策(如数据增强或网络架构)的整体自动化的基础。
尽管在53个多样化的任务中表现出色,nnU-Net的自动适应可能在某些分割任务中仍不理想。例如,nnU-Net是基于Dice系数作为性能指标进行开发的。然而,某些任务可能需要高度特定领域的目标指标进行评估,这可能会影响方法设计。此外,尚未考虑的某些数据集属性也可能导致分割性能不佳。一个例子是CREMI挑战中的突触间隙分割任务(https://cremi.org)。尽管nnU-Net的性能非常具有竞争力(排名第6),但手动调整损失函数以及EM特定的预处理可能需要超越当前最佳性能(34)。
原则上,处理尚未充分覆盖的案例有两种方法。对于潜在重复出现的案例,可以相应扩展nnU-Net的经验法则;对于高度特定领域的案例,应将nnU-Net视为必要的修改的良好起点。
总之,nnU-Net在各种语义分割挑战中达到了新的最佳状态,表现出强大的泛化特性,无需专家知识或超出标准网络训练所需的计算资源。正如Litjens等人所指出的,并且在本工作中定量确认,生物医学成像中的方法配置曾被视为一种“高度经验性的练习”,没有“明确的配方”(参考文献10)。基于本工作中提出的配方,nnU-Net能够自动化这一常常不够系统且繁琐的程序,从而可能减轻这一负担。我们建议将nnU-Net作为现成的工具用于最先进的分割,作为比较的标准化和数据集无关的基线,并作为大规模评估新想法的框架,无需手动努力。
在线内容
任何方法、额外参考文献、Nature Research 报告摘要、原始数据、扩展数据、补充信息、致谢、同行评审信息;作者贡献和竞争利益的详细信息;以及数据和代码可用性的声明均可在 https://doi.org/10.1038/s41592-020-01008-z 获取。
4. 方法
nnU-Net 设计原则的快速概述可以在补充说明2中找到。本节提供了这些原则的详细实施信息。
-
数据集指纹。
作为第一步处理步骤,nnU-Net 将提供的训练案例裁剪为其非零区域。虽然这在我们的实验中对大多数数据集没有影响,但显著减少了脑部数据集(如D1(脑肿瘤)和D15(多发性硬化病灶(MSLes)))的图像尺寸,从而提高了计算效率。基于裁剪后的训练数据,nnU-Net 创建了一个数据集指纹,该指纹捕获所有相关参数和属性:裁剪前后图像的尺寸(即每个空间维度的体素数量)、图像间距(即体素的物理大小)、模态(从元数据读取)以及所有图像的类别数量,以及总训练案例数量。此外,指纹还包括所有训练案例中前景区域(即属于任何类别标签的体素)强度值的均值、标准差,以及第0.5百分位和第99.5百分位。 -
管道指纹。
nnU-Net 通过生成所谓的管道指纹来自动化生物医学图像分割的深度学习方法设计,该指纹包含所有相关信息。重要的是,nnU-Net 将设计选择简化为最基本的几个,并自动通过一组启发式规则推断这些选择。这些规则凝练了领域知识,并作用于上述描述的数据指纹和项目特定的硬件约束。这些基于规则的参数由固定参数和经验参数补充,固定参数与数据无关,而经验参数则在训练过程中进行优化。 -
固定参数。
架构模板。所有由nnU-Net配置的U-Net架构均源自同一模板。该模板紧密遵循原始U-Net15及其3D版本26。根据我们假设一个良好配置的普通U-Net仍然难以超越的观点,我们的所有U-Net配置均未使用最近提出的架构变体,如残差连接28、41,密集连接29、30,注意力机制31,挤压与激励网络46或扩张卷积32。相对于原始架构,仅进行了少量修改。为了支持大尺寸的图像块,nnU-Net中的网络批量大小较小。事实上,大多数3D U-Net配置仅使用批量大小为2(补充说明5中的图SN5.1a)。批量归一化43,通常用于加速或稳定训练,在小批量大小下表现不佳47、48。因此,我们为所有U-Net模型使用了实例归一化44。此外,我们用泄漏ReLU(负斜率,0.01)替换了ReLU。网络使用深度监督进行训练;在解码器中为除了最低两个分辨率之外的所有分辨率添加了辅助损失,允许梯度更深入地注入网络,从而促进网络中所有层的训练。所有U-Net在编码器和解码器中均采用每分辨率步两个块的非常常见的配置,每个块由卷积、接着是实例归一化和泄漏ReLU非线性组成。下采样通过步幅卷积实现(受表征瓶颈50的启发),上采样通过转置卷积实现。为了在性能和内存消耗之间取得平衡,初始特征图数量设置为32,并在每次下采样(上采样)操作中翻倍(减半)。为了限制最终模型的大小,3D和2D U-Net中的特征图数量分别被限制在320和512。 -
训练调度。
基于经验和在运行时间和奖励之间的权衡,所有网络均训练1,000个epoch,一个epoch定义为迭代250个小批量。使用具有Nesterov动量(μ = 0.99)的随机梯度下降法和初始学习率为0.01来学习网络权重。在整个训练过程中,学习率按照“poly”学习率策略32衰减,即(1 − epoch/epochmax)0.9。损失函数是交叉熵和Dice损失的和。对于每个深度监督输出,使用相应的下采样地面真实分割掩模进行损失计算。训练目标是所有分辨率下的损失之和,L = w1 × L1 + w2 × L2 + … 其中,权重(w)在每个分辨率降低时减半,结果为w2 = ½ × w1,w3 = ¼ × w1等,并归一化使其总和为1。小批量样本从随机训练案例中选择。通过过采样确保对类别不平衡的稳健处理;66.7%的样本来自所选训练案例内的随机位置,而33.3%的切片保证包含所选训练样本中存在的前景类(随机选择)。前景切片的数量四舍五入,最低为1(导致批量大小为2时,一个随机切片和一个前景切片)。在训练过程中实时应用多种数据增强技术:旋转、缩放、高斯噪声、高斯模糊、亮度、对比度、低分辨率模拟、伽马校正和镜像。详情请参见补充说明4。 -
推理。
图像使用滑动窗口方法预测,窗口大小等于训练期间使用的切片大小。相邻预测之间重叠窗口大小的一半。分割的准确性在窗口边界附近降低。为了抑制拼接伪影并减少靠近边界位置的影响,应用了高斯重要性加权,增加softmax聚合中心体素的权重。测试时沿所有轴向镜像进行数据增强。 -
基于规则的参数。
强度归一化。nnU-Net支持两种不同的图像强度归一化方案。对于所有模态,除了CT图像外,默认设置为z-score归一化。在这种情况下,在训练和推理过程中,每个图像首先减去其均值,然后除以其标准差进行独立归一化。如果裁剪导致平均大小减少25%或更多,将创建一个中心非零体素的掩模,并仅对该掩模内的体素进行归一化,忽略周围的零体素。对于CT图像,nnU-Net采用不同的方案,因为强度值是定量的,反映了组织的物理特性。因此,通过使用适用于所有图像的全局归一化方案来保留这些信息是有益的。为此,nnU-Net使用前景体素的0.5和99.5百分位数进行裁剪,并使用全局前景均值和标准差对所有图像进行归一化。
重采样。在某些数据集中,特别是在医学领域,体素间距(体素所代表的物理空间)是异质的。卷积神经网络在体素网格上运行并忽略这些信息。为了应对这种异质性,nnU-Net使用三次样条、线性或最近邻插值将所有图像重采样到相同的目标间距(见下文段落)。图像数据的默认设置为三次样条插值。对于各向异性图像(最大轴间距 ÷ 最小轴间距 > 3),沿面插值使用三次样条插值,而跨面插值使用最近邻插值。在各向异性情况下,对跨面轴的不同处理可以抑制重采样伪影,因为层间轮廓变化较大。分割图通过转换为独热编码进行重采样。然后,每个通道使用线性插值进行插值,分割掩模通过argmax操作检索。对于各向异性情况,低分辨率轴使用“最近邻”进行插值。 -
目标间距。
选定的目标间距是一个关键参数。较大的间距导致较小的图像,从而损失细节,而较小的间距导致较大的图像,网络无法积累足够的上下文信息,因为块大小受限于给定的图形处理单元(GPU)内存预算。虽然3D U-Net级联(见下文)部分解决了这一权衡问题,但低分辨率和全分辨率仍需合理的目标间距。对于3D全分辨率U-Net,nnU-Net使用训练案例中每个轴独立计算的间距的中位值作为默认目标间距。对于各向异性数据集,如果体素和间距各向异性(即最低间距轴与最高间距轴的比例)均大于3,则默认值可能导致严重的插值伪影或由于训练数据中分辨率的大幅变化而导致信息损失。因此,最低分辨率轴的目标间距选择为训练案例中发现的间距的十分位数。对于2D U-Net,nnU-Net通常在具有最高分辨率的两个轴上操作。如果所有三个轴都是各向同性的,则使用尾随的两个轴进行切片提取。目标间距是训练案例中每个轴独立计算的间距的中位值。对于基于切片的处理,无需沿跨面轴进行重采样。 -
网络拓扑、块大小和批量大小的适应。
找到合适的U-Net架构配置对于获得良好的分割性能至关重要。nnU-Net优先选择较大的块大小,同时保持在预定义的GPU内存预算范围内。较大的块大小可以聚合更多的上下文信息,通常会提高分割性能。然而,这会降低批量大小,从而在反向传播过程中导致更嘈杂的梯度。为了提高训练的稳定性,我们要求最小批量大小为2,并选择较大的动量项进行网络训练(固定参数)。图像间距也在适应过程中考虑:下采样操作可以配置为仅在特定轴上和3D U-Net的卷积核上进行,也可以配置为仅在某些图像平面进行(伪2D)。所有U-Net配置的网络拓扑基于重采样后的中位图像尺寸以及图像重采样的目标间距选择。适应过程的流程图见补充说明5的附图SN5.1。 -
架构模板的适应。
如后续文本中所述,架构模板的适应计算成本较低。因为GPU内存消耗估算基于特征图大小,所以无需GPU即可运行适应过程。 -
初始化。
块大小初始化为重采样后的中位图像形状。如果块大小在每个轴上不为2的幂次,则相应地进行填充。
架构拓扑。通过确定每个轴上的下采样操作数来配置架构,这取决于块大小和体素间距。下采样操作直到进一步下采样会使特征图尺寸减少到少于四个体素,或者特征图间距变得各向异性为止。下采样策略由体素间距决定;高分辨率轴分别下采样,直至其分辨率是低分辨率轴分辨率的两倍以内。随后,所有轴同时下采样。对于每个轴,一旦触发相应的特征图约束,下采样操作即终止。3D U-Net和2D U-Net的卷积默认内核大小分别为3 × 3 × 3和3 × 3。如果存在轴之间的初始分辨率差异(定义为间距比大于2),则跨面轴的卷积内核大小设置为1,直到分辨率是低分辨率轴分辨率的两倍以内。请注意,卷积内核大小此后保持为3。 -
适应GPU内存预算。
配置过程中最大的可能块大小受限于GPU内存量。由于块大小初始化为重采样后的中位图像形状,它最初对于大多数数据集来说太大,无法完全放入GPU。nnU-Net根据网络中特征图的大小估算给定架构的内存消耗,并将其与已知内存消耗的参考值进行比较。然后,通过迭代过程逐步减小块大小,同时在每一步相应更新架构配置,直到达到所需的预算(参见补充说明5的附图SN5.1)。每次减小的块大小相对于数据的中位图像形状总是针对最大的轴进行。每次减小的量为该轴的2nd体素,其中nd是下采样操作的数量。 -
批量大小。
作为最终步骤,配置批量大小。如果进行了块大小的减小,批量大小设置为2。否则,使用剩余的GPU内存头程来增加批量大小,直到GPU完全使用。为了防止过拟合,批量大小被限制,使得批量中的体素总数不超过所有训练案例体素总数的5%。生成的U-Net架构示例见补充说明3的第1和2部分。 -
3D U-Net级联的配置。
在下采样数据上运行分割模型会增加相对于图像的块大小,从而允许网络积累更多的上下文信息。这以降低生成分割图的详细程度为代价,并且如果分割目标非常小或由纹理特征定义时,还可能导致错误。在假设无限GPU内存的情况下,通常更倾向于在全分辨率下训练模型,块大小覆盖整个图像。3D U-Net级联通过首先在下采样图像上运行3D U-Net,然后训练第二个全分辨率3D U-Net来细化前者的分割图,来近似这种方法。这样,“全局”的低分辨率网络使用最大上下文信息生成其分割输出,该输出随后作为附加输入通道来指导第二个“局部”U-Net。级联仅在3D全分辨率U-Net的块大小覆盖中位图像形状的不足12.5%的数据集上触发。如果这种情况发生,下采样数据的目标间距及其相关3D低分辨率U-Net的架构将在迭代过程中联合配置。目标间距初始化为目标分辨率数据的目标间距。为了使块大小覆盖输入图像的大部分,目标间距逐步增加1%,同时在每一步相应更新架构配置,直到生成网络拓扑的块大小超过当前中位图像形状的25%。如果当前间距是各向异性的(最低分辨率轴与最高分辨率轴之间的差异是两倍),则仅增加高分辨率轴的间距。级联的第二个3D U-Net的配置与独立的3D U-Net相同,其配置过程如上所述(除了第一U-Net的上采样分割图被连接到其输入)。补充说明5的附图SN5.1b提供了此优化过程的概述。
经验参数。集成和U-Net配置的选择。nnU-Net基于在训练数据上进行交叉验证计算的平均前景Dice系数,自动确定用于推理的哪种(集成的)配置。所选模型可以是一个U-Net(2D、3D全分辨率、3D低分辨率或级联的全分辨率U-Net),或者这些配置中的任何两个的集成。通过平均softmax概率将模型集成。 -
后处理。
基于连通区域的后处理在医学图像分割中常用18,25。特别是在器官图像分割中,它通常有助于通过移除所有非最大连通区域来消除虚假正例的检测。nnU-Net遵循这一假设,并自动评估抑制较小组件对交叉验证结果的影响。首先,所有前景类被视为一个组件。如果抑制所有非最大区域提高平均前景Dice系数,并且不降低任何类别的Dice系数,则此过程被选为第一步后处理步骤。最后,nnU-Net基于此步骤的结果决定是否对每个类执行相同的过程。 -
实现细节。
nnU-Net使用PyTorch框架1.6.0(参考文献52)在Python 3.8.5中实现。使用Batchgenerators 0.21(参考文献53)进行数据增强。其他使用的Python库包括tqdm 4.48.2、dicom2nifti 2.2.10、scikit-image 0.17.2、MedPy 0.4.0、SciPy 1.5.2、batchgenerators 0.21、NumPy 1.19.1、scikit-learn 0.23.2、SimpleITK 1.2.4和pandas 1.1.1。作为框架使用,nnU-Net的源代码可在GitHub(https://github.com/MIC-DKFZ/nnUNet)上获得。希望使用nnU-Net作为标准化基准或运行我们预训练模型的用户可以通过PyPI安装nnU-Net。有关如何使用nnU-Net的完整说明,以及最新版本和依赖项,请参见GitHub页面上的在线文档。
5. nnUNet 项目概述
项目下载:github-nnUNet
5.1 nnU-Net能为你的研究带来什么?
如果你是一名领域科学家(生物学家、放射科医生等),希望分析自己的图像,nnU-Net提供了一个开箱即用的解决方案,几乎可以保证在你的个性化数据集上提供卓越的结果。只需将你的数据集转换为nnU-Net格式,即可享受AI的强大功能 - 不需要任何专业知识!
如果你是一名开发分割方法的AI研究人员,nnU-Net:
- 提供了一个出色的开箱即用的基础算法,可以用来与之竞争
- 可以作为方法开发框架,无需调整个别管道即可在大量数据集上测试你的贡献(例如评估一个新的损失函数)
- 提供了进一步数据集特定优化的强起点。特别是在参与分割挑战时尤为有用为分割方法的设计提供了新的视角:你能否找到数据集属性与最优分割流程之间更佳的联系?
5.2 nnU-Net 的应用范围是什么?
nnU-Net专门用于语义分割。它可以处理任意输入模态/通道的2D和3D图像。它能够理解体素间距、各向异性,并在类别高度不平衡的情况下仍能保持鲁棒性。
nnU-Net依赖于监督学习,这意味着你需要为你的应用提供训练案例。所需的训练案例数量取决于分割问题的复杂性。在这里无法提供一个通用的数量!nnU-Net所需的训练案例数量与其他解决方案相似,甚至可能更少,因为我们将数据增强技术广泛应用于此。
在预处理和后处理阶段,nnU-Net期望能够一次性处理整个图像,因此无法处理 enormous 的图像。作为参考:我们测试了从3D的40x40x40像素到1500x1500x1500像素,以及从2D的40x40像素到约30000x30000像素的图像!如果内存允许,更大尺寸的图像总是可能的。
5.3 nnU-Net的工作原理是什么?
给定一个新的数据集,nnU-Net将系统地分析提供的训练案例,并创建一个“数据集指纹”。然后,nnU-Net为每个数据集创建几种不同的U-Net配置:
- 2d:2D U-Net(适用于2D和3D数据集)
- 3d_fullres:3D U-Net,仅在高图像分辨率下操作(仅适用于3D数据集)
- 3d_lowres → 3d_cascade_fullres:3D U-Net级联,首先在低分辨率图像上运行3D U-Net,然后在高分辨率3D U-Net中细化前者的预测结果(仅适用于具有大型图像尺寸的3D数据集)
请注意,并非所有U-Net配置都适用于所有数据集。在图像尺寸较小的数据集中,U-Net级联(包括3d_lowres配置)将被省略,因为全分辨率U-Net的 patchesize 已经覆盖了大部分输入图像。
nnU-Net根据以下三步食谱来配置其分割管道:
- 固定参数:不会进行调整。在开发nnU-Net过程中,我们确定了一种鲁棒的配置(即特定的网络架构和训练属性),可以始终使用。这包括,例如,nnU-Net的损失函数、(大部分)数据增强策略和学习率。
- 基于规则的参数:使用数据集指纹通过硬编码的启发式规则来调整某些分割管道属性。例如,网络拓扑(池化行为和网络架构的深度)根据patch size 进行调整;patch size、网络拓扑和批量大小在给定一些GPU内存约束的条件下联合进行最优化。
- 经验参数:本质上是通过试验和错误来确定的。例如,为给定数据集选择最佳的U-Net配置(2D、3D全分辨率、3D低分辨率、3D级联)和后处理策略的优化。
5.4 nnU-Net在哪些情况下表现优异?
nnU-Net在哪些情况下表现优异,又在哪些情况下表现不佳?
nnU-Net在需要从头开始训练的分割问题上表现出色,例如:具有非标准图像模态和输入通道的研究应用、来自生物医学领域的挑战数据集、大多数3D分割问题等。我们尚未找到一个nnU-Net的工作原理失效的数据集!
注意:在标准分割问题中,例如ADE20k和Cityscapes中的2D RGB图像,微调一个预训练模型(该模型在大量相似图像上进行了预训练,例如ImageNet 22k和JFT-300M)将比nnU-Net提供更优的性能!这是因为这些模型能够提供更好的初始化。nnU-Net不支持这些预训练模型,因为1)它们对于与标准设置不同的分割问题(见上述数据集)并无用处,2)它们通常仅支持2D架构,3)它们与我们精心为每个数据集适配网络拓扑的核心设计原则相冲突(如果改变拓扑结构,则无法转移预训练权重!)
6. 参考文献
1. Falk, T. et al. U-net: deep learning for cell counting, detection, and
morphometry. Nat. Methods 16, 67–70 (2019).
2. Hollon, T. C. et al. Near real-time intraoperative brain tumor diagnosis
using stimulated Raman histology and deep neural networks. Nat. Med. 26,
52–58 (2020).
3. Aerts, H. J. W. L. et al. Decoding tumour phenotype by noninvasive imaging
using a quantitative radiomics approach. Nat. Commun. 5, 4006 (2014).
4. Nestle, U. et al. Comparison of different methods for delineation of 18F-FDG
PET-positive tissue for target volume definition in radiotherapy of patients
with non-small cell lung cancer. J. Nucl. Med. 46, 1342–1348 (2005).
5. De Fauw, J. et al. Clinically applicable deep learning for diagnosis and referral
in retinal disease. Nat. Med. 24, 1342–1350 (2018).
6. Bernard, O. et al. Deep learning techniques for automatic MRI cardiac
multi-structures segmentation and diagnosis: is the problem solved? IEEE
Trans. Med. Imaging 37, 2514–2525 (2018).
7. Nikolov, S. et al. Deep learning to achieve clinically applicable segmentation
of head and neck anatomy for radiotherapy. Preprint at https://arxiv.org/
abs/1809.04430 (2018).
8. Kickingereder, P. et al. Automated quantitative tumour response assessment
of MRI in neuro-oncology with artificial neural networks: a multicentre,
retrospective study. Lancet Oncol. 20, 728–740 (2019).
9. Maier-Hein, L. et al. Why rankings of biomedical image analysis competitions
should be interpreted with care. Nat. Commun. 9, 5217 (2018).
10. Litjens, G. et al. A survey on deep learning in medical image analysis.
Med. Image Anal. 42, 60–88 (2017).
11. LeCun, Y. 1.1 deep learning hardware: past, present, and future. In 2019 IEEE
International Solid-State Circuits Conference 12–19 (IEEE, 2019).
12. Hutter, F., Kotthoff, L. & Vanschoren, J. Automated Machine Learning:
Methods, Systems, Challenges. (Springer Nature, 2019).
13. Bergstra, J. & Bengio, Y. Random search for hyper-parameter optimization.
J. Mach. Learn. Res. 13, 281–305 (2012).
14. Simpson, A. L. et al. A large annotated medical image dataset for the
development and evaluation of segmentation algorithms. Preprint at
https://arxiv.org/abs/1902.09063 (2019).
15. Ronneberger, O., Fischer, P. & Brox, T. U-net: convolutional networks for
biomedical image segmentation. In MICCAI (eds. Navab, N. et al)
234–241 (2015).
16. Landman, B. et al. MICCAI multi-atlas labeling beyond the cranial
vault—workshop and challenge. https://doi.org/10.7303/syn3193805 (2015).
17. Litjens, G. et al. Evaluation of prostate segmentation algorithms for MRI: the
PROMISE12 challenge. Med. Image Anal. 18, 359–373 (2014).
18. Bilic, P. et al. The liver tumor segmentation benchmark (LiTS). Preprint at
https://arxiv.org/abs/1901.04056 (2019).
19. Carass, A. et al. Longitudinal multiple sclerosis lesion segmentation: resource
and challenge. NeuroImage 148, 77–102 (2017).
20. Kavur, A. E. et al. CHAOS challenge—combined (CT–MR) healthy abdominal
organ segmentation. Preprint at https://arxiv.org/abs/2001.06535 (2020).
21. Heller, N. et al. The KiTS19 challenge data: 300 kidney tumor cases with
clinical context, CT semantic segmentations, and surgical outcomes. Preprint
at https://arxiv.org/abs/1904.00445 (2019).
22. Lambert, Z., Petitjean, C., Dubray, B. & Ruan, S. SegTHOR: segmentation of
thoracic organs at risk in CT images. Preprint at https://arxiv.org/
abs/1912.05950 (2019).
23. Maška, M. et al. A benchmark for comparison of cell tracking algorithms.
Bioinformatics 30, 1609–1617 (2014).
24. Ulman, V. et al. An objective comparison of cell-tracking algorithms.
Nat. Methods 14, 1141–1152 (2017).
25. Heller, N. et al. The state of the art in kidney and kidney tumor segmentation
in contrast-enhanced CT imaging: results of the KiTS19 challenge. In
Medical Image Analysis vol. 67 (2021).
26. Çiçek, Ö., Abdulkadir, A., Lienkamp, S. S., Brox, T. & Ronneberger, O. 3D
U-net: learning dense volumetric segmentation from sparse annotation. In
International Conference on Medical Image Computing and Computer-Assisted
Intervention (eds. Ourselin, S. et al.) 424–432 (Springer, 2016).
27. Milletari, F., Navab, N. & Ahmadi, S.-A. V-net: fully convolutional neural
networks for volumetric medical image segmentation. In International
Conference on 3D Vision (3DV) 565–571 (IEEE, 2016).
28. He, K., Zhang, Z., Ren, S. & Sun, J. Deep residual learning for image
recognition. In Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition 770–778 (IEEE, 2016).
29. Jégou, S., Drozdzal, M., Vazquez, D., Romero, A. & Bengio, Y. The one
hundred layers tiramisu: fully convolutional DenseNets for semantic
segmentation. In Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition Workshops 11–19 (IEEE, 2017).
30. Huang, G., Liu, Z., van der Maaten, L. & Weinberger, K. Q. Densely
connected convolutional networks. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition 4700–4708 (IEEE, 2017).
31. Oktay, O. et al. Attention U-net: learning where to look for the pancreas.
Preprint at https://arxiv.org/abs/1804.03999 (2018).
32. Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K. & Yuille, A. DeepLab:
semantic image segmentation with deep convolutional nets, atrous
convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach.
Intell. 40, 834–848 (2017).
33. McKinley, R., Meier, R. & Wiest, R. Ensembles of densely-connected CNNs
with label-uncertainty for brain tumor segmentation. In International MICCAI
Brain Lesion Workshop (eds. Crimi, A. et al.) 456–465 (Springer, 2018).
34. Heinrich, L., Funke, J., Pape, C., Nunez-Iglesias, J. & Saalfeld, S. Synaptic cleft
segmentation in non-isotropic volume electron microscopy of the complete
Drosophila brain. In International Conference on Medical Image Computing
and Computer-Assisted Intervention (eds. Frangi, A.F. et al.) 317–325
(Springer, 2018).
35. Nolden, M. et al. The Medical Imaging Interaction Toolkit: challenges and
advances. Int. J. Comput. Assist. Radiol. Surg. 8, 607–620 (2013).
36. Castilla, C., Maška, M., Sorokin, D. V., Meijering, E. & Ortiz-de-Solórzano, C.
3-D quantification of filopodia in motile cancer cells. IEEE Trans. Med.
Imaging 38, 862–872 (2018).
37. Sorokin, D. V. et al. FiloGen: a model-based generator of synthetic 3-D
time-lapse sequences of single motile cells with growing and branching
filopodia. IEEE Trans. Med. Imaging 37, 2630–2641 (2018).
38. Menze, B. H. et al. The Multimodal Brain Tumor Image Segmentation
benchmark (BRATS). IEEE Trans. Med. Imaging 34, 1993–2024 (2014).
39. Svoboda, D. & Ulman, V. MitoGen: a framework for generating 3D synthetic
time-lapse sequences of cell populations in fluorescence microscopy. IEEE
Trans. Med. Imaging 36, 310–321 (2016).
40. Wu, Z., Shen, C. & van den Hengel, A. Bridging category-level and
instance-level semantic image segmentation. Preprint at https://arxiv.org/
abs/1605.06885 (2016).
41. He, K., Zhang, X., Ren, S. & Sun, J. Identity mappings in deep residual
networks. In European Conference on Computer Vision (eds. Sebe, N. et al.)
630–645 (Springer, 2016).
42. Kingma, D. P. & Ba, J. Adam: a method for stochastic optimization. In 3rd
International Conference on Learning Representations (eds. Bengio, Y. &
LeCun, Y.) (ICLR, 2015).
43. Ioffe, S. & Szegedy, C. Batch normalization: accelerating deep network training
by reducing internal covariate shift. In Proceedings of Machine Learning
Research Vol. 37 (eds. Francis Bach and David Blei) 448–456 (PMLR, 2015).
44. Ulyanov, D., Vedaldi, A. & Lempitsky, V. Instance normalization: the missing
ingredient for fast stylization. Preprint at https://arxiv.org/abs/1607.08022 (2016).
45. Wiesenfarth, M. et al. Methods and open-source toolkit for analyzing and
visualizing challenge results. Preprint at https://arxiv.org/abs/1910.05121 (2019).
46. Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of
the IEEE Conference on Computer Vision and Pattern Recognition
7132–7141 (IEEE, 2018).
47. Wu, Y. & He, K. Group normalization. In Proceedings of the European
Conference on Computer Vision (ECCV) (eds. Leal-Taixé, L. & Roth, S.)
3–19 (ECCV, 2018).
48. Singh, S. & Krishnan, S. Filter response normalization layer: eliminating
batch dependence in the training of deep neural networks. In Proceedings of
the IEEE/CVF Conference on Computer Vision and Pattern Recognition
11237–11246 (CVPR, 2020)
49. Maas, A. L., Hannun, A. Y. & Ng, A. Y. Rectifier nonlinearities improve
neural network acoustic models. In Proceedings of the International
Conference on Machine Learning 3 (eds. Dasgupta, S. & McAllester, D.)
(ICML, 2013).
50. Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking the
inception architecture for computer vision. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition 2818–2826
(IEEE, 2016).
51. Drozdzal, M., Vorontsov, E., Chartrand, G., Kadoury, S. & Pal, C. The
importance of skip connections in biomedical image segmentation. In Deep
Learning and Data Labeling for Medical Applications (eds. Carneiro, G. et al.)
179–187 (Springer, 2016).
52. Paszke, A. et al. PyTorch: an imperative style, high-performance deep
learning library. In Advances in Neural Information Processing Systems
(eds. Wallach, H. et al.) 8024–8035 (NeurIPS, 2019).
53. Isensee, F. et al. Batchgenerators—a Python framework for data
augmentation. Zenodo https://doi.org/10.5281/zenodo.3632567 (2020).
版权说明:
本文由 youcans@xidian 对论文 nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
引用格式:
Isensee, F., Jaeger, P. F., Kohl, S. A., Petersen, J., & Maier-Hein, K. H. (2021). nnU-Net: a self-configuring
method for deep learning-based biomedical image segmentation. Nature methods, 18(2), 203-211. https://doi.org/10.1038/s41592-020-01008-z
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】nnU-Net:一种用于生物医学图像分割的深度学习方法
(https://youcans.blog.csdn.net/article/details/153210822)
Crated:2025-10

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 28
28 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)