【数据结构——树和二叉树】
二叉树的深搜广搜
引入
树是一种非线性数据结构,用于模拟具有层次关系的数据。与线性结构(如数组、链表)不同,树通过父子关系组织数据,适合表达层级、分类、依赖等场景。
声明
通常树的层数是从底部开始往上标(1、2、3……),但这里为方便文章后面有关遍历次序的描述就先从上往下标。
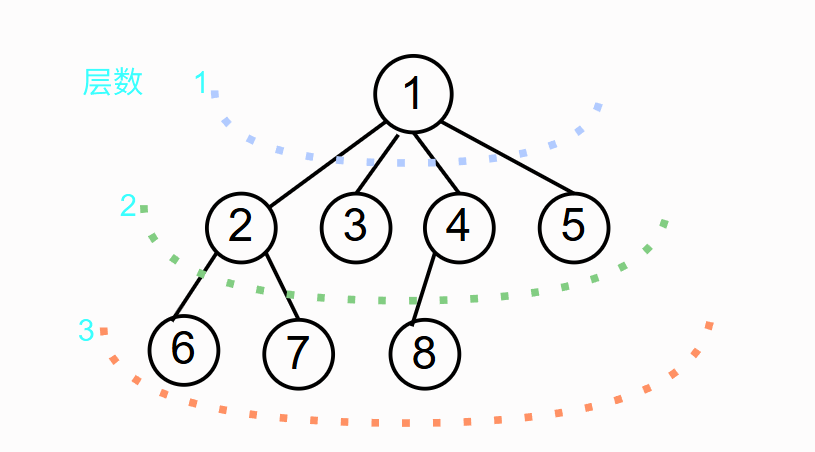
树的重要特性
1.度(degree)
树的度指树中节点的最大子节点数量。
对于树结构中任意一个节点,其子节点的个数称为该节点的度。
简单来说就是一个节点分多少叉,称该节点的度为多少。而树的度就是节点度的最大值如上图:
1的度为4(有4个子节点),4的度为1(只有一个子节点),2的度为2(有两个子节点)。而3、5、6、7、8这些节点的度都为0,被称为叶子节点。
总的来看此树中的节点度最大值为4,则该树的度为4。
2.高度(深度)
树的高度是指从根节点到最远叶子节点的最长路径上的节点数或边数。
简单来说就是分了几层,比如上图中节点分为3层,则该树的高度为3。
3.亲缘关系
亲缘关系有许多种,在树中的使用类似于高中生物在遗传病概率的推导部分的遗传系谱图,当然也是常识。
比如上图中显示的1是2、3、4、5的父亲节点(双亲结点),2、3、4、5之间互称为兄弟节点,6、7是2的子结点,而对于6、7来说,3、4、5是它们的叔叔节点,1是8的祖先。
树的存储方式
1.双亲表示法(适用于找父亲)
R为树的根,无双亲结点。A、B、C的双亲结点是下标为0的R, D、E的双亲结点为下标为1的A,以此类比其他节点。(下标顺序:从上到下、从左到右依次递增)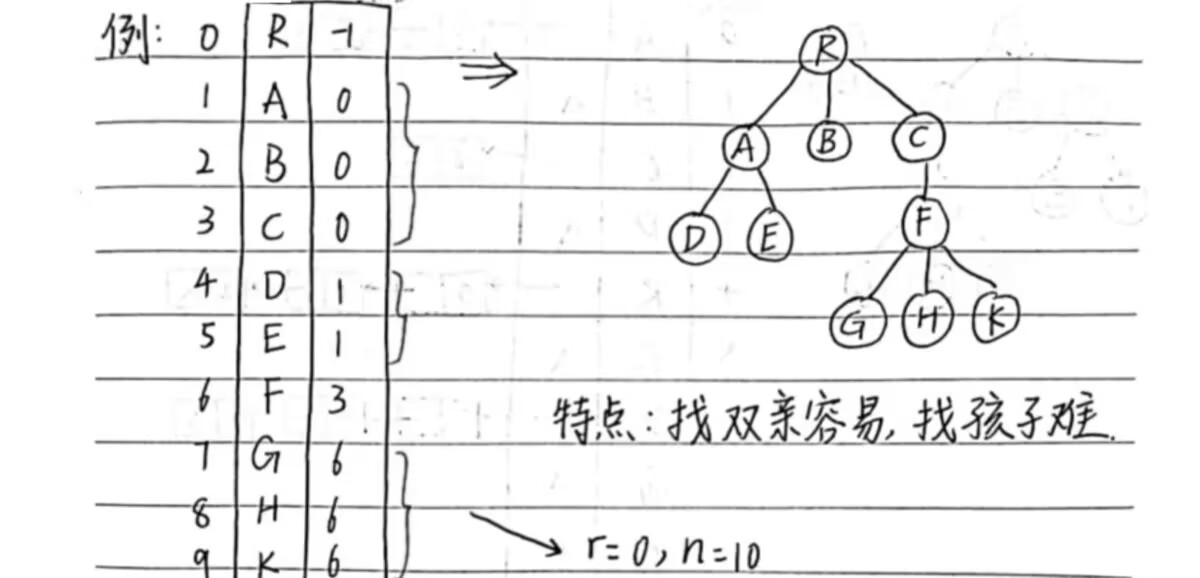
2.孩子表示法(顺序表加链表)
r:树的高度(深度)
n:节点个数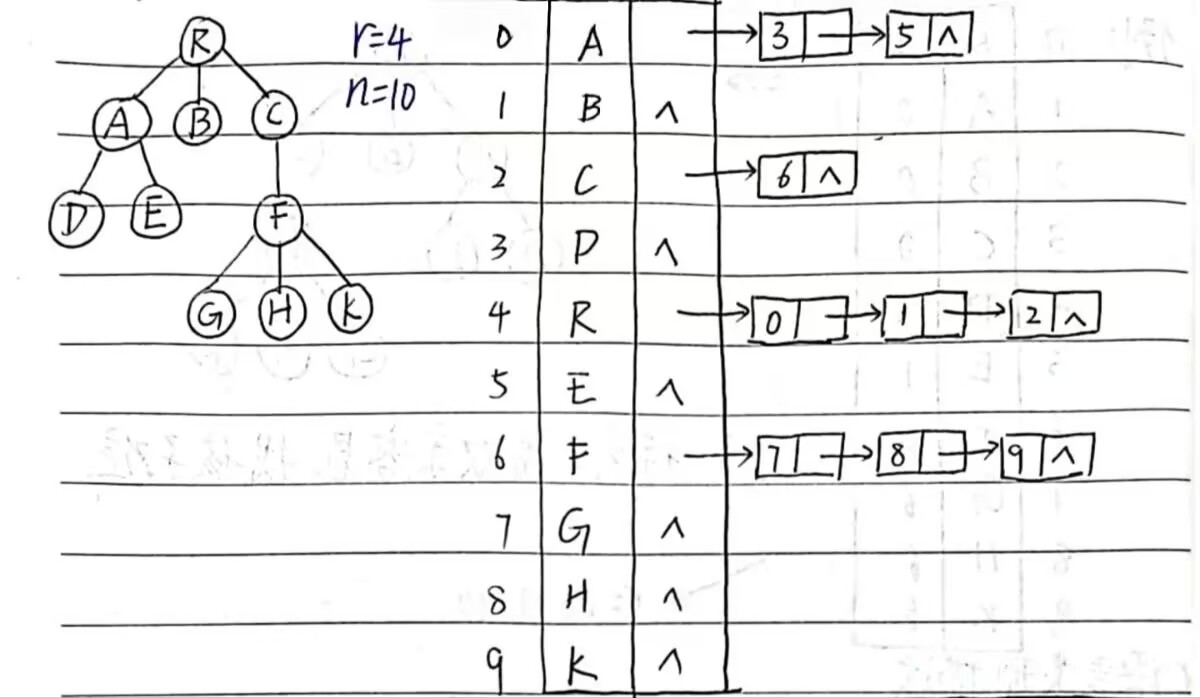
3.孩子兄弟表示法(孩子指针域加数据域加兄弟指针域)
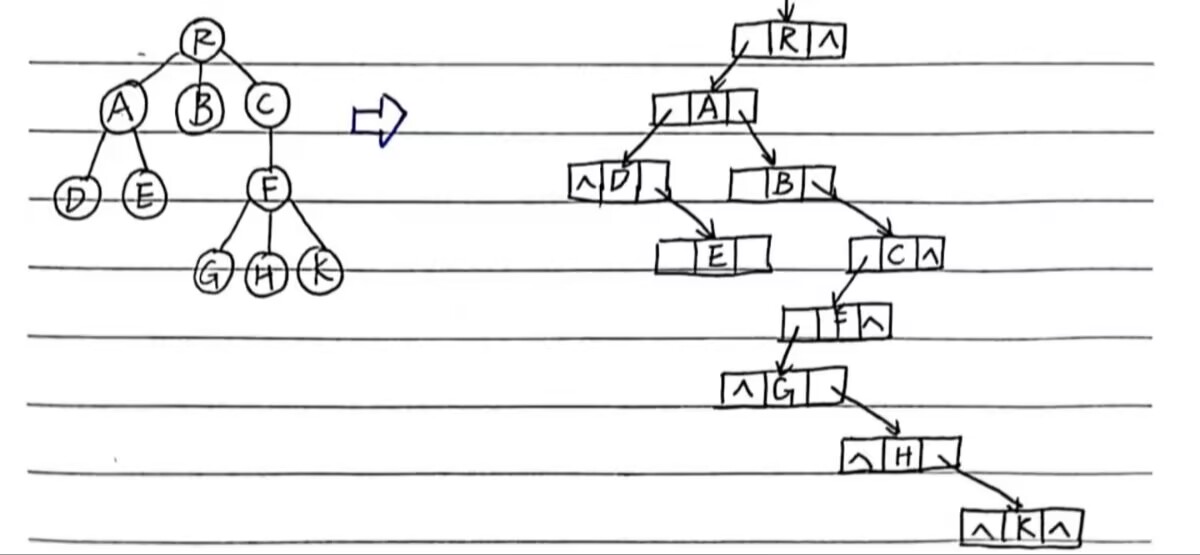
二叉树
每个节点最多有两个子节点的树结构,二叉树可以是空集。
存储顺序:从上到下,从左到右。
n0:度为0的点的个数,n1:度为1的点的个数
棒子数:除第一个节点,其他节点头上都有一个棒子,所以要加1(计数时算上第一个节点)
各节点数之和=n0+n1+n2=棒子数+1
棒子数=n1+2*n2(度为2的节点能引出两个棒子所以对应的节点个数要乘2,度为0的没有棒子、直接省略)
则该等式为n0+n1+n2=n1+2n2+1;
化简得n0=n2+1;
遍历可分为两种:广度遍历和深度遍历,以下是大致思路。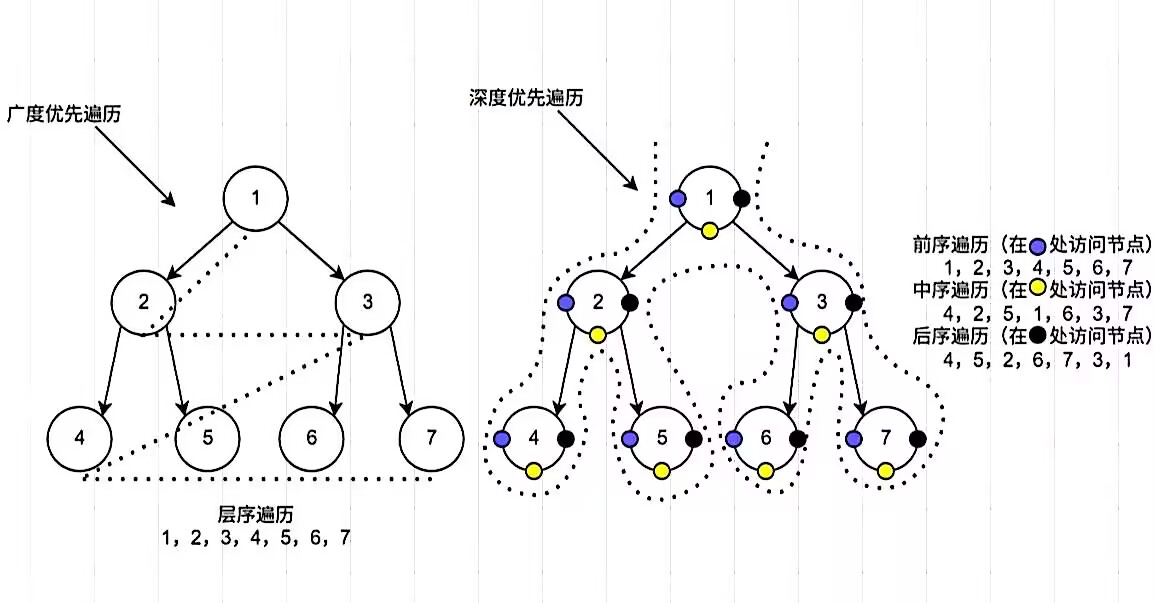
广度遍历
从根节点(或任意节点)开始,逐层探索所有邻近节点,再依次探索这些邻近节点的邻近节点,直到找到目标或遍历完整个结构。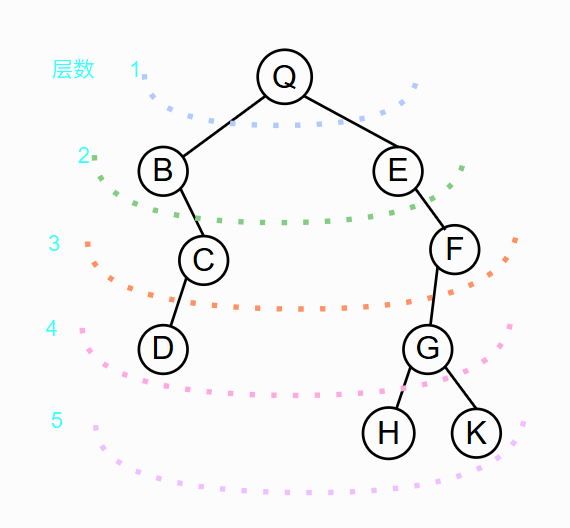
使用队列进行缓存操作:
出队后获得一个新任务,处理新任务,有左入左,有右入右,都有则先左后右。
逐层来看,第一层只有一个Q节点,先入Q,出Q再从左往右入第二层(B、E),入完之后在出第二层,再从左往右分别入第二层的每个节点在第三层的子节点(逐个往右走)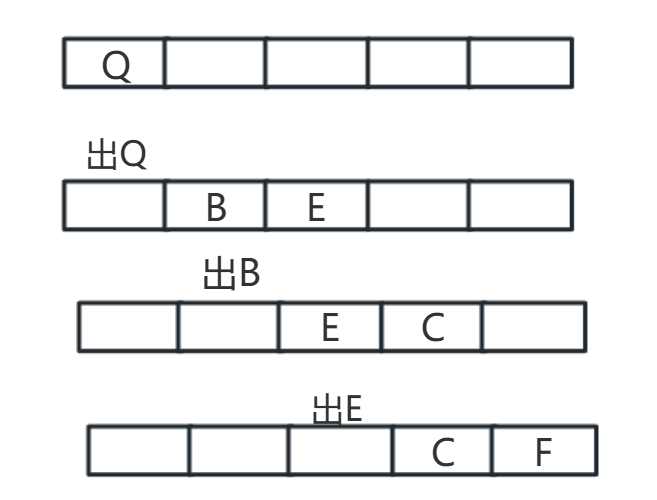
代码部分
头文件
typedef int Element;
typedef struct _tree_node{
Element data;
struct _tree_node* left;
struct _tree_node* right;
}TreeNode;
typedef struct {
TreeNode* root;
int count;
}BinaryTree;
BinaryTree* createBinaryTree(TreeNode* node);
void releaseBinaryTree(BinaryTree* tree);
TreeNode* createTreeNode(Element e);
void insertBinaryTree(BinaryTree* tree, TreeNode* parent, TreeNode* left, TreeNode* right);
void visitTreeNode(const TreeNode* node);
void preOrderBTree(const BinaryTree* tree);
void inOrderBTree(const BinaryTree* tree);
void postOrderBTree(const BinaryTree* tree);
void levelOrderBTree(const BinaryTree* tree);
void preOrderBtreeNoRecursion(const BinaryTree* tree);
void inorderBtreeNoRecursion(const BinaryTree* tree);
功能实现
/*广度遍历
* 1.引入一个任务队列,先把根节点入队
* 2. 从任务队列中,取出一个节点,处理(访问)
* 3. 如果第2步的节点有左节点,那么就入队,有右那么右就入队(加到后面)
* 4. 重复第2步
*/
void levelOrderBTree(const BinaryTree* tree) {
//申请一个任务队列,用顺序存储,循环队列,队列里每个元素是节点的地址
#define MaxQueueSize 8
TreeNode* queue[MaxQueueSize];
int front, rear;
// 初始化
front = rear = 0;
queue[rear] = tree->root;
rear = (rear + 1) % MaxQueueSize;
// 循环处理事务
while (rear != front) {
TreeNode* node = queue[front];
front = (front + 1) % MaxQueueSize;
visitTreeNode(node);
if (node->left) {
queue[rear] = node->left;
rear = (rear + 1) % MaxQueueSize;
}
if (node->right) {
queue[rear] = node->right;
rear = (rear + 1) % MaxQueueSize;
}
}
}
此处思路可以上图为参考,这里为方便查看再放一次:
深度遍历
一种沿着树的深度方向尽可能深入地访问节点的策略。对于二叉树,DFS通常分为三种具体形式:前序遍历、中序遍历和后序遍历,每种遍历方式决定了节点访问的顺序。
深度遍历可以理解为顺着一条路走到底,左、右子节点都有时走左边。
如广度遍历标题下的图,深度遍历顺序为QBBCDDDCCBQEEFGHHHGKKKGFFEQ.
从上往下走时按从左往右的顺序往下走,若左为空再回来走右边。
从下往上走时若此时的落点为右节点,则不用看左节点,直接往上走。若为左节点,返回根结点后再访问右节点。
每个节点访问三次,选择其中以此作为触发时机:
- 先序遍历(可确定根节点:第一个)
访问顺序为:根节点 → 左子树 → 右子树。
例图的先序遍历为:QBCDEFGHK - 中序遍历(确定左右:以根为界,划分左右)
访问顺序为:左子树 → 根节点 → 右子树。
例图的中序遍历为:BDCQEHGKF - 后续遍历(确定根节点:最后一个)
访问顺序为:左子树 → 右子树 → 根节点。
例图的后序遍历为:DCBHKGFEQ
仅知道先序和后续遍历的结果不能得出二叉树的结构。
代码部分
功能实现
//深度遍历
BinaryTree* createBinaryTree(TreeNode* root) {
BinaryTree* tree = (BinaryTree*)malloc(sizeof(BinaryTree));
if (tree == NULL) {
fprintf(stderr, "tree malloc failed!\n");
return NULL;
}
if (root) {
tree->root = root;
tree->count = 1;
}
else {
tree->root = NULL;
tree->count = 0;
}
return tree;
}
TreeNode* creatTreeNode(Element e) {
TreeNode* node = (TreeNode*)malloc(sizeof(TreeNode));
node->data = e;
node->left = node->right = NULL;
return node;
}
void insertBinaryTree(BinaryTree* tree, TreeNode* parent, TreeNode* left, TreeNode* right) {
if (tree && parent) {
parent->left = left;
parent->right = right;
if (left) {
tree->count++;
}
if (right) {
tree->count++;
}
}
}
void visitTreeNode(const TreeNode* node) {
if (node)
printf("\t%c", node->data);
}
//先序、中序、后序遍历
static void preOrderNode(const TreeNode* node) {
if (node) {
visitTreeNode(node);
preOrderNode(node->left);
preOrderNode(node->right);
}
}
static void inOrderNode(const TreeNode* node) {
if (node) {
inOrderNode(node->left);
inOrderNode(node);
inOrderNode(node->right);
}
}
static void postOrderNode(const TreeNode* node) {
if (node) {
postOrderNode(node->left);
postOrderNode(node->right);
postOrderNode(node);
}
}
//递归实现
void preOrderBTree(const BinaryTree* tree) {
preOrderNode(tree->root);
printf("\n");
}
void inOrderBTree(const BinaryTree* tree) {
inOrderNode(tree->root);
printf("\n");
}
void postOrderBTree(const BinaryTree* tree) {
postOrderNode(tree->root);
printf("\n");
}
非递归实现先序遍历,基本思路:
- 先序的结果是当前节点、再左节点、最后右节点。把栈当做任务的暂存空间,
先压右节点,再压左节点,一旦弹栈,出现的是左节点。 - 基本步骤:
- 初始化部分
将根节点压栈 - 循环处理任务部分
弹栈,访问弹出来的节点,判断节点有右先压右,有左再压左,保证先右后左
循环出栈,直到栈内无元素
void preOrderBtreeNoRecursion(const BinaryTree* tree) {
ArrayStack stack;
initArrayStack(&stack);
pushArrayStack(&stack, tree->root);
TreeNode *node;
while (!isEmptyArrayStack(&stack)) {
node = getTopArrayStack(&stack);
popArrayStack(&stack);
visitTreeNode(node);
if (node->right) {
pushArrayStack(&stack, node->right);
}
if (node->left) {
pushArrayStack(&stack, node->left);
}
}
}
```c
以根节点开始,整条左边进栈,从栈中弹出节点,开始访问
如果这个节点有右孩子,把右孩子当做新节点,再次整条边进栈,再弹栈
ArrayStack stack;
initArrayStack(&stack);
// pushArrayStack(&stack, tree->root);
TreeNode *node = tree->root;
while (!isEmptyArrayStack(&stack) || node) {
if (node) {
pushArrayStack(&stack, node);
node = node->left;
} else {
node = getTopArrayStack(&stack);
popArrayStack(&stack);
visitTreeNode(node);
node =node->right;
}
}
}
overover!下篇见喽~

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)