基于Python+爬虫的影片电影数据可视化分析系统设计与实现
今天带来的是基于Python+爬虫的影片电影数据可视化分析系统设计与实现,线上影片电影数据可视化分析提供了良好的发展空间,随着人们生活质量的提高,人们对服务质量的要求越来越严格。人们希望拥有更好的影片电影数据可视化分析体验。而且,影片电影数据可视化分析服务有着使用常规电话交流比不了的便捷高效简单等优势。影片电影数据可视化分析就是为广大劳动人民提供这样一个方便的系统,以满足人们的需求。
💗博主介绍:✌全网粉丝10W+,CSDN全栈领域优质创作者,博客之星、掘金/华为云/阿里云等平台优质作者。
👇🏻 精彩专栏 推荐订阅👇🏻
计算机毕业设计精品项目案例-200套
🌟文末获取源码+数据库+文档🌟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以和学长沟通,希望帮助更多的人
一.前言

首先,利用爬虫技术可以轻松地从各个网站上获取影片电影相关的数据,而Python作为一种强大的编程语言,提供了丰富的库和工具用于数据处理,可以对这些数据进行清洗、筛选和转换,为后续的分析做好准备。其次,通过数据可视化,我们可以用图形化的方式直观地展示数据的规律和趋势。借助Echarts可以设计和绘制各种形式的图表、图像,更好地展示和解读分析结果。这有助于我们更好地理解影片电影市场的特点,比如热门类型、观众喜好、票房走势等,为制片方、影院、投资者等决策提供参考。此外,通过分析用户的历史评分、观影记录等数据,我们可以建立用户画像,从而进行个性化推荐,提高用户对影片电影资源的满意度,也为电影平台提供更有针对性的推广和营销活动。最后,基于Python和爬虫的影片电影数据可视化分析系统不仅在学术研究中具有重要的研究价值,还在商业应用领域有广泛的应用前景。它可以帮助制片方制定更科学的投资策略,帮助影院做出更合理的排片安排,还可以帮助广告商找到更精准的目标受众。综上所述,该系统为人们处理、分析和展示影片电影相关数据提供了有效的方法和工具,推动了相关行业的发展和创新。
二.技术环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
爬虫框架:Scrapy
大数据框架:Hadoop
开发软件:PyCharm/vs code
前端框架:vue.js
三.功能设计
本课题要求实现一套基于python的影片电影数据可视化分析,系统主要包括管理员和用户两大功能模块。
(1)管理员用例图如下所示: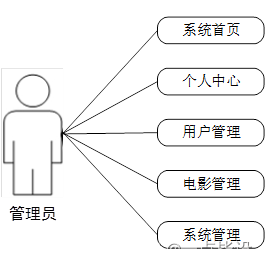
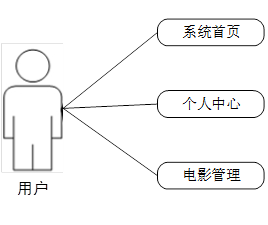
(2)用户用例图如下所示:
系统整体模块设计:系统分为管理员和用户两大角色,系统管理员有最大的权限,总体功能展示如图所示。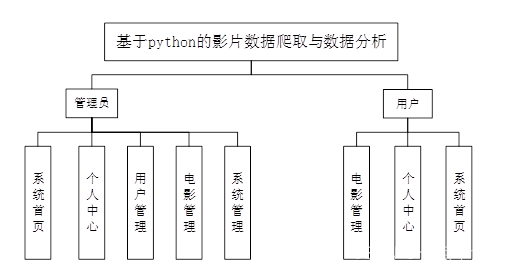
四.数据设计
概念模型的设计是为了抽象真实世界的信息,并对信息世界进行建模。它是数据库设计的强大工具。数据库概念模型设计可以通过E-R图描述现实世界的概念模型。系统的E-R图显示了系统中实体之间的链接。而且Mysql数据库是自我保护能力比较强的数据库,下图主要是对数据库实体的E-R图: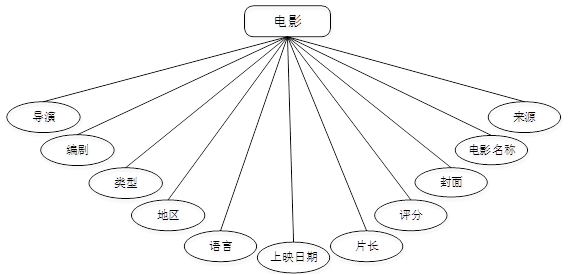
五.部分效果展示
管理员功能实现效果
系统登录,在登录页面选择需要登录的角色,在正确输入用户名和密码后,进入操作系统进行操作;系统登录界面如图所示: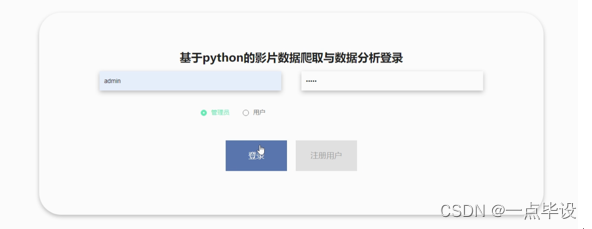
管理员进入主页面,主要功能包括对系统首页、个人中心、用户管理、电影管理、系统管理等进行操作。管理员主界面如图所示: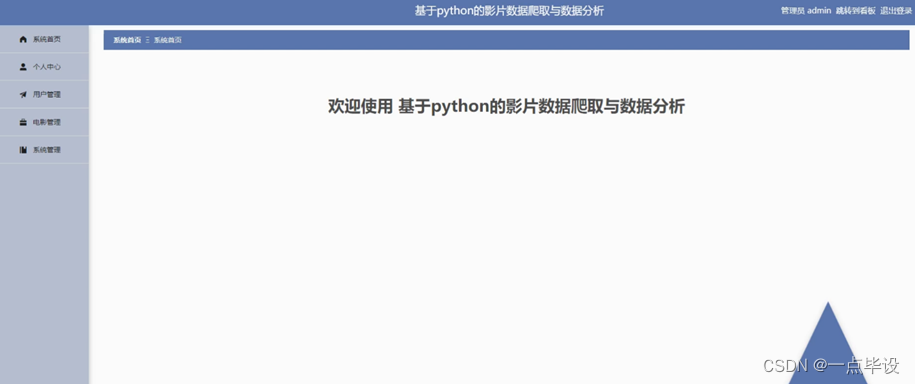
管理员点击用户管理。进入用户页面输入用户名可以查询,新增或删除用户列表,并根据需要对用户信息进行查看详情,修改或删除操作。如图所示: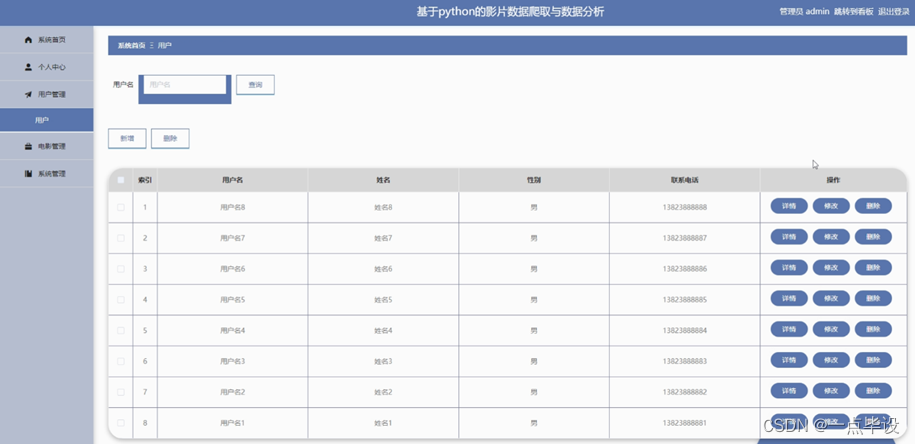
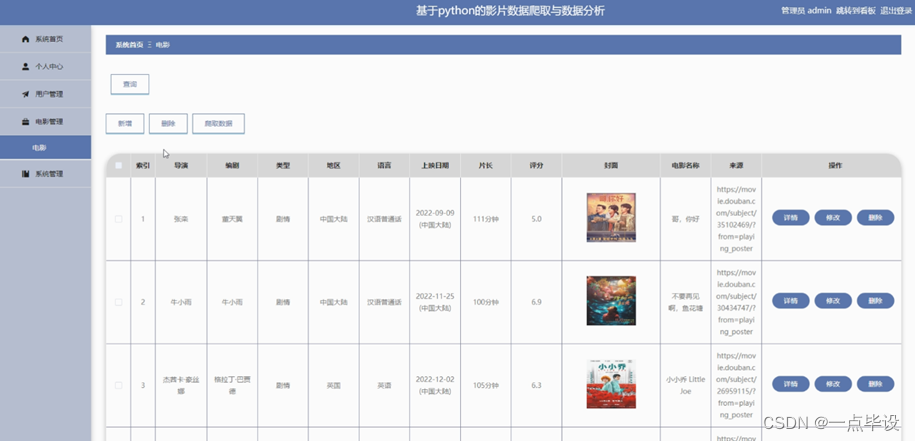
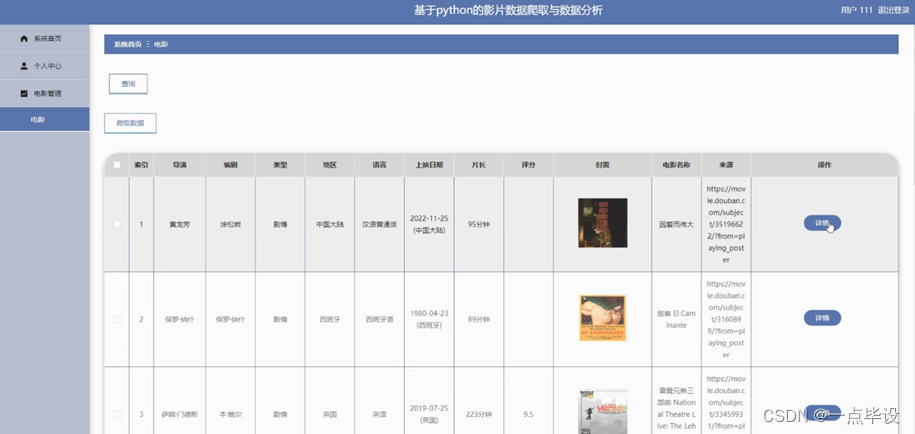
管理员点击电影管理。进入电影页面可以查询,新增,删除或爬取数据电影列表,并根据需要对电影信息进行查看详情,修改或删除操作。如图所示:
管理员点击系统管理。进入系统简介页面输入标题可以查询系统简介列表,并根据需要对系统简介信息进行查看详情或修改操作。如图所示: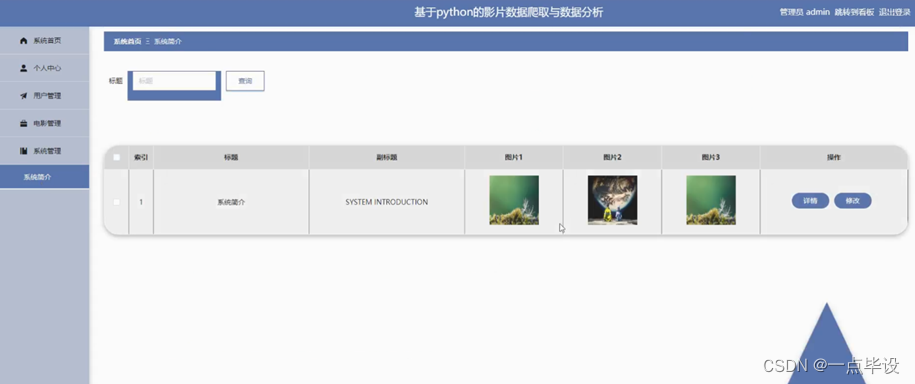
管理员点击跳转到看板。进入看板页面可以查看类型、评分、地区、语言、电影总数和导演等详细数据分析。如图所示: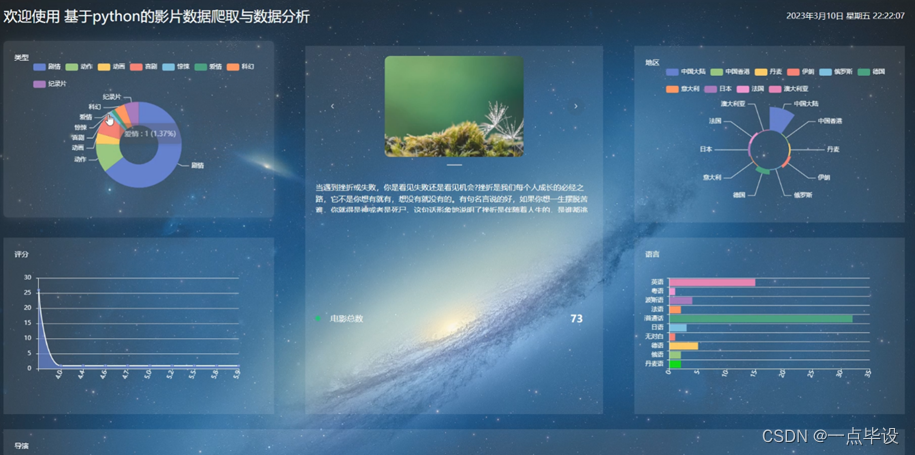
用户功能实现效果
用户进入主页面,主要功能包括对系统首页、个人中心、电影管理等进行操作。用户主界面如图所示: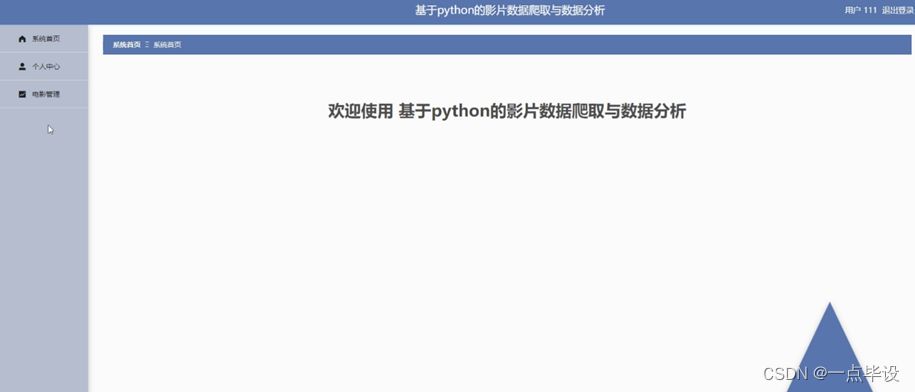
用户点击电影管理。进入电影页面可以查询或爬取数据电影列表,并根据需要对电影信息进行查看详情操作。如图所示:
六.部分功能代码
# 数据爬取文件
import scrapy
import pymysql
import pymssql
from ..items import MovieItem
import time
from datetime import datetime,timedelta
import re
import random
import platform
import json
import os
import urllib
from urllib.parse import urlparse
import requests
import emoji
# 电影
class MovieSpider(scrapy.Spider):
name = 'movieSpider'
spiderUrl = 'https://movie.douban.com/cinema/nowplaying/meizhou/'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if plat == 'windows_bak':
pass
elif plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'by8ev_movie') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('div#nowplaying ul.lists li.list-item, div#upcoming ul.lists li.list-item')
for item in list:
fields = MovieItem()
if '(.*?)' in '''li[class="poster"] a::attr(href)''':
try:
fields["laiyuan"] = re.findall(r'''li[class="poster"] a::attr(href)''', item.extract(), re.DOTALL)[0].strip()
except:
pass
else:
fields["laiyuan"] = self.remove_html(item.css('li[class="poster"] a::attr(href)').extract_first())
detailUrlRule = item.css('li[class="poster"] a::attr(href)').extract_first()
if self.protocol in detailUrlRule:
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
# fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse, dont_filter=True)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''div[id="info"] span:nth-child(1) span a::text''':
fields["daoyan"] = re.findall(r'''div[id="info"] span:nth-child(1) span a::text''', response.text, re.S)[0].strip()
else:
if 'daoyan' != 'xiangqing' and 'daoyan' != 'detail' and 'daoyan' != 'pinglun' and 'daoyan' != 'zuofa':
fields["daoyan"] = self.remove_html(response.css('''div[id="info"] span:nth-child(1) span a::text''').extract_first())
else:
fields["daoyan"] = emoji.demojize(response.css('''div[id="info"] span:nth-child(1) span a::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''div[id="info"] br~span span[class="attrs"] a::text''':
fields["bianju"] = re.findall(r'''div[id="info"] br~span span[class="attrs"] a::text''', response.text, re.S)[0].strip()
else:
if 'bianju' != 'xiangqing' and 'bianju' != 'detail' and 'bianju' != 'pinglun' and 'bianju' != 'zuofa':
fields["bianju"] = self.remove_html(response.css('''div[id="info"] br~span span[class="attrs"] a::text''').extract_first())
else:
fields["bianju"] = emoji.demojize(response.css('''div[id="info"] br~span span[class="attrs"] a::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''div[id="info"] span[class="actor"] span[class="attrs"] a::text''':
fields["zhuyan"] = re.findall(r'''div[id="info"] span[class="actor"] span[class="attrs"] a::text''', response.text, re.S)[0].strip()
else:
if 'zhuyan' != 'xiangqing' and 'zhuyan' != 'detail' and 'zhuyan' != 'pinglun' and 'zhuyan' != 'zuofa':
fields["zhuyan"] = self.remove_html(response.css('''div[id="info"] span[class="actor"] span[class="attrs"] a::text''').extract_first())
else:
fields["zhuyan"] = emoji.demojize(response.css('''div[id="info"] span[class="actor"] span[class="attrs"] a::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''div[id="info"] span[property="v:genre"]::text''':
fields["leixing"] = re.findall(r'''div[id="info"] span[property="v:genre"]::text''', response.text, re.S)[0].strip()
else:
if 'leixing' != 'xiangqing' and 'leixing' != 'detail' and 'leixing' != 'pinglun' and 'leixing' != 'zuofa':
fields["leixing"] = self.remove_html(response.css('''div[id="info"] span[property="v:genre"]::text''').extract_first())
else:
fields["leixing"] = emoji.demojize(response.css('''div[id="info"] span[property="v:genre"]::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''<span class="pl">制片国家/地区:</span>(.*?)<br/>''':
fields["diqu"] = re.findall(r'''<span class="pl">制片国家/地区:</span>(.*?)<br/>''', response.text, re.S)[0].strip()
else:
if 'diqu' != 'xiangqing' and 'diqu' != 'detail' and 'diqu' != 'pinglun' and 'diqu' != 'zuofa':
fields["diqu"] = self.remove_html(response.css('''<span class="pl">制片国家/地区:</span>(.*?)<br/>''').extract_first())
else:
fields["diqu"] = emoji.demojize(response.css('''<span class="pl">制片国家/地区:</span>(.*?)<br/>''').extract_first())
except:
pass
try:
if '(.*?)' in '''<span class="pl">语言:</span>(.*?)[/].*?<br/>.*?<span class="pl">上映日期:</span>''':
fields["yuyan"] = re.findall(r'''<span class="pl">语言:</span>(.*?)[/].*?<br/>.*?<span class="pl">上映日期:</span>''', response.text, re.S)[0].strip()
else:
if 'yuyan' != 'xiangqing' and 'yuyan' != 'detail' and 'yuyan' != 'pinglun' and 'yuyan' != 'zuofa':
fields["yuyan"] = self.remove_html(response.css('''<span class="pl">语言:</span>(.*?)[/].*?<br/>.*?<span class="pl">上映日期:</span>''').extract_first())
else:
fields["yuyan"] = emoji.demojize(response.css('''<span class="pl">语言:</span>(.*?)[/].*?<br/>.*?<span class="pl">上映日期:</span>''').extract_first())
except:
pass
try:
if '(.*?)' in '''span[property="v:initialReleaseDate"]::text''':
fields["shangyingriqi"] = re.findall(r'''span[property="v:initialReleaseDate"]::text''', response.text, re.S)[0].strip()
else:
if 'shangyingriqi' != 'xiangqing' and 'shangyingriqi' != 'detail' and 'shangyingriqi' != 'pinglun' and 'shangyingriqi' != 'zuofa':
fields["shangyingriqi"] = self.remove_html(response.css('''span[property="v:initialReleaseDate"]::text''').extract_first())
else:
fields["shangyingriqi"] = emoji.demojize(response.css('''span[property="v:initialReleaseDate"]::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''span[property="v:runtime"]::text''':
fields["pianchang"] = re.findall(r'''span[property="v:runtime"]::text''', response.text, re.S)[0].strip()
else:
if 'pianchang' != 'xiangqing' and 'pianchang' != 'detail' and 'pianchang' != 'pinglun' and 'pianchang' != 'zuofa':
fields["pianchang"] = self.remove_html(response.css('''span[property="v:runtime"]::text''').extract_first())
else:
fields["pianchang"] = emoji.demojize(response.css('''span[property="v:runtime"]::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''strong[class="ll rating_num"]::text''':
fields["pingfen"] = re.findall(r'''strong[class="ll rating_num"]::text''', response.text, re.S)[0].strip()
else:
if 'pingfen' != 'xiangqing' and 'pingfen' != 'detail' and 'pingfen' != 'pinglun' and 'pingfen' != 'zuofa':
fields["pingfen"] = self.remove_html(response.css('''strong[class="ll rating_num"]::text''').extract_first())
else:
fields["pingfen"] = emoji.demojize(response.css('''strong[class="ll rating_num"]::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''span[property="v:summary"]''':
fields["xiangqing"] = re.findall(r'''span[property="v:summary"]''', response.text, re.S)[0].strip()
else:
if 'xiangqing' != 'xiangqing' and 'xiangqing' != 'detail' and 'xiangqing' != 'pinglun' and 'xiangqing' != 'zuofa':
fields["xiangqing"] = self.remove_html(response.css('''span[property="v:summary"]''').extract_first())
else:
fields["xiangqing"] = emoji.demojize(response.css('''span[property="v:summary"]''').extract_first())
except:
pass
try:
if '(.*?)' in '''div[id="mainpic"] a img::attr(src)''':
fields["fengmian"] = re.findall(r'''div[id="mainpic"] a img::attr(src)''', response.text, re.S)[0].strip()
else:
if 'fengmian' != 'xiangqing' and 'fengmian' != 'detail' and 'fengmian' != 'pinglun' and 'fengmian' != 'zuofa':
fields["fengmian"] = self.remove_html(response.css('''div[id="mainpic"] a img::attr(src)''').extract_first())
else:
fields["fengmian"] = emoji.demojize(response.css('''div[id="mainpic"] a img::attr(src)''').extract_first())
except:
pass
try:
if '(.*?)' in '''span[property="v:itemreviewed"]::text''':
fields["mingcheng"] = re.findall(r'''span[property="v:itemreviewed"]::text''', response.text, re.S)[0].strip()
else:
if 'mingcheng' != 'xiangqing' and 'mingcheng' != 'detail' and 'mingcheng' != 'pinglun' and 'mingcheng' != 'zuofa':
fields["mingcheng"] = self.remove_html(response.css('''span[property="v:itemreviewed"]::text''').extract_first())
else:
fields["mingcheng"] = emoji.demojize(response.css('''span[property="v:itemreviewed"]::text''').extract_first())
except:
pass
return fields
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `movie`(
id
,daoyan
,bianju
,zhuyan
,leixing
,diqu
,yuyan
,shangyingriqi
,pianchang
,pingfen
,xiangqing
,fengmian
,mingcheng
,laiyuan
)
select
id
,daoyan
,bianju
,zhuyan
,leixing
,diqu
,yuyan
,shangyingriqi
,pianchang
,pingfen
,xiangqing
,fengmian
,mingcheng
,laiyuan
from `by8ev_movie`
where(not exists (select
id
,daoyan
,bianju
,zhuyan
,leixing
,diqu
,yuyan
,shangyingriqi
,pianchang
,pingfen
,xiangqing
,fengmian
,mingcheng
,laiyuan
from `movie` where
`movie`.id=`by8ev_movie`.id
))
limit {0}
'''.format(random.randint(10,15))
cursor.execute(sql)
connect.commit()
connect.close()
最后
💕💕
最新计算机毕业设计选题篇-选题推荐
小程序毕业设计精品项目案例-200套
Java毕业设计精品项目案例-200套
Python毕业设计精品项目案例-200套
大数据毕业设计精品项目案例-200套
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 20
20 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)