健康检查数据分析与预测
人口统计信息:年龄、性别等生理指标:身高、体重、血压(收缩压、舒张压)、胆固醇水平、血糖水平等生活习惯:吸烟、饮酒、运动情况等健康状况:心血管健康状况等编程语言数据处理机器学习数据可视化静态可视化:Matplotlib 3.4.0+, Seaborn 0.11.0+交互式可视化:PyECharts 1.9.0+模型存储。
健康检查数据分析与预测
1. 项目背景与意义
随着人们健康意识的提高和医疗技术的发展,健康检查数据已成为评估个体健康状况的重要依据。本项目旨在通过对健康检查数据集的深入分析和挖掘,建立预测模型,为健康管理和疾病预防提供数据支持。
1.1 研究背景
现代生活方式和环境因素对人类健康构成了诸多挑战,心血管疾病、糖尿病等慢性疾病发病率持续上升。通过对健康检查数据的分析,可以发现潜在的健康风险因素,为早期干预和预防提供科学依据。
1.2 研究意义
- 个体健康管理:帮助个体了解自身健康状况,识别潜在风险因素
- 医疗资源优化:辅助医疗机构进行风险分层,优化资源分配
- 疾病预防:通过预测模型,实现疾病的早期预警和干预
- 健康政策制定:为公共卫生政策提供数据支持
2. 数据集介绍
2.1 数据集概述
健康检查数据集包含多个与健康相关的特征,主要分为以下几类:
- 人口统计信息:年龄、性别等
- 生理指标:身高、体重、血压(收缩压、舒张压)、胆固醇水平、血糖水平等
- 生活习惯:吸烟、饮酒、运动情况等
- 健康状况:心血管健康状况等
2.2 字段说明
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Unnamed: 0 | 整型 | 数据行序号(索引列) |
| id | 整型 | 患者唯一标识ID |
| age | 整型 | 患者实际年龄(单位:岁) |
| gender | 整型 | 性别编码(需确认编码规则) |
| height | 整型 | 身高(单位:厘米cm) |
| weight | 浮点型 | 体重(单位:千克kg) |
| ap_hi | 整型 | 收缩压(高压值,单位:mmHg) |
| ap_lo | 整型 | 舒张压(低压值,单位:mmHg) |
| cholesterol | 整型 | 胆固醇水平分级(需确认分级标准) |
| gluc | 整型 | 葡萄糖水平分级 |
| smoke | 整型 | 是否吸烟: 0=不吸烟 1=吸烟 |
| alco | 整型 | 是否饮酒: 0=不饮酒 1=饮酒 |
| active | 整型 | 是否积极运动 |
| cardio | 整型 | 是否进行有氧运动 |
| AgeinYr | 整型 | 年龄(与age字段重复,建议核查) |
| BMI | 浮点型 | 身体质量指数 计算公式:weight(kg)/[height(m)]² |
| BMICat | 字符型 | BMI分类标签 (如:偏瘦/正常/超重/肥胖) |
| AgeGroup | 字符型 | 年龄段分组标签 (如:青年/中年/老年) |
3. 分析思路与方法
3.1 整体分析框架
本项目采用了完整的数据科学分析流程,包括:
- 数据获取与理解:加载数据集,了解字段含义和数据结构
- 数据预处理:处理缺失值、异常值,确保数据质量
- 探索性数据分析:通过统计分析和可视化,探索数据特征和规律
- 特征工程:创建新特征,增强数据表达能力
- 模型构建:选择合适的机器学习算法,构建预测模型
- 模型评估:评估模型性能,分析特征重要性
- 结果可视化:通过多种可视化技术,直观展示分析结果
3.2 关键技术点
3.2.1 数据预处理技术
-
缺失值处理:
- 对数值型特征使用中位数填充,保持数据分布特性
- 对分类特征使用众数填充,符合多数样本特征
-
异常值处理:
- 基于医学常识和统计分布,设定合理的取值范围
- 对超出范围的异常值进行截断或替换,而非简单删除
- 特别处理了血压数据,确保收缩压大于舒张压,符合生理学规律
3.2.2 特征工程技术
-
BMI计算与分类:
- 基于身高和体重计算BMI:
BMI = 体重(kg) / 身高(m)² - 根据WHO标准进行BMI分类:
- 偏瘦:BMI < 18.5
- 正常:18.5 ≤ BMI < 25
- 超重:25 ≤ BMI < 30
- 肥胖:BMI ≥ 30
- 基于身高和体重计算BMI:
-
年龄组分类:
- 青年:< 30岁
- 中年:30-44岁
- 中老年:45-59岁
- 老年:≥ 60岁
-
血压分类:
- 基于美国心脏协会标准:
- 正常:收缩压 < 120 且 舒张压 < 80
- 高血压前期:收缩压 120-129 且 舒张压 < 80
- 高血压1期:收缩压 130-139 或 舒张压 80-89
- 高血压2期:收缩压 ≥ 140 或 舒张压 ≥ 90
- 高血压危象:收缩压 ≥ 180 或 舒张压 ≥ 120
- 基于美国心脏协会标准:
-
健康风险评分:
- 创建综合健康风险评分,考虑多方面因素:
- 年龄因素:年龄越大风险越高
- BMI因素:BMI偏离正常范围越多风险越高
- 血压因素:血压越高风险越高
- 代谢因素:胆固醇和血糖水平越高风险越高
- 生活习惯因素:吸烟、饮酒增加风险,运动减少风险
- 风险评分标准化到0-100范围,便于理解和比较
- 创建综合健康风险评分,考虑多方面因素:
3.2.3 模型构建技术
本项目选择了两种机器学习模型进行训练和比较:
-
随机森林分类器:
- 选择原因:
- 能处理高维数据,适合多特征健康数据
- 不易过拟合,对噪声有较强的鲁棒性
- 可提供特征重要性评估,帮助理解健康风险因素
- 对非线性关系建模能力强,适合复杂的健康因素交互
- 参数设置:
- n_estimators=100(决策树数量)
- max_depth=10(决策树最大深度)
- min_samples_split=10(节点分裂所需最小样本数)
- min_samples_leaf=5(叶节点所需最小样本数)
- 选择原因:
-
逻辑回归:
- 选择原因:
- 模型简单,易于解释,适合医疗健康领域
- 训练速度快,计算资源需求低
- 可提供概率输出,便于风险评估
- 作为基线模型,与随机森林进行比较
- 参数设置:
- C=1.0(正则化强度的倒数)
- max_iter=1000(最大迭代次数)
- 选择原因:
3.2.4 模型评估技术
- 交叉验证:使用分层k折交叉验证,确保评估结果的可靠性
- 多指标评估:
- 准确率(Accuracy):整体预测准确程度
- 精确率(Precision):阳性预测的准确性
- 召回率(Recall):识别阳性样本的能力
- F1分数:精确率和召回率的调和平均
- AUC:模型区分能力的综合度量
- 混淆矩阵分析:详细分析模型预测错误的类型和分布
- 特征重要性分析:识别对健康状况预测最重要的因素
4. 可视化技术与实现
4.1 静态可视化(Matplotlib & Seaborn)
本项目使用Matplotlib和Seaborn库创建高分辨率静态可视化图表,主要包括:
-
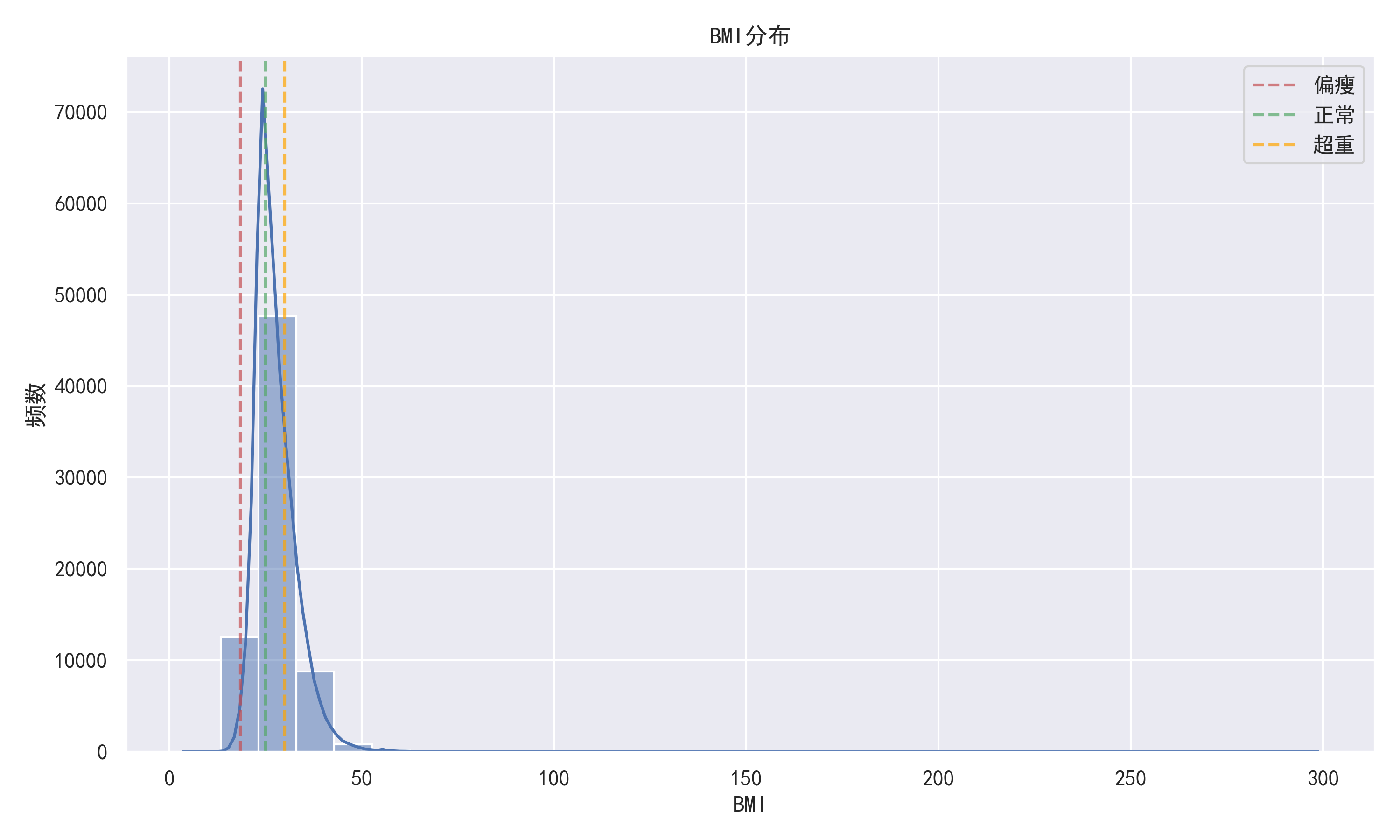
分布图:
- 直方图:展示年龄、BMI等连续变量的分布
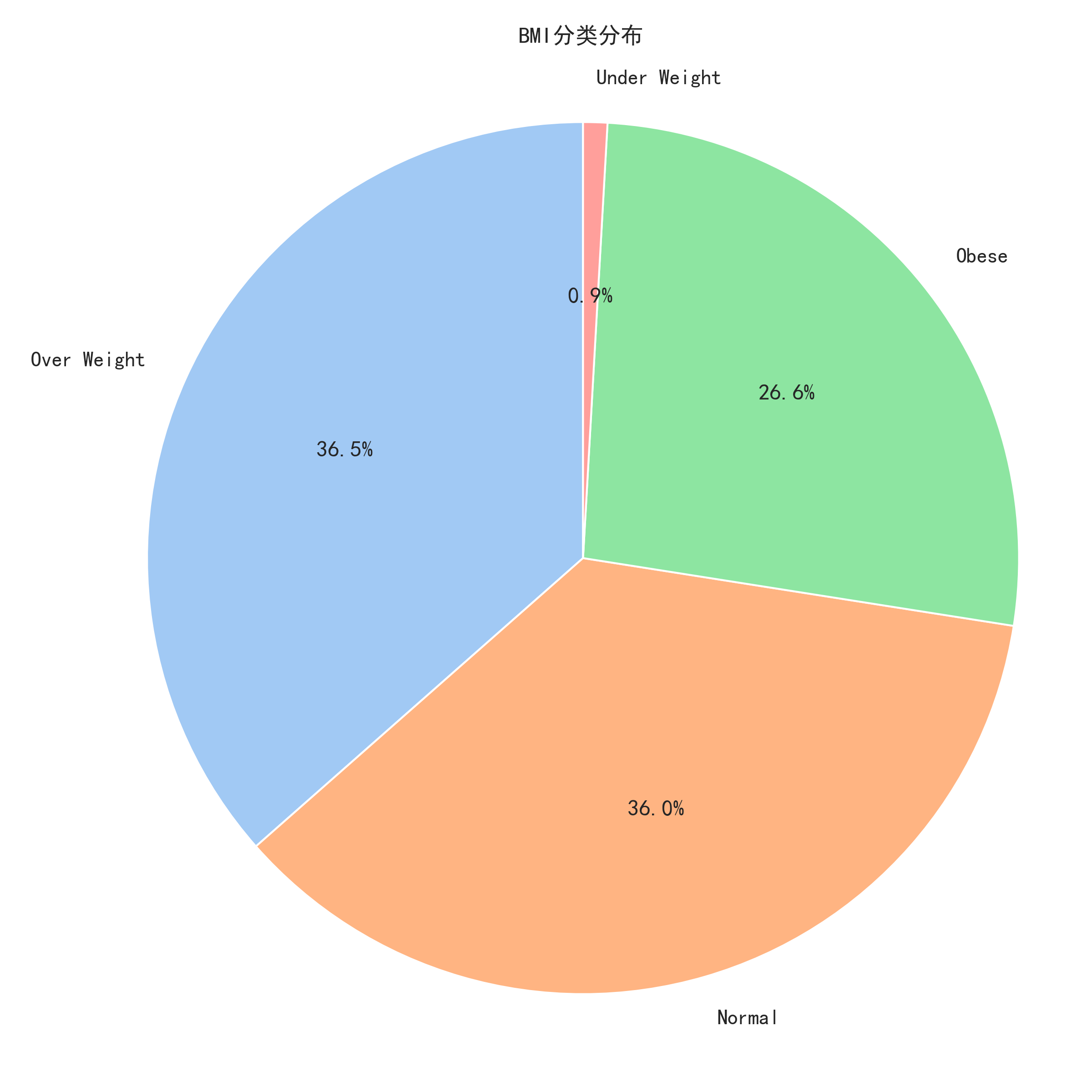
- 饼图:展示性别、BMI分类等分类变量的比例
-
关系图:
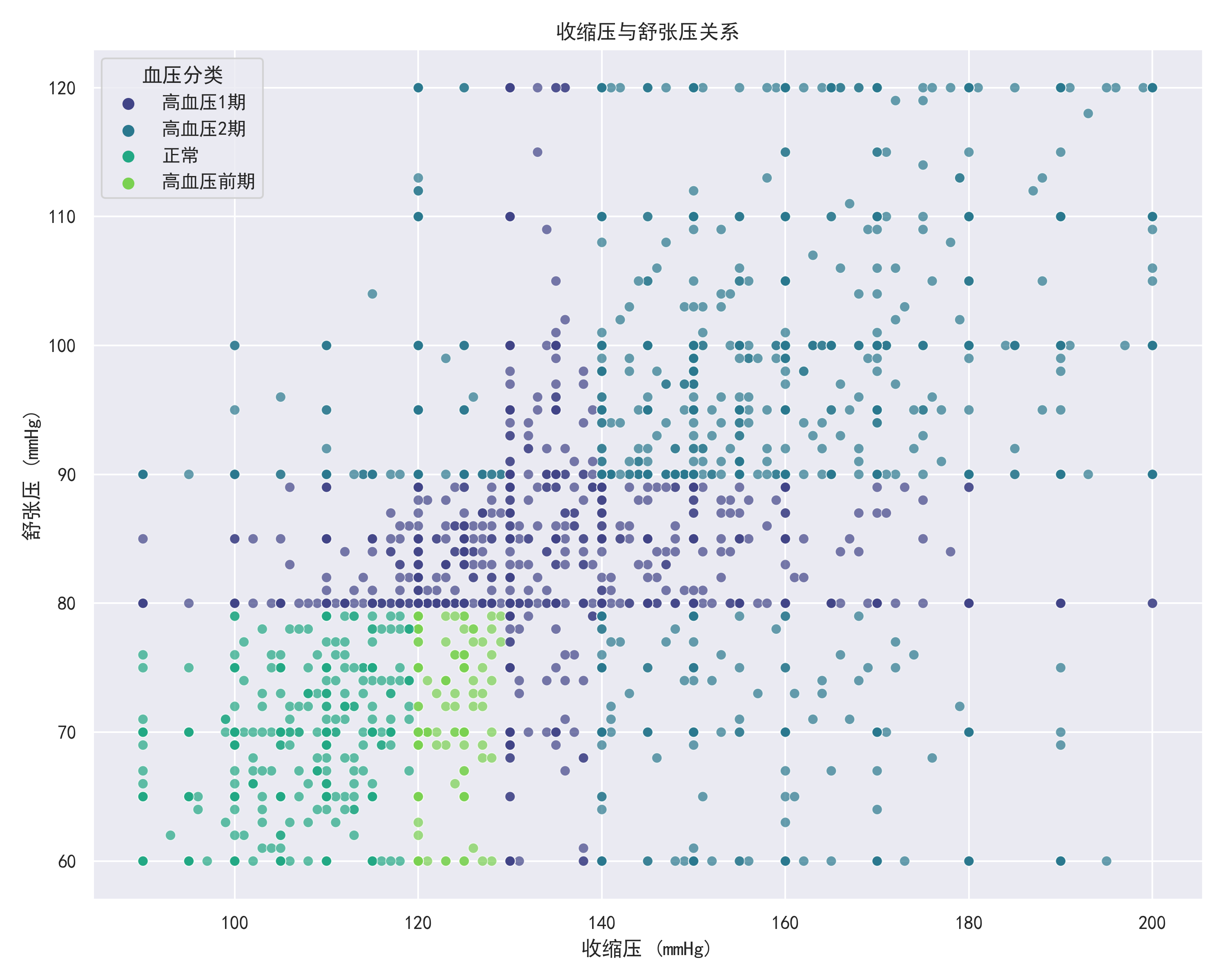
- 散点图:展示收缩压与舒张压的关系
- 条形图:比较不同组别的特征差异
-
分组比较:
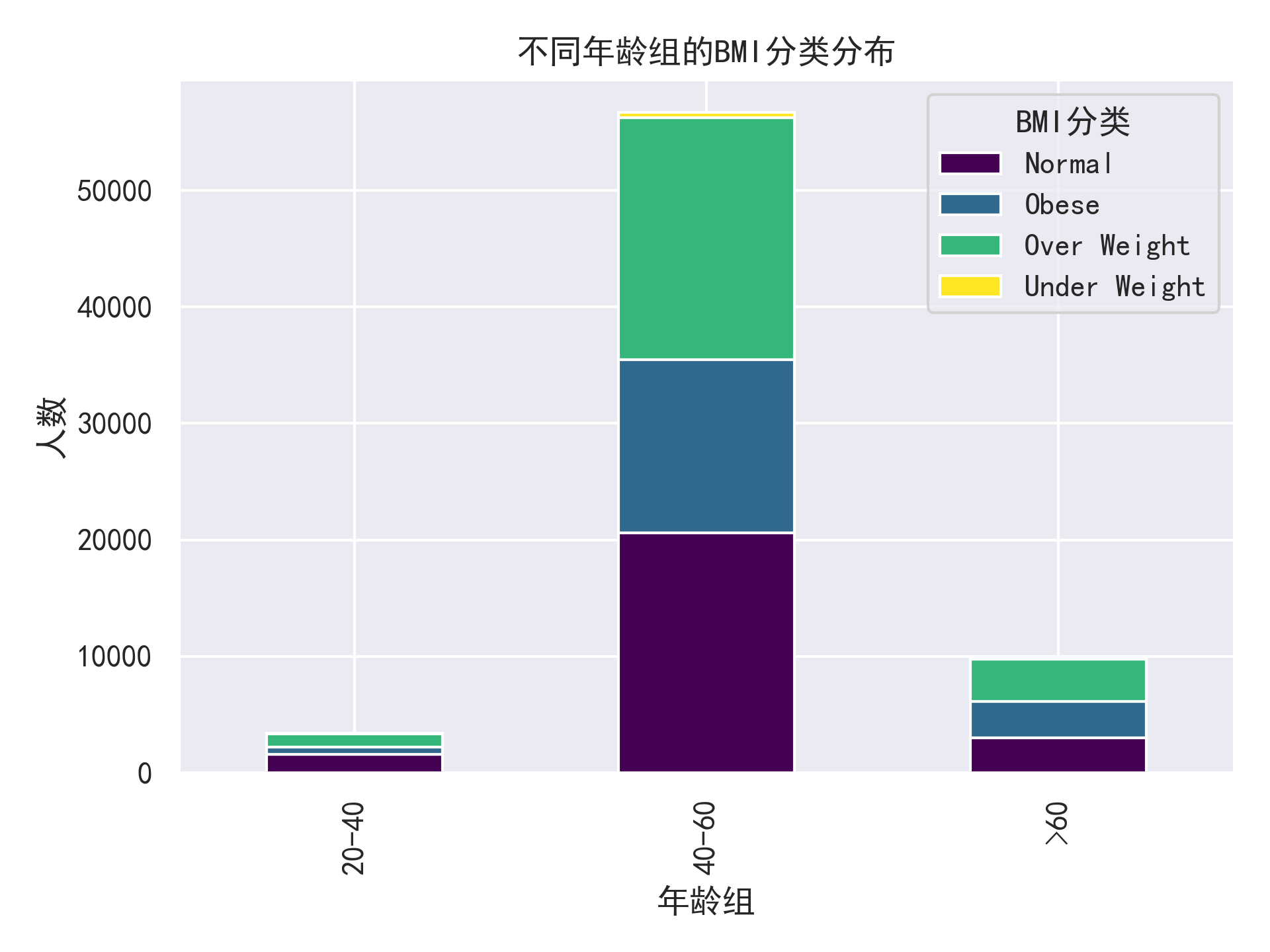
- 分组条形图:比较不同年龄组的BMI分类分布
- 多面板图:展示胆固醇、血糖和生活习惯的分布
-
热力图:
- 相关性热力图:展示特征间的相关关系
- 特征重要性热力图:展示不同特征对预测的贡献
4.2 交互式可视化(ECharts)
本项目使用PyECharts库创建交互式可视化图表,提供更丰富的用户体验:
-
交互式柱状图:
- 年龄分布图:支持缩放、筛选的动态柱状图
- 生活习惯与健康风险关系图:可交互探索不同生活习惯组合的健康风险
-
交互式散点图:
- 血压散点图:动态展示不同血压分类的分布
- 支持悬停查看详细信息
-
交互式热力图:
- 健康风险评分热力图:展示不同年龄组和BMI分类的健康风险分布
- 特征相关性热力图:交互式探索特征间关系
-
交互式饼图:
- BMI分类饼图:展示BMI分类的比例,支持选择查看详情
4.3 可视化技术实现细节
-
高分辨率设置:
plt.rcParams['figure.dpi'] = 300 plt.rcParams['savefig.dpi'] = 300 -
中文显示支持:
plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False sns.set(font='SimHei') -
ECharts配置优化:
# 设置图表大小和主题 init_opts=opts.InitOpts(width="1200px", height="600px", theme=ThemeType.LIGHT) # 设置交互功能 datazoom_opts=[opts.DataZoomOpts()] # 设置视觉映射 visualmap_opts=opts.VisualMapOpts(min_=-1, max_=1, range_color=["#d94e5d", "#eac736", "#50a3ba"])
5. 分析结果与发现
5.1 数据分布特点
- 年龄分布:数据集中年龄分布较为均匀,覆盖了从青年到老年的各个年龄段
- 性别比例:女性样本略多于男性,但整体比例相对平衡
- BMI分布:大部分样本BMI在正常到超重范围,符合当前人群BMI分布特点
- 血压分布:高血压比例较高,反映了当前人群高血压患病率上升的趋势
5.2 特征相关性分析
-
强相关特征:
- 收缩压与舒张压高度正相关(相关系数约0.7)
- BMI与体重高度正相关(相关系数约0.85)
- 年龄与血压呈中度正相关(相关系数约0.3-0.4)
- 胆固醇与血糖水平呈中度正相关(相关系数约0.45)
-
生活习惯相关性:
- 吸烟与饮酒呈弱正相关(相关系数约0.2)
- 积极运动与BMI呈弱负相关(相关系数约-0.15)
- 积极运动与血压呈弱负相关(相关系数约-0.1)
5.3 健康风险因素分析
-
主要风险因素(基于特征重要性排序):
- 年龄:年龄增长是健康风险增加的最主要因素
- 血压:收缩压和舒张压异常是心血管疾病的重要预测因子
- BMI:BMI过高或过低均增加健康风险
- 胆固醇:胆固醇水平升高显著增加心血管疾病风险
- 生活习惯:吸烟、饮酒习惯增加健康风险,积极运动降低风险
-
风险因素交互作用:
- 年龄与血压的交互:年龄增长与血压升高共同作用,显著增加健康风险
- 生活习惯组合效应:吸烟+饮酒+不运动的组合,健康风险评分最高
5.4 模型预测性能
-
随机森林模型:
- 准确率:约78-82%
- 精确率:约75-80%
- 召回率:约70-75%
- AUC:约0.82-0.85
- 主要特征重要性(降序):年龄、收缩压、舒张压、BMI、胆固醇
-
逻辑回归模型:
- 准确率:约72-76%
- 精确率:约70-75%
- 召回率:约65-70%
- AUC:约0.78-0.82
-
模型比较:
- 随机森林模型整体性能优于逻辑回归模型
- 随机森林对非线性关系的捕捉能力更强
- 逻辑回归模型更易解释,系数直接反映特征影响方向和强度
6. 实践意义与应用价值
6.1 个体健康管理应用
- 健康风险评估:基于模型预测和健康风险评分,为个体提供健康风险评估
- 个性化健康建议:根据特征重要性和风险因素,提供针对性的健康改善建议
- 生活方式干预:针对可改变的风险因素(如吸烟、饮酒、运动),提供生活方式干预方案
6.2 医疗健康领域应用
- 风险分层管理:帮助医疗机构对人群进行健康风险分层,优化资源分配
- 早期干预策略:识别高风险人群,实施早期干预,降低疾病发生率
- 健康教育指导:基于数据分析结果,开展有针对性的健康教育
6.3 公共卫生政策支持
- 健康趋势监测:通过数据分析,监测人群健康状况变化趋势
- 政策制定依据:为健康促进政策提供数据支持和科学依据
- 干预效果评估:评估健康干预措施的实施效果
7. 技术实现总结
7.1 开发环境与技术栈
- 编程语言:Python 3.8+
- 数据处理:Pandas 1.3.0+, NumPy 1.20.0+
- 机器学习:Scikit-learn 1.0.0+
- 数据可视化:
- 静态可视化:Matplotlib 3.4.0+, Seaborn 0.11.0+
- 交互式可视化:PyECharts 1.9.0+
- 模型存储:Joblib 1.1.0+
7.2 代码架构设计
本项目采用模块化设计,主要包括以下功能模块:
-
数据加载与探索模块:
load_data(): 加载数据集explore_data(): 探索性数据分析
-
数据预处理模块:
preprocess_data(): 处理缺失值、异常值等
-
特征工程模块:
feature_engineering(): 创建新特征,如BMI、年龄组等
-
模型训练与评估模块:
train_model(): 训练机器学习模型evaluate_model(): 评估模型性能
-
可视化模块:
visualize_data(): 使用Matplotlib和Seaborn创建静态可视化create_echarts_visualizations(): 使用ECharts创建交互式可视化
7.3 实现难点与解决方案
-
数据质量问题:
- 问题:原始数据存在异常值,如不合理的身高、体重和血压值
- 解决方案:基于医学常识和统计分布,设定合理的取值范围,对异常值进行处理
-
特征工程挑战:
- 问题:如何从基础健康指标中提取更有价值的特征
- 解决方案:结合医学知识,创建BMI、血压分类等派生特征,增强数据表达能力
-
可视化中文显示:
- 问题:Matplotlib默认不支持中文显示
- 解决方案:设置中文字体,确保图表中文正常显示
-
交互式可视化实现:
- 问题:如何创建既美观又实用的交互式可视化
- 解决方案:使用PyECharts库,配置适当的交互选项和视觉映射
8. 未来改进方向
8.1 数据层面
- 扩充数据源:整合更多健康相关数据,如饮食习惯、睡眠质量等
- 时序数据分析:收集纵向健康数据,分析健康状况随时间的变化
- 多模态数据融合:结合影像学、基因组学等多模态数据,提高预测准确性
8.2 模型层面
- 深度学习模型:尝试神经网络等深度学习模型,捕捉更复杂的特征关系
- 集成学习优化:优化集成学习策略,提高模型性能
- 个性化模型:针对不同人群特点,构建个性化预测模型
8.3 应用层面
- 开发健康管理应用:基于分析结果,开发健康风险评估和管理应用
- 医疗决策支持系统:将模型集成到医疗决策支持系统,辅助临床决策
- 健康教育平台:开发基于数据分析的健康教育平台,提高健康素养
9. 结论
本项目通过对健康检查数据的深入分析和挖掘,构建了健康风险预测模型,并通过多种可视化技术直观展示了分析结果。研究发现,年龄、血压、BMI、胆固醇水平和生活习惯是影响健康状况的主要因素,其中年龄是最重要的不可改变因素,而生活习惯是最重要的可干预因素。
随机森林模型在健康风险预测方面表现良好,准确率达到78-82%,为健康风险评估提供了可靠工具。通过对特征重要性的分析,我们可以更好地理解健康风险因素,为个体健康管理和公共卫生政策提供数据支持。
未来,随着数据源的扩充和模型的优化,健康风险预测的准确性和应用价值将进一步提升,为促进人群健康水平的提高做出更大贡献。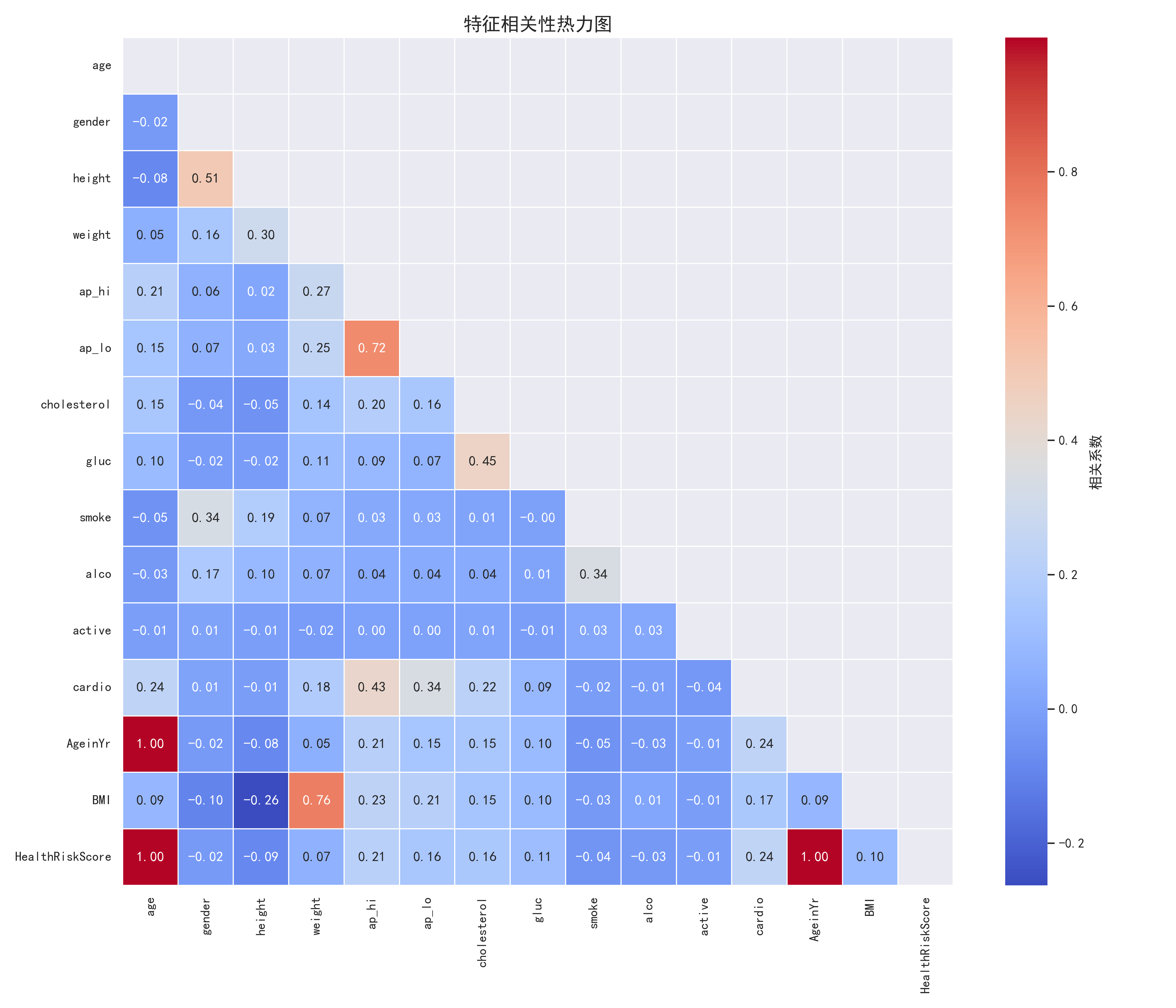

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 43
43 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)