英伟达不同深度学习计算GPU的性能比较
A800和A100的区别是A800的NVlink带宽受到限制,多卡性能比A100差。
·
英伟达GPU发展时间线:
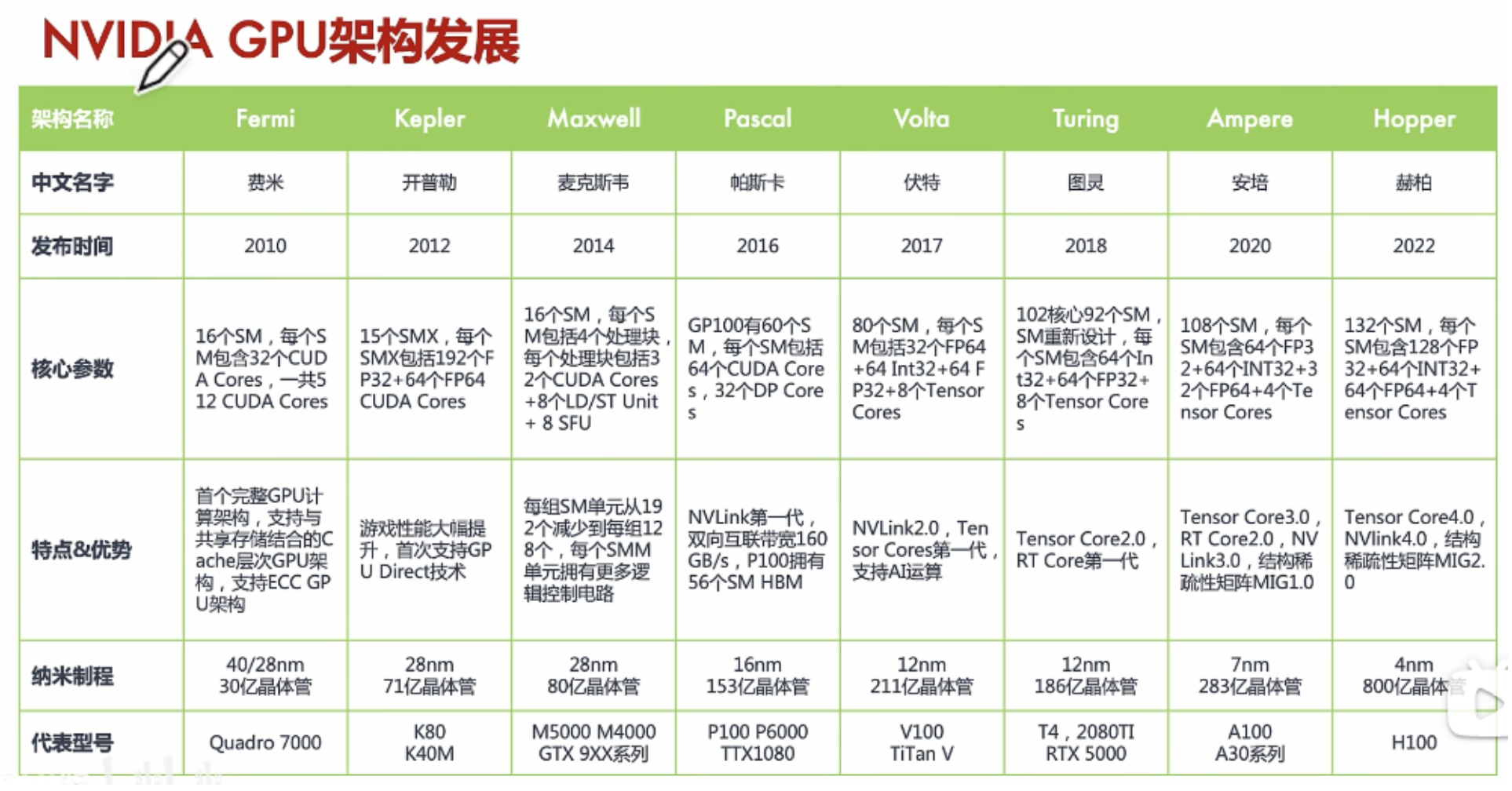
目前最新和最强的计算GPU是H200 (H100)(中国专供的H100阉割版为H800)
A100系列是上一代的版本
A100和A800

A800和A100的区别是A800的NVlink带宽受到限制,多卡性能比A100差

RTX4090和A100比较:
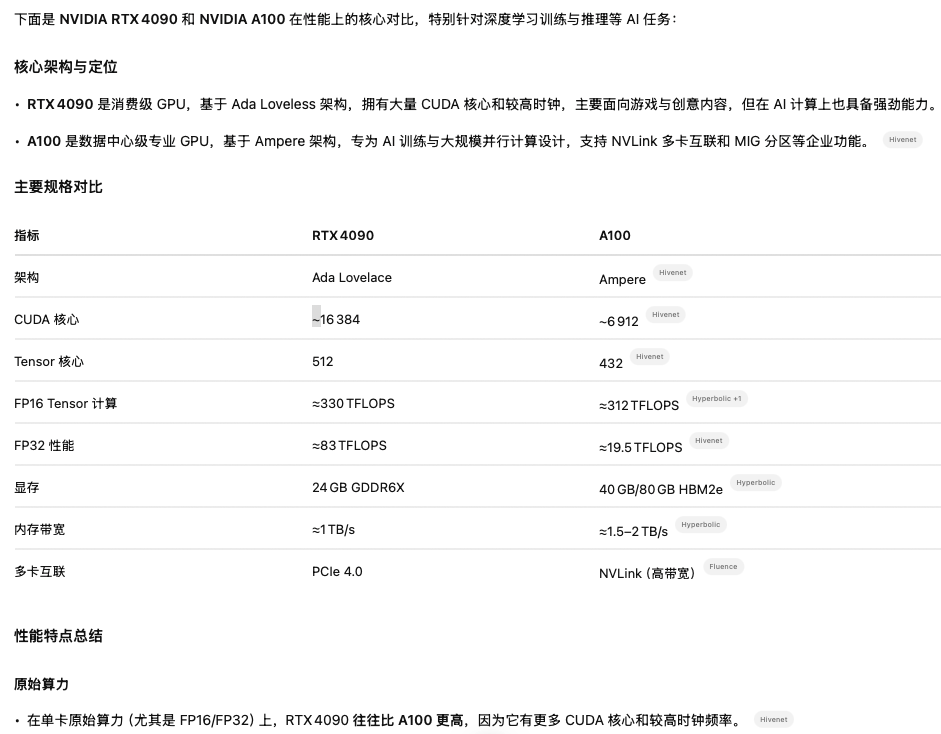
在单卡上4090比A100算力还更高一点。但是4090的显存会低很多,多卡性能会比4090强

H100
H100是A100的升级版,算力提升3倍
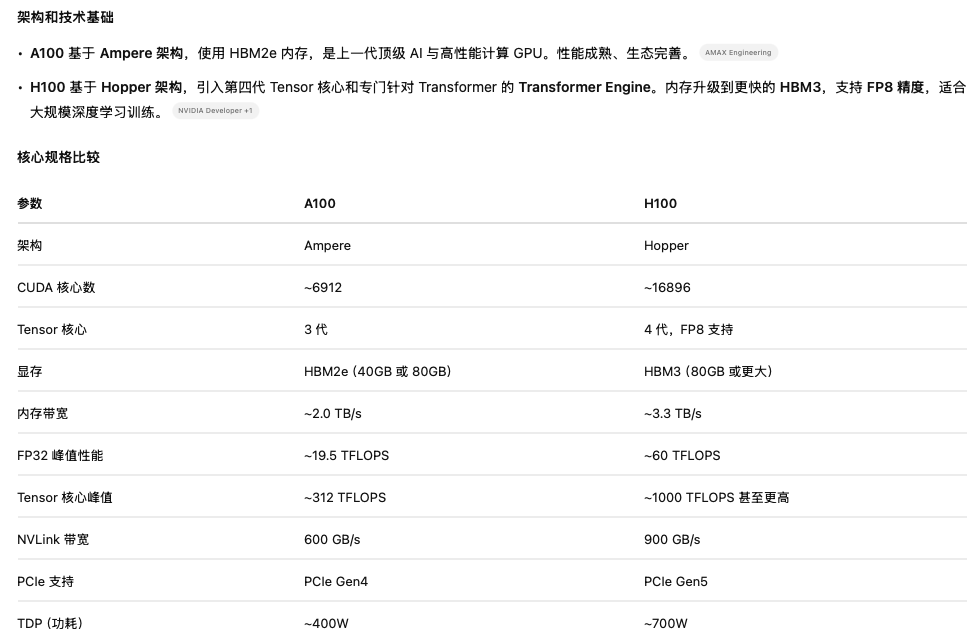
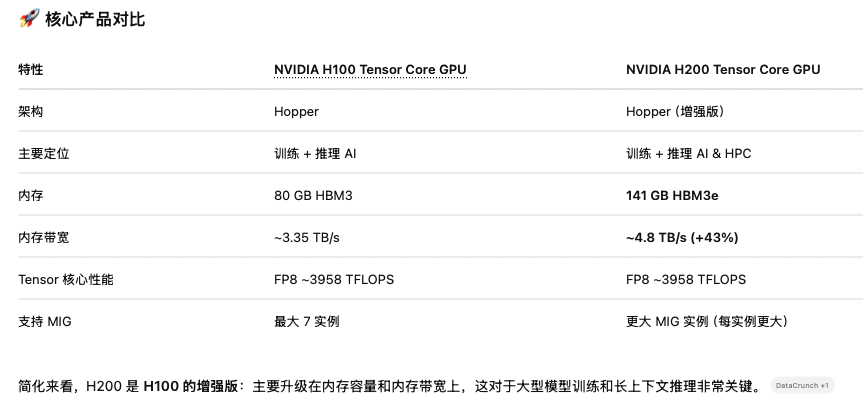
H200
H200和H100对比起来,H200主要是显存上从80G提升到了140G,在FP32算力上面和H100其实差不多

H20
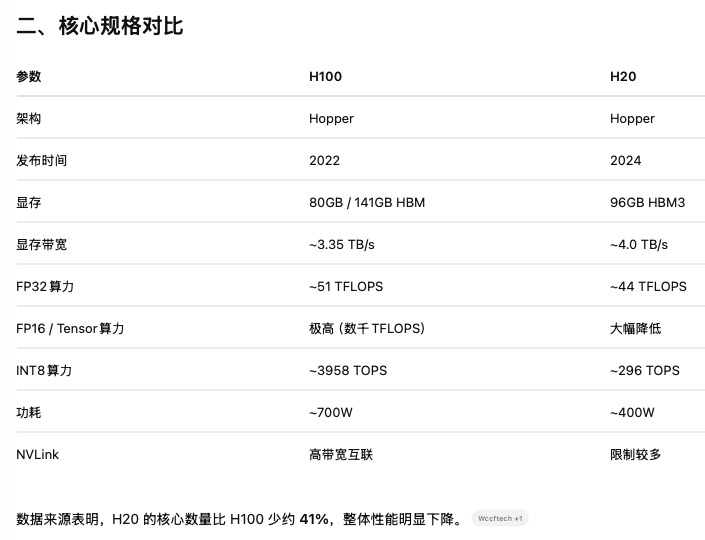
H100 = 顶级 AI 训练 GPU
H20 = 为中国市场降规格的 Hopper GPU,主要用于推理
H800
H800是H100的中国专供阉割版,性能比H100差一点

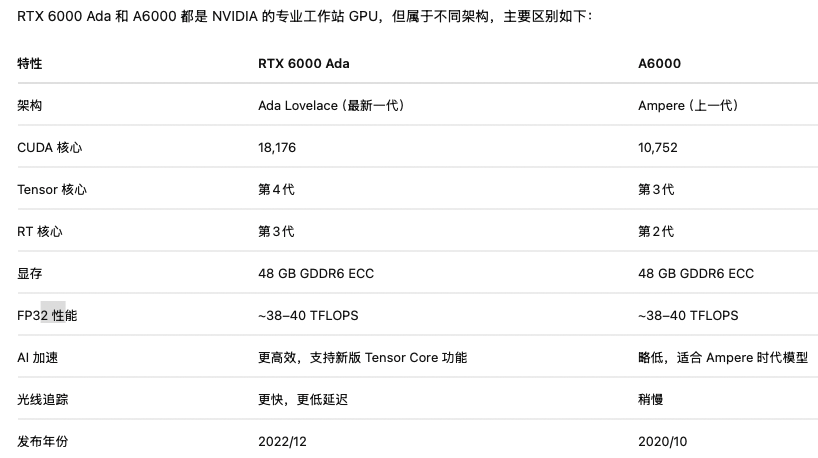
A6000和RTX6000 Ada
A6000的显存有48G,比A100要小,但是算力比A100快两倍

V100
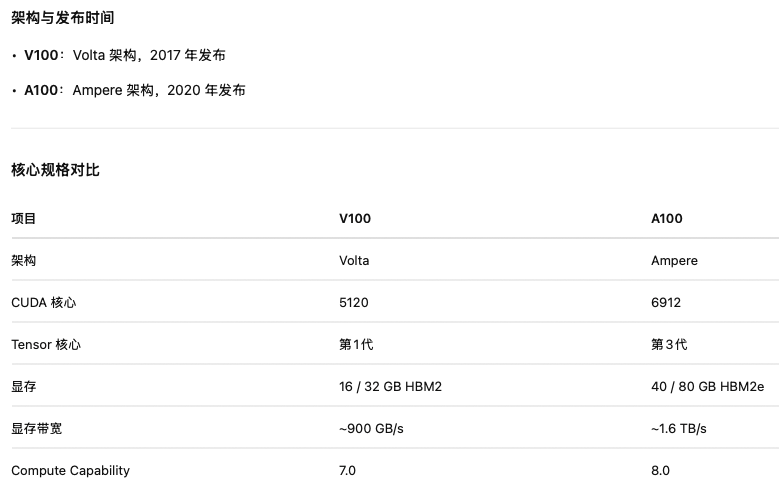
V100是很早的显卡:2017年
V100的显存只有32G

FLOPS解释:
FLOPS 是 Floating Point Operations Per Second(每秒浮点运算次数)的缩写,用来衡量计算机或 GPU 的 计算能力,尤其是执行浮点数运算的速度


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)