我通过了阿里云高级大模型工程师ACP认证:详细学习攻略(文末抽奖)
这篇介绍阿里云 ACP 课程大纲特色、免费 GPU 实例环境配置、配套学习资源、重点学习章节概览以及习题推荐等。
过去半年在知识星球中,陆续有些刚入门的盆友会问到有什么在企业做 LLM 应用落地的学习路线参考。我一般就把我从最开始学习 Langchain、LlamaIndex 等框架熟悉底层逻辑开始,到后来使用封装度较高的开源框架做PoC,以及后来的结合业务场景定制工具的工程实践积累过程做个推荐。
不过下午参加完阿里云大模型高级工程师 ACP 的线下考试,并顺利通过后,我觉得这似乎是个挺好的入门以及进阶的学习样例,就专门写篇文章和各位做个分享。

课程的官方定位是面向具备编程基础的 AIGC 技术爱好者和应用开发者,培养针对复杂业务场景设计并实施大模型驱动的解决方案的能力。总共 13 个课时,我过去一个月大概拢共花了 40 个小时(主要是微调部分耗时)具体复现了下所有的课程代码和案例。总体来说,麻雀虽小五脏俱全。对产品经理以及转型做 AI 应用的盆友来说,还是有挺好的查漏补缺的作用。
注:课程资源是开源的,可以不必参加付费认证。
这篇试图说清楚:
阿里云 ACP 课程大纲特色、免费 GPU 实例环境配置、配套学习资源、重点学习章节概览以及习题推荐等。
以下,enjoy:
1、ACP 课程大纲
这个课程最早是 24 年 12 月份推出的,最近一次更新是今年 5 月份。先通过官方文档的一个表格来做个快速预览下内容大纲:
|
主要章节 |
主要内容 |
考察知识点 |
|
大模型应用开发 |
通过 OpenAI API 调用大模型 |
基本 API 参数如 model、temperature、top_p 等等 |
|
大模型提示词工程 |
构建有效的提示词 |
提示词框架如提示词要素、提示词分隔符、提示词模板 |
|
利用大模型处理各类任务 |
理解大模型的适用场景 |
|
|
大模型检索增强 |
通过 LlamaIndex 构建 RAG 应用的基本使用方法 |
理解 RAG 的核心要素,如文件解析、文本切片、段落召回、段落重排序 |
|
持续优化检索增强能力 |
理解更贴近实战的 RAG 优化方法如优化文本解析、标题改写优化、表格内容增强、文本分割方法对比等等 |
|
|
对检索增强的能力做自动化评测 |
了解 RAGAS 指标体系 |
|
|
大模型的微调 |
微调的概念与要求 |
模型微调的作用、前提、基本步骤、常用算法 |
|
微调的实验与评测 |
微调数据集构建、微调参数介绍、微调模型评测 |
|
|
多 Agent 及多模态应用 |
基于百炼 Assistant API 构建智能体 |
理解智能体运行机制 |
|
构建更复杂的 AI 应用 |
动手实践阿里发布的 AI 技术解决方案系列,体验多模态交互技术。 |
|
|
生产环境应用实践 |
内容安全合规检查手段 |
了解大模型开发中存在的内容安全问题 |
|
大模型应用部署(云服务)安全 |
了解在云服务环境下应用系统安全的基本要素和解决方案 |
|
|
在云上部署微调模型的基本方案 |
掌握如何使用 vLLM 进行大模型的部署操作 |
章节知识面覆盖比较齐全,我在学习的过程中也确实发现了些知识盲点。总结来说,涉及到的知识点大致包括:大模型提示词技巧、RAG 和微调的原理和流程、LangChain、Llama-Index 和 Dify 等大模型开发组件的使用方法、Ragas 工程化评测的概念与方法、大模型的规范和安全性。
2、限时免费 GPU
阿里云比较慷慨的赠送了 3 个月,每月 250 计算时。不过,这个福利我在去年 9 月份参加智谱清言的一个跨境电商多模态挑战时,每月是 5000 计算时。不过单就这个课程的复现而言,也是完全够用的。
如果你当前的阿里云账号无法申请,可以使用手机号再注册一个。最多好像是可以注册五个。需要注意的是,每月额度用尽后超出按量计费,支持抵扣 DSW 开发实例的 A10/V100/G6 3 种机型:ecs.gn7i-c8g1.2xlarge,ecs.gn6v-c8g1.2xlarge,ecs.g6.xlarge。不过好在阿里云的实例有自动关机策略,所以不用担心每次忘了手动暂停而消耗时长。
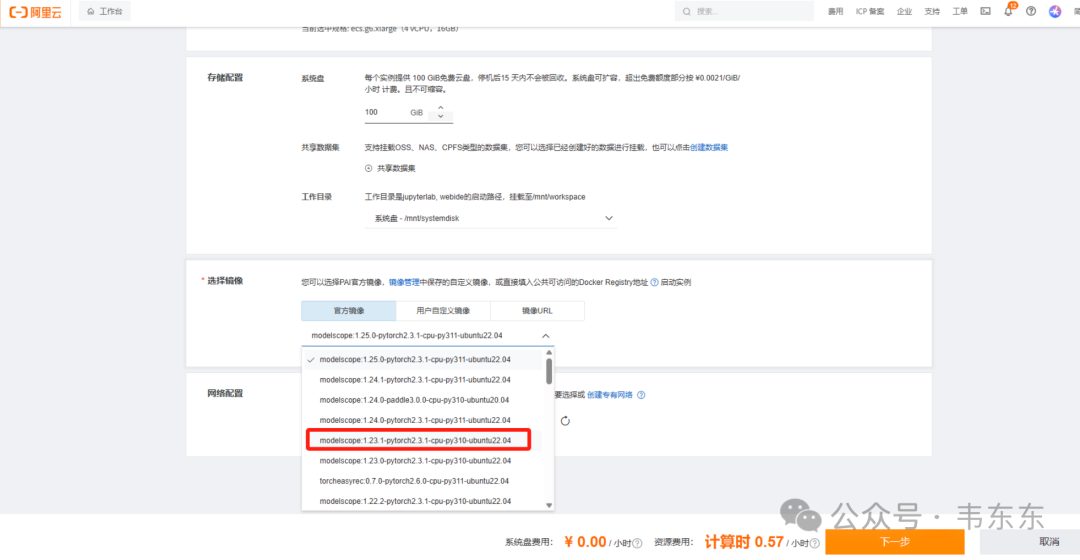
2.1、实例配置步骤
输入地址:https://free.aliyun.com/?searchKey=交互式建模+PAI-DSW,点击"立即试用"

点击试用后,先根据提示跳转访问控制 RAM 控制台,完成一键授权。紧接着根据提示一键开通相关服务。
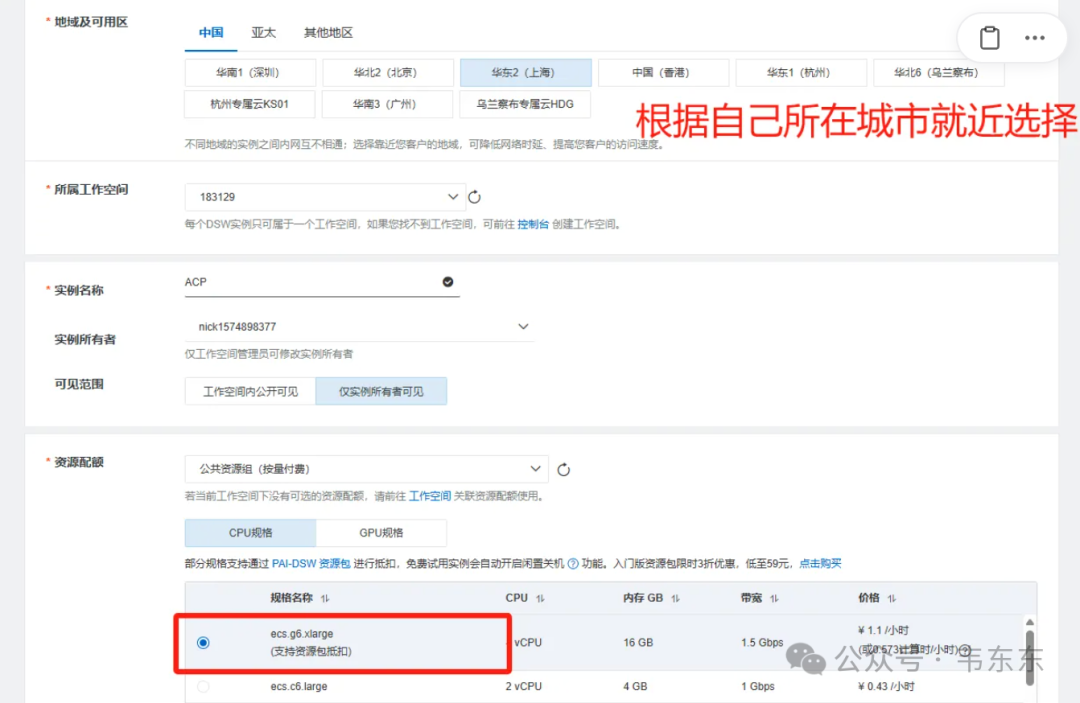
需要选择 CPU 类型镜像,推荐使用 python 版本为 3.10 的镜像方便后续配置,可以通过上图方式筛选符合条件的最新镜像(如:modelscope:1.23.1-pytorch2.3.1-cpu-py310-ubuntu22.04)。到这一步就算是完成了实例创建,后续可以根据需要随时打开或者停止实例。
2.2、项目源代码获取
如果本地有 GPU 资源,可以选择下载到本地使用,https://github.com/AlibabaCloudDocs/aliyun_acp_learning
在 DSW 中,可以通过点击顶部的 Terminal(终端)来进入命令行环境:
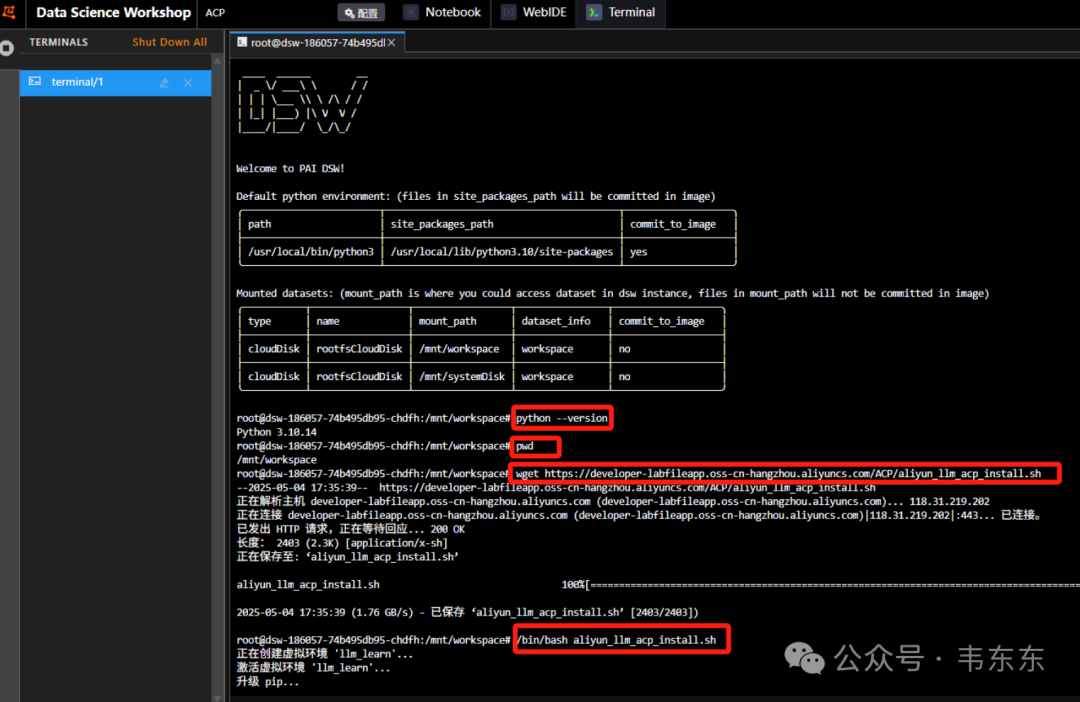
确认环境变量,在 Terminal 中输入 python --version 来确认当前的 python 版本是 3.10 ,输入 pwd 确认当前所在目录为/mnt/workspace。
python --version
pwd在 DSW 的 Terminal 中执行如下命令,下载脚本自动安装课程所需的环境依赖。
wget https://developer-labfileapp.oss-cn-hangzhou.aliyuncs.com/ACP/aliyun_llm_acp_install.sh
/bin/bash aliyun_llm_acp_install.sh完成安装步骤后,在顶部切换到 Notebook,你就可以在文件树中看到 aliyun_acp_learning 文件夹了。
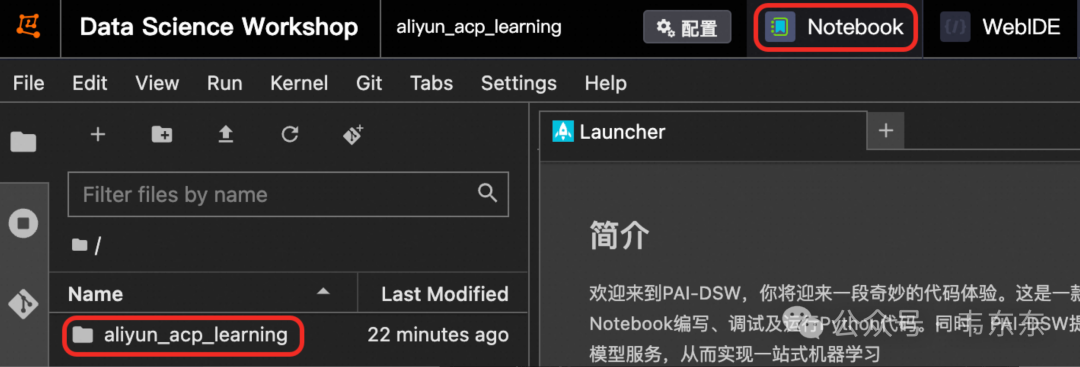
接下来你可以在文件树中依次进入 aliyun_acp_learning->大模型 ACP 认证教程->p2_ 构造大模型问答系统 文件夹,就能看到下一章的教程内容。
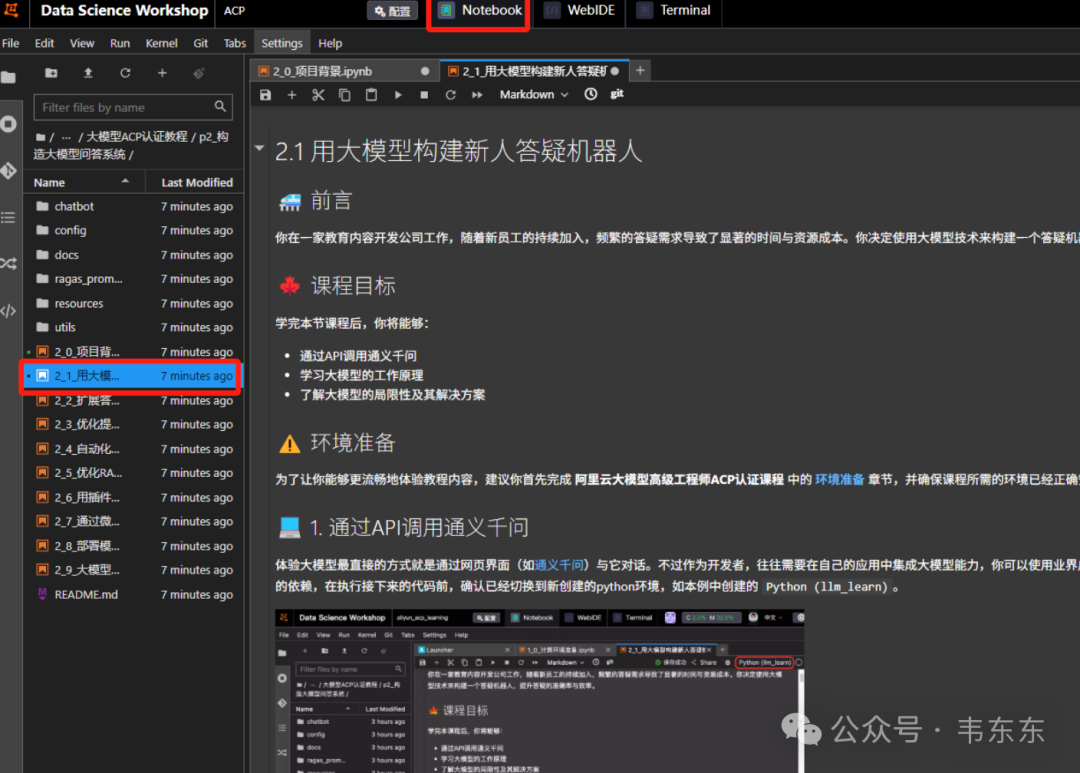
课程内容安装完成后,你还需要在 Notebook 课程(.ipynb 文件)右上角选择内核(默认内核为:Python 3 (ipykernel)),切换为刚创建的 Python 环境:Python(llm_learn)环境。
注:创建实例后,如果关闭超过 14 天系统会清空所有上述配置内容,到时需要重新操作一遍。
3、重点章节预览
3.1、优化提示词的一些方法
这部分内容的大部分细节我相信在一线参与实践的盆友应该都有所了解。这个课时的主要价值在于提供了一个完整的提示词框架,包含任务目标、上下文、角色、受众、样例和输出格式六大要素,这种系统化思维有助于构建更全面的提示策略。
在工程实践中应将提示词设计为可配置的,便于行业或者业务专家参与优化,这是从工程化角度的有效做法。
3.2、Ragas 自动化评测的完整示例
这部分包含两个课时,主要介绍 Ragas 评测框架的基本概念以及如何基于量化指标进行 RAG 系统的针对性优化。尤其可以关注各种评估指标(Answer Correctness、context recall 和 context precission 分数等)的计算方法及其在 RAG 优化中的应用。
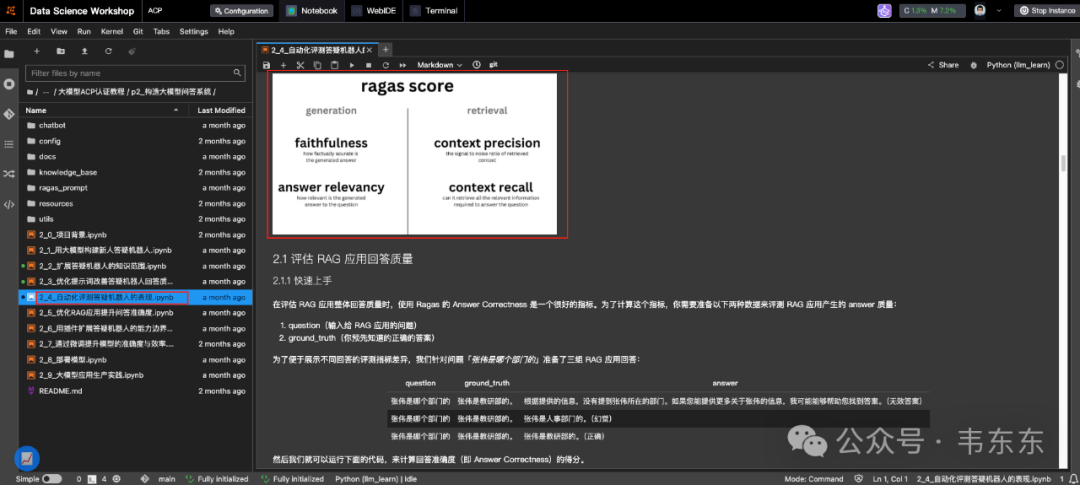
实务中需要根据应用场景和优化目标选择关注的指标,以上面提到的三个指标为例举例说明:
高 Recall 低 Precision + 低 F1:
系统检索了大量信息,包含了正确答案所需的全部信息,但混杂了太多无关信息,且排序不佳
问题:信息噪音过大,大模型无法从杂乱信息中提取关键内容
优化方向:改进检索相关性排序,可考虑添加 Rerank 步骤
低 Recall 高 Precision + 低 F1:
检索到的信息高度相关且排序良好,但缺少支持完整答案的关键信息
问题:信息不完整导致大模型无法生成全面准确的回答
优化方向:扩充知识库或改进检索策略,确保关键信息被召回
低 Recall 低 Precision + 高 F1:
含义:罕见情况,检索效果差但答案却正确
可能原因:大模型已有相关知识,不依赖检索结果就能回答;或问题过于简单
风险:这种情况下系统表现不稳定,容易产生幻觉
通常 Context 指标提升会带动 F1 分数提升,如果只提升了一个 Context 指标而 F1 没有相应提升,可能需要平衡另一个 Context 指标,F1 分数的天花板往往受限于 Context 指标的短板。
3.3、引入自定义工具
其中的工具函数定义方式遵循了 OpenAI 的 Function Calling 规范,私以为对于初学者来说,通过代码方式学习是一条更加彻底的学习路径,熟悉了底层原理后,可以更加轻松适应不同平台的界面和工作流程,因为本质上它们都基于相似的概念。对于特殊需求,也可以进行深度定制,这在企业级应用中深度适配业务场景中尤为重要。
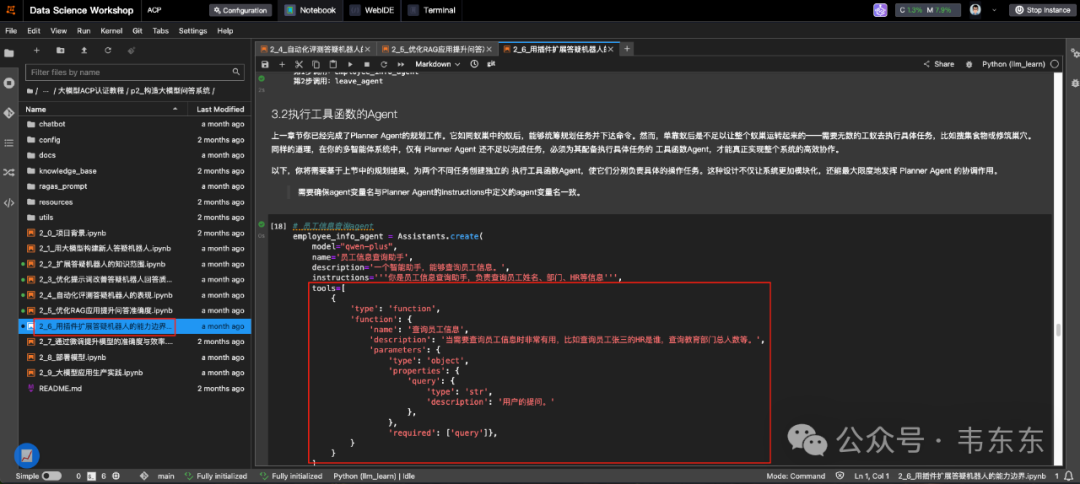
这里正好预告下,下周我会写篇文章专门介绍下如何基于京东刚开源的端到端的 joyagent,结合特定业务场景定制工具的示例。
3.4、微调的完整入门及实现过程
这部分有完整的概念入门和可视化的图示,对于不熟悉或者没有上手实操过微调的盆友可以着重测试下。
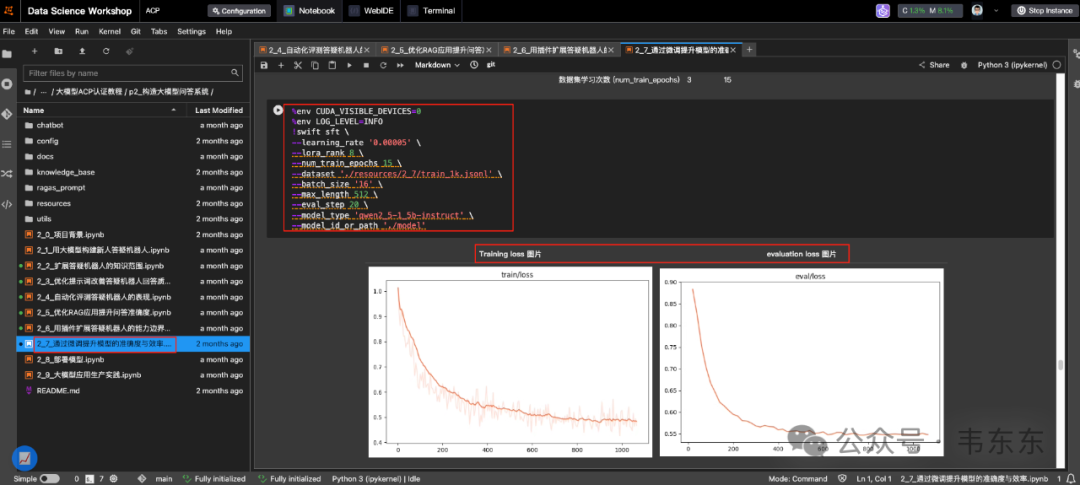
但是,Lora 微调虽然有很多面向特定任务的效果好处,但是在实务中要注意要有充分数量及代表性的高质量训练数据集作为前提,否则效果很难有保障。
3.5、大模型应用生产实践
这部分主要是阿里云一些产品介绍,对于计划做端云混合部署的企业可以了解下,我梳理了下大概是分为三部分:
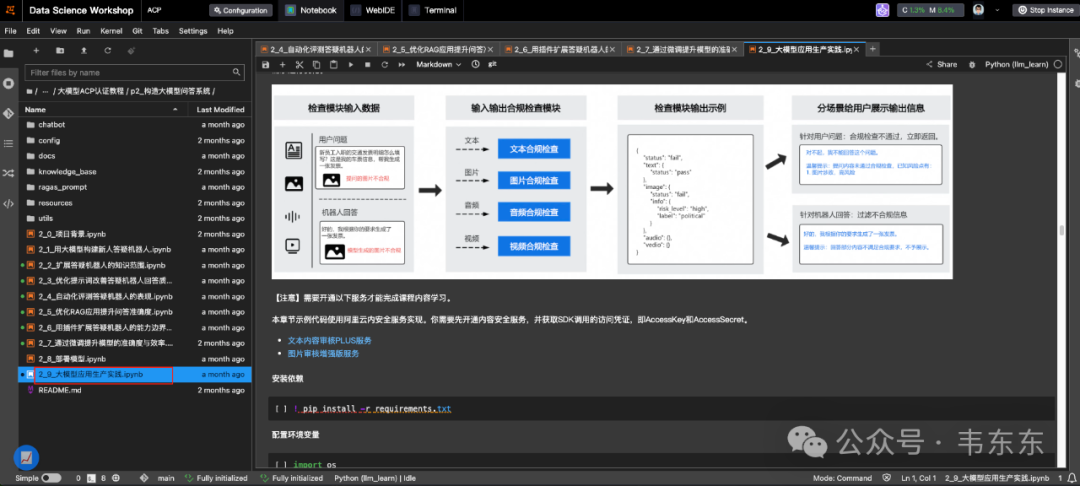
PAI-EAS:企业部署大模型的全家桶,主要用于模型部署和在线推理服务。
Function Compute:简单的推理任务,或流量不稳定的场景
容器服务 Kubernetes 版:高度定制的部署方案,适合有专业运维团队的企业
4、练习题及工具安利
做高质量的练习题是快速检验掌握新知识点的好办法,不过碍于官方提供的练习题只有一套,而且只有 20 道。所以我使用了我过去几个月一直常用的一款 AI 创作工具(youmind.ai(需要科学上网),简单理解是创作版的Cursor)来帮我我基于课程大纲以及我做的学习笔记,帮我生成了一些专项练习题和对应的答案解释。当然,如果为了更加可视化,你也可以尝试选择针对特定内容来生图、博客、图表等形式。

当然,还有很重要的一个作用是,在我实际学习课程的过程中,记录下的课程的一些疑难点,也会同步的点开侧边栏的 agent 模式(支持多种工具调用和国内外最领先的 LLM)进行多轮问答的答疑。
练习题已发布到知识星球《企业大模型应用从入门到落地》中,实际线下考试难度是低于我整理的这份练习题。各位有兴趣可以先做个自测,如果发现疑难点较多,可以再考虑有针对性的学习。预计 8 月下旬开始,我也会针对这个课程以及历史发布过的相关场景案例录制视频课的方式,进行手把手的拆解演示,到时也会同步发布在知识星球中。
最后有个抽奖活动,明天中午 12 点在知识星球会员群中随机抽奖,赠送 5个YouMind.ai 的一年年度会员(国内目前年费 200 元,海外定价20美金/月)。对这个产品感兴趣的可以点开文末的”原文链接“跳转查看下官网介绍。
下期预告:
预计周末会发篇介绍基于向量相似度+Diff算法的协议差异对比系统实现,欢迎蹲一蹲。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)