STATA入门指南,数据分析必看(内含stata安装包)
在科研过程中,掌握Stata工具不仅能提高效率,也能增强数据分析的说服力。在处理多表数据时,可以使用 merge/append(横向/纵向)合并数据集,了解不同合并类型(如一对一合并或多对一合并)。学习 help 和 search 命令,快速找到所需的帮助文档和命令解释。rename(重命名变量)、gen 和 replace(生成或修改变量),这些是数据处理的基础。在程序页面运行的代码无法保存,一
在科研过程中,掌握Stata工具不仅能提高效率,也能增强数据分析的说服力。今天小鹿给大家介绍一下Stata的基础功能。希望本文能帮助大家高效使用Stata,在学术研究的道路上事半功倍。
↓↓添加小助手↓↓
即可获取 完整版“Stata安装包”
为您的科研启程提供助力

01
认识 Stata
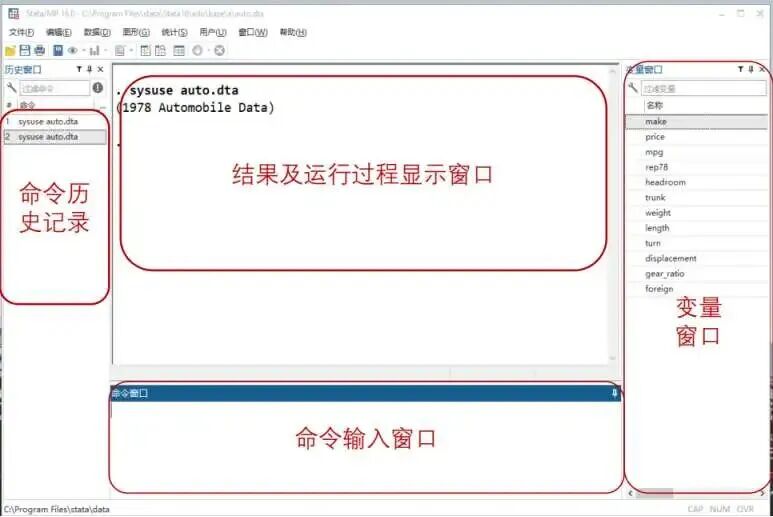
1.1用户界面介绍
Stata包括命令窗口、变量窗口、结果窗口、历史窗口等。了解各部分的功能将帮助你快速定位自己所需的操作。
1.2 Do file editor
在程序页面运行的代码无法保存,一般使用 ctrl+9 新建一个do文件,用来保存代码。
1.3 基础命令
学习 help 和 search 命令,快速找到所需的帮助文档和命令解释。了解该命令的使用方法:
help <想了解的命令>
导入数据:
import excel using "文件地址/数据文件.xlsx", firstrow
import delimited "文件地址/数据文件.csv", clear
保存数据:
save "文件地址/文件名"
切换到数据所在路径命令:
cd -- Change directory
Stata的注释:
在一行的开头输入*符号或者在命令后输入//符号。
*<注释>
//<注释>
数据浏览与基本操作:
使用 list 浏览数据,summarize /describe查看变量统计信息。
list varname
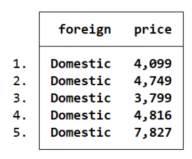
summarize/describe varname

02
数据处理
变量操作:
rename(重命名变量)、gen 和 replace(生成或修改变量),这些是数据处理的基础。
rename varname1 varname2
gen varname = 表达式
replace varname = 新值 if 条件
筛选和分组:
使用 keep 和 drop 筛选变量,sort 和 by 按分组处理数据;if 子句,如 summarize 变量 if 条件。
keep/drop varname
sort varname
by group: summarize varname if 条件
缺失值处理:
识别缺失值(missing 函数)清洗数据。
drop if missing (varname1 varname2......)
replace varname = 0 if missing varname
数据合并:
在处理多表数据时,可以使用 merge/append(横向/纵向)合并数据集,了解不同合并类型(如一对一合并或多对一合并)。
merge 1:1 主键变量 using "另一个数据文件.dta"
append using "追加的数据文件.dta"
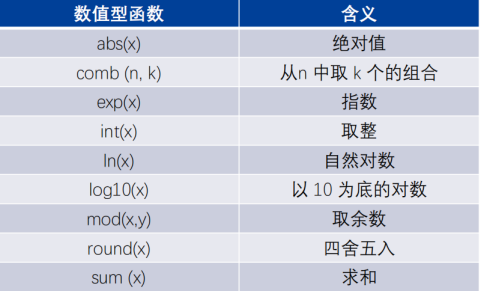
常用函数:
处理数据时常用的函数,可以在生成新变量的时候使用。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 7
7 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)