CVPR-2025 | 中山大学先验信息赋能具身导航!NaviBridger:基于去噪扩散桥模型的视觉导航
NaviBridger框架通过利用先验动作信息,显著提高了视觉导航任务中的动作生成效率和准确性!
·

- 作者: Hao Ren1^{1}1, Yiming Zeng1^{1}1, Zetong Bi1^{1}1, Zhaoliang Wan1^{1}1, Junlong Huang2^{2}2, Hui Cheng1^{1}1
- 单位:1^{1}1中山大学计算机科学与工程学院,2^{2}2中山大学智能系统工程学院
- 论文标题:Prior Does Matter: Visual Navigation via Denoising Diffusion Bridge Models
- 论文链接:https://openaccess.thecvf.com/content/CVPR2025/papers/Ren_Prior_Does_Matter_Visual_Navigation_via_Denoising_Diffusion_Bridge_Models_CVPR_2025_paper.pdf
- 代码链接:https://github.com/hren20/NaiviBridger
主要贡献
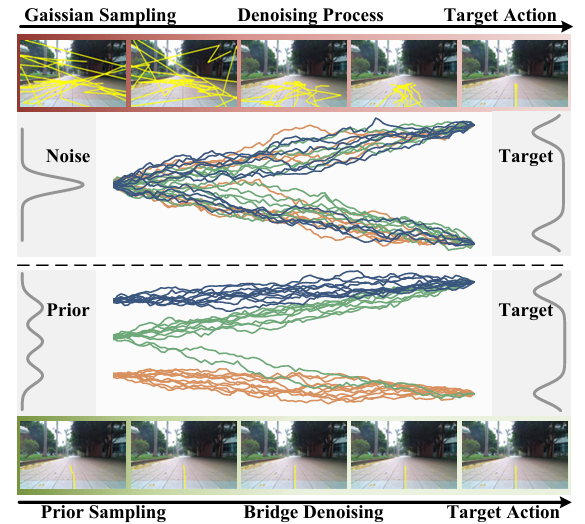
- 提出NaviBridger框架:首个探索将去噪扩散桥模型应用于视觉导航的工作。该框架基于去噪扩散桥模型(DDBM),通过使用先验动作而非高斯噪声作为初始输入,实现了性能与计算效率的有效平衡。
- 理论分析源分布影响:深入分析了源分布对基于扩散模型性能的影响,提出了针对不同源分布类型的先验动作生成方法,包括高斯噪声先验、基于规则的先验和基于学习的先验。
- 全面评估NaviBridger:通过在模拟和真实世界的室内及室外场景中进行大量实验,验证了NaviBridger框架的有效性。实验结果表明,该框架在多种场景下均优于基线模型,能够加速策略推理,并在生成目标动作序列方面表现出色。
研究背景
- 视觉导航是移动机器人的一项关键技术,它允许机器人通过视觉观察到达目标位置。传统的视觉导航方法通常包括全局规划器和局部规划器,其中全局规划器提供高级指令或子目标,局部规划器实时生成可行的局部路径。
- 近年来,基于扩散模型的模仿学习在视觉导航领域取得了显著进展,但现有方法通常从高斯噪声开始生成动作序列,这与目标动作分布存在较大差异,导致冗余的去噪步骤和增加的学习复杂性。
- 此外,有效动作分布的稀疏性也使得策略在没有引导的情况下难以生成准确的动作。因此,如何提高动作生成的效率和准确性成为了一个亟待解决的问题。
基础知识
扩散过程
- 定义与作用:扩散过程是一种逐渐向数据中添加噪声的过程,将数据从初始分布p0p_0p0转换为更简单的分布,通常是高斯分布pT=N(0,I)p_T = \mathcal{N}(0, I)pT=N(0,I)。这一过程在生成模型中用于模拟数据的退化过程,为后续的去噪过程提供基础。
- 数学描述:扩散过程可以通过随机微分方程(SDE)来描述,具体形式如下:
dxt=f(xt,t)dt+g(t)dwt dx_t = f(x_t, t)dt + g(t)dw_t dxt=f(xt,t)dt+g(t)dwt
其中,f(xt,t)f(x_t, t)f(xt,t)是漂移函数,描述了数据在时间ttt处的漂移趋势;g(t)g(t)g(t)是扩散系数,控制噪声的强度;wtw_twt表示维纳过程,引入随机性。
扩散桥
- 定义与作用:扩散桥是扩散过程的扩展,它不仅考虑了从初始分布到目标分布的转换,还确保生成的数据能够从一个特定的起始分布过渡到一个指定的终点分布。这在视觉导航等任务中尤为重要,因为它允许模型从一个与目标动作分布更接近的分布开始,从而提高生成动作的准确性和效率。
- 数学描述:扩散桥的前向过程可以表示为:
dxt=[f(xt,t)+g(t)2h(xt,t,y,T)]dt+g(t)dwt dx_t = [f(x_t, t) + g(t)^2h(x_t, t, y, T)]dt + g(t)dw_t dxt=[f(xt,t)+g(t)2h(xt,t,y,T)]dt+g(t)dwt
其中,h(xt,t,y,T)=∇xtlogp(xT∣xt)∣xt=x,xT=yh(x_t, t, y, T) = \nabla_{x_t} \log p(x_T | x_t) \big|_{x_t=x, x_T=y}h(xt,t,y,T)=∇xtlogp(xT∣xt) xt=x,xT=y是Doob的h变换,用于确保在时间TTT时接近目标分布yyy。
去噪扩散桥模型
- 定义与作用:DDBM是扩散模型的推广,它允许在配对分布之间进行转换,通过反向时间SDE或概率流ODE来实现。DDBM的核心在于通过去噪过程将初始动作分布逐步调整为目标动作分布,这一过程在视觉导航任务中用于生成准确的动作序列。
- 数学描述:对于反向扩散桥,其SDE可以表示为:
dxt=[f(xt,t)−g(t)2(s(xt,t,y,T)−h(xt,t,y,T))]dt+g(t)dwˉt dx_t = [f(x_t, t) - g(t)^2(s(x_t, t, y, T) - h(x_t, t, y, T))]dt + g(t)d\bar{w}_t dxt=[f(xt,t)−g(t)2(s(xt,t,y,T)−h(xt,t,y,T))]dt+g(t)dwˉt
其中,s(xt,t,y,T)=∇xtlogq(xt∣xT)∣xt=x,xT=ys(x_t, t, y, T) = \nabla_{x_t} \log q(x_t | x_T) \big|_{x_t=x, x_T=y}s(xt,t,y,T)=∇xtlogq(xt∣xT) xt=x,xT=y是得分函数,用于指导去噪过程;h(xt,t,y,T)h(x_t, t, y, T)h(xt,t,y,T)确保向目标分布的过渡。 - 损失函数:DDBM通过去噪得分匹配来学习得分函数,损失函数定义为:
Lθ=Ext,x0,t[w(t)∥sθ(xt,xT,t)−∇xtlogq(xt∣x0,xT)∥2] L_\theta = \mathbb{E}_{x_t, x_0, t} \left[ w(t) \left\| s_\theta(x_t, x_T, t) - \nabla_{x_t} \log q(x_t | x_0, x_T) \right\|^2 \right] Lθ=Ext,x0,t[w(t)∥sθ(xt,xT,t)−∇xtlogq(xt∣x0,xT)∥2]
其中,w(t)w(t)w(t)是损失函数的权重调度器,用于平衡不同时间步的损失。
研究方法
文章提出的NaviBridger框架包含三个核心组件:特征提取模块、先验动作生成模块和去噪扩散桥模块。该框架通过从观察到的任意源分布策略映射到目标分布策略,而不是依赖于在固定的高斯噪声空间内进行采样和去噪。
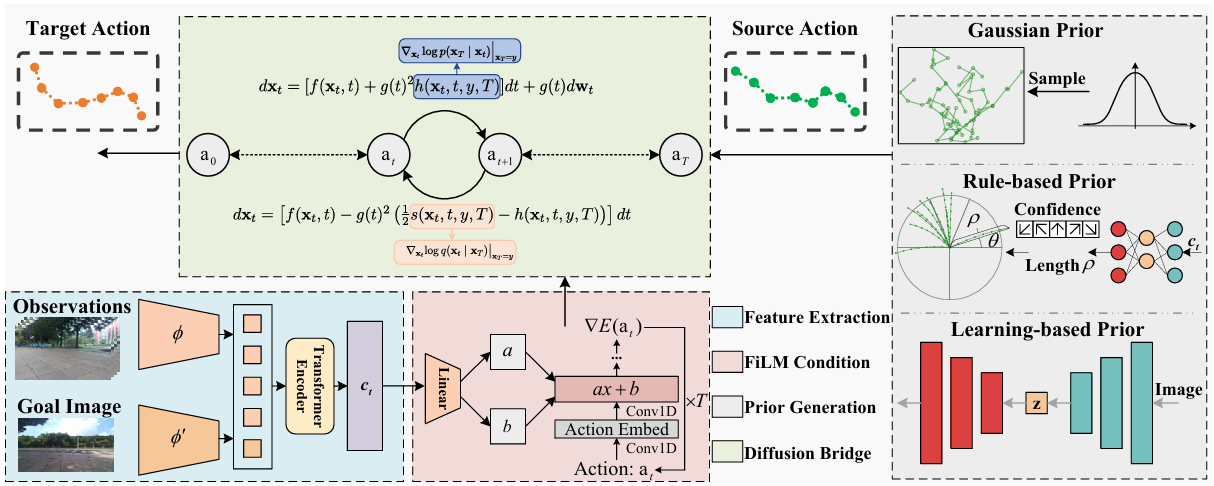
去噪扩散桥模型(DDBM)
- DDBM通过扩展传统的扩散模型,允许在两个固定分布之间进行插值,确保生成的数据从起始分布过渡到指定的终点分布。
- NaviBridger利用DDBM的这一特性,将动作生成过程从高斯噪声初始化转变为从基于观察的任意源分布策略开始。
- 具体来说,DDBM的反向扩散过程可以通过以下随机微分方程(SDE)描述:
dat=[f(at,t)−g2(t)(s(at,t,aT,T)−h(at,t,aT,T))]dt+g(t)dw^t da_t = [f(a_t, t) - g^2(t)(s(a_t, t, a_T, T) - h(a_t, t, a_T, T))]dt + g(t)d\hat{w}_t dat=[f(at,t)−g2(t)(s(at,t,aT,T)−h(at,t,aT,T))]dt+g(t)dw^t
其中,f(at,t)f(a_t, t)f(at,t)表示漂移项,g(t)g(t)g(t)是扩散系数,s(at,t,aT,T)s(a_t, t, a_T, T)s(at,t,aT,T)是得分函数,h(at,t,aT,T)h(a_t, t, a_T, T)h(at,t,aT,T)是Doob的h变换,用于调整扩散路径,确保从asa_sas到aTa_TaT的受控过渡。
先验策略设计
论文提出了三种生成先验动作的方法,包括高斯噪声先验、基于规则的先验和基于学习的先验。
- 高斯噪声先验:
- 作为无信息先验,选择高斯白噪声作为源分布,与传统的扩散模型一致。这种方法便于与基于原始扩散方法的模型进行直接比较。
- 基于规则的先验:
- 通过简单的全连接层将上下文向量映射到动作空间,提取与动作生成相关的低维特征。先验动作被预设为通过当前点的抛物线路径,该路径的形状基于预测的路径长度和运动行为分类(直行、左转、右转、右U转和左U转)来确定。
- 基于学习的先验:
- 利用专家数据和学习模型来生成先验动作。文章中使用了一个轻量级的条件变分自编码器(CVAE)作为学习模型,通过将观测数据输入CVAE来产生相应的动作。
- 这种方法旨在有效地捕捉观测数据和动作之间的显著相关性,从而以较低的计算成本高效地获得源分布。
训练细节
- 去噪网络:
- 使用一维时间卷积神经网络(1-D temporal CNN),以从观测数据中提取的上下文向量ctc_tct为条件,对先验动作aTa_TaT进行迭代去噪。网络通过特征线性调制(FiLM)进行调节,并执行k次去噪迭代。
- 损失函数:
- 损失函数由扩散桥损失LbL_bLb、先验动作生成损失LpL_pLp和时间距离损失LdL_dLd组成。
- 扩散桥损失LbL_bLb通过加权均方误差(MSE)损失函数计算;先验动作生成损失LpL_pLp根据基于规则的方法和基于学习的方法有所不同,基于规则的方法使用均方误差和交叉熵损失,而基于学习的方法使用条件变分自编码器(CVAE)的损失函数;时间距离损失LdL_dLd用于量化目标图像和当前图像之间在离散时间线上的间隔数量。
实验
实验在模拟和真实世界的室内及室外环境中进行,以评估NaviBridger框架的有效性。实验使用了来自不同环境和机器人平台的数据集,包括RECON、SCAND、GoStanford和SACSoN数据集。
性能指标
实验报告了路径长度、碰撞次数和成功率三个指标,以全面评估视觉导航方法的性能。
结果
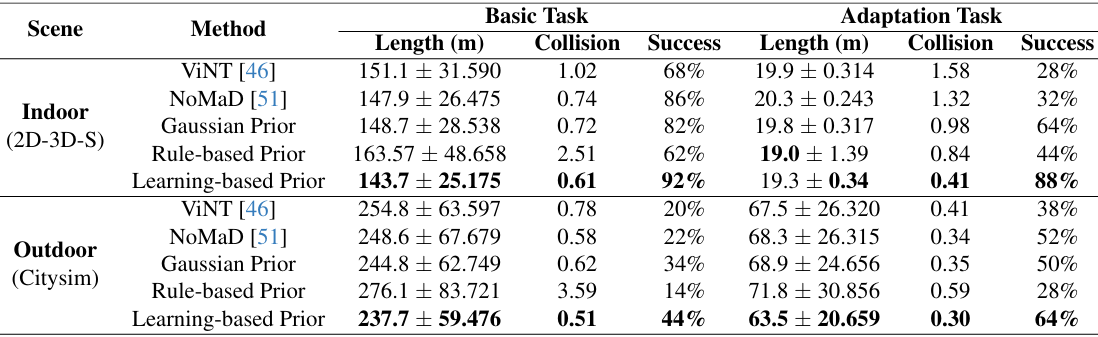
- 模拟环境实验:
- 在模拟环境中,基于学习的先验方法在各种任务和场景中表现最佳,显示出良好的泛化能力。高斯先验方法在某些任务中与基线方法相当,但在复杂环境中表现稍弱。基于规则的先验方法在特定场景中表现良好,但缺乏广泛的泛化能力。
- NaviBridger在减少碰撞次数和提高成功率方面优于基线模型。具体来说,在室内场景中,基于学习的先验方法的路径长度为143.7米,碰撞次数为0.61,成功率为92%;在室外场景中,路径长度为237.7米,碰撞次数为0.51,成功率为44%。
- 相比之下,NoMaD方法在室内场景中的路径长度为147.9米,碰撞次数为0.74,成功率为86%;在室外场景中的路径长度为248.6米,碰撞次数为0.58,成功率为22%。

- 真实世界实验:
- 在真实世界环境中,NaviBridger框架也表现出良好的泛化能力。实验结果表明,该框架能够在不同的场景和机器人配置下,生成一致且有效的导航轨迹。
- 例如,在真实世界的室外环境中,基于学习的先验方法能够使机器人在铺有瓷砖的小径上进行导航,展现出良好的适应性和鲁棒性。
消融研究
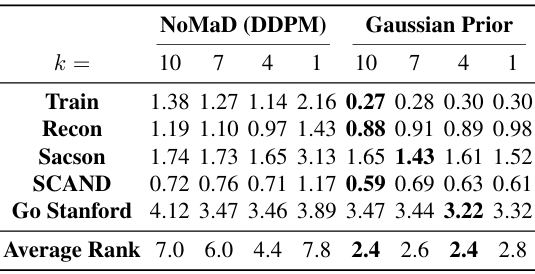
- 去噪步骤对模型学习的影响:
- 实验结果表明,随着去噪步骤的减少,基于DDPM的方法预测轨迹与专家轨迹之间的差异显著增加,而NaviBridger与高斯先验之间的差异相对稳定。
- 无论去噪步骤的数量如何变化,NaviBridger始终能够获得更好的排名,并且排名变化较小。
- 这表明NaviBridger在不同去噪步骤下均优于基于DDPM的方法,并且更少的去噪步骤就能达到相似的性能。
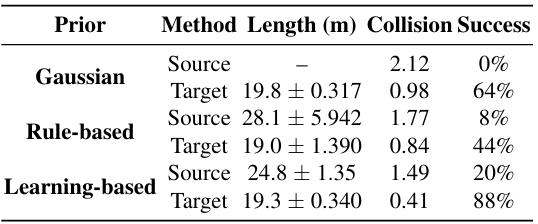
- 源分布和扩散桥的作用:
- 实验结果表明,随着先验生成方法从随机到有序、从基于启发式的规则到基于专家数据的方法转变,仅使用先验动作进行导航的成功率有所提高,尽管仍然较低。
- 经过桥去噪后,导航成功率显著提高。这表明,更有信息量的先验动作有助于提高性能,同时扩散桥能够有效地将不太有效的先验动作转换为更高质量的目标动作,从而提高整体性能。
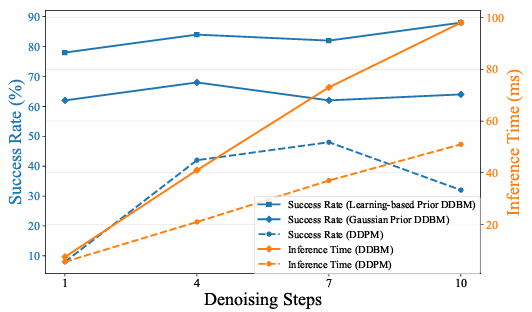
- 去噪步骤与成功率及推理时间的关系:
- 实验结果表明,基于学习的先验DDBM在较少的去噪步骤下就能达到较高的成功率,并且在推理时间上也表现出较好的平衡。
- 相比之下,高斯先验DDBM的成功率适中且略有波动,而DDPM的成功率较低。这进一步证明了基于学习的先验DDBM在视觉导航任务中的高效性和可靠性。
结论与未来工作
- 结论:
- 文章提出的NaviBridger框架通过利用先验动作信息,显著提高了视觉导航任务中的动作生成效率和准确性。
- 该方法在模拟环境中显示出较高的成功率和较低的碰撞次数,并且在真实世界的实验中也表现出良好的泛化能力。
- 然而,文章也指出,尽管该方法在一定程度上能够泛化到动态场景,但在存在高速移动物体的复杂场景中,可能需要更快的响应或自适应策略。
- 未来工作:
- 未来的工作可能会集中在进一步提高模型在动态环境中的性能,以及探索更多的先验动作生成策略,以进一步优化视觉导航的性能。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 57
57 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)