MosaicDoc:面向视觉丰富文档理解的大规模双语基准数据集深度解析
MosaicDoc数据集和DocWeaver流水线,解决了文档理解领域的关键挑战。针对现有数据集布局简单、语言单一、阅读顺序标注缺失等问题,MosaicDoc提供72,000+图像和620,000+双语问答对,专门针对报纸杂志等复杂布局文档。DocWeaver创新性地采用多智能体协作流水线,实现文档分解、复杂阅读顺序建模和高保真QA生成。核心技术包括HTML对齐方法、语义序列与布局层次混合策略,以
一、论文概述
在文档AI领域,当前的主流趋势是将多种任务统一到端到端的模型中,其中文档视觉问答(DocVQA)已成为关键范式。然而,现有基准数据集存在显著局限:主要以英语为中心、布局过于简单、任务支持有限,这些问题严重制约了视觉丰富文档理解(Visually Rich Document Understanding, VRDU)能力的评估。
华南理工大学的研究团队在2025年提出了MosaicDoc基准数据集及其构建流水线DocWeaver。该工作针对报纸和杂志这类真实世界中布局复杂、信息密集的文档,提供了首个综合性的双语(中英文)评估资源。数据集包含72,000+图像和620,000+问答对,支持多项任务包括DocVQA、OCR、阅读顺序预测和内容定位。
二、核心问题与挑战
2.1 现有数据集的不足
当前文档理解领域面临三大核心挑战:
布局复杂性缺失:现有数据集如VisualMRC、Docmatix等主要基于视觉简单的文档,缺乏多栏布局、非曼哈顿布局等真实世界复杂场景。例如,XFUND中文数据集虽然支持多语言,但其布局复杂度基本复制了英文数据集的简单结构。
语言覆盖不足:绝大多数高质量数据集以英语为主。中文数据集如DuReadervis虽然使用长网页内容,但实际上只利用了视觉简单的顶部区域,忽略了更丰富的内容。
阅读顺序标注缺失:几乎所有现有数据集都缺少准确的阅读顺序标注,迫使模型依赖从上到下、从左到右的简单假设。这种假设在多栏或非标准布局中会导致性能显著下降。
2.2 视觉丰富文档的独特挑战
报纸和杂志等视觉丰富文档具有以下特征,给文档理解带来独特挑战:
- 信息密度高:相比简单文档,报纸页面的平均token数可达3,500+(MosaicDoc英文报纸子集),而MP-DocVQA仅490左右
- 布局非线性:多个独立文章、多栏排版、图文混排使得阅读路径不唯一
- 跨页关联:文章可能跨越多个页面,需要理解长距离依赖关系
- 多模态融合:文字、表格、图表、图片等多种元素交织
三、DocWeaver多智能体流水线
DocWeaver是一个创新的多智能体协作流水线,由大语言模型驱动,实现高保真、多任务文档标注的全自动生成。整个流水线分为三个阶段:
3.1 文档分解与结构化
3.1.1 数据预处理
流水线使用PyMuPDF和pdfminer.six解析数字PDF,提取原始文本和边界框。预处理阶段会剔除语义无关元素(注释、超链接、下划线、高亮等),并使用chardet处理编码错误,确保文本恢复。
每页被渲染为两种分辨率的图像:
- 高分辨率图像用于精确的布局分析
- 随机DPI图像模拟真实世界的渲染变化,增加数据集多样性
3.1.2 单元分割
这一步骤采用多个专门化智能体协同工作:
布局检测智能体:使用在M6Doc杂志数据集上微调的PP-DocLayout模型,识别13种布局元素类型(标题、段落、副标题等)。微调后精度从初始的0.583提升至0.871。
多引擎OCR智能体:为弥补PDF解析器可能遗漏的文本,对每个布局元素使用三个OCR引擎(PaddleOCR、pytesseract、EasyOCR)进行识别。最终文本通过加权投票方案确定:
ŝ = argmax_{t∈T} Σ(i=1 to N) w_i * p_i * 1[s_i = t]
其中T为所有候选字符串集合,w_i为引擎可靠性权重,p_i为置信度分数。
表格结构智能体:使用TableStructureRec工具箱将检测到的表格转换为结构化HTML格式。
**Unstructured**会将文档中的表格识别为Table对象,包含单元格内容和坐标信息,可通过其 API 转换为 HTML。①对数字化 PDF(可复制文本的表格)支持较好,能保留基本行列结构;集成简单,无需额外训练模型。但复杂表格和图像表格的处理能力较弱。②扫描件 PDF(图像格式):Unstructured 需依赖 OCR(如unstructured-inference调用 Tesseract),此时表格结构识别容易出错。
**<font style="color:#DF2A3F;">TableStructureRec</font>**:适合高精度表格结构识别(尤其是复杂或图像表格),直接支持 HTML 转换,专注于表格结构提取。
阅读顺序智能体:基于MinerU预测标准布局文档的初始阅读顺序。
跨页链接智能体:利用DeepSeek计算相邻页面的语义相似度,当相似度超过0.8时自动合并页面(最多四页),形成单一逻辑文档。
3.2 复杂阅读顺序建模
这是DocWeaver的核心创新之一。研究者认识到视觉丰富文档通常不存在单一的线性阅读路径,因此不强制建立全局阅读顺序,而是侧重于在行和段落层面建立可靠的局部顺序。针对不同文档类型,设计了三种专门化策略:
3.2.1 中文报纸策略:HTML对齐方法
许多中文报纸的官方网站提供结构化HTML版本,包含文章级元数据(标题、副标题、作者、图注及精确的布局边界框)。该策略的核心思想是将PDF图像提取的文本与HTML内容对齐。
对齐算法(Algorithm 1)采用基于上下文的编辑距离匹配:
- 模板构建:从爬取的HTML构建文本池(BuildPool)
- 文本清洗:清理行级和块级文本,去除前缀(PrepareTexts)
- 候选筛选:基于文本相似度、空间邻近性和上下文连贯性筛选候选项(FindCandidates)
- 上下文匹配:若候选项多于一个,利用前后PDF块文本计算上下文相似度:
s(c) = max(Sim(p+c.t, t_b^c), Sim(c.t+n, t_b^c))
其中p和n分别为前驱和后继文本
- 阈值判断:相似度超过0.3则匹配成功,否则归入未匹配类别
HTML源代码中的文本元素序列作为行级和段落级阅读顺序的真值。由于不同出版商HTML结构差异显著,研究者实现了针对各出版商的专用爬取流水线,并微调边界框回归模型以准确映射。
3.2.2 双语杂志策略:语义序列与布局层次混合
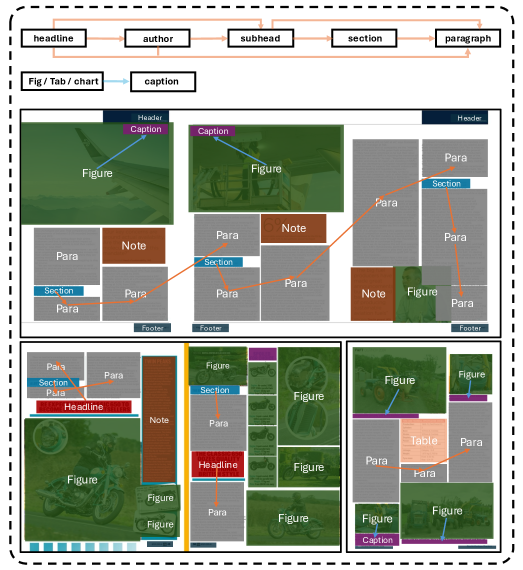
杂志采用类似HTML的策略,但增加了布局层次约束。该方法结合两个信号:
语义序列:文本在HTML源代码中的自然出现顺序
布局层次:预定义的优先级规则,管理不同布局元素类型之间的关系。例如:
- 标题必须位于段落之前
- 图注必须位于图形之后
- 作者信息位于副标题之后
这些层次约束通过有向图表示,箭头表示有效的顺序关系。这种混合方法使得模型能够在复杂的非曼哈顿布局中可靠地建模阅读顺序。
3.2.3 英文报纸策略:视觉中心流水线

英文报纸通常缺乏公开的结构化元数据,且布局更加密集多样。研究者开发了更鲁棒的视觉中心流水线:
文章分割:
- 应用二值化和形态学操作(膨胀、腐蚀)检测分隔线
- 基于规则的过滤与合并确定每个逻辑文章边界
- 将页面划分为矩形内容块
块内顺序推断:结合多种PDF元数据线索:
- 文本行空间坐标(从上到下、从左到右)
- 字体属性(样式和大小)
- PDF结构中嵌入的内在文本序列
这种多线索方法即使在缺乏外部结构化数据的情况下也能确保可靠的阅读顺序推断。
3.3 高保真QA生成
3.3.1 提示构建
研究者为文本、表格和图表开发了专门的提示模板,每个模板包含五个关键组件:
- 任务说明:细粒度的任务指令
- 内容摘要:输入内容的总结
- 输入数据:原始数据及相关布局信息
- 输出格式:指定的JSON输出格式
- 上下文示例:8个示例(4个来自数据集、4个人工设计)
文本QA模板要求生成:
- 单跳/多跳QA:基于文章摘要和多段文本,优先生成多跳QA
- 问题类型多样化:直接询问、确认、解释请求、假设性问题等
- 上下文忠实原文,答案为精确摘录(单段或多段)
表格QA模板(参考TVG实现)要求生成:
- 特定提取题:针对特定单元格
- 简单推理题:基于少于3个单元格
- 复杂推理题:需要3个以上单元格
- 数值计算题:涉及求和、平均、最大最小值等
- 需适配表格语言,明确行列位置,提供计算过程
图表QA模板要求:
- 特定值提取题
- 简单比较题
- 趋势分析题
- 数值计算题
- 结合图表图像和文本内容,提供计算过程
3.3.2 问题生成流程
主生成器采用GPT-4o和DeepSeek-R1,遵循结构化的多步骤工作流:
- 内容总结:生成输入内容摘要以识别关键信息
- 问题制定:基于摘要生成问题
- 答案定位:明确指示在原始内容中定位答案支撑上下文,避免依赖先验知识
- 精确提取:直接提取答案,避免改写
- 位置匹配:将最终答案及其证据匹配回文档图像中的精确位置
推理增强机制:引入QWQ-32B作为辅助判别器,评估检索到的上下文是否支持跨句推理。如果支持,则将上下文和提示返回给生成器,明确指示制定包含详细推理链和支撑证据的多跨度问题。
这种生成器-判别器协作确保了问题的多样性和复杂性。
3.4 自动化质量保障
3.4.1 幻觉防护机制
受G-EVAL框架启发,研究者实现了五维度评分系统,使用QWQ-32B作为LLM评估器。每个生成的QA对从1到5评分,仅保留所有维度评分大于3的QA对。
五个评估维度:
| 维度 | 评分标准(1-5分) | 评估步骤 |
|---|---|---|
| 完整性 | 答案是否包含所有关键信息,无遗漏。单跨度答案必须自包含完整回答,多跨度答案的组合必须必要且充分 | 1. 识别问题的所有显式和隐式部分 2. 对比答案与问题要求 3. 评分 |
| 一致性 | 答案是否与源文档事实一致,无错误、遗漏、冗余或模糊信息。答案必须在源文档和上下文中出现 | 1. 对比答案与文档 2. 检查不准确或无支撑声明 3. 评分 |
| 简洁性 | 答案是否简洁但完整,无冗余信息。不应重复问题内容,但简洁不能牺牲清晰度 | 1. 审查问题和答案 2. 评估是否以最简洁方式呈现 3. 评分 |
| 清晰度 | 答案中的代词和指代词是否明确且在上下文中有清晰的先行词,无模糊指代(如"今年"“这里”) | 1. 识别答案中的指代词 2. 验证每个指代词在答案中有清晰先行词 3. 基于模糊程度评分 |
| 推理有效性 | 计算或逻辑推理过程是否准确。推理必须仅使用上下文中的准确数据,思维链必须清晰完整,所有计算和推理必须正确 | 1. 验证所有证据来自上下文 2. 检查逻辑缺陷、计算错误或无效推理 3. 确认最终答案正确简洁 4. 评分 |
3.4.2 几何一致性过滤
对于报纸子集的阅读顺序标注,应用基于规则的过滤策略来移除错误或不合理的行间连接。
定义指示器I_ij判断从框i到框j的连接是否无效:
I_ij = {
√((x_j-x_i)² + (y_j-y_i)²) > T₁ 且
arccos(|x_j-x_i| / √((x_j-x_i)² + (y_j-y_i)²)) < θ₁
}
其中T₁为长度阈值(设为页面宽度),θ₁为方向阈值(设为45°)。如果文档包含超过5个这样的无效连接,则该文档及其阅读顺序标注被丢弃。
这一步骤确保只有几何结构合理的文档保留在最终数据集中。
四、MosaicDoc数据集
4.1 数据来源与规模
MosaicDoc展现了高度的来源多样性,材料来自196个不同的出版机构,覆盖24个领域(科学、金融、文化、艺术等)。数据主要从以下渠道收集:
中文报纸子集:
- 来源:官方网站
- 包括:人民日报、经济日报、检察日报、中国教育报、中国文化报、新华日报、羊城晚报
- 特点:权威性高,布局规范
英文报纸子集:
- 主要出版物:华尔街日报、今日美国、华盛顿邮报、洛杉矶时报
- 特点:密集布局,多栏排版复杂
中文杂志子集:
- 52种知名期刊:航空世界、中国国家旅游、NBA特刊、环球银幕等
- 特点:非曼哈顿布局,视觉元素丰富
英文杂志子集:
- 包括:新科学家、纽约客、哈佛商业评论、华尔街日报杂志等130+杂志
- 特点:主题多样,布局创新
完整基准数据集包含:
- 72,300+文档图像
- 620,000+问答对
- 细粒度OCR和阅读顺序标签
- 文本、表格、图表多模态覆盖
4.2 数据集特性
4.2.1 规模与组成
| 子集 | 图像数 | 平均Token数 | 任务数 | 语言 | 问题数 | 唯一性 |
|---|---|---|---|---|---|---|
| 杂志 | 42.7K | 1,075±861 | 6 | 英语、中文 | 304.6K | 99.7% |
| 报纸 | 29.6K | 1,075±861 | 6 | 英语、中文 | 304.6K | 99.7% |
4.2.2 文本与布局复杂度
MosaicDoc的信息密度显著高于现有数据集。英文报纸子集的平均token数远高于MP-DocVQA。虽然DuReadervis也有高token数,但其网页截图往往布局稀疏,答案局限于小区域。相比之下,MosaicDoc的文档在整个页面上都有密集的结构化文本。
布局复杂度量化:使用BLEU分数(2-4-gram)量化布局复杂度。将全局正确阅读顺序作为参考文本,通过坐标排序(从左到右、从上到下)构建。模型生成的阅读序列作为候选文本。BLEU分数越低,表示布局越非线性或复杂。
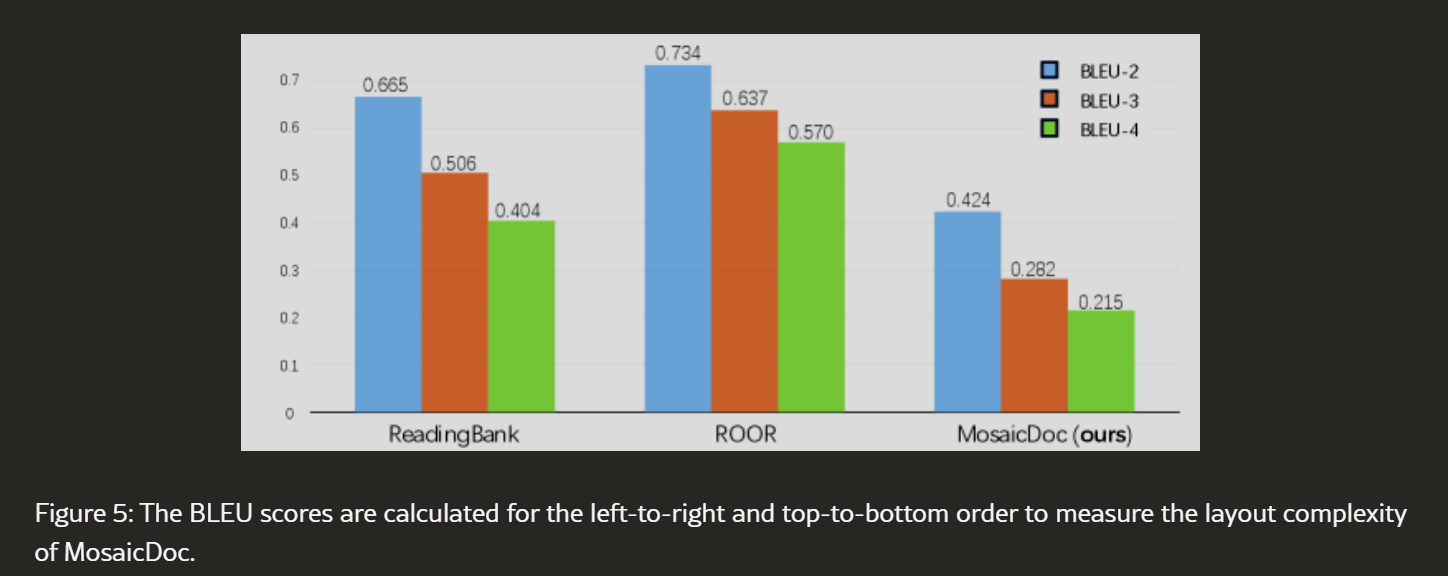
| 数据集 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|
| ReadingBank | 0.665 | 0.506 | 0.404 |
| ROOR | 0.734 | 0.637 | 0.570 |
| MosaicDoc | 0.424 | 0.282 | 0.215 |
结果确认MosaicDoc呈现更具挑战性的结构推理任务。
4.2.3 问题质量与多样性
使用Qwen嵌入模型分析每个数据集5,000个问题样本,计算语义相似度分数和token长度:
- 平均token长度更高:MosaicDoc问题更长,涉及更多细节
- 语义相似度显著更低:问题之间差异性大,重复少
- 唯一性超过99.7%:几乎每个问题都是独特的
MosaicDoc包含大量多跨度QA对,解决了现有DocVQA数据集的已知缺陷,使得复杂答案抽取场景的评估成为可能(需要从文档内多个位置聚合信息)。
4.2.4 综合多任务支持
与单一任务基准(如ReadingBank)或领域特定基准(如DuReadervis)不同,MosaicDoc为广泛的VRDU任务提供统一平台:
- 文档VQA:单跨度、多跨度、表格、图表QA
- OCR:词级和行级
- 阅读顺序预测:块级和行级
- 内容感知定位:答案和上下文的空间定位
通过提供单一的综合资源桥接这些任务,MosaicDoc成为推进文档AI的更全面和具有挑战性的基准。
4.3 质量保证
4.3.1 自动过滤
所有生成的QA对通过五维度幻觉防护系统,只有高分样本被保留。表2显示了过滤结果:
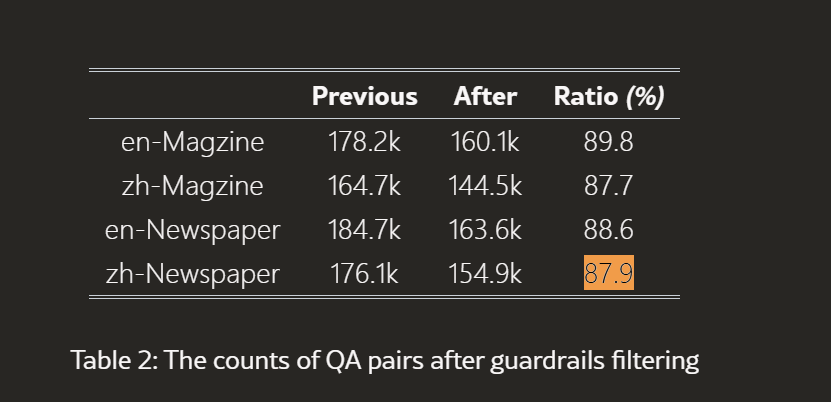
| 子集 | 过滤前 | 过滤后 | 保留率 |
|---|---|---|---|
| 英文杂志 | 178.2K | 160.1K | 89.8% |
| 中文杂志 | 164.7K | 144.5K | 87.7% |
| 英文报纸 | 184.7K | 163.6K | 88.6% |
| 中文报纸 | 176.1K | 154.9K | 87.9% |
约10-12%的QA对因质量问题被过滤,确保数据集的高质量。
4.3.2 人工验证
为建立黄金标准测试集,进行了细致的人工验证。从所有四个子集中随机抽取200个文档图像及其对应标注,人工标注者手动纠正QA对和阅读顺序序列中的任何剩余错误,遵循与自动防护相同的标准。
标注者间一致性通过平均成对F1分数测量为0.97,表明高度一致性。这个人工验证的子集用于论文报告的所有实验评估,确保结果基于最准确的数据。
测试集分布:
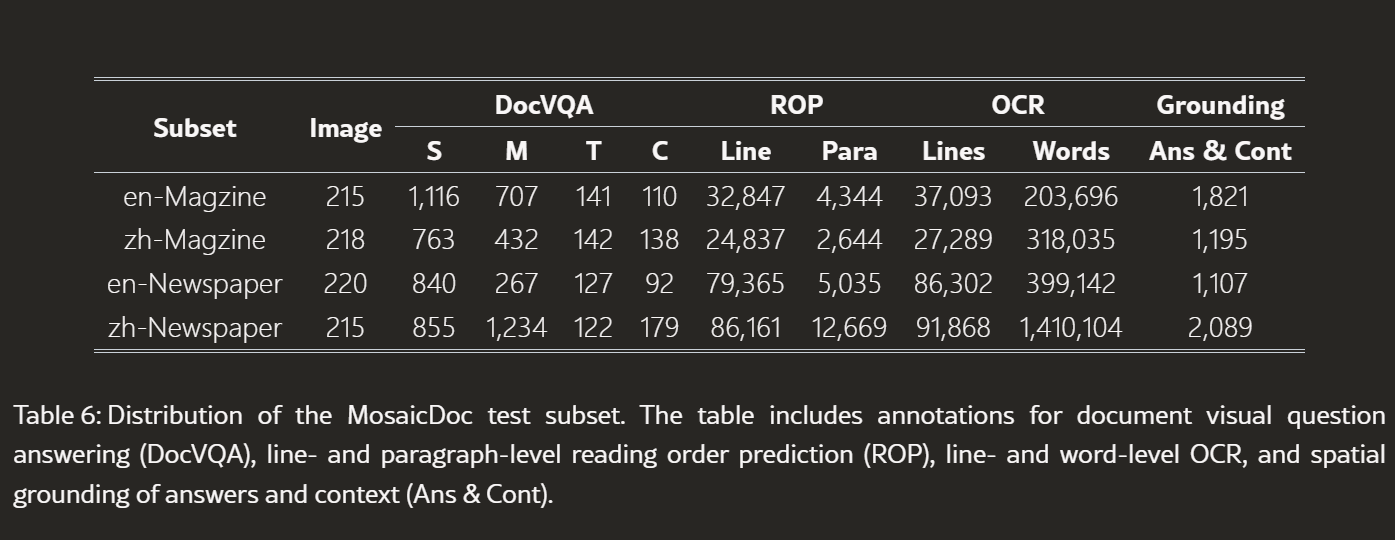
| 子集 | 图像 | 单跨度 | 多跨度 | 表格 | 图表 | 行级ROP | 段落级ROP | 行级OCR | 词级OCR | 答案&上下文定位 |
|---|---|---|---|---|---|---|---|---|---|---|
| 英文杂志 | 215 | 1,116 | 707 | 141 | 110 | 32,847 | 4,344 | 37,093 | 203,696 | 1,821 |
| 中文杂志 | 218 | 763 | 432 | 142 | 138 | 24,837 | 2,644 | 27,289 | 318,035 | 1,195 |
| 英文报纸 | 220 | 840 | 267 | 127 | 92 | 79,365 | 5,035 | 86,302 | 399,142 | 1,107 |
| 中文报纸 | 215 | 855 | 1,234 | 122 | 179 | 86,161 | 12,669 | 91,868 | 1,410,104 | 2,089 |
ROP:Reading Order Prediction(阅读顺序预测)
五、实验评估
5.1 评估设置
5.1.1 基线模型
研究者评估了13个最新SOTA模型,分为三类:
专家模型(预LLM架构):
- LayoutReader:使用行级文本边界框作为输入
- Donut(253M参数):仅消费图像和问题
- ViTLP(259M参数):仅消费图像和问题
- 特点:参数量小(<0.3B),不整合大语言模型
专家VLM(文档特化):
- Vary-7B:基于Qwen-7B
- mPLUG-DocOwl2-7B:基于LLaMA-7B
- TextMonkey-7B:基于Qwen-7B
- GOT-OCR-0.5B:基于Qwen-0.5B
- olmOCR-8B:基于Qwen2-7B
- 特点:基于LLM骨干,在大规模文档数据集上预训练,专门用于DocVQA和ROP任务
通用VLM:
- CogVLM2-19B:基于Meta-Llama-3-8B
- InternVL3-9B:基于Internlm3-8B
- Qwen2.5-VL-7B:基于Qwen2.5-7B
- GPT-4o(API)
- Gemini-2.5(API)
- 特点:通用目的视觉语言模型,跨广泛任务具有SOTA能力
所有模型在零样本设置下使用官方默认配置评估,图像以每个模型支持的最大分辨率提供。VLM评估在配备80GB内存的NVIDIA A100 GPU上的VLLM框架内进行。
5.1.2 评估指标
平均归一化莱文斯坦相似度列表**ANLSL****(Average Normalized Levenshtein Similarity for List)**:用于DocVQA任务。该指标扩展了ANLS以支持顺序不变的列表评估。
ANLS 原本适用于单条文本的相似度评估,能柔化 OCR 识别等导致的字符级小错误惩罚,但无法适配列表这类多元素输出场景。
ANLSL 填补了这一空白,专门用于评估模型输出的列表与真实列表的相似度,且关键支持顺序不变的评估逻辑。
主要用于 DocVQA 任务中**涉及列表输出的场景**,比如向模型提问 “提取该发票中的所有采购商品名称”,模型输出商品列表后,ANLSL 可量化该列表与真实商品列表的匹配程度。也适用于票据多行信息抽取、简历中技能列表提取等相关任务的模型性能评估。
- 适配顺序不变的列表匹配:该指标采用**匈牙利匹配算法**,为模型预测列表和真实列表找到最优元素配对方式。这意味着即便列表中元素顺序错乱,只要内容对应,也能被正确计算相似度,完美适配发票商品清单、表单多行填写项等顺序无关的列表类任务评估。
- 改良编辑距离以兼容格式小差异:它改编了传统莱文斯坦编辑距离的测量方式。传统评估可能因输出中多空格、少标点等格式小问题判定为错误,而 ANLSL 会弱化这类无关惩罚。例如真实答案列表中是 “iPhone 15”,模型输出 “iPhone15”,字符级核心信息正确,仅格式有差异,ANLSL 会给出较高相似度分数,而非直接判错。
为避免惩罚字符级正确但格式略有不同的有效输出,研究者改编了编辑距离测量。
对于列表G = {g_i}和预测P̂ = {p_j}:
- 计算成对NLS(g_i, p_j)
- 解决最优匹配M*
- ANLSL(G, P̂) = Σ_{(i,j)∈M*} NLS(g_i, p_j) / max(M, N)
分数在[0,1]之间,1表示所有匹配项之间的完美对齐。
CRR(Character Recognition Rate)和OCRR(Output-based CRR):用于页面级OCR。
- CRR = (正确识别字符数) / |G|
- OCRR = (正确识别字符数) / |P̂|
**CRR **是最基础、最常用的 OCR 字符级评估指标,直接衡量 “模型正确识别的字符数” 占 “真实场景中所有应识别字符数(金标准字符数)” 的比例,核心反映 OCR 模型的 “字符级精准度”。
OCRR 是 CRR 的 “补充优化版”,专门解决通用 VLM 等模型在 OCR 任务中 “输出冗余 / 重复字符” 的问题 —— 它将 “模型输出的总字符数” 作为分母,衡量 “正确识别的字符数” 占 “模型实际输出字符数” 的比例,核心反映 OCR 输出的 “字符级有效率”。
OCRR归一化为输出长度,测量生成文本内的精度,应对VLM常见的重复或跳过字符问题。
Micro-F1:用于阅读顺序预测ROP,在文本行序列上计算。由于VLM产生纯文本,通过将文本块匹配到真值序列来确定预测顺序的正确性。
**Micro - F1 **是一种综合考量准确率和召回率的模型性能评估指标。是 F1 分数的变体,计算时会先统计所有类别的总真正例(TP,正确预测为目标类别的数量)、总假正例(FP,错误预测为目标类别的数量)和总假反例(FN,应预测为目标类别却预测错误的数量),再基于这些总和计算整体的准确率和召回率,最后通过调和平均得出结果。
该指标的显著特点是对样本数量多的类别更敏感,能反映模型的整体性能。因为它基于所有类别样本的汇总数据计算,当数据集存在类别不平衡时,占比高的类别对最终结果的影响会更突出,数值越接近 1 代表模型整体性能越好。
先将 VLM 生成的纯文本拆分为多个文本块,同时确定这些文本块对应的 “真值序列”(即符合人类阅读习惯的正确文本块顺序);
把 “文本块是否处于正确顺序位置” 当作分类任务,逐个判断预测序列中的文本块与真值序列中对应位置的匹配情况,统计所有文本块匹配的总 TP、总 FP 和总 FN;
P、R、F1 分别对应 Precision(精确率)、Recall(召回率)、F1-score(F1 分数)
5.2 文档VQA性能
综合结果揭示了几个关键发现:
5.2.1 通用VLM显著优于专家模型
**通用VLM(如InternVL3、Qwen2.5-VL、GPT-4o、Gemini-2.5)显著优于专家模型和大多数专家VLM。**这表明通用模型的大规模、多样化预训练数据和优越的架构扩展为VRDU提供了比简单文档上的领域特定预训练更鲁棒的基础。
VRDU指Visually-rich Document Understanding(视觉丰富文档理解).
视觉丰富文档(如发票、简历、表单等)的语义不仅由文本内容决定,还和排版格式、表格结构等视觉元素强相关。VRDU 的核心目标就是让机器自动读取、分析并处理这类文档,既包含识别提取文档内对象的 “感知” 任务,也涵盖基于文档特征做问答、信息抽取等的 “理解” 任务。
例如,在英文杂志子集上:
- 最佳通用VLM(Gemini-2.5)达到61.27% ANLSL
- 而专家VLM中最好的(mPlug-DocOWL2)仅为11.70%
5.2.2 专家VLM的意外困境
专家VLM在MosaicDoc来源上的表现出人意料地困难。研究者将此主要归因于TextMonkey和mPLUG-DocOwl2等模型采用的token缩减策略。虽然这些方法对简单文档有效,但在应用于杂志和报纸的信息密集布局时,合并或丢弃视觉token可能导致关键语义损失。
5.2.3 多跨度QA的普遍性能下降
所有模型在多跨度问题上表现出戏剧性且一致的性能下降。即使是表现最好的本地模型Qwen2.5-VL和远程模型Gemini-2.5,相比单跨度性能,ANLS分数也大幅下降。
以英文杂志为例(ANLSL分数):
- 单跨度 vs 多跨度性能差距
- Qwen2.5-VL:57.86 → 43.81(下降约14%)
- Gemini-2.5:65.78 → 55.63(下降约10%)
这突显了当前模型在执行需要跨复杂布局合成信息的多跨度提取方面的关键和普遍弱点。
5.2.4 表格和图表问题的相对优势
有趣的是,表格和图表问题的性能相对较高,可能是因为这些任务更多依赖于定位结构化对象,而不是精细阅读密集段落。
5.3 页面级OCR性能
页面级OCR评估揭示了模型在原始文本识别能力上的显著差异:
5.3.1 报纸子集的普遍困难
所有模型在报纸子集上的表现都显著更差,凸显了其密集和复杂布局的极端困难。
报纸中的中文更差。
CRR和OCRR结果(英文/中文):
| 模型 | 杂志CRR | 杂志OCRR | 报纸CRR | 报纸OCRR |
|---|---|---|---|---|
| GOT-OCR | 22.27/31.46 | 45.62/41.15 | 3.09/7.15 | 1.13/5.17 |
| olmOCR | 73.76/53.85 | 86.33/74.20 | 32.58/1.19 | 52.00/12.45 |
| InternVL3 | 66.06/59.29 | 74.65/61.38 | 56.03/31.77 | 58.59/44.89 |
| Qwen2.5-VL | 55.24/57.29 | 23.60/28.40 | 34.46/39.62 | 11.17/31.40 |
| GPT-4o | 69.81/30.33 | 75.88/39.15 | 37.55/2.69 | 53.17/15.34 |
| Gemini-2.5 | 89.42/87.34 | 90.32/80.31 | 87.90/66.64 | 91.04/78.18 |
5.3.2 重复序列生成问题
观察到一个普遍且常见的失败模式:VLM在生成一定量文本后,开始产生重复序列直到达到token限制,导致OCRR降低。这严重惩罚了CRR分数,表明在处理长的、密集的视觉输入时上下文理解的崩溃,即使初始识别的文本是准确的。
这种读取整页的失败有效地限制了模型回答内容相关问题的能力。
因为水平相邻的块通常比文章内的垂直连续行在空间上更近,这挑战了简单的自上而下启发式方法。尽管在三个子集上表现强劲,Gemini 只能有效地在同一列内排序文本,而无法在多列或非曼哈顿布局中建立段落级文本的正确顺序关系——这一挑战构成了在如此复杂的文档布局中恢复阅读顺序的核心问题(参见附录 F.4 中的结果和可视化)。未能理解全局布局导致 OCR 任务中出现重复输出,并从根本上削弱了模型理解文档整体的能力。
5.4 阅读顺序预测
使用Micro-F1分数在文本行序列上评估ROP。结果揭示了大多数模型的高度一致趋势:
模型擅长排序单个行,但在处理跨越多列或视觉上相邻但语义上无关的段落时表现不佳。
5.4.1 高精度、低召回的模式
行级ROP结果(精度P / 召回R / F1):
| 模型 | 杂志(英/中) | 报纸(英/中) |
|---|---|---|
| LayoutReader | 5.93/10.6, –/–, –/– | 5.40/3.19, –/–, –/– |
| GOT-OCR | 2.55/7.05, 0.61/2.72, 0.99/3.93 | 14.2/13.5, 0.55/0.17, 1.07/0.34 |
| olmOCR | 92.7/91.1, 73.3/58.7, 81.9/71.4 | 60.1/22.6, 23.5/0.36, 33.8/0.71 |
| InternVL3 | 86.1/87.6, 62.1/70.7, 72.2/76.6 | 82.2/74.8, 52.2/28.4, 63.9/41.2 |
| Qwen2.5-VL | 92.6/93.5, 50.6/63.6, 65.4/75.7 | 90.0/92.0, 35.5/41.5, 50.9/57.2 |
| GPT-4o | 85.9/74.6, 60.1/33.2, 70.7/45.9 | 74.6/60.0, 33.2/17.3, 45.1/26.9 |
| Gemini-2.5 | 91.9/93.8, 84.2/85.4, 87.9/89.4 | 95.7/94.2, 81.3/40.2, 87.9/56.3 |
这表明虽然模型识别的文本片段通常在正确的局部序列中(例如,在单列内),但它们未能捕获页面的全部内容。
5.4.2 段落级序列的额外挑战
段落级ROP结果显示更低的召回率,表明模型在跨栏或段落建立正确顺序关系时面临更大挑战:
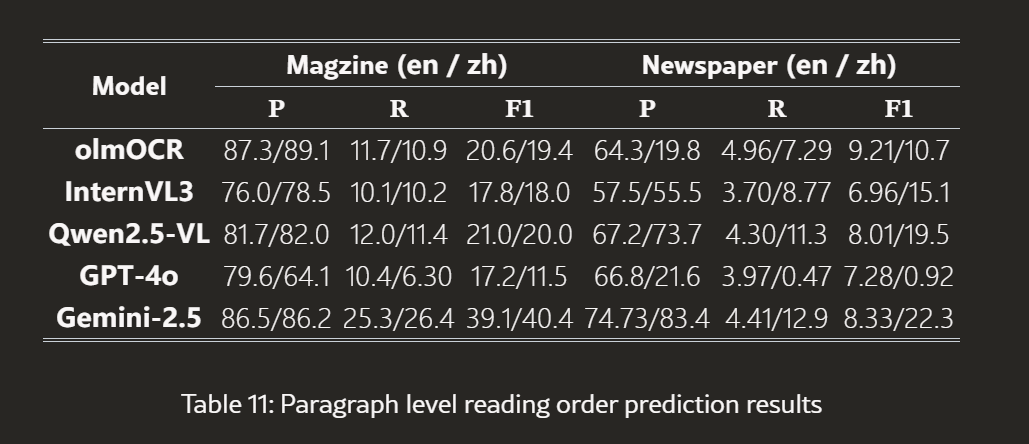
| 模型 | 杂志(英/中)F1 | 报纸(英/中)F1 |
|---|---|---|
| olmOCR | 20.6/19.4 | 9.21/10.7 |
| InternVL3 | 17.8/18.0 | 6.96/15.1 |
| Qwen2.5-VL | 21.0/20.0 | 8.01/19.5 |
| GPT-4o | 17.2/11.5 | 7.28/0.92 |
| Gemini-2.5 | 39.1/40.4 | 8.33/22.3 |
5.4.3 多栏和非曼哈顿布局的挑战
在报纸中,水平相邻的块通常在空间上比文章内垂直连续的行更接近,这挑战了简单的从上到下启发式。
尽管Gemini在三个子集上表现强劲,但它只能有效地对同一列内的文本排序,未能在多栏或非曼哈顿布局中建立段落级文本之间的正确顺序关系——这是复杂文档布局中阅读顺序恢复的核心挑战。
这种未能理解全局布局导致了OCR任务中观察到的重复输出,并从根本上削弱了模型将文档作为整体理解的能力。
5.5 关键发现总结
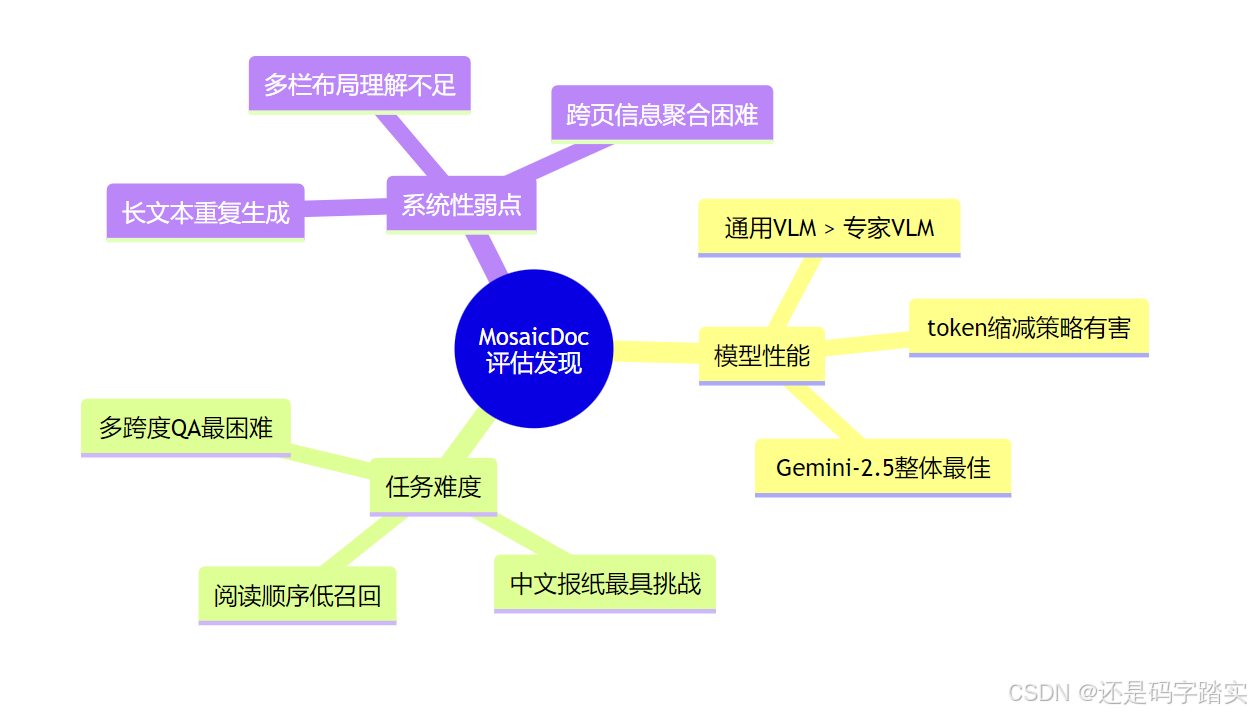
- 通用VLM的优势:大规模多样化预训练比领域特定预训练更有效
- 多跨度推理的普遍困境:所有模型在需要合成多个文本片段的任务上都表现不佳
- 布局理解的系统性缺陷:高精度低召回表明模型只能理解局部结构,缺乏全局布局理解
- 长文本处理的崩溃:重复生成问题揭示了上下文窗口管理的根本性挑战
六、创新点与贡献
6.1 方法论创新
全自动化标注流水线:DocWeaver实现了首个完全自动化的多任务文档标注生成和验证流程,超越了如TRIG等仍需人工验证的先前工作。这为大规模数据集构建提供了可扩展的解决方案。
自适应阅读顺序建模:不强制全局线性顺序,而是针对不同文档类型设计专门化策略:
- HTML对齐方法(中文报纸)
- 语义-布局混合方法(双语杂志)
- 视觉中心方法(英文报纸)
这种灵活的方法更符合人类阅读视觉丰富文档的真实行为。
五维幻觉防护机制:完整性、一致性、简洁性、清晰度、推理有效性的综合评估框架,确保生成数据的高质量。
6.2 数据集贡献
首个大规模复杂布局双语基准:填补了现有数据集在语言覆盖、布局复杂度、任务多样性方面的空白。
真实世界场景的忠实反映:报纸和杂志代表了实际应用中最具挑战的文档类型,而非简化的合成数据。
多跨度QA的大量覆盖:约50%的QA对为多跨度问题,直接解决了现有数据集的已知缺陷。
6.3 评估贡献
全面的基线建立:13个SOTA模型的系统评估为未来研究提供了清晰的性能基准。
系统性弱点的揭示:
- token缩减策略在密集布局中的失效
- 多跨度推理的普遍困难
- 阅读顺序理解的高精度低召回模式
- 长文本处理的重复生成问题
这些发现为社区指明了未来研究的关键方向。
七、局限性与未来方向
7.1 当前局限性
领域覆盖有限:虽然MosaicDoc在报纸和杂志领域提供了前所未有的深度,但仍缺乏其他重要文档类型:
- 历史文档
- 手写文档
- 技术图纸
- 表单和发票
数字文档依赖:流水线基于可编辑PDF,对于纯扫描文档(如历史档案)可能需要额外的OCR预处理步骤。
跨页理解深度不足:虽然有跨页链接智能体,但最多合并四页,对于长篇报告或书籍可能不够。
表格和图表覆盖不均:虽然包含表格和图表QA,但在某些子集中的数量相对较少,可能限制了对这些模态的深入评估。
7.2 补充性研究
自MosaicDoc提出以来,已有研究在以下方向进行了补充:
长文档理解:MP-DocVQA的多页版本尝试扩展到多页问答,但如论文所指出,其问题往往不需要跨页推理。更近期的工作如DocGenome专注于科学论文的长文档理解。
域外泛化:olmOCR-mix-0225等大规模混合数据集尝试通过web爬取的PDF提高泛化能力,但布局多样性仍然有限。
结构化输出:一些工作(如Dolphin)开始探索异构锚点提示(heterogeneous anchor prompting)来改进文档图像解析,这可能与DocWeaver的多智能体方法形成互补。
视觉定位能力:TRIG等工作提供视觉定位功能,但最终仍依赖人工验证。MosaicDoc的自动化空间定位标注为这一方向提供了可扩展的解决方案。
7.3 未来研究方向
基于实验揭示的系统性弱点,以下方向值得深入研究:
改进的多跨度推理机制:
- 显式的跨段落信息聚合模块
- 基于图的文档表示学习
- 层次化注意力机制
鲁棒的全局布局理解:
- 端到端的布局结构学习
- 非曼哈顿布局的专门化编码
- 多尺度布局表示
长上下文处理优化:
- 防止重复生成的机制
- 更高效的长文档编码策略
- 自适应的上下文窗口管理
跨领域泛化:
- 在MosaicDoc上预训练,迁移到其他领域
- 少样本学习在新文档类型上的应用
- 零样本布局理解能力的提升
八、实际落地建议
8.1 模型选择
基于MosaicDoc的评估结果,针对不同应用场景提供以下模型选择建议:
8.1.1 API服务 vs 本地部署
推荐API服务(Gemini-2.5),如果:
- 预算充足,可承受API调用成本
- 对性能要求最高(全任务最佳)
- 无数据隐私限制
- 需要处理多语言文档
推荐本地部署(InternVL3-9B或Qwen2.5-VL-7B),如果:
- 有数据隐私或合规要求
- 需要可控的推理成本
- 有GPU资源(建议至少A100 80GB)
- 可接受略低于API的性能
8.1.2 任务特定选择
| 任务类型 | 首选模型 | 次选模型 | 理由 |
|---|---|---|---|
| DocVQA(单跨度) | Gemini-2.5 | Qwen2.5-VL | 在所有子集上性能最佳 |
| DocVQA(多跨度) | Gemini-2.5 | InternVL3 | 性能下降相对较小 |
| 页面级OCR | Gemini-2.5 | InternVL3(Qwen2.5-VL会很差) | 高CRR和OCRR,重复问题较少(适合复杂布局导致的 重复输出) |
| 阅读顺序预测 | Gemini-2.5 | olmOCR | 最佳F1分数,但仍需改进召回 |
8.1.3 通用VLM vs 专家VLM
避免使用传统专家VLM(如TextMonkey、mPLUG-DocOwl2)用于复杂布局文档,原因:
- Token缩减策略导致语义损失
- 在MosaicDoc上性能显著低于通用VLM
考虑新一代专家模型(如olmOCR)如果:
- 专注于纯OCR任务
- 文档布局相对规范
- 需要针对特定文档类型微调
8.1.4 模型集成策略
对于生产环境,建议采用级联或集成策略:
8.2 提示工程
DocWeaver的成功很大程度上归功于精心设计的提示工程。以下是关键提示模板的中文翻译和分析。
8.2.1 单跨度和多跨度QA生成提示
单段和多段问答生成的提示(Prompt)
<System: 你是一位专业的摘要撰写者和编辑。你的主要目标是将复杂信息提炼为清晰、简洁且中立的摘要。
Prompt: 为以下文章生成一句话摘要(即 TL;DR — “太长没读”)。
文章: <Text in Order>
--------------------------------------------
<System: 你是一位细致的 <Doc Type> 分析师。你的任务是根据提供的 <Doc Type> 文章文本片段,生成有洞察力的问题。
Prompt: 你将获得 **文章的摘要** 和 **多个文本片段**(用 <document> 和 </document> 标签包围,每个片段由 <part type> 和 </part> 分隔)。请仔细阅读这些文本,确保每个部分中的词语顺序有意义,因为文本顺序可能略有颠倒。如果某个 <part> 包含有意义的内容(即使很短),你也必须从中生成至少一个相关问题。对于每一个有效部分,生成 **不超过20个高质量问答对**(包括单段和多段问答),并 **尽可能优先生成多段问答**。每个问答对都必须包含相关的上下文。
定义:
- **单段问答(Single-span QA)**:答案仅由 **恰好一个片段** 组成({<answer>}),且文本其他部分无法正确回答该问题。
- **多段问答(Multi-span QA)**:答案由 **多个片段** 组成({<answer1>, <answer2>, ...});仅靠一个片段不足以完整回答问题。
问题、上下文和答案的指南:
1. **问题(Questions)**:
- 相比于单段问答,尽量生成更多多段问答对。
- 尽量使问题简短,只要不影响清晰度和可回答性即可。
- 问题必须 **紧密关联所提供内容**。避免模糊、过于宽泛或总结式的问题。
- 不要在问题中直接包含答案。
- 避免仅基于时间顺序的多段问答。
- 关于日期或年份的问题最多只允许一个(周年纪念或特定历史引用除外)。
- 确保问题类型多样化,例如:
(1) 直接提问(如:“什么是……?”)
(2) 确认类问题(如:“说……是否正确?”)
(3) 解释请求(如:“为什么人们相信……?”)
(4) 假设性问题(如:“如果……会发生什么?”)
(5) 要求示例的问题(如:“你能举个例子吗?”)
,以及其他类型。
- 问题应 **涵盖关键信息、主要概念和重要细节**,不得有重大遗漏。
2. **上下文(Context)**:
- 上下文必须 **忠实反映原文,不得改写、缩写、总结或替换**。
- 提供完整准确的上下文,仅删除明显冗余或无关的部分。
- 对于多段问答,需包含文本中所有必要的片段,这些片段可能来自多个段落。
- 上下文必须包含答案内容的逐字原文。
- 如有必要,加入日期、姓名、标题和背景信息以增强清晰度。
3. **答案(Answers)**:
- 答案应简洁,为原文中的精确摘录——禁止改写或总结。
- 只有在答案仍然完全正确且逻辑完整的前提下,才可截断。
- 多段答案需以字符串列表形式呈现。
- 确保所有答案均可直接从原文中提取,以保证一致性和准确性。
4. **输出格式(Output Format)**:
- 按如下 JSON 格式组织输出:{questions: [{ "question": "...", "context": ["...", ...], "answer": ["...", ...]}, ...]}。
你可以参考以下示例:
- 单段问答示例:
<dataset-based e.g.> + <well-designed e.g.>
- 多段问答示例:
<dataset-based e.g.> + <well-designed e.g.>
文章摘要:
<summary><Summary></summary>
文章内容:
<document><Text in Layout type></document>
基于此摘要(<summary>)和文本(<document>),请生成 JSON 格式的问答对。
8.3 实施建议
8.3.1 数据准备
# 伪代码:文档预处理流程
def preprocess_document(pdf_path):
# 1. PDF解析
text, bboxes = extract_pdf_content(pdf_path)
# 2. 编码修复
text = fix_encoding(text)
# 3. 图像渲染
high_res_img = render_page(pdf_path, dpi=300)
random_dpi_img = render_page(pdf_path, dpi=random.randint(72, 300))
# 4. 布局分析
layout_elements = detect_layout(high_res_img)
# 5. 多引擎OCR投票
ocr_results = []
for engine in [PaddleOCR, Tesseract, EasyOCR]:
result = engine.recognize(layout_elements)
ocr_results.append(result)
final_text = weighted_voting(ocr_results)
# 6. 阅读顺序推断
reading_order = infer_reading_order(
layout_elements,
pdf_metadata,
html_source=get_html_if_available(pdf_path)
)
return {
'text': final_text,
'bboxes': bboxes,
'layout': layout_elements,
'reading_order': reading_order,
'images': (high_res_img, random_dpi_img)
}
8.3.2 质量控制
实施多层质量控制:
- 自动过滤:使用五维度评分系统,阈值设为>3
- 几何验证:对于阅读顺序,检查无效连接数量
- 抽样人工审核:定期抽样审核生成数据
- A/B测试:对于关键应用,比较不同提示版本的输出质量
8.3.3 成本优化
对于大规模应用:
- 级联策略:简单问题用小模型,复杂问题升级到大模型
- 批处理:聚合请求减少API调用开销
- 缓存机制:缓存常见文档类型的中间结果
- 自托管优先:对于高频场景,优先考虑本地部署
8.3.4 持续改进
建立反馈循环:
- 收集用户对答案质量的反馈
- 分析常见错误模式
- 针对性优化提示或微调模型
- 持续监控关键指标(准确率、延迟、成本)
九、参考文献
- MosaicDoc论文
Chen, K., Chen, Y., & Xue, Y. (2025). MosaicDoc: A Large-Scale Bilingual Benchmark for Visually Rich Document Understanding. arXiv:2511.09919.
官方论文,详细介绍了DocWeaver流水线和MosaicDoc数据集的构建过程。
https://arxiv.org/abs/2511.09919 - GitHub代码仓库
MosaicDoc官方代码、数据集下载链接和使用说明。
https://github.com/DOCLAB-SCUT/MosaicDoc - LayoutReader: Pre-training of Text and Layout for Reading Order Detection
Wang et al. (2021). 提出了使用行级文本边界框预测阅读顺序的早期方法。
https://arxiv.org/abs/2108.11591 - Donut: OCR-Free Document Understanding Transformer
Kim et al. (2022). 首个端到端的、无需OCR的文档理解模型。
ECCV 2022 - DocVQA: A Dataset for VQA on Document Images
Mathew et al. (2021). 文档视觉问答领域的基础数据集。
https://arxiv.org/abs/2007.00398 - MP-DocVQA: Multi-page Document VQA
Tito et al. (2023). 扩展到多页文档的VQA数据集。
Pattern Recognition, 2023 - InfographicsVQA
Mathew et al. (2022). 专注于信息图表的VQA数据集。
WACV 2022 - DuReadervis: 中文长网页文档理解数据集
Qi et al. (2022). 百度发布的中文文档理解数据集。
https://arxiv.org/abs/2203.11142 - DUDE: Document Understanding Dataset and Evaluation
Van Landeghem et al. (2023). 多领域文档理解评估基准。
ICCV 2023 - ReadingBank: 大规模阅读顺序数据集
Wang et al. (2021). 包含500K文档的词级文本序列数据集。
https://arxiv.org/abs/2108.11591 - olmOCR: Unlocking Trillions of Tokens in PDFs
Poznanski et al. (2025). 在web爬取的PDF上训练的大规模OCR模型。
https://arxiv.org/abs/2502.18443 - DocGenome: 科学文档基准
Xia et al. (2024). 专注于科学论文的多模态大语言模型训练和测试基准。
https://arxiv.org/abs/2406.11633 - XFUND: 多语言表单理解基准
Xu et al. (2022). Microsoft发布的多语言视觉丰富表单理解数据集。
ACL 2022 Findings - G-EVAL: NLG Evaluation Using GPT-4
Liu et al. (2023). 使用LLM进行自然语言生成评估的框架,启发了MosaicDoc的幻觉防护机制。
https://arxiv.org/abs/2303.16634 - PP-DocLayout: 统一文档布局检测模型
Sun et al. (2025). 加速大规模数据构建的布局分析工具。
https://arxiv.org/abs/2503.17213 - M6Doc: 多格式多类型文档布局数据集
Cheng et al. (2023). 用于训练PP-DocLayout的大规模杂志数据集。
CVPR 2023 - MinerU: 精确文档内容提取的开源解决方案
Wang et al. (2024). 用于初始阅读顺序预测的工具。
https://arxiv.org/abs/2409.18839 - InternVL3: 探索开源多模态模型的高级训练和测试秘诀
Zhu et al. (2025). 本文评估的最佳本地通用VLM之一。
https://arxiv.org/abs/2504.10479 - Qwen2.5-VL Technical Report
Bai et al. (2025). 阿里巴巴发布的强大开源VLM。
https://arxiv.org/abs/2502.13923 - Gemini 2.5: 推进前沿与高级推理、多模态、长上下文和下一代智能体能力
Comanici et al. (2025). Google最新的多模态模型,在MosaicDoc上表现最佳。
https://arxiv.org/abs/2507.06261 - GPT-4o System Card
OpenAI (2024). GPT-4o的技术文档和能力描述。
https://openai.com/research/gpt-4o-system-card - TVG: 表格视觉定位
Liu et al. (2024). 用于表格理解和视觉定位的方法。
https://arxiv.org/abs/2409.19573 - TRIG: 视觉文本定位
Li et al. (2025). 多模态大语言模型的视觉文本定位方法。
https://arxiv.org/abs/2504.04974 - Dolphin: 通过异构锚点提示的文档图像解析
Feng et al. (2025). 新型文档解析方法。
https://arxiv.org/abs/2505.14059 - TextMonkey: OCR-Free Large Multimodal Model
Liu et al. (2024). 专为文档理解设计的大型多模态模型。
https://arxiv.org/abs/2403.04473 - mPLUG-DocOwl2: 高分辨率压缩用于无OCR多页文档理解
Hu et al. (2025). 阿里巴巴发布的文档专用VLM。
ACL 2025 - CogVLM2: 图像和视频理解的视觉语言模型
Hong et al. (2024). 清华大学和智谱AI发布的强大通用VLM。
https://arxiv.org/abs/2408.16500 - PyMuPDF Documentation
用于PDF解析的Python库文档。
https://pymupdf.readthedocs.io - pdfminer.six Documentation
另一个用于PDF文本和元数据提取的Python工具。
https://pdfminersix.readthedocs.io - chardet: 字符编码检测库
用于处理PDF编码错误的Python库。
https://pypi.org/project/chardet - PaddleOCR
百度开源的OCR工具,支持80+语言。
https://github.com/PaddlePaddle/PaddleOCR - TableStructureRec
用于表格结构识别和转换为HTML的工具箱。
https://github.com/RapidAI/TableStructureRec - DeepSeek API
用于语义相似度计算的LLM服务。
https://www.deepseek.com - QWQ-32B: 拥抱强化学习的力量
Team (2025). 用作判别器和评估器的强推理能力模型。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)