datastage mysql wire,Datastage 配置Odbc 连接Hive (内含实现作业)
版本:IBM InfoSphere DataStage V11.5.1操作系统:linux redhat 6.4平台:Apache Hadoop 2.6.0-cdh5.9.0场景:需要将数仓的表数据,加载到Hive 数据库供 Spark 分发数据。虽然测试成功,但是经过测试效率太慢。最后将数据存放到Hdfs Hive 做外部映射表实现。另外DS11.5版本已经提供链接Hive 接口,同时支持链接.
版本:IBM InfoSphere DataStage V11.5.1
操作系统:linux redhat 6.4
平台:Apache Hadoop 2.6.0-cdh5.9.0
场景:
需要将数仓的表数据,加载到Hive 数据库供 Spark 分发数据。虽然测试成功,但是经过测试效率太慢。最后将数据存放到Hdfs Hive 做外部映射表实现。
另外DS11.5版本已经提供链接Hive 接口,同时支持链接Hice控件。
步骤1:
登陆DS服务器 编辑
/opt/IBM/InformationServer/Server/DSEngine/.odbc.ini
[T_HIVE]
Driver=/onstarlog/IBM/InformationServer/Server/branded_odbc/lib/VMhive00.so
Description=DataDirect Apache Hive Wire Protocol
ArraySize=16384
AuthenticationMethod=0
Database=default
DefaultLongDataBuffLen=1024
EnableDescribeParam=0
GSSClient=native
HostName= 按照Hive节点IP
LoginTimeout=30
LogonID=
MaxVarcharSize=8192
Password=
PortNumber=10000
ProxyUser=
RemoveColumnQualifiers=0
ServicePrincipalName=
StringDescribeType=12
TransactionMode=0
UseNativeCatalogFunctions=0
UseCurrentSchema=0
WireProtocolVersion=0
步骤2:
登陆DS服务器 编辑
DBMSTYPE = ODBC
步骤3:
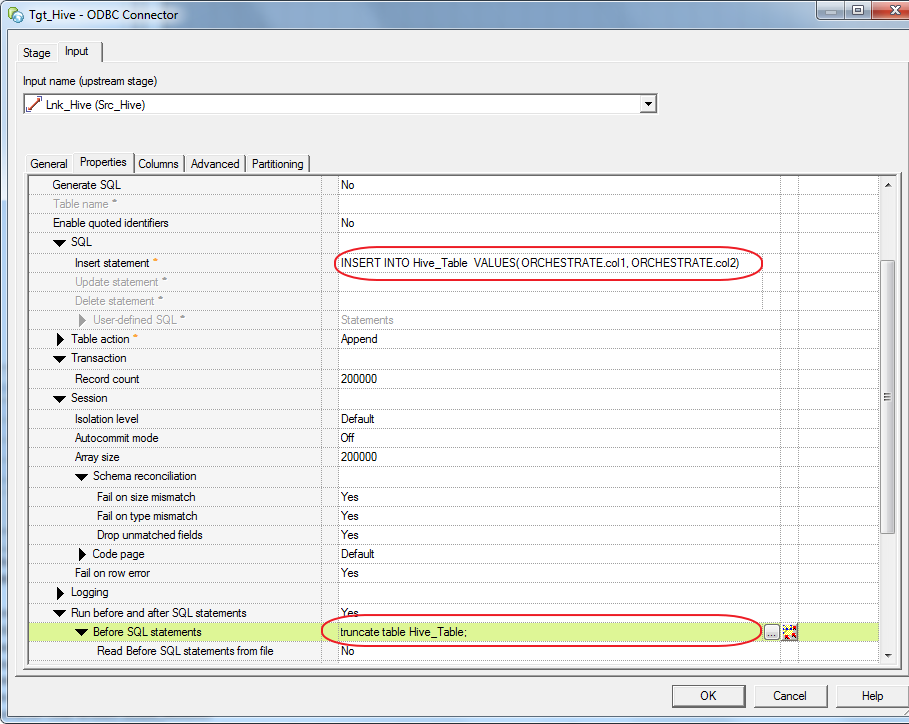
因为Hive 插入表语法和DS插入表语法不一致,所以只能手工写脚本
INSERT INTO Hive_Table VALUES( ORCHESTRATE.col1, ORCHESTRATE.col2)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)