带你从入门到精通——知识图谱(二. 实体抽取)
基于传统机器学习的方法通常是将实体抽取任务转化为序列标注任务,需要经过特征选择(需要人工进行特征选择)、模型选型、模型训练、模型预测四个步骤。隐马尔科夫模型(Hidden Markov Model, HMM)以及条件随机场(Conditional Random Field,CRF)。与基于规则和词典的方法相比基于传统机器学习的方法的可移植性更强,但仍然需要人工进行特征工程,成本较高。
建议先阅读我知识图谱专栏中的前置博客,掌握一定的知识图谱前置知识后再阅读本文,链接如下:
目录
二. 实体抽取
2.1 实体抽取概念
实体抽取即命名实体识别(named entity recognition,NER),指识别并分类文本中的具体实体名称,例如人名、地名、机构名、时间等等。
常用的实体抽取方法可以分为基于规则和词典的实体抽取方法、基于传统机器学习的实体抽取方法以及基于深度学习的实体抽取方法三大类。
2.2 基于规则和词典的实体抽取方法
基于规则和词典的方法主要由语言学专家手工构造规则模式(例如使用标点符号来判断实体的边界、使用指示词来如判断实体与其他词的依存关系等)和词典(通常是一些关键字,例如公司、大学等),并使用规则模式和词典对文本进行正则表达式的匹配完成实体抽取任务,示例如下:
import jieba.posseg as pseg
import re
# 词典
vocab = ['公司', '有限公司', '大学', '政府', '人民政府', '总局']
def NER(text):
# 对text进行分词,分词结果包含词和词性
word_pos = pseg.lcut(text)
words, ps, res = [], [], []
# 定义规则模式
for w, p in word_pos:
words.append(w)
if w in vocab:
ps.append('E') # E表示实体结尾
elif p in ['ns']: # ns表示地名
ps.append('B') # B表示实体开始
else:
ps.append('O') # O表示其他
labels = ''.join(ps)
pattern = re.compile(r'B+O*E+')
match = re.finditer(pattern, labels)
for m in match:
# <re.Match object; span=(8, 13), match='BOOOE'>
# <re.Match object; span=(16, 23), match='BOOOOOE'>
res.append(''.join(words[m.span()[0]: m.span()[1]]))
return res
if __name__ == '__main__':
text = "可在接到本决定书之日起六十日内向中国国家市场监督管理总局申请行政复议,杭州海康威视数字技术股份有限公司."
ans = NER(text)
print(ans)
# ['中国国家市场监督管理总局', '杭州海康威视数字技术股份有限公司']
基于规则和词典的实体抽取方法难以涵盖所有的语种,可移植性较差,此外,制作和维护成本太大。
2.3 基于传统机器学习的实体抽取方法
2.3.1 概述
基于传统机器学习的实体抽取方法通常是将实体抽取任务转化为序列标注任务,需要经过特征选择(需要人工进行特征选择)、模型选型、模型训练、模型预测四个步骤。
使用机器学习完成NER任务的常用模型为:隐马尔科夫模型(Hidden Markov Model, HMM)以及条件随机场(Conditional Random Field,CRF)。
与基于规则和词典的实体抽取方法相比基于传统机器学习的实体抽取方法的可移植性更强,但仍然需要人工进行特征工程,成本较高。
2.3.2 标注体系
常用的标注体系有三种,即IO标注体系、BIO标注体系以及BIOES标注体系,其中B即Begin,表示实体的开头,I即Inside,表示实体的内部,E即End,表示实体的结尾,O即Outside,表示非实体字符,S代表Single,表示一个字符即为一个实体。
示例如下,其中PER表示人名、LOC表示地名:
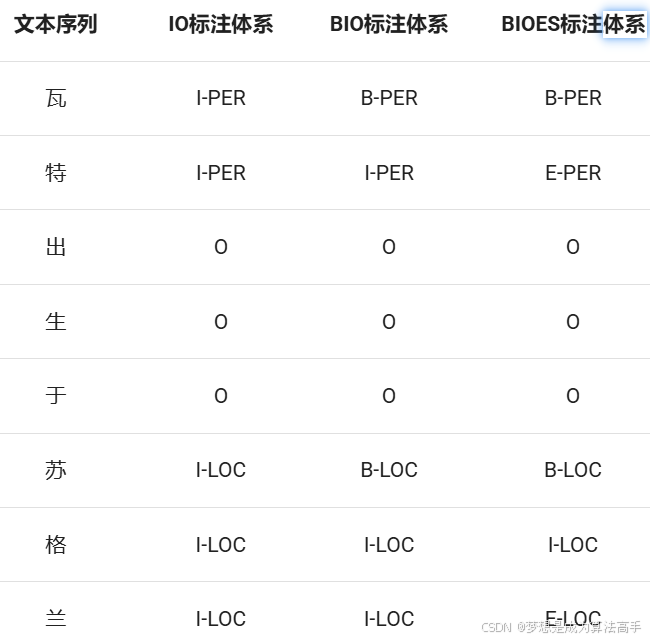
IO标注体系中只需要区分实体内部I和非实体O,规则简单,标注的复杂度较低,但是无法标记实体的开头和结尾,NER的精度有限。
BIO标注体系在IO标注体系的基础上引入了B标签用于标记实体的开头,是最常用的标注体系,平衡了标注的复杂度和NRE的精度。
BIOES标注体系在BIO标注体系的基础上引入了E标记用于标记实体的结尾、S标签用于标记以单个字符构成的实体,标注的复杂度较高,同时NER的精度也是最高的
2.3.3 马尔可夫链
马尔可夫链(Markov Chain,MC)是满足马尔可夫性的一种概率有向图(也称贝叶斯网络)模型,这里的马尔可夫性是指当前时刻 t 的状态只与 t - 1 时刻的状态有关,而与更早的状态无关,系统中各个状态的转移概率构成一个状态转移矩阵(简称转移矩阵),该矩阵即为马尔可夫链的参数。
马尔可夫链对状态进行建模,系统中的各个状态之间的构成一张状态转移图,也称状态机,状态转移图中节点表示系统中的各种状态,边表现各个状态之间的转移概率。
以天气为状态的马尔可夫链如下:
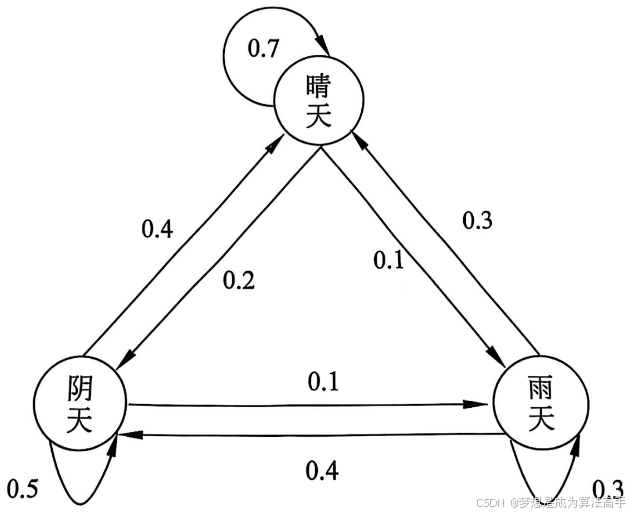
注意:在马尔可夫链中,状态通常是有限个且系统在一个时刻只能处于一个状态。
在满足遍历性的马尔可夫链中,各个状态的概率分布在长期演化后会趋于一个与初始概率分布无关的、稳定的分布,此时的概率分布也被称为稳态分布,通常使用稳态分布作为马尔可夫链的初始概率分布。
遍历性包含三点:首先是马尔可夫链中的各个状态两两连通;其次是满足常返性,即从一个状态出发后能够再次返回该状态;最后是满足非周期性,即从一个状态出发后能够再次返回该状态时所经过的边数集合的最小公倍数小于2。
2.3.4 隐马尔可夫模型
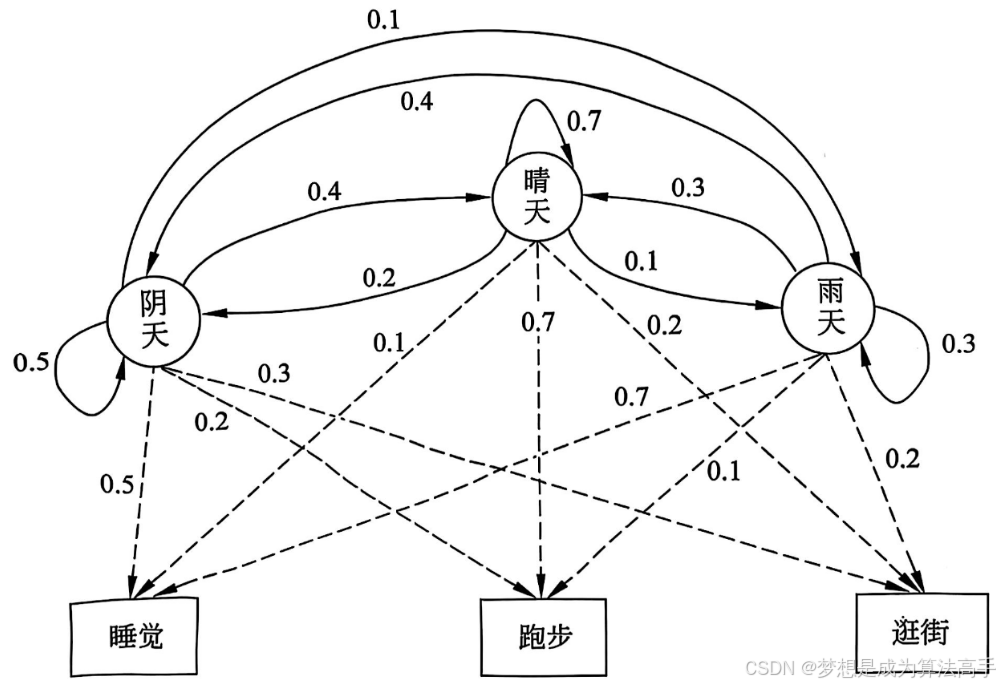
由于在某些情况中,状态往往是隐含的,我们只能得到一系列的观测值,因此作为对马尔可夫链的一种扩展,提出了隐马尔可夫模型(Hidden Markov Model,HMM),隐马尔可夫模型不仅对状态进行建模,还对观测进行建模,即对状态 - 观测的联合概率分布𝑃(𝑌, 𝑋)进行建模,是一种生成式模型。
隐马尔可夫模型在满足马尔可夫性的基础上还需要满足观测独立性,即当前时刻的观测只与当前时刻的状态有关,因此隐马尔可夫模型的参数除了有状态转移矩阵之外,还有一个观测矩阵(也称发射矩阵),即在某一确定的状态下,出现某一观测的条件概率分布。
以天气为状态,以人的活动为观测的隐马尔可夫模型如下:
2.3.5 条件随机场
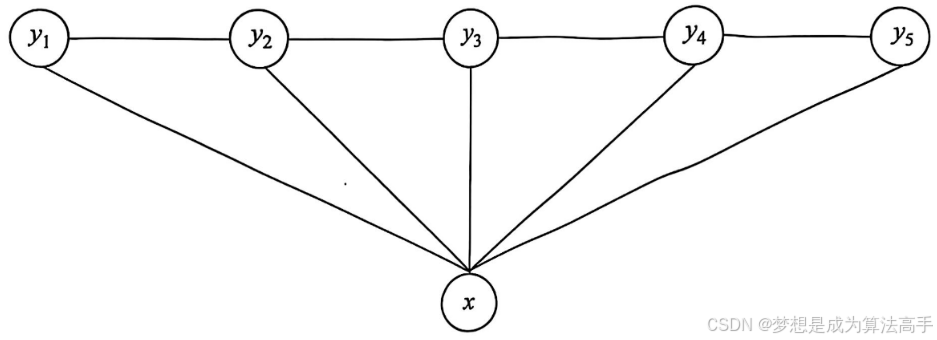
如果在给定观测X的条件下,状态Y是一个马尔可夫随机场,则称条件概率分布𝑃(𝑌|𝑋)构成条件随机场(Conditional Random Field,CRF),马尔可夫随机场是指满足马尔科夫性的概率无向图模型,这里的马尔科夫性是指满足图中某一节点的状态只与和该节点相连的节点的状态有关。
注意:条件随机场直接对条件概率分布𝑃(𝑌|𝑋)建模,是一种判别式模型,并且没有HMM中的观测独立性的限制。
条件随机场中参数与马尔可夫链相似,有一个关于状态Y的状态转移矩阵,但是矩阵中的元素是未归一化的逻辑值。
如果条件随机场中的观测X和状态Y都是一个一维的链式结构,即都为一个一维的随机变量序列,这样的条件随机场被称为线性链条件随机场(Linear Chain Conditional Random Field,LCCRF),图示如下:
2.4 基于深度学习的实体抽取方法
基于深度学习的实体抽取方法主要是使用神经网络结合条件随机场来完成实体抽取任务,其中BiLSTM-CRF是目前最为常用的深度学习模型。
基于深度学习的实体抽取方法,不需要进行复杂的特征工程即可得到较高的准确率和召回率,但是较为依赖人工标注的数据集。
此外,现阶段的实体抽取方法中,通常每个字符只能属于某一类标签,对于有标签重叠问题(即每个字符可能具有两种及以上的标签)的多标签实体抽取是所有实体抽取方法都需要考虑和解决的问题。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)