【数据挖掘】聚类算法 简介 ( 基于划分的聚类方法 | 基于层次的聚类方法 | 基于密度的聚类方法 | 基于方格的聚类方法 | 基于模型的聚类方法 )
I . 聚类主要算法II . 基于划分的聚类方法III . 基于层次的聚类方法IV . 聚合层次聚类 图示V . 划分层次聚类 图示VI . 基于层次的聚类方法 切割点选取VII . 基于密度的方法VIII . 基于方格的方法IX . 基于模型的方法
文章目录
I . 聚类主要算法
聚类主要算法 :
① 基于划分的聚类方法 : K-Means 方法 ;
② 基于层次的聚类方法 : Birch ;
③ 基于密度的聚类方法 : DBSCAN ( Density-Based Spatial Clustering of Applications with Noise ) ;
④ 基于方格的方法 ;
⑤ 基于模型的方法 : GMM 高斯混合模型 ;
II . 基于划分的聚类方法
基于划分的方法 简介 : 基于划分的方法 , 又叫基于距离的方法 , 基于相似度的方法 ;
① 概念 : 给定 n n n 个数据样本 , 使用划分方法 , 将数据构建成 k k k 个划分 ( k ≤ n ) (k \leq n) (k≤n) , 每个划分代表一个聚类 ;
② 分组 : 将数据集 分成 k k k 组 , 每个分组至少要有一个样本 ;
③ 分组与样本 对应关系 : 每个分组有 1 1 1 个或多个样本对象 ( 1 1 1 对多 ) , 每个对象同时只能在 1 1 1 个分组中 ( 1 1 1 对 1 1 1 ) ;
④ 硬聚类 与 软聚类 : 每个数据对象只能属于一个组 , 这种分组称为硬聚类 ; 软聚类每个对象可以属于不同的组 ;
III . 基于层次的聚类方法
1 . 基于层次的聚类方法 概念 : 将数 据集样本对象 排列成 树结构 , 称为 聚类树 , 在指定的层次 ( 步骤 ) 上切割数据集样本 , 切割后时刻的 聚类分组 就是 聚类算法的 聚类结果 ;
2 . 基于层次的聚类方法 : 一棵树可以从叶子节点到根节点 , 也可以从根节点到叶子节点 , 基于这两种顺序 , 衍生出两种方法分支 , 分别是 : 聚合层次聚类 , 划分层次聚类 ;
3 . 聚合层次聚类 ( 叶子节点到根节点 ) : 开始时 , 每个样本对象自己就是一个聚类 , 称为 原子聚类 , 然后根据这些样本之间的 相似性 , 将这些样本对象 ( 原子聚类 ) 进行 合并 ;
常用的聚类算法 : 大多数的基于层次聚类的方法 , 都是 聚合层次聚类 类型的 ; 这些方法从叶子节点到根节点 , 逐步合并的原理相同 ; 区别只是聚类间的相似性计算方式不同 ;
4 . 划分层次聚类 ( 根节点到叶子节点 ) : 开始时 , 整个数据集的样本在一个总的聚类中 , 然后根据样本之间的相似性 , 不停的切割 , 直到完成要求的聚类操作 ;
5 . 算法性能 : 基于层次的聚类方法的时间复杂度为 O ( N 2 ) O(N^2) O(N2) , 如果处理的样本数量较大 , 性能存在瓶颈 ;
IV . 聚合层次聚类 图示
1 . 聚合层次聚类 图示 :
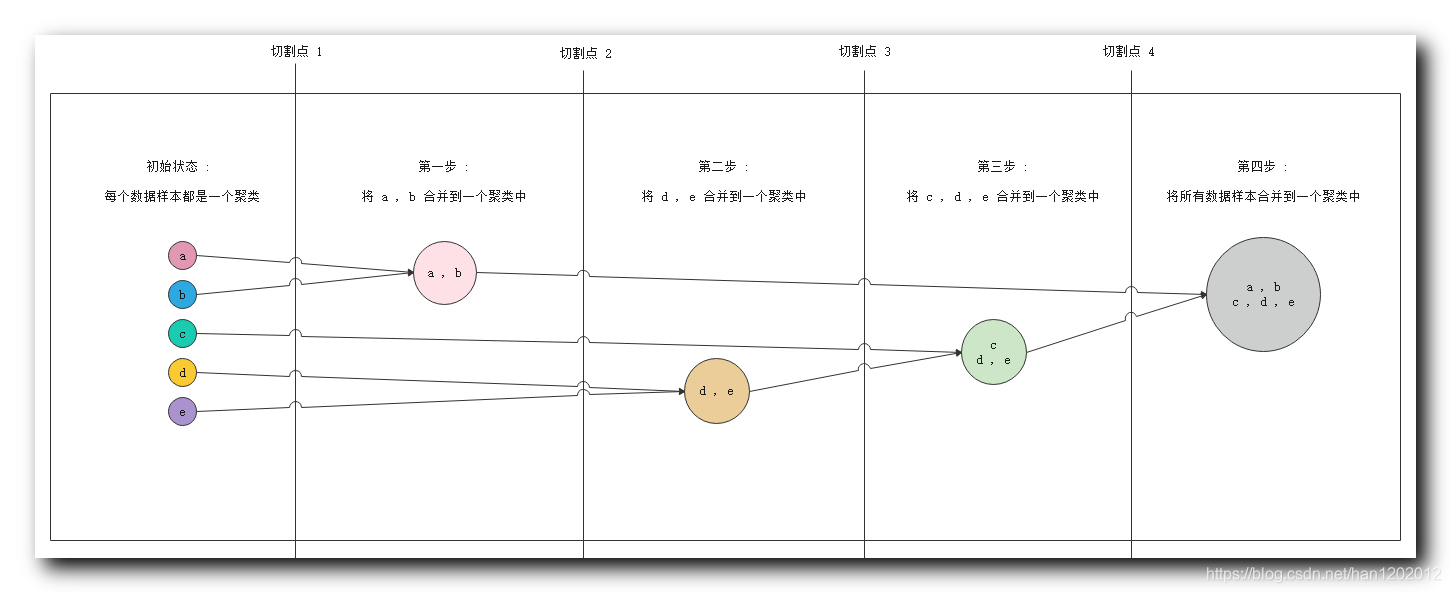
① 初始状态 : 最左侧 五个 数据对象 , 每个都是一个聚类 ;
② 第一步 : 分析相似度 , 发现 a , b a , b a,b 相似度很高 , 将 { a , b } \{a ,b\} {a,b} 分到一个聚类中 ;
③ 第二步 : 分析相似度 , 发现 d , e d, e d,e 相似度很高 , 将 { d , e } \{d, e\} {d,e} 分到一个聚类中 ;
④ 第三步 : 分析相似度 , 发现 c c c 与 d , e d,e d,e 相似度很高 , 将 c c c 数据放入 { d , e } \{d, e\} {d,e} 聚类中 , 组成 { c , d , e } \{c,d, e\} {c,d,e} 聚类 ;
⑤ 第四步 : 分析相似度 , 此时要求的相似度很低就可以将不同的样本进行聚类 , 将前几步生成的两个聚类 , 合并成一个聚类 { a , b , c , d , e } \{a, b, c, d, e\} {a,b,c,d,e} ;
2 . 切割点说明 : 实际进行聚类分析时 , 不会将所有的步骤走完 , 这里提供四个切割点 , 聚类算法进行聚类时 , 可以在任何一个切割点停止 , 使用当前的聚类分组当做聚类结果 ;
① 切割点 1 1 1 : 在切割点 1 1 1 停止 , 会得到 5 5 5 个聚类分组 , { a } \{a\} {a} , { b } \{b\} {b}, { c } \{c\} {c}, { d } \{d\} {d} , { e } \{e\} {e} ;
② 切割点 2 2 2 : 在切割点 2 2 2 停止 , 会得到 4 4 4 个聚类分组 , { a , b } \{a, b\} {a,b} , { c } \{c\} {c}, { d } \{d\} {d} , { e } \{e\} {e} ;
③ 切割点 3 3 3 : 在切割点 3 3 3 停止 , 会得到 3 3 3 个聚类分组 , { a , b } \{a, b\} {a,b} , { c } \{c\} {c}, { d , e } \{d, e\} {d,e} ;
④ 切割点 4 4 4 : 在切割点 4 4 4 停止 , 会得到 2 2 2 个聚类分组 ; { a , b } \{a, b\} {a,b} , { c , d , e } \{c, d, e\} {c,d,e} ;
⑤ 走完整个流程 : 会得到 1 1 1 个聚类分组 , { a , b , c , d , e } \{a, b ,c, d, e\} {a,b,c,d,e} ;
V . 划分层次聚类 图示
1 . 划分层次聚类 图示 :
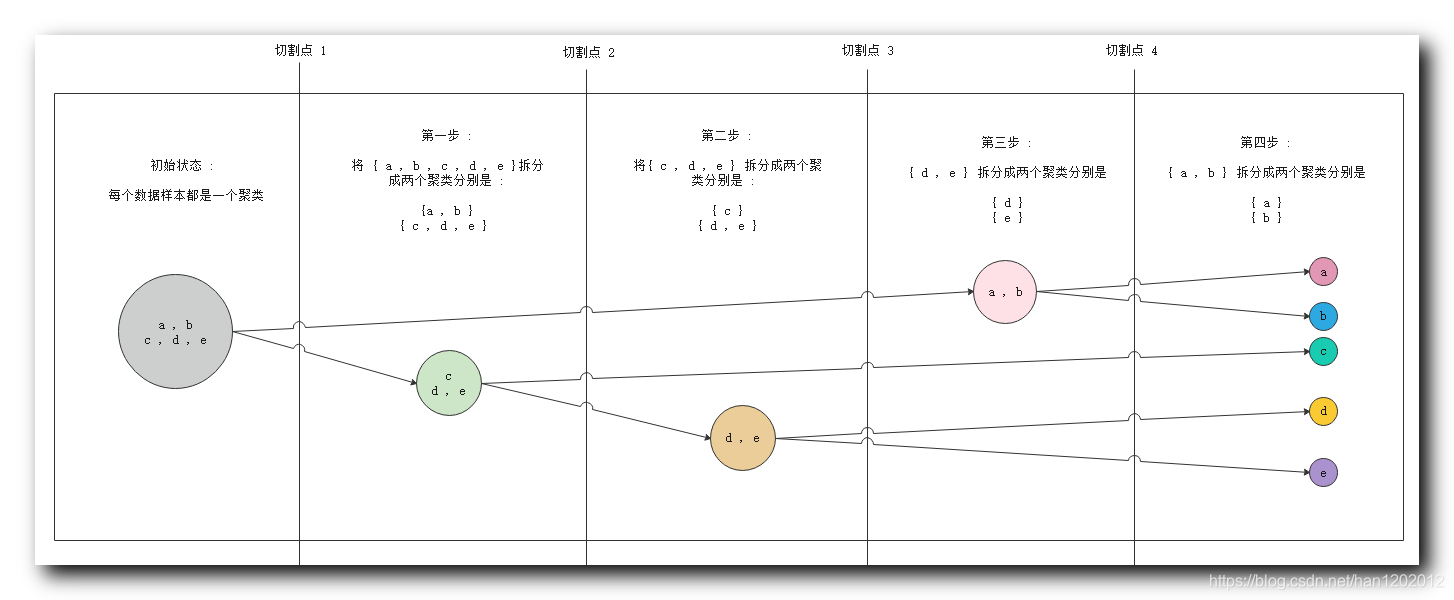
① 初始状态 : 最左侧 五个 数据对象 , 属于一个聚类 ;
② 第一步 : 分析相似度 , 切割聚类 , 将 { c , d , e } \{c,d, e\} {c,d,e} 与 { a , b } \{a ,b\} {a,b} 划分成两个聚类 ;
③ 第二步 : 分析相似度 , 将 { c , d , e } \{c,d, e\} {c,d,e} 中的 { c } \{c\} {c} 与 { d , e } \{d, e\} {d,e} 划分成两个聚类 ;
④ 第三步 : 分析相似度 , 将 { d , e } \{d, e\} {d,e} 拆分成 { d } \{d\} {d} 和 { e } \{e\} {e} 两个聚类 ;
⑤ 第四步 : 分析相似度 , 将 { a , b } \{a ,b\} {a,b} 拆分成 { a } \{a\} {a} 和 { b } \{b\} {b} 两个聚类 , 至此所有的数据对象都划分成了单独的聚类 ;
2 . 切割点说明 : 实际进行聚类分析时 , 不会将所有的步骤走完 , 这里提供四个切割点 , 聚类算法进行聚类时 , 可以在任何一个切割点停止 , 使用当前的聚类分组当做聚类结果 ;
① 切割点 1 1 1 : 在切割点 1 1 1 停止 , 会得到 1 1 1 个聚类分组 , { a , b , c , d , e } \{a, b ,c, d, e\} {a,b,c,d,e} ;
② 切割点 2 2 2 : 在切割点 2 2 2 停止 , 会得到 2 2 2 个聚类分组 ; { a , b } \{a, b\} {a,b} , { c , d , e } \{c, d, e\} {c,d,e} ;
③ 切割点 3 3 3 : 在切割点 3 3 3 停止 , 会得到 3 3 3 个聚类分组 , { a , b } \{a, b\} {a,b} , { c } \{c\} {c}, { d , e } \{d, e\} {d,e}$ ;
④ 切割点 4 4 4 : 在切割点 4 4 4 停止 , 会得到 4 4 4 个聚类分组 , { a , b } \{a, b\} {a,b} , { c } \{c\} {c}, { d } \{d\} {d} , { e } \{e\} {e} ;
⑤ 走完整个流程 : 会得到 5 5 5 个聚类分组 , { a } \{a\} {a} , { b } \{b\} {b}, { c } \{c\} {c}, { d } \{d\} {d} , { e } \{e\} {e} ;
VI . 基于层次的聚类方法 切割点选取
1 . 算法终止条件 ( 切割点 ) : 用户可以指定聚类操作的算法终止条件 , 即上面图示中的切割点 , 如 :
① 聚类的最低个数 : 聚合层次聚类中 , n n n 个样本 , 开始有 n n n 个聚类 , 逐步合并 , 聚类个数逐渐减少 , 当聚类个数达到最低值 m i n min min , 停止聚类算法 ;
② 聚类最高个数 : 划分层次聚类中 , n n n 个样本 , 开始有 1 1 1 个聚类 , 逐步划分 , 聚类个数逐渐增加 , 当聚类个数达到最大值 m a x max max , 停止聚类算法 ;
③ 聚类样本的最低半径 : 聚类的数据样本范围不能无限扩大 , 指定一个阈值 , 只有将该阈值内的样本放入一组 ; 半径指的是所有对象距离其平均点的距离 ;
2 . 切割点回退问题 : 切割点一旦确定 , 便无法回退 ; 这里以聚合层次聚类为例 :
① 处于切割点 4 4 4 : 如已经执行到了步骤三 , 此时处于切割点 4 4 4 , 聚类分组为 { a , b } \{a, b\} {a,b} , { c , d , e } \{c, d, e\} {c,d,e} ;
② 试图回退到 切割点 3 3 3 : 想要会回退到切割点 3 3 3 的状态 , 视图将聚类分组恢复成 { a , b } \{a, b\} {a,b} , { c } \{c\} {c}, { d , e } \{d, e\} {d,e} ;
③ 无法回退 : 该操作是无法实现的 , 聚类分组一旦 合并 或 分裂 , 此时就无法回退 ;
VII . 基于密度的方法
1 . 基于距离聚类的缺陷 : 很多的聚类方法 , 都是 基于样本对象之间的距离 ( 相似度 ) 进行的 , 这种方法对于任意形状的分组 , 就无法识别了 , 如下图左侧的聚类模式 ; 这种情况下可以使用基于密度的方法进行聚类操作 ;
基于距离的方法 , 是基于欧几里得距离函数得来 , 其基本的形状都是球状 , 或凸形状 , 如下图右侧的形状 ; 无法计算出凹形状 , 如下图左侧的形状 ;

2 . 基于密度的聚类方法 : 相邻的区域内 样本对象 的密度超过某个阈值 , 聚类算法就继续执行 , 如果周围区域密度都很小 , 那么停止聚类方法 ;
① 密度 : 某 单位大小 区域内的样本对象个数 ;
② 聚类分组要求 : 在聚类分组中 , 每个分组的数据样本密度都 必须达到密度要求的最低阈值 ;
3 . 基于密度的聚类方法 算法优点 :
① 排除干扰 : 过滤噪音数据 , 即密度很小 , 样本分布稀疏的数据 ;
② 增加聚类模式复杂度 : 聚类算法可以识别任意形状的分布模式 , 如上图左侧的聚类分组模式 ;
VIII . 基于方格的方法
1 . 基于方格的方法 : 将数据空间划分成 一个个方格 , 在这些方格数据结构上 , 将每个方格中的数据样本 , 当做一个数据处理 , 进行聚类操作 ;
2 . 基于方格的方法优点 : 处理速度很快 , 将每个方格都作为一个数据 , 如果分成 少数的几个方格进行聚类操作 , 聚类瞬间完成 ; 其速度与数据集样本个数无关 , 与划分的数据方格个数有关 ;
3 . 局限性 : 该方法的错误率很高 ;
IX . 基于模型的方法
基于模型的方法
① 基于统计的方法 : GMM 高斯混合模型 ;
② 神经网络方法 ;

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 9
9 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)