PCA算法人脸识别
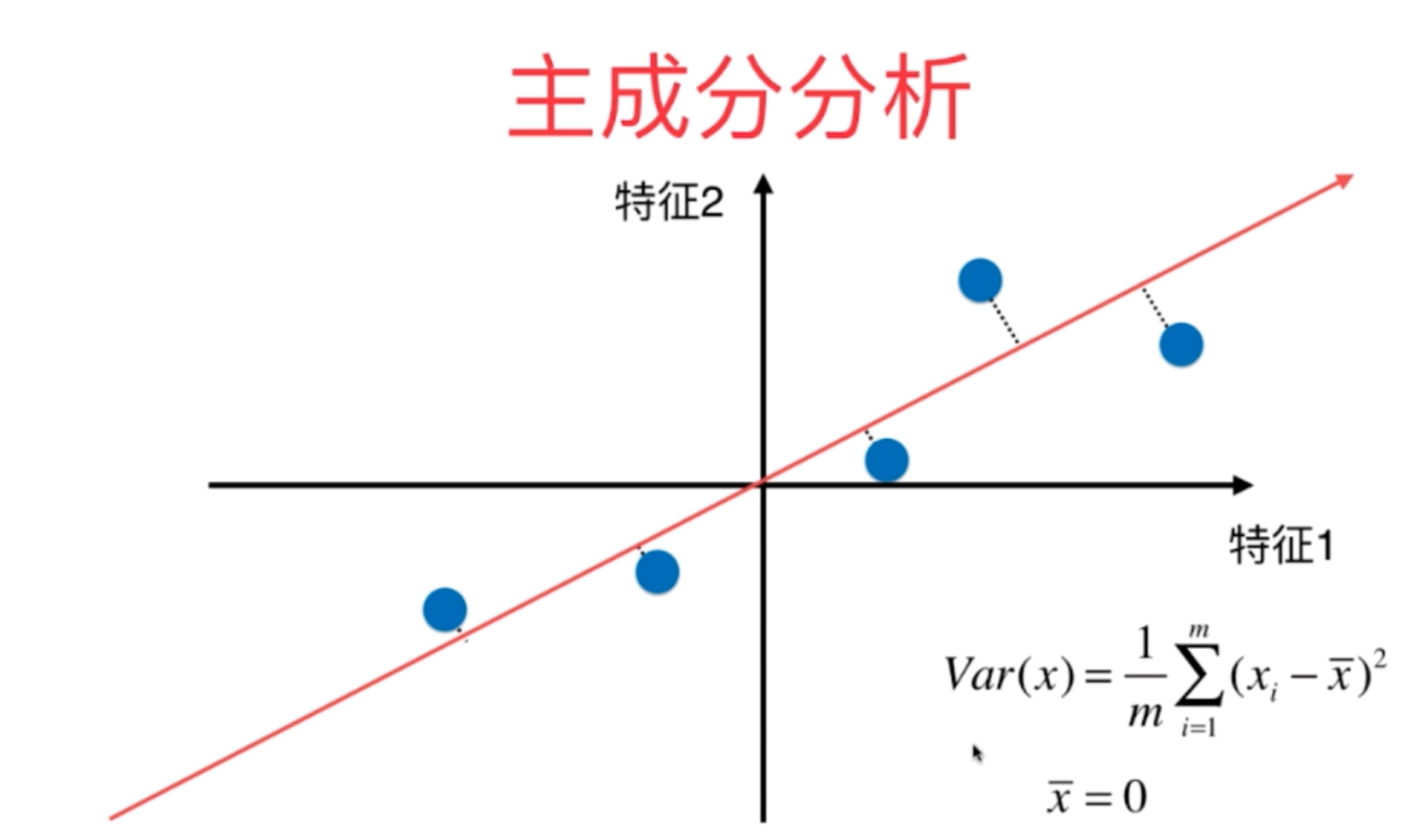
其核心目标是通过线性变换将高维数据映射到低维空间,同时尽可能保留原始数据的关键信息(方差),从而简化数据结构、降低计算复杂度,并揭示数据的潜在结构。方差指的是数据映射到新坐标轴上的数据分布方差,方差越大,映射即降维后的数据,保存的原始数据信息最大。主成分选择:按特征值排序,保留前n_components个。特征脸:协方差矩阵的特征向量重塑回图像形状(112×92)(4)特征脸可视化(显示前 10
一、PCA 的基本概念
主成分分析(Principal Component Analysis,PCA)是一种常用的无监督学习降维技术,其核心目标是通过线性变换将高维数据映射到低维空间,同时尽可能保留原始数据的关键信息(方差),从而简化数据结构、降低计算复杂度,并揭示数据的潜在结构。
二、PCA 的核心思想
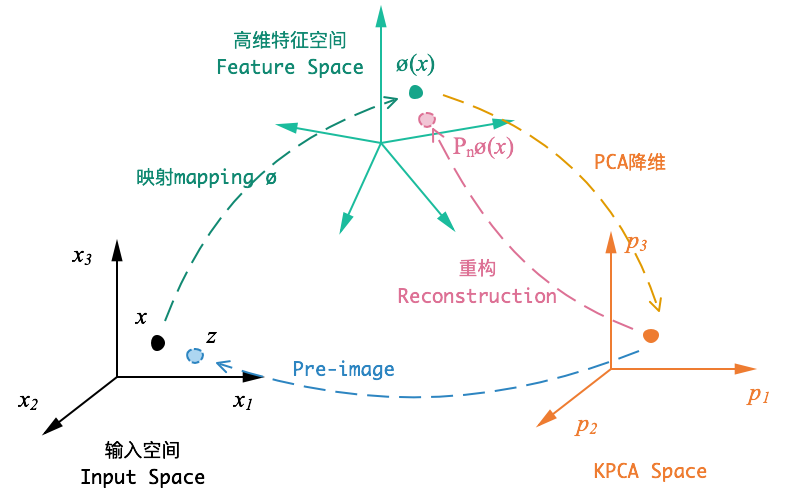
1.方差最大化
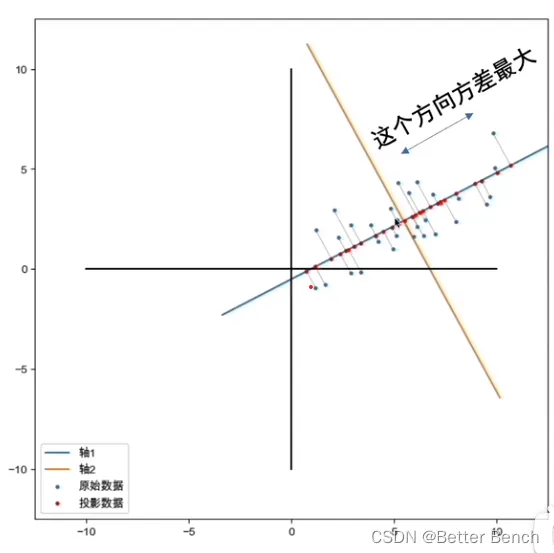
- 原始数据在高维空间中可能存在冗余或相关性(例如多个特征高度相关)。PCA 通过寻找一组新的正交坐标轴(主成分),使得数据在这些轴上的投影方差最大。
- 主成分是原始特征的线性组合,第一个主成分对应数据方差最大的方向,第二个主成分与第一个正交且方差次大,依此类推。
2.降维本质
- 选择前 k 个主成分(k < 原始维度),将数据从 n 维降至 k 维,使得降维后的数据尽可能接近原始数据的分布。
三、PCA 的主要步骤
- 数据预处理:对原始数据进行标准化(缩放特征至相同尺度,避免量纲影响)。
- 计算协方差矩阵:协方差矩阵用于衡量特征之间的相关性,对角线元素为各特征的方差,非对角线元素为特征间的协方差。
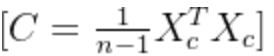
方差指的是数据映射到新坐标轴上的数据分布方差,方差越大,映射即降维后的数据,保存的原始数据信息最大
- 求解特征值与特征向量:对协方差矩阵进行特征分解,得到特征值(衡量对应主成分的方差大小)和特征向量(主成分的方向)。
- 选择主成分:按特征值从大到小排序,选择前 k 个特征值对应的特征向量,组成变换矩阵。
- 数据映射:将原始数据投影到选定的主成分上,得到降维后的数据。
四.具体应用
1.通过PCA算法实现人脸识别,代码实现
import os
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
def load_orl_faces(data_path='./ORL_Faces'):
"""加载ORL人脸数据库"""
X, y = [], []
for person_id in range(1, 41):
person_dir = os.path.join(data_path, f's{person_id}')
for img_id in range(1, 11):
img_path = os.path.join(person_dir, f'{img_id}.pgm')
if os.path.exists(img_path):
img = Image.open(img_path).convert('L')
img = img.resize((92, 112))
X.append(np.array(img).flatten())
y.append(person_id)
return np.array(X), np.array(y)
def train_test_split(X, y, test_size=0.5, random_state=42):
"""自定义训练集测试集划分"""
np.random.seed(random_state)
indices = np.random.permutation(len(X))
test_size = int(len(X) * test_size)
return X[indices[test_size:]], X[indices[:test_size]], y[indices[test_size:]], y[indices[:test_size]]
class PCA:
"""自定义PCA实现"""
def __init__(self, n_components):
self.n_components = n_components
def fit(self, X):
self.mean_ = np.mean(X, axis=0)
X_centered = X - self.mean_
if X.shape[0] < X.shape[1]:
cov = np.dot(X_centered, X_centered.T) / (X.shape[0] - 1)
eigenvalues, eigenvectors = np.linalg.eigh(cov)
idx = np.argsort(eigenvalues)[::-1]
eigenvalues, eigenvectors = eigenvalues[idx], eigenvectors[:, idx]
eigenvectors = np.dot(X_centered.T, eigenvectors)
for i in range(eigenvectors.shape[1]):
eigenvectors[:, i] /= np.linalg.norm(eigenvectors[:, i])
else:
cov = np.dot(X_centered.T, X_centered) / (X.shape[0] - 1)
eigenvalues, eigenvectors = np.linalg.eigh(cov)
idx = np.argsort(eigenvalues)[::-1]
eigenvalues, eigenvectors = eigenvalues[idx], eigenvectors[:, idx]
self.components_ = eigenvectors[:, :self.n_components].T
self.explained_variance_ = eigenvalues[:self.n_components]
return self
def transform(self, X):
return np.dot(X - self.mean_, self.components_.T)
class KNNClassifier:
"""自定义KNN分类器"""
def __init__(self, n_neighbors=1):
self.n_neighbors = n_neighbors
def fit(self, X, y):
self.X_train = X
self.y_train = y
return self
def predict(self, X):
y_pred = np.zeros(len(X), dtype=self.y_train.dtype)
for i, x in enumerate(X):
distances = np.sqrt(np.sum((self.X_train - x) ** 2, axis=1))
nearest_indices = np.argsort(distances)[:self.n_neighbors]
nearest_classes = self.y_train[nearest_indices]
y_pred[i] = np.bincount(nearest_classes).argmax()
return y_pred
def visualize_eigenfaces(eigenfaces, n=10):
"""可视化特征脸"""
fig, axes = plt.subplots(1, n, figsize=(20, 3))
for i in range(n):
axes[i].imshow(eigenfaces[i].reshape(112, 92), cmap='gray')
axes[i].set_title(f'特征脸 {i+1}')
axes[i].axis('off')
plt.tight_layout()
plt.show()
def visualize_recognition_results(X_test, y_test, y_pred, n=9):
"""可视化人脸识别结果"""
fig, axes = plt.subplots(3, 3, figsize=(12, 10))
for i, ax in enumerate(axes.flat):
if i < len(X_test):
ax.imshow(X_test[i].reshape(112, 92), cmap='gray')
ax.set_title(f'真实: {y_test[i]}, 预测: {y_pred[i]}', fontsize=10)
ax.axis('off')
plt.tight_layout()
plt.show()
def main():
# 加载数据
print("加载人脸数据...")
X, y = load_orl_faces()
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
# PCA降维
print("执行PCA降维...")
pca = PCA(n_components=100) # 可调整主成分数量
X_train_pca = pca.fit(X_train).transform(X_train)
X_test_pca = pca.transform(X_test)
# 可视化特征脸
print("可视化特征脸...")
visualize_eigenfaces(pca.components_)
# 训练KNN分类器
print("训练人脸识别模型...")
knn = KNNClassifier(n_neighbors=1)
knn.fit(X_train_pca, y_train)
y_pred = knn.predict(X_test_pca)
# 计算准确率
accuracy = np.mean(y_pred == y_test)
print(f"人脸识别准确率: {accuracy:.4f}")
# 可视化识别结果
print("可视化识别结果...")
visualize_recognition_results(X_test, y_test, y_pred)
if __name__ == "__main__":
main() (1)加载 ORL 人脸数据集:
(2)自定义 PCA 实现特征脸提取:
核心步骤:
数据中心化:减去平均脸
协方差矩阵计算:X^T·X
特征分解:获取特征值和特征向量
主成分选择:按特征值排序,保留前n_components个
特征脸:协方差矩阵的特征向量重塑回图像形状(112×92)
(3)KNN 分类器进行人脸识别
(4)特征脸可视化(显示前 10 个特征脸)
(5)人脸识别结果可视化(9 个样本)
2.显示结果
特征脸
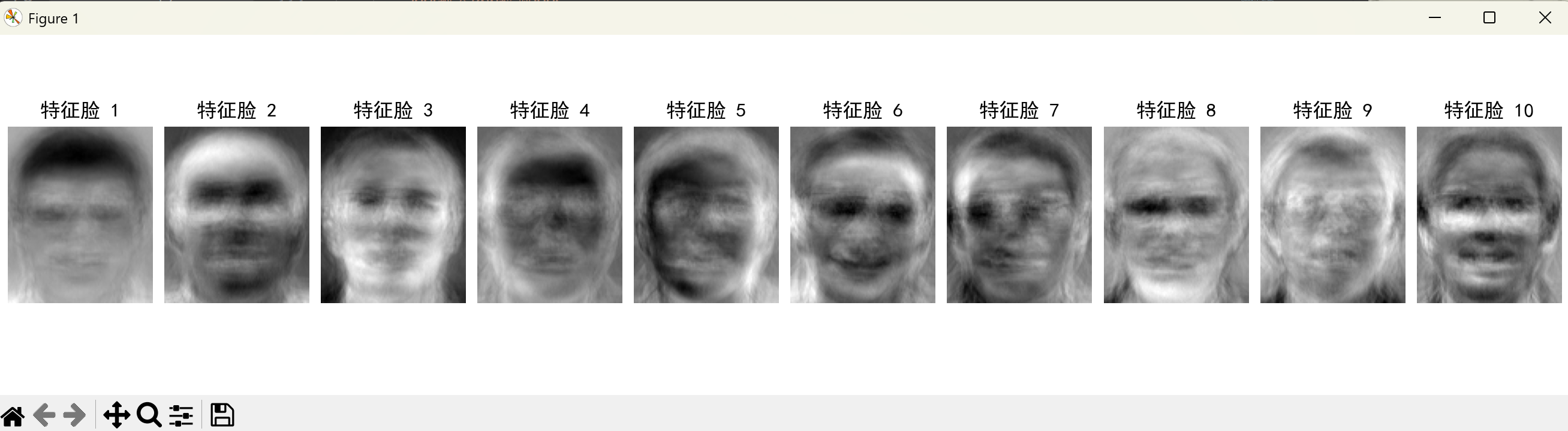
人脸识别可视化展示

3.PCA算法优缺点
| 优点 | 缺点 |
|---|---|
| 1. 无监督学习,无需标签数据 2. 计算效率高,适用于大规模数据 3. 可解释性较强(主成分的方差含义明确) |
1. 可能损失有意义的细节(尤其当数据非线性相关时) 2. 主成分的物理含义可能不明确(依赖原始特征的线性组合) 3. 对异常值敏感(标准化后仍可能受影响) |

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)