音频调试记录!
前言:大家好,公众号现在可以留言了,后期可以和大家互动交流!今天主要给大家分享一下,最近调试音频的感受!音频调试:我相信大家平时学习和开发,可能接触视频编解码会比较多,对h264和h265会比较熟悉一点!估计大家平时接触音频的技术点会比较少,在音频技术点上,平时会遇到的技术难点,比如:回声、噪声等音质问题出现,这个相对来说会比较难解决,主要问题点首先要定位清楚,是硬件影响的还是软件影响的,或者说软
前言:
大家好,公众号现在可以留言了,后期可以和大家互动交流!
今天主要给大家分享一下,最近调试音频的感受!
音频调试:
我相信大家平时学习和开发,可能接触视频编解码会比较多,对h264和h265会比较熟悉一点!
估计大家平时接触音频的技术点会比较少,在音频技术点上,平时会遇到的技术难点,比如:回声、噪声等音质问题出现,这个相对来说会比较难解决,主要问题点首先要定位清楚,是硬件影响的还是软件影响的,或者说软件算法上可以进行优化!
这就会涉及到音频soc的移植和调试以及相关驱动编写。同时把底层采集到的原始音频数据,要经过上层的编码器进行编码和在业务上进行解码操作,在嵌入式里面,目前用的比较多的编码器标准:
-
AAC
-
G7xx
这里我主要以aac编码和解码来说,常见的aac编码器和解码器开源项目有:
-
fdk-aac
-
faac
-
faad2
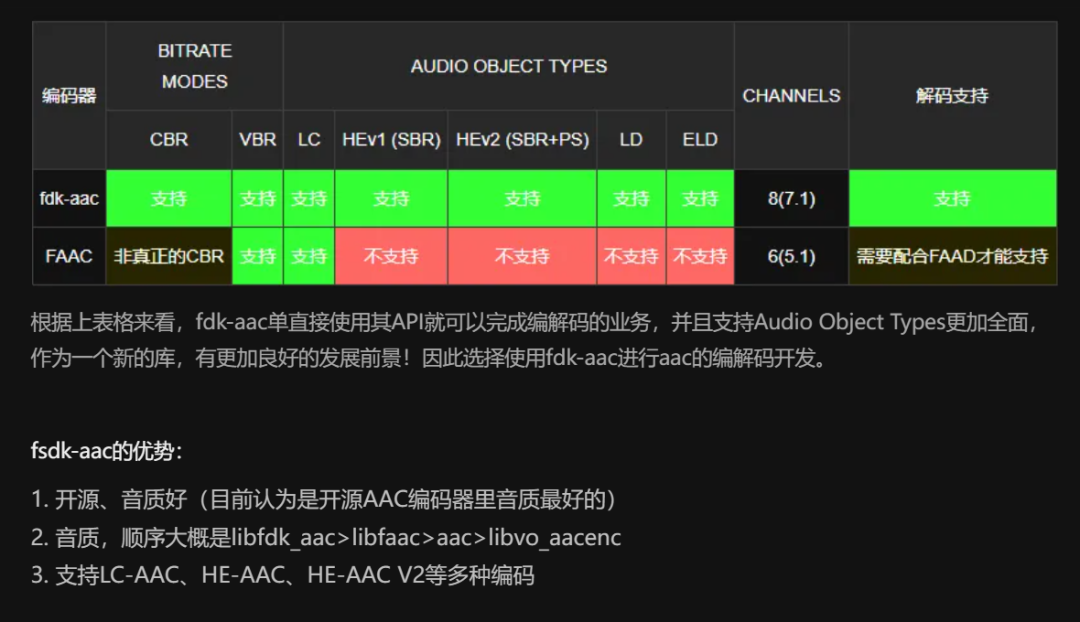
最近在调试音频的时候,把采集的pcm通过fdk-aac进行编码的时候,由于是第一次使用fdk-aac(交叉移植第一次到zynq平台),在使用过程中遇到一个坑,就是fdk-aac源码里面不支持24bit的编码,目前只支持16bit,当时调试,底层只支持24bit来存储音频数据,经过编码后成aac音频文件,声音死活都是异常的,就像以前小时候看黑白电视机的声音一样!
在这次调试过程中,也熟悉了tiny-alsa和alsa的应用编程使用,当时一开始用tiny-alsa去访问声卡,以为采集的pcm也有问题,后面就使用alsa去采集,发现也是一样的问题,声音异常;最后后面才排查到是,是底层支持的24bit采样位深度,实际是32bit的,当时用命令arecord 命令录制出来的声音,通过aplay命令播放是正常的,所以就没有怀疑底层声卡的问题!
以上就是在调试音频的时候,遇到的一些问题总结!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)