GLM-4.5发布:面向推理、代码与智能体的开源SOTA模型
GLM-4.5是智谱AI推出的国产开源大模型,采用混合专家架构(MoE)与“深度优先”设计理念,在性能与效率之间实现精妙平衡。模型分为旗舰版与轻量版,结合Grouped-Query Attention机制和Muon优化器,显著提升了推理能力和训练效率。在MMLU等权威基准上表现优异,具备强大的代码生成与多任务处理能力。其开源生态完善,支持多种推理框架,并通过三阶段训练体系实现高质量模型构建,为国产
当国产大模型在开源赛道上持续发力时,智谱AI最新推出的GLM-4.5系列为技术社区带来了实质性突破。这款采用混合专家架构(MoE)的旗舰模型,通过精妙的架构设计实现了性能与效率的平衡,为开源大模型领域树立了新的技术标杆。
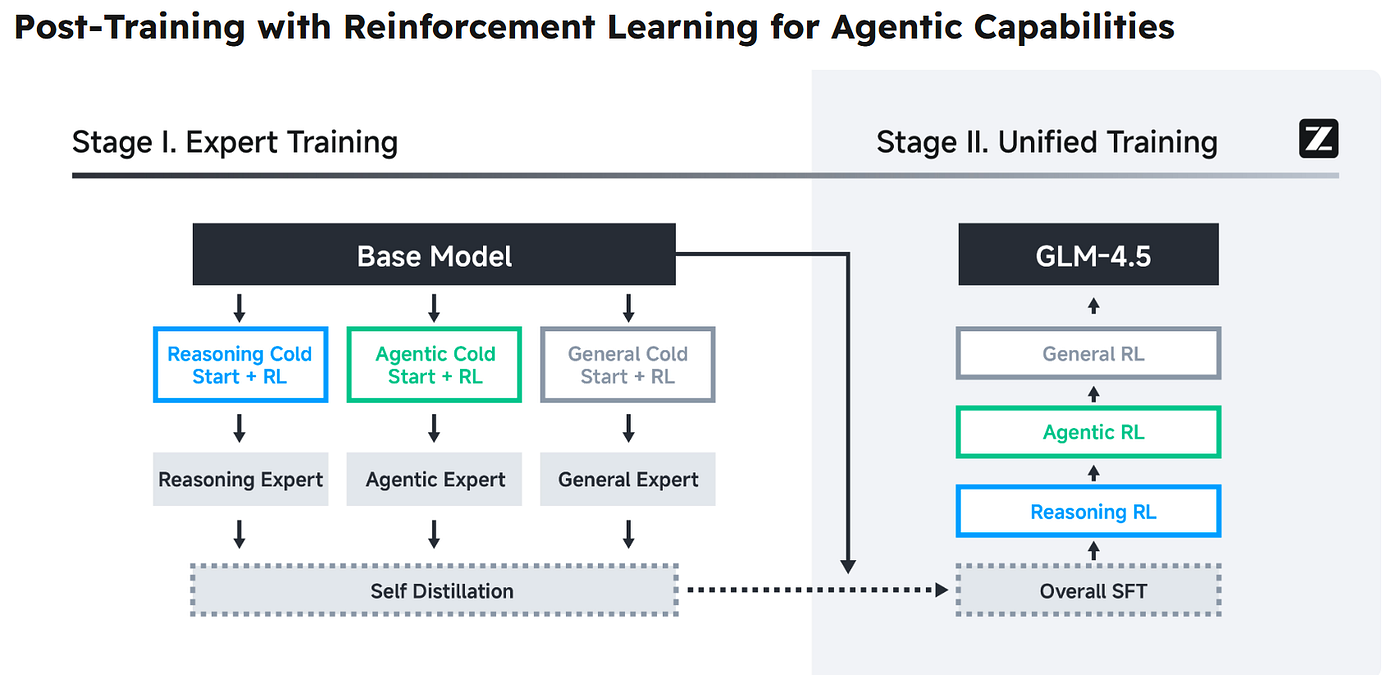
GLM-4.5架构图
架构设计的精妙平衡
GLM-4.5系列包含两个版本:旗舰版采用3550亿总参数/320亿活跃参数的配置,轻量版GLM-4.5-Air则为1060亿总参数/120亿活跃参数。这种“深度优先”的设计理念——通过增加层数而非单纯扩大宽度,使得模型在保持推理能力的同时,将训练成本控制在DeepSeek-R1的一半参数规模下。 混合专家系统(MoE)的数学本质可表示为:
其中是门控函数输出的权重,
表示第
个专家网络。GLM-4.5通过top-k稀疏激活策略,在355B总参数中仅激活32B活跃参数,实现了计算效率与模型性能的最优平衡。
技术细节上,模型采用了分组查询注意力机制(Grouped-Query Attention)与部分RoPE相结合的设计,配合96个注意力头的超常规配置。GQA的数学表达为:
其中查询头被分为组,每组共享相同的键值头。虽然实验表明增加注意力头数并未直接改善训练损失,但在MMLU和BBH等推理基准上却展现出明显的性能提升。Muon优化器的引入则使模型能够支持更大的批处理规模,加速训练收敛。
性能表现的实证分析
在多项权威基准测试中,GLM-4.5展现出优异的综合性能,特别是在推埋、编的和替能体能力万面表现突出。其工具调用能力经过严格测试,展现出较高的任务执行可靠性。 参数效率是评估大模型的关键指标,可通过公式量化:
GLM-4.5的设计理念注重参数的有效利用,避免了单纯追求参数规模带来的资源浪费。 在推理性能方面,GLM-4.5实测生成速度表现优异,推理速度公式表示为:
通过专家并行和张量并行的优化组合,模型实现了高效的推理性能。APl定价策略也体现了对开发者友好的考虑,为实际应用提供了经济可行的解决方案。
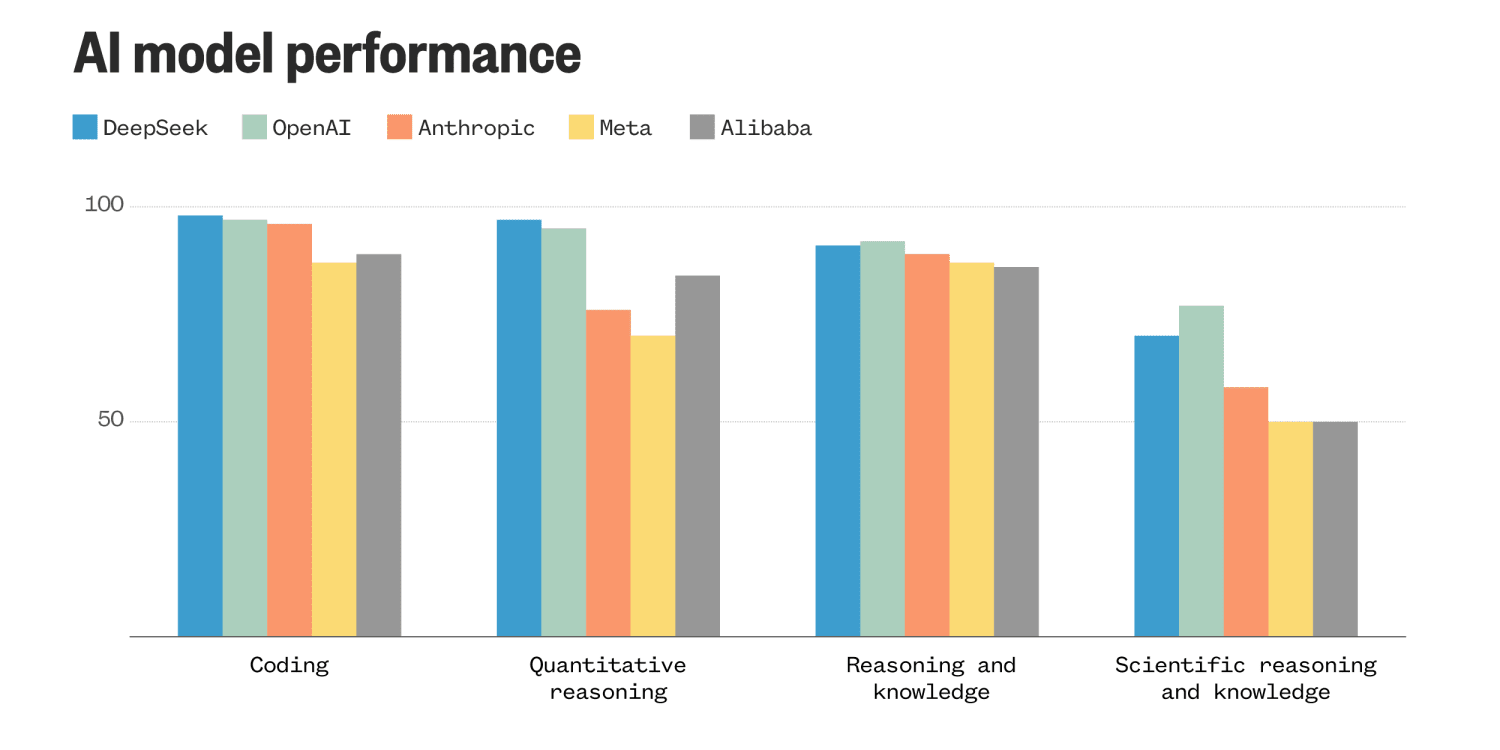
GLM-4.5性能对比图
开发场景的实战验证
在编码能力评估中,GLM-4.5展现出扎实的工程化能力。在多项编程任务测试中,模型能够准确理解开发需求并生成高质量代码,体现了其在软件开发领域的实用价值。
三个典型应用场景验证了其多任务处理能力:在网页开发中可快速生成全栈应用原型;通过自主搜索和内容整合自动创建演示文稿;还能构建包含物理模拟的交互式数字作品。这些案例展示了模型将自然语言指令转化为可执行工作流的能力,其背后是三阶段训练的数学框架支撑:通用预训练、领域专项训练和强化学习微调,使模型在保持通用能力的同时,提升了特定任务的表现。
GLM-4.5应用场景
开源生态的技术辐射
作为MIT协议开源的模型,GLM-4.5为开发者提供了完整的工具链支持,包括transformers、vLLM和SGLang等推理框架的适配。其开源的slime强化学习框架采用混合精度训练(FP8生成数据+BF16训练),通过解耦rollout引擎与训练引擎的设计,解决了智能体任务中数据生成瓶颈的问题。
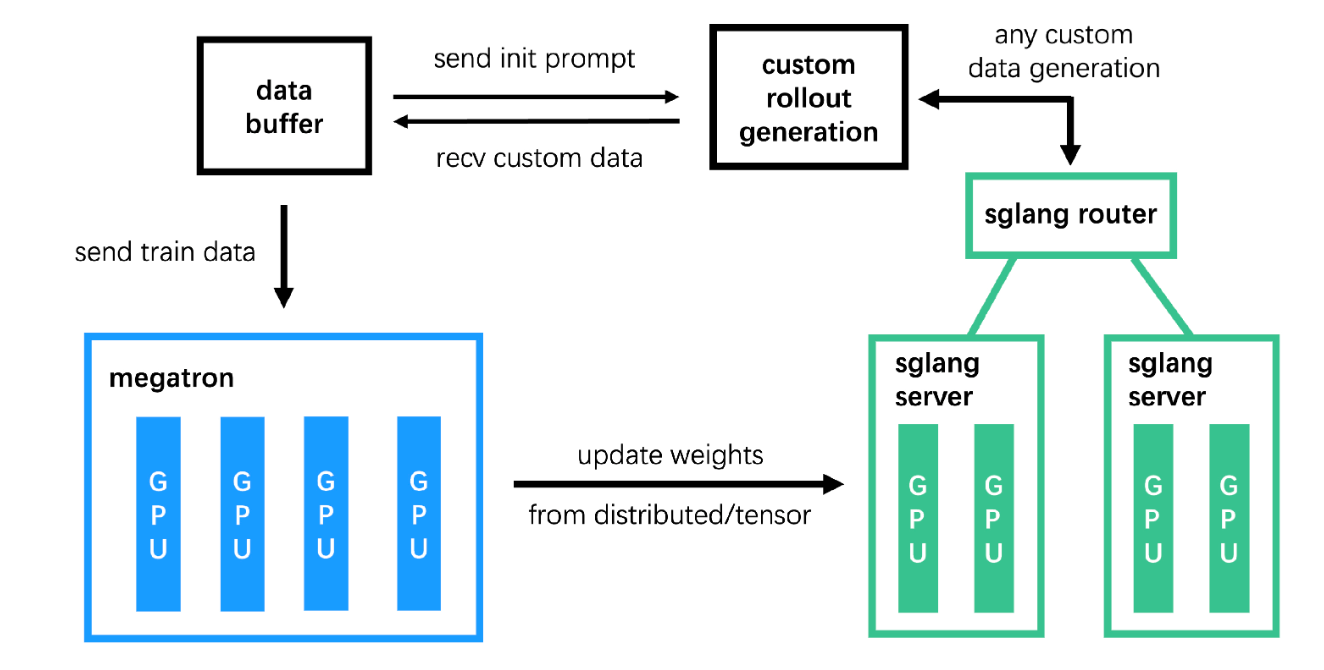
GLM-4.5训练架构
模型的三阶段训练流程——150万亿token的通用预训练、70万亿token的领域专项训练,以及强化学习微调,为社区提供了可复现的技术路径。这种开放策略不仅降低了企业部署门槛(仅需8块H20芯片即可运行),更推动了国产模型生态的协同进化。
GLM-4.5的发布标志着国产大模型在开源赛道上实现了技术突破,其设计理念强调实用性和效率,避免了单纯追求参数规模的误区。通过开源策略,智谱AI为全球AI开发者提供了高性能、高性价比的开源选择,有望推动大模型技术在更多实际场景中的落地应用。这一进展不仅展示了中国AI研究的实力,也为全球开源社区贡献了重要的技术成果。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)