【Python 】深度学习 Transformer
写在前面: 本文个人笔记,可能存在错误理解,谅解!
写在前面: 本文个人笔记,可能存在错误理解,谅解!
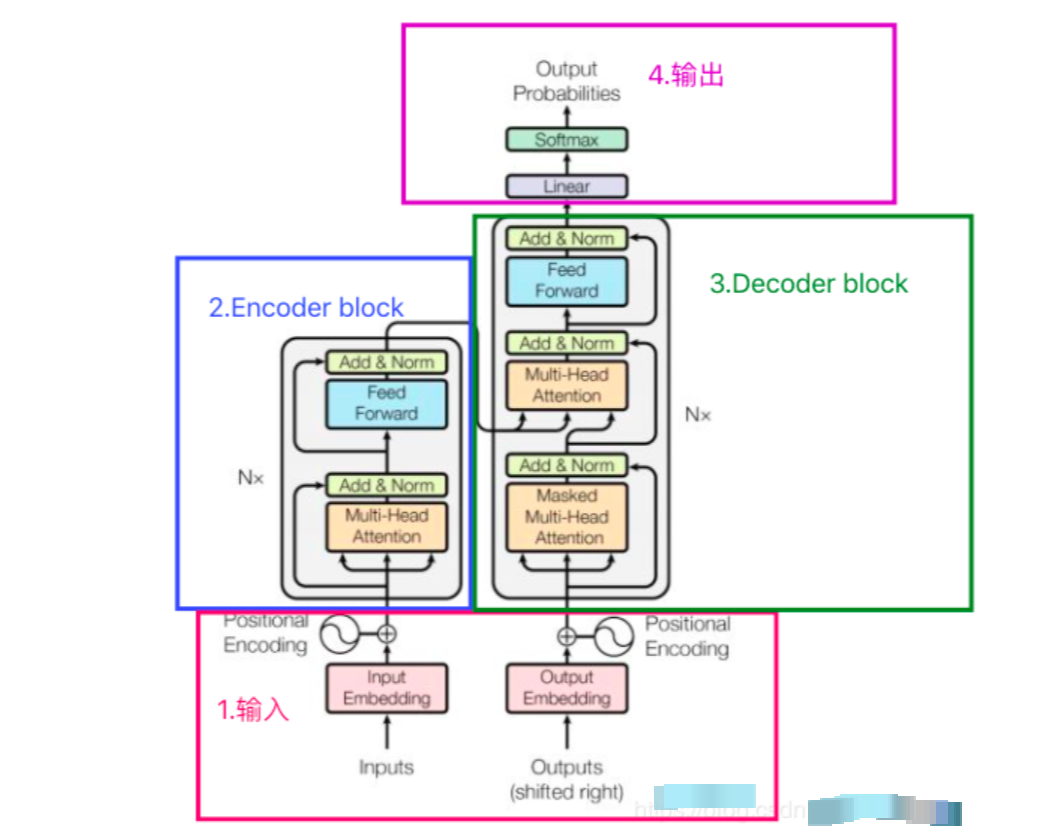
1. Transformer是什么
Transformer是一种用于自然语言处理(NLP)和其他序列到序列(sequence-to-sequence)任务的深度学习模型架构,它在2017年由Vaswani等人首次提出。Transformer架构引入了自注意力机制(self-attention mechanism),这是一个关键的创新,使其在处理序列数据时表现出色。
以下是Transformer的一些重要组成部分和特点:
- 自注意力机制(Self-Attention):这是Transformer的核心概念之一,它使模型能够同时考虑输入序列中的所有位置,而不是像循环神经网络(RNN)或卷积神经网络(CNN)一样逐步处理。自注意力机制允许模型根据输入序列中的不同部分来赋予不同的注意权重,从而更好地捕捉语义关系。
- 多头注意力(Multi-Head Attention):Transformer中的自注意力机制被扩展为多个注意力头,每个头可以学习不同的注意权重,以更好地捕捉不同类型的关系。多头注意力允许模型并行处理不同的信息子空间。
- 堆叠层(Stacked Layers):Transformer通常由多个相同的编码器和解码器层堆叠而成。这些堆叠的层有助于模型学习复杂的特征表示和语义。
- 位置编码(Positional Encoding):由于Transformer没有内置的序列位置信息,它需要额外的位置编码来表达输入序列中单词的位置顺序。
- 残差连接和层归一化(Residual Connections and Layer Normalization):这些技术有助于减轻训练过程中的梯度消失和爆炸问题,使模型更容易训练。
- 编码器和解码器:Transformer通常包括一个编码器用于处理输入序列和一个解码器用于生成输出序列,这使其适用于序列到序列的任务,如机器翻译。
Nx = 6,Encoder block由6个encoder堆叠而成,图中的一个框代表的是一个encoder的内部结构,一个Encoder是由Multi-Head Attention和全连接神经网络Feed Forward Network构成。如下图所示:
1.1自注意力机制
自注意力的作用:随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。在处理过程中,自注意力机制会将对所有相关单词的理解融入到我们正在处理的单词中。更具体的功能如下:
- 序列建模:自注意力可以用于序列数据(例如文本、时间序列、音频等)的建模。它可以捕捉序列中不同位置的依赖关系,从而更好地理解上下文。这对于机器翻译、文本生成、情感分析等任务非常有用。
- 并行计算:自注意力可以并行计算,这意味着可以有效地在现代硬件上进行加速。相比于RNN和CNN等序列模型,它更容易在GPU和TPU等硬件上进行高效的训练和推理。(因为在自注意力中可以并行的计算得分)
- 长距离依赖捕捉:传统的循环神经网络(RNN)在处理长序列时可能面临梯度消失或梯度爆炸的问题。自注意力可以更好地处理长距离依赖关系,因为它不需要按顺序处理输入序列。

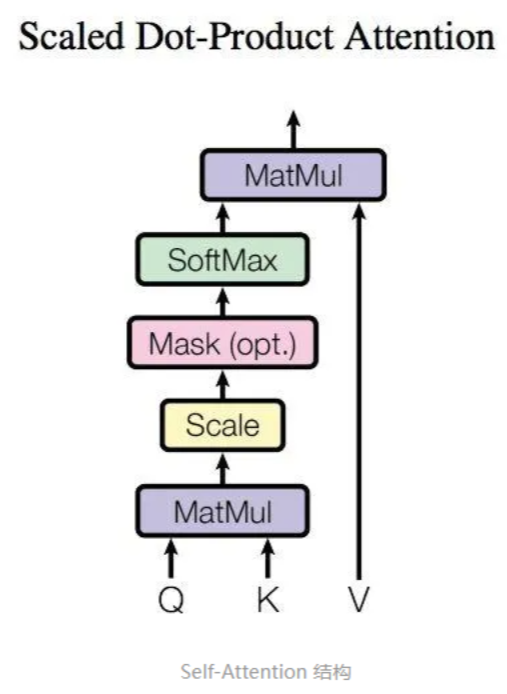
自注意力的计算:从每个编码器的输入向量(每个单词的词向量,即Embedding,可以是任意形式的词向量,比如说word2vec,GloVe,one-hot编码)
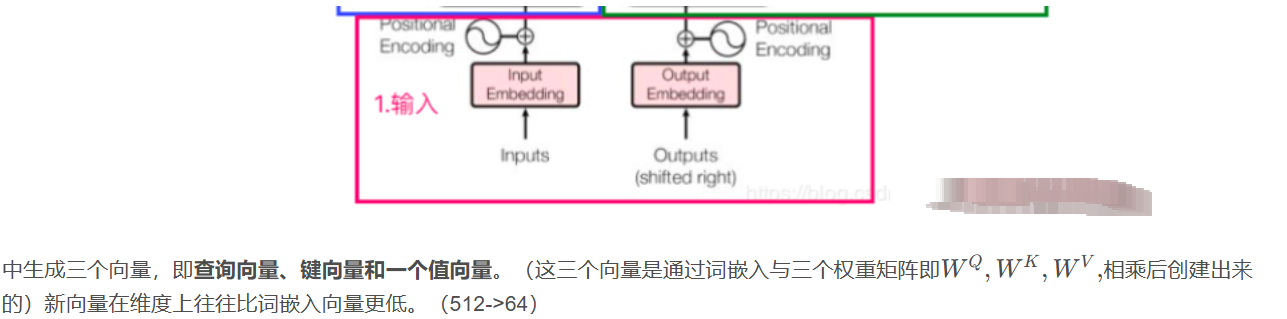
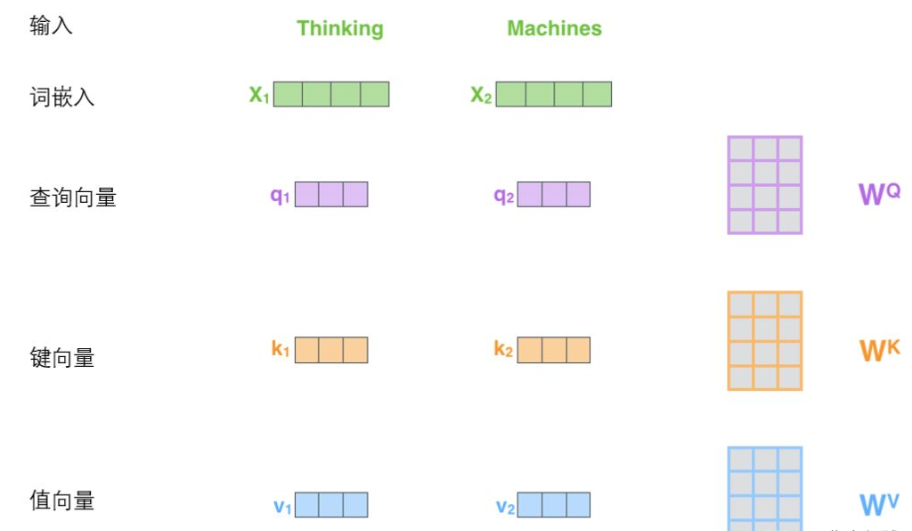
更一般的,将以上所得到的查询向量、键向量、值向量组合起来就可以得到三个向量矩阵Query、Keys、Values。
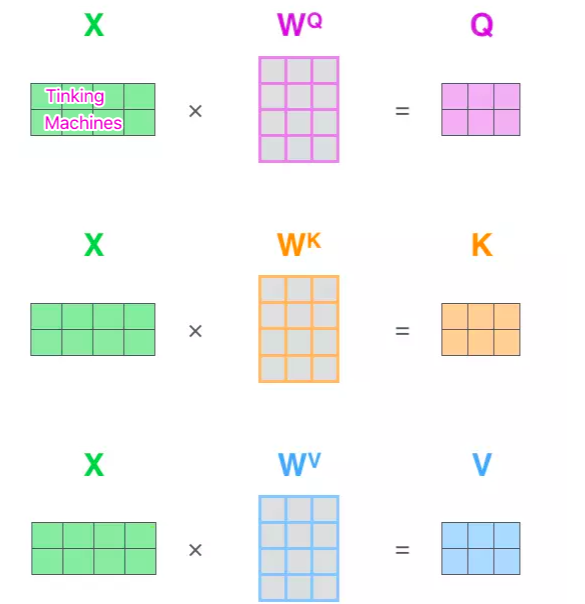
查询向量、键向量和值向量
计算自注意力的第二步是计算得分,假设我们在为这个例子中的第一个词“Thinking”计算自注意力向量,我们需要拿输入句子中的每个单词对“Thinking”打分。这些分数是通过所有输入句子的单词的键向量与“Thinking”的查询向量相点积来计算的。
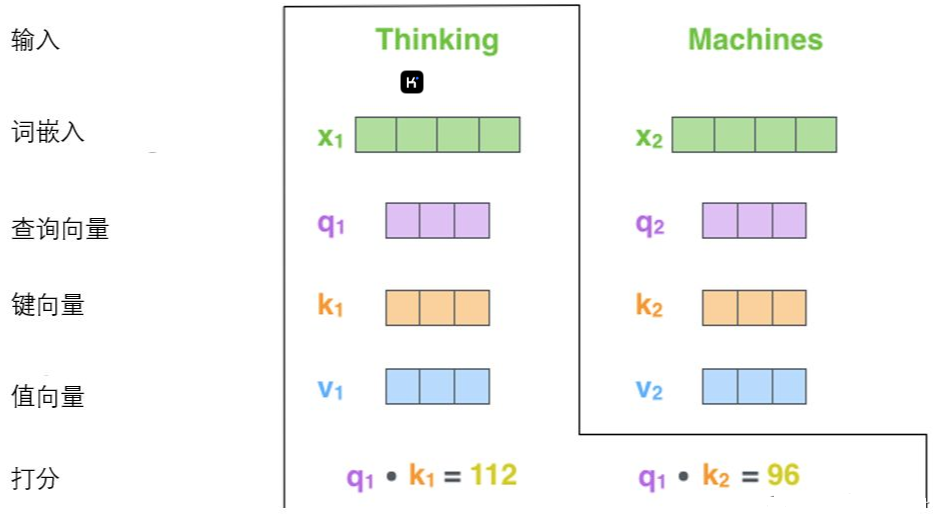
第三步和第四步是将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值,这样做是为了防止内积过大。),然后通过softmax传递结果。随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。
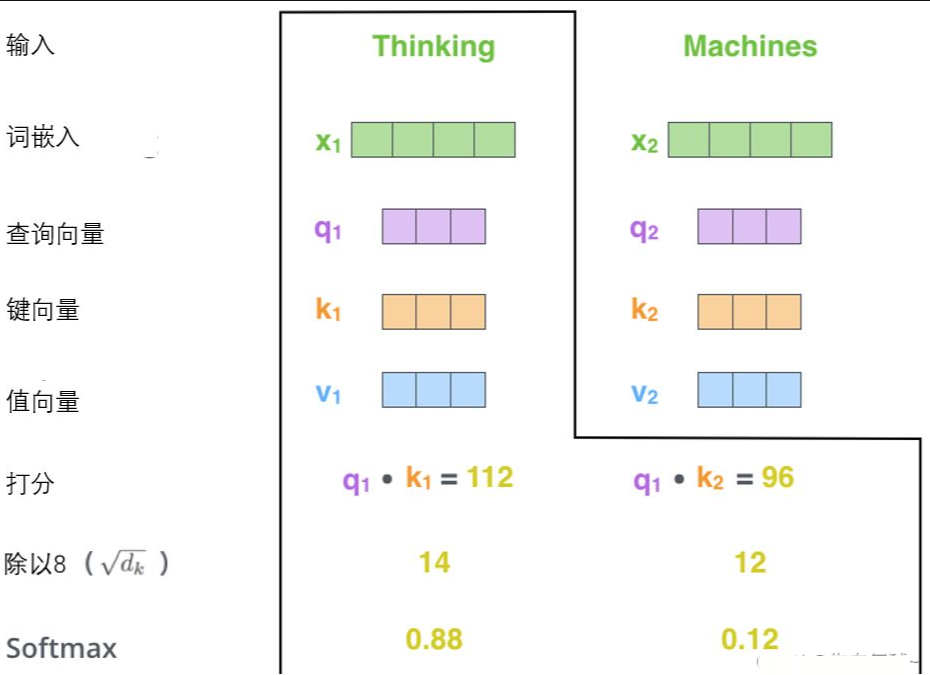
这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,
第五步是将每个值向量乘以softmax分数(这是为了准备之后将它们求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的小数)。
Softmax函数:或称归一化指数函数,它将每一个元素的范围都压缩到(0,1)之间,并且所有元素的和为1。
第六步是对加权值向量求和,然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词)
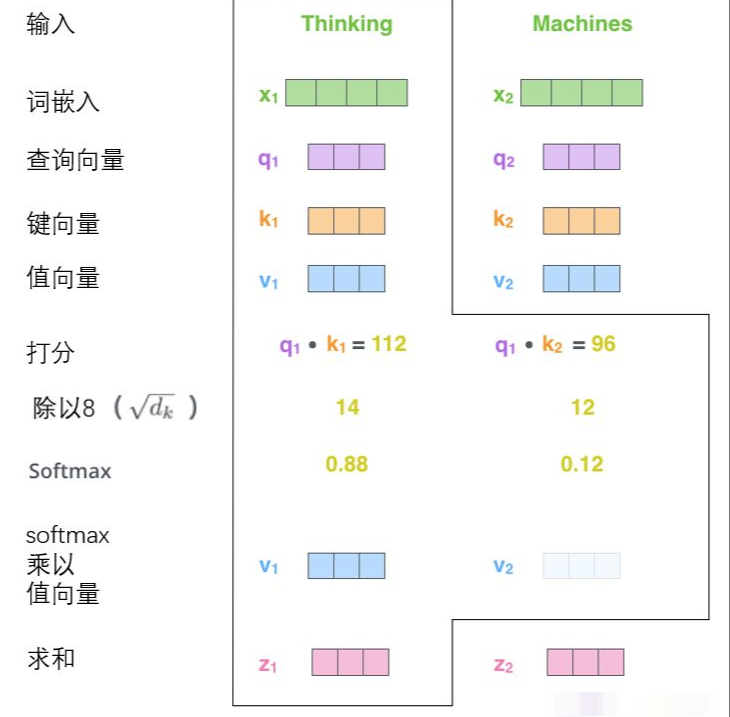
整体的计算图如图所示
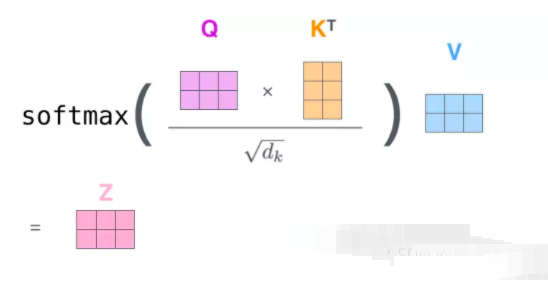
最终得到了自注意力,并将得到的向量传递给前馈神经网络。以上二到六步合为一个公式计算自注意力层的输出。
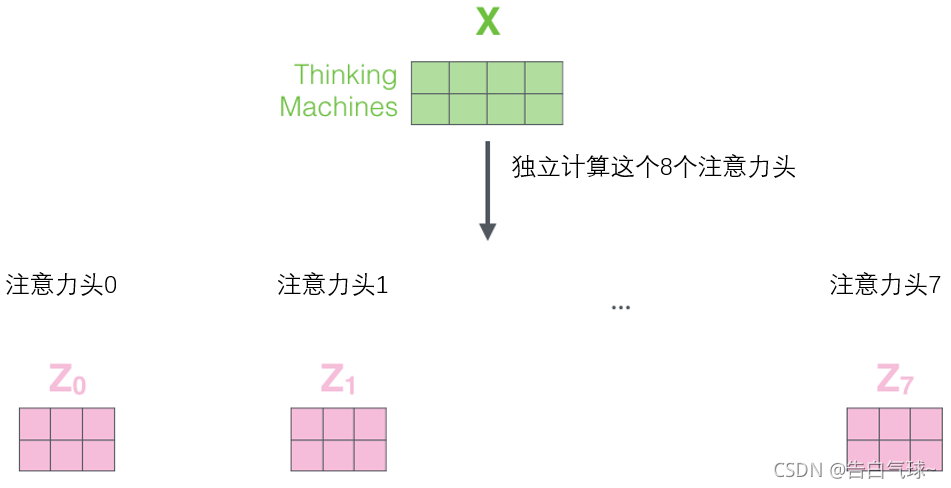
自注意力层的完善——“多头”注意力机制:
对应整体结构图中的Multi——Head Attention
1、扩展了模型专注于不同位置的能力。
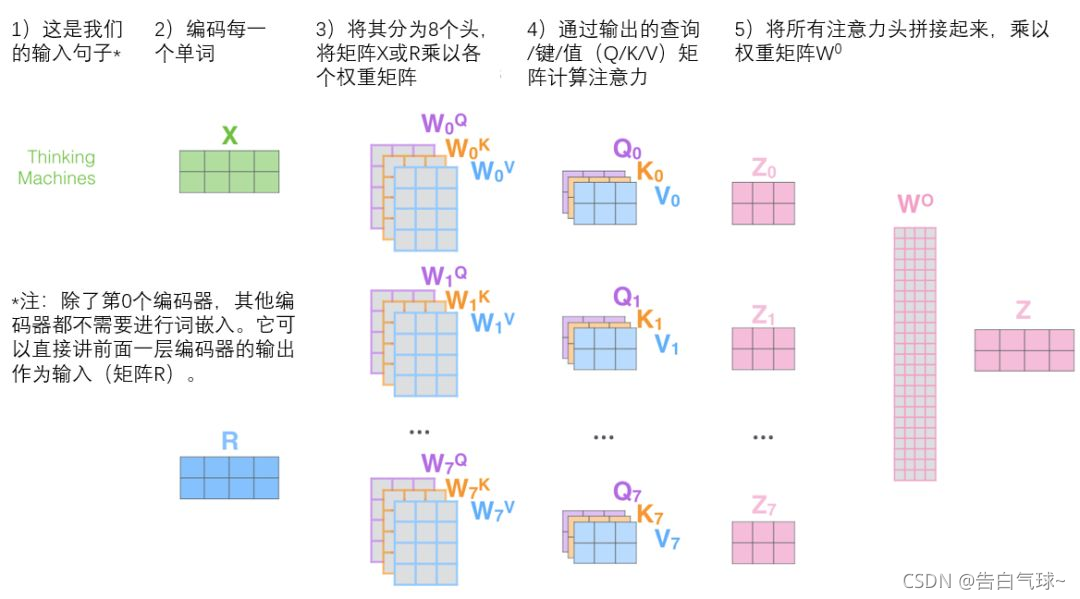
2、有多个查询/键/值权重矩阵集合,(Transformer使用八个注意力头)并且每一个都是随机初始化的。和上边一样,用矩阵X乘以WQ、WK、WV来产生查询、键、值矩阵。
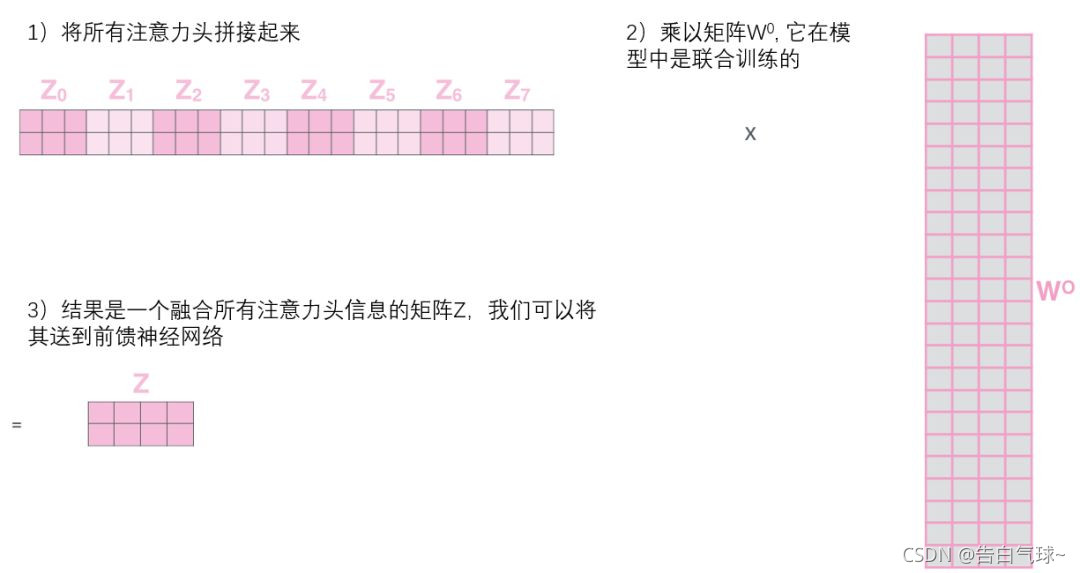
3、self-attention只是使用了一组WQ、WK、WV来进行变换得到查询、键、值矩阵,而Multi-Head Attention使用多组WQ,WK,WV得到多组查询、键、值矩阵,然后每组分别计算得到一个Z矩阵。
![]()
2.1self-attention 实现
流程
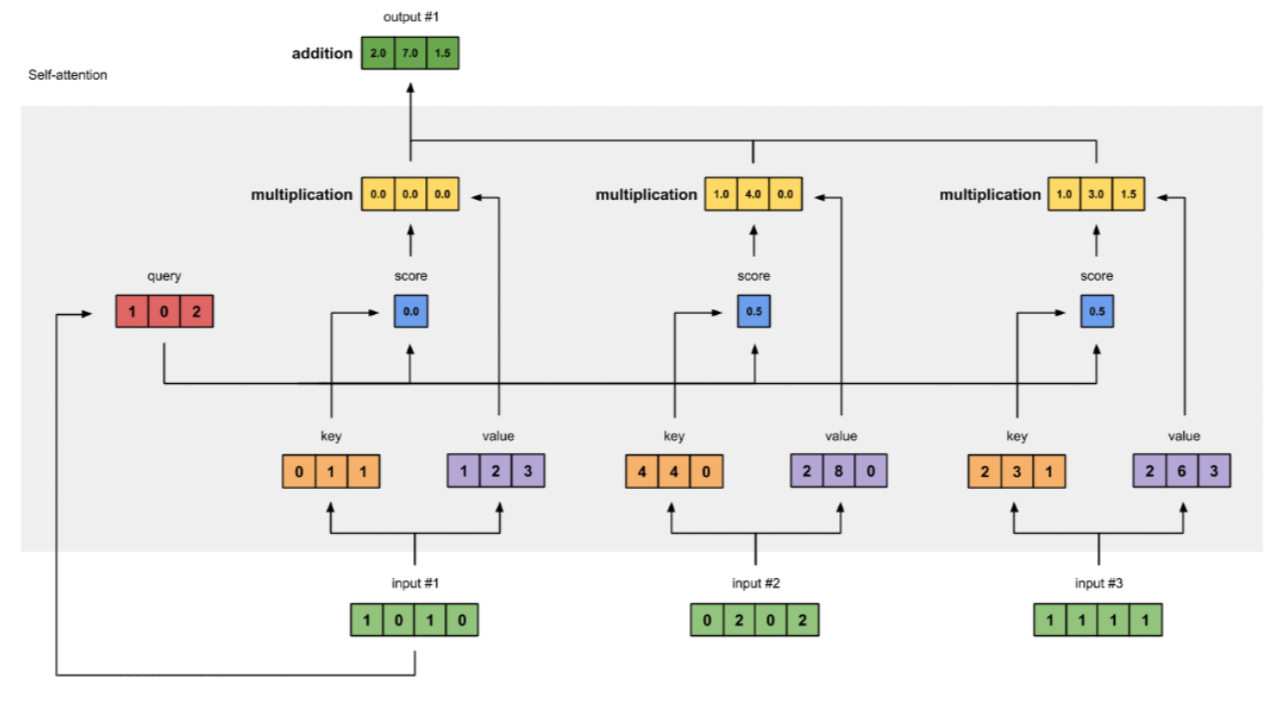
- 准备输入
- 初始化参数
- 获取key,query和value
- 给input1计算attention score
- 计算softmax
- 给value乘上score
- 给value加权求和获取output1
- 重复步骤4-7,获取output2,output3
- 流程图如下
import numpy as np
# 1. 构建输入 定义一个矩阵
x = [
[1, 0, 1, 0], # Input 1
[0, 2, 0, 2], # Input 2
[1, 1, 1, 1] # Input 3
]
x = np.array(x, dtype=np.float32)
print(f'🎃🎃1.....................\nInput\n: {x}')
# 2. 定义 Q K V 参数矩阵,用来编码获取q, k, v输入
w_key = [
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]
]
w_query = [
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]
]
w_value = [
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]
]
w_key = np.array(w_key, dtype=np.float32)
w_query = np.array(w_query, dtype=np.float32)
w_value = np.array(w_value, dtype=np.float32)
print("🎃🎃2.....................\nWeights for key: \n", w_key)
print("Weights for query: \n", w_query)
print("Weights for value: \n", w_value)
# 3. 获取key,query和value
keys = x @ w_key
querys = x @ w_query
values = x @ w_value
print("🎃🎃3.....................\nKeys: \n", keys)
print("Querys: \n", querys)
print("Values: \n", values)
# 4. 计算注意力分数
attn_scores = querys @ keys.T
print(f'🎃🎃4.....................attn_scores:\n{attn_scores}')
# 5. 计算softmax
def softmax(x, axis=-1):
# 防止数值溢出,先减去最大值
x_max = np.max(x, axis=axis, keepdims=True)
exp_x = np.exp(x - x_max)
return exp_x / np.sum(exp_x, axis=axis, keepdims=True)
attn_scores_softmax = softmax(attn_scores, axis=-1)
print(f'🎃🎃5.....................\nattn_scores_softmax:\n{attn_scores_softmax}')
# 为了使得后续方便,这里简略将计算后得到的分数赋予了一个新的值
# For readability, approximate the above as follows
attn_scores_softmax = [
[0.0, 0.5, 0.5],
[0.0, 1.0, 0.0],
[0.0, 0.9, 0.1]
]
attn_scores_softmax = np.array(attn_scores_softmax)
print(f'attn_scores_softmax reset:\n{attn_scores_softmax}') # 每一行代表一个元素 与另外三个元素之间的相似度
# 6、给value乘上score
values = np.ones_like(values) # 为了方便观察,将 values 都设为 1
print(f'🎃🎃 6.....................')
print(f'values:\n {values}')
print(f'attn_scores_softmax:\n {attn_scores_softmax}')
print(f'attn_scores_softmax.T:\n {attn_scores_softmax.T}')
weighted_values = attn_scores_softmax * values.T
print(f'values.shape: {values.shape}')
print(f'attn_scores_softmaxs.shape: {values.shape}')
print(f'weighted_values:\n {weighted_values}')
Tranform实现
import torch
import torch.nn as nn
import numpy as np
def get_len_mask(b: int, max_len: int, feat_lens: torch.Tensor, device: torch.device) -> torch.Tensor:
attn_mask = torch.ones((b, max_len, max_len), device=device)
for i in range(b):
attn_mask[i, :, :feat_lens[i]] = 0
return attn_mask.to(torch.bool)
def get_subsequent_mask(b: int, max_len: int, device: torch.device) -> torch.Tensor:
"""
Args:
b: batch-size.
max_len: the length of the whole seqeunce.
device: cuda or cpu.
"""
return torch.triu(torch.ones((b, max_len, max_len), device=device), diagonal=1).to(torch.bool) # or .to(torch.uint8)
def get_enc_dec_mask(
b: int, max_feat_len: int, feat_lens: torch.Tensor, max_label_len: int, device: torch.device) -> torch.Tensor:
attn_mask = torch.zeros((b, max_label_len, max_feat_len), device=device) # (b, seq_q, seq_k)
for i in range(b):
attn_mask[i, :, feat_lens[i]:] = 1
return attn_mask.to(torch.bool)
# 注意力机制完整代码
class MultiHeadAttention(nn.Module):
def __init__(self, d_k, d_v, d_model, num_heads, p=0.):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model # dimension of model
self.d_k = d_k # dimension of key
self.d_v = d_v # dimension of value
self.num_heads = num_heads # number of heads
self.dropout = nn.Dropout(p) # dropout
# linear projections,
self.W_Q = nn.Linear(d_model, d_k * num_heads) # linear projection for Q
self.W_K = nn.Linear(d_model, d_k * num_heads) # linear projection for K
self.W_V = nn.Linear(d_model, d_v * num_heads) # linear projection for V
self.W_out = nn.Linear(d_v * num_heads, d_model) # 多头合并
# Normalization initialization
# References: <<Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification>>
nn.init.normal_(self.W_Q.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.W_K.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.W_V.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
nn.init.normal_(self.W_out.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
def forward(self, Q, K, V, attn_mask, **kwargs):
N = Q.size(0) # batch size
q_len, k_len = Q.size(1), K.size(1) # query length, key length
d_k, d_v = self.d_k, self.d_v # dimension of key, value
num_heads = self.num_heads # head
# multi_head split
Q = self.W_Q(Q).view(N, -1, num_heads, d_k).transpose(1, 2)
K = self.W_K(K).view(N, -1, num_heads, d_k).transpose(1, 2)
V = self.W_V(V).view(N, -1, num_heads, d_v).transpose(1, 2)
# pre-process mask
if attn_mask is not None:
assert attn_mask.size() == (N, q_len, k_len)
attn_mask = attn_mask.unsqueeze(1).repeat(1, num_heads, 1, 1) # broadcast
attn_mask = attn_mask.bool()
# calculate attention weight
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
if attn_mask is not None:
scores.masked_fill_(attn_mask, -1e4)
attns = torch.softmax(scores, dim=-1) # attention weights
attns = self.dropout(attns)
# calculate output
output = torch.matmul(attns, V)
# multi_head merge
output = output.transpose(1, 2).contiguous().reshape(N, -1, d_v * num_heads)
output = self.W_out(output)
return output
# 逐位置前馈网络
class PoswiseFFN(nn.Module):
def __init__(self, d_model, d_ff, p=0.):
super(PoswiseFFN, self).__init__()
self.d_model = d_model
self.d_ff = d_ff
self.conv1 = nn.Conv1d(d_model, d_ff, 1, 1, 0)
self.conv2 = nn.Conv1d(d_ff, d_model, 1, 1, 0)
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=p)
def forward(self, X):
out = self.conv1(X.transpose(1, 2)) # (N, d_model, seq_len) -> (N, d_ff, seq_len)
out = self.relu(out)
out = self.conv2(out).transpose(1, 2) # (N, d_ff, seq_len) -> (N, d_model, seq_len)
out = self.dropout(out)
return out
# 位置编码
def pos_sinusoid_embedding(seq_len, d_model):
embeddings = torch.zeros((seq_len, d_model))
for i in range(d_model):
f = torch.sin if i % 2 == 0 else torch.cos
embeddings[:, i] = f(torch.arange(0, seq_len) / np.power(1e4, 2 * (i // 2) / d_model))
return embeddings.float()
class EncoderLayer(nn.Module):
def __init__(self, dim, n, dff, dropout_posffn, dropout_attn):
"""
Args:
dim: input dimension
n: number of attention heads
dff: dimention of PosFFN (Positional FeedForward)
dropout_posffn: dropout ratio of PosFFN
dropout_attn: dropout ratio of attention module
"""
assert dim % n == 0
hdim = dim // n # dimension of each attention head
super(EncoderLayer, self).__init__()
# LayerNorm
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
# MultiHeadAttention
self.multi_head_attn = MultiHeadAttention(hdim, hdim, dim, n, dropout_attn)
# Position-wise Feedforward Neural Network
self.poswise_ffn = PoswiseFFN(dim, dff, p=dropout_posffn)
def forward(self, enc_in, attn_mask):
# reserve original input for later residual connections
residual = enc_in
# MultiHeadAttention forward
context = self.multi_head_attn(enc_in, enc_in, enc_in, attn_mask)
# residual connection and norm
out = self.norm1(residual + context)
residual = out
# position-wise feedforward
out = self.poswise_ffn(out)
# residual connection and norm
out = self.norm2(residual + out)
return out
class DecoderLayer(nn.Module):
def __init__(self, dim, n, dff, dropout_posffn, dropout_attn):
"""
Args:
dim: input dimension
n: number of attention heads
dff: dimention of PosFFN (Positional FeedForward)
dropout_posffn: dropout ratio of PosFFN
dropout_attn: dropout ratio of attention module
"""
super(DecoderLayer, self).__init__()
assert dim % n == 0
hdim = dim // n
# LayerNorms
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.norm3 = nn.LayerNorm(dim)
# Position-wise Feed-Forward Networks
self.poswise_ffn = PoswiseFFN(dim, dff, p=dropout_posffn)
# MultiHeadAttention, both self-attention and encoder-decoder cross attention)
self.dec_attn = MultiHeadAttention(hdim, hdim, dim, n, dropout_attn)
self.enc_dec_attn = MultiHeadAttention(hdim, hdim, dim, n, dropout_attn)
def forward(self, dec_in, enc_out, dec_mask, dec_enc_mask, cache=None, freqs_cis=None):
# decoder's self-attention
residual = dec_in
context = self.dec_attn(dec_in, dec_in, dec_in, dec_mask)
dec_out = self.norm1(residual + context)
# encoder-decoder cross attention
residual = dec_out
context = self.enc_dec_attn(dec_out, enc_out, enc_out, dec_enc_mask)
dec_out = self.norm2(residual + context)
# position-wise feed-forward networks
residual = dec_out
out = self.poswise_ffn(dec_out)
dec_out = self.norm3(residual + out)
return dec_out
# 完整的encode
class Encoder(nn.Module):
def __init__(
self, dropout_emb, dropout_posffn, dropout_attn,
num_layers, enc_dim, num_heads, dff, tgt_len,
):
"""
Args:
dropout_emb: dropout ratio of Position Embeddings.
dropout_posffn: dropout ratio of PosFFN.
dropout_attn: dropout ratio of attention module.
num_layers: number of encoder layers
enc_dim: input dimension of encoder
num_heads: number of attention heads
dff: dimensionf of PosFFN
tgt_len: the maximum length of sequences
"""
super(Encoder, self).__init__()
# The maximum length of input sequence
self.tgt_len = tgt_len
self.pos_emb = nn.Embedding.from_pretrained(pos_sinusoid_embedding(tgt_len, enc_dim), freeze=True)
self.emb_dropout = nn.Dropout(dropout_emb)
self.layers = nn.ModuleList(
[EncoderLayer(enc_dim, num_heads, dff, dropout_posffn, dropout_attn) for _ in range(num_layers)]
)
def forward(self, X, X_lens, mask=None):
# add position embedding
batch_size, seq_len, d_model = X.shape
out = X + self.pos_emb(torch.arange(seq_len, device=X.device)) # (batch_size, seq_len, d_model)
out = self.emb_dropout(out)
# encoder layers
for layer in self.layers:
out = layer(out, mask)
return out
# 完整的decode
class Decoder(nn.Module):
def __init__(
self, dropout_emb, dropout_posffn, dropout_attn,
num_layers, dec_dim, num_heads, dff, tgt_len, tgt_vocab_size,
):
"""
Args:
dropout_emb: dropout ratio of Position Embeddings.
dropout_posffn: dropout ratio of PosFFN.
dropout_attn: dropout ratio of attention module.
num_layers: number of encoder layers
dec_dim: input dimension of decoder
num_heads: number of attention heads
dff: dimensionf of PosFFN
tgt_len: the target length to be embedded.
tgt_vocab_size: the target vocabulary size.
"""
super(Decoder, self).__init__()
# output embedding
self.tgt_emb = nn.Embedding(tgt_vocab_size, dec_dim)
self.dropout_emb = nn.Dropout(p=dropout_emb) # embedding dropout
# position embedding
self.pos_emb = nn.Embedding.from_pretrained(pos_sinusoid_embedding(tgt_len, dec_dim), freeze=True)
# decoder layers
self.layers = nn.ModuleList(
[
DecoderLayer(dec_dim, num_heads, dff, dropout_posffn, dropout_attn) for _ in
range(num_layers)
]
)
def forward(self, labels, enc_out, dec_mask, dec_enc_mask, cache=None):
# output embedding and position embedding
tgt_emb = self.tgt_emb(labels)
pos_emb = self.pos_emb(torch.arange(labels.size(1), device=labels.device))
dec_out = self.dropout_emb(tgt_emb + pos_emb)
# decoder layers
for layer in self.layers:
dec_out = layer(dec_out, enc_out, dec_mask, dec_enc_mask)
return dec_out
# 完整的transformer
class Transformer(nn.Module):
def __init__(
self, frontend: nn.Module, encoder: nn.Module, decoder: nn.Module,
dec_out_dim: int, vocab: int,
) -> None:
super().__init__()
self.frontend = frontend # feature extractor
self.encoder = encoder
self.decoder = decoder
self.linear = nn.Linear(dec_out_dim, vocab)
def forward(self, X: torch.Tensor, X_lens: torch.Tensor, labels: torch.Tensor):
X_lens, labels = X_lens.long(), labels.long()
b = X.size(0)
device = X.device
# frontend
out = self.frontend(X)
max_feat_len = out.size(1) # compute after frontend because of optional subsampling
max_label_len = labels.size(1)
# encoder
enc_mask = get_len_mask(b, max_feat_len, X_lens, device)
enc_out = self.encoder(out, X_lens, enc_mask)
# decoder
dec_mask = get_subsequent_mask(b, max_label_len, device)
dec_enc_mask = get_enc_dec_mask(b, max_feat_len, X_lens, max_label_len, device)
dec_out = self.decoder(labels, enc_out, dec_mask, dec_enc_mask)
logits = self.linear(dec_out)
return logits
# --------------------------------- 测试 ---------------------------------
def testMultiHeadAttention():
m = MultiHeadAttention(d_k=64, d_v=64, d_model=512, num_heads=8)
x = torch.randn(8, 100, 512)
out = m(x, x, x, None)
print(out.shape)
def testTransformer():
# constants
batch_size = 16 # batch size
max_feat_len = 100 # the maximum length of input sequence
max_label_len = 100 # the maximum length of output sequence
fbank_dim = 80 # the dimension of input feature
hidden_dim = 512 # the dimension of hidden layer
vocab_size = 26 # the size of vocabulary 输出词的个数
# dummy data
fbank_feature = torch.randn(batch_size, max_feat_len, fbank_dim) # input sequence
feat_lens = torch.randint(1, max_feat_len, (batch_size,)) # the length of each input sequence in the batch
labels = torch.randint(0, vocab_size, (batch_size, max_label_len)) # output sequence
label_lens = torch.randint(1, max_label_len, (batch_size,)) # the length of each output sequence in the batch
# model
feature_extractor = nn.Linear(fbank_dim, hidden_dim) # alinear layer to simulate the audio feature extractor
encoder = Encoder(
dropout_emb=0.1, dropout_posffn=0.1, dropout_attn=0.,
num_layers=6, enc_dim=hidden_dim, num_heads=8, dff=2048, tgt_len=2048
)
decoder = Decoder(
dropout_emb=0.1, dropout_posffn=0.1, dropout_attn=0.,
num_layers=6, dec_dim=hidden_dim, num_heads=8, dff=2048, tgt_len=2048, tgt_vocab_size=vocab_size
)
transformer = Transformer(feature_extractor, encoder, decoder, hidden_dim, vocab_size)
# forward check
logits = transformer(fbank_feature, feat_lens, labels)
print(f"logits: {logits.shape}") # (batch_size, max_label_len, vocab_size)
# output msg
# logits: torch.Size([16, 100, 26])
if __name__ == '__main__':
# testMultiHeadAttention()
testTransformer()参考

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 23
23 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)