大模型应用介绍和典型范式
大模型应用介绍和典型范式:厘清LLM与“泛大模型”边界,揭示其本质是下一个token概率预测;系统梳理幻觉、缺规划、记忆短板及RAG、CoT、Workflow、Tool/Agent、Memory、微调组合补救路径;强调评测与数据工程驱动ROI。助你高效打造可靠AI应用。全链提效升级快
思维导图
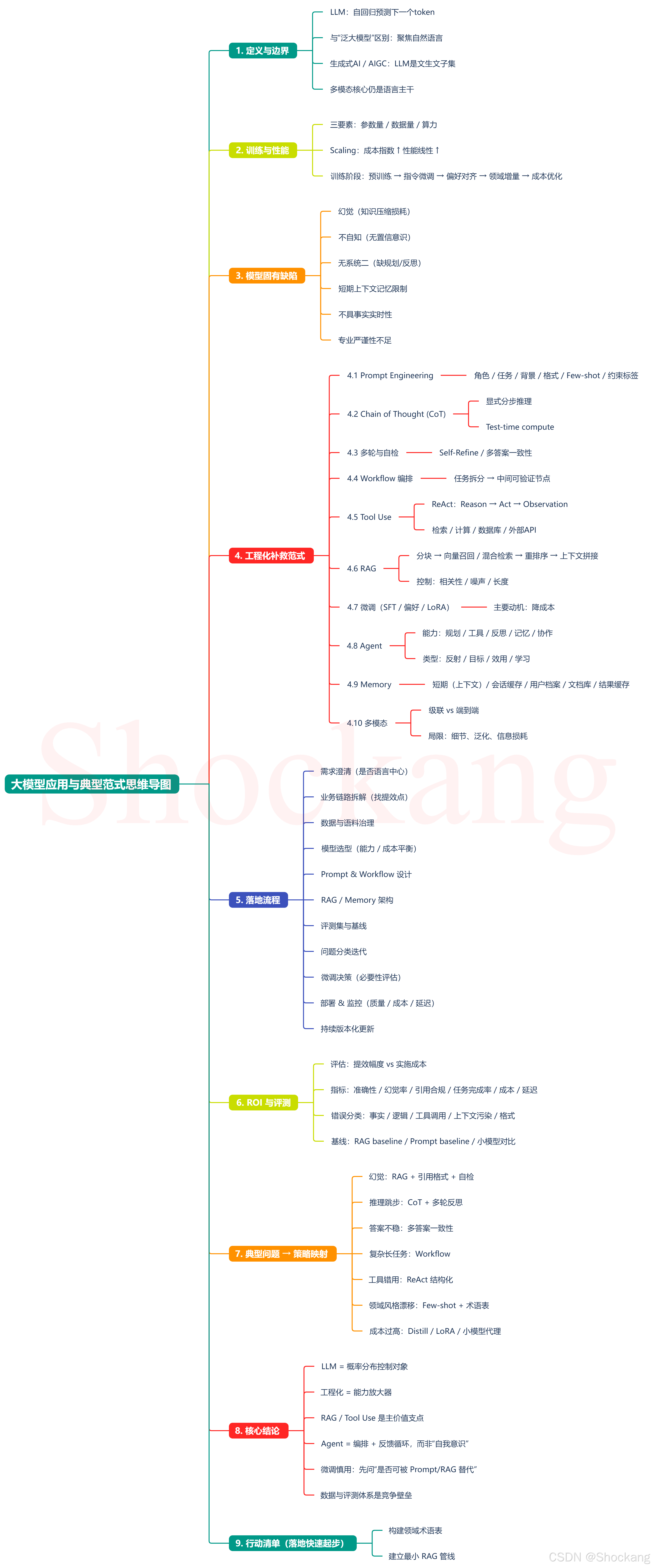
正文
1. 课程总体结构与重心
课程主线:
- 大语言模型(LLM)概念与定位澄清
- LLM 能力与局限(知识/思考/记忆)
- 为什么需要“应用范式”而不仅是“调用 API”
- 核心工程范式:Prompt / CoT / Multi-turn / Workflow / Tool Use / RAG / Fine-tuning / Agent
- Agent 的能力分解与工程化补全
- 多模态大模型实现方式与当前局限
- 实际开发与落地关注点(提效、ROI、数据、评测、迭代)
课程强调:
- “裸模型 ≠ 可用应用”
- 绝大多数价值来自“工程化弥补”模型固有缺陷
- RAG 与 Agent 是当前两大最主要落地范式
- Fine-tuning 在多数场景的主目标是“降成本”而非“显著提性能”
2. 术语与边界澄清(国内常见混用点拆解)
| 术语 | 课程准确含义 | 重点澄清 |
|---|---|---|
| 大模型(国内泛称) | 任何参数较大的模型 | 课程限定主题实际聚焦“大语言模型 (LLM)” |
| LLM | 以自然语言文本为核心输入输出,基于大规模语料 + Transformer 训练的自回归预测模型 | 不等同于气象、时序等其他“非语言”任务模型 |
| 生成式 AI / AIGC | 能生成文本 / 图像 / 视频 / 音频等内容的模型总称 | LLM 是其中“文生文”子集 |
| 语言模型 (LM) 与 LLM | LLM 是 LM 的“规模化升级” | 本质目标未变:预测下一个 token |
| 多模态大模型 | 以 LLM 为主干(语言为“思考核心”)引入多模态输入/输出 | 不是完全“去语言化”的统一心智 |
3. LLM 的定义与本质

核心定义:
LLM = 使用超大规模(万亿 token 级)文本数据 + 大参数容量(十亿~千亿以上)+ 高算力训练的自回归语言模型,其唯一训练目标:给定上下文,预测下一个 token 的条件概率分布 [P(token_{t} | token_{<t})]。
三要素(Scaling 三轴):
- 参数量(Capacity)
- 训练数据 token 量(D)
- 计算预算(C)
性能随三轴扩大呈“线性收益 / 指数成本”模式 → 已进入平台期(继续堆参数与数据的边际收益递减)。
关键强调:
- LLM 是“语言任务能力”的基础设施,而非通用一切任务的万能模型
- 不适合直接承担纯结构化预测(如风控评分)——应结合小模型或上层编排
4. 训练与能力形成(高层流程拆解)
| 阶段 | 目的 | 课程提及要点 |
|---|---|---|
| 预训练(自监督) | 学习语言统计与通用语义模式 | 数据来源含互联网、书籍、百科、代码、论文等;信息压缩必然丢失细节 |
| 指令/监督微调(SFT) | 学会遵循人类格式与指令 | 让模型“可用” |
| 偏好对齐(RLHF / DPO / KTO / SimPO / ORPO 等) | 更符合人类偏好与安全 | 课程列举方法类别(不展开细节) |
| 领域增量(可选) | 适配垂直术语或风格 | 可能用 LoRA / QLoRA / 其他 PEFT |
| 资源优化(微调主因之一) | 用更小模型取代大模型 | “多数企业微调 = 降成本而非效果飙升” |
5. 应用价值定位与筛选标准
| 维度 | 课程观点 |
|---|---|
| 价值模式 | “提效 + 辅助创新” > 直接替代全链人力 |
| 评估标准 | 是否能替代“刚毕业大学生 + 一定参考资料”的完成能力 |
| 错误风险 | 高风险高精度领域必须加入外部知识(RAG)或校验环节 |
| 生产力逻辑 | 拆解业务流程 → 找语言密集、重复性、信息聚合/转写类环节 |
| 成本错配风险 | 低提效比例 + 高开发成本 → 需谨慎(课中举例:早期 AI 场景 ROI 失衡) |
6. 模型固有缺陷与根本成因
| 缺陷 | 具体表现 | 根源(课程强调) | 弥补手段(后续范式对应) |
|---|---|---|---|
| 知识缺失与幻觉 | 生成似是而非事实 | 1) 信息压缩损耗(TB→GB) 2) 语料冲突 3) 更新滞后 | RAG / 校验 / 外部工具 |
| 不自知(Uncertainty Unawareness) | 不知道“自己不知道”仍编造 | 预测式机制,无置信度内生建模 | 置信度启发策略 / 多轮自检 |
| 无内在系统二思考 | 直接产出结果;缺规划/反思链 | 前向推理深度有限(层数有限) | CoT / ReAct / Test-time Compute |
| 无长期记忆 | 超出上下文即遗忘 | 上下文窗口(如 128K)有限 | Memory Layer / Profile Store / RAG |
| 无内省与自检 | 不做自我校对 | 训练目标仅是“似然最大化” | Self-Refine / 多轮反馈 / 多答案一致性 |
| 实时性缺失 | 无法回答最新事实 | 静态训练快照 | 工具检索 / 时间戳策略 |
| 专业严谨性不足 | 领域深细节错误 | 语料覆盖浅;统计泛化偏概念 | 领域检索 / 领域小模型协同 |
7. 工程化补全:计算机类比框架
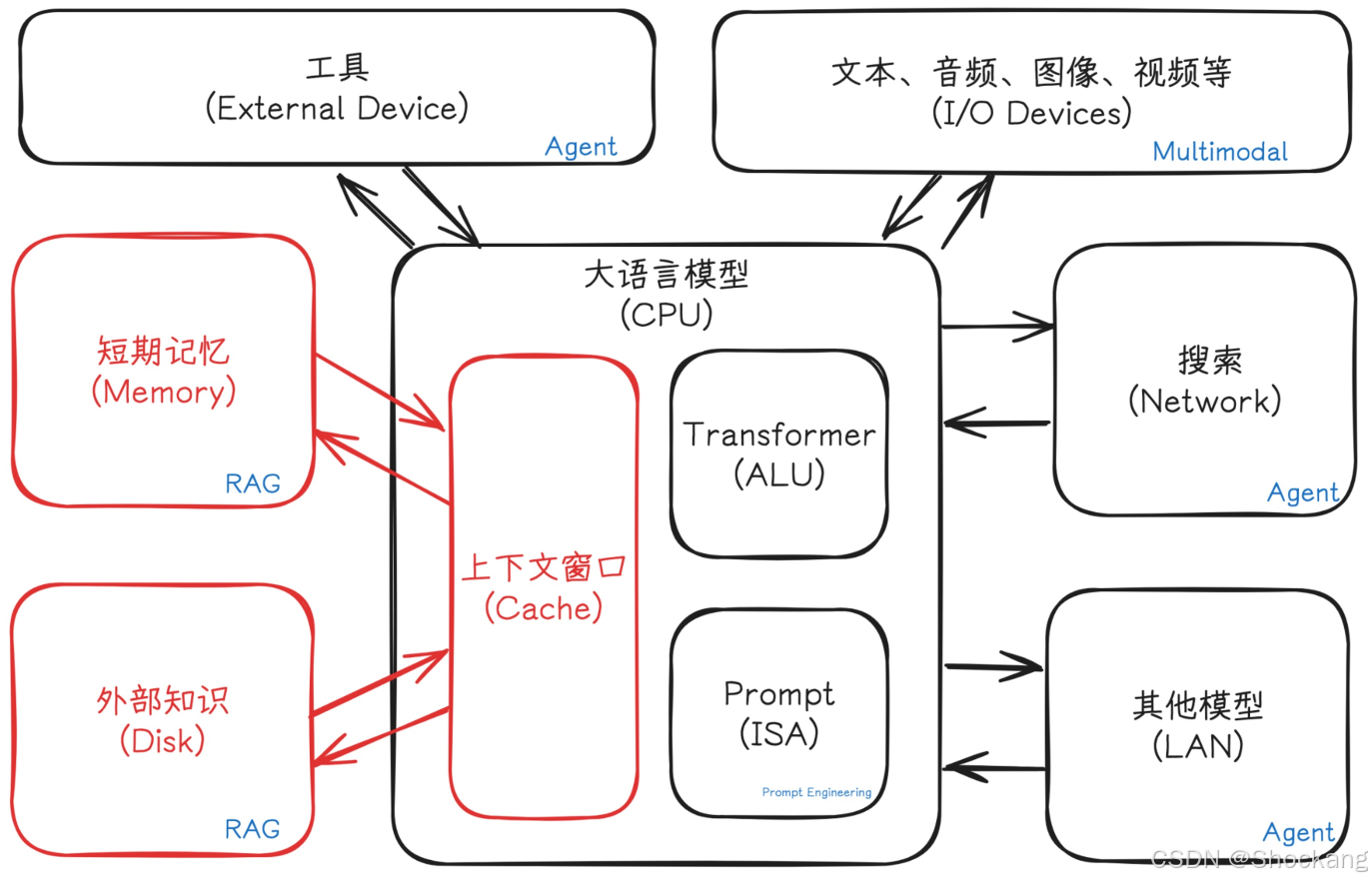
| LLM 应用组件 | 类比计算机 | 课程含义 |
|---|---|---|
| Transformer | ALU | 核心“语言 token 预测” |
| 上下文窗口 | L1/L2 Cache | 短期工作记忆 |
| 外部文档库 | 磁盘 | 需检索(RAG)才能“加载” |
| Prompt(系统/用户/工具) | 系统总线 | 串联各阶段输入输出 |
| 工具 / API 调用 | 外设 / I/O 控制器 | 拓展算力与外部信息 |
| Workflow / Orchestrator | 操作系统调度 | 管控多步、错误恢复、路由 |
| Memory(用户偏好/历史) | 持久化存储 + 缓存回填 | 个性化与连续性 |
| Agent 框架 | 任务调度器 / 自主控制层 | 规划 + 反思 + 工具组合 |
结论:仅调用“裸模型 + 简单对话”远低于官方产品体验,原因是缺失上述完整链路(课程中特别强调“为什么接一个 API 会显著比官网笨”)。
8. 具体应用范式
8.1 Prompt Engineering(基础骨架)

结构要素:
- 角色/人设(你是谁)
- 任务定义(要做什么)
- 输出格式/风格/约束(如 JSON / Markdown / 严禁发散)
- 背景信息(上下文、领域限定、定义表)
- 输入区分(<用户提问>、<相关文档> 等标签隔离)
- 示例(Few-shot,提升模式对齐)
- 评估/打分指令(用于自检或裁决)
实践要点:
- 用显式标签(类似 XML)区隔不同语块 → 降低指令与材料混淆
- 写作视角:这是“控制概率分布的工程”而非“与一个人格对话”
8.2 思维链(Chain of Thought, CoT)
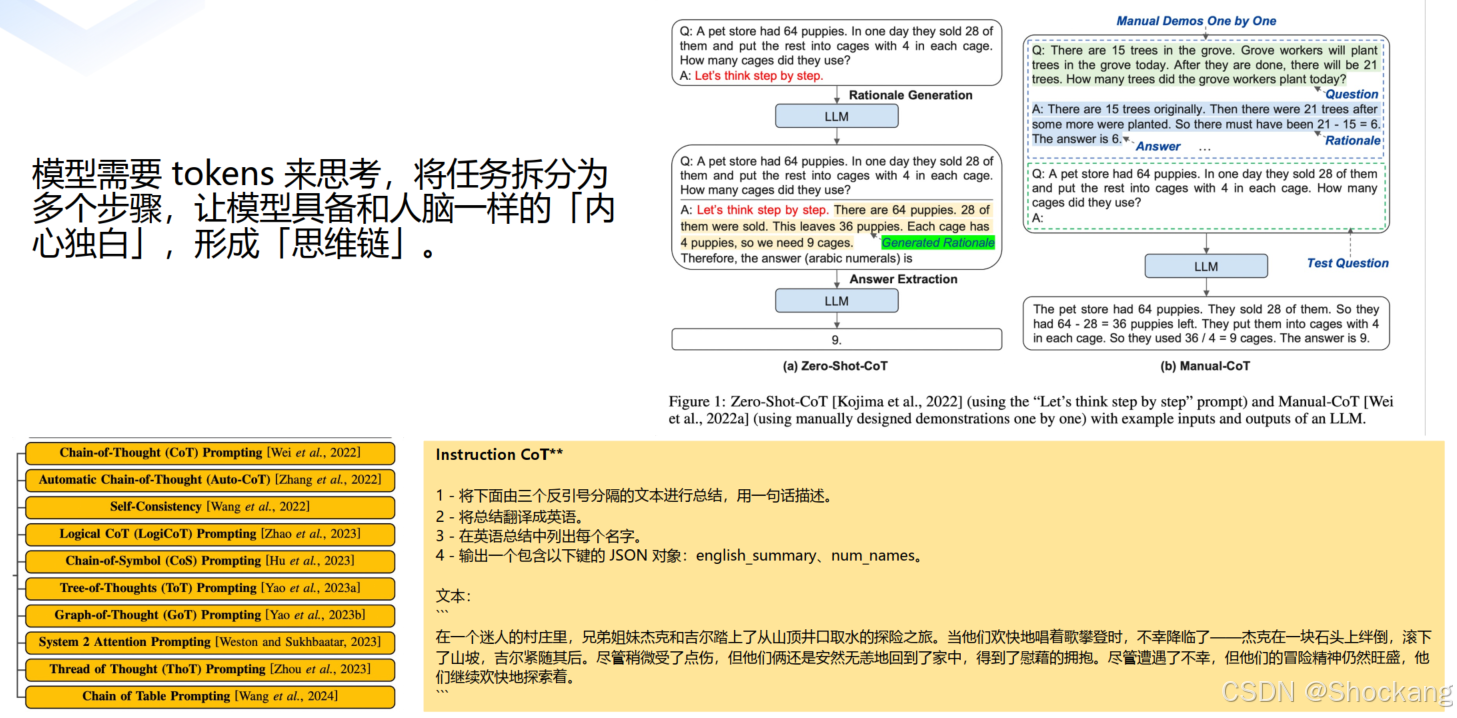
目标:通过让模型输出中间推理 token 序列,弥补其“深度不足”。
方式:
- 明示引导:例如“请分步推理”“先分析再作答”
- 指令分段:拆成 1→2→3→4 子任务(课程例:总结 → 翻译 → 抽取名字 → 输出 JSON)
- Test-time Compute:用更多推理 token 换取更稳健答案
- 课程强调“新一代具思考模型(如具内置推理链)时,反而不要过度束缚,引导可适度减少”
8.3 多轮 / 反馈 / 自一致性
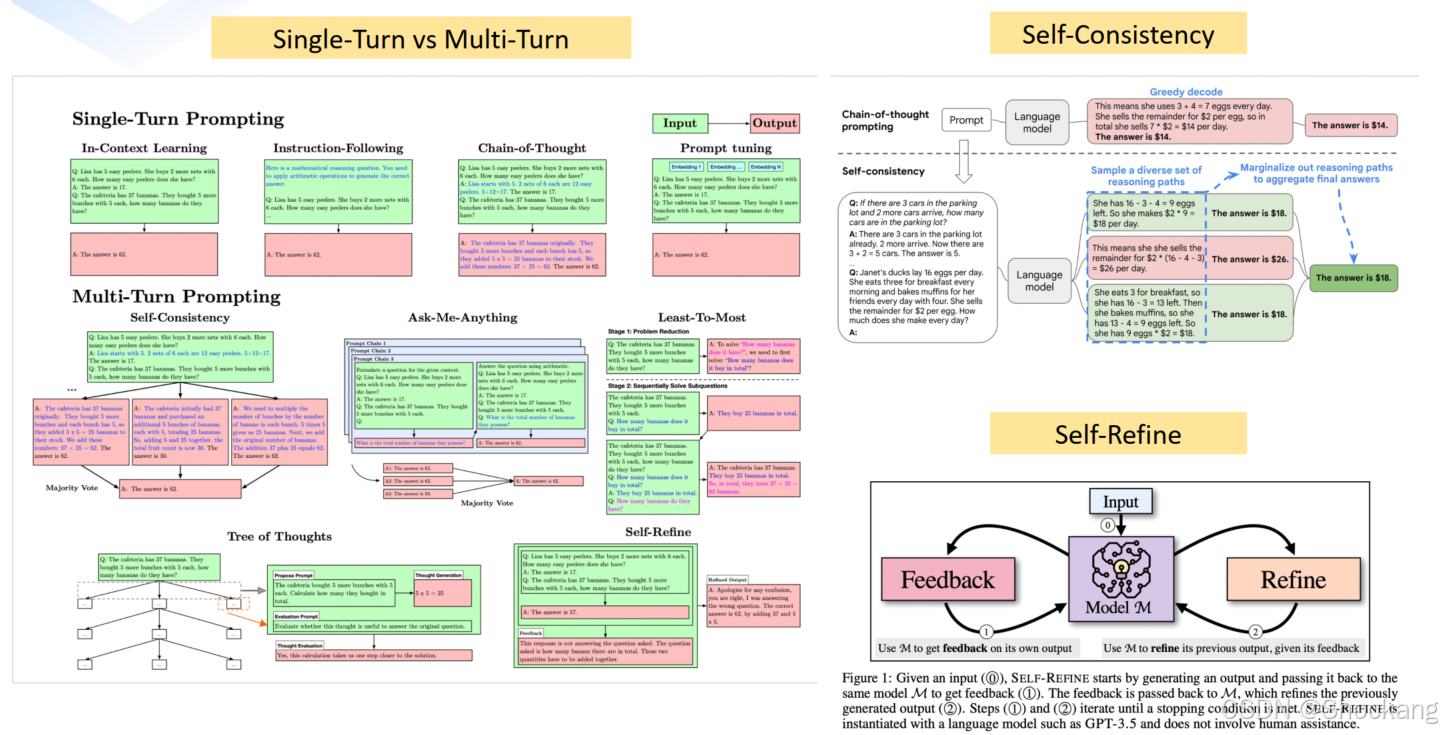
- Self-Refine:第一轮生成→第二轮自我评估→修订
- 多答案(Self-Consistency):同一问题多次生成 → 选频次/评分最高答案
- 结构化多轮:翻译示例(术语提取 → 直译 → 质量点评 → 二次润色)
8.4 Workflow / Pipeline(编排范式)
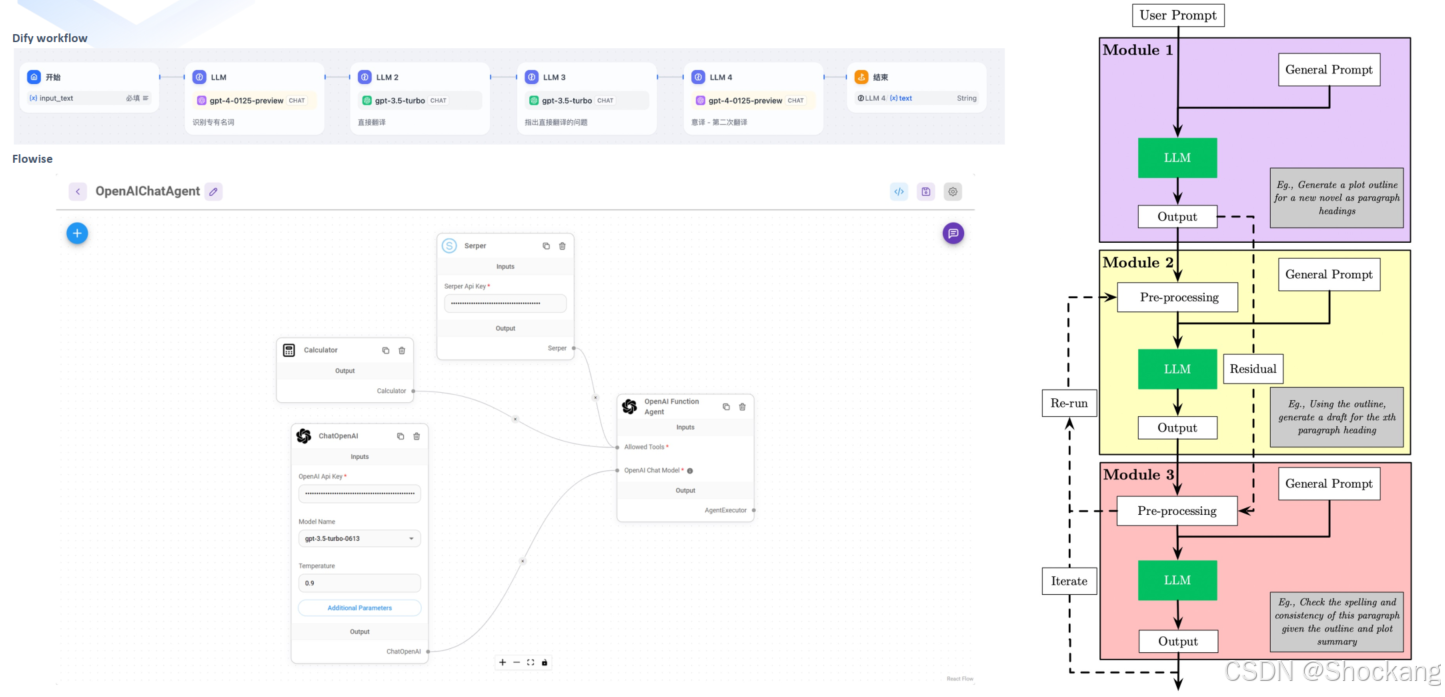
核心价值:把一个复杂任务拆分为“可验证的中间节点”,便于插入不同模型或工具。
典型示例(课程案例:翻译工作流):
- 专有名词识别
- 初次直译
- 质量问题定位(错误列举)
- 二次润色输出
8.5 工具使用(Tool Use / Function Call)
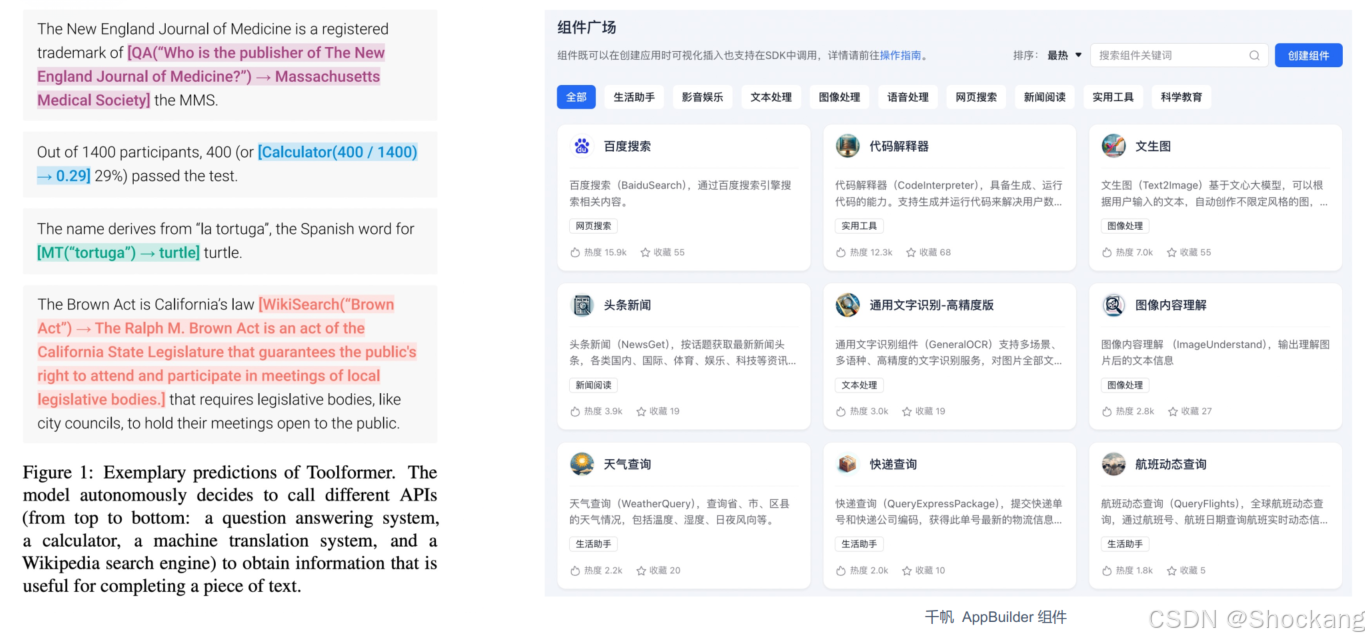
用途:
- 获取新鲜知识(搜索、百科)
- 数值/逻辑精确计算(计算器)
- 查询数据库 / 内部系统
模型角色: - 思考(Reason)→决定调用哪个工具
- 动作(Action)→传参
- 观察(Observation)→吸收结果再迭代
8.6 RAG(Retrieval-Augmented Generation)
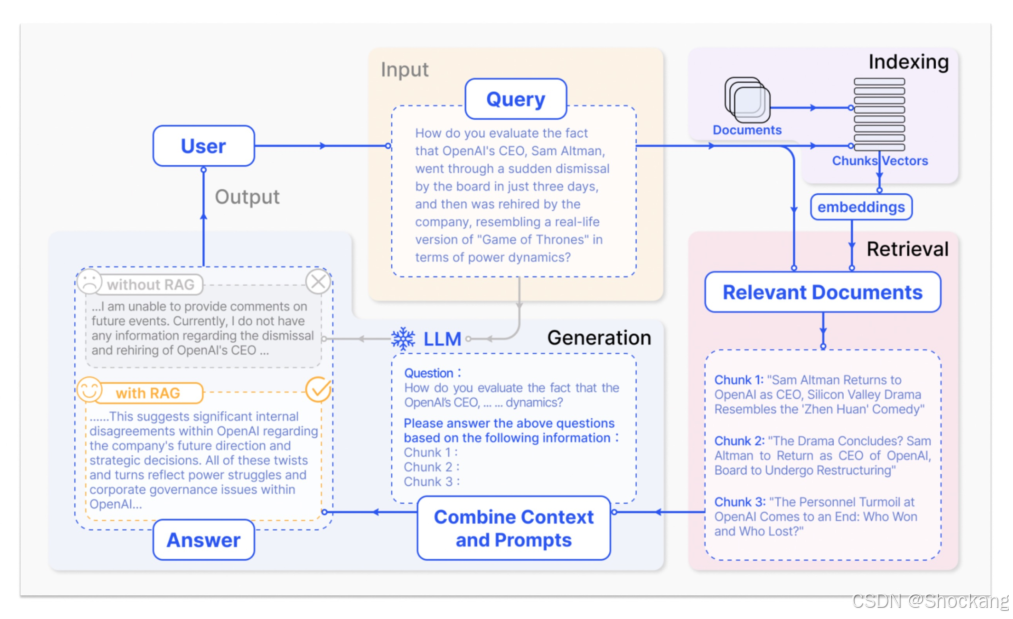
解决:知识缺失 / 幻觉 / 更新滞后
高层流程:
- Query 预处理(规范化、去噪、可选扩展)
- 文档分块(Chunking)与向量化
- 初步召回(向量 / BM25 / 混合)
- 重排序(可引入交叉编码器)
- 构造上下文(插槽控制:顺序、摘要、裁剪)
- Prompt 注入(加标签 <相关文档>)
- 生成与可选答案验证
课程强调:
- “理论简单,实践多坑”——例如:分块策略、召回噪声、上下文污染、格式挤压主问题
- 真实案例:讲师制作金融相关 RAG 评测集 + baseline,鼓励学员迭代
8.7 Fine-tuning(微调)
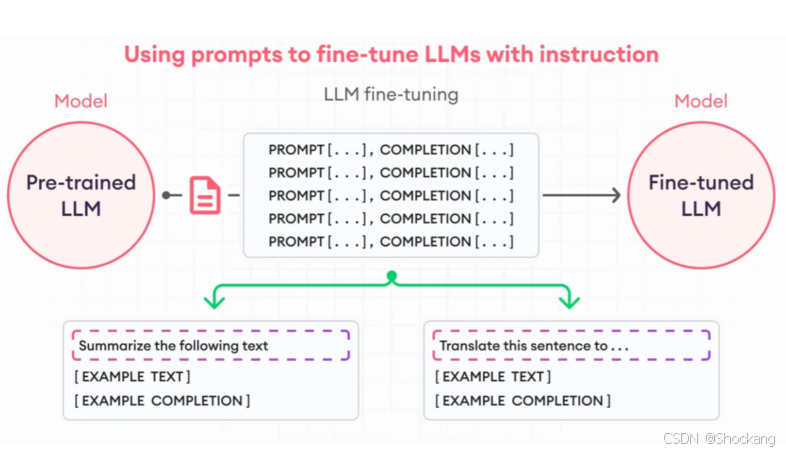
分类:
- Instruction / SFT(遵循指令)
- Preference(RLHF / DPO / KTO / SimPO / ORPO 等)
技术路径:
- 全参数
- LoRA / QLoRA
- 其他 PEFT(提及但当前使用较少)
课程观点(重点):
- 现实主驱动:模型压缩 / 成本下降(“用 7B 替 70B”)
- 非所有场景都“值得”微调:RAG + Prompt 往往更高性价比
8.8 Agent(智能体)
区分:
- Flow 类(本质是工作流/编排)
- 自主类(具有较强自驱循环)
特征(课程列出四核心):自主性、感知、决策制定、行动
能力拆解:规划(Planning)、工具使用(Tool Use)、反思(Reflection)、合作(Multi-Agent / Role 分工)、记忆(Memory)
类型:反射代理 / 目标代理 / 效用代理 / 学习代理
当前可用代表性方向:
- 自动写代码(AI Coding)
- 深度研究报告生成
- 咨询/分析型初级探索
核心架构示例:ReAct(Reason → Act → Observation 循环)
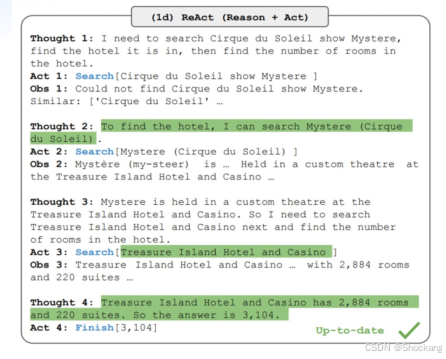
- 串行链式迭代:思考 → 选工具 → 执行 → 反思 → 下一步
- 仍是主流可解释框架之一
8.9 Memory
- 短期:上下文窗口
- 中期:会话线程缓存
- 长期:用户偏好 / 档案存储(调用时检索注入)
- 知识型:RAG 文档库
- 结果缓存:历史工具调用结果(减少重复查询)
8.10 多轮与“系统二”模拟
- 通过显式规划(先列步骤)、工具链、反思、自检评分等工程化组件拼接 → 模拟“系统二”
- 多模态/思考模型出现后:部分链条内嵌,但工程外骨骼仍必要(治理、校验、事实注入)
9. 典型落地流程
| 阶段 | 关键问题 | 对应产物 |
|---|---|---|
| 需求澄清 | 任务是否语言中心?是否“毕业生 + 资料”可完成? | 任务描述 & ROI 粗评 |
| 价值评估 | 提效幅度?节省人力分布?误用风险? | 业务链路拆解表 |
| 数据准备 | 语料清洗 / 分块策略 / 标注规范(若评测集) | 语料库 & 向量库 |
| 模型选择 | 公有 API / 私有化 / 参数规模与成本权衡 | 模型栈清单 |
| Prompt / Workflow 设计 | 任务拆解、标签规范、格式控制 | 初始 Prompt 套件 |
| RAG / Memory 架构 | 分块、召回、排序、上下文拼接策略 | 检索管线 |
| 评测(离线) | 构造问答/工具链评测集(如金融 RAG 基线) | 指标报表 |
| 迭代(在线) | 错误类型分类(幻觉/缺步骤/错格式/引用缺失) | 迭代日志 |
| 是否微调 | 触发条件:频繁模式化补丁 / 模型过大成本 | 微调计划(可选) |
| 部署与治理 | 监控:延迟 / 成本 / 质量;日志归档 | 运维仪表 |
| 持续更新 | 新文档/术语注入频率,Prompt 演化基线 | 版本纪要 |
10. 多模态大模型
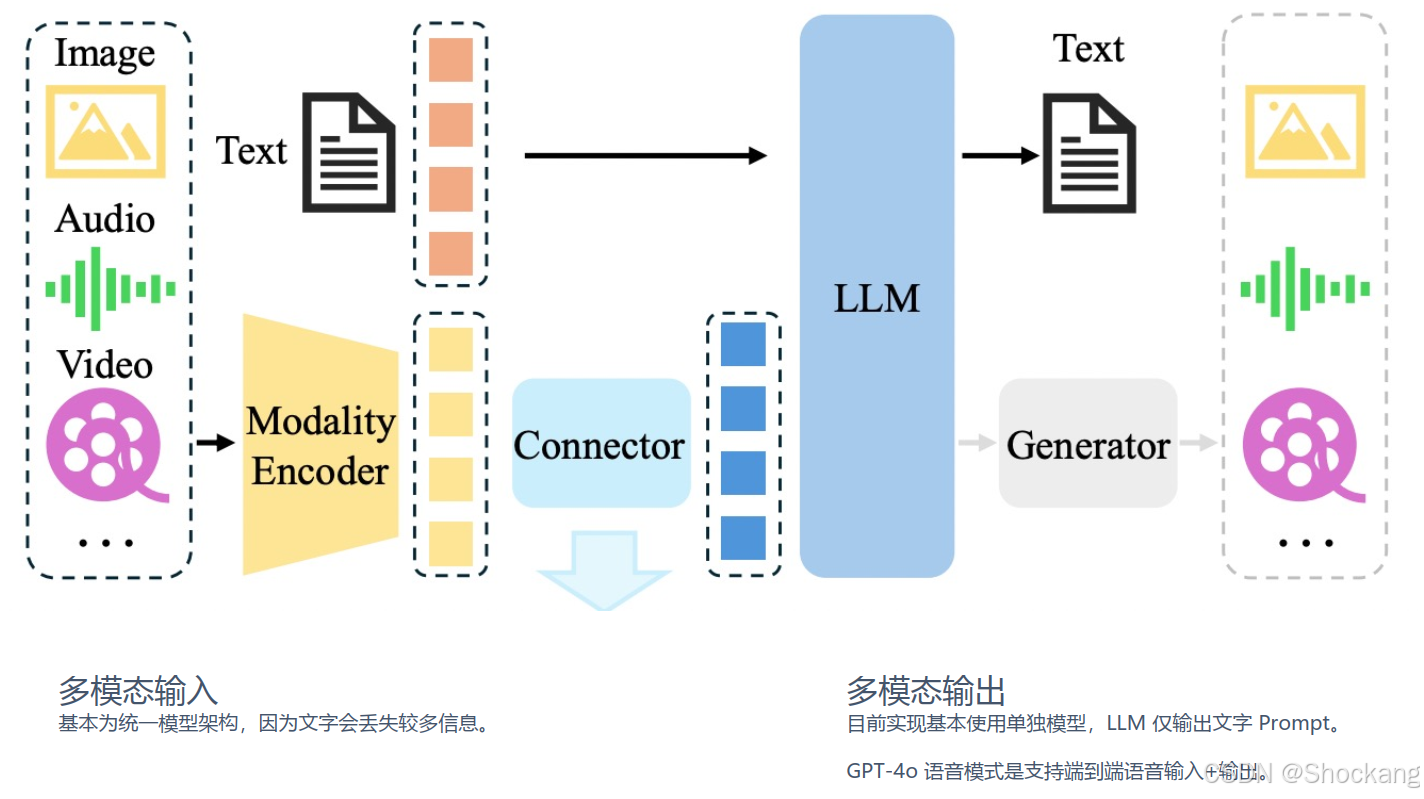
| 维度 | 课程描述 |
|---|---|
| 输入模态 | 文本、图片、语音、视频(经 Encoder 转换) |
| “思考核心” | 依然是语言(文本 token 序列)——用语言“内部表征”统一模态 |
| 两类实现 | 1) 大小模型级联(ASR→LLM→TTS / 文本提示→扩散模型) 2) 端到端对齐(多模态 Encoder + 对齐层 + LLM 主干) |
| 输出模式 | 当前多以“文本 + 级联生成”主流;端到端直接输出语音/图像仍训练难度高 |
| 局限 | 泛化弱(对细粒度视觉细节、复杂专业图纸如 CAD / P&ID / 电路图识别可靠性不足) |
| 信息损失点 | 级联模式中:语音情感 / 语气 → 丢失;文本瓶颈 |
| 当前定位 | 作为“高质量辅助输入渠道”优先;对垂直视觉任务仍需专用模型 |
11. 课堂示例与细节提示
| 示例/说法 | 课程用意 |
|---|---|
| “List the cities of China” 概率例 | 直观展示 token 概率分布是根本 |
| 《红楼梦》第 62 回细节问答 | 说明概念性记忆 vs 细节缺失 → 需 RAG |
| “山东 vs 山西人口倍数” | 演示规划 + 工具调用 + 计算链条(系统二) |
| 金融 RAG 评测集与 baseline | 鼓励学员掌握“评测先行”理念 |
| “给 5 万或 10 万做一个私有化 Chat”案例 | 驳斥“裸 API 即应用”误区 |
| 翻译工作流四步 | Workflow 拆解范式模板化案例 |
| 微调主因=成本 | 矫正“微调=提升效果”直觉偏误 |
12. 参考范式与能力映射汇总表
| 目标问题 | 直接症状 | 推荐范式组合 |
|---|---|---|
| 幻觉严重 | 编造引用 / 错事实 | RAG + 引用格式约束 + 答案自检 |
| 推理链缺失 | 跳步结论 / 逻辑跳跃 | CoT + 多轮反馈 + 自一致性 |
| 答案不稳定 | 不同次回答差异大 | Self-Consistency / 温度控制 / 多候选裁决 |
| 复杂任务拆解困难 | 一次性长指令失控 | Workflow 编排 + 子任务 Prompt |
| 工具调用混乱 | 参数错 / 步骤多余 | ReAct / 明确工具描述 Schema |
| 领域风格不符 | 语气 / 术语漂移 | Few-shot + Style Prompt / 领域词表注入 |
| 成本过高 | 大模型推理占比高 | LoRA 压缩 / Distill / 小模型代理 |
| 记忆丢失 | 跨轮偏好不连续 | Memory Store + 检索补注 |
13. 课程强调的核心共识性结论
- “预测下一个 token”是所有能力的源点,一切范式都是“控制概率分布”的工程。
- 模型缺陷不是“异常”而是“结构性必然”(信息压缩 + 静态训练 + 目标函数限制)。
- RAG 与 Tool Use 是对“知识缺失 + 实时性 + 精算精度”最具性价比的补偿手段。
- Agent 并非“魔法智能”,多数可落地能力仍建立在 ReAct + Workflow 之上。
- 多模态当前价值偏“增强输入维度”,全面通用理解仍受限于泛化与训练覆盖。
- 微调要先过三问:是否必要?是否高频共性?是否可被 Prompt / RAG 替代?
- 评测与迭代(构建评测集、错误分类)是工程质量闭环的“底座设施”,不能后置。
14. 参考文献
- LLaMA: https://arxiv.org/abs/2302.13971
- 1.5-Pints Technical Report: https://arxiv.org/abs/2408.03506
- Bridging Generative Models and System 1 with System 2
- A Systematic Survey of Prompt Engineering in Large Language Models: https://arxiv.org/pdf/2402.07927
- AlignBench: https://github.com/THUDM/AlignBench/blob/master/judge.py
- ReAct / Tool Use: https://arxiv.org/pdf/2302.04761
- RAG Survey: https://arxiv.org/pdf/2312.10997
- Agent 架构相关: https://arxiv.org/pdf/2401.03428
- 多模态相关: https://arxiv.org/pdf/2306.13549 / https://arxiv.org/pdf/2309.10020
总结
大语言模型的核心仍是“自回归概率预测”,其局限(幻觉、无规划、无长期记忆)是结构性必然。应用价值不在“直接调用”,而在通过 ==Prompt、CoT、RAG、Workflow、Tool Use、Agent、Memory、Fine-tuning ==的工程组合构建“增强型智能系统”,使其在业务链条中承担“可验证、可控、可组合”的子功能单元,从而实现提效与辅助创新。多模态发展仍受制于泛化与信息损失,其当前最佳定位是“附加输入/输出增强层”。研发落地的核心竞争力来自“数据与评测体系 + 工程范式设计”而非简单模型堆叠。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)