NeurIPS2025 |WorldTrace 数据集 + UniTraj 模型,突破轨迹建模三大局限!
来自NeurIPS2025,最新前沿时序技术,针对人类轨迹建模,构建了首个源于 OpenStreetMap 开放平台的,全球大规模轨迹数据集WorldTrace,以及提出通用轨迹基础模型UniTraj。
本篇论文来自NeurIPS2025,最新前沿时序技术,针对人类轨迹建模,构建了首个源于 OpenStreetMap 开放平台的,全球大规模轨迹数据集WorldTrace,以及提出通用轨迹基础模型UniTraj。
了解顶会最新技术,紧跟科研潮流,研究与写作才能保持在时代一线,最新126篇NeurIPS2025前沿时序合集(更新中)小时已经整理好了,在宫🀄蚝“时序大模型”发送“资料”添加回复“NeurIPS2025时序合集”即可自取~其他顶会时序合集也可以回复相关顶会名称自取哈~(AAAI25,ICLR25,ICML25等)
文章信息
论文名称:UniTraj: Learning a Universal Trajectory Foundation Model from Billion-Scale Worldwide Traces
论文作者:Yuanshao Zhu,James Jianqiao Yu,Xiangyu Zhao, Xuetao Wei,Yuxuan Liang

研究背景
人类轨迹建模在交通管理、物流优化、基于位置的服务等领域至关重要。随着 GPS 设备普及,海量轨迹数据产生,但现有方法存在三大核心局限:
-
任务特异性:模型多为特定任务(如轨迹预测、异常检测)设计,跨任务适配需大量修改,复用性差。
-
区域依赖性:多数模型基于特定地理区域数据训练,难以适应不同地区的基础设施、交通模式差异,泛化能力弱。
-
数据质量敏感性:真实轨迹数据采样率、噪声水平不一,且常存在缺失值,现有模型对这类异质性数据鲁棒性不足,需大量预处理。
此外,构建通用轨迹基础模型还面临两大挑战:
-
一是现有轨迹数据集多为企业私有或区域受限(如 GeoLife 仅覆盖北京、Porto 聚焦葡萄牙波尔图),缺乏大规模、全球化、高质量的公开数据;
-
二是现有模型难以同时满足跨时空泛化、异质数据鲁棒性、复杂度与效率平衡的需求。
因此文章提出了WorldTrace数据集,以及UniTraj模型,以解决上述挑战问题。
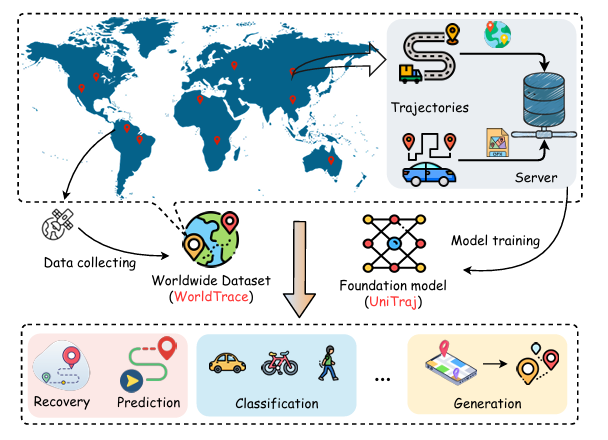
模型框架
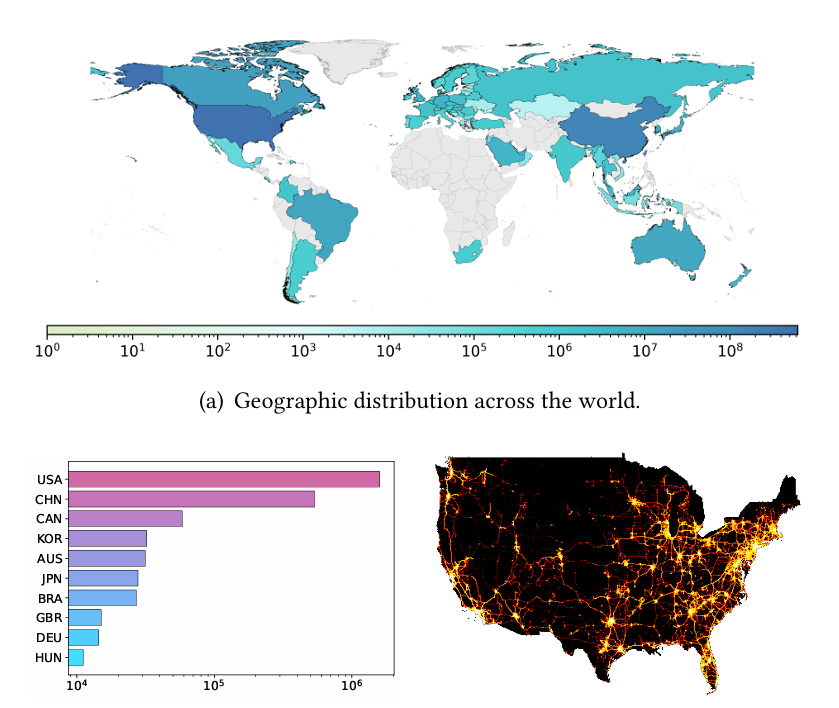
全球大规模轨迹数据集 WorldTrace
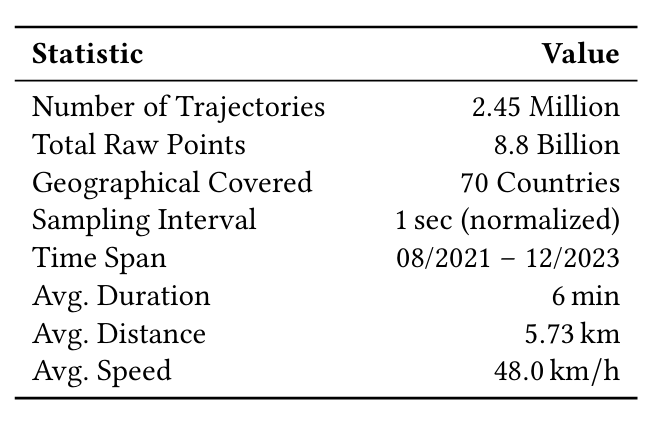
数据规模与覆盖:包含 245 万条轨迹、88 亿个 GPS 点,覆盖 70 个国家,时间跨度为 2021 年 8 月 - 2023 年 12 月,填补了全球化轨迹数据的空白。
来源:从 OpenStreetMap(OSM)平台筛选 2021-2023 年的车辆轨迹数据,采用 GPX 标准化格式,确保数据结构统一。
预处理:通过归一化(将 10Hz 采样率标准化为 1Hz,减少冗余)、过滤(剔除点数 <32 或距离 < 100 米的短轨迹,移除速度> 120km/h 的异常数据)、校准(结合地图匹配技术修正 GPS 定位误差)三步优化数据质量。
关键统计特征:平均轨迹时长 6 分钟、平均距离 5.73km、平均速度 48.0km/h,采样间隔统一为 1 秒,兼顾多样性与一致性。
隐私与版权:数据匿名化处理,遵循 ODbL 开源协议,提供样本供研究使用,支持广泛协作。
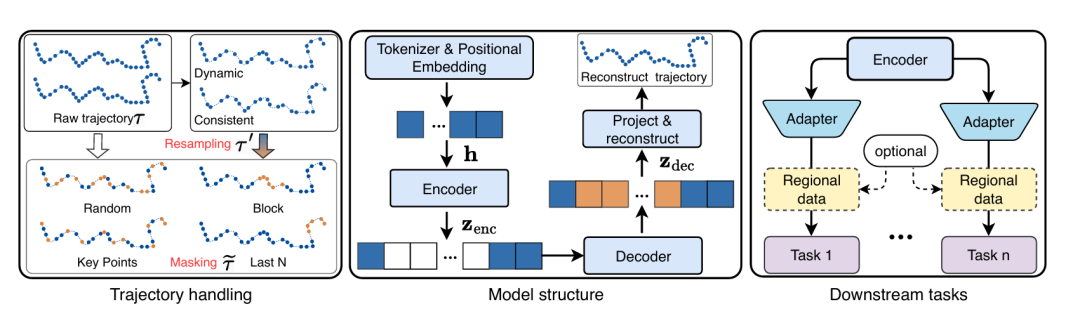
通用轨迹基础模型 UniTraj
核心定位:具备任务适应性、区域独立性和数据质量鲁棒性,可作为基础骨干网络,通过少量适配支持多轨迹分析任务。
核心技术设计
重采样策略:解决采样率异质性与轨迹长度失衡问题。
-
动态轨迹重采样:基于轨迹长度的对数采样比(短轨迹保留全部点,长轨迹降低采样比),平衡信息保留与计算效率。
-
间隔一致性重采样:将每条轨迹按固定时间间隔(如 3 秒)重采样,标准化时序结构,简化建模。
掩码策略:通过自监督学习增强模型泛化能力,模拟四类真实数据缺失场景。
-
随机掩码:随机掩盖轨迹点,学习全局时空依赖。
-
块掩码:掩盖连续点,训练长时依赖捕捉能力。
-
关键点掩码:基于 Ramer-Douglas-Peucker 算法识别转弯、变速等关键节点并掩码,强化轨迹结构理解。
-
末尾 N 点掩码:掩盖轨迹最后 N 个点,适配轨迹预测任务。
模型结构:采用 Encoder-Decoder 架构,基于 Transformer 实现。
-
轨迹分词器:将经纬度(归一化到起点)与时间间隔分别嵌入,再求和得到统一的点嵌入,保留时空信息。
-
位置嵌入:使用旋转位置编码(RoPE),通过向量旋转保留点间相对位置关系,支持局部与全局模式捕捉。
-
Encoder:处理未掩码点,学习压缩的轨迹 latent 表示;Decoder:结合掩码 token 重构缺失点,训练目标为最小化掩码位置的预测误差(MSE 损失)。
下游适配:预训练 Encoder 作为骨干,仅需添加少量任务头(如分类头、预测头)或微调,即可支持多任务。
实验数据
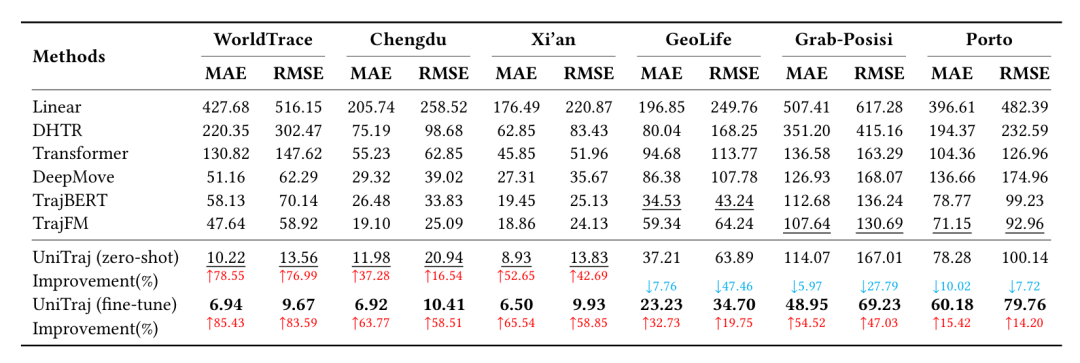
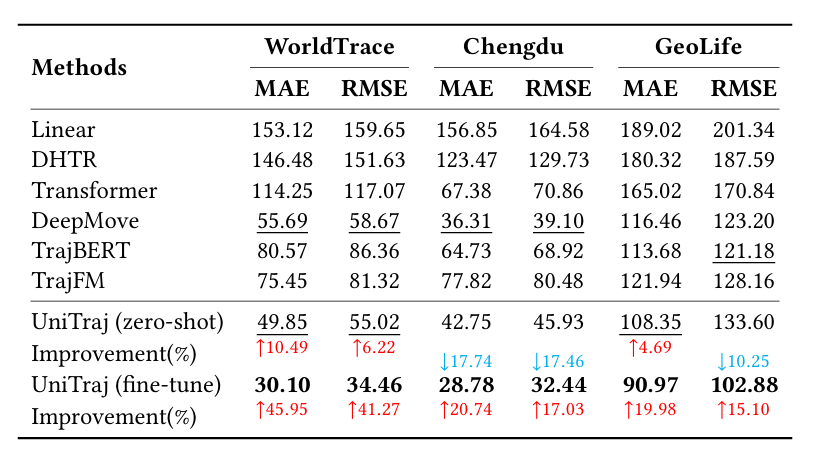
数据集:使用 WorldTrace 及 5 个真实数据集(Chengdu、Xi’an、GeoLife、Grab-Posisi、Porto),覆盖不同区域、采样率与任务场景。
对比基线:传统模型(Linear、DHTR、Transformer、DeepMove)与预训练模型(TrajBERT、TrajFM),评估指标包括 MAE、RMSE(轨迹恢复 / 预测)、准确率(分类)、密度误差(生成)。
模型参数:Encoder 含 8 个 RoPE 块、Decoder 含 4 个块,嵌入维度 128,总参数量 238 万,Adam 优化器,训练 200 轮, batch size=1024。
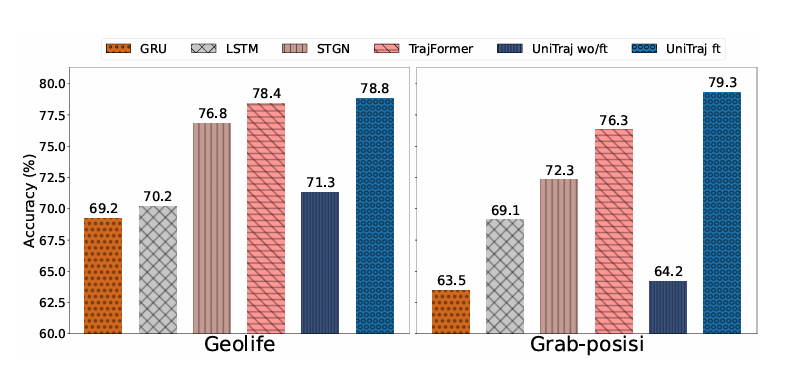

重点实验数据
任务适用性分析:UniTraj 在四类核心任务中均显著优于基线。
-
轨迹恢复:零样本场景下,WorldTrace 上 MAE 仅 10.22m(较 TrajFM 提升 78.55%);微调后 MAE 降至 6.94m,在 GeoLife(低质量数据)上 MAE 23.23m(较 TrajFM 减半)。
-
轨迹预测:预测 5 个未来点,Chengdu 数据集微调后 MAE 28.78m(较 DeepMove 低 20.74%),零样本性能仍优于多数基线。
-
轨迹分类:GeoLife 数据集微调准确率 78.8%(超 TrajFormer 等模型),无微调时 71.3%,验证预训练表示的有效性;Grab-Posisi(摩托车与汽车轨迹相似)微调准确率 79.3%,体现复杂场景适配能力。
-
轨迹生成:集成到 ControlTraj 框架,Chengdu 数据集密度误差从 0.0039 降至 0.0037,跨城市(成都→西安)误差从 0.0171 降至 0.0152,证明拓扑结构捕捉与区域泛化能力。
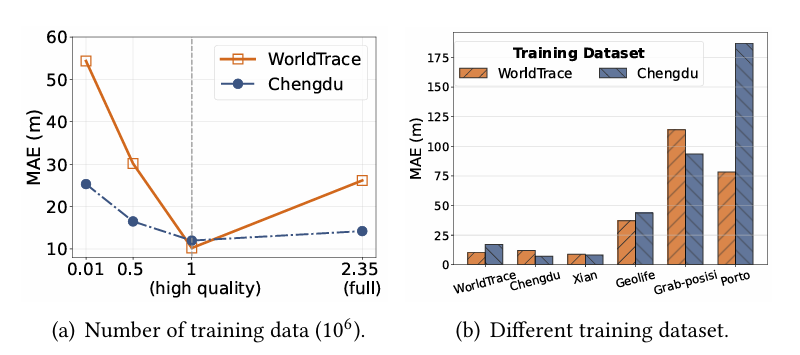
数据集研究:WorldTrace 的规模与多样性是模型性能关键。
-
数据量影响:随 WorldTrace 训练数据量增加(0.01M→1M),MAE 持续下降;高质量 1M 子集性能优于全量 2.45M 数据集,说明数据质量比单纯规模更重要。
-
多样性优势:WorldTrace 训练的模型在跨数据集(如 GeoLife、Porto)泛化性能优于 Chengdu(区域受限数据)训练的模型,且 WorldTrace 开源可获取,适用性更广。
消融实验:重采样与掩码策略缺一不可。
移除动态重采样:GeoLife、Grab-Posisi 等低质量数据集 MAE 大幅上升(如 Grab-Posisi 从 114.07m 升至 1933.28m)。
移除关键点掩码:Chengdu、Xi’an 等高质量数据集性能下降,说明关键结构捕捉的重要性。
最优参数:Encoder 块数 8、掩码比 50% 时性能最佳,过多块数或过高 / 过低掩码比均会导致性能下降。

小小总结
UniTraj 通过创新的重采样、掩码设计与 Transformer 架构,解决了现有轨迹模型的任务、区域、数据质量局限;WorldTrace 则为通用轨迹建模提供了高质量的全球化数据基础。为交通管理、城市规划等领域的轨迹分析提供了高效、通用的解决方案。
关注小时,持续学习前沿时序技术!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)