【信息科学与工程学】【安全领域】第十二篇 简述数据安全体系与保密技术
设计一个自适应窗口调整算法,本质上是为您的系统装备一个能够感知环境、智能决策的“自动驾驶”模式。核心在于明确您的核心目标(是优先延迟还是精度),然后据此精心设计触发条件和调整策略。
一、数据安全体系
1.1 数据安全体系考量
构建一个健全的数据安全体系,确实需要从基础加密算法到复杂的系统推理,乃至硬件底层原理进行通盘考量。

这个体系的核心目标,是确保数据在全生命周期内的机密性(未经授权无法访问)、完整性(防止被篡改)和可用性(授权时可正常使用)。
1.1.1 基础密码学算法
基础密码学算法是整个数据安全体系的基石,主要通过数学变换来保护数据的机密性和完整性。
-
对称加密算法:这类算法加密和解密使用同一把密钥,特点是速度非常快,适合加密大量数据。常见的算法包括AES(高级加密标准)和3DES(三重数据加密标准)。AES尤其被广泛认为是安全且高效的现代加密标准。其主要挑战在于如何将密钥安全地分发给通信双方。
-
非对称加密算法:这类算法使用一对密钥:公钥(公开)和私钥(自己保密)。用公钥加密的数据,只有对应的私钥才能解密,反之亦然。RSA算法是其中最著名的代表。非对称加密解决了密钥分发问题,但计算速度远慢于对称加密。
-
混合加密体系:为了平衡安全与效率,现代系统常采用混合加密。例如,使用RSA非对称加密来安全传递一个随机的会话密钥,然后使用AES等对称加密算法和这个会话密钥来加密实际传输的大量数据。数字签名技术也基于非对称加密,用于验证消息发送方的身份(认证)并确保消息在传输中未被篡改(完整性)。
1.1.2 AI与复杂推理安全
随着人工智能技术的广泛应用,数据安全面临新的挑战,也需要新的防护手段。
-
隐私增强技术:这些技术旨在让数据“可用不可见”。联邦学习允许在多个参与方在不交换本地数据的前提下,共同训练一个机器学习模型,从而保护各自数据的隐私。差分隐私则通过在数据查询结果中添加精心控制的噪声,使得无法从输出结果反推任何单个个体的信息。同态加密是一种更前沿的技术,允许在加密状态下直接对数据进行计算,而无需解密。
-
模型安全防护:AI模型本身也可能遭受攻击。对抗性攻击通过给输入数据添加人眼难以察觉的微小扰动,导致模型做出错误判断。防御方法包括对抗训练,即在模型训练时主动加入对抗样本,提升其鲁棒性。模型投毒则是在训练数据中植入恶意样本,破坏模型可靠性,需要在数据预处理和训练过程中进行严格检测。
-
AI增强安全:AI也能用于主动防御。可以利用机器学习模型来分析网络流量、用户行为等,智能地检测异常模式和潜在威胁,实现更主动的安全防护。
1.1.3 硬件与侧信道安全
数据安全不仅依赖于数学算法的强度,也需要关注物理和硬件层面的安全。
-
硬件安全模块:HSM是专用于保护和管理数字密钥的物理计算设备,能提供安全的加密运算环境,并防止密钥被非法提取。
-
可信执行环境:TEE通过处理器层面的硬件隔离技术,在设备中创建一个安全区域,保证内部的代码和数据在机密性和完整性上得到保护。
-
侧信道攻击与防护:这类攻击不直接攻击算法本身,而是通过分析设备运行时的功耗、电磁辐射、时间信息等物理特征来窃取密钥等敏感信息。例如,相关电磁分析(CEMA)就是通过分析密码芯片运行时泄漏的电磁信息来实施攻击的。防护措施包括采用具有抗侧信道攻击设计的硬件,或使用添加了随机掩码的算法实现。
1.1.4 数据安全体系的核心策略
构建一个可靠的数据安全体系,确实需要在方法、策略和流程上形成闭环,并有效应对篡改、泄露乃至残留数据(防记忆)等风险。
|
保护维度 |
核心目标 |
关键方法与策略 |
|---|---|---|
|
防篡改 |
保障数据的完整性,防止数据被未授权修改或破坏。 |
技术层面:哈希校验、数字签名、区块链存证;管理层面:严格的操作权限控制(最小权限原则)、操作日志审计。 |
|
防泄露 |
保障数据的机密性,防止数据被未授权访问和泄露。 |
数据分类分级;加密技术(传输与存储);数据脱敏;DLP系统;纵深防御(网络隔离、访问控制)。 |
|
防记忆(残留) |
保障数据彻底销毁,防止数据在废弃或转移后残留导致泄露。 |
数据销毁制度与流程;物理销毁(消磁、粉碎);逻辑销毁(多次擦写);数据生命周期管理(明确销毁节点)。 |
|
核心策略与流程 |
确保数据安全工作的系统性、持续性和有效性。 |
数据分类分级;全生命周期安全管理(从采集到销毁);纵深防御体系;常态化运营(培训、演练、审计、改进)。 |
防止数据篡改
确保数据在存储和传输过程中不被非法修改、破坏或删除是数据安全的基本要求。
-
技术保障:哈希校验和数字签名是验证数据完整性的核心技术。例如,对重要文件生成数字摘要,任何微小改动都会导致摘要值巨变,从而及时发现篡改。在一些对完整性要求极高的场景(如电子证据存证),区块链技术因其不可篡改的特性也被广泛应用。
-
管理流程:必须实施严格的权限管理,遵循最小权限原则,确保用户只能访问和操作其授权范围内的数据。同时,所有数据的访问和操作行为都应有详细、不可篡改的日志记录,以便事后审计和追溯。正如一些实践中所强调的,要实现操作“终身可追溯”。
防止数据泄露
数据泄露是当前面临的最主要威胁之一,需要从内外部同时着手进行防护。
-
数据分类分级是基石:这是所有防护措施的前提。首先要识别出真正的“宝贝”数据(通常敏感数据占比不超过10%),然后针对不同级别数据采取差异化防护策略,实现安全与效率的平衡。
-
加密与脱敏:加密是保护数据机密性的核心技术,包括数据传输加密(如SSL/TLS)和数据存储加密。对于需要共享或测试使用的数据,则采用数据脱敏技术,屏蔽敏感信息,实现“可用不可见”。
-
纵深防御与行为监控:构建覆盖网络、应用、主机和数据的纵深防御体系。部署数据防泄漏(DLP)系统,对数据流转进行监控和策略控制。通过安全审计系统,实时监测异常数据访问行为,实现事前预防、事中预警和事后追溯的闭环管理。需要特别注意平衡内外威胁,避免只重视外部黑客攻击而忽视内部泄密风险。
防止数据残留(防记忆)
数据在被删除或存储介质废弃后,其痕迹可能依然存在并可被恢复,因此需要彻底销毁。
-
建立数据销毁制度:明确数据销毁的责任、流程和标准。对于不同安全级别和存储介质的数据,规定相应的销毁方法。
-
物理与逻辑销毁:对于涉密程度高的数据或报废的存储介质(如硬盘),应采用物理销毁(如粉碎、消磁)等彻底破坏性手段。对于一般性数据,可采用逻辑销毁(如多次擦写覆盖)确保数据不可恢复。关键在于,数据销毁措施必须与数据分类分级结果相匹配。
构建安全流程与策略
上述所有方法的有效执行,都依赖于健全的策略和可持续的运营流程。
-
制度先行:建立完善的数据安全管理制度体系,包括数据安全管理办法、分类分级指南、操作流程规范等,使数据安全工作有章可循。
-
全生命周期管理:将安全措施嵌入数据的采集、传输、存储、处理、交换、销毁等每一个环节。例如,数据采集时要明确权责,传输时加密,存储时分类分级,共享时脱敏,销毁时彻底。
-
常态化运营:数据安全并非一劳永逸。需要定期进行安全风险评估和审计,开展员工数据安全意识培训和应急演练,并建立安全事件应急响应机制,形成持续的“规划-实施-检查-改进”(PDCA)闭环。
1.1.5 数据安全的硬件实现和多媒体技术融合
在数据安全领域,硬件实现和复杂的多媒体处理技术并非简单的“可选项”,而是构建 robust 防御体系的核心支柱。它们分别从“信任根基”和“认知维度”解决了纯软件方案难以克服的挑战。
|
安全维度 |
纯软件方案的局限性 |
硬件实现 + 复杂多媒体处理技术的优势 |
|---|---|---|
|
信任根基 |
依赖操作系统自身安全,易受底层(固件、BIOS)攻击。 |
建立硬件信任根,通过安全启动等技术确保从底层固件到上层应用的可信链路。 |
|
密钥安全 |
密钥存储在软件可访问的内存中,易被窃取。 |
密钥在安全芯片内部生成和存储,无法被外部读取。 |
|
随机数质量 |
伪随机数,可能存在规律,导致加密强度减弱。 |
真随机数发生器,基于物理熵源,不可预测,提升加密协议强度。 |
|
抗攻击能力 |
易遭受恶意软件、逆向工程等软件攻击。 |
可抵御物理攻击(如侧信道分析) 和软件攻击,提供更高安全级别。 |
|
处理性能 |
加密解密大量数据时会消耗大量CPU资源。 |
专用密码运算单元,高效卸载加密任务,提升系统整体性能。 |
|
内容理解深度 |
主要依赖关键词匹配,对非文本内容(图片、视频)的深层语义识别能力弱。 |
跨模态语义理解,能综合分析文本、图像、音频、视频的深层含义,发现潜在风险。 |
硬件构筑安全根基
硬件为数据安全提供了不可或缺的可信根基和物理屏障。
-
建立硬件信任根:系统启动时的初始可信基点至关重要。通过硬件技术(如英特尔平台的Boot Guard),可以确保系统从开机一刻起就运行在可信的软件环境中,有效防御针对启动过程的恶意软件。国产CPU厂商飞腾提出的PSPA架构规范,也强调了将安全机制内生于CPU设计流程,实现“关后门、堵漏洞”。
-
保障密钥安全:安全芯片能将涉及个人隐私、知识产权的敏感数据存储起来,并进行加密保护,且数据加解密的处理过程都在芯片内部,不易造成信息外泄。例如,海光CPU内置的安全处理器具备更高的安全权限,用于实现芯片的安全管理,其安全密钥由芯片厂商管理,并确保这些密钥在烧录、使用的各个阶段不会被泄露或者窃取。
-
提升抗攻击与运算性能:基于硬件的安全功能不仅能抵抗软件攻击,还能更好地抵抗物理攻击等硬件攻击。同时,采用硬件实现加解密,其计算处理性能通常有较大提升,并且可以降低密码运算对CPU主核运算资源的占用,从而提升整体运算速度。
多媒体处理深化认知
面对海量非结构化数据,安全产品需具备深度内容理解与风险洞察能力。
-
超越关键词的内容审核:传统的关键词匹配方式难以有效应对图像、音频、视频等非文本媒介中隐含的丰富信息,例如暴力、色情、恐怖主义象征等潜在违规元素。现代方案通过AI技术(如OCR、ASR、图像识别)将多媒体内容转化为机器可读的信息,并基于知识库与规则集自动执行内容安全性评估。
-
跨模态语义理解:跨媒体智能感知技术通过图像、音频和语义的向量化表示建立信息检索机制,利用向量空间模型进行跨媒体信息关联。这意味着系统能理解一段视频中画面、对话和字幕的整体含义,而不仅仅是孤立分析,从而更精准地识别复杂或隐晦的违规内容。
-
高效处理海量数据:面对视频等大数据量、计算资源消耗大的场景,可横向扩展的数据防泄漏系统会采用文件调度模块来监控各处理单元的状态并识别待处理文件的优先等级,据此设置处理顺序,并尽可能调用处于非占用状态的处理单元来进行文件的文本转换处理,从而提升在大数据量时的处理效率。对象存储服务(OSS)和智能多媒体服务(IMM)也为多媒体数据的存储和处理提供了可扩展的解决方案。
多媒体认知方法策略
在具体方法上,现代数据安全体系对多媒体内容的认知遵循一个分层深化的策略。
-
感知层:通过AI预处理模块将多媒体输入(视频、音频、图片等)转换为标准化的、更易于AI模型处理的数据格式(如单张图片、音频内容、文本内容等)。
-
识别与分析层:利用预先训练的深度学习模型对标准化后的多媒体内容进行全面扫描识别。例如,对单张图片进行LOGO识别、人脸识别、场景识别等,对音频内容进行语音识别(ASR),对文本内容进行分段/分句处理。
-
认知与决策层:通过大模型推理模块,将图像、音频和文本等不同模态的数据映射到同一高维特征空间,进行跨模态信息关联和深层次语义理解。规则匹配模块则基于知识库与规则集,对识别和推理得到的信息进行自动化内容安全性评估与判断。
简单总结
总而言之,数据安全产品走向硬件实现并集成复杂的多媒体处理技术,是应对当前和未来安全威胁的必然选择。硬件提供了坚固的“盾”,确保了安全基石的可靠;而先进的媒体认知技术则打造了锐利的“矛”,能够洞察数据深处的风险。这两者结合,共同构成了一个深度防御体系。
实践中的关键原则
在构建和维护数据安全体系时,以下几点原则至关重要:
-
纵深防御:不要依赖单一安全措施,而是在数据生命周期的各个阶段、系统的各个层面部署防御手段,形成多层屏障。
-
密钥管理:密码系统的安全性很大程度上依赖于密钥的保密性。必须对密钥的生成、存储、分发、轮换和销毁进行全生命周期的严格管理。
-
隐私保护设计:在系统设计和开发的最初阶段,就将隐私保护和数据安全作为核心原则嵌入其中,而非事后补救。
-
动态适应:安全威胁在不断演变,安全体系也需要具备动态学习和调整的能力,通过持续监控和评估来保持防御的有效性。
1.2 混合加密体系在网络安全中的应用
1.2.1 混合加密体系在网络安全中的应用
混合加密体系通过结合对称加密和非对称加密的优势,在网络安全领域发挥着核心作用。
|
应用场景 |
核心功能 |
混合加密实现方式 |
|---|---|---|
|
HTTPS/TLS(网站安全) |
保护浏览器与服务器间的数据传输 |
使用RSA或ECDH等非对称算法协商一个临时的会话密钥,然后使用AES等对称算法加密实际传输的数据。 |
|
端到端加密(E2EE) |
确保只有通信双方可读取信息,服务提供商也无法解密 |
发送方使用接收方的长期公钥加密一个临时生成的数据加密密钥,然后用该密钥加密消息本身。只有接收方的私钥才能解密出数据密钥。 |
|
安全文件传输与存储 |
加密文件内容,确保机密性 |
为每个文件随机生成一个文件加密密钥,用其对称加密文件内容,再用接收者的公钥加密该文件密钥,并与文件密文一同存储或传输。 |
|
安全外壳(SSH) |
为远程登录和管理提供安全通道 |
在连接握手阶段,使用非对称加密(如RSA)进行身份验证并安全地协商一个临时的会话密钥,后续所有通信由对称加密算法保护。 |
|
物联网(IoT)安全 |
保护资源受限设备与平台间的数据 |
采用HPKE等轻量级混合加密方案,非对称加密仅用于密钥交换环节,高效的数据传输由对称加密完成,兼顾安全与效率。 |
理解混合加密的优势
混合加密体系的核心思想是“扬长避短”:利用对称加密(如AES)算法速度快、效率高的优势,来加密实际要传输的大量数据;同时,利用非对称加密(如RSA)在密钥分发方面的安全性,来加密那个用于对称加密的、临时生成的会话密钥。这种分工完美解决了两个关键问题:
-
对称加密的密钥配送问题:无需在不安全信道中预先共享同一个密钥。
-
非对称加密的效率问题:避免直接用非对称加密处理大量数据导致的性能瓶颈。
构建高强度混合加密系统的关键
一个健壮的混合加密系统,其安全性依赖于多个组件的协同作用,而不仅仅是算法的简单拼凑。
-
高质量的随机数源:会话密钥必须由密码学安全的伪随机数生成器产生。如果随机性质量差,密钥容易被预测,整个系统的安全基础将崩塌。
-
算法强度与密钥长度平衡:需要采用高强度的对称加密算法(如AES-256)和公钥密码算法(如RSA-2048以上),并且两者的密钥强度应保持平衡。通常,考虑到密钥的长期价值,公钥密码的强度应略高于对称密码。
-
实现细节至关重要:
-
使用前向保密技术至关重要。这意味着每次会话都应使用独一无二的临时会话密钥。这样,即使服务器的长期私钥未来不慎泄露,攻击者也无法解密过去截获的通信记录。
-
对于对称加密,应选择安全的工作模式(如AES-GCM),并确保初始化向量的唯一性和随机性。
-
演进与展望
混合加密体系本身也在不断发展。例如,HPKE作为一种标准化的、更灵活的混合加密方案,正得到越来越广泛的应用,特别适合无需建立长连接的场景(如安全消息、邮件)。同时,为应对未来量子计算的威胁,后量子密码学的研究也与混合加密思路结合,探索使用能够抵抗量子攻击的算法来替代当前的RSA或ECC进行密钥协商。
1.2.2 Https混合加密
HTTPS协议中混合加密的工作流程,其核心思想是“扬长避短”:利用非对称加密的安全性解决密钥交换难题,再借助对称加密的高效率进行实际数据传输。
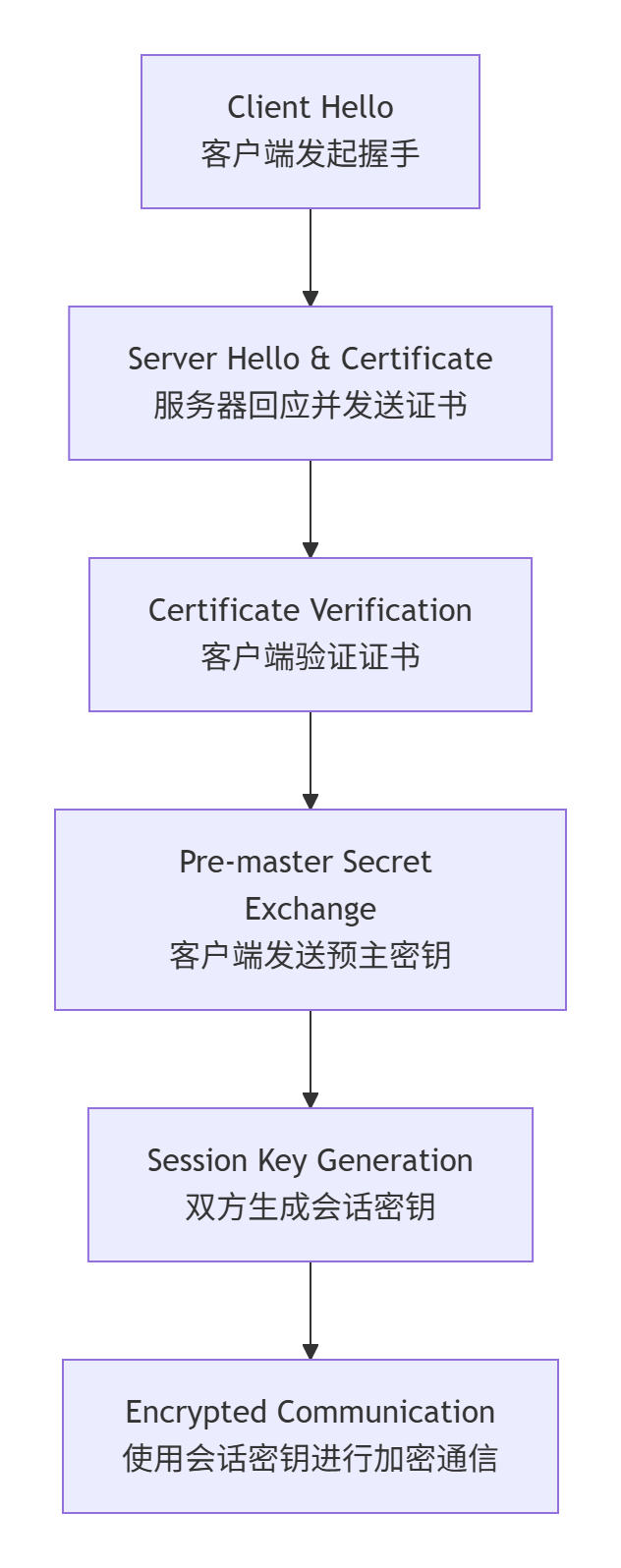
TLS握手详解
上图展示的流程,即TLS握手,是HTTPS安全通信的基础。这个过程确保了后续通信双方的身份可信,并协商出只有他们知道的“秘密钥匙”(会话密钥)。
-
发起通信请求(Client Hello)
当你访问一个HTTPS网站时,你的浏览器(客户端)会向服务器发送一个“Client Hello”消息。这个消息里包含了三个关键信息:客户端支持的TLS协议版本、一个由客户端生成的随机数(Client Random),以及一个支持的密码套件列表。
-
服务器响应与认证(Server Hello & Certificate)
服务器收到请求后,会返回一个“Server Hello”消息作为应答。消息中包含:双方共同支持的TLS版本、服务器生成的另一个随机数(Server Random),以及从客户端列表中选择的一个密码套件。紧接着,服务器会发送其数字证书。这个证书类似于服务器的“营业执照”,由全球公认的证书颁发机构签发,其中包含了服务器的公钥和身份信息。
-
验证证书与发送预主密钥(Certificate Verification & Pre-master Secret)
你的浏览器会严格验证收到的证书:检查签发机构是否可信、证书是否在有效期内、域名是否匹配等。验证通过后,浏览器会生成第三个随机数,称为“预主密钥”。然后用从证书中取出的服务器公钥对这个预主密钥进行加密,发送给服务器。只有持有对应私钥的服务器才能解密此消息,从而验证了服务器的身份。
-
生成会话密钥(Session Key Generation)
至此,客户端和服务器都拥有了三个相同的要素:Client Random、Server Random 和 Pre-master Secret。双方会使用相同的算法,基于这三个随机数生成唯一的会话密钥。这个密钥将是后续所有通信对称加密的钥匙。
-
准备加密通信
双方会互发一条“Change Cipher Spec”消息,通知对方:“之后的通信都将使用刚刚生成的会话密钥进行加密”。然后,再发送一条用会话密钥加密的“Finished”消息,让对方校验握手过程是否完整且未被篡改。
高效的数据传输
握手阶段完成后,安全的通道就已建立。此后,所有的HTTP请求和响应数据都会被会话密钥对称加密后传输。对称加密算法(如AES)效率极高,能够保证大量数据加密解密的速度。同时,每条加密信息都会附上消息认证码,用于验证数据的完整性,防止传输过程中被篡改。
关键安全特性
-
前向保密:先进的密码套件支持**前向保密特性。这意味着每次会话生成的Pre-master Secret都是独立的。即使有人截获并长期保存了加密流量,之后又破解了服务器的私钥,他也无法用这个私钥去解密之前任何一次会话的内容,因为每次的会话密钥都与这次临时的Pre-master Secret相关。
1.3 数据驱动决策的可视化媒体导致的数据安全风险和规避方法
在数据驱动决策的时代,可视化媒体极大地提升了数据的沟通效率,但同时也引入了新的安全风险。
1.3.1、可视化媒体数据处理方法与安全机制
可视化媒体的安全处理贯穿于数据生命周期的各个环节。
-
数据采集与预处理
在数据采集阶段,首先需要对敏感字段进行自动识别(如身份证号、手机号),并设置相应的敏感数据标签或级别。随后,根据匹配的脱敏规则(如部分替换、范围映射、格式转换)对敏感数据进行动态脱敏。例如,将手机号中间四位替换为星号 (
138****1234),或在可视化展示时将具体数值转换为区间范围(如将“年龄:25”展示为“年龄:20-30岁”)。 -
数据处理与加密
对于需要深度保护的可视化数据图像,可采用更强的加密算法。传统的AES、DES算法可能不足以保证图像加密的安全指标。此时,混沌图像加密 技术显示出优势,其利用混沌系统对初值的极度敏感性、非线性等特点,生成的序列随机性强、不可预测,能有效对抗各类攻击。此外,DNA编码等生物计算思想也可与混沌序列结合,进行动态编码和替代,进一步消除像素间的关联性。对于多媒体数据的渲染展示,可设计多媒体安全渲染引擎,通过沙箱技术、隔离技术等,防止恶意代码通过多媒体数据攻击系统。
-
可视化呈现与交互控制
在渲染层,利用如Apache ECharts等可视化库提供的标签格式化功能,对提示框(Tooltip)、轴标签等内容进行脱敏显示。在交互层面,实施严格的权限控制,根据不同用户角色(如管理员、运营人员、访客)动态控制数据的可见性及精细化操作权限(如查看、导出)。对于导出功能,需在导出前对数据进行安全检查或清除敏感信息。同时,记录详细的安全审计日志,监控异常操作行为(如非工作时间登录、高频访问敏感数据)。
1.3.2、核心原因与背景
对可视化媒体数据安全的高度重视,源于多方面深刻的现实原因。
-
数据价值的提升与攻击威胁加剧:数据已成为关键生产要素,媒体平台汇聚了大量用户信息、政务信息等敏感数据,自然成为不法分子攻击的目标。他们可能利用爬虫、撞库等技术窃取数据,甚至通过“内鬼”进行非法数据交易。
-
可视化数据的内在特性:与传统文本数据相比,图像、视频等可视化数据包含的信息更生动,信息量更大,冗余度更高,像素间相关性更强。这意味着传统的加密方法可能无法完全保证其安全指标,需要更专门和强大的安全措施。
-
媒体平台架构复杂化:媒体数据从孤立的业务系统转向云端平台和大数据中心进行汇聚、清洗、共享和应用,导致安全风险点和威胁路径增多。各类媒体App留存的敏感数据更易成为数据泄露的重灾区。
-
合规与监管要求:随着《数据安全法》、《个人信息保护法》等法规的深入实施,以及行业规范(如对政务新媒体委托运营的资质要求)的明确,组织在数据处理和展示方面必须满足严格的合规性标准。
1.3.3、安全设计原理
构建可靠的可视化媒体数据处理体系,应遵循以下核心设计原理。
-
数据最小化原则:仅收集、处理和展示完成特定目的所必需的最少量数据。在可视化前,应过滤掉非必要的敏感字段。
-
纵深防御原则:构建多层次的安全防护体系。例如,在数据采集时脱敏,在传输和存储时加密,在渲染时进行安全控制,在交互时进行权限校验和审计。即使某一层被突破,其他层仍能提供保护。
-
默认安全原则:系统应在默认配置下就是安全的。例如,默认对敏感数据进行脱敏或模糊显示,默认禁止高风险操作(如任意数据导出),而非依赖用户手动开启这些安全设置。
-
全程可审计原则:所有对数据的操作,特别是敏感数据的访问、导出、修改等行为,都应有清晰、不可篡改的日志记录,以便事后审计和追溯。
1.3.4、规避数据泄露的专项方法
除了上述机制和原理,还可以采取一些专项方法来规避特定风险。
-
规避媒体化方式泄露
-
权限动态分级与审批:建立细粒度的账号权限管理体系,针对不同角色(如超级管理员、区域操作员、外包人员)分配最小必要权限,并对关键操作(如内容发布、素材修改)设置多级审批流程。
-
内容安全审核前置:利用AI模型在内容发布前自动检测和拦截可能包含的违禁词、敏感信息或潜在侵权内容。
-
员工离职风控闭环:建立规范的账号交接“熔断机制”,包括提前冻结敏感权限、限期完成账号解绑、审计历史操作记录等。
-
数据输出严格控制:对数据导出行为进行严格监控和记录(如记录设备指纹和操作截图),并对导出的数据强制加密或添加隐形水印,以便溯源。
-
-
防范电磁信息泄露
这方面(如通过捕捉显示器电磁辐射还原屏幕图像)属于专业的物理安全(TEMPEST)范畴,技术要求极高,通常用于对安全有极端要求的场景(如军事、金融核心机房)。一般企业可参考的基础性措施包括:
-
使用电磁屏蔽设备:为关键计算机或视频线缆配备经过认证的电磁屏蔽罩或屏蔽袋。
-
保持安全距离:确保关键数据处理区域与公共区域或公司边界有足够的物理隔离距离。
-
规范设备报废:对存储过敏感数据的废旧显示器、投影仪等设备,进行专业的物理销毁,而非简单删除数据或格式化。
-
确保可视化媒体数据安全是一项系统工程,它要求我们在数据从采集、处理、展示到销毁的全生命周期中,综合运用技术工具与管理流程,构建多层次、纵深防御的安全体系。关键在于树立主动防护的意识,将安全措施内嵌于数据处理流程的每一个环节,从而在享受数据可视化带来便利的同时,有效守护数据安全。
1.4 不可克隆函数
1.4.1 物理不可克隆函数(PUF)
物理不可克隆函数(PUF)是一种巧妙利用硬件制造过程中产生的、无法复制的微观物理差异来生成唯一“数字指纹”的安全技术。
|
PUF 类型 |
核心原理 |
主要特点与应用方向 |
|---|---|---|
|
强PUF |
拥有海量的挑战-响应对(CRP),适用于身份认证。 |
挑战空间巨大,难以穷举;但部分类型可能面临机器学习建模攻击的威胁。 |
|
弱PUF |
挑战-响应对数量有限,通常用于密钥生成。 |
资源开销相对较小,非常适合于为加密算法生成根密钥。 |
|
SRAM PUF |
利用标准静态随机存储器(SRAM)上电时的随机初始状态。 |
无需专用硬件,利用现有标准组件,是应用最广泛的PUF类型之一。 |
|
仲裁器 PUF |
比较信号在一对对称路径中的传播速度差异。 |
结构简单,但可能对机器学习建模攻击较为脆弱。 |
|
环形振荡器 PUF |
比较多个环形振荡器的频率差异。 |
|
|
光学 PUF |
利用激光照射特殊材料产生的随机散斑图样。 |
通常用于安全级别极高的场景。 |
PUF在不同介质场景的应用
PUF的价值在于其能够为不同类型的设备和介质提供内置的、高强度的安全身份。
-
芯片与集成电路:这是PUF最核心的应用领域。在芯片制造过程中,利用其内部固有的SRAM PUF或环形振荡器 PUF,可以为每一颗芯片生成一个独一无二且无法克隆的密钥。这个密钥无需存储在非易失性存储器中,从而从根本上避免了密钥被物理提取的风险,常被用作设备的硬件信任根,为安全启动、安全加密等关键操作提供基础。
-
存算一体芯片与边缘智能:在前沿的存算一体架构中,PUF被直接集成到计算单元内部。例如,北京大学的研究团队成功在电阻式随机存取存储器(RRAM)存内计算阵列上实现了PUF。这种深度集成可以在进行神经网络推理的同时,保护模型的权重、结构以及输入数据的隐私,为边缘侧的人工智能计算提供了强大的知识产权保护和数据安全方案。
PUF在网络与算力网络中的应用
在网络传输领域,PUF为解决设备身份认证和数据源真实性这一核心问题提供了新思路。
-
设备身份认证与安全通信:在工业物联网(IIoT)中,现场的传感器和设备资源有限且环境复杂。基于PUF可以实现轻量级的双向认证机制。例如,监控中心的PLC(可编程逻辑控制器)可以向传感器发送一个挑战(Challenge),传感器利用其内部的PUF生成响应(Response)并返回。通过验证响应是否正确,PLC即可确认传感器的合法性,从而有效防止恶意节点接入。同时,基于PUF产生的密钥可以用于建立安全通信通道(如TLS)或生成消息认证码(HMAC),保障传输数据的机密性和完整性。
-
在算力网络中的安全价值:算力网络的核心是实现计算资源的动态调度与共享。在这一场景下,PUF技术能发挥关键作用:
-
节点可信认证:确保加入算力网络的每一个计算节点(如边缘服务器、智能终端)都是可信的实体,防止算力资源被恶意占用或污染。
-
任务与数据溯源:通过PUF唯一标识任务的发起者和执行者,为算力任务的执行过程提供不可篡改的溯源能力。
-
安全资源编排:将节点的PUF身份信息与其可信状态、安全策略关联,作为算力资源调度决策的一个重要维度,从而实现“安全可控”的算力调配。
-
挑战与应对
尽管PUF优势显著,但在实际应用中仍需应对一些挑战:
-
环境敏感性:温度、电压波动可能导致PUF响应产生比特错误。
-
解决方案:采用模糊提取器技术,结合纠错码(如BCH码),可以从带有噪声的PUF响应中稳定地重建出一致的密钥。
PUF技术将物理世界的不可克隆性转化为数字世界的安全基石,为从芯片、边缘设备到算力网络等各种场景提供了轻量级、高强度的安全解决方案,特别是在构建动态、可信的未来网络基础设施方面潜力巨大。
1.4.2 物理不可克隆函数(PUF)为5G/6G网络中各类设备的身份认证解决方案
物理不可克隆函数(PUF)凭借其轻量级、高安全的特性,为5G/6G网络中各类设备的身份认证提供了新颖的解决方案。
PUF认证的核心价值与流程
PUF技术的核心优势在于,它利用芯片制造过程中产生的、无法复制的微观物理差异,为每个设备生成独一无二的“硬件指纹”。这意味着密钥无需存储,而是按需动态生成,从而从根本上避免了密钥被提取或克隆的风险,特别适合资源受限的物联网设备、无人机等场景。
一个典型的基于PUF的设备身份认证流程,涉及设备、网络接入点(如基站或网关)以及认证服务器之间的协作,其核心交互过程可概括为以下环节:
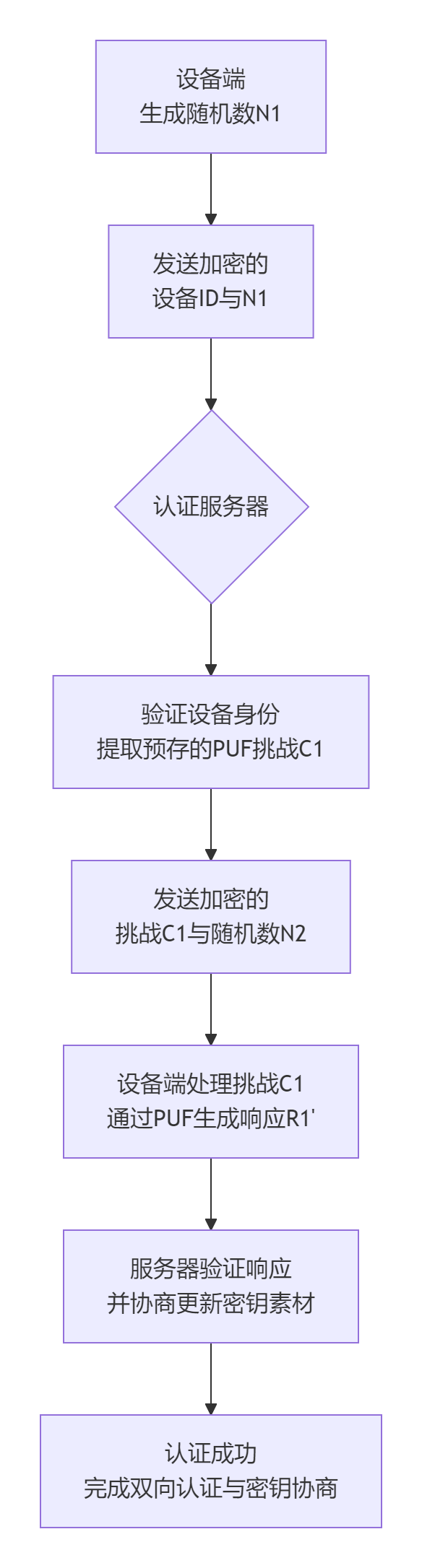
具体到一次完整的认证交互,其关键步骤包括:
-
设备发起请求:设备端生成一个随机数(N1),并用其加密设备标识(ID),然后向认证服务器发送请求。
-
服务器下发挑战:服务器验证设备身份后,从数据库中提取与该设备绑定的PUF挑战值(C1),并生成另一个随机数(N2),一并加密后发送给设备。
-
设备生成响应:设备接收到挑战C1后,将其输入自身的PUF电路,产生一个唯一的响应值(R1')。由于PUF的物理特性,只有合法的设备才能生成正确的响应。
-
验证与密钥更新:设备将响应R1'加密后送回服务器。服务器将其与预存的或计算出的期望响应进行比对(允许一定的容错阈值)。验证通过后,双方可基于此次交互的随机数等参数生成安全的会话密钥。为增强前向安全性,服务器可能会触发挑战-响应对的更新,即协商一个新的挑战值(C2)用于下一次认证。
网络部署方案
在不同的5G/6G网络场景中,PUF技术的集成方式各有侧重:
-
大规模物联网场景:针对海量的低功耗物联网设备,可以采用云边协同的认证架构。边缘节点负责处理频繁的PUF挑战-响应验证,减轻云端压力;云端则负责统一管理设备凭证、安全策略和核心密码算法参数。中国联通推出的“犀甲认证”系统即是此类方案的代表,实现了跨省份、跨行业的规模部署。
-
高动态性场景(如无人机、车联网):在无人机辅助的星地一体化网络或车辆通信中,设备移动性强,网络切换频繁。PUF可用于实现快速切换认证。当设备从一个网络节点切换到另一个时,可以利用PUF进行快速重认证,显著降低切换时延和信令开销,确保通信的连续性。
-
非地面网络(NTN)场景:在6G时代重要的卫星通信等NTN场景中,链路延迟长、带宽有限。将PUF认证功能部署在卫星终端或地面信关站,可以实现本地化的快速身份验证,减少与远程中心认证服务器之间的交互,提升效率。
技术实现考量
在实际部署PUF技术时,还需要重点解决以下挑战:
-
提升响应稳定性:环境变化(如温度、电压波动)可能导致PUF响应产生比特错误。为了解决这个问题,可以引入模糊提取器技术,通过纠错码(如BCH码)来从带有噪声的PUF响应中稳定地重建出一致的密钥。
-
增强抗攻击能力:为防止攻击者通过收集大量挑战-响应对来构建PUF的数学模型,需要设计抗建模攻击的PUF电路结构。例如,有研究提出基于延迟差量化的PUF结构,通过增加非线性特性来有效抵御机器学习建模攻击。
总结与展望
总而言之,PUF技术为5G/6G网络提供了一种从硬件层面构建信任根的安全思路。通过将其与具体的网络架构和业务场景深度融合,能够为万物互联的庞大设备群体提供轻量、高效且高安全性的身份认证保障。
1.4.3 物理不可克隆函数(PUF)与5G/6G现有认证框架的协同
物理不可克隆函数(PUF)与5G/6G现有认证框架的协同,为解决海量物联网设备的身份安全提供了一个非常前沿且坚固的思路。下面这个表格梳理了PUF认证方案与5G/6G网络认证框架协同工作的核心模式与接口。
|
协同层面 |
核心工作模式 |
在5G/6G认证框架中的角色与交互 |
|---|---|---|
|
终端侧增强 |
PUF作为硬件信任根 |
在终端设备内部,PUF电路取代或辅助传统种子密钥。当需要认证时,终端并非直接发送存储的密钥,而是由认证服务器下发一个挑战(Challenge),设备利用PUF电路根据此挑战和自身物理特征动态生成响应(Response)。该响应作为认证凭据之一,有效避免了密钥在终端非易失性存储器中被提取的风险 。 |
|
网络侧集成 |
PUF作为增强的认证方法 |
在5G-AKA流程中,PUF可以作为一种增强的认证方法集成到认证服务器(如AUSF/UDM)中。网络侧可以存储与每个设备PUF对应的挑战-响应对(CRP),或者支持更先进的机制(如基于PUF响应的密钥派生),从而在标准的AKA流程中完成对设备硬件“指纹”的验证 。 |
|
架构创新 |
与新型密码原语结合 |
为解决海量设备带来的预存储挑战-响应对(CRP)的存储开销问题,有研究提出将PUF与变色龙哈希函数等密码原语结合的新架构。在这种架构中,PUF用于本地生成或保护密钥材料,而变色龙哈希函数等则用于实现无需预存大量CRP的、高效的远程认证和密钥协商,更适合6G网络中海量无人值守终端的安全接入与快速切片切换 。 |
协同工作原理详解
PUF与5G/6G-AKA的协同工作,可以理解为在标准的认证流程中,嵌入了一个基于硬件“指纹”的增强验证环节。其核心思想是利用PUF产生的设备唯一性标识,来强化传统认证流程 。
-
终端侧的增强:在设备制造或初始化阶段,会采集其PUF的“指纹”信息,并在网络的认证服务器中安全地注册相关的挑战-响应对(CRP)或生成密钥所需的参数。当设备尝试接入5G/6G网络时,除了执行标准的5G-AKA流程(包含对用户身份的认证)外,认证服务器可以发起一个针对设备硬件的二次挑战。设备利用其内置的PUF电路,根据收到的挑战实时生成一个响应并返回。服务器通过比对预期的响应,来验证该设备是否是“正品”硬件,而不仅仅是持有合法用户身份凭证的终端 。
-
网络侧的集成:这种PUF认证过程可以与5G-AKA流程有机融合。例如,认证服务器(AUSF/UDM)可以支持将PUF认证作为一种可选的、增强的认证方法。在进行5G-AKA相互认证的同时,可以并行或顺序地执行PUF设备认证,从而实现对“用户身份”和“设备硬件”的双重绑定验证,极大提升了安全性 。
标准化接口现状
目前,PUF与5G/6G核心网的集成尚未有官方的、强制性的国际标准(如3GPP标准)。当前的集成方式更多是增强型和研究型的 。
-
增强现有框架:产业界的一种实践思路是,将PUF认证作为在用户面安全建立之后,应用于特定垂直行业(如工业物联网)的二次认证。设备先通过标准的5G-AKA接入网络,随后在访问关键业务(如工厂控制系统)时,业务平台再发起一次基于PUF的设备身份强认证。
-
面向未来的架构:学术界和工业界正在积极探索更深度的融合方案,例如前文提到的基于PUF和变色龙哈希的架构,旨在为6G时代的海量、资源受限的无人值守终端(如传感器)提供原生支持的高效、抗物理攻击的认证方案。这些研究为未来的标准制定提供了重要的技术参考 。
总结与前景
总而言之,PUF认证方案与5G/6G现有认证框架的协同,代表了从“软件安全”向“硬件内生安全”演进的重要方向。它通过将安全根植于硬件的物理特性中,显著提升了设备身份的可信度。
虽然完全的标准化集成仍在演进中,但通过作为现有认证框架的增强手段,或与新型密码技术结合构建面向未来的轻量级安全架构,PUF技术在应对5G/6G网络,特别是物联网场景下面临的设备伪造、密钥泄露等安全挑战方面,展现出巨大的应用潜力。
1.4.4 物理不可克隆函数(PUF)与变色龙哈希函数结合
将物理不可克隆函数(PUF)与变色龙哈希函数结合,是解决海量物联网设备身份认证和密钥管理难题的一个非常巧妙且前沿的思路。它核心上是将硬件的唯一性与密码学的灵活性相结合。
核心架构设计
这种融合架构的核心思想,是让设备内置的、不可克隆的物理特征(PUF)成为生成其唯一“身份”的根源,然后利用变色龙哈希的特性,使与这个身份绑定的密码学操作(如签名)具备可控的灵活性。其典型架构和关键组件如下图所示,它清晰地展示了从硬件信任根到上层安全服务的完整流程:
flowchart TD
A[设备制造端] --> B[“设备唯一物理特征<br>(PUF)”]
B --> C[“生成阶段<br>产生初始响应R与辅助数据H”]
C --> D[“密钥生成<br>派生唯一设备密钥对(pk, sk)”]
D --> E[“安全存储<br>仅保存辅助数据H与公钥证书”]
E --> F[设备运行端]
F --> G[“重现阶段<br>利用PUF及H重现密钥”]
G --> H[“变色龙哈希计算<br>对消息m生成哈希h”]
H --> I[“签名与验证<br>生成变色龙签名”]
I --> J[“争议解决<br>必要时生成碰撞证明”]
E -- 设备出厂 --> F要实现上图所示的流程,该系统主要包含以下几个关键组件和步骤:
-
PUF模块:这是硬件信任根。它利用芯片制造过程中产生的、无法复制的微观物理差异,在受到挑战(输入)时产生唯一的、具有噪声的响应(输出)。常见的实现方式包括基于环形振荡器的PUF或利用SRAM上电状态的PUF等。
-
模糊提取器:由于PUF响应存在噪声,直接用于生成密钥不稳定。模糊提取器(通常包含纠错码,如BCH码)的作用就是从带噪声的PUF响应中稳定地再生出一致的密钥。
-
变色龙哈希函数:这是架构的“智能”部分。它与传统哈希函数的关键区别在于,掌握陷门密钥(通常与设备私钥
sk关联)的人,可以为不同的消息m和m'找到两个不同的随机数r和r',使得Ch_Hash(pk, m, r) = Ch_Hash(pk, m', r')。这意味着,一个签名可以被“改变”而无需使签名密钥失效。
解决海量CRP存储问题
挑战-响应对(CRP)存储爆炸是传统PUF大规模应用的主要瓶颈。想象一下,每个设备都有海量的CRP,管理中心需要为亿万设备存储天文数字般的CRP,这是不现实的。PUF与变色龙哈希的结合,通过以下几种方式从根本上解决了这一问题:
-
从“存储CRP”到“按需生成密钥”
架构的核心理念是不再预存储大量的CRP。相反,只在需要时(例如在安全启动或认证过程中),向设备发送一个挑战(这可以是一个随机数),设备利用其PUF和模糊提取器动态生成本次会话所需的密钥材料。服务器端无需存储每个设备对应的具体响应,只需验证其签名或加密结果即可。这极大地减轻了服务器的压力。
-
变色龙哈希的“密钥解放”效应
变色龙哈希函数引入了一个关键能力:密钥的可控重构。即使设备的密钥材料是基于PUF动态生成的,如果该密钥需要更新或撤销,传统的方案可能非常复杂。而在这里,由于变色龙哈希的陷门与设备密钥绑定,可以通过发布一个新的变色龙哈希碰撞(新的随机数
r'),来实质上宣告旧的消息(或旧密钥状态)失效,并关联到新的状态,而无需物理更换PUF或重新初始化设备。这为实现高效的密钥生命周期管理(如撤销、更新)提供了可能,避免因密钥变更而导致需要重新存储大量新数据。 -
与新型数据结构的结合
为了高效管理这些可撤销的凭证,可以引入更先进的数据结构。例如,研究提出了基于变色龙哈希的区块树。这种结构是一种平衡搜索树,利用变色龙哈希函数的特性,仅用一棵树就能实现证书的高效加入和撤销,其查询、加入和撤销操作的时间复杂度均为对数级别,非常适合海量设备场景。
架构优势与挑战
这种融合架构带来了显著优势:
-
增强的安全性:私钥等关键信息从未以静态形式存储,而是用时才在设备内部生成,有效对抗物理攻击和密钥提取。
-
提升的可管理性:支持安全的远程密钥更新和撤销,解决了PUF密钥一旦暴露难以更新的问题。
-
降低的运营成本:解决了CRP存储难题,使基于PUF的安全方案能够扩展到数十亿级别的物联网设备。
当然,这种架构也面临一些挑战:
-
实现复杂度:需要集成硬件(PUF)和密码学(变色龙哈希)组件,设计复杂度较高。
-
计算开销:变色龙哈希的计算可能比传统哈希更耗时,需优化或采用专用硬件加速。
-
标准化进程:目前这类融合方案仍多处于研究和专利阶段,大规模的行业标准和互操作性认证尚在发展之中。
1.4.5 变色龙哈希的区块树(如CHACT机制)
基于变色龙哈希的区块树(如CHACT机制)实现高效证书撤销的核心,在于巧妙地将变色龙哈希的可编辑性与平衡搜索树的高效查询相结合,从而解决了传统证书撤销列表(CRL)或某些区块链方案存在的存储开销大、查询效率低的问题。
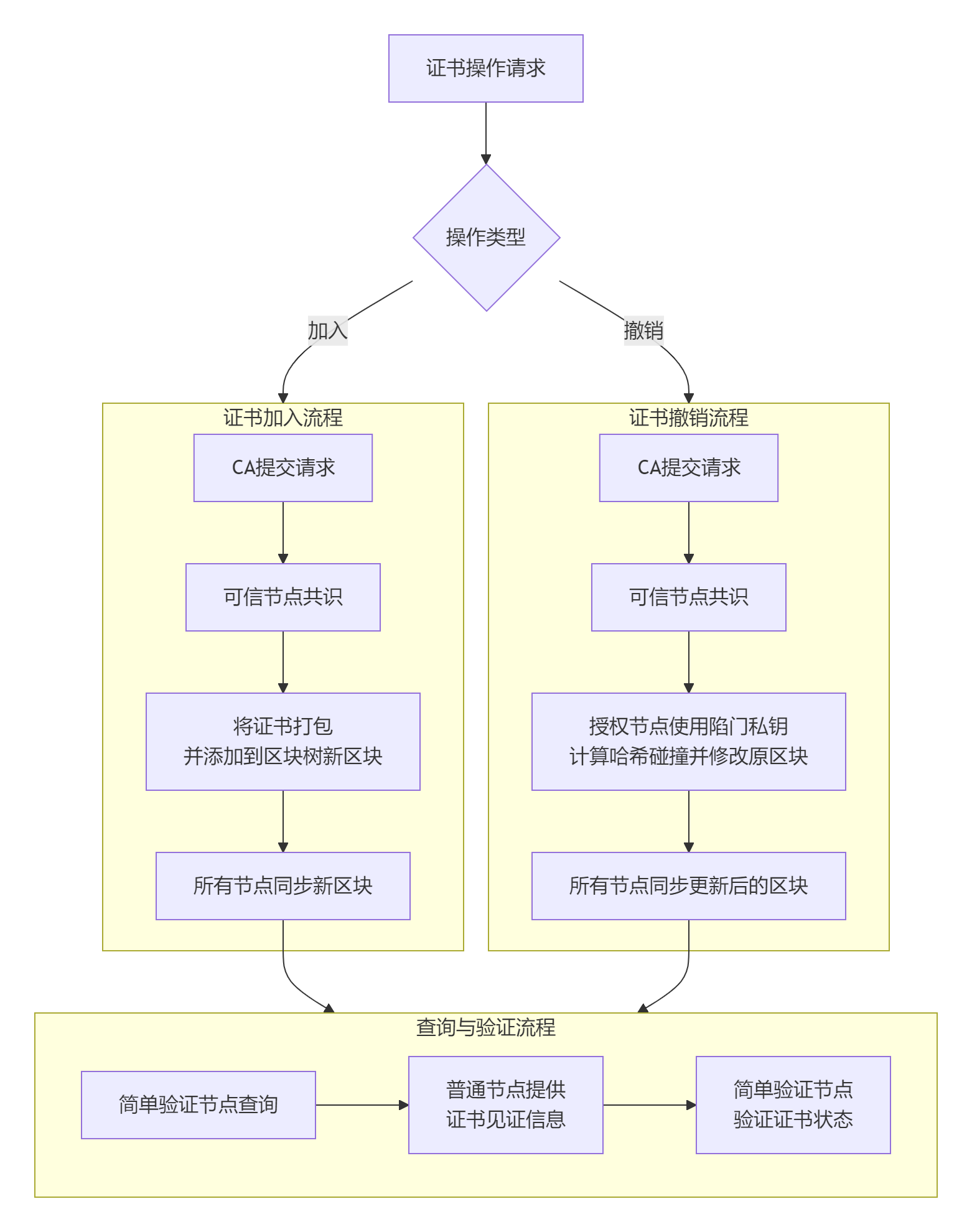
其核心工作流程涉及多个参与方(用户、CA、不同类型的区块链节点)的协同操作。为了更直观地展示这一过程,下图概括了证书从加入、撤销到验证的关键步骤与数据流向:
下面,我们重点剖析证书撤销和查询这两个关键操作的具体流程。
证书撤销流程
证书撤销的核心是“编辑”而非“追加”。这意味着无需新增区块来记录撤销信息,而是直接修改存储原始证书的区块内容。
-
触发撤销请求:证书所有者或CA机构向系统提交证书撤销请求。
-
共识与授权:系统中的可信节点(ST)对撤销请求进行验证并达成共识。获得授权后,掌握变色龙哈希陷门私钥(或其在门限秘密共享方案中的份额)的节点可以执行修改操作。
-
计算碰撞与修改区块:这是最关键的一步。授权节点运行
CertRevoke()算法,利用陷门私钥为待撤销的证书计算一个哈希碰撞。-
简单来说:原始区块中存储了证书信息
m和一个随机数r,其哈希值为H。撤销时,节点将区块内容修改为标记为“已撤销”的新信息m'(例如,设置一个撤销状态位),并利用陷门私钥计算出一个新的随机数r',使得Hash(m', r')的结果仍然等于原来的哈希值H。 -
效果:区块的内容被成功修改(证书状态更新为“撤销”),但该区块的哈希值却保持不变。因此,它之后的所有区块都无需改动,整个区块链的历史完整性得以维持。
-
-
节点同步:区块修改后,网络中的普通节点(SO)和简单验证节点(SV)将同步更新后的区块信息。
证书查询流程
得益于区块树的平衡搜索树结构,证书查询和验证非常高效。
-
发起查询:简单验证节点(SV,通常是资源受限的客户端)需要验证某个证书的状态时,向普通节点(SO)发起查询请求,并提供证书标识。
-
生成见证信息:普通节点(SO)在区块树中定位到包含该证书的区块。由于树是平衡的,这个查找过程的时间复杂度是对数级别的(O(log n)),非常高效。找到后,节点会生成一个“见证信息”(Witness),该信息通常包含从目标区块到树根的路径上所有相关兄弟节点的哈希值,形成一个Merkle证明。
-
验证证书:简单验证节点(SV)收到见证信息后,运行
CertVerify()算法。它利用本地存储的创世区块哈希(根哈希)和收到的见证信息,通过重算哈希路径来验证目标证书的当前状态是否真实有效。如果路径一致,则证明证书状态未被篡改。
总结与优势
通过上述流程,基于变色龙哈希的区块树实现了高效的证书管理:
-
存储效率高:无需维护庞大的CRL,撤销信息直接“原位”更新,节省链上空间。
-
操作效率高:基于平衡树的查询和更新操作均具有对数时间复杂度,适合大规模证书管理。
-
安全可信:修改需经共识授权,且任何修改都可被拥有根哈希的节点验证,在去中心化和可审计之间取得了良好平衡。
这种设计特别适合对可扩展性和查询性能有高要求的联盟链场景,例如大规模物联网设备身份管理。
1.4.6 门限控制方案
门限控制方案的核心思想,是将一把完整的陷门私钥(通常对应一个强大的权限)拆分成多个分片,由不同的节点保管。任何单个节点都无法独立完成签名,必须达到预设数量的节点合作才能生成有效签名。这有效避免了单点故障和权力过度集中的风险。
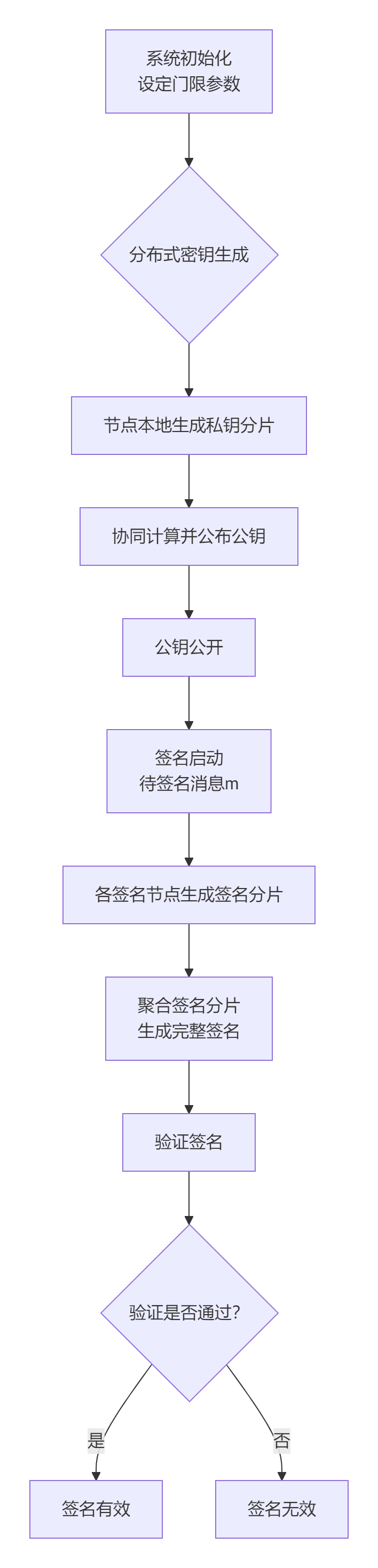
下面,我们详细拆解图中的几个关键阶段。
分布式密钥生成
这是所有流程的起点,目标是共同生成一个主公钥和分散在各节点的私钥分片,而自始至终不产生一个完整的、可被单点掌握的陷门私钥。
-
系统初始化:所有参与节点约定椭圆曲线等公共参数,并设定门限参数
(t, n),即总共n个节点,只要凑齐不少于t个节点即可合作签名。 -
生成私钥分片:每个节点
i在本地随机生成自己的私钥分片sk_i,并保密。这个过程是分布式的,无需一个中心化的“密钥颁发机构”。 -
计算并交换公钥组件:每个节点用自己的私钥分片
sk_i计算对应的公钥分片P_i = sk_i * G(其中G是椭圆曲线的基点),并将其广播给其他节点。 -
协同计算主公钥:所有节点在收集到足够的公钥分片后,通过特定的算法(如拉格朗日插值)协同计算出一个统一的系统主公钥 PK。对外,系统只有一个公钥
PK,验证签名时也只需使用这个公钥。
协同签名流程
当需要对一条消息 m进行签名时,流程如下:
-
发起签名请求:任一获得授权的节点可向网络广播对消息
m的签名请求。 -
生成签名分片:每个参与签名的节点
i(至少需要t个)使用自己的私钥分片sk_i 和消息m,在本地独立计算出一个部分签名(或签名分片)σ_i。常见的部分签名生成方法包括基于拉格朗日插值的秘密共享方案,确保只有凑齐至少t个分片才能恢复出有意义的签名。 -
(可选)验证签名分片:在一些方案中,节点生成部分签名后,可以相互交换并验证彼此分片的正确性,以确保没有节点恶意提交错误分片破坏签名。
-
聚合签名分片:当一个节点(可以是参与签名的节点之一,也可以是一个指定的聚合器)收集到至少
t个有效的部分签名σ_i后,便利用聚合算法将这些分片合成为一个完整的、有效的标准数字签名σ。整个过程中,完整的陷门私钥从未在任何节点上被重构或出现。
核心优势与安全特性
这种门限控制方案带来了显著的安全提升:
-
避免单点故障和权力集中:私钥分片分散存储,攻击者需同时攻破至少
t个节点才能窃取私钥,极大增加了攻击难度。 -
提升系统可靠性:即使部分节点(少于
t个)故障或离线,系统仍能正常产生签名,具备容错能力。 -
实现分布式控制与信任:签名权力被分散,决策需要多数参与方同意,适合联盟链或需要多方共同管理的场景。
挑战与注意事项
尽管门限方案很强大,但其实现也面临一些挑战:
-
通信开销:节点间需要多次交互,可能影响性能。
-
复杂性:协议设计和使用都比单钥方案复杂,更易因实现不当引入漏洞。
-
密钥管理:需要安全存储私钥分片,并设计完善的节点动态(如增加、删除)机制。
1.4.7 变色龙哈希的区块树 vs CRL和OCSP
基于变色龙哈希的区块树在证书撤销的效率和可扩展性上相比传统的CRL和OCSP方案有显著优势。下面这个表格直观对比了它们在核心性能指标上的关键差异。
|
性能指标 |
传统CRL |
传统OCSP |
基于变色龙哈希的区块树 |
|---|---|---|---|
|
吞吐量 |
低,周期性发布完整列表,峰值压力大 |
中,依赖在线响应器性能,易成瓶颈 |
高,利用平衡树结构实现高效查询(O(log n)),分布式验证分散压力 |
|
延迟 |
高,依赖CRL发布周期,存在延迟窗口 |
低(理想情况下),实时单证书查询 |
低(验证方),查询路径短;中(撤销操作),需共识与计算碰撞 |
|
扩展性 |
差,列表随撤销证书数量线性增长 |
一般,响应器性能和带宽受限 |
好,区块链结构分布式存储,结合IPFS等链下存储方案应对数据增长 |
|
核心机制 |
推送完整的撤销列表 |
在线响应“查询-响应” |
区块链上的可编辑、可验证状态 |
如何选择证书撤销方案
了解这些差异后,在实际应用中你可以这样考虑:
-
传统CRL:适用于内部网络、设备数量有限或对实时性要求不高的封闭场景。其优点是简单、离线可验证,但需接受其固有的延迟。
-
传统OCSP:适用于用户直接访问的Web服务、金融交易等对延迟敏感且证书数量不多的场景。需要注意响应器的可靠性和隐私泄露风险。
-
基于变色龙哈希的区块树:非常适合大规模、分布式物联网设备管理、联盟链环境下的数字身份系统等场景。它在可扩展性、抗审查和透明度方面优势明显,但技术相对复杂,且依赖于底层的区块链网络性能。有研究指出,通过改进的共识算法(如基于信誉度的PBFT改进算法),可以进一步提升此类区块链系统的吞吐量和降低共识时延。
1.4.8 优雅应对节点动态加入和退出的密钥分片更新机制
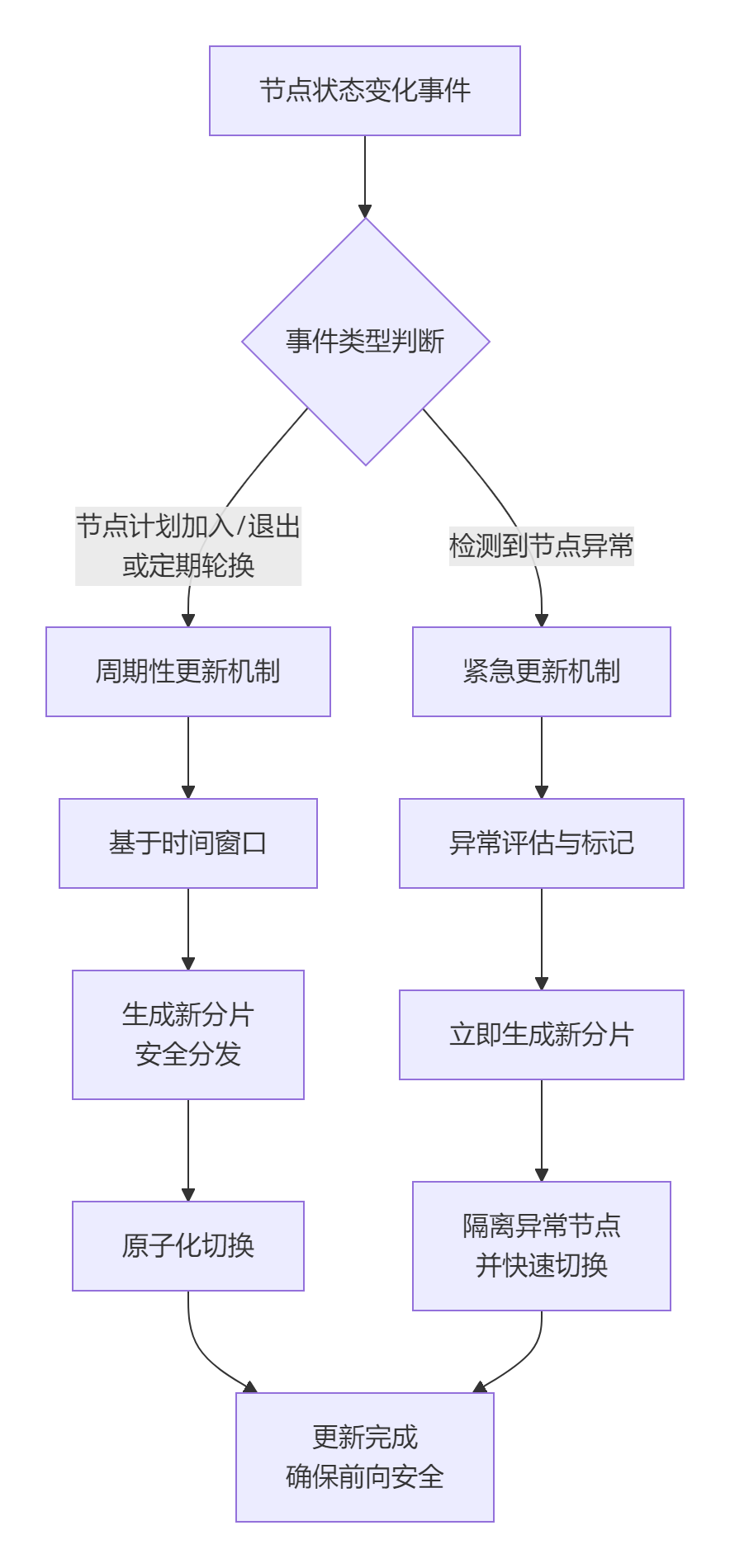
在实际部署中,设计一个能优雅应对节点动态加入和退出的密钥分片更新机制至关重要。这不仅能提升系统的灵活性和可扩展性,更是应对潜在安全威胁、防止密钥泄露的核心策略。
。
周期性更新机制
周期性更新是系统的“常规体检”,无论节点是否主动加入或退出,它都会按照预定计划进行,旨在防患于未然。
-
基于时间窗口的轮换:系统会定义一个时间窗口(例如,以小时或天为单位)和轮换周期。通过公式
t = floor((t_now - t_0) / Δt)计算当前有效的时间窗口编号t,其中t_now是当前时间,t_0是初始化时间,Δt是轮换周期。每个时间窗口t都对应一套独立的密钥分片sk_{t,i},从而实现了密钥的版本化管理 。 -
新分片的生成与分发:当进入新的时间窗口,系统会利用分层确定性算法和主密钥
sk_master,为每个有效节点生成新的分片私钥,例如通过公式sk_{t,i} = HMAC-SHA256(sk_master, t || i) mod p。新分片通过安全信道分发至各节点。为确保平滑过渡,通常采用原子化切换策略,即在某个特定时刻,所有节点几乎同时启用新分片,废弃旧分片,避免因切换不同步导致签名失败。
紧急更新机制
当系统检测到节点异常(如被入侵、故障或恶意行为)时,会立即启动紧急更新机制,这是系统的“紧急抢险”。
-
异常检测与评估:系统依赖于入侵检测机制或AI异常检测模型来实时监控节点的行为数据(如CPU使用率、在线时长、签名请求频率等)。一旦某个节点的行为偏离正常模式,其异常得分
s_i超过预设阈值ex_i,该节点就会被标记为存在异常风险 。 -
即时响应与分片轮换:确认异常后,系统会生成一个临时时间窗口标识符
t',并立即为所有未标记为异常的节点生成一套全新的密钥分片 。同时,系统会隔离异常节点,剥夺其参与签名的权限,防止其继续造成损害。这个过程强调速度,以最快速度消除异常节点带来的风险。
确保更新过程的安全
无论哪种更新方式,都必须保障过程本身的安全可靠。
-
维护前向安全:这是密钥更新机制的核心目标之一。即使在当前时间窗口的密钥分片
sk_{t,i}不慎泄露,攻击者也无法逆向计算出过去时间窗口的旧分片sk_{t-1,i}, sk_{t-2,i}, ...或系统的主密钥sk_master。这得益于在轮换时使用前向安全哈希链进行验证,例如h_t = H(h_{t-1} || sign(sk_t, h_{t-1})),使得每个时间窗口的密钥相互独立且不可逆 。 -
安全的子密钥更新算法:在分布式CA等场景中,当管理者节点集合发生变动时,会采用安全的子密钥更新算法。例如,利用拉格朗日插值法,由未变动的节点集合B协同计算,使得退出节点集合A持有的旧子密钥失效,并为新加入的节点集合C安全地生成新的子密钥,而无需重构CA的主私钥 。
节点信用与门限调整
为了增强系统的自适应能力,可以引入更智能的动态管理策略。
-
节点信用评估体系:系统可以为每个节点维护一个信用值(例如,基于节点被指控异常行为的次数和指控来源的可信度进行计算)。节点的信用状况可以作为其能否成为密钥分片保管者(管理者节点)的重要依据,信用值排名靠前的节点更可能被选为管理者 。
-
动态门限调整:在多方协同签名中,所需的门限值
k(即最少需要多少个分片才能签名)并非一成不变。系统可以根据当前检测到的异常节点数量动态调整门限值k_new,例如通过公式k_new = k + round(θ * (1/m) * Σ max(s_i - ex_i, 0)),其中θ是调整系数,m是节点总数 。当系统感知到风险升高时,可以适当提高门限k以增强安全性;在平稳时期,则可以保持或适当降低门限以提升效率 。
1.4.9 IP网络传输中融入物理不可克隆函数(PUF)
在IP网络传输中融入物理不可克隆函数(PUF),是一种旨在从根本上提升通信端点身份可信度和数据传输安全性的前沿思路。其核心在于,将网络实体的唯一、不可克隆的物理“指纹”作为其信任根,而非依赖传统可能被复制或窃取的数字证书或静态密钥。
PUF 如何增强网络传输安全
简单来说,PUF利用的是硬件制造过程中产生的、无法预测和复制的微观物理差异(如晶体管阈值电压的细微差别)。这使得每个芯片都拥有一个独一无二的身份标识。将这种特性应用于IP网络传输,主要为了实现以下两个核心目标:
-
设备身份认证:在网络通信的初始阶段,验证对方设备是否是合法的硬件实体,而非仿冒或克隆的设备。
-
安全密钥协商:基于PUF产生的响应,通信双方可以动态地生成一个仅本次会话有效的加密密钥,用于后续数据的加密传输,实现前向保密。
下面的流程图清晰地展示了一个典型的集成PUF的IP网络传输安全连接建立过程,它涵盖了从设备身份认证到安全数据传输的全过程。
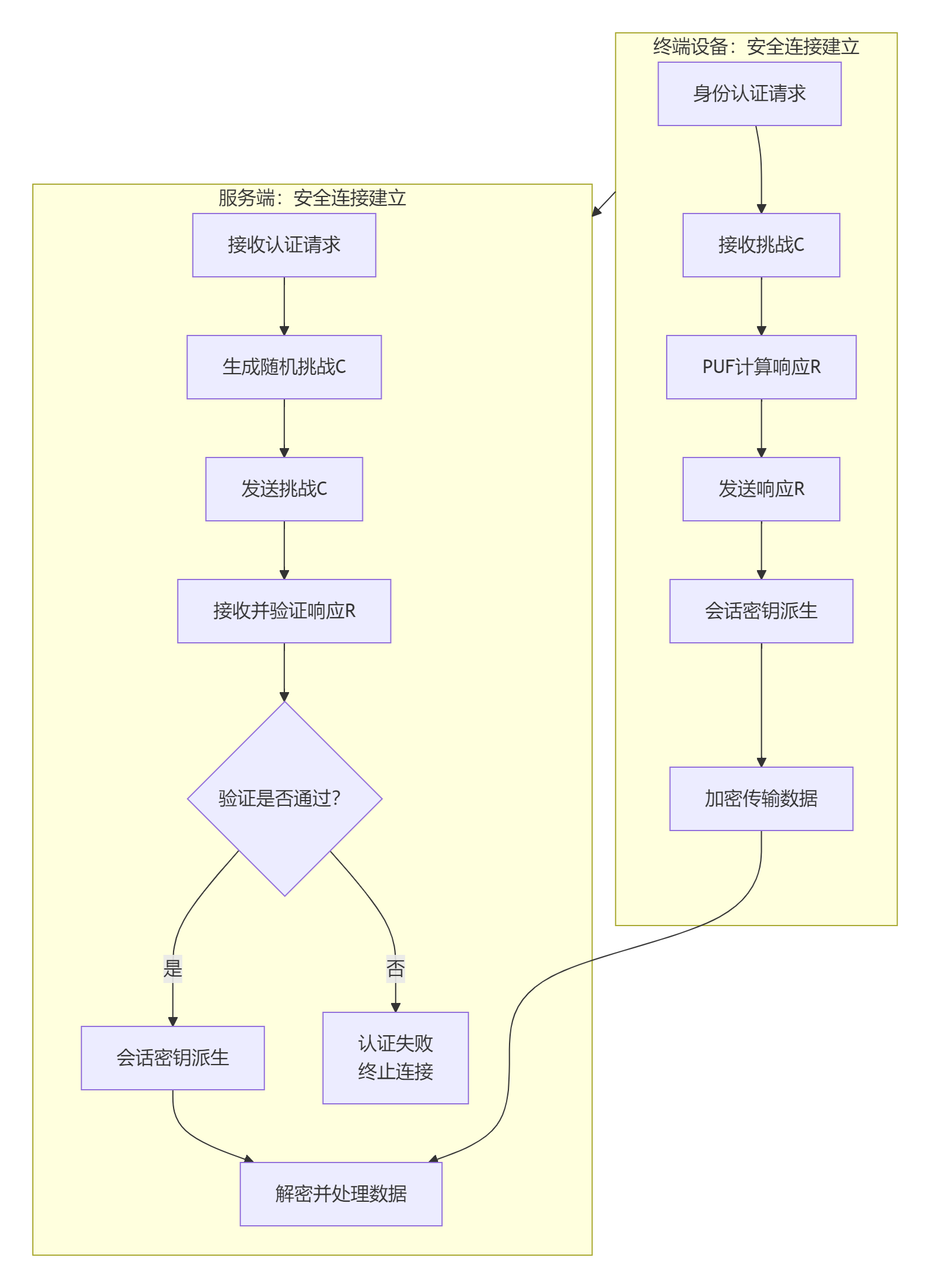
关键技术实现方式
要实现上述流程,需要解决几个关键的技术问题:
-
生成稳定的设备“指纹”:PUF的响应会受环境因素(如温度、电压)影响而出现波动。为确保每次生成的响应一致,需要采用模糊提取器技术。它结合纠错码(如BCH码)和隐私放大技术,可以从带有噪声的PUF原始响应中稳定地再生出一致的密码学密钥 。
-
实现安全的挑战-响应协议:这是PUF认证的核心。如图中所示,验证方(服务器)向终端设备发送一个随机挑战,设备使用其PUF计算并返回响应。服务器通过比对响应是否正确来验证设备身份。为了提升安全性,挑战可以是动态变化的,甚至可以结合时间戳等信息,增加重放攻击的难度 。
-
派生会话密钥:认证成功后,双方可以利用验证过程中交换的随机数(挑战和响应)以及PUF衍生的根密钥材料,通过标准的密钥派生函数(如HKDF)计算出一个新鲜的会话密钥。这个密钥用于加密后续的通信数据。
-
与现有协议栈集成:一种可行的方式是将PUF认证作为TLS握手协议的一个扩展。在TLS的“ClientHello”和“ServerHello”阶段交换PUF挑战,并将PUF响应作为预主密钥的一部分,从而将硬件身份认证深度融入成熟的安全协议框架中。
设计考量与挑战
在实际部署中,这种设计方案也需要权衡一些因素:
-
优势
-
增强的根密钥安全:密钥由硬件动态生成,无需非易失性存储,降低了从硬件中提取密钥的风险。
-
防设备克隆:每个设备的物理特性独一无二,难以复制,有效防止了通过克隆设备凭证发起的攻击。
-
轻量级潜力:适合资源受限的物联网设备,可作为其内置的安全身份。
-
-
挑战与注意事项
-
响应稳定性:必须通过有效的纠错机制来克服环境变化对PUF响应稳定性的影响,这是技术可用的前提 。
-
隐私考虑:PUF信息是设备的永久身份标识,在公开信道传输时需注意保护,防止被用于跟踪设备。
-
标准化与成本:目前PUF在IP网络协议中的集成缺乏广泛的标准,且集成PUF可能会带来一定的硬件成本和设计复杂度的增加。
-
应用前景
尽管存在挑战,但PUF为IP网络传输安全,特别是在物联网设备认证、卫星通信、工业控制系统等对设备身份真实性和通信安全有极高要求的场景,提供了一条从硬件根基上构建信任的新路径。随着技术的成熟和标准化工作的推进,它有望成为未来网络基础设施中不可或缺的安全基石。
1.4.10 抗机器学习(ML)建模攻击的强物理不可克隆函数(PUF)协议
设计能抵抗机器学习(ML)建模攻击的强物理不可克隆函数(PUF)协议,核心在于打破机器学习模型赖以学习的可预测性。这需要让PUF的挑战-响应对(CRP)关系变得足够复杂、非线性且动态变化。下面我将详细介绍几种关键的设计策略、一个综合协议流程以及评估方法。
核心防御策略
以下几种策略可以从不同层面提升PUF的抗攻击能力:
-
动态重构PUF电路
这是最根本的防御策略之一。其核心思想是让PUF电路本身可以动态改变,从而使攻击者之前收集的CRP迅速失效。
-
实现方式:在认证前,由验证者发送一个重配置指令。例如,在FPGA上,可以通过远程随机重构PUF的延迟路径或逻辑单元,创建一个全新的、临时性的PUF实例 。
-
优势:即使攻击者在某个时间点克隆了PUF行为,一旦PUF被重构,之前的所有模型都将失效。这要求攻击者必须在极短时间内完成对全新PUF的建模,难度极大。
-
-
混淆挑战比特
这种方法专注于扰乱输入,破坏挑战与响应之间清晰的线性或可逼近关系。
-
实现方式:在挑战信号输入到核心PUF(如仲裁器PUF)之前,先通过一个混淆模块。研究表明,重点混淆对最终响应影响最大的高阶挑战比特(如64位挑战中的最高几位),能更有效地降低机器学习模型的预测准确率,同时比混淆所有比特的硬件开销小得多 。
-
优势:这是一种轻量级且高效的方案,能以较低的成本显著增加建模的复杂性。
-
-
引入非线性与状态依赖
让PUF的响应不仅取决于当前的挑战,还依赖于内部历史状态或引入非线性运算。
-
响应反馈:将本次产生的响应位反馈回去,用于控制下一轮认证的挑战选择或PUF配置。例如,FLAM-PUF设计将响应反馈给一个线性反馈移位寄存器(LFSR),动态改变其配置,从而将单个仲裁器PUF的挑战空间极大扩展,并植入复杂的时间关联性 。
-
异或迭代:另一种思路是进行迭代计算。例如,可以将上一次的响应作为新的挑战,与一个固定的指纹矩阵进行异或等运算,产生下一次的响应。这种前后序列间的耦合大大增加了CRP的复杂度 。
-
-
利用新型器件的物理复杂性
基于新型非易失存储器(如忆阻器)的PUF天然具备更复杂的物理特性。
-
实现方式:忆阻器在纳米尺度下的电阻值变化巨大且难以预测。利用忆阻器交叉阵列中丰富的模拟特性(如潜行路径电流、非线性I-V特性)来生成响应,其内在的物理复杂性使得建立准确的数学模型非常困难 。
-
优势:从物理根源上提升安全性,对抗基于简单线性延迟模型的攻击尤为有效。
-
综合协议流程示例
下面是一个融合了上述多种策略的增强型认证协议流程,旨在提供一个具体的设计范例:
-
初始化与注册阶段:
-
为每个PUF设备生成一个唯一标识符(
Device_ID)。 -
在绝对安全的环境中,执行一次初始的CRP采集。但不直接存储原始CRP,而是存储用于验证的“信息摘要”,例如,将响应
R通过一个密码学哈希函数(如SHA-256)计算后存储哈希值H(R)。 -
如果采用动态重构策略,还需安全地预配置或协商好一组可能的PUF电路配置参数。
-
-
认证阶段:
-
设备标识与挑战请求:设备向验证服务器发送其
Device_ID。 -
服务器生成动态挑战包:服务器根据
Device_ID生成一个挑战包,其中可能包含:-
一个一次性随机数(Nonce),用于防御重放攻击。
-
一个PUF重配置指令(如果支持)。
-
一个或多个核心挑战值(C)。
-
-
设备端动态响应生成:
-
设备收到指令后,首先执行PUF重配置(若适用)。
-
然后,对核心挑战
C应用挑战混淆逻辑 。 -
被混淆的挑战输入到当前配置的PUF电路中,产生一个初始响应。
-
该初始响应可能再经过一轮响应反馈或迭代计算,最终生成用于此次认证的响应
R。
-
-
响应验证:设备将响应
R发送回服务器。服务器不直接比较R,而是计算H(R)并与注册阶段存储的哈希值进行比对。如果匹配,则认证通过。
-
评估与考量要点
设计好协议后,需要通过以下指标和方法来评估其有效性:
-
安全性评估:必须使用多种主流的机器学习算法(如逻辑回归、支持向量机、深度学习神经网络等)对协议进行建模攻击测试。一个健壮的协议应能使攻击模型的预测准确率长期稳定在接近50%(随机猜测水平) 。
-
资源开销:评估协议带来的额外硬件资源消耗(如逻辑门数量、存储器使用)和性能影响(认证过程耗时)。目标是在安全性和开销之间找到最佳平衡。
-
错误容忍度:PUF响应可能因环境因素(温度、电压波动)而出现少量比特错误。协议需要引入模糊提取器技术,通过纠错码来确保从带有噪声的响应中稳定地生成一致的密钥,同时不泄露PUF的关键信息。
-
控制CRP暴露量:协议设计应确保在设备的整个生命周期内,暴露给外界的CRP数量尽可能少,并且彼此间难以关联,从而让攻击者无法获得足够的高质量数据来训练模型 。
总结
总而言之,设计抗机器学习建模攻击的强PUF协议是一个系统工程,没有单一的“银弹”。最有效的方案往往是协同使用多种策略,例如将动态重构、挑战混淆和响应反馈结合起来,从物理实现、逻辑运算和协议流程多个维度共同构筑防御体系。
二、数据安全与保密工作
2.1 保密工作的专业知识体系
2.1.1 保密工作专业知识体系
保密工作的有效实施,依赖于一套环环相扣的专业知识体系。
|
知识模块 |
核心目标 |
关键内容概览 |
|---|---|---|
|
保密工作制度 |
建立机关单位内部保密管理的总框架和基本规矩 |
涵盖涉密人员、载体、网络、场所、会议等全方位的管理制度;落实保密工作责任制。 |
|
保密行政管理 |
保密行政管理部门依法对全国或区域保密工作进行指导、监督与管理 |
主管全国及本行政区域保密工作;开展保密宣传教育、检查、技术防护和案件查处;制定保密规章和标准。 |
|
定密理论与实务 |
解决“什么是国家秘密、密级如何定、保密多久、谁能知悉”的问题,确保定密精准规范 |
遵循最小化、精准化原则;严格依据保密事项范围;执行定密责任人制度和定期审核解密机制。 |
|
保密检查与案件查处 |
通过监督检查发现隐患,并通过查处泄密案件追究责任、堵塞漏洞 |
保密行政管理部门组织实施保密检查;泄密案件查处包括受理、初查、立案、调查、处理、结案等程序。 |
|
保密资质管理 |
对从事涉密业务的企业事业单位进行规范、审批与监管,确保其具备相应的保密能力 |
从事涉密信息系统集成、武器装备科研生产等业务需经审查批准并取得相应保密资质。 |
核心原则与动态
深入理解上述领域,需要把握几个核心原则:
-
最小化与精准化:这是定密管理的核心原则,确保国家秘密限定在尽可能小的范围内,避免过度定密。
-
全程管控与动态管理:保密管理覆盖国家秘密从产生到销毁的全生命周期,并根据情况变化及时调整密级或解密。
-
权责一致与责任追究:明确了从机关单位到个人的保密责任,并对违反规定的行为进行严肃问责。
保密工作也在不断适应新发展。例如,新修订的保密法强调了数据安全的管控,要求对汇聚、关联后可能属于国家秘密的数据加强安全管理。同时,鼓励应用先进技术如量子通信、区块链等来强化保密防护,并推动形成 “人人有责”的群防群治保密格局。
2.1.2 定密责任人制度
定密责任人制度是我国保密管理的一项核心制度,旨在实现定密工作的权责明确、依据充分、程序规范和准确精准。下面这个表格能帮你快速抓住这项制度的运作核心和责任人职责权限的要点:
|
制度要素 |
核心内容 |
|---|---|
|
制度目标 |
实现定密工作的权责明确、依据充分、程序规范、准确精准,确保国家秘密安全 。 |
|
责任人类型 |
1. 法定定密责任人:机关、单位主要负责人(通常为“一把手”),对本单位定密工作负总责 。 |
|
核心职责 |
1. 审核批准:对承办人拟定的密级、保密期限和知悉范围进行审核批准 。 |
|
权限范围 |
1. 法定定密责任人:权限与本单位定密权限一致 。 |
定密责任人的指定与要求
指定定密责任人通常来自经常产生国家秘密事项的业务部门负责人或核心工作人员,例如分管相关业务的单位副职领导、内设机构负责人或特定岗位工作人员 。他们必须熟悉保密法律法规、相关保密事项范围以及本单位的业务工作,并接受专门的定密培训 。
法定定密责任人指定其他人员时,会明确其定密权限(如只能批准秘密级事项,或可批准机密级及以下事项)。指定后,名单及其权限需在单位内部公布,并报同级保密行政管理部门备案。当指定定密责任人出现严重工作失误、离职或不再适合担任时,应及时调整 。
定密工作的实际流程
一项具体的定密工作通常遵循以下程序,它清晰地展示了定密责任人与事项承办人之间的协作关系:
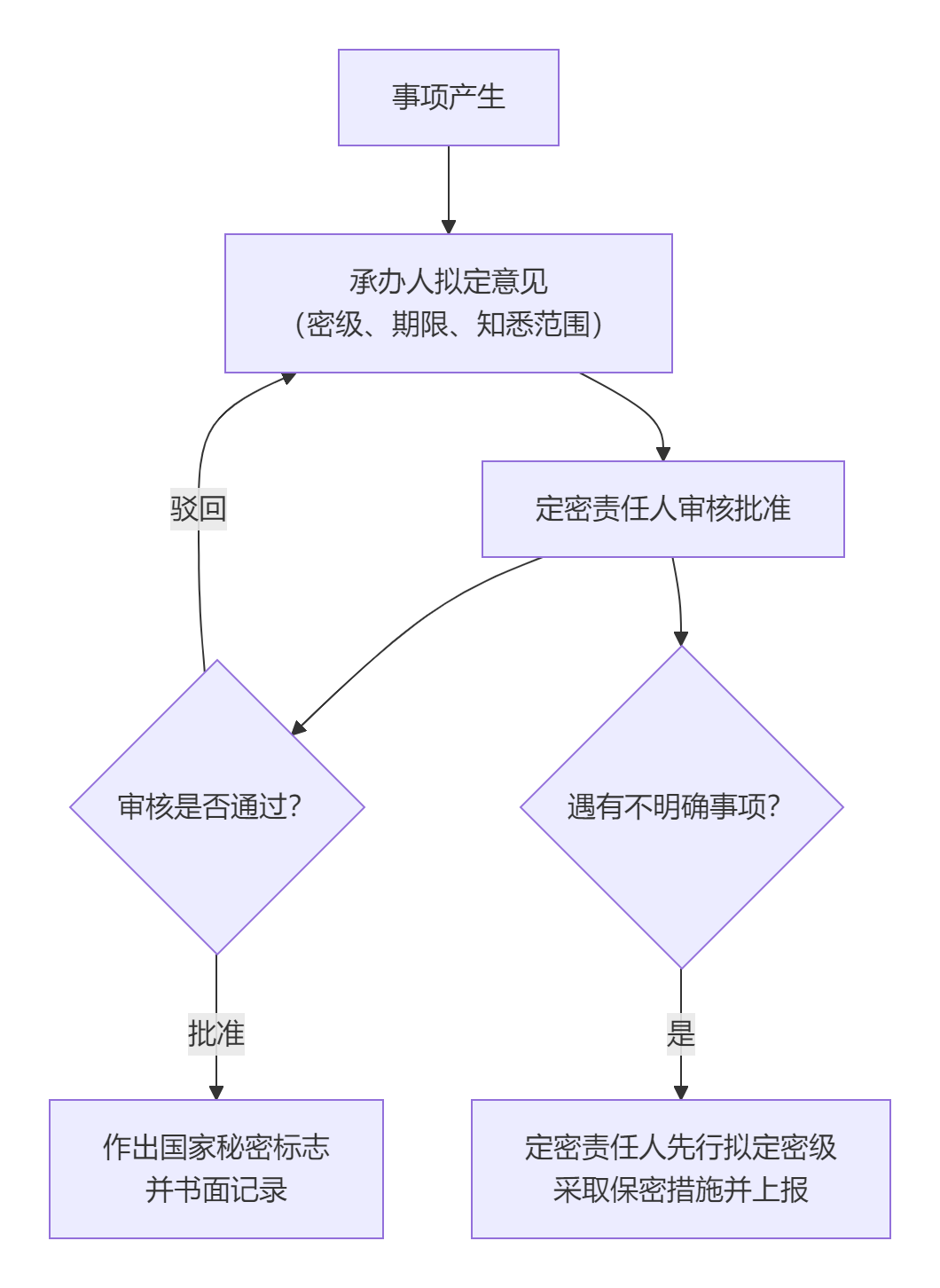
在整个过程中,定密责任人的审核批准是关键环节,需要对承办人提出的意见进行把关。如果事项属于“不明确事项”,即相关保密事项范围中没有直接规定,定密责任人需先行拟定密级并采取保密措施,按规定程序报保密行政管理部门确定 。
理解制度的三个关键点
-
分级负责:法定定密责任人负总责,指定定密责任人在授权范围内对自身决定负责,其决定具有法律效力,通常无需再报法定定密责任人批准 。
-
全生命周期管理:定密责任人的职责涵盖国家秘密从“出生”到“消亡”的全过程,包括确定、变更(如降低密级或缩短保密期限)以及解除(解密) 。
-
动态调整:定密责任人队伍和授权范围并非一成不变,会根据工作实际和人员变化进行动态调整和备案,确保制度的有效运行 。
2.2 数据安全的保密技术
2.2.1 数据安全中的保密技术
数据安全中的保密技术是一个既经典又充满活力的领域,它围绕着保障数据的机密性、完整性 和 可用性 这三大核心目标来构建防御体系 。下面这个表格可以帮助你快速搭建起对保密技术知识体系的整体认知框架。
|
知识模块 |
核心目标 |
关键技术举例 |
|---|---|---|
|
基础密码技术 |
通过数学变换保护数据机密性与完整性,实现身份认证 |
对称加密(AES)、非对称加密(RSA)、散列算法(SHA)、数字签名 |
|
数据防泄露(DLP) |
防止敏感数据被有意或无意地泄露 |
内容识别(正则、指纹)、通道控制、加密、行为审计 |
|
身份认证与访问控制 |
确保只有授权用户才能访问特定数据 |
数字证书、RBAC(基于角色的访问控制)模型 |
|
网络安全传输 |
保护数据在网络传输过程中的安全 |
TLS/SSL协议、IPSec VPN |
|
数据安全治理基础 |
为技术实施提供管理框架和策略依据 |
数据分类分级、安全风险评估 |
核心密码技术
现代密码学是保密技术的基石,主要包含三类算法:
-
对称加密算法(如 AES):加密和解密使用同一把密钥。优点是速度快,适合加密大量数据;挑战在于密钥需要通过安全渠道分发和管理 。
-
非对称加密算法(如 RSA):使用公钥和私钥配对。公钥公开,用于加密;私钥自己保存,用于解密。它解决了密钥分发问题,常用于建立安全通信通道和数字签名 。
-
散列算法(如 SHA-256):将任意长度数据映射为固定长度的“指纹”(哈希值)。主要用于校验数据完整性,任何对数据的篡改都会导致哈希值巨变 。
数据防泄露(DLP)技术
DLP技术专注于识别、监控和保护敏感数据,防止其违规外泄。其技术核心在于精准的内容分析 :
-
基础检测技术:包括正则表达式(用于匹配身份证号、信用卡号等特定模式)、关键字/关键字对、以及文档属性检测。
-
高级检测技术:包括精确数据比对(适合保护数据库中的结构化数据)、指纹文档比对(为重要文档创建“指纹”,用于检测部分或变体内容)和向量分类比对(利用机器学习对文档分类,判断是否敏感)。
根据数据状态,DLP防护重点也不同:
-
静态数据:关注存储中的数据,可通过文档加密、磁盘加密等技术保护 。
-
动态数据:关注网络传输中的数据,可采用网络通道加密(如TLS)和内容过滤技术监控 。
-
使用中数据:关注应用系统使用时面临的风险,可通过权限控制和操作审计等手段防护 。
身份认证与访问控制
确保用户身份真实并仅能访问授权资源。
-
身份认证:数字证书是核心机制,由受信任的第三方机构颁发,将用户身份与密码学密钥绑定,用于登录系统、签署文件等 。
-
访问控制:常用基于角色的访问控制(RBAC),通过给用户分配角色、为角色分配权限,实现权限管理的规范化和高效性,遵循最小权限原则 。
网络安全传输
当数据在网络中流动时,需保护其免遭窃听或篡改。
-
TLS/SSL协议:在传输层和应用层之间提供安全通道,通过加密和完整性校验保护数据。现代系统应优先采用TLS 1.3版 。
-
VPN技术:如IPSec VPN,可在公共网络上建立加密隧道,常用来连接不同地理位置的网络或允许远程安全访问内部资源 。
数据安全治理基础
有效的技术实施离不开顶层设计和策略管理。
-
数据分类分级:是安全保护的首要步骤。根据数据遭篡改、破坏、泄露或非法利用后造成的危害程度,将其划分为一般数据、重要数据、核心数据等不同级别,从而采取相应保护措施 。
-
安全风险评估:网络运营者应定期(如每年度)开展风险评估,识别数据资产面临的威胁、自身脆弱性及可能带来的风险,为制定安全措施提供依据 。
保密技术的设计方法
掌握技术后,如何系统性地设计和实施?可遵循以下生命周期方法:
-
需求分析与数据测绘:明确保护目标,结合业务流梳理数据流,识别关键敏感数据在何处创建、存储、流转及使用,并依据法规和业务影响对其进行分类分级 。
-
技术选型与架构设计:基于数据生命周期各阶段需求选择技术:
-
存储时:采用加密存储(数据库加密、文件加密)技术 。
-
传输时:采用TLS/SSL等安全协议 。
-
使用时:强化身份认证(如数字证书)和访问控制(如RBAC)。
-
共享与外发时:部署DLP系统进行内容检测和阻断,或采用数字权利管理控制文件使用权限 。
-
-
实施部署与策略配置:将技术方案落地,如安装DLP客户端、部署网络加密网关、配置访问控制策略等。策略应具体,例如仅允许特定角色用户访问特定类型数据 。
-
监控、审计与持续改进:系统运行后需持续监控,记录详细日志以便审计,并定期评估有效性,根据新的威胁和业务变化调整策略 。
前沿发展与趋势
保密技术也在不断演进:
-
同态加密:允许在密文上直接进行计算,计算结果解密后与明文计算一致,特别适用于需保护隐私的云计算数据分析 。
-
差分隐私:在统计数据中添加可控噪声,在保护个体隐私的同时保证宏观统计结果的准确性,常用于人口普查或大数据分析 。
-
行为分析与AI:利用人工智能分析用户行为模式,自动检测异常操作(如非工作时间大量下载敏感数据),实现更智能的威胁预测和响应 。
-
零信任架构:核心理念是“从不信任,始终验证”,不再单纯依赖网络边界,而是基于身份、设备、应用等多维度信号动态授予访问权限 。
2.2.2 数据安全的保密技术
|
技术领域 |
核心目标 |
关键要点 |
|---|---|---|
|
分级保护与保密标准 |
建立差异化的防护体系,确保安全投入的精准和高效。 |
根据数据遭篡改、破坏、泄露或非法利用后可能造成的危害程度,对数据进行分类分级(如一般数据、重要数据、核心数据),并依据级别采取相应的保护措施。国家标准(如等级保护制度)和行业标准是实施的根本依据。 |
|
物理安全保密 |
防止对存储和处理数据的物理设施、设备的未授权接触、破坏或窃取。 |
传统措施包括门禁、监控、屏蔽机房等。在通信领域,物理层安全技术利用无线信道本身的特性(如差异、射频指纹)实现安全传输和身份认证,为5G等网络提供轻量级、高安全的增强防护。 |
|
保密防护技术 |
在数据的存储、传输、使用等全生命周期中保障其机密性、完整性和可用性。 |
核心技术包括密码技术(加密、签名)、数据防泄露(DLP)、访问控制、安全传输协议(如TLS/SSL)等。需建立覆盖数据接入、传输、共享、存储、应用和监管审计各环节的技术体系。 |
|
保密技术检查 |
主动发现系统存在的安全漏洞、配置缺陷以及潜在的泄密风险。 |
手段包括漏洞扫描、渗透测试、安全审计、日志分析等。关键在于建立监测预警和应急响应机制,并能够对异常行为进行追踪溯源。 |
支撑技术的工作原理
上述应用技术的背后,有深刻的科学原理作为支撑:
-
数学与函数方法:这是密码学的基石。加密算法(如AES、RSA) 依赖于复杂的数学问题(如大数分解、离散对数),确保数据加密的强度。散列函数(如SHA-256) 能生成数据的唯一“指纹”,用于验证数据完整性。这些数学工具为数据安全提供了理论上的可靠性保证。
-
电路与电磁原理:在硬件安全层面至关重要。芯片设计需考虑防止通过侧信道攻击(如分析功耗、电磁辐射)来窃取密钥。物理隔离(如空气间隙)和电磁屏蔽技术则用于保护关键设备,防止信息通过电磁泄漏被截获。这些原理是构建可信计算环境的物理基础。
-
心理学与认知工效学原理:人是安全中最重要也最薄弱的一环。此原理应用于:
-
安全意识培训:根据人的认知习惯设计培训内容,提高对钓鱼邮件、社交工程等攻击的警惕性。
-
安全流程设计:使安全操作(如复杂的密码策略)更符合人的使用习惯,降低因繁琐而导致的不合规行为。
-
人因工程:优化管理终端的人机交互界面,减少因操作失误导致的安全风险。
-
技术的综合应用
在实际场景中,这些技术并非孤立存在,而是紧密协作。我们可以政务数据共享为例,展示它们如何协同工作:
-
前期:首先依据法规和标准对政务数据进行分类分级,确定哪些是敏感或关键数据。
-
中期:根据数据级别,在共享平台的不同层级(物理与环境、网络与通信、设备与计算、应用和数据)部署相应的防护技术。例如,重要数据传输采用加密通道,并对数据使用方实施严格的身份认证与访问控制。
-
后期:通过安全技术检查手段(如安全审计、追踪溯源)对数据交换过程进行监控和审计,以便及时发现异常并启动应急响应。
总结
简单来说,保护数据安全就像守护一座珍宝库:分级保护标准告诉我们哪些是普通宝石、哪些是传世钻石,从而决定用木盒还是钛合金保险箱(差异化防护);物理安全是库房的墙壁和门锁(基础屏障);保密防护技术是库内的红外警报和保险柜(主动防御);而保密技术检查则是定期的安全巡检和漏洞排查(持续监控)。所有这些,都建立在坚实的数学、物理和人类行为学原理之上。
2.2.3 数据分类分级
数据分类分级是数据安全的基石,它确保不同类型和敏感度的数据能得到相匹配的安全保护。下面这个表格能帮你快速抓住核心框架:
|
数据级别 |
核心特征与界定标准 |
典型防护措施导向 |
|---|---|---|
|
核心数据 (L6) |
对国家安全具有最高影响,关系政治安全、国民经济命脉、重大公共利益的数据。 |
严格管控:最高级别防护,原则上禁止共享、开放和出境,通常采取物理隔离或逻辑严控。 |
|
重要数据 (L5) |
一旦受损可能直接危害国家安全、经济运行、社会稳定、公共健康和安全的数据。 |
重点保护:在可信环境下采取严格管控措施(如“数据不出域、可用不可见”),限制出境。 |
|
一般数据 (L4-L1) |
不影响国家安全和公共利益,主要涉及组织权益和个人权益的数据。根据危害程度细分为4级(L4最高,L1最低)。 |
分级防护:从相对严格(L4)到基础安全管理(L1),共享开放权限随级别降低而放宽。 |
数据分类的常见维度
要对数据进行分类,需要从多个维度审视其属性。根据国家标准和实践,主要分类视角包括:
-
行业领域与业务职能:这是公共数据分类的常见方法。例如,先按金融、能源、教育、卫健等行业划分(一级),再按部门的具体业务职能(二级)、内容主题(三级)细化。
-
数据对象:根据数据描述的对象进行划分,如个人、法人/组织、客体(如基础设施、地理信息) 等。
-
共享与开放属性:明确数据是否可以以及在何种条件下可以在不同主体间流动。
-
共享属性:分为无条件共享、有条件共享、不予共享。
-
开放属性:分为无条件开放、有条件开放、不予开放。
-
-
技术管理特征:从IT管理角度,按数据结构化特征(结构化、半结构化、非结构化)、数据产生频率、数据存储方式等分类,这直接影响技术选型和存储策略。
数据分级的具体标准
分级的核心是评估数据一旦遭到泄露、篡改、损毁或非法使用后可能造成的危害程度及其影响对象。
-
影响对象:危害程度是针对以下六个方面来判断的:
-
国家安全
-
经济运行
-
社会秩序
-
公共利益
-
组织权益
-
个人权益
-
-
定级规则:数据级别的确定遵循一套清晰的规则,特别是要识别出核心数据和重要数据。例如,某些指南会给出具体的识别参考规则,如包含超过1000万包含组织和客体属性信息的数据,或100万人以上的敏感个人信息,可能被视为重要数据;而当规模或精度达到更高阈值(如1亿以上组织客体信息或1000万人以上敏感个人信息)时,可能被视为核心数据。对于一般数据,则根据对组织权益和个人权益的危害程度进行1-4级的划分。
分级防护的量化差异
不同级别数据对应的安全措施不仅在强度上不同,在具体控制措施上也有明确的量化差异。
|
管控方面 |
核心数据 (L6) |
重要数据 (L5) |
一般数据 (L4-L1) |
|---|---|---|---|
|
共享与开放 |
原则上不予共享和开放 |
有条件共享或不予共享;原则上不予开放 |
从严格限制到完全开放:L4级可能有条件共享/开放,L1级可无条件共享/开放 |
|
授权运营 |
禁止 |
禁止 |
L1-L3级可授权运营,L4级依情况而定 |
|
数据出境 |
禁止出境 |
严格限制出境,需通过安全评估 |
可出境(但涉及个人信息时需遵守相关法规) |
|
技术防护措施 |
最高级别防护,可能包括物理隔离、高强度加密、严格访问控制和全面审计 |
高级别防护,如加密存储传输、访问控制、安全审计等 |
分级防护:例如,高级别一般数据(L4)需进行高风险SQL操作审计 |
实施要点与动态管理
-
就高从严与动态调整:在定级时,如果一条数据同时符合多个级别标准,应遵循“就高不就低”的原则。数据分类分级不是一次性的工作,需要定期审核和更新。
-
数据集与聚合数据定级:对于一个数据集(如数据库表),其级别通常由其中包含的最高级别数据项决定。当不同来源的数据聚合后,其级别可能需要根据聚合后的整体影响重新评估,且不应低于原始数据中的最高级别。
2.3 数据安全与信息安全
2.3.1 数据安全与信息安全体系的关系
|
技术领域 |
核心目标 |
关键技术与方法 |
底层原理与设计思路 |
优势 |
缺陷与挑战 |
|---|---|---|---|---|---|
|
密码学 |
保障数据机密性、完整性、真实性和不可否认性。 |
对称加密(AES)、非对称加密(RSA)、散列函数(SHA系列)、数字签名。 |
基于复杂的数学难题(如大数分解、离散对数),将明文通过算法和密钥转换为密文。 |
对称加密效率高;非对称加密解决密钥分发难题;散列函数可校验数据完整性。 |
对称加密密钥管理复杂;非对称加密计算开销大;量子计算对传统算法构成潜在威胁。 |
|
信息安全体系结构 |
构建系统化、多层次的防护框架,实现纵深防御。 |
零信任架构、纵深防御模型、数据中心化安全。 |
零信任:默认不信任,持续验证;纵深防御:不依赖单一防线,层层设防;数据中心化:安全策略与数据本身绑定。 |
零信任有效应对边界模糊化;纵深防御单点失效不影响全局;数据中心化确保数据流动中持续受控。 |
零信任实施复杂度高;纵深防御成本较高;数据中心化对数据发现和分类能力要求极高。 |
|
信息安全管理与风险评估 |
将安全要求制度化、流程化,并前瞻性识别与处置风险。 |
ISO 27001、NIST CSF等管理体系;风险识别、分析、评估与处置流程。 |
管理思维:通过PDCA(计划-执行-检查-处置)循环实现持续改进。风险思维:基于资产价值、威胁可能性、脆弱性严重性来量化风险。 |
将技术、人员、流程有机结合,实现可预测、可复制的安全状态。将安全投入聚焦于最关键、最脆弱的环节。 |
体系落地依赖组织文化和执行力;风险评估的准确性受限于信息的完备性和主观判断。 |
|
系统与网络安全 |
为数据和信息系统的处理与传输提供底层运行环境的安全保障。 |
防火墙、入侵检测/防御系统(IDS/IPS)、端点检测与响应(EDR)、安全传输协议(TLS/SSL)。 |
在网络边界、通信链路、主机系统等层面建立访问控制、威胁检测、恶意代码防护等机制。 |
构成基础的、不可或缺的安全屏障;多种技术协同可形成有效防护。 |
传统边界安全模型难以适应云与移动办公;系统漏洞不可避免且需要持续修补。 |
技术间的协同与演进
这些技术并非孤立存在,而是在现代数据安全架构中紧密协同。例如,零信任架构的实现极度依赖密码学(用于建立信任和加密通道)、系统与网络安全(实现微隔离和策略执行点)以及信息安全管理(制定访问策略和审批流程)。同样,风险评估的结果会直接指导信息安全体系结构的设计,决定在哪些层面部署何种强度的防护措施。
从发展趋势看,数据安全防护正从传统的以网络和系统边界为中心的“边界防御”模式,向以数据本身为中心的“智能治理”模式演进。这意味着安全控制措施将更紧密地围绕数据生命周期(采集、存储、使用、共享、销毁)来部署,并越来越多地引入人工智能和自动化技术,以实现更精细、动态和自适应的安全保护。
从边界防护到数据核心
理解数据安全与信息安全体系的关系,以及底层技术的原理与优劣,能帮助我们在实际工作中更好地进行技术选型、体系设计和风险决策。
没有一种技术是银弹,有效的防护来自于管理体系的指导、风险评估的精准、体系结构的合理,以及各项安全技术的有机协同。
2.3.2 内存加密引擎如何支持数据保护
内存加密引擎要在保护数据的同时不影响CPU性能,其电路设计的关键在于通过专用硬件、并行架构和智能调度,将加密操作从CPU主计算任务中彻底“剥离”出去,使其成为一种高效、透明的后台服务。
内存加密引擎为实现这一目标所采用的核心电路设计策略
|
设计策略 |
核心目标 |
关键电路/技术实现 |
|---|---|---|
|
专用硬件协处理器 |
将加解密计算任务从CPU核心卸载,避免占用其运算资源。 |
在CPU内部集成独立的密码协处理器,如海光CPU的CCP单元。 |
|
总线与内存控制器集成 |
减少数据路径延迟,实现加密操作的高效并行。 |
将加密引擎作为内存控制器的一部分紧密集成,如英特尔MEE的设计。采用类似“双内存异或”的专用数据通路。 |
|
专用缓存与元数据管理 |
解决加密引入的元数据访问带来的性能开销。 |
设立专用的MEE缓存,用于存储频繁访问的完整性树节点等元数据。 |
|
高效密码学原语与并行引擎 |
提升单个加密操作的硬件执行效率。 |
采用并行化的加密引擎(如AES的计数器模式),支持对数据块的同时处理。 |
上述表格中的策略,具体通过以下技术实现:
-
独立硬件与并行流水线
-
独立运算单元:加密引擎拥有独立的算术逻辑单元,专门优化用于执行AES、SM4等密码算法的固定步骤。当CPU需要读写内存时,数据会被发送至内存控制器,其中的加密引擎会像一条“流水线”一样,对数据块进行流水线式的加密或解密操作。这个过程与CPU核心的指令执行流水线并行不悖,CPU无需等待。
-
超低延迟数据通路:为了极致降低延迟,一些设计采用更直接的硬件电路。例如,基于“双内存异或”的技术,通过硬件电路使密钥和加密数据在相同地址下被自动读取并进行异或运算,其延迟仅相当于一级逻辑门,速度极快。
-
-
智能的元数据管理与缓存
内存加密不仅仅是加密数据本身,还需维护用于保证数据完整性和新鲜性的元数据。直接访问这些元数据会产生巨大开销。为解决此问题,加密引擎会集成一个专用的小型缓存,用于存放最活跃的元数据(如完整性树的节点)。当需要校验数据时,引擎优先查询此缓存,大幅减少了对主内存的访问次数,从而显著提升性能。
-
DMA与总线优化
在高性能场景下,加密引擎常与直接内存访问(DMA) 控制器协同工作。DMA控制器负责在内存和加密引擎之间直接搬运数据,无需CPU介入。同时,如SRIO的高速串行总线能为CPU与外部加密硬件提供高带宽、低延迟的数据通道,确保加密数据传输不成为瓶颈。
-
海光CPU:其在通用CPU内内置了独立的安全处理器和密码加速引擎,专门处理密码运算。这种设计显著降低了对CPU主核运算资源的占用,提升了整体效率,从而可以替代外置加密卡。
-
英特尔内存加密引擎:作为业界标杆,其设计深度集成于内存控制器中。它采用先加密后认证的范式,并利用优化的多级完整性树结构,在提供强大安全保证的同时,通过上述多种技术将性能开销降至最低。
总而言之,内存加密引擎通过专芯专用、并行处理、就近缓存等一系列精妙的电路级优化,成功地将安全防护打造成一个高效且几乎无感的底层服务,确保了CPU可以心无旁骛地专注于核心计算任务。
2.3.3 密态数据库
密态数据库通过确保数据在整个生命周期(传输、存储、计算)中都保持加密状态,来为数据资产提供核心安全保障。其核心在于,即便数据库服务器本身(例如云服务商的系统或潜在的内部威胁)不完全可信,数据也能得到保护。
下面这张图概括了全密态数据库的典型工作流程和关键安全设计:
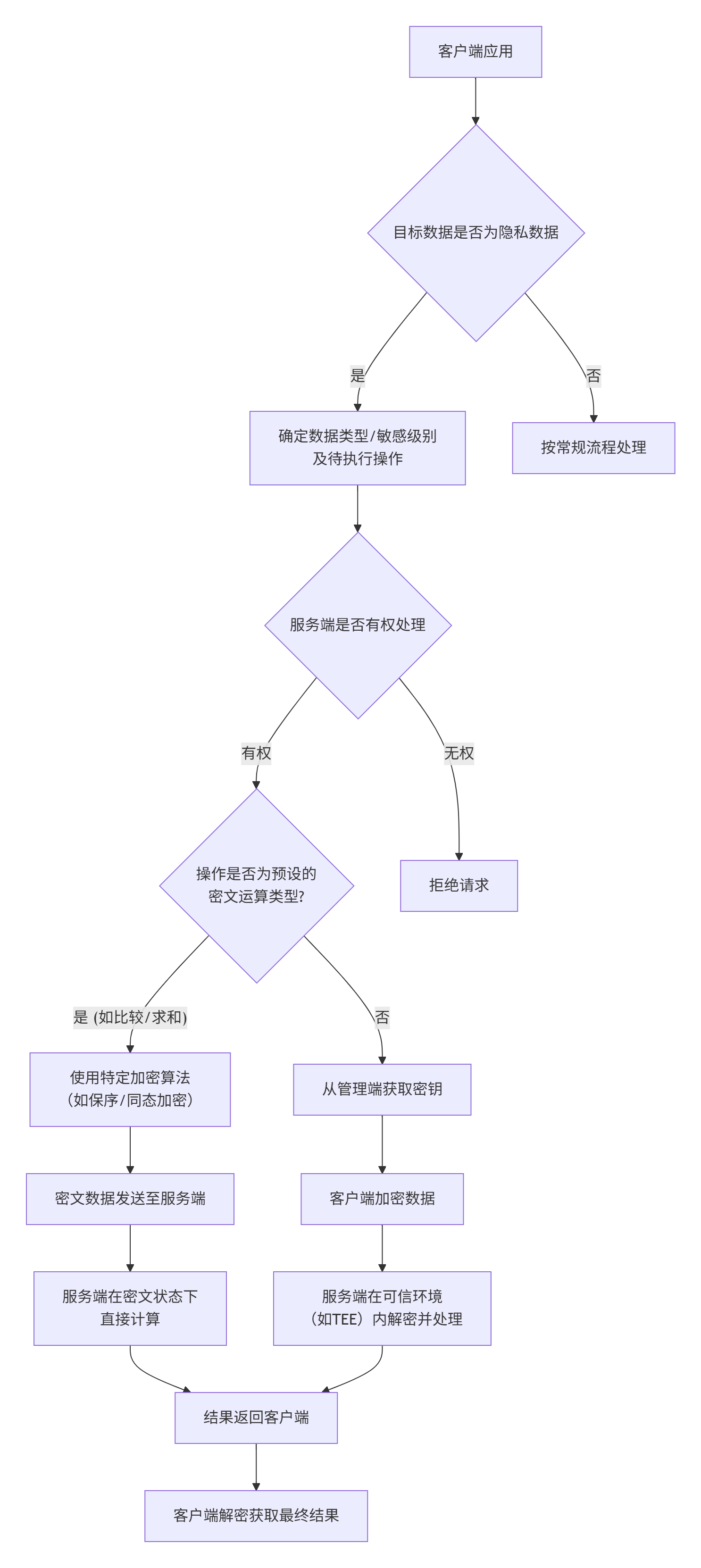
核心技术与实现方式
-
客户端加密与密钥管理
数据安全的起点在客户端。数据在离开客户端之前就会被加密,确保敏感信息在传输过程中和服务器端都以密文形式存在。密钥通常由客户端管理或通过外部的密钥管理服务(KMS) 进行托管,数据库服务端无法接触密钥明文。例如,华为云GaussDB采用多级密钥体系(主密钥保护列密钥,列密钥再保护数据),密钥密文存储在服务端,而主密钥由KMS或用户自己掌管。
-
密文运算能力
这是密态数据库区别于简单加密存储的核心。为了对加密数据进行操作,密态数据库会采用一系列先进的密码学技术:
-
特定算法支持:根据不同的查询需求,选择相应的加密算法。例如,保序加密(OPE) 支持对加密数据直接进行大小比较,可搜索加密(SE) 支持关键词检索,而同态加密(HE) 则允许在密文上直接执行某些算术运算。
-
可信执行环境(TEE):这是一种硬件级的安全解决方案。通过将数据和密钥导入到CPU构建的受保护隔离环境(如Intel SGX/海光CSV)中执行运算,确保即使服务器操作系统或Hypervisor被攻破,数据在内存中也不会泄露。阿里云全密态数据库的硬件加固版就采用了此技术。
-
-
无缝对接与业务透明
为了降低应用改造成本,密态数据库通常通过定制化的数据库驱动来实现对应用的透明性。如阿里云开源的Go驱动,它在内部封装了标准数据库驱动,自动拦截SQL语句,对指定为加密列的字段进行加密和解密操作。这使得业务代码几乎无需修改即可获得数据加密能力。
主要应用场景
密态数据库技术在以下场景中尤为重要:
-
云端数据安全与合规:当企业将数据库部署在公有云或第三方平台时,可以有效防止云平台运维人员或DBA直接访问明文数据,满足诸如GDPR、个人信息保护法等数据合规要求。
-
防止内部数据泄露:在企业内部,可以限制研发、测试甚至管理员对生产敏感数据的访问,实现“数据可用不可见”,降低“内鬼”风险。
-
数据合作与安全计算:在需要与多个合作方进行数据联合分析(如联合风控、合作营销)但又不能暴露原始数据的场景下,密态数据库为安全的多方计算提供了基础。
技术权衡与挑战
采用密态数据库也意味着需要在安全、性能和功能之间做出权衡:
-
性能开销:加密解密操作和复杂的密文运算会带来一定的性能损耗。例如,在事务型场景下,性能可能达到明文数据库的50%到90%。
-
功能限制:并非所有的SQL操作和复杂查询都能在密文上高效执行,这可能会限制某些高级分析功能的使用。
-
架构复杂性:引入密钥管理、TEE环境等组件,会增加系统的复杂度和运维成本。
与传统加密方案的对比
为了更清晰地展示密态数据库的优势,可以参考下表与传统加密技术的对比:
|
特性 |
全密态数据库 |
透明数据加密(TDE) |
应用层加密 |
|---|---|---|---|
|
保护范围 |
全生命周期(传输、存储、计算) |
主要针对存储落盘的数据 |
端到端(应用层到存储层) |
|
服务器端明文暴露 |
否(数据在服务端内存中也是密文) |
是(数据在内存处理时为明文) |
否(但数据库功能受限) |
|
数据库功能支持 |
支持在密文上进行特定查询和计算 |
完全支持所有数据库功能 |
几乎无法支持复杂的数据库查询 |
|
主要目标 |
在不可信环境中保护数据 |
防止物理介质被盗或数据文件泄露 |
实现端到端加密,服务端不可信 |
总结
密态数据库,特别是全密态数据库,通过将安全边界从基础设施层推进到数据层本身,从根本上重塑了数据资产的保护模式。它使得数据即使在不受信任的云平台或复杂的企业内部环境中,也能在保持可用性的前提下,确保机密性。
2.3.4 密态数据库在内存体系中的核心目标
密态数据库在内存体系中的核心目标,是确保敏感数据即便在运行态也得到保护。下面这个表格汇总了其中的关键设计考量。
|
核心维度 |
关键目标与挑战 |
代表性技术/策略 |
|---|---|---|
|
内存读取方法 |
平衡安全与性能,确保数据在内存中被处理时(解密、计算)的安全。 |
基于硬件的可信执行环境(TEE)、密码学方案(如保序加密OPE)、混合方案。 |
|
访存策略 |
管理受限的安全内存(如TEE的EPC),减少与不可信环境的数据交换开销。 |
显式分页、数据密封、缓存策略、DMA保护。 |
|
安全体系 |
建立从硬件、密钥管理到运行环境的全方位信任链。 |
远程证明、层次化密钥管理(主密钥、列密钥、数据密钥)、最小权限原则。 |
内存读取方法
内存读取方法关注数据在CPU计算时,如何在安全与性能之间取得平衡。
-
硬件可信执行环境(TEE)
这是目前主流的高安全级别方案,以Intel SGX和Intel TDX为代表。其核心思想是在CPU内构建一个隔离的“飞地”(Enclave)或“信任域”(Trust Domain)。数据只有在进入这个受硬件保护的飞地后才会被解密成明文进行计算,计算结果在离开飞地前会被重新加密。这意味着,即使操作系统或云平台管理员被攻破,攻击者也无法从内存中窃取有效数据。该方案的优势在于能提供强大的硬件级安全隔离,但挑战在于受保护的内存(如SGX的EPC)容量有限,且与外部环境(REE)的通信(ECALL/OCALL)会带来性能开销。
-
软件密码学方案
此方案不依赖特定硬件,而是利用密码学算法(如确定性加密(DET)、保序加密(OPE)、同态加密(HE) 等)的特性,使得数据库可以直接在密文上进行特定类型的查询和计算。例如,使用OPE加密后,数据库可以直接对密文进行大小比较和排序,而无需解密。这种方案的优势是部署灵活,不依赖特定硬件;缺点是计算开销大、功能受限(例如难以高效实现模糊查询),且某些算法(如OPE)会泄露明文的顺序信息,安全性弱于TEE。
-
软硬融合混合方案
为了兼顾安全性和功能性,业界提出了混合方案。例如,华为云GaussDB的“内存解密逃生通道”便是一种实践:在默认的密文处理基础上,通过设置参数(如
enable_ce=3),在特定条件下可将密钥传输至服务端内存中进行解密,以支持更复杂的计算操作(如范围查询、排序)。尽管这引入了特定场景下的风险,但为企业提供了灵活性。
访存策略
访存策略聚焦于如何高效、安全地管理受限的安全内存资源。
-
TEE环境内存管理
在TEE中,受保护的内存(如EPC)是稀缺资源。因此需要显式分页等策略,即按需将加密的页面从普通内存交换到EPC中处理。这个过程(页面置换)会带来性能开销。此外,为避免重复计算,常采用数据密封策略,即将飞地内处理后的敏感数据用飞地专属密钥加密后存储到普通内存,下次需要时再由同一飞地解密加载,确保数据仅在飞地内为明文。
-
内存加密与完整性保护
为防止通过直接读取内存模块或分析总线流量来窃取数据,现代机密计算技术(如Intel TDX的MK-TME)支持内存加密,确保离开CPU芯片的数据在内存总线上始终是密文。一些方案还通过默克尔树等数据结构为加密内存提供完整性保护,能检测到对内存数据的恶意篡改。
-
I/O与DMA安全
当数据需要与外部设备(如GPU、网卡)交互时,需防范通过DMA的直接内存访问攻击。先进方案会利用IOMMU等技术对DMA地址进行重映射和访问控制,确保只有可信的设备才能访问受保护的内存区域。
安全体系架构
安全体系是确保前两者有效运作的基石,构建了从硬件、密钥到运行环境的信任链。
-
信任根与远程证明
系统安全始于可信的硬件信任根。关键的环节是远程证明,它允许客户端在发送数据前,远程验证服务端确实运行在真实的TEE环境中,且运行的软件是预期版本。这通常依赖CPU内嵌的密码学协处理器生成硬件签名证书来实现。
-
层次化密钥管理
密态数据库采用严格的密钥分层体系:
-
主密钥(MEK):由用户绝对控制,通常存储在外部KMS中。
-
列加密密钥(CEK):用于加密具体列的数据,自身由主密钥加密后存储。
-
数据密钥:最终用于加密数据块。
这种结构实现了密钥的隔离和安全生命周期管理。
-
-
最小权限与审计
整个体系遵循最小权限原则,每个组件仅获取完成其任务所必需的最低权限。同时,全链路审计日志至关重要,记录包括密钥访问、数据查询在内的所有敏感操作,以满足合规要求和事后追溯。
工程权衡与选型考量
在实际应用中,选择何种方案需要在安全、性能、功能和成本之间权衡:
-
极致安全与合规:金融、政务等场景可优先考虑基于TEE的方案。
-
功能丰富与易迁移:若业务需要复杂的范围查询、连接操作,TEE或混合方案更合适。
-
成本与通用性:对于安全性要求相对较低或希望部署灵活的场景,可评估软件密码学方案。
2.3.5 软件密码学方案与TEE(可信执行环境)方案的差异
了解软件密码学方案与TEE(可信执行环境)方案在具体业务场景下的性能差异,对于技术选型至关重要。下面这个表格汇总了它们在关键维度上的核心对比,方便你快速把握。
|
对比维度 |
软件密码学方案 (如MPC、FHE) |
TEE方案 (如Intel SGX) |
|---|---|---|
|
核心原理 |
依赖密码学算法(如同态加密、安全多方计算)在密文上直接计算。 |
依赖硬件隔离(如CPU中的安全区域“飞地”),在飞地内对明文数据进行计算。 |
|
通用性能表现 |
计算和通信开销大,性能通常比明文计算慢数个数量级。 |
高性能,性能损失可控制在10%以内,接近明文计算速度。 |
|
安全模型 |
基于计算复杂性的数学难题,假设算法本身是安全的。 |
基于硬件隔离和安全区域的可验证性(远程认证)。 |
|
典型适用场景 |
安全性要求极高、可接受较高延迟和非实时性的场景,如少量敏感数据的合规交换。 |
数据量大、计算复杂、对性能有高要求的场景,如金融风控联合建模、实时数据分析。 |
性能差异的根源
两者性能差异巨大的根本原因在于其技术原理的不同。
-
软件密码学方案的瓶颈在于其巨大的计算开销。以同态加密为例,它对数据进行加密后,密文体积会急剧膨胀(密文膨胀),并且在密文上执行运算远比直接对明文数据进行相同的运算要复杂和耗时得多。有研究表明,在同等资源条件下,基于TEE的方案其执行时间可缩短为基于软件隐私计算时间的1/25甚至更少。
-
TEE方案的优势在于其硬件加速。它通过在CPU内部创建一个受硬件保护的安全区域(飞地),使得绝大部分计算可以直接在明文中进行,避免了复杂的密码学运算。其主要开销来自于TEE与外部富执行环境(REE)之间的上下文切换,以及偶尔需要的数据加密/解密操作,但这些开销通过硬件优化已被控制在较低水平。
不同业务场景下的选择考量
结合具体场景,可以更清晰地看到两者的适用性。
-
金融风控与联合建模
在银行、保险公司进行贷前反欺诈或联合建模时,通常需要处理海量数据,并且对模型的准确性和实时性有很高要求。TEE方案因其高性能和强大的通用计算能力(支持复杂的机器学习算法)成为更合适的选择。它能满足大规模数据训练和实时预测的性能需求。
-
简单查询与轻量计算
如果业务场景主要是对加密数据库进行简单的等值查询、范围查询或求和等轻量级操作,软件密码学方案中的特定算法(如确定性加密DET、保序加密OPE、半同态加密PHE)可以胜任,且避免了依赖特定硬件。但对于复杂的查询或关联分析,这些方案可能因功能限制或性能骤降而难以应对。
-
对硬件依赖性的考量
TEE方案的一个显著限制是它需要特定的硬件支持(如搭载Intel SGX等技术的CPU),这可能会增加部署成本并限制灵活性。而软件密码学方案则具有更好的通用性,可以在普通的云服务器或物理机上部署,成本更低且更灵活。
总结与建议
总的来说,选择哪种方案是一个在安全、性能和成本之间权衡的过程。
-
若业务场景涉及海量数据、复杂计算且对性能(尤其是实时性)要求苛刻,例如高并发实时风控、精准营销等,应优先考虑TEE方案。
-
若业务场景数据量不大、计算简单,或对硬件环境有特殊限制(如无法使用特定CPU),且可以接受较高的延迟,软件密码学方案是一个可行的选择。在一些极端场景下,甚至可以结合两者,形成混合方案,例如利用TEE处理大部分复杂计算,同时使用密码学技术保护最关键的数据或进行最终结果的验证。
2.3.6 同态加密和可信执行环境的关系与应用
在数据协作的安全方案选择上,同态加密和可信执行环境并非简单的替代关系,而是面向不同需求的互补性技术。简单来说,同态加密的核心优势在于其基于密码学的、无需信任的安全模型,而TEE的核心优势在于其通用性和高性能。
|
对比维度 |
同态加密的优势场景 |
TEE的优势场景 |
|---|---|---|
|
信任模型 |
密码学安全,不依赖硬件或软件供应商,安全性基于数学难题。 |
硬件隔离安全,依赖特定硬件(如Intel SGX)构建可信环境。 |
|
数据流动 |
数据无需解密,全程以密文形式在不可信环境中计算,实现“数据不动计算动”。 |
数据需进入硬件飞地(Enclave) 后在内部解密计算,是“计算动,数据也动”。 |
|
适用操作 |
尤其擅长线性的、数学形式固定的计算(如加法和乘法)。 |
通用计算,可执行任意复杂的逻辑,包括非线性计算和条件分支。 |
|
性能特点 |
计算开销巨大,尤其对于复杂和非线性操作。 |
高性能,性能损失通常可控制在较低比例(如10%以内),接近明文计算。 |
优先选择同态加密的场景
基于上述对比,在以下几类特定业务需求下,同态加密是比TEE更具优势的选择:
-
严格的跨机构数据协作
当多个互不信任的机构(如不同银行、竞争对手公司)需要共同计算一份数据时,同态加密的密码学安全模型提供了最高级别的保障。数据从离开本方到最终结果返回,全程处于加密状态,任何参与方都无法看到他人的原始数据。这种“可用不可见”的特性,完美解决了在缺乏共同信任基础的实体间进行数据价值交换的难题。
-
算法或模型本身的保密
在某些场景下,需要保密的不只是数据,还包括计算所依赖的核心算法或模型参数。例如,一家券商拥有价值连城的专有金融模型,希望为客户提供服务但又不想泄露模型细节。利用同态加密,可以将加密后的客户数据输入到保密的模型中进行计算,最终只将加密的结果返回给客户。在这个过程中,客户数据全程保密,券商的模型也得到了保护。
-
简单的统计与聚合计算
对于投票统计、金融风险评估中的加权求和、以及某些机器学习算法(如线性回归、逻辑回归)等主要基于加法和乘法的计算任务,同态加密非常高效。这些任务的数学形式固定,可以很好地映射到同态加密支持的操作上,在保证安全的同时实现业务目标。
重要考量与当前局限
尽管同态加密在上述场景中不可替代,但在技术选型时也必须清醒认识到其当前的主要局限:
-
显著的性能开销:同态加密的计算速度比明文计算慢数个数量级,这是其为强大安全性付出的主要代价。虽然通过批处理、算法优化和专用硬件加速可以大幅改善,但在处理海量数据或要求低延迟的场景下仍需谨慎评估。
-
功能限制:同态加密(尤其是完全同态加密FHE)理论上支持任意计算,但实际中对于复杂的非线性计算(如某些激活函数)支持仍然不够高效,通常需要复杂的近似处理,这可能会引入精度损失。
如何选择:总结与建议
选择同态加密还是TEE,归根结底是对安全性、性能、功能复杂度和成本的综合权衡。
-
如果您的场景涉及高敏感度的数据在不可信环境(如公有云、合作方平台)流通,且计算逻辑相对简单固定,对实时性要求不高,那么同态加密是更安全、更理想的选择。
-
如果您的场景需要处理复杂的、非固定的计算逻辑(如复杂的AI模型推理),且对性能有较高要求,同时可以接受基于特定硬件的信任模型,那么TEE是更务实和高效的选择。
未来的趋势可能是两者的融合,例如在TEE内部使用同态加密处理最敏感的数据片段,从而兼顾安全与性能。
2.3.7 同态加密保护算法模型隐私
在同态加密保护算法模型隐私的实践中,计算精度与安全性之间存在一种内在的权衡关系。追求更高的安全性往往伴随着更大的计算开销和潜在的精度损失,而平衡这一者需要综合运用多种技术策略。
实现平衡的几种核心策略及其关注点:
|
平衡策略 |
核心思路 |
对精度的影响 |
对安全性的影响 |
|---|---|---|---|
|
算法与参数选择 |
根据计算类型(如仅需加法还是需支持乘法)选择部分同态加密或全同态加密方案,并精细调整参数。 |
不同的方案和参数设置直接关系到噪声增长和计算精度。 |
加密方案的选择和参数(如密钥长度、噪声上限)是安全性的基础。 |
|
计算过程优化 |
采用特定的编码方法、噪声管理技术或优化算法来提升计算效率,控制误差。 |
旨在减少或控制因加密计算引入的误差,是保障精度的关键。 |
优化过程本身不应引入新的安全漏洞。 |
|
混合架构设计 |
不追求全程同态加密,而是将同态加密与其他隐私计算技术(如安全多方计算)结合,在关键环节使用最合适的技术。 |
通过架构设计,在非关键步骤使用更高效的技术,从而为高精度计算保留资源。 |
形成多层次的安全防护,兼顾不同环节的安全与效率需求。 |
深入理解平衡之道
上述策略的具体实现,依赖于对技术和架构的深入理解。
-
算法选择与参数调优是基础
-
方案选择:如果您的模型推理或训练过程主要是加法运算(如一些线性回归、梯度聚合),那么加法同态加密(PHE) 就已足够,其计算效率远高于全同态加密(FHE)。例如,保护深度学习梯度上传时,加法同态加密可以在保证安全的同时维持模型准确性。若计算涉及加法和乘法,则需选择支持近似算术的CKKS方案或支持精确布尔运算的TFHE方案。CKKS方案通过rescaling操作控制精度,适用于机器学习场景。
-
参数调优:同态加密中的噪声是影响精度和安全的关键。噪声随着计算深度增加而增长,一旦超出阈值将导致解密失败。因此,需要根据计算的复杂度预留足够的“噪声预算”,同时在满足安全要求下选择更高效的参数。
-
-
计算过程的优化与创新
-
编码与噪声管理:将浮点数等明文数据高效地“编码”到加密域是关键步骤。例如,通过指数编码并结合可编程自举技术,可以在密文状态下进行高精度的比较运算,这对于实现激活函数等非线性操作至关重要。
-
交互式协议与混合技术:有时,纯粹的同态加密并非最优解。例如,一种基于双服务器的隐私保护神经网络推理方法,在线性层计算利用同态加密,而在非线性层(如ReLU激活函数)则结合了安全比较协议,从而在保证精确计算的同时避免了纯同态加密的高开销。另一种云环境下用户数据交互式计算隐私保护方法,通过在两个服务器间进行基于同态加密的交互式操作来计算ReLU函数,避免了近似计算带来的精度损失。
-
-
架构层面的灵活设计
最实用的策略往往是分层加密或选择性加密。以Meta Opaque Layers技术为例,它并不在神经网络的每一层都进行加密,而是选择在信息熵最高、最敏感的初始层嵌入加密机制,后续层则可在受控环境中解密处理。这种策略有效切断了从原始输入到中间特征的直接关联,在安全性和计算效率之间取得了良好平衡。
实际应用考量
在实际项目中,还需要考虑以下几点:
-
明确安全假设与需求:评估您需要防范的威胁模型。是防范“诚实但好奇”的云服务商,还是更强大的外部攻击者?这决定了您所需的安全级别。最新的vCCA(可验证选择密文攻击安全性) 安全概念为FHE提供了更强的密文完整性保障,但也会引入额外的验证开销。
-
性能与成本的权衡:同态加密的计算和通信开销巨大。例如,一次全同态加密的ResNet-18推理延迟可能超过5秒。您需要评估业务场景是否能接受这样的延迟,以及相应的计算成本。
-
技术融合趋势:未来的趋势是多种隐私计算技术的融合。例如,将同态加密与可信执行环境(TEE) 结合,在TEE内部处理最敏感的解密操作,或与差分隐私(DP) 结合,在加密数据上额外添加可控噪声,提供统计意义上的隐私保证。
总结
总而言之,平衡同态加密中的计算精度与安全性并非寻找一个固定答案,而是一个基于具体场景的持续优化过程。核心在于深刻理解您的算法计算需求、安全边界以及成本约束,进而灵活运用算法选型、计算优化和架构设计等多种手段,在保障模型隐私的前提下,最大限度地满足应用的精度和性能要求。
2.3.8 同态加密在金融风控建模场景的应用
同态加密在金融风控联合建模中,通过在密文状态下直接进行计算,实现了“数据可用不可见”,为金融机构在合规前提下释放数据价值提供了关键支撑。
|
应用场景 |
核心目标 |
典型实现方案 |
|---|---|---|
|
横向联合建模 |
保护各参与方本地数据的特征直方图,防止服务器或其他参与方推断出特定客户的敏感信息。 |
各参与方使用CKKS方案等支持向量运算的同态加密算法加密本地生成的直方图,发送至中心服务器。服务器在密文状态下直接进行安全聚合,得到全局直方图后返回给各方解密,用于后续的模型训练与更新。 |
|
纵向联合建模 |
保护标签信息(如客户的贷款是否逾期),防止无标签的特征方(如银行、电商平台等)在协作中获取核心业务标签。 |
持有标签的主动方计算每个样本的梯度后,使用Paillier等加法同态加密算法对梯度进行加密,然后发送给被动方(特征方)。被动方在密文状态下根据自身特征完成直方图统计,并将加密的统计结果返回。主动方解密后,再用于构建风控模型。 |
关键性能优化策略
同态加密计算开销巨大,是其在实践中面临的主要挑战。以下策略可有效优化性能:
-
硬件加速与算法选择
利用GPU(如NVIDIA CUDA) 对同态加密运算进行加速是当前最有效的手段之一。相较于纯CPU运算,GPU加速方案可以将Paillier加密等操作的速度提升数倍至数十倍。同时,需根据计算任务的特点精准选择加密方案:对单个数值的加密和加法运算(如纵向风控中的梯度),Paillier算法效率更高;而对向量或矩阵的运算(如横向风控中的直方图),CKKS方案更为合适。
-
算法与工程级优化
在算法层面,可通过梯度压缩技术(如将32位浮点数量化为8位整数)减少传输数据量,从而降低通信和加密开销。在工程层面,采用模块化插件设计(如NVIDIA FLARE框架中的同态加密插件)可以将加密功能无缝集成到现有联合学习流程中,实现灵活调度,避免不必要的性能损耗。
-
融合架构与协同设计
单一技术往往难以兼顾安全、性能与功能。将同态加密与可信执行环境(TEE)、差分隐私(DP) 等技术融合是前沿方向。例如,在TEE构建的可信环境中执行高安全要求的解密或复杂计算环节,而用同态加密保护数据传输过程,形成优势互补的纵深防御体系。
实践与权衡
总而言之,成功应用同态加密进行金融风控联合建模,关键在于根据具体的业务场景和安全需求,在安全性、性能和功能三者之间做出审慎的权衡。
-
高安全要求的金融核心风控场景:可优先考虑基于GPU加速的同态加密方案,尽管计算成本较高,但能提供基于密码学的强安全性保障。
-
对实时性有较高要求的场景(如实时反欺诈):可以考虑同态加密与TEE相结合的混合架构,或将同态加密主要用于离线模型训练,线上预测则使用在TEE中部署的模型或其他高效方案。
2.3.9 神经网络推理中如何为不同层选择同态加密方案
在神经网络推理中,如何为不同层选择同态加密方案,核心在于平衡计算效率、功能需求和安全性。下面这个表格汇总了针对不同层级的主流方案选择和建议。
|
神经网络层级 |
核心计算特征 |
推荐同态加密方案 |
关键优化技术 |
|---|---|---|---|
|
卷积层 / 全连接层 |
大量的线性计算(矩阵乘法、向量内积) |
CKKS 方案 |
密文打包、SIMD |
|
非线性激活函数层 |
非多项式运算(如ReLU, Sigmoid, GELU) |
CKKS方案(多项式逼近) 或 混合方案(如结合LWE) |
分布感知的多项式逼近 、计算协议融合 |
|
通用考量与趋势 |
兼顾安全假设与性能 |
CKKS(主流)、BFV(需精确整数结果) |
混合协议(同态加密+安全多方计算) |
选择依据与优化策略
选择不同方案主要基于以下考量:
-
卷积层与全连接层为何适合CKKS?
这些层的核心是线性运算,如矩阵乘法和向量内积。CKKS方案的优势在于支持浮点数近似计算,这与神经网络对数值精度的天然容错性非常匹配。更重要的是,CKKS支持高效的密文打包和单指令多数据(SIMD) 技术 。这意味着可以将整个向量或矩阵的多个元素打包到一个密文中,一次同态操作就能完成大量计算,极大地提升了吞吐量,克服了同态加密计算开销大的主要瓶颈。
-
非线性激活层如何处理?
像ReLU或GELU这样的激活函数是非多项式运算,无法直接在密文上计算。主流做法是采用多项式函数(如分段低次多项式)来近似模拟这些非线性函数,而CKKS方案正好支持对这些近似多项式进行同态计算 。为了进一步提升效率和精度,前沿研究采用了分布感知的近似方法,即根据网络中真实激活值的统计分布来优化多项式近似的区间和系数,从而用更简单的多项式实现更高的近似精度 。另一种思路是混合方案,例如在卷积等线性部分使用CKKS,而在激活函数处转换为支持布尔运算的LWE密文等形式进行处理,之后再转换回来,但这会带来额外的转换开销 。
-
其他重要考量因素
-
BFV方案:如果神经网络推理要求得到精确的整数结果,BFV方案可能更合适,但它通常比CKKS带来更大的计算开销 。
-
混合协议:在极度追求性能的场景下,常采用混合协议。例如,线性部分使用同态加密,而非线性部分则结合安全多方计算 技术,这通常能获得比纯同态加密方案更快的速度,但代价是通信开销较大 。
-
核心权衡与实践建议
在实际应用中,您需要根据具体需求在以下几个维度做出权衡:
-
效率 vs. 精度:使用低阶多项式近似激活函数可以提升速度,但可能引入精度损失。需要评估您的应用对推理准确率的敏感度 。
-
通用性 vs. 定制化:为特定模型结构(如Transformer)或特定层定制加密方案和优化策略,往往能获得最佳性能,但这牺牲了通用性 。
-
安全假设:大部分同态加密方案针对的是“半诚实”敌手模型。如果您的威胁模型包含“恶意”敌手,则需要考虑引入零知识证明 等机制来验证计算的正确性,但这会带来显著性能开销 。
总结
总而言之,目前CKKS方案因其对浮点近似计算的良好支持和高效的SIMD操作,已成为神经网络隐私推理的主流选择,尤其适用于卷积层和全连接层。对于非线性层,则通过精心设计的多项式逼近或在混合协议中处理。最终方案的选择,取决于您的具体业务场景对安全、效率、精度和开发复杂度的综合要求。
2.3.10 Transformer模型的自注意力机制中应用同态加密
在Transformer模型的自注意力机制中应用同态加密,确实需要在安全性、计算效率和模型精度之间做出精细的权衡。同态加密本身计算开销大,而自注意力机制又存在二次复杂度,这使得直接套用传统方法非常困难。下面的表格梳理了关键的适配与优化策略。
|
优化维度 |
核心策略 |
具体方法与目标 |
|---|---|---|
|
算法层面 |
近似与简化 |
使用多项式函数逼近Softmax等非线性操作;利用注意力矩阵的稀疏性(如局部窗口注意力)减少实际计算量。 |
|
计算层面 |
量化与融合 |
采用低精度量化(如INT8)减少同态操作数;进行操作融合,将多个线性步骤合并为一次加密计算。 |
|
系统层面 |
并行与硬件加速 |
利用GPU/TPU的并行计算能力和同态加密专用硬件加速器;设计高效的批处理策略以提升吞吐量。 |
算法层面的核心适配
自注意力机制中的某些操作与同态加密的特性存在天然冲突,需要专门的算法改造。
-
非线性操作的近似:自注意力机制中的Softmax函数是非多项式运算,无法直接在密文上执行。最常见的策略是使用多项式函数(如通过泰勒展开或切比雪夫逼近得到的低阶多项式)来近似Softmax的指数运算和除法操作。但这会引入近似误差,需要在计算效率、安全性(多项式次数可能泄露信息)和模型精度之间取得平衡。
-
利用注意力稀疏性:标准的自注意力矩阵是稠密的。研究表明,许多场景下注意力矩阵本质上是稀疏的。可以借鉴如局部窗口注意力(限制每个token只关注其邻近窗口内的token)或聚类注意力(让token只关注与其相似的少数关键token)等思想,显著减少需要计算和加密的注意力对数量,从而大幅降低计算复杂度。
计算与系统优化
在算法改进之外,计算和系统层面的优化对于实现可行性至关重要。
-
低精度量化与操作融合:同态加密操作随数据精度提高而代价剧增。在加密前,对模型权重和中间激活值进行低精度量化(如从FP32降至INT8甚至INT4),可以极大减少同态乘法的开销。此外,将注意力计算中的多个线性操作(如Q、K、V的投影)融合成一个更大的矩阵乘法,可以减少加密域与明文域之间的频繁转换,提升整体效率。
-
硬件加速与批处理:同态加密计算是高度并行的,非常适合在GPU上加速。此外,一些研究开始探索为同态加密设计的专用硬件加速器。在实际部署时,通过批处理(Batching)技术,将多个数据样本或序列位置的同类型计算打包成一个任务,可以充分利用硬件并行能力,显著提高吞吐量。
重要权衡与注意事项
在设计和选择策略时,必须清醒地认识到以下几个关键权衡:
-
安全、效率与精度的三角权衡:这是核心矛盾。更强的安全假设(如更大的多项式模数)会降低效率;更激进的计算近似(如低阶多项式逼近)会损害精度。需要根据具体应用场景(如对隐私要求极高的医疗数据分析,或对实时性有要求的场景)确定优先级。
-
通信开销的考量:在某些隐私计算框架下(如将同态加密与安全多方计算结合),密文数据需要在参与方之间传输。计算流程的优化可能会增加通信轮次或数据量,网络带宽可能成为新的瓶颈。
-
端到端的安全设计:同态加密只是保护数据“计算中”的状态。必须确保数据在客户端加密前、服务端计算后结果返回解密的整个流程都是安全的,构成一个完整的可信链条。
稀疏注意力机制与同态加密的结合,确实能显著降低计算复杂度,但其效果高度依赖于具体的算法设计、硬件优化以及任务类型。下面这个表格汇总了关键维度的优化潜力,帮助您快速建立整体认知。
|
优化维度 |
核心策略 |
对同态加密计算复杂度的潜在影响 |
|---|---|---|
|
算法理论层面 |
将全连接(稠密)的注意力矩阵变为稀疏矩阵,仅计算关键位置之间的关联。 |
将计算复杂度从 O(n²) 降低至 O(n log n) 甚至更低,直接减少需要同态计算的注意力对数量。 |
|
硬件与内核层面 |
设计硬件对齐的专用内核,优化内存访问模式,充分利用GPU等硬件的并行计算能力。 |
大幅提升单位时间内的计算吞吐量,缓解同态加密的内存带宽瓶颈,使理论加速得以实现。 |
|
实际基准测试 |
在特定模型(如DeepSeek NSA)和序列长度下进行测量。 |
在8k序列长度的预填充阶段,可实现近12倍的加速比,并将KV缓存的内存访问量降低超过80%。 |
复杂度如何被降低
同态加密(特别是全同态加密FHE)在Transformer模型中的主要计算瓶颈在于注意力机制,其计算量随序列长度呈二次方增长。稀疏注意力机制通过以下方式从根本上减轻这一负担:
-
减少计算单元:传统的注意力机制需要计算序列中每个查询(Query)与所有键(Key)之间的关联度,形成一个稠密的矩阵。稀疏注意力机制则像是一个“筛子”,通过局部注意力、全局令牌、滑动窗口等策略,只选择性地计算部分关键的查询-键对,而忽略大量次要的关联。这意味着需要进行同态乘法和加法运算的元素数量被大幅削减。
-
改变复杂度类别:如上表所示,这种筛选策略能够将注意力计算的理论复杂度从平方级降低到接近线性级。这对于处理长文本、高分辨率图像等长序列场景至关重要,使得在密文状态下进行长序列建模变得可行。
🚀 来自实践的性能数据
理论是美好的,但实际性能更为关键。一些前沿研究已经给出了具体的基准测试数据。
例如,DeepSeek提出的NSA(Native Sparse Attention)机制是一个将稀疏注意力与同态加密思想结合进行优化的典型案例。根据其报告的性能数据:
-
加速比:在序列长度为8k的预填充(pre-fill)阶段,其专用内核相比标准的全注意力计算,实现了11.93倍的加速比。
-
内存访问优化:同样是8k序列长度,其KV缓存的内存访问量减少了84.5%。这一点尤为重要,因为同态加密过程中巨大的内存带宽需求往往是主要的性能瓶颈之一。
这些数据表明,通过精心的算法与硬件协同设计,稀疏注意力机制能为同态加密带来数量级级别的性能提升,使原本计算成本高昂的加密模型推理向实用化迈进了一大步。
⚖️ 重要的权衡与注意事项
在为您描绘了乐观图景的同时,也必须指出其中的权衡和挑战:
-
精度与效率的权衡:稀疏性本质上是一种近似。过滤掉部分注意力连接可能会造成模型性能(如预测准确率)的轻微下降。设计时需要确保稀疏模式能够捕捉到足够的关键信息,以维持模型质量。
-
算法与硬件的协同:并非所有稀疏注意力算法都能天然地适配同态加密或高效运行在硬件上。例如,一些基于动态聚类的算法可能引入难以优化的不规则内存访问模式。最高效的方案往往是像NSA那样,从开始就为目标硬件(如GPU)进行原生设计和优化。
-
非线性激活的挑战:即便注意力计算被稀疏化,Transformer中的非线性激活函数(如GeLU、SiLU) 在同态加密下处理起来仍然非常昂贵,通常需要用多项式函数来近似,这也会引入额外的计算和精度损失。
2.4 数据安全的管理学基础
2.4.1 数据安全的管理学基础
数据安全确实远不止于技术堆砌,而是一套深刻嵌入管理学思维的复杂实践。下面这个表格可以帮助你快速把握数据安全中管理学基础的核心维度及其关联。
|
管理学科 |
在数据安全中的核心应用导向 |
关键管理思维/框架举例 |
|---|---|---|
|
管理学原理 |
确立数据安全的治理框架、权责体系和文化基调,解决“如何组织与决策”的问题。 |
数据安全治理框架(如Gartner DSG)、战略规划、组织架构设计(决策层、管理层、执行层、监督层)、制度流程建设、PDCA循环。 |
|
统计学 |
提供量化洞察和风险建模的方法,解决“如何评估与预测”的问题。 |
描述性统计(安全事件分析)、推断性统计(威胁预测)、统计过程控制(异常行为基线建模)、回归/聚类分析(威胁模式发现)、概率犹豫模糊集(专家决策信息处理)。 |
|
运筹学 |
实现安全资源的最优配置和流程优化,解决“如何权衡与决策”的问题。 |
多目标优化(平衡安全、成本、效率)、任务调度算法(MapReduce/Spark框架下考虑安全约束)、决策分析(风险偏好量化)、资源分配模型。 |
管理认知与跨边界框架
在数据安全领域,清晰的管理认知和有效的跨边界协同至关重要。
-
核心管理认知框架
理解数据安全,可以建立起几个关键的认知框架:
-
“安全左移” (Shift-Left Security):将安全考量前置到系统和产品设计的初始阶段,使安全由事后补救变为内置属性。这要求安全团队早期介入,与开发、运维等团队紧密协作。
-
隐私保护设计 (Privacy by Design):在产品或服务开发的整个生命周期中,预先嵌入隐私保护措施,使其成为默认设置。
-
零信任 (Zero Trust):核心原则是“从不信任,始终验证”。它要求摒弃传统的基于网络边界的静态信任假设,对每一次访问请求都进行严格认证和授权。
-
-
跨边界协同管理
数据安全涉及组织内多个部门,甚至外部合作伙伴,有效的跨边界管理是关键难点和成功要素。
-
内部协同:需要打破技术、业务和管理部门之间的壁垒。例如,京东科技提出的三层管理模型(高级管理人员、中层管理团队、数据治理工作组),旨在明确各层级在数据安全治理中的角色与责任,促进协同。
-
外部协同与生态治理:数据在复杂生态中高频流动,单一组织的能力是有限的。因此,需要建立与云服务商、第三方合作伙伴等的问责机制和责任共担模型。例如,通过合同明确数据安全责任,或引入第三方认证(如基于DSMM的评估)来评估合作伙伴的数据安全能力。
-
在数据安全领域,管理学原理、统计学和运筹学并非孤立存在,而是相互交织。例如,可以依据管理学原理确立安全目标和组织职责(Plan),利用统计学方法量化风险并监测运行状态(Check),再通过运筹学模型优化安全控制措施和资源投放(Do),进而持续改进(Act)。同时,有效的跨边界管理确保了上述过程在复杂的组织内外部环境中得以顺利执行。
2.4.2 PDCA循环(Plan-Do-Check-Act)促进数据安全治理
PDCA循环(Plan-Do-Check-Act)为数据安全治理提供了一个高效的持续改进框架。下面这个表格总结了其在数据安全治理中各阶段的核心活动与关键产出,之后我会结合实例加以说明。
|
PDCA阶段 |
核心活动与关键产出 |
|---|---|
|
计划 (P) |
活动:识别数据资产与业务流、进行风险识别与根因分析、设定改进目标、制定解决方案。 |
|
执行 (D) |
活动:技术手段落地(如部署加密网关、动态脱敏)、管理措施实施(如修订安全管理制度、开展意识培训)。 |
|
检查 (C) |
活动:通过自动化审计工具监控、渗透测试、专项审计、风险度量等方式评估效果。 |
|
处理 (A) |
活动:对成功经验进行标准化固化,对未解决问题进行根因分析并纳入下一循环。 |
各阶段应用实例
-
计划阶段实例:某金融企业在计划阶段,系统性地识别了其业务系统边界、用户权限图谱和数据资产分布,建立了 “业务流-数据流-权限流”的三维映射模型。此举帮助他们精准定位了1200个敏感数据处理节点,清晰界定了需要保护的重点目标和范围,为后续制定精准的防护策略奠定了坚实基础。
-
执行阶段实例:中国移动浙江公司在执行阶段,为保护数据开放共享安全,建设了授权网关,并基于数据分类分级实施敏感数据访问的动态脱敏。同时,他们整合文档加密授权和终端泄露防护能力,通过统一客户端实现对涉敏文档的落地加密、权限控制和外发管控,有效防止数据二次泄密。
-
检查阶段实例:某政务云平台在检查阶段,利用自动化合规审计工具,每月生成超过2000项安全指标的分析报告。这些量化的报告,结合攻防演练中发现的43个脆弱环节,共同为防护策略的迭代更新提供了客观依据和明确方向。
-
处理阶段实例:浙江省肿瘤医院在处理阶段,将成功经验标准化,例如将定期信息安全培训、修订后的制度、更新设备等有效措施固化为常规工作。同时,他们将未彻底解决的问题或新发现的隐患(如某些难以根除的病毒变种)纳入下一个PDCA循环,实现了安全水平的阶梯式上升,最终使内网设备病毒感染率从3.83%显著降低至0.1%。
总结与建议
PDCA循环的精髓在于闭环管理和持续改进。它引导数据安全治理从一个静态的、项目式的活动,转变为一个动态的、融入日常运营的有机过程。
在实践中,成功应用PDCA需要注意以下几点:
-
小步快跑:不必追求在一个循环内解决所有问题。可以聚焦当前最突出的风险,完成一个有效的短周期循环,其价值远大于一个庞大却难以落地的计划。
-
数据驱动:在Check阶段,尽量采用可量化的指标(如威胁响应时间、安全事件数量、漏洞修复周期等)来衡量效果,让改进方向更加清晰。
-
文化与协同:PDCA的有效运行有赖于清晰的组织架构和职责分工(例如设立由CISO牵头的三级治理架构),并需要技术、管理、运维乃至业务部门的共同参与,从而形成合力。
2.4.3 概率犹豫模糊集支持数据安全风险评估
概率犹豫模糊集(Probabilistic Hesitant Fuzzy Sets, PHFS)在处理数据安全风险评估中专家意见的模糊性和不确定性方面表现出色。它通过为每个可能的隶属度值分配概率,来精细刻画决策时的犹豫程度。下面我们来看其应用方式和数学模型。
概率犹豫模糊集的核心概念
概率犹豫模糊集是犹豫模糊集的扩展。一个概率犹豫模糊集定义如下:
H={<x,hx(px)>∣x∈X}
其中,hx(px)={γl(pl)∣l=1,2,...,∣hx(px)∣}被称为概率犹豫模糊元(Probabilistic Hesitant Fuzzy Element, PHFE)。这里,γl是元素 x属于集合 H的隶属度,而 pl是该隶属度发生的概率。所有可能的概率之和为 1,即 ∑l=1∣hx(px)∣pl=1。
例如,在评估某个数据存储系统“遭遇外部攻击导致泄露的风险”时,专家组的评价用 PHFE 表示为 {0.7(0.3),0.9(0.7)}。这意味着,30% 的专家认为风险隶属度是 0.7(中等风险),70% 的专家认为是 0.9(高风险)。
应用于数据安全风险评估的数学模型与流程
将概率犹豫模糊集应用于数据安全风险评估,通常遵循一个结构化的流程,其核心步骤和相关的数学模型可概括如下:
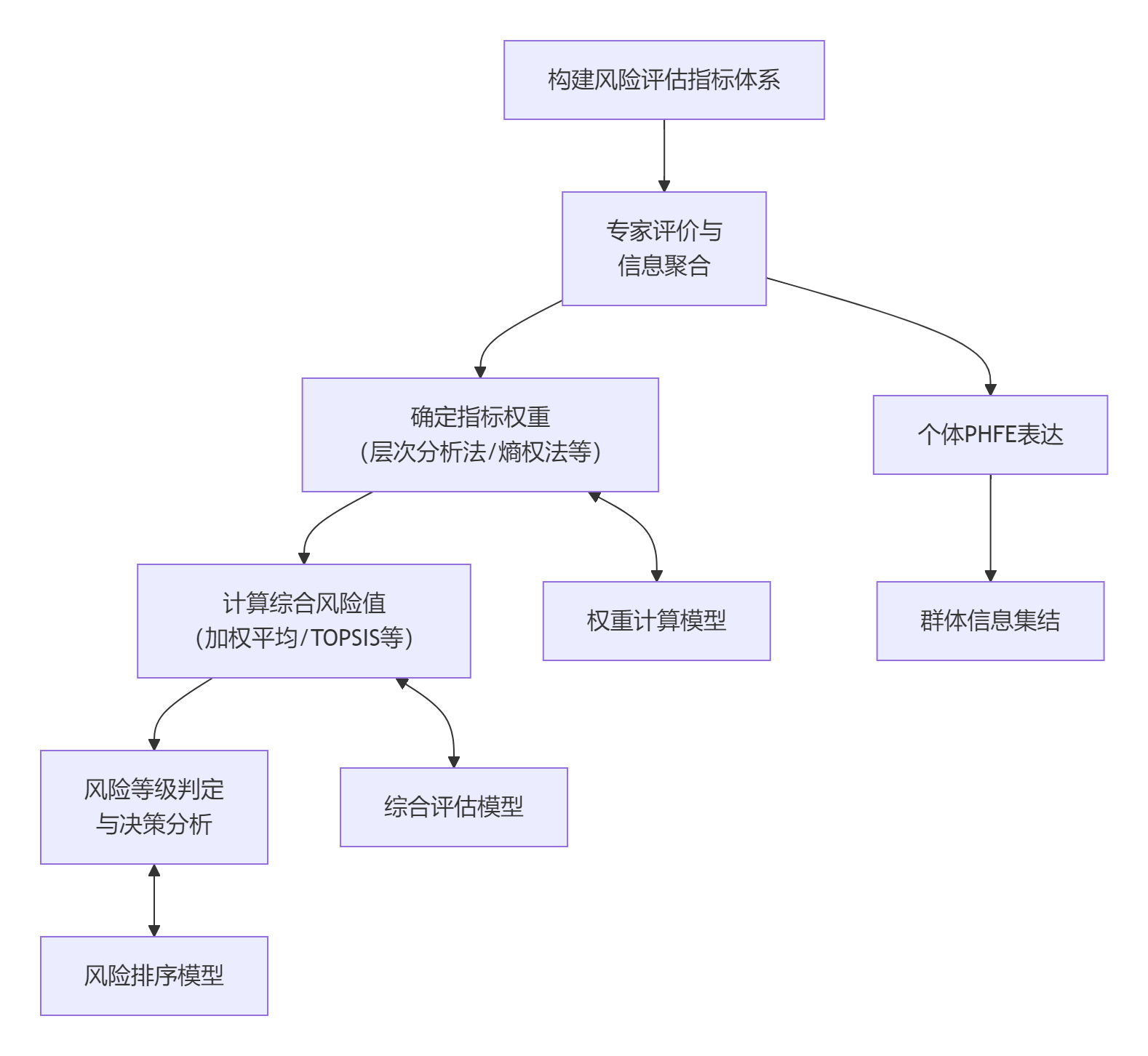
第一步:构建分层风险评估指标体系
首先需要建立一个全面、结构化的风险评估指标体系。例如,在医疗数据安全评估中,指标体系通常包含多个层级:
-
一级指标:如“数据全生命周期安全”和“数据管理安全”。
-
二级指标:隶属于一级指标,如“数据存储安全”、“数据处理安全”、“数据传输安全”等。
-
三级指标:最具体的评估维度,如“存储媒体安全”、“逻辑存储安全”、“数据备份与恢复”等。
第二步:专家评价与信息表达
邀请多位专家对最底层的每个风险指标进行评估。每位专家提供一个或多个隶属度值,表示其对特定风险水平的判断。统计所有专家的评价,为每个底层指标形成一个概率犹豫模糊元(PHFE),其中包含了不同隶属度值及其对应的专家比例(概率)。
第三步:确定指标权重
不同风险指标的重要性不同,需要确定其权重 wj。常见的方法包括:
-
主观赋权法:如层次分析法(AHP),通过专家两两比较指标的重要性构建判断矩阵来计算权重。
-
客观赋权法:如熵权法,基于各指标下评估值的差异程度(信息熵)来计算权重。
有时也会将主客观方法结合,得到综合权重。
第四步:计算综合风险值并排序
有了各底层指标的PHFE和权重后,需要集结这些信息,得到系统的整体风险值。常用方法包括:
-
加权平均聚合:使用如广义概率犹豫模糊Hamacher加权平均(GPFHWA)等算子,将各指标的PHFE按权重聚合为一个综合的PHFE。
-
TOPSIS法:计算每个方案的PHFE与正理想解(最安全状态)和负理想解(最危险状态)的距离。通常使用加权海明距离等公式。然后计算相对贴近度 CI,其值越接近1,表示风险越高;越接近0,表示风险越低。
例如,贴近度 CI的计算公式考虑到了决策者的风险偏好 θ(0 ≤ θ ≤ 1),θ > 0.5 表示决策者是风险追求型,θ < 0.5 表示是风险规避型:
CI=d++d−d−或更复杂的形式CI=θd++(1−θ)d−d−
其中 d+是到正理想解的距离,d−是到负理想解的距离。
第五步:风险等级判定与决策
根据计算出的综合得分或相对贴近度,参照预设的风险等级标准(如“低风险”、“中等风险”、“高风险”),即可判定系统的整体安全风险等级,为管理者提供决策依据。
方法优势与适用场景
概率犹豫模糊集方法在数据安全风险评估中具有显著优势:
-
信息保留更完整:能同时保留专家给出的所有可能评估值及其概率分布,不损失信息。
-
处理不确定性能力强:特别适合处理专家意见存在分歧、决策信息不完整的复杂评估场景。
-
灵活性高:可以与多种决策方法(如TOPSIS、VIKOR、MULTIMOORA)结合,适应不同的评估需求。
这种方法尤其适用于涉及大量主观判断、多种数据源、需要在不确定性环境下进行预测性评估的场景。
2.4.4 跨边界数据协同场景下设计合理的责任共担与问责机制
2.4.4.1 责任共担与问责机制
在跨边界数据协同场景下,设计合理的责任共担与问责机制至关重要。下面这个表格梳理了其核心设计维度,可以帮助你快速把握要点。
|
核心维度 |
关键要素 |
设计要点与挑战 |
|---|---|---|
|
责任共担模型 |
主体识别与角色界定 |
明确数据控制者、处理者、协同平台等各方角色。例如,欧盟《通用数据保护条例》(GDPR)明确由数据控制者承担数据保护的主要责任。可借鉴“基础服务—平台服务—深度协作”的分层思路,根据参与度界定责任。 |
|
责任范围与分配 |
遵循数据主权和本地化存储要求(如物理层面责任),同时明确在逻辑和内容层面的义务边界。可引入“负面清单”机制,明确禁止行为,清单外则鼓励创新。 |
|
|
动态适配与场景化 |
责任分配需根据数据敏感性(如个人数据、核心数据)、业务场景风险(如应急联防与民生服务不同)进行动态调整。 |
|
|
问责机制 |
清晰的法律与合同依据 |
通过具有法律约束力的文件(如标准合同条款)明确各方权利义务。例如,美欧之间的《隐私盾协议》(已失效,其演变为《欧盟-美国数据隐私框架》)和亚太经合组织的CBPR体系都为企业提供了合规路径。 |
|
全链路安全控制与追溯 |
采用技术手段确保问责落地,如字段级权限控制、区块链存证(实现数据操作的全生命周期可追溯)。 |
|
|
有效的争议解决与救济 |
为权益受损方提供清晰的申诉、赔偿和追责渠道。例如,美欧协议中要求必须为用户提供有效的救济途径。 |
成熟的法律与技术框架参考
在具体实践中,有以下一些相对成熟的法律机制和技术路径可供参考:
-
法律与合规框架
-
充分性认定与“白名单”制度:欧盟委员会可认定非欧盟国家是否提供了与欧盟实质等同的数据保护水平。被列入“白名单”的国家、地区或特定行业领域可获得数据跨境流动的便利。
-
标准合同条款(SCCs):企业可通过采纳由监管机构制定或认可的标准合同文本,来约束数据接收方,从而满足跨境传输的合规要求。
-
约束性公司规则(BCRs):适用于跨国集团内部的数据传输。集团制定一套经监管部门批准的统一数据保护政策,在其全球分支机构间共同遵守。
-
跨境监管沙盒:为平衡创新与风险,可在特定领域(如跨境支付)试点监管沙盒,在可控环境中测试新技术和新模式,并配套相应的容错和激励机制。
-
-
技术实现框架
-
数据标准化与互操作:建立统一的数据元标准、接口规范是协同的基础。例如,长三角地区在推进“跨省通办”时,首先就民生服务字段的定义进行了统一。
-
“三位一体”协同平台架构:参考业界实践,可构建涵盖数据标准化、智能核验中枢、跨域安全交换等功能的平台架构,为协同提供技术支撑。
-
实施路径建议
构建有效的责任与问责机制并非一蹴而就,可以遵循分阶段实施的路径:
-
奠基阶段(0-6个月):核心是摸清家底。梳理协同涉及的数据目录、明确各参与方的权责清单,并界定出数据的负面清单或敏感等级。选择个别高频、需求迫切的场景进行试点。
-
贯通阶段(7-18个月):重点在于构建协同能力。建立安全的数据交换中间件或平台,解决新旧系统差异问题。部署动态规则引擎,以自动化方式应对法规变化和复杂场景的合规判断。
-
优化与跃迁阶段(19个月以上):目标是实现可持续的协同治理。将前期试点经验转化为可复制的标准和模式,并逐步推广到更多场景。同时,利用数据分析与AI技术,从事后问责向事前风险预警和事中动态管控演进。
总结
跨边界数据协同中的责任与问责机制设计,本质上是一场治理模式的变革。它要求从传统的孤立管控转向基于信任、技术与规则的网络化协同。
2.4.4.2 金融和医疗行业在跨边界数据协同中责任共担模型的差异
理解金融和医疗行业在跨边界数据协同中责任共担模型的差异,对于设计合规高效的协作方案至关重要。这两个行业因数据属性、监管环境和核心目标的不同,其责任共担模型的设计也呈现出鲜明的特色。
|
比较维度 |
金融行业责任共担模型特点 |
医疗行业责任共担模型特点 |
|---|---|---|
|
核心责任焦点 |
风险共担与实时风控:侧重于欺诈识别、信用评估、市场风险联防联控,强调风险的即时发现与阻断。 |
生命健康与隐私保护:首要目标是保障患者生命安全、提升诊疗准确性,并对隐私保护有极致要求。 |
|
技术实现路径 |
偏好高效、可解释的技术:广泛采用联邦学习进行联合建模,并依赖区块链进行可信存证和自动化分润,追求在风控效果和商业回报间取得平衡。 |
倾向高强度的隐私保护技术:常使用差分隐私、同态加密、可信执行环境(TEE)等技术,确保原始临床和基因数据“不出域”,对技术强度的要求更高。 |
|
激励与回报机制 |
直接的经济收益分润:通过精准量化各方数据在风控模型中的贡献度(如使用Shapley值),并利用智能合约实现风控服务收益的自动、透明分配。 |
科研价值与间接回报:回报往往体现为联合科研产出(如新药研发、疾病模型优化)、公共卫生效益(如区域疾病防控),以及医保基金的结余留用。 |
|
监管与合规框架 |
面临严格的嵌入式监管:监管节点可嵌入数据流通链路,实现穿透式、实时监管。需将《数据安全法》等法规要求直接转化为智能合约中的可执行代码。 |
需通过多重伦理与合规审查:除法律法规外,还需接受区域性伦理审查委员会的审查。协同项目需确保患者知情同意,并严格限定数据使用场景和范围。 |
行业差异背后的深层逻辑
表格中的差异主要源于两个行业根本性的不同:
-
数据性质不同:金融数据(如交易流水、征信记录)虽然敏感,但其价值主要体现在统计规律和关联关系上。通过隐私计算技术,可以在不暴露原始数据的前提下提取这些规律。而医疗数据(如基因序列、特定病例)本身往往就包含直接的临床诊断价值或高价值的科研信息,其“原始数据”的泄露可能对患者造成不可逆的伤害,或直接泄露商业机密,因此对“数据不出域”的要求更为绝对。
-
核心目标不同:金融协同的最终目标是管理风险、实现资金的有效配置和商业盈利,具有强烈的经济导向。医疗协同的最终目标是提升诊疗水平、保障公民健康、促进医学进步,社会公共属性更强。这直接决定了对数据价值回报的不同期待。
实践启示
了解这些差异后,在实际工作中我们可以参考以下几点:
-
避免“一刀切”:为金融或医疗项目设计责任共担模型时,必须深入理解该行业的业务逻辑、监管红线和技术偏好,不能简单套用模板。
-
关注技术融合:当前趋势是多种隐私计算技术与区块链、可信数据空间等技术融合应用。例如,医疗领域正在探索“联邦治理+智能合约”的双核模型,以实现更精细的治理。
-
重视动态调整:责任共担模型不是一成不变的。随着法规更新、技术演进和业务场景的拓展,模型需要具备一定的动态调整能力,通过定期评估和协议更新来适应变化。
2.4.4.3 金融风控中精准量化各方数据的贡献度
在金融风控中,精准量化各方数据的贡献度,对于优化模型、控制成本及促进数据合作都至关重要。这背后有一套融合了统计学、机器学习合作博弈论的成熟方法论。
|
阶段 |
核心任务 |
关键活动与产出 |
|---|---|---|
|
1. 数据准备与评估 |
为分析准备高质量、可比较的数据基础。 |
数据预处理:清洗、对齐来自各方的数据。质量评估:使用“三率”(覆盖率、缺失率、准确率)等指标评估各数据源质量。 |
|
2. 模型构建与基准建立 |
构建风控模型并确立性能基准。 |
模型训练:使用所有可用数据训练模型(如逻辑回归、GBDT)。基准性能:在测试集上得到模型基准性能(如AUC、KS值)。 |
|
3. 贡献度计算 |
运用特定方法量化各数据源的贡献。 |
方法执行:采用Shapley值法或排列重要性法进行计算。贡献分数:得到每个特征或数据源的数值化贡献度。 |
|
4. 结果解读与应用 |
理解贡献度含义并用于实际业务。 |
业务解读:结合业务知识分析贡献度高低的原因。策略应用:根据结果优化特征工程、模型或数据采购策略。 |
主流计算方法与工具
在以上流程的第三步,有以下几种成熟的计算方法:
-
基于合作博弈论的 Shapley 值法
这是理论上最为公平的贡献度分配方法之一。它通过计算某个特征在所有可能的特征组合下对模型性能的平均边际贡献来评估其价值。
-
优势:理论坚实,考虑特征间的协同效应,结果公平。
-
挑战:计算复杂度随特征数量增加呈指数级增长,需借助抽样等近似算法。
-
工具:Python中的
shap库是当前最流行的实现。
-
-
基于模型自身的特征重要性
-
排列重要性:思路直接,将某个特征的值随机打乱,然后观察模型性能下降的程度。性能下降越多,说明该特征越重要。
-
内置重要性:如梯度提升树(GBDT)模型可输出基于分裂次数或信息增益的特征重要性。
-
优势:计算效率高,易于理解。
-
注意:内置重要性可能对有大量取值的特征有偏差;排列重要性更能反映预测能力。
-
-
基于信息价值的评估指标
在传统风控中,信息值(IV) 是一个关键指标,用于衡量一个特征对目标变量(如是否违约)的预测能力。
-
评估标准:通常认为IV值小于0.02的特征预测能力无用;0.1-0.3预测能力中等;大于0.3则预测能力强。
-
优势:直观反映了特征在区分好坏客户方面的能力。
-
实施流程与关键工具
-
数据评估与预处理:首先需对来自不同合作方的数据质量进行量化评估,这是后续分析可靠性的基础。关键指标包括覆盖率(已匹配样本数/总样本数)、缺失率和准确率等。此外,特征的稳定性也至关重要,通常使用群体稳定性指数(PSI) 来监控,PSI值低于0.1说明特征分布很稳定。
-
模型构建与可解释性分析:利用PaddlePaddle(飞桨) 等深度学习框架,可以提供诸如SHAP、LIME等可解释性工具包,帮助理解复杂模型中特征的贡献度。对于更传统的机器学习模型,Scikit-learn 提供了丰富的模型和特征重要性评估工具。
-
业务解读与持续监控:贡献度分析并非纯技术工作。数字本身的重要性(如高IV值)需要结合业务知识来解读,判断其是否符合业务逻辑。风控环境在不断变化,需要建立持续监控机制,定期评估特征贡献度的稳定性(如监控PSI),确保模型持续有效。
核心思维框架
要有效实施数据贡献度量化,可以建立以下思维框架:
-
系统性视角:将风控模型视为一个由多方数据协同作用的系统,贡献度分析旨在理解系统内各部分的相互作用。
-
动态评估:认识到数据的重要性并非一成不变,需随着业务发展、市场环境和数据本身的变化而进行持续评估和调整。
-
业务导向:始终坚持技术方法服务于业务目标,量化贡献度的最终目的是为了优化风控策略、提升决策效率和降低风险成本。
2.4.4.4 政务、物流等行业在跨边界数据协同
政务、物流等行业在跨边界数据协同方面,因其公共属性和业务特点,衍生出了与金融、医疗差异显著的责任共担模型。下面这个表格梳理了它们在核心目标和责任分担上的独特之处。
|
行业领域 |
核心协同目标 |
独特的责任共担模式与焦点 |
|---|---|---|
|
政务数据 |
提升治理效能与公共服务水平 |
法定责任主导的共享机制:依据《政务数据共享条例》,建立"谁管理谁负责、谁使用谁负责"的责任链条,通过统一的目录管理和法定的共享流程(如无条件共享类数据1个工作日内答复)来划分责任。 |
|
物流数据 |
降低全社会物流成本,提升供应链效率 |
场景驱动与市场化运营结合:围绕多式联运、国际物流等具体场景,通过国家物流公共数据共享开放清单明确数据供给责任;通过授权运营和政府指导价等机制,平衡公益性与市场化需求,实现责任与利益共担。 |
|
农村物流(特色模式) |
服务乡村振兴,打通"最后一公里" |
多元主体共建共享:政府、邮政、供销社、农业企业、商户、群众等多方共同参与,通过构建"共同缔造+城乡共享"模式,在基础设施(县、镇、村三级网络)、运力资源、数据信息上深度整合,责任共担,收益共享。 |
行业模式背后的逻辑
这些独特的责任共担模式,源于各行业不同的属性和要解决的核心问题:
-
政务数据的核心在于其公共属性和法定职责。其协同首要目标是提升政府效能和公共服务水平,因此责任划分强调权威性、规范性和强制性。《政务数据共享条例》的出台正是为了从根本上破解"不愿共享、不敢共享、不会共享"的难题,通过立法明确各方在数据共享中的责任与义务。
-
物流数据的核心在于其强关联性和经济性。它连接生产和消费,涉及环节众多,其协同的直接目标是降本增效。因此,其责任共担模型更注重实用性和可持续性,采用"场景驱动"的方式,让数据协同直接服务于具体的业务需求(如"一单制"联运),并通过授权运营、分类定价等市场化机制,让参与方都能从数据开放中获得实际利益,从而愿意并能够承担相应责任。
-
农村物流作为物流领域的特殊场景,其核心痛点是基础薄弱、成本高昂。因此,其模式更强调在政府引导下,最大限度地整合和复用现有社会资源(如交通、邮政、供销、客运班线等),通过"共建共治"来分摊成本、共享收益,是一种典型的在资源约束条件下形成的协同模式。
理解这些模式的区别,在实际工作中非常重要:
-
参与政务数据项目时,要高度重视合规性,严格遵循《政务数据共享条例》等法规设定的目录、流程和安全责任要求。
-
参与物流数据平台建设时,应聚焦于有明确商业价值的具体场景(如跨境电商物流、大宗商品多式联运),并设计好可持续的利益分配机制,这是吸引各方参与并承担责任的关键。
-
在设计跨行业数据协同方案时,切忌生搬硬套。必须深入分析该行业的业务本质、核心驱动力(是公共责任、经济效益还是资源整合)以及关键参与方的核心诉求,才能设计出可行的责任共担模型。
2.4.4.5 信贷审批和反欺诈场景中量化数据贡献度的目标
在信贷审批和反欺诈场景中,量化数据贡献度的目标虽然都是提升风控效果,但由于核心目标不同,其侧重点、评估方法和具体指标都存在显著差异。总的来说,信贷审批追求的是稳定性与可解释性,而反欺诈则更强调实时性与异常识别能力。
|
对比维度 |
信贷审批场景 |
反欺诈场景 |
|---|---|---|
|
核心目标 |
评估长期信用风险,预测借款人未来的还款能力和意愿 |
识别瞬时欺诈意图,检测当前的异常行为 |
|
数据侧重 |
强金融属性数据:收入、负债、央行征信、资产证明 |
弱金融属性数据:设备指纹、行为序列、地理位置、关联网络 |
|
量化重点 |
特征的 预测稳健性 和 业务可解释性 |
特征的 异常识别能力 和 实时响应速度 |
|
典型量化指标 |
特征信息值(IV)、群体稳定性指数(PSI)、SHAP值(对违约概率的贡献) |
精确率、召回率、F1-Score、规则命中率、实时计算延迟 |
信贷审批:关注稳定与可解释的预测
在信贷审批中,模型的核心是预测借款人在未来(如未来1-2年)的违约概率。因此,对数据贡献度的评估侧重于其预测能力的稳定性和可解释性。
-
侧重点:重点关注那些能够反映借款人长期稳定偿付能力和还款意愿的数据。例如,央行征信报告中的历史还款记录、收入水平、负债情况等强金融属性特征通常是贡献度的核心。模型需要回答的是:“这个人的收入和历史信用,如何共同影响了他违约的可能性?”
-
具体方法与指标:
-
特征筛选与评估:在模型构建前,会使用信息值(IV) 等指标来筛选预测能力强的变量。同时,非常关注特征的稳定性,常用群体稳定性指数(PSI) 来监控特征分布随时间的变化,PSI过高意味着该特征的预测效果可能已经失效。
-
贡献度量化:在模型可解释性层面,SHAP值是基于博弈论的经典方法,它能精确量化每个特征(如“收入水平”、“征信查询次数”)对单笔贷款审批决策的贡献度。这不仅能向监管和客户解释决策逻辑,也是风控团队优化模型的关键依据。
-
反欺诈:追求实时与精准的异常捕捉
反欺诈场景像是在进行一场高速的“猫鼠游戏”,目标是瞬间识别出伪装成正常用户的欺诈者。其数据贡献度评估完全围绕实时性和异常识别灵敏度展开。
-
侧重点:贡献度的核心在于数据能否有效暴露异常信号。设备指纹(如设备是否被频繁重置)、行为生物特征(如击键节奏、滑动轨迹)、操作序列(如页面跳转是否反常)、关联网络(如手机号是否关联多个高风险账户)等弱金融属性数据至关重要。
-
具体方法与指标:
-
模型效果直接体现贡献:反欺诈中,数据的贡献度往往直接由它参与构建的模型或规则的效果来衡量。常用的评估指标包括精确率(抓得准不准)、召回率(漏抓多不多)和F1-Score(综合考量)。如果一个包含设备风险特征的行为序列模型能显著提升F1-Score,就证明这些数据贡献巨大。
-
规则与特征性能:对于基于规则的引擎,会关注规则命中率和准确率。同时,系统对实时性要求极高,要求特征计算和指标监控的延迟极低(如低于100毫秒),以确保能瞬间响应。
-
总结与挑战
简单来说,两个场景的终极目标决定了其方法论:信贷审批是“预测未来”,因此需要稳定、可解释的因果关系;反欺诈是“捕捉当下”,因此需要灵敏、快速的相关关系识别。
在实际应用中,金融机构也面临共同挑战:
-
数据质量:数据的完整性、准确性和时效性是所有分析的基础。
-
模型可解释性与合规:尤其是反欺诈中的复杂模型,需要满足监管对算法公平、透明的要求。
-
数据融合:如何将行为数据等非传统数据与传统财务数据有效融合,统一建模,仍是一个待持续探索的领域。
2.4.4.6 反欺诈场景中设备指纹和行为序列数据的协同计算
在反欺诈场景中,设备指纹和行为序列数据的协同计算,就像是安全系统同时拥有了“身份档案”和“行为录像”,通过综合评估这两方面来更精准地判断风险。
|
协同层面 |
设备指纹的核心作用 (回答“谁”) |
行为序列数据的核心作用 (回答“在做什么”) |
协同计算的关键思路 |
|---|---|---|---|
|
特征层 |
提供设备唯一性标识和静态风险标签。 |
提供动态行为模式特征。 |
将设备风险标签与源自该设备的行为序列特征进行交叉组合,生成新的关联特征。 |
|
模型层 |
作为图网络的节点,连接账号、IP等,揭示群体关系。 |
通过自然语言处理技术转化为数值向量,作为模型输入。 |
在图算法中,设备节点关联其上的行为模式;在集成模型中,两类特征共同训练。 |
|
决策层 |
输出设备层面的风险评分。 |
输出单次会话行为的异常评分。 |
通过加权平均、逻辑回归或更复杂的融合模型,聚合两个评分得到最终风险决策。 |
🔮 贡献度的量化评估
在协同计算中,量化设备指纹和行为序列各自贡献度的核心方法是可解释性AI技术,例如 SHAP。这类方法能计算出在模型做出某个风险判断时,设备特征和行为特征分别起到了多大作用。
举例来说,对于一个被模型判定为高风险的登录事件,SHAP分析可能显示:
-
设备指纹贡献了60%的风险分数:因为该设备ID在短时间内于多个地理位置迥异的IP地址上成功登录了不同账户,呈现出典型的“设备农场”特征。
-
行为序列贡献了40%的风险分数:因为本次登录后的操作序列(如登录后直接进行大额转账、修改关键信息)与账户历史正常模式严重偏离。
这种量化能让风控专家理解模型的决策依据,并优化特征工程和模型。
💁 实际应用案例
让我们看一个电商反“薅羊毛”欺诈的具体案例,感受一下协同计算的实际应用。
-
场景:一个电商平台的促销活动,黑产试图用大量账号批量领取优惠券。
-
设备指纹发现:风险监控系统发现,数百个看似不同的账号都来自一个之前被标记为高风险的设备指纹(例如,该设备曾因自动化行为被识别)。同时,这些账号的注册信息(如收货手机号)呈现出明显的模式化特征,例如属于连续号段或特定号段。
-
行为序列发现:这些账号登录后的行为高度一致:进入活动页面、立即领取优惠券、然后退出,整个流程耗时极短,且操作间隔时间具有机器般的规律性,与正常用户的浏览、比价行为模式差异显著。
-
协同计算与决策:系统将设备风险标签(高风险设备簇)与行为序列异常评分(自动化脚本行为)进行聚合计算。当同一个设备指纹下关联的账号数量及其行为异常分数超过阈值时,风控引擎会实时拦截这些账号的领券请求,并标记该设备指纹及其关联的所有账号,从而阻止一次规模性的“薅羊毛”攻击。
💎 总结与优势
通过设备指纹和行为序列的协同计算,反欺诈系统实现了从单点、静态防御到全局、动态分析的进化。这种协同的优势在于:
-
提升精度:降低单一维度误判,减少误杀。
-
识别未知威胁:即使出现新设备或新IP,异常行为模式也能触发警报。
-
对抗进化:黑产难以同时完美伪造设备标识和模拟正常人类行为,大大增加了其作弊成本。
希望以上的解释和案例能帮助你理解设备指纹与行为序列在反欺诈中是如何协同工作的。如果你对其中某个具体的技术细节(如图神经网络的应用或SHAP值的计算)有进一步的兴趣,我们可以继续探讨。
2.4.5 数据安全治理从“被动防护”迈向“主动免疫”的挑战
设计框架的核心思路
这个框架的设计遵循一个核心逻辑:将数据全生命周期的各个阶段作为“横向”流程维度,将不同的统计分析方法和安全管理活动作为“纵向”能力维度,二者交织形成一个立体化的治理网络。其顶层设计如下图所示,它清晰地展示了如何将各类统计分析工具嵌入到数据生命周期的不同阶段,并通过持续的安全运营形成闭环。
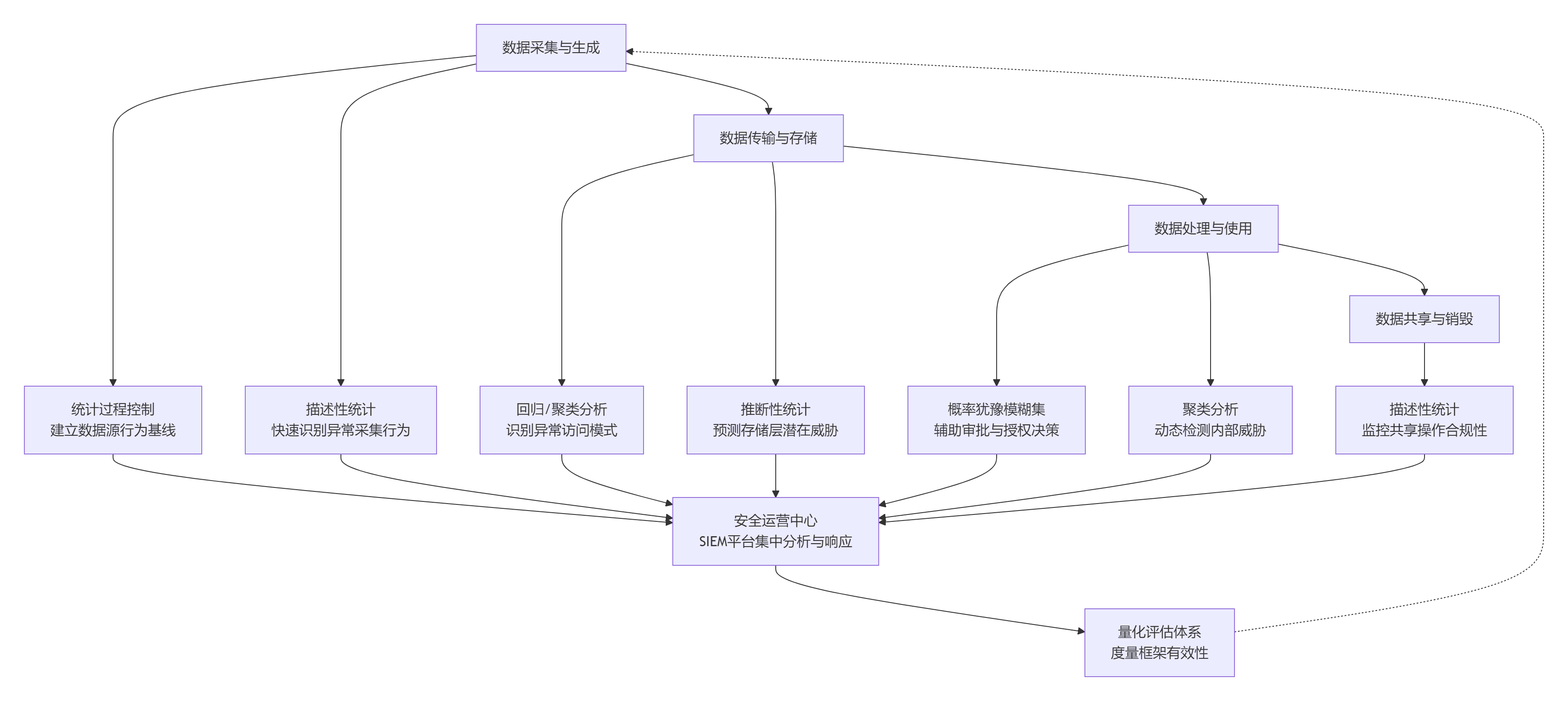
这个框架的落地,需要将图表中的思路转化为具体的技术管理措施。下表概述了在各生命周期阶段如何融合关键技术与管理活动。
|
生命周期阶段 |
核心统计分析技术应用 |
融合的管理活动与产出 |
|---|---|---|
|
采集与生成 |
统计过程控制(SPC):为各数据接入源(如API、日志)建立流量、格式、频次的控制图基线。 |
管理产出:形成《数据源健康度报告》,作为数据供应链管理的依据。 |
|
传输与存储 |
回归/聚类分析:分析访问日志,聚类出正常/异常访问模式,识别潜在内外部威胁。 |
管理产出:动态调整访问控制策略;优化数据加密存储策略。 |
|
处理与使用 |
概率犹豫模糊集:处理多位专家在数据分级、授权审批中的不确定性和分歧,得出科学结论。 |
管理产出:生成《数据定级评审意见》;更新用户行为基线,触发内部审计。 |
|
共享与销毁 |
描述性统计:监控数据共享量、接口调用成功率、敏感数据流出量等,确保合规。 |
管理产出:形成《数据共享合规性看板》,作为数据价值释放的效能证明。 |
框架有效性的量化评估体系
设计好框架后,更需要一套科学的评估体系来证明其价值。建议采用过程指标和结果指标相结合的方式。
|
评估维度 |
核心指标 |
指标解读与评估方法 |
|---|---|---|
|
安全运营效率 |
平均检测时间(MTTD)与平均响应时间(MTTR) |
对比框架实施前后,利用描述性统计计算均值变化,衡量威胁发现和处置速度的提升。 |
|
风险控制能力 |
安全事件下降率 |
通过推断性统计(如假设检验)验证事件下降是否显著;评估预测模型能否精准命中真实威胁。 |
|
合规与成本效益 |
合规审计项覆盖率 |
统计框架措施覆盖法律法规要求的比例;计算通过自动化节省的人力成本,直接体现ROI。 |
实施路径与展望
在具体实施时,可以遵循“统筹规划、分步实施、持续迭代”的策略,参考以下路径推进:
-
第一阶段(基础建设期):优先完成核心数据资产的分类分级,并建立关键数据流的基础描述性统计和监控能力。
-
第二阶段(能力增强期):引入统计过程控制为关键数据源建立基线,并运用聚类/回归分析构建初步的用户行为分析模型。
-
第三阶段(智能运营期):全面应用推断性统计进行威胁预测,并在重大安全决策中引入概率犹豫模糊集等高级模型,实现安全运营的智能化升级。
未来的框架会越来越智能化,大语言模型(LLM) 技术可能会被用于理解自然语言描述的安全策略,并自动生成部分检测规则或代码,从而进一步提升运营效率。
总结与建议
总而言之,构建这样一个融合框架的本质,是将数据安全治理从一门“艺术”转变为一项有数据支撑的“科学”。
-
对于决策者(CISO):这个框架提供了一种用业务语言(如效率提升、成本节约、风险降低)来论证安全投入价值的方式,有助于获取管理层支持。
-
对于执行者(安全团队):它提供了一套清晰的技术路径和效果度量标尺,让安全工作可量化、可追溯、可优化。
2.4.6 数据安全中的运筹学方法
运筹学方法能帮助我们系统性地解决资源有限但目标冲突的复杂决策问题。下面这个表格概括了这些方法的核心应用场景,希望能帮你快速建立整体认知。
|
运筹学方法 |
核心要解决的矛盾 |
典型应用场景 |
|---|---|---|
|
多目标优化 |
平衡安全强度、实施成本与系统效率 |
云环境数据放置策略、数据生命周期安全管控策略制定 |
|
任务调度算法 |
在满足安全约束的前提下,高效完成数据处理任务 |
带安全约束的MapReduce/Spark作业调度、混合云工作流调度 |
|
决策分析 |
将主观的安全风险偏好转化为客观的、可量化的决策依据 |
信息安全风险评估、数据共享与开放策略审批 |
|
资源分配模型 |
将有限的安全资源(计算、存储、带宽)优先用于防护关键资产 |
云数据中心的安全资源动态分配、零信任架构中的访问控制资源调度 |
多目标优化:寻找最佳平衡点
多目标优化的核心是认识到数据安全不是一个可以无限拔高的单一目标,它必须与成本和效率进行权衡。
-
安全等级与成本/性能的权衡:例如,在混合云环境中为工业软件工作流制定数据放置策略时,目标包括数据安全、低传输时延、低执行代价 和数据中心负载均衡。研究人员采用改进的多目标进化算法来寻找一组最优解,并通过熵权法和TOPSIS等方法辅助决策。
-
数据生命周期中的策略平衡:在数据采集、存储、传输、使用、共享和销毁的各个阶段,都需要制定策略。多目标优化可以帮助确定在哪些环节采用何种技术措施,能在满足安全要求的同时,对业务流畅性和IT成本的影响最小。
任务调度算法:嵌入安全约束
在分布式计算框架中,任务调度算法通过引入安全约束,确保数据处理过程既高效又安全。
-
带安全约束的MapReduce/Spark调度:传统的调度器主要考虑数据本地性和计算资源。为保障数据安全,可引入安全约束,例如:检查任务是否有权限访问其处理的数据块;对含敏感数据的任务优先调度到安全等级更高的计算节点;甚至对任务处理的数据进行动态脱敏。有研究为此设计了考虑任务优先级和数据安全性的匹配策略,以及节点故障时的任务重调度机制。
-
混合云工作流调度:对于涉及公有云和私有云的复杂工作流,调度需考虑数据隐私。通常将处理敏感数据的任务调度到私有云,将非敏感计算任务调度到成本更低的公有云,并确保任务间的数据传输安全。
决策分析:量化风险偏好
决策分析提供了一套数学工具,将管理层的风险偏好量化,为安全决策提供客观依据。
-
风险量化与排序:采用模糊层次分析法(FAHP)处理评估中的不确定性。专家无需给出精确数字,而是通过两两比较,用“稍微重要”、“明显重要”等语言项判断风险因素的重要性。FAHP将这些判断转化为权重,并结合风险发生的可能性和造成的损失,计算整体风险值并进行排序。
-
群组决策降低偏差:重要决策不应依赖单一专家。可引入群组决策机制,综合多位专家的独立判断,建立群组偏好模型,从而降低个体认知偏差带来的不确定性,使评估结果更可靠。
资源分配模型:实现安全效能最大化
资源分配模型的核心思想是将好钢用在刀刃上,使有限的安全资源发挥最大价值。
-
基于数据价值的动态分配:借鉴容量调度器支持多队列的思想,可为不同安全等级的数据资产建立独立的资源队列。高安全等级队列分配更多资源用于实时监控和高级威胁防护,低等级队列则采用成本更低的周期性扫描策略。
-
零信任架构中的动态授权:在零信任架构中,每次访问请求都需要进行认证和授权。资源分配模型可根据访问主体、被访问数据、当前环境风险等多个信号实时计算出一个“安全分数”,并动态分配计算资源来执行相应的访问控制策略。
方法选择与实践建议
在实际应用中,如何选择这些方法呢?
-
如果你需要制定战略级的安全政策,例如确定整体的安全投入水平或为不同业务系统设定安全基线,多目标优化和决策分析能提供宏观的、基于数据的决策支持。
-
如果你需要优化具体的技术流程,例如调整大数据平台的任务调度或设计云上数据的流动方案,任务调度算法和资源分配模型更为直接和有效。
-
从简单开始:不必一开始就追求复杂的多目标优化模型。可以从在现有调度策略中加入一两个关键的安全约束开始,或者使用简单的加权评分法对安全风险进行初步排序。
-
数据是基础:所有这些方法的有效性都依赖于高质量的输入数据,如准确的资产清单、合理的数据分类分级、以及可靠的任务性能日志。
总结
运筹学方法为数据安全治理提供了从“凭经验”到“讲科学”的转型路径。通过系统性地应用多目标优化、任务调度、决策分析和资源分配模型,我们能够在深刻理解安全、成本、效率等多维度冲突的基础上,做出更精细、更合理、更具说服力的决策,从而在复杂的数字化环境中构建起高效且稳健的安全防线。
2.5 数据安全中的信息管理与信息系统
2.5.1 数据安全与信息管理及信息系统之间的关系
|
关联维度 |
数据安全角色 |
信息管理与信息系统 (MIS) 角色 |
互动关系 |
|---|---|---|---|
|
目标一致性 |
保障数据的机密性、完整性、可用性 (CIA三要素) |
有效管理信息资源,支持组织决策与运营,实现战略目标 |
数据安全是MIS实现其核心目标的基石和保障。没有安全,信息的价值和管理效能会大打折扣。 |
|
过程融合性 |
贯穿信息生命周期的每个阶段(收集、存储、处理、传输、销毁) |
覆盖信息的收集、传输、加工、储存、更新、拓展和维护全过程 |
安全措施内嵌于管理流程之中。例如,在数据收集环节需验证来源真实性,在存储环节需加密和访问控制。 |
|
系统共生性 |
是信息系统不可或缺的属性或子系统 |
作为一个集成系统,其稳定可靠运行是发挥作用的前提 |
安全并非外挂,而是信息系统与生俱来的内在需求。一个健壮的信息系统架构必然包含安全考量。 |
与信息技术基础的关联
以下几门核心课程为你理解和实现数据安全提供了直接的技术工具和方法论:
-
管理信息系统 (MIS):MIS是研究如何运用信息技术解决管理问题、支持决策的学科。它提供了一个顶层视角,让你理解数据安全需求如何从业务需求和管理目标中衍生。例如,MIS中关于不同管理层级(战略层、战术层、操作层)的信息需求分析,直接决定了数据安全策略的粒度和强度(如高管战略数据需要更严格的保护)。MIS的系统观也强调,安全措施需要与组织的业务流程、组织结构和企业文化相融合,是典型的“三分技术,七分管理”。
-
数据结构与数据库:这是数据在微观和宏观层面的组织方式,是安全措施作用的直接对象。
-
数据结构(如链表、树、图)的高效性与安全性有时需要权衡。例如,某些加密或水印算法可能会改变数据的存储结构或增加开销。
-
数据库技术是数据安全的核心阵地。你需要通过访问控制(如Oracle数据库中的系统权限与对象权限、角色管理)、数据加密(透明加密、字段加密)、备份与恢复等技术,在数据库层实现安全要求。
-
-
计算机网络与应用:网络是数据传输的通道,网络安全是数据安全的关键环节。你需要理解TCP/IP协议族各层的安全漏洞(如IP欺骗、会话劫持)及防御措施(防火墙、入侵检测系统IPS、VPN、TLS/SSL协议)。安全防护需在网络边界(防火墙)、通信链路(加密)和应用层(身份认证)共同部署,形成纵深防御。
-
信息系统分析与设计:这门课教你如何系统化地构建一个信息系统。安全必须贯穿整个系统开发生命周期,而非事后补救。在分析阶段,需进行安全需求分析;在设计阶段,需进行安全架构设计,明确安全组件(如加密模块、审计模块)的位置和接口。业界提倡的“安全左移”(Security Shift-Left),即在开发初期就引入安全考量,与这里的理念不谋而合。
与复杂理论的关联
当系统规模庞大、元素间交互复杂时,以下理论提供了深刻洞察:
-
复杂科学理论与复杂网络理论:现代信息系统(如社交网络、物联网)本身就是复杂网络。复杂网络理论帮助我们从拓扑结构理解安全风险。例如,识别网络中的关键节点(高度中心性的节点,如核心服务器),对其进行重点保护,防止因其失效导致系统性瘫痪。同时,病毒或谣言在网络中的传播模型,与网络蠕虫、僵尸网络的扩散机理高度相似,可用于预测和防御网络攻击。
-
认知理论:数据安全的最终环节是“人”。认知理论揭示了人在处理安全信息时的认知偏差和局限性(如对繁琐密码的厌恶、对钓鱼邮件的误判)。这指导我们:第一,安全机制和界面的设计需符合人因工程学,降低用户犯错概率;第二,安全意识培训需依据人的认知规律来设计,才能事半功倍。许多成功的安全攻击正是利用了人的认知漏洞(如社交工程学攻击)。
总结看待
简单来说,数据安全与信息管理及信息系统是目的与手段、保障与被保障的共生关系。信息技术基础是实现安全的“武器库”,而复杂科学和认知理论则是提升安全认知维度、应对大规模和人性化挑战的“导航图”。
2.5.2 将复杂网络理论中的关键节点保护思想融入安全架构
在信息系统分析与设计中,巧妙地将复杂网络理论中的关键节点保护思想融入安全架构,是一种从全局和系统层面提升整体韧性的高效策略。其核心在于,不再试图平均用力地保护每一个组件,而是精准识别出对系统功能和稳定性具有决定性影响的“枢纽”并优先加固,以此牵一发而动全身。
|
阶段 |
核心目标 |
关键活动/方法 |
|---|---|---|
|
一、识别与分析 |
精准定位系统中的关键节点与脆弱点 |
节点重要性评估:基于节点度、介数、紧密度等中心性指标识别关键节点。 依赖关系分析:明确系统内(应用、服务、数据)及跨系统(如电力-通信网)的依赖路径。 攻击影响模拟:分析关键节点失效可能引发的级联故障范围与业务影响。 |
|
二、差异化防护设计 |
针对不同关键节点,部署多层次、自适应的防护措施 |
核心节点强化:对最重要的节点(如认证中心、核心数据库)采用最高等级保护(如多因素认证、深度防御、实时监控)。 冗余与容灾:为核心节点和关键链路设计冗余备份(如负载均衡、异地多活)。动态访问控制:结合用户角色、设备状态、环境风险实施动态授权,践行最小权限原则。 |
|
三、持续监控与自适应 |
建立持续的风险感知与响应能力,实现动态免疫 |
纵深防御体系:构建覆盖网络、主机、应用、数据各层面的协同防护与监控体系。 智能威胁检测:利用大数据分析、AI及入侵检测系统,实时监测异常流量和行为。 应急响应与自愈:建立包含检测(Detect)、响应(React)、恢复(Restore)环节的应急响应流程,并尽可能实现故障自动隔离与服务自愈。 |
关键思路与场景建议
在实际应用中,把握以下思路能让你更好地运用这一策略:
-
资源优化意识:关键节点保护思想的精髓在于承认资源有限性。它指导我们将有限的安全预算、人力和技术资源,优先投入到能产生最大防护效益的关键区域,实现安全投入的效用最大化。
-
从“静态边界”到“动态免疫”:传统安全思维依赖于清晰的边界,而复杂网络思维强调在开放、动态、无清晰边界的系统环境中,通过重点保护关键枢纽、监控关键路径来抑制威胁扩散,使系统具备类似免疫系统的动态防御和自愈能力。这符合现代信息系统,特别是云原生和微服务架构的特点。
实际应用场景举例
-
电子商务平台:在系统分析中,用户认证服务、支付交易链路、核心商品数据库通常是最关键节点。设计中,应为认证服务部署集群并实施限流降级;确保支付链路高度冗余并加密通信;对核心数据库进行加密存储、严格访问控制和完善的备份恢复策略。
-
企业内网与政务平台:对于此类系统,核心业务数据本身是需要保护的关键资产。可部署数据防泄露(DLP)系统,明确数据所有权和管理权分解,监控敏感数据的流向,防止内部泄密。同时,身份认证服务器和网络出口也是需要重点防护的关键节点。
总结与进阶
将复杂网络的关键节点保护思想应用于信息系统安全架构设计,本质上是从“网络拓扑”和“系统功能”的视角重新审视和量化系统脆弱性,从而实现从被动防护到主动增强、从孤立设防到协同联防的转变。
这种思路也引领了零信任(Zero Trust) 安全架构的发展,其核心理念——“从不信任,始终验证”——就要求精准识别和保护每一个访问请求路径上的关键节点和链路。
2.5.3 数据安全管理体系中的零信任安全架构
在数据安全管理体系中,零信任安全架构提供了一种跳出传统“内网安全,外网危险”思维定式的主动防御范式。下面的表格能帮你快速抓住其核心脉络:
|
核心维度 |
传统边界安全模型 |
零信任安全架构 |
范式转变 |
|---|---|---|---|
|
信任基础 |
基于网络位置(如内网默认可信) |
基于身份(用户、设备、应用身份),网络位置不再等于信任 |
从“网络中心化”到“身份中心化” |
|
安全原则 |
静态的“一次认证,长期信任” |
动态的“显式验证,最小权限”,持续评估信任 |
从“信任但验证”到“从不信任,始终验证” |
|
防护思路 |
构筑坚固的“城墙”进行边界防护 |
缩小攻击面,假设边界已失效,聚焦数据资源保护 |
从“构筑城墙”到“深度防御与隐身” |
|
技术焦点 |
防火墙、入侵检测系统(IDS)等边界设备 |
SDP(软件定义边界)、IAM(身份与访问管理)、MSG(微隔离) 等技术组合 |
从依赖硬件边界到软件定义、身份驱动的细粒度控制 |
零信任的核心理念
零信任的核心理念可概括为三条基本原则:
-
显式验证:不论访问请求来自何处,访问何种资源,都必须经过严格的身份认证和授权,没有任何隐含的信任 。
-
最小权限访问:授权策略应遵循最小权限原则,用户只能访问其完成工作所必需的资源,避免过度授权带来的横向移动风险 。
-
假定 breach:假设系统已经存在威胁或已经被攻破,因此需要通过动态控制、分段等方式,尽力防止 breach 后的横向移动和数据泄露 。
零信任的思维模型与实施框架
将零信任理念落地,通常需要一个结构化的思维模型作为指导。“零信任五步法” 提供了一个清晰的实践路径 :
-
定义保护面:首先识别需要保护的核心数据资产和关键业务系统,即划定重点防护范围,避免盲目扩大防御焦点 。
-
映射事务流:清晰描绘访问这些保护面的正常合法流量是怎样的,包括用户、设备、应用之间的访问关系和数据流向,为制定策略奠定基础 。
-
构建安全网关:在网络关键节点部署零信任网关(或代理),作为策略执行点,对所有访问请求进行拦截和检查,实现资源“隐身” 。
-
制定访问策略:基于身份、设备状态、环境风险等多维度信息,构建动态的、细粒度的访问控制策略 。
-
监控与动态授权:持续监控访问会话中的用户行为、设备状态等,根据风险变化动态调整访问权限,实现自适应安全 。
关键技术与组件支撑
零信任架构的实现依赖于几项关键技术的协同:
-
SDP:SDP通过控制平面与数据平面分离,将业务应用的后端服务“隐藏”起来,对外只暴露网关。访问者必须先经过SDP控制器的严格认证和授权,才能获得临时通行证,连接到后台应用,从而显著减少攻击面 。
-
增强的IAM:身份是零信任的基石。增强的IAM不仅包括多因子认证等强认证手段,更强调对身份的生命周期管理和基于属性的动态授权,确保正确的身份在合适的条件下访问特定资源 。
-
微隔离:在数据中心或云环境内部,根据业务逻辑将网络划分为更小、更细粒度的安全段,并为每个段设置精细的访问控制策略。即使攻击者突破外围,微隔离也能有效阻止其横向移动 。
实施路径与挑战
零信任的实施是一个战略性的演进过程,而非一蹴而就的项目。它通常被视为“一把手工程”,需要高层的理解和支持,因为其涉及对现有安全架构、管理流程乃至组织文化的调整 。
成功的实施路径往往是分阶段、循序渐进的:
-
起点:可从特定场景入手,如优先保护最关键的业务系统(如财务系统、核心数据库),或解决最迫切的需求(如实现安全远程办公)。
-
扩展:在取得成效后,逐步将零信任架构推广到更多应用和数据,持续构建和完善企业整体的免疫能力。
总结
零信任安全架构作为一种现代的、以数据和身份为中心的安全范式,通过持续验证和最小权限原则,为组织在无边界趋势下构建动态、自适应的数据安全防御能力提供了清晰的道路 。
2.5.4零信任其不同架构变体的根本差异
下面这个表格梳理了三种架构在设计焦点和技术实现上的核心差异。
|
架构类型 |
核心设计焦点与信任建立方式 |
关键技术实现差异 |
|---|---|---|
|
传统零信任架构 |
以身份为中心,动态验证访问请求。关注“谁”在“什么环境下”访问“何种资源”,通过持续评估上下文动态授予最小权限。 |
依赖软件定义边界(SDP)、多因子认证(MFA)、微隔离等技术,构建逻辑上的安全边界。 |
|
基于数据安全的零信任架构 |
以数据本身为中心,保护贯穿全生命周期。信任基于数据标签、分类级别以及对数据操作的持续监控。安全策略紧密围绕数据展开。 |
深度集成数据安全策略,如动态数据标记、加密、脱敏、权限控制,并关注数据流动中的风险。 |
|
基于保密法的零信任架构 |
以合规性为中心,信任源于依法依规。严格遵循《数据安全法》、《个人信息保护法》等,访问授权必须符合法律规定的场景和最小必要原则。 |
技术实现强依赖于法规解读,需将法律要求转化为可执行的技术策略,如数据出境控制、特定人员背景审查、操作行为合规性审计。 |
根本性差异的科学基础
上述架构差异的背后,是不同基础科学理论支撑的体现:
-
数学与密码学:这是通用底层基石。无论是基于数学难题(如大整数分解)的非对称加密(RSA)、用于完整性校验的散列函数(SHA系列),还是支持“可用不可见”的同态加密和隐私计算,它们为所有架构中的身份认证、传输加密、数据保密提供了最核心的工具箱。差异在于,基于数据安全的架构会更激进地应用新型密码学(如属性基加密ABE)实现更精细的访问控制。
-
物理与硬件安全:这是高阶信任的根。传统架构可能仅依赖软件证书。而高安全等级架构必须引入物理不可克隆函数(PUF)、硬件安全模块(HSM)等,将身份与不可复制的物理特征绑定,从根本上防御伪造。芯片实现中,如何设计抗旁道攻击(如功耗分析)的电路是核心难点。
-
认知科学与行为分析:这是动态评估的关键。通过监控用户的操作习惯、节奏、时间等行为序列,利用复杂系统理论(如隐马尔可夫模型)建立正常行为基线。任何显著偏离都可能触发重新认证。这为所有架构的“持续评估”提供了内在依据。
-
复杂系统与控制理论:这是架构运行的保证。零信任系统本身是一个复杂自适应系统。需运用控制论实现策略执行的反馈闭环,并利用博弈论分析攻防双方的策略互动,从而优化防御策略。
实现流程、难点与芯片级考量
理解了科学基础,我们来看如何将它们实现为一个系统,以及在不同层级上的挑战。
实现流程的关键阶段
一个稳健的零信任架构落地,通常遵循一个环环相扣的流程,其核心阶段可概括如下:
-
资产与风险识别:全面梳理数据资产、业务流和用户角色,并进行风险评估。
-
策略制定与模型设计:将业务和法律需求转化为具体的技术策略,如定义基于属性(用户角色、数据敏感度、环境风险)的访问控制模型。
-
技术组件选型与集成:选择或开发策略引擎、策略执行点等核心组件,并整合身份管理、加密服务等支撑系统。
-
策略部署与系统调优:采用分阶段策略,先在非核心业务试点,验证策略有效性后逐步推广,并持续优化性能。
-
持续监控与演进:建立监控体系,审计所有访问行为,基于发现的新威胁动态调整策略。
通用技术难点
-
性能与用户体验的平衡:每次访问都伴随多次验证和策略检查,会引入延迟。如何在安全与效率间取得平衡是巨大挑战。
-
策略的完备性与一致性:设计既足够精细又能覆盖所有场景,且不自相矛盾的策略极为复杂。
-
系统的复杂性与可维护性:引入众多新组件,使得系统复杂度飙升,对运维团队挑战巨大。
-
遗留系统的兼容与改造:许多老旧系统可能无法直接适配零信任的细粒度控制,改造或封装成本很高。
芯片/硬件实现 vs. 软件实现
当安全要求达到极致,人们会寻求硬件层面的保障。
|
实现方式 |
核心原理 |
优势 |
核心难点与挑战 |
|---|---|---|---|
|
软件实现 |
通过操作系统或应用程序层面的代码执行加密、策略决策等所有安全功能。 |
灵活性强、成本低、易于升级迭代。 |
运行环境不可靠:软件易被恶意代码攻击或调试。密钥存储不安全:存在泄露风险。性能开销大:复杂运算对主CPU造成负担。 |
|
硬件/芯片实现 |
设计专用集成电路或硬件安全模块,将核心安全功能(如密码运算、密钥管理)在物理层面固化。 |
高性能:专芯专用,效率极高。高安全性:密钥在硬件内生成和存储,难以提取。物理防篡改:具备主动防护设计。 |
设计复杂、成本高昂:流片费用极高。升级困难:一旦制造完成,逻辑难以修改。供应链风险:依赖可信的芯片制造链条。 |
2.5.5 同态加密(Homomorphic Encryption, HE)和属性基加密
同态加密(Homomorphic Encryption, HE)和属性基加密(Attribute-Based Encryption, ABE)是实现零信任架构“永不信任,始终验证”核心理念的关键技术。它们分别从数据计算安全和数据访问安全两个维度,共同构筑起“数据不动代码动”或“数据可用不可见”的深层防御体系 。
|
特性 |
同态加密 (HE) |
属性基加密 (ABE) |
|---|---|---|
|
核心安全贡献 |
计算过程保密:允许对密文进行运算,结果解密后与明文运算结果一致,实现“数据可用不可见”。 |
访问控制精细:基于用户属性(如部门、角色)动态生成解密密钥,实现“一次加密,按需解密”。 |
|
在零信任中的角色 |
保护使用中数据的安全,确保即使在不可信的计算环境(如公有云)中处理数据,原始信息也不会暴露。 |
动态实施最小权限原则,确保只有满足特定策略(如“属于项目组且设备健康”)的用户才能解密数据。 |
|
典型应用场景 |
云端加密数据分析、隐私保护的机器学习、跨机构联合统计。 |
安全的企业文件共享、云存储的细粒度访问控制、跨域数据协同。 |
|
关键技术挑战 |
计算开销巨大、密文膨胀率高。 |
用户属性撤销复杂、计算资源消耗较大。 |
同态加密的实际应用与优化
同态加密让第三方(如云服务商)能够在无法查看数据内容的情况下,应要求对加密数据执行特定计算。这为高度敏感数据的云端利用开辟了道路。
-
军事联合威胁分析:例如,在北约的联合训练项目中,各成员国将加密后的军事数据上传至中央服务器,共同训练高精度的威胁评估模型。整个过程无需任何一方共享原始数据,有效保护了各国的数据主权和机密 。
-
医疗健康数据分析:多家医院可在不交换原始患者数据的前提下,联合训练疾病预测模型。每家医院使用同态加密技术本地加密数据后上传,云端在密文状态下进行模型参数的聚合与更新,最终得到一个有效的全局模型,同时严格保护了患者隐私 。
为应对HE固有的性能瓶颈,业界主要从软件算法优化和硬件加速两方面入手:
-
软件层算法优化:采用部分同态加密(PHE,仅支持加法或乘法一种运算)或层次型同态加密(LHE,支持有限次运算)以平衡安全与性能。例如,微软的SEAL库就提供了高效的PHE/LHE实现 。
-
硬件层加速计算:利用GPU的并行计算能力大幅提升核心运算(如多项式乘法)效率。通过CUDA编程模型优化算法(如数论变换NTT),可将计算速度提升数十倍 。
属性基加密的实际应用与优化
ABE将访问控制策略嵌入密文,解密能力与用户持有的属性证书绑定,完美契合零信任的动态授权需求。
-
企业安全数据共享:在云存储场景中,一份包含敏感财务数据的文件可以被加密,并设定策略为
“财务部 AND 总监级别”。系统自动为符合该属性的员工生成解密密钥,无需为每人单独加密文件,也无需担心员工职位变动后权限遗留问题 。 -
跨域数据协同:在基于区块链的数据共享方案中,数据所有者利用可追踪的CP-ABE将数据加密后存储在IPFS等分布式存储上,访问策略和密文哈希记录于区块链。数据使用者需提供满足策略的属性证明,通过智能合约验证后获得访问权,实现了去中心化的可信数据共享 。
ABE的优化聚焦于减轻计算负担和高效管理权限:
-
计算外包:将复杂的加密和解密计算任务委托给可信的代理服务器执行,资源受限的终端设备(如手机)只负责最终结果的轻量级处理 。
-
分层密钥管理与延迟重加密:采用层级结构管理密钥,当需要撤销某个用户的某一属性时,系统无需立即重新加密所有相关数据,可延迟到下次访问或特定时间窗口批量处理,显著降低系统开销 。
总结与展望
同态加密和属性基加密从不同层面增强了零信任架构的数据安全。未来,HE与ABE的融合是一个重要趋势,例如先使用ABE控制谁能对加密数据发起计算请求,再使用HE在云端安全执行计算。同时,抗量子密码算法的集成也将为这些基于数学难题的加密技术应对未来挑战提供保障 。
2.5.5硬件安全模块(HSM)和物理不可克隆函数(PUF)
硬件安全模块(HSM)和物理不可克隆函数(PUF)是零信任架构中实现“永不信任,始终验证”理念的硬件基石。下面这个表格能帮你快速把握它们的核心特性和协同关系。
|
特性维度 |
硬件安全模块 (HSM) |
物理不可克隆函数 (PUF) |
|---|---|---|
|
核心角色 |
高性能、高保障的硬件信任根,安全的密码处理器 |
轻量级、低成本的硬件身份标识,独特的“设备指纹” |
|
信任基础 |
物理防篡改设计、高标准安全认证(如FIPS 140-3) |
半导体制造过程中固有的、不可控的微观物理差异 |
|
密钥处理方式 |
密钥在硬件内部生成、存储和使用,永不离开安全边界 |
密钥从不存储,仅在需要时由PUF电路根据物理特征动态生成,用完即焚 |
|
典型应用场景 |
PKI/CA系统、金融交易签名、云服务密钥管理 |
IoT设备身份认证、芯片级安全启动、防设备克隆 |
HSM:坚固的硬件信任根
HSM的核心原理是创建一个物理上安全、防篡改的隔离环境,所有敏感的密码操作和密钥材料都被禁锢在这个“堡垒”内。
-
实现原理:HSM自带专用的密码协处理器,能高速执行RSA、ECC、AES等算法。当应用程序(如Web服务器)需要进行TLS握手时,它并不直接接触私钥,而是将待签名的数据发送给HSM。HSM在内部完成签名运算后,仅将结果返回给应用程序,确保了私钥的绝对安全。此外,HSM具备严格的角色访问控制(如安全管理员、密码员角色分开)和完整的操作审计日志,满足高级别合规要求。
-
抗攻击机制:
-
物理防篡改:HSM具备多层物理防护。一旦检测到外壳被打开、钻孔、电压或温度异常,会立即触发零化机制,自动清除所有密钥。
-
逻辑隔离:通过安全的API(如PKCS#11)与主机交互,密钥材料无法通过软件指令读取或导出。有些HSM还提供类似CodeSafe的安全区,允许用户将自定义的安全敏感代码在HSM内部执行,即使主机被入侵,代码和密钥也受到保护。
-
PUF:天生的设备身份证
PUF的智慧在于“以缺陷为特征”,它不存储密钥,而是利用每颗芯片在制造过程中必然存在的、不可复制的微观差异(如晶体管阈值电压的细微差别)作为生成密钥的源头。
-
实现原理:以常见的SRAM PUF为例,SRAM内存单元在上电瞬间的初始状态(0或1)是由其内部晶体管的随机细微差异决定的。这种独特的0/1分布模式就构成了设备的“物理指纹”。系统通过纠错码技术从原始指纹中生成稳定且唯一的密码学密钥。由于密钥仅在需要时动态重构,不非易失性存储,从根本上解决了密钥存储的隐患。新兴的忆阻器PUF等方案,则利用纳米级器件的电阻变化特性,有望提供更多的挑战-响应对和更强的抗建模攻击能力。
-
抗攻击机制:
-
物理不可克隆性:由于依赖纳米级的制造随机性,即使同一批次的芯片,其PUF响应也截然不同,无法通过物理复制来伪造。
-
环境敏感性:PUF响应会随温度、电压变化而轻微波动,但这通过纠错码克服。然而,这种敏感性本身也是一种防御,可检测到异常环境条件。此外,通过在挑战中混入随机数,可以有效防止重放攻击。
-
协同应用
在零信任架构中,HSM和PUF可以协同工作,构建更深层的信任链。例如,在一个物联网场景中:
-
每个终端设备通过其PUF生成唯一的设备身份凭证,作为本地信任根。
-
该设备接入网络后,需要与后台的认证服务建立安全连接。
-
认证服务所在的服务器集群则集成HSM,用于保护其TLS证书的私钥,并对设备进行高强度的身份验证。
这种组合形成了从边缘设备到云数据中心的、贯穿始终的硬件信任基础。
2.5.6 硬件安全模块(HSM)和物理不可克隆函数(PUF)方案的选择场景
在选择硬件安全模块(HSM)和物理不可克隆函数(PUF)方案时,关键是要让技术的防护能力与业务场景的实际风险相匹配。
|
安全等级 |
典型场景举例 |
HSM 选型考量 |
PUF 整合策略 |
典型方案举例 |
|---|---|---|---|---|
|
基础级 |
消费级物联网设备、智能家居 |
优先考虑软件模拟的HSM或轻量级安全芯片,重点评估成本、功耗和集成便捷性。 |
采用软件形态的PUF技术(如SoftPUF),为大量低成本设备提供基础防克隆和设备身份唯一性保障。 |
集成内置轻量级安全模块和PUF技术的MCU。 |
|
增强级 |
网络设备、企业云平台、视频监控 |
选择通过FIPS 140-2 Level 2/3认证的PCIe或网络HSM。关注标准化API支持和高可用性。 |
优先选择已内置SRAM PUF等硬件PUF技术的芯片,增强设备根密钥的安全性。 |
泰雷兹Luna Network HSM、Entrust nShield系列。 |
|
关键级 |
支付系统、数字证书、自动驾驶 |
严格选用通过FIPS 140-3 Level 3或Common Criteria EAL4+等高等级认证的产品。需具备防篡改、抗旁道攻击等高级物理防护。 |
采用满足EVITA-Full等行业严苛标准的高度集成方案,将PUF作为安全芯片的硬件信任根。 |
符合EVITA-Full标准的车规级HSM方案、IBM Crypto Express系列。 |
核心评估维度
在实际评估时,我们可以从以下几个关键维度对备选方案进行深入考察:
-
合规性与认证:这是硬性门槛。首先确认方案是否通过了行业要求的认证,例如:
-
国际/通用标准:FIPS 140-2/3(美国)、Common Criteria(通用准则)。
-
行业特定标准:在汽车领域,需符合EVITA标准;在中国市场,需关注是否支持国密算法并符合相关标准。
-
云安全:若部署在云端,方案需支持BYOK等功能,并符合相关云安全标准。
-
-
技术特性与性能
-
物理安全:对于HSM,高安全等级要求具备坚实的防篡改外壳和侧信道攻击防护能力。 对于PUF,需评估其输出的稳定性和唯一性。
-
性能与扩展:评估方案的加密运算性能(如TPS)能否满足业务峰值需求,以及是否支持集群部署以方便未来扩展。
-
功能完备性:检查所需功能(如特定算法、数字签名、密钥管理接口等)是否得到良好支持。
-
-
成本与运维
-
总拥有成本:综合考虑初始硬件/许可费用、后期维护、升级及电费成本。云HSM采用订阅制,可能降低前期投入。
-
可管理性:了解方案是否提供集中管理工具、详细的审计日志和告警功能,以降低运维复杂度。
-
供应链与生态:确认供应商的可靠性和技术支持能力,以及产品与现有系统、开发工具的兼容性。
-
实施流程建议
一个结构化的选型和实施流程能有效保障项目成功:
-
需求分析:明确数据的敏感级别、业务流量规模、合规性要求、可用性目标和预算范围。
-
初选方案:基于需求,筛选出2-3个符合要求的候选方案。
-
概念验证:这是最关键的一步。搭建测试环境,重点验证:
-
性能表现:在预期负载下,HSM的延迟和吞吐量是否达标。
-
集成难度:使用提供的SDK和API进行联调,评估开发工作量。
-
管理体验:实际操作密钥管理、备份恢复等日常运维任务。
-
PUF稳定性:在特定温度、电压变化下,PUF密钥重建的成功率。
-
-
安全评审:邀请内部或第三方安全专家对PoC结果和方案设计进行评审。
-
试点部署:选择非核心业务进行小范围试点,全面检验方案的稳定性和可靠性。
-
全面推广与持续监控:逐步推广到全业务,并建立监控体系,持续观察系统运行状态。
核心选型思路
面对HSM和PUF的选型,核心思路是让安全投入与业务风险相匹配,实现安全与效率的平衡。对于绝大多数场景,选择一款经过市场广泛验证、具备相应合规性认证的成熟商用HSM是稳妥且高效的方案。PUF技术则特别适合为海量物联网设备提供轻量级、低成本的内在身份标识,或在芯片层面为高安全等级应用构建强大的硬件信任根。
三、前沿应用:大模型的数据安全
3.1 大模型的数据安全
3.1.1 大模型的数据安全
大模型的数据安全是一个涉及数据、模型机理、业务场景乃至人类认知的复杂系统性问题。为了清晰把握其全貌,以下表格概括了四大核心风险维度及其关键机理。
|
风险维度 |
核心机理 |
关键表现与影响 |
|---|---|---|
|
数据层面风险 |
训练数据污染、偏见注入;模型对敏感信息的记忆与反演 |
输出内容存在偏见或错误;隐私、商业秘密等敏感信息被提取泄露 |
|
模型机理风险 |
“黑箱”决策不可解释;统计拟合而非因果理解 |
决策过程不透明,结果难以追溯和信任;易产生“幻觉”,输出捏造内容 |
|
业务应用风险 |
智能体越权操作;供应链第三方漏洞引入 |
与外部系统交互时执行未授权操作,导致数据泄露或服务中断;开源框架、预训练模型等引入安全后门 |
|
认知与评估风险 |
算法价值观对齐偏差;自动化评估与人类感知的鸿沟 |
评估标准可能扼杀技术多样性;传统评估指标与真实安全感知存在偏差 |
数据与模型的内在脆弱性
大模型的安全问题根植于其训练和运行的基本逻辑之中。
-
数据源的污染与偏见:大模型的训练数据广泛来源于互联网,其中不可避免会混杂着偏见、虚假乃至恶意注入的信息。这些缺陷会在训练过程中被模型学习并固化,导致其输出内容可能损害社会公正,或包含错误信息。同时,数据中若包含未脱敏的敏感信息,模型可能通过“记忆”机制在特定诱导下将其还原,造成严重的隐私或商业秘密泄露 。
-
模型机理的固有缺陷:大模型基于深度神经网络,其决策过程如同一个“黑箱”,缺乏透明度和可解释性,这为追溯决策责任和识别潜在漏洞带来了巨大挑战 。更重要的是,其训练本质是学习文本中的统计规律以预测下一个词,而非真正理解语义或事实。这导致模型可能生成看似流畅合理但完全错误的“幻觉”内容,严重影响其可靠性 。
业务应用放大的安全挑战
当大模型嵌入真实的业务流,其安全风险会变得更为复杂和具体。
-
智能体行为失控:当大模型进化为具备感知和行动能力的智能体(Agent)时,风险超越了内容生成范畴。它能够调用外部工具(如数据库、API),可能引发越权执行、数据泄露乃至对物理设备的控制等系统性风险。攻击者可利用“提示词注入”等手法,诱导模型执行未经授权的多步操作,造成严重后果 。
-
供应链与开源风险:大模型技术栈深度依赖开源框架、预训练模型和第三方API。这些组件可能被植入难以察觉的“后门”,构成供应链攻击的盲区。一旦关键基础设施采用存在漏洞的模型,将威胁整个生态的安全 。
认知与评估的深层次困境
在管理和评估层面,同样存在需要克服的难题。
-
评估范式的局限性:目前常用的“以模型评估模型”的自动化方法,其结果很大程度上只是衡量被测模型与作为“裁判”的强大模型在价值观和风格上的相似度,这可能固化为单一的优化目标,扼杀技术路线的多样性。而传统的人工评估(如红队测试)虽能发现特定风险,但效率低、难以规模化,无法覆盖开放环境中不断演化的新型风险 。
-
“小数据”的核心价值与风险集中:在AI驱动下,企业将海量原始数据提炼为高价值的“精华小数据”,这些数据是企业核心竞争力的集中体现。一旦这些“小数据”被窃取或篡改,将给企业带来“一失万无”的毁灭性打击。同时,数据处理权限较高的特殊岗位(如数据管理员、算法工程师)成为内部威胁的焦点,其权限如若被冒用,极易导致核心数据泄露 。
构建综合治理框架
应对大模型的数据安全挑战,需采取多层次、全生命周期的系统化治理策略。
-
强化技术防御:在技术层面,需构建纵深防御体系。例如,采用差分隐私技术在训练数据中添加可控噪声,利用联邦学习实现数据“可用不可见”,并通过同态加密等技术保障参数交换安全,从源头强化数据和隐私保护 。同时,需提升模型的鲁棒性,通过对抗训练等方式防御恶意攻击,并开发解释性工具增强模型透明度 。
-
优化管理流程:在管理上,应建立覆盖模型训练、部署、运维到退役的全生命周期风险管理闭环 。明确开发者、运维者和使用者的“三位一体”责任机制 。同时,严格落实数据分类分级管理制度,并对跨境数据流动实施严格审查 。
-
创新治理范式:在治理层面,应推动从被动防御向主动免疫的范式转变,将安全防护前置到技术研发和业务设计环节 。可探索“监管沙盒”等敏捷治理模式,在安全可控的环境中鼓励创新 。同时,构建多元共治机制,发挥政府、行业组织、企业和社会公众的各自优势,形成协同防御生态 。
3.1.2 大模型数据安全的可知性、不可知性、上确界、下确界、积面积和方法
数据安全的可知性与不可知性
在大模型数据安全领域,“可知性”指的是那些能够通过技术手段和管理措施被识别、度量、监控和控制的已知风险。例如,通过数据分类分级、加密技术、访问控制、安全审计等手段,我们可以有效管理数据传输、存储环节的许多风险,确保数据在生命周期内的安全性。像《生成式人工智能服务管理暂行办法》等法规的出台,也明确了数据收集、训练数据质量等方面的合规性要求,使得这部分风险变得相对“可知”和可控。
而“不可知性”则主要体现在大模型自身因“黑箱”特性产生的复杂性、以及外部新型攻击的不可预测性。大模型的决策过程往往缺乏透明度和可解释性,其内部可能记忆训练数据中的敏感信息,但这些信息何时、以何种方式被推导出来(即“成员推断攻击”),往往是难以完全预测和监控的。同时,模型可能生成虚假或无意义的信息(“幻觉”问题),或面临难以预见的“对抗性攻击”,这些都属于安全风险中“不可知”的范畴。此外,大模型技术栈对开源框架和第三方API的深度依赖,也引入了供应链攻击等难以完全掌控的未知风险。
安全能力的上下确界
“上确界”可以理解为在当前技术条件下,通过最完善的安全措施所能达到的理论安全上限。例如,通过部署基于硬件加密的可信执行环境(TEE)进行安全沙箱隔离,构建覆盖模型训练、部署、运维和退役的全生命周期闭环管控流程,或者采用“零信任”架构实现精细化的权限管控,这些努力方向都旨在不断提升安全水平的理论上限。一些技术方案,如隐私增强技术(如联邦学习、差分隐私)以及在数据向量化过程中叠加不可逆的噪声扰动,也旨在追求特定场景下数据安全和隐私保护的理论极限。
“下确界”则可视为必须守住的安全底线,是应用大模型不可逾越的安全红线。法律法规(如《数据安全法》、《个人信息保护法》)中关于数据分类分级、重要数据出境、个人信息保护等的强制性规定,以及《生成式人工智能服务管理暂行办法》中明确的不予豁免的禁止性行为,共同构成了大模型数据安全的下确界。例如,《政务领域人工智能大模型部署应用指引》中明确要求“防止国家秘密、工作秘密和敏感信息等输入非涉密人工智能大模型”,这就是一条明确的安全底线。
风险面积的度量与“积分和方法”
在数据安全领域可以形象地理解为对系统整体攻击面或风险暴露面的量化评估。其核心思想类似于一个多维空间中的“体积分”,即通过识别和度量所有可能的数据交互点(输入/输出)、API接口、模型参数访问通道、内部数据处理流等潜在的风险点,并评估每个风险点的脆弱性和被利用后的影响程度,从而对系统整体风险进行累积计算和综合评估。
在实践中,这体现为攻击面管理和动态风险评估。例如,奇安信提出的“红域”概念,通过构建专属安全空间并进行多维度边界隔离,旨在控制和缩小大模型应用的“风险面积”。同时,通过构建智能威胁感知与响应平台,实时监测针对大模型的攻击行为(如提示词注入、模型越狱),并对安全风险威胁信息进行共享,这类似于对风险面积的动态扫描和实时积分计算,以实现安全运营的闭环。
四者关系与治理启示
这四个概念共同描绘了大模型数据安全的治理轮廓:在“可知”的范围内不断优化措施,逼近“上确界”;对“不可知”的风险保持敬畏和警惕,通过持续监测和研究来降低其不确定性;同时,坚决守住“下确界”这一法律和安全的底线。而“积面积和方法”则提供了一种系统性的思路和工具,通过不断度量和优化,最终目标是将整个系统的“风险体积”最小化。
3.2 跨模态语义理解
跨模态语义理解技术通过综合分析文本、图像、音频、视频等多种媒介之间的深层语义关联,能够检测出孤立分析单个模态时难以发现的复杂违规内容。下面这个表格通过几个典型场景,帮你快速了解其工作原理和优势。
|
违规场景类型 |
传统方法的局限 |
跨模态语义理解技术的应用 |
|---|---|---|
|
图文组合违规 |
单独看图片(普通瓶子)或文案(“抗癌神药”)可能均不违规,无法识别二者间的语义矛盾。 |
模型能理解图片内容与文案宣称之间的不一致性,结合人物表情、场景等上下文,识别出虚假宣传。 |
|
隐含违规关联 |
关键词匹配对“亡八蛋”、“某水果”等谐音、隐喻指代束手无策。 |
基于语义知识图谱,建立“亡八”与“王八”、“某水果”与敏感事件间的同义/隐喻关系,从而识别隐含违规。 |
|
跨模态分散风险 |
敏感信息分散在不同模态(如文本提及“看这个标志”,图片中包含敏感标识),单独分析风险低。 |
通过实体关联建模,将图片中识别出的敏感标识与文本中的指代词进行关联绑定,判定为整体违规。 |
|
AIGC生成内容风险 |
单模态检测难以发现经过篡改的、语义不一致的多媒体内容。 |
采用类似HAMMER的模型,通过多模态层次化篡改推理,定位图像篡改区域和文本篡改单词,检测跨模态语义不一致性。 |
深入理解技术原理
以上案例的实现,依赖于以下几项核心技术进步,它们使得机器能够像人一样“整体地”理解内容:
-
图文联合理解与推理:以Qwen3-VL-8B这类多模态大模型为例,其底层架构(如改进的ViT视觉编码器和Transformer解码器)通过交叉注意力机制,让模型在分析文本时能“回头看”图像的相关区域,从而实现真正的联合理解,而非简单的信息拼接。这种能力使其能够进行上下文推理,判断一个姿态在特定文化背景或场景下的真实含义,从而有效减少误判。
-
语义知识图谱关联:这类系统通过构建包含海量实体(如敏感词、人物、事件)及其复杂关系(如同义、隐喻、组合)的语义知识图谱,形成一个庞大的“关系网”。当处理内容时,系统不再是机械匹配关键词,而是进行语义推理,例如,根据图谱中“水果A”与“某敏感事件B”存在的“隐喻”关系,当检测到文本中出现“水果A真甜”且上下文相关时,就能识别出其中可能存在的隐含违规。
-
风险传播与结构化分析:更前沿的专利技术(如基于语义风险图扩散感知的方法)将不同的信息片段(文本片段、图像区域等)构建成一张语义风险图,节点是信息片段,边代表它们之间的语义、时序等关联。然后利用类似热扩散的机制在图中模拟风险的传播。即使每个片段单独看风险不高,但若它们通过图结构紧密关联并形成特定模式,整个内容也可能被判定为高风险。这种方法特别擅长识别“组合敏感”场景。
核心价值与未来趋势
跨模态语义理解技术的核心价值在于,它将内容安全检测从基于表面特征匹配的“手电筒”升级为基于深层语义关联的“探照灯”。这对于应对日益复杂和隐蔽的违规内容至关重要。
在实际应用中,这些技术往往被整合到完整的风控解决方案里。例如,数美科技的AIGC内容风控方案就融合了多模态审核能力,通过对比学习等方法对齐不同模态的语义特征,以精准识别画面中的对象及其隐含意图。
3.3 跨模态语义理解在数据安全中的作用
跨模态语义理解技术通过深度整合文本、图像、音频、视频等不同模态的信息,让机器能够像人类一样“整体地”理解复杂内容,正在数据安全领域发挥着革命性的作用。
核心应用场景
|
应用场景 |
传统方法的局限 |
跨模态语义理解技术的解决方案与价值 |
|---|---|---|
|
内容安全与审核 |
依赖关键词匹配,无法有效识别图像、视频中的违规内容(如色情、暴恐元素),且难以应对谐音、隐喻等隐蔽违规。 |
同步分析画面中的物体、场景、文字以及音频中的对话、背景音,综合判断整体语义,实现精准识别。 |
|
企业数据防泄露(DLP) |
主要监控文本,难以防止通过截图、屏幕拍照、语音沟通等方式泄露核心设计图纸、机密文件。 |
识别图像中的敏感图表、图纸水印,或分析语音通话中的关键信息,实现对企业敏感信息的全方位保护。 |
|
网络安全态势感知 |
各类安全设备(如防火墙、IDS)产生的海量、异构日志难以关联分析,无法形成全局威胁视角。 |
将网络流量、安全告警文本、拓扑图等多源信息融合分析,绘制出完整的攻击链图谱,实现主动预警。 |
|
隐私与合规管理 |
难以核查海量视频、图片资料是否合规处理了入镜人脸的隐私信息(如马赛克)。 |
自动检测多媒体内容中的人脸、车牌等敏感信息,并校验其是否按政策要求进行了脱敏处理。 |
以下流程图直观地展示了跨模态语义理解技术如何通过三大核心机制协同工作,最终实现精准的内容安全判断。
核心机制与算法原理
-
跨模态表征学习:建立统一的语义空间
这是技术的基础。其目标是将文本、图像等不同形态的数据映射到同一个高维的数学空间(向量空间),使得语义相近的概念(如“猫”的图片和“猫”这个文字)在这个空间里的位置也很接近。核心算法包括:
-
对比学习:一种自监督学习范式。通过构造“正样本对”(匹配的图文,如一张猫图及其描述)和“负样本对”(不匹配的图文,如猫图和“一只狗”的描述),让模型学会拉近正样本在向量空间中的距离,推远负样本的距离。CLIP模型是成功典范。
-
模态桥接:通过共享的投影层,将分别由不同编码器(如ViT处理图像,BERT处理文本)提取的特征,映射到统一维度的向量空间,以便进行后续的融合和比较。
-
-
跨模态信息融合:实现深度的模态交互
在统一表征的基础上,需要让不同模态的信息进行深度交互。关键在于交叉注意力机制。以图文为例,当模型处理一段文本时,交叉注意力机制允许文本中的每个词(作为“查询”或Query)去“询问”图像中各个区域(作为“键”或Key)的相关性,然后根据相关性权重,对图像区域的信息(“值”或Value)进行加权汇总,从而将视觉信息融合到文本理解中。这种机制使模型能实现细粒度的对齐,例如将“蓝色的眼睛”这个文本描述精准地关联到图片中猫的特定眼部区域。
-
知识增强的推理判断:引入领域知识提升精度
为了提升在专业安全场景下的判断准确性,先进的系统会引入外部知识库(如威胁情报库、敏感内容黑库、安全知识图谱) 来增强模型的推理能力。这通常采用“神经符号融合”框架,将神经网络的强大感知能力与符号知识(可读的逻辑规则)结合起来。例如,模型识别出图片中有一个特定Logo,同时从知识库中知道这个Logo属于一个敏感组织,那么即使描述文本没有明说,系统也能结合两者信息判断出内容涉及该敏感组织,从而做出更精准的拦截。
核心流程与标准
一个典型的基于跨模态语义理解的安全系统,其内部处理流程通常遵循一套标准化的步骤,并注重相应的规范:
-
预处理与特征提取:系统首先对输入的多媒体内容进行解析,例如将视频分解为图像帧序列,并从音频中分离出人声。然后,利用深度学习模型(如CNN、ViT、BERT)分别提取图像、文本、音频等各模态的特征向量。
-
跨模态语义理解与对齐:提取的特征被送入模型的核心(如基于交叉注意力的Transformer网络),进行深度的跨模态融合和对齐,生成包含丰富跨模态信息的统一语义表征。
-
规则匹配与安全判断:系统将理解到的语义信息与预设的安全规则库、知识库(如敏感词黑名单、敏感人物库、合规策略)进行比对。这个过程不仅包括简单的关键词匹配,更包括基于向量相似度的语义级检索,以发现更隐蔽的违规。
-
决策与输出:最终,系统会根据风险评估结果(如置信度分数)做出决策,例如通过、告警、拦截或提交人工复审,并输出结构化的结果,包括违规类型、坐标、时间戳等。
在构建此类系统时,还需关注一些核心标准与最佳实践:
-
数据安全与隐私保护:采用联邦学习进行模型训练,或通过差分隐私技术在数据中添加可控噪声,防止从模型输出反推原始敏感数据。对于高合规要求场景,优先选择支持本地化部署的模型(如Qwen3-VL-8B),确保原始数据不出私域。
-
模型鲁棒性与对抗防御:针对可能的对抗性攻击(如图像上添加人眼难以察觉的噪声导致模型误判),需采用对抗训练等技术提升模型的鲁棒性。
-
系统性能与可扩展性:通过知识蒸馏、模型剪枝等模型压缩技术,以及流水线并行等分布式推理架构,在保证精度的同时提升处理效率,满足高并发需求。
3.4 认知原理上构建更科学的大模型安全评估体系
要从认知原理上构建更科学的大模型安全评估体系,核心在于让评估过程尽可能模拟人类专家进行安全判断时那种多角度、深层次、动态权衡的思维活动,从而缩小冷冰冰的自动化指标与复杂温热的人类感知之间的温差。
理解评估偏差的认知根源
首先,我们需要正视当前评估方法在认知层面存在的几个关键短板,这些短板直接导致了与人类感知的偏差:
-
单一化思维与批判性思考的缺失:许多自动化评估器(包括单一的“LLM-as-a-Judge”)就像一个孤立的决策者,其判断依赖于单一的、固化的内部“思维”模式。这容易产生评估者偏差,并且缺乏人类专家通过辩论、质疑来发现潜在逻辑漏洞的批判性思维过程。
-
“思维捷径”与隐性风险盲区:算法倾向于依赖统计规律和“思维捷径”,这使其擅长识别明确的违规内容(显式风险),但对于需要结合复杂上下文、文化背景和常识进行推理的隐式风险(如隐喻、讽刺、诱导性提问),其识别能力远逊于人类。
-
知识结构的扁平化:人类掌握知识是分层次的,包括需要记忆的事实性知识、需要理解的概念性知识以及需要动手实践的程序性知识。传统的评估往往混为一谈,无法精准诊断模型是在哪个认知层面上出现了问题。
-
“自我审查”带来的盲点:当使用与被评估模型同源的模型作为评估器时,可能存在自评估盲区。这类似于人类心理中的“自我保护倾向”,评估器可能会不自觉地降低对“兄弟模型”生成内容的敏感度,导致高风险内容被漏判。
构建新评估体系的核心原则
基于以上认知层面的短板,一个更科学的评估体系应遵循以下原则:
-
引入多元认知视角:模拟人类专家会诊或辩论的场景,通过多智能体协作框架,让具备不同侧重点的“角色”模型(如专注于规则审计的、擅长挖掘漏洞的、负责反驳质疑的)共同评估,通过角色间的互动与辩论来逼近更全面、深刻的判断。
-
细分知识维度与认知层次:参考认知科学中的知识分类理论,将安全知识体系细致地划分为事实性、概念性和程序性等不同类别。针对不同类别设计不同的评估方式,从而精准定位模型的能力缺陷,为改进提供明确方向。
-
构建动态演进的评估基准:安全威胁是不断变化的。评估基准不能是静态的,而应建立一种持续众包更新的机制,吸收真实世界中出现的新风险案例,使评估体系具备动态适应性,能够应对不断演化的新型威胁。
前沿实践与未来方向
一些前沿研究已经开始将这些认知原理付诸实践。例如,RADAR多智能体协同评估框架通过设置多个专业角色(如安全准则审计员、漏洞检测器、反驳评论员等)并进行多轮辩论,有效提升了对于隐式风险的发现能力,显著降低了误判率。而像CSEBenchmark这样的评估基准,则通过构建基于认知层次的知识图谱,实现了对模型安全知识掌握情况的细粒度诊断,从而能进行针对性的“补强”。
未来,一个理想的评估体系可能会更加强调人机协同。将人类的直觉、价值观判断和跨文化理解能力,与机器的规模处理、不知疲倦的优势结合起来。同时,可解释性将变得至关重要,评估系统不仅要给出“不安全”的结论,更要能清晰地展示出推理路径和判断依据,让人类能够理解和信任。
3.5 持续动态更新、吸收真实世界新风险案例的评估基准
设计一个能够持续动态更新、吸收真实世界新风险案例的评估基准,其核心在于构建一个自动化、可演进、且能与快速变化的威胁环境保持同步的生态系统。这需要一套融合了技术创新与可持续运营的完整方案。

技术架构:自动化与智能化的核心引擎
技术架构是实现动态更新的基石,其目标是最大限度地减少人工干预,实现基准的自我进化。
-
多源数据采集与标准化输入
这是系统的“感官”。它需要从多种渠道持续获取新的风险案例,例如通过自动化红队工具模拟攻击,建立社区众包和漏洞奖励计划以收集来自真实世界的攻击样本,以及监控学术论文和产业安全报告以吸收最新的攻击手法。采集到的原始数据(如攻击提示词、恶意图片、漏洞描述)需要经过清洗和标准化,转化为基准系统可以理解的统一格式,为后续处理打下基础。
-
动态基准生成核心
这是系统的“大脑”,负责将输入的案例转化为有效的测试题。关键技术组件包括:
-
攻击“蒸馏”与选择算法:如微软提出的 JBDISTILL 框架所示,其核心思想并非简单堆积案例,而是利用算法从海量攻击样本中“提炼”出最有效、最具代表性的子集。例如,
RANKBYSUCCESS (RBS)算法会选择在多个开发模型上成功率最高的攻击提示词,而BESTPERGOAL (BPG)算法则确保基准能覆盖多样化的风险目标。这种智能选择解决了传统静态基准的“饱和”与“污染”问题。 -
动态策略引擎:如 SDEval 框架所实践的,通过预设的“动态策略”自动对种子案例进行多样化变换。例如,对文本进行同义替换、多语言混写、添加思维链指令,对图像进行风格转换、添加噪声、物体插入等。这能自动生成海量变种,有效缓解数据泄露问题,并测试模型对核心风险本质的理解而非机械记忆。
-
模块化与可插拔设计:一个优秀的动态基准应具备良好的模块化架构,类似于“天衡”(TeleAI-Safety)平台。这意味着其攻击方法、防御策略、评估标准等组件是解耦的,可以像积木一样方便地替换或增加新的模块,使得集成新的攻击技术变得非常灵活。
-
-
自动化评估与反馈循环
这是系统的“循环系统”,确保评估结果能反馈给基准本身,驱动其进化。
-
高效评估执行引擎:能够自动化的将最新生成的测试集 against 一批需要评估的模型,并收集响应。
-
稳健且多视角的评估器:评估模型输出是否“有害”是关键且困难的一步。为了避免单一评估模型的偏见,采用类似 RADAR 的多智能体评估框架正成为趋势。该框架让多个具备不同视角的“专家”模型进行辩论以达成共识,这比单一模型作为“法官”更能减少评估偏差。同时,评估指标也应超越单一的攻击成功率,涵盖有效性、可分离性、多样性等多个维度。
-
反馈与优化闭环:评估结果会反哺给基准生成引擎。例如,系统可以自动识别出哪些新攻击策略对当前主流模型普遍有效,从而将其权重调高;或者淘汰那些已经失效的测试案例。这个闭环是实现基准持续演化的“灵魂”。
-
运营机制:保障基准持续活力的生态系统
技术架构需要可持续的运营机制来驱动,否则将成无源之水。
-
可持续的社区与数据运营
建立开放的社区平台,鼓励研究人员、白帽黑客乃至用户提交新发现的风险案例和攻击模式。通过漏洞奖励计划等方式,激励社区贡献,形成良性的数据流入循环。同时,设立专门的数据治理团队,负责对提交的案例进行审核、去噪和分类,确保输入数据的质量。
-
版本化发布与合规对接
动态基准本身也应进行版本化管理(如语义化版本号),定期发布包含新威胁的基准版本。这有助于研究社区在统一的标尺下进行比较。同时,运营机制需要与监管要求对接,例如,基准的评估结果可以自动生成符合《生成式人工智能服务安全基本要求》等国家标准的评估报告,帮助企业完成合规备案。
-
自动化监控与更新调度
整个系统需要高度的自动化监控,确保从数据采集、基准生成、评估执行到结果分析的管道顺畅运行。可以设定自动触发规则,例如每月自动运行一次完整的基准更新流程,或在接收到一定数量的高质量新案例后触发增量更新。
总结与展望
总而言之,设计一个能持续动态更新的评估基准,其精髓在于构建一个自我驱动的智能生态系统。它通过JBDISTILL等智能算法从海量威胁中蒸馏出精华考题,通过SDEval等动态策略无限扩展题目变体,并依托多智能体评估确保评分的公正性。在运营上,则依赖社区贡献、自动化管道和版本化发布来维持其生命力。
这种动态基准的价值在于,它使得评估不再是模型发布前的一次性“期末考试”,而贯穿模型全生命周期的“常态体检”,能够真实反映模型在快速变化的网络环境中的实际安全水位,为构建更安全、可信的AI系统提供坚实保障。
3.6 JBDISTILL框架中,RANKBYSUCCESS(RBS)和BESTPERGOAL(BPG)
在JBDISTILL框架中,RANKBYSUCCESS(RBS)和BESTPERGOAL(BPG)是两种核心的提示词选择算法,它们的设计目标和实现逻辑有显著差异,因此也适用于不同的评估场景。
|
对比维度 |
RANKBYSUCCESS (RBS) |
BESTPERGOAL (BPG) |
|---|---|---|
|
核心目标 |
最大化基准的攻击有效性 |
保证基准的目标覆盖率和模型区分度 |
|
选择逻辑 |
全局优选:将所有提示词按在开发模型上的总成功次数排序,选取Top-N。 |
目标平衡:为每一个种子目标,单独挑选对其最有效的提示词。 |
|
输出特性 |
基准由“攻击力”最强的提示词组成,但可能过度集中于少数热门目标。 |
基准均匀覆盖所有种子目标,每个目标至少有一个代表性子集。 |
|
核心优势 |
攻击成功率最高,能有效暴露模型的普遍弱点。 |
覆盖全面,能更好地评估模型在不同类型危害上的防御能力。 |
|
潜在局限 |
可能导致覆盖率失衡,无法全面评估模型对所有类型危害的防御情况。 |
为覆盖冷门目标,可能纳入一些平均有效性稍低的提示词。 |
深入理解算法实现
基于上述核心思路,两种算法的具体实现路径如下:
-
RANKBYSUCCESS (RBS) 的实现路径
RBS算法的运作可以概括为“广撒网,取精华”。其流程是,首先,框架会利用多种越狱攻击方法(即“转换函数”),在多个“开发模型”上对一批“种子目标”进行攻击,生成一个庞大的候选提示词池。接着,算法会统计每个提示词在所有开发模型上的总成功次数。最后,它像一个冷酷的裁判,简单直接地选择那些成功次数最高的前N个提示词,组成最终的安全基准。这种方法确保基准中的每一个提示词都是经过验证的“精兵强将”。
-
BESTPERGOAL (BPG) 的实现路径
BPG算法则更像一个“统筹规划”的经理,其核心在于为目标服务。在生成候选提示词池后,算法不会进行全局排序,而是针对每一个种子目标,单独进行筛选。它会找出针对该特定目标时,在开发模型上表现最好的那个提示词。通过这种方式,BPG能确保最终构建的基准中,每一个种子目标至少有一个代表性的、有效的攻击提示词被包含在内,从而避免了评估盲区。
如何选择适用场景
了解了两者的特性,在实际应用中可以根据评估目标做出选择:
-
追求极致攻击效果时,选用RBS:当你需要压力测试,想知道一个模型在最犀利的攻击下表现如何时,RBS是最佳选择。例如,在模型开发后期进行红队演练或强度测试时,使用RBS生成的基准可以最大限度地冲击模型的安全防线,发现深层次漏洞。
-
需要全面、均衡评估时,选用BPG:当你需要系统性地评估和比较多个模型的整体安全性能时,BPG更为合适。因为它保证了测试的全面性,使得评估结果能真实反映模型 across the board(在所有方面)的安全能力,尤其有利于进行公平的模型间排名。在学术研究或基准测试中,BPG能提供更可靠、偏差更小的结论。
值得一提的是,JBDISTILL框架还提供了第三种算法——COMBINEDSELECTION (CS),它巧妙地结合了RBS和BPG的优点:先使用BPG确保每个目标都被覆盖,再使用RBS填充剩余名额以提升整体攻击力。这为需要平衡“有效性”和“覆盖率”的场景提供了一个理想的折中方案。
四、数据安全融入数据资产管理
4.1 数据安全管理融入数据资产管理
将数据安全管理融入数据资产管理的全流程,并满足各类法律法规要求,是一项系统工程。
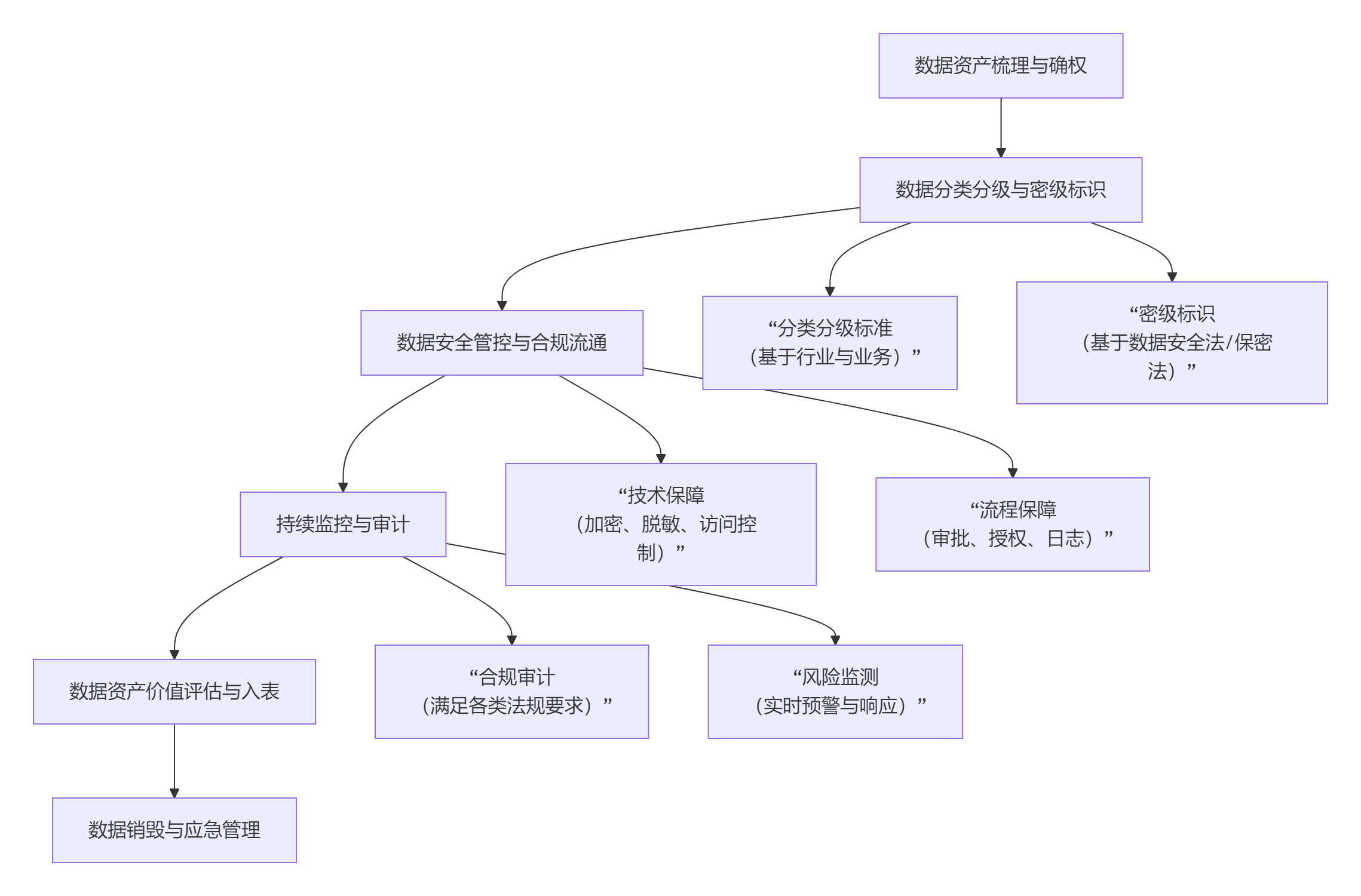
数据资产梳理与确权
首先,你需要全面盘点组织内的数据资产,建立详细目录,明确数据来源、格式、存储位置、责任部门/人员等信息。在此基础上,明晰数据权属关系至关重要。应依据《关于构建数据基础制度更好发挥数据要素作用的意见》(“数据二十条”)提出的数据资源持有权、数据加工使用权、数据产品经营权三权分置方案,在合法合规的前提下,通过合同、管理制度等方式明确数据资产的权益归属与流转规则。
数据分类分级与密级标识
在摸清家底后,必须对数据进行分类分级管理,这是后续所有安全措施的基础。
-
制定标准:根据国家及行业标准(如GB/T 35273对个人信息的保护要求),结合业务特征制定分类分级标准。例如,个人身份证号、生物识别信息属于敏感个人信息;与国家安全、经济发展、公共利益密切相关的则为重要数据。
-
标识与管理:对不同级别数据实施相应的保护措施。重要数据和核心数据需重点保护,其操作日志应至少保存六个月。涉及国家秘密的,还需依据《保守国家秘密法》确定密级并标识。
全流程安全管控与合规流通
在数据的采集、存储、使用、加工、传输、提供、公开、销毁等全生命周期环节中,需嵌入安全管控措施。
-
技术保障:应用加密、脱敏、访问控制、数据防泄漏(DLP)等技术。特别是在数据流通过程中,积极探索使用隐私计算技术(如联邦学习、安全多方计算),实现“数据可用不可见”及“数据不出域”的安全要求。
-
流程保障:建立数据安全审批流程,特别是在与第三方合作时,需进行安全评估并签订保密协议,明确双方责任。重要数据处理活动应进行安全影响评估。
持续监控、审计与合规证明
建立持续监控和审计机制至关重要。
-
日志与审计:记录详细的数据操作日志,并定期审计,确保可追溯。这既是满足《网络安全法》、《数据安全法》等合规要求的手段,也是内部风险控制的重要环节。
-
风险监测与应急:建立数据安全风险监测预警与应急响应机制,制定应急预案并定期演练。在数据资产管理平台中,应能实时监测数据资产状态,识别潜在风险事件并及时处置。
数据资产价值评估与合规入表
在安全合规的前提下,才能有效盘活数据资产价值。
-
价值评估:遵循《数据资产评估指导意见》等规范,结合数据成本、应用场景、市场供求等因素,选择合适方法评估数据资产价值。需特别注意避免虚增资产价值,尤其是公共数据资产。
-
数据资产入表:按照《企业数据资源相关会计处理暂行规定》,在满足特定条件时(如企业拥有控制权、能带来经济利益、成本可靠计量等),可将数据资源确认为无形资产或存货等资产项目入表。关键在于建立健全内部管理制度,确保数据资产的确权、计量、披露等环节有据可依。
规范销毁与应急管理
数据生命周期的终点也需规范管理。
-
规范销毁:建立数据销毁制度,明确销毁流程、审批权限和技术手段,确保数据不可恢复。特别是敏感个人信息和重要数据,销毁需严格审批并记录。
-
应急管理:制定数据安全事件应急预案,并定期演练。一旦发生泄露,立即启动预案,采取补救措施,并按规定上报。
实施路径建议
推进这项工作,建议分阶段进行:
-
现状评估与规划(1-3个月):全面梳理数据资产,评估当前数据安全管理现状与法律法规要求的差距。
-
体系建设与试点(3-6个月):制定数据分类分级标准、数据安全管理制度、数据审批流程等。选择1-2个业务场景进行试点。
-
全面推广与优化(6-12个月及以上):在试点基础上,全面推广数据资产管理体系,并持续优化。
核心原则
最后,请始终牢记几个核心原则:
-
合法合规是底线:所有数据处理活动必须在《网络安全法》、《数据安全法》、《个人信息保护法》、《保守国家秘密法》、《公司法》等法律法规框架内进行。
-
安全与发展并重:不能因噎废食,要在保障安全的前提下促进数据合规高效流通使用。
-
责任共担:数据安全需要所有相关方(数据所有者、管理者、使用者、第三方合作伙伴)共同承担责任。
4.2 数据分类分级国家标准与《数据安全法》中核心数据、重要数据定义的对应关系
理解数据分类分级国家标准与《数据安全法》中核心数据、重要数据定义的对应关系,关键在于把握一个核心原则:国家标准是将《数据安全法》的原则性法律规定,转化为可落地、可执行的具体技术规则和操作指南。
|
对比维度 |
核心数据 |
重要数据 |
|---|---|---|
|
法律定义(《数据安全法》) |
关系国家安全、国民经济命脉、重要民生、重大公共利益等的数据 |
一旦遭到篡改、破坏、泄露或者非法获取、非法利用,可能危害国家安全、经济运行、社会稳定、公共健康和安全等的数据 |
|
国家标准中的定位 |
对领域、群体、区域具有最高覆盖度、精度、规模或深度的重要数据,其非法使用会直接危害政治安全 |
特定领域、群体、区域或达到一定精度和规模的数据,其泄露或篡改会直接危害国家安全、经济运行、社会稳定、公共健康和安全 |
|
危害对象与强度 |
危害对象:直接针对政治安全、国家主权等根本。 |
危害对象:范围更广,包括国家安全、经济运行、社会稳定、公共健康和安全等。 |
|
识别与目录制定 |
由国家数据安全工作协调机制统筹协调,国家有关部门评估确定具体目录。 |
由各地区、各部门(如行业主管、监管部门)根据国家标准的指导,确定本地区、本行业的具体目录。企业需主动申报或根据监管部门告知来识别。 |
|
保护要求 |
实行严格保护,违反其管理制度可能面临最高一千万元罚款并追究刑责。 |
实行重点保护,处理者需明确安全负责人、进行风险评估等。违法向境外提供最高可处一千万元罚款。 |
|
关系 |
是重要数据中一个危害性最高、需要最严格保护的特殊子集。 |
包含核心数据,是介于一般数据和核心数据之间的类别。 |
理解对应关系的操作要点
在实际操作中,要实现精准对应,还需要把握以下几点:
-
遵循国标的识别指南:《数据安全技术 数据分类分级规则》(GB/T 43697-2024)等国标提供了重要的识别指南。例如,它可能会列出关系国家安全重点领域的数据、覆盖全国规模的重大国情国力普查基层数据等,这些通常会被认定为核心数据。而对于重要数据,则会考虑特定领域(如能源、金融)、特定群体或达到一定规模精度的数据。
-
动态识别与申报:重要数据和核心数据的识别是动态的。企业需要根据业务变化及时调整数据目录。如果无法明确判断,应遵循“先按程序申报重要数据目录,请相关部门审定”的原则。相关部门也会主动评估,将未报备但实际已达标的数据纳入目录并通知企业。
-
就高原则与层级关系:根据“就高不就低”的原则,如果同一数据类别包含不同级别,应按其中最高级别定级。这清晰地表明,核心数据本质上是重要数据中危害性最高、需要最严格保护的一个特殊子集。
总结来说
您可以这样理解二者的对应关系:《数据安全法》提供了法律上的定义和框架,而数据分类分级国家标准则是一部详细的“说明书”和“操作手册”。它通过可量化的指标(如覆盖范围、精度)、具体的危害场景描述和识别流程,确保了法律定义在现实工作中能够被准确理解和执行。
4.3 动态的数据分类分级调整机制
建立动态的数据分类分级调整机制,对现代企业来说已不再是“可选项”,而是确保数据安全、满足监管合规、让数据资产真正创造价值的核心工程。一个优秀的动态机制,能确保您的数据保护策略始终与业务风险和监管要求同步。
|
机制板块 |
核心目标 |
关键活动/要素 |
|---|---|---|
|
制度与流程保障 |
明确“谁、在何时、如何做”,确保调整有据可依。 |
建立数据安全责任制、制定动态调整审批流程、设定定期评估与触发式评估机制。 |
|
技术平台支撑 |
实现自动化、可视化的数据发现、打标和监控。 |
采用数据发现与分类工具、构建数据资产地图、建立数据血缘追踪能力、实施动态访问控制与审计。 |
|
运营与治理融合 |
将数据安全要求无缝嵌入业务日常,而非额外负担。 |
将数据安全纳入系统开发生命周期、建立数据分级管控与业务场景的绑定、开展持续的员工培训与意识提升。 |
|
持续优化循环 |
通过定期审计和演练,验证机制有效性并持续改进。 |
定期进行数据安全专项审计、组织数据安全应急演练、基于审计和演练结果优化策略。 |
4.3.1、制度与流程设计
动态调整的基石是明确的责任和清晰的流程。
-
明确责任主体:企业应建立覆盖决策层、管理层、执行层的数据安全责任制。明确企业主要负责人是数据安全第一责任人,并指定数据安全归口管理部门(如数据安全委员会或首席数据安全官),负责领导分类分级工作。各业务部门则承担本领域数据管理的直接责任。
-
设立动态调整的“触发器”:调整不应随意进行,而应由特定事件触发。这主要包括:
-
定期评估:例如每季度或每半年对数据目录和分级情况进行全面审查。
-
事件驱动评估:当发生业务系统变更、数据泄露事件、新的法律法规出台或数据出境等场景时,应立即启动重新评估。
-
-
制定清晰的调整流程:一个标准的调整流程应包括:申请(由业务方或数据所有者提出)-> 审批(由数据安全归口部门根据既定标准审核)-> 执行(在技术平台更新标签和策略)-> 记录与通知(更新数据资产目录并告知相关方)。
4.3.2、技术平台与工具
依靠人工维护Excel表格无法实现真正的“动态”,必须借助技术力量。
-
自动化数据发现与分类:利用专业工具(如Microsoft Purview、Alibaba Cloud Data Security Center等)自动扫描数据源,识别敏感数据(如身份证号、银行卡号),并初步打上分类分级标签,大幅提升效率和覆盖面。
-
构建数据资产地图与血缘关系:建立企业级数据架构和数据资产地图,实现数据资产的统一登记和管理。同时,通过技术手段追踪数据血缘关系,即数据从产生、加工到使用的全链路。当源头数据级别调整时,能快速评估和通知下游数据受影响范围,实现标签的自动传播和联动更新。
-
实现动态的访问控制与审计:将数据分级结果与权限系统绑定,实施基于角色和最小权限原则的访问控制。例如,对核心数据设置“角色+时间”双因子认证,非工作时段自动冻结访问权限。同时,所有对敏感数据的操作都必须全程留痕,以便审计和追溯。
4.3.3、与业务和治理的深度融合
技术和管理流程最终要服务于业务,避免安全和业务“两张皮”。
-
安全左移,嵌入开发流程:在信息系统开发的需求和设计阶段,就明确所处理数据的预期级别,并将安全保护措施与系统实现同步规划、同步建设、同步使用(三同步原则)。
-
绑定业务场景,避免静态标签:分类分级必须与具体业务场景结合。例如,单个用户的身份证号在数据库里可能被定为“重要数据”,但当其与100万用户的信息聚合后,因规模效应可能升级为“核心数据”。这就需要建立规则,根据使用场景、用途用量和数据规模动态调整数据级别。
-
培育数据安全文化:定期对全员进行数据安全意识和分类分级知识的培训,将数据安全要求纳入绩效考核,形成全员共同维护数据安全的氛围。
总结与建议
建立一个动态的数据分类分级机制,本质上是将数据安全治理从一项阶段性项目,转变为一个融入企业运营血脉的持续迭代过程。
建议您可以从一个或几个关键业务部门开始试点,优先处理最重要的数据资产,跑通“制度-技术-业务”联动的闭环,积累经验后再逐步推广到全企业。记住,目标是让数据安全成为业务的赋能者,而不仅仅是合规的成本项。
4.4 数据发现与分类工具的评估指标
在选择数据发现与分类工具时,需要一套全面的评估指标来确保工具能真正满足您的业务需求。
|
评估维度 |
核心评估要点 |
关键问题与具体指标 |
|---|---|---|
|
数据识别能力 |
扫描覆盖范围、识别准确度、内容深度 |
- 支持的数据源类型:能否覆盖各类数据库、数据仓库、大数据平台、云存储及文件系统?对非结构化数据(如文档、图片、视频)的支持程度如何? |
|
自动化与智能化 |
任务调度、AI应用、人工协作 |
- 自动化运行:是否支持定时扫描、实时监测、事件触发等自动化策略?是否支持“主被动结合”的监测模式? |
|
结果可操作性 |
资产可视化、策略联动、开放集成 |
- 可视化与资产地图:是否提供统一视图,清晰展示数据资产分布、分类分级结果、血缘关系? |
|
平台性能与总拥有成本 |
扫描性能、部署模式、生态合规 |
- 扫描效率与扩展性:处理海量数据时的扫描速度、对计算资源的占用情况,以及是否支持水平扩展。 |
|
合规与行业适配 |
法规模板、行业模板、审计支持 |
- 合规性支持:是否预置《数据安全法》等相关法规要求的分类分级模板?是否支持金融(JR/T 0197—2020)、医疗等行业标准? |
选型决策流程
在实际选型过程中,可以遵循以下步骤以确保决策的全面性和准确性:
-
明确核心需求:首先明确企业必须满足的合规性要求,以及当前面临的最紧迫的数据安全风险。这将帮助您确定工具必备的功能。
-
功能验证:向候选厂商索取在其类似技术环境(如相同品牌的数据库、对象存储)下的概念验证(POC)测试报告,重点验证其在您环境中的识别准确率和性能。
-
评估集成与总拥有成本(TCO):评估工具与现有数据安全体系(如DLP、数据库审计系统)的集成成本和长期运维成本。总拥有成本(TCO)包括软件许可/订阅费、实施开发、服务器资源消耗和专职运维人员投入等。
-
关注易用性与团队赋能:选择界面直观、支持业务团队协同打标的工具,可以显著降低推广使用的门槛,确保分类分级成果能有效赋能业务人员。
总结
选择数据发现与分类工具是一项战略投资。核心在于选择一款能够精准识别数据、通过自动化与智能化降低运营成本、并提供开放接口与现有安全体系无缝集成,同时满足合规性要求的平台。
4.5 数据血缘追踪系统高效支撑数据分类分级的动态调整
要让数据血缘追踪系统高效支撑数据分类分级的动态调整,关键在于打通两大体系,实现“血缘链路精准刻画数据流转,分类分级标签自动传递与联动管控”。其核心设计目标是:一旦源头数据的分类分级标签发生变化,系统能自动、快速、准确地识别影响范围,并驱动全线安全策略协同更新。
系统核心架构设计
一个能有效支撑分类分级联动调整的数据血缘系统,其架构设计应确保数据流动关系与安全策略紧密耦合。以下表格展示了系统的核心组件与协作关系:
|
系统层级 |
核心职责 |
关键组件/技术选型 |
|---|---|---|
|
数据采集与解析层 |
从各类数据源自动采集元数据,并解析出数据血缘关系。 |
- 连接器:适配Hive, Spark, Kafka, 关系型数据库等。 |
|
血缘建模与存储层 |
将血缘关系建模为图结构并存储,支持高效的上游溯源和下游影响分析。 |
- 数据模型:采用属性图模型,节点(数据实体)和边(转换关系)均可携带属性(如分类分级标签)。 |
|
分类分级标签集成层 |
将分类分级结果与血缘图中的数据实体绑定,并管理标签的传递规则。 |
- 标签注入:通过API将分类分级系统的标签同步至血缘系统,作为节点/边的属性。 |
|
联动调整与策略执行层 |
响应标签变更事件,计算影响范围,并触发下游的安全策略更新。 |
- 事件驱动机制:当源头数据标签变更时,自动触发影响分析。 |
|
可视化与监控层 |
为管理和运维人员提供直观的可视化界面和监控能力。 |
- 血缘地图:以图的形式清晰展示数据链路,并高亮显示数据的分类分级标签。 |
实现高效联动调整的关键技术策略
在核心架构基础上,以下几点技术策略是实现高效联动的精髓:
-
追求字段级血缘粒度
表级血缘在评估影响范围时颗粒度太粗,可能造成管控盲点。字段级血缘能精确揭示敏感字段(如
user_info.id_number)的流转路径,确保分类分级策略能精准落地到每一个数据单元,是实现精细化管控的基石。 -
建立标签传递与冲突解决规则
数据在流转过程中常被加工整合,其分类分级可能发生变化。系统需内置规则引擎,定义清晰的标签继承逻辑。例如,当多个来源的数据合并时,应遵循“就高原则”,将结果数据标记为所有来源中的最高安全等级。这能有效防止高敏感数据流入低安全级别的下游系统。
-
采用事件驱动的动态传播机制
理想的联动不应依赖全天候的批量作业。采用事件驱动架构是关键:当分类分级系统检测到某核心数据的标签变更后,立即向血缘系统发送事件。血缘系统接收事件后,自动启动影响范围分析,找出所有受影响的下游节点,并通知相关安全系统更新策略。这套流程应尽可能自动化,以缩短策略生效的延迟。
-
确保端到端的可视性与可审计性
系统需提供强大的可视化能力,让治理人员不仅能看清数据链路,还能一眼看清敏感数据的分布和流动。当标签发生变更时,系统应记录完整的审计日志,包括谁、在何时、因何故修改了标签,以及此次变更自动影响了哪些下游,为合规审计提供确凿证据。
总结与最佳实践
总而言之,设计一个能高效支撑分类分级联动调整的数据血缘系统,本质上是构建企业数据治理的“中枢神经系统”。它让静态的数据标签“活”起来,随着数据流动而自动传递和生效。
在实践初期,建议采取分步实施的策略:先从最重要的业务数据域(如包含用户个人信息的核心表)开始试点,建立端到端的字段级血缘和标签联动,跑通闭环后再逐步推广到全企业。同时,务必重视将数据血缘分析与分类分级联动流程固化为企业数据治理的标准操作规程,并通过培训提升相关团队的数据素养。
通过上述设计,企业能够建立起一个响应迅速、管控精准的数据安全防护网,真正让数据分类分级制度“动”起来,在满足合规要求的同时,赋能数据的安全、高效利用。
4.7 设计POC测试以验证数据发现与分类工具
在设计POC测试以验证数据发现与分类工具处理非结构化数据的性能时,关键在于构建一个科学、全面且贴近实际的测试框架。以下是一套核心的设计原则和具体方法,希望能为你提供清晰的指引。
构建贴近真实的测试数据集
测试数据的质量直接决定评估结果的可靠性。建议从以下维度构建数据集:
-
数据多样性:确保测试集涵盖工具需要处理的所有非结构化数据类型,如文本文档(PDF、Word)、图像(截图、图表)、代码文件、音频/视频文件等。同时,应包含不同敏感级别(公开、内部、机密等)和不同业务场景(人力资源、财务、研发等)的数据。
-
数据来源:尽可能使用脱敏后的真实业务数据。如果无法获取,可参考的方法,通过公开漏洞数据库(如CVE、Snyk)收集真实漏洞模式,或利用公开数据集(如斯坦福STL-10数据集)进行补充,以模拟真实环境中的数据分布。
-
数据标注:为测试数据集建立准确的“标准答案”(Ground Truth),即预先对每份测试文件进行精确的人工分类和敏感信息标记。这是后续计算各项准确率指标的基础。
设计科学有效的测试用例
基于构建好的测试数据集,设计测试用例时应重点关注以下几点:
-
引入可验证的随机性:为避免工具因简单的关键字匹配而产生误判,可以参考中提到的策略,在测试用例中加入可预测的随机变化。例如,在文本文档中嵌入特定随机字符串的MD5哈希值,然后验证工具是否能正确识别出该哈希值本身。
-
覆盖边缘和异常情况:除了常规数据,应有意识地设计测试用例来验证工具对边界情况和异常输入的鲁棒性。例如,测试处理格式损坏的文件、含有特殊字符的文本、低分辨率或含有水印的图像等能力。
-
确保测试的无害性:所有测试用例,尤其是涉及文件上传或写入操作的,必须遵循无害化原则(PoC无害性原则)。例如,若测试文件上传功能,文件应在被访问后能自动删除,避免对测试环境造成持久化影响。
执行测试与量化评估
在实际执行测试时,需要制定清晰的流程和量化指标:
-
测试执行:将设计好的测试用例批量导入待评估的工具中,运行扫描和分类任务。记录工具的处理结果,并与“标准答案”进行比对。
-
核心量化指标:使用以下指标来量化工具的准确率:
-
精确率:在所有被工具标记为“敏感”或属于“某类别”的文件中,真正符合条件的文件比例。高精确率意味着低误报。
-
召回率:在所有实际敏感或属于某类别的文件中,被工具成功识别出来的比例。高召回率意味着低漏报。
-
F1-Score:精确率和召回率的调和平均数,是综合评价模型性能的核心指标。
-
-
性能与资源消耗:记录工具扫描完整个测试数据集所花费的时间,以及其在运行过程中对计算资源(CPU、内存)的占用情况。这对于评估工具在大规模环境下的可行性至关重要。
总结与建议
要有效验证数据发现与分类工具对非结构化数据的识别能力,一个结构化的POC测试方案至关重要。其核心在于构建贴近现实的测试数据、设计包含随机性和边缘案例的测试用例,并采用精确率、召回率等量化指标进行客观评估。
4.8 字段级血缘采集
实施字段级血缘采集确实会因数据源的特性面临不同的技术挑战。下面这个表格汇总了针对Hive、Kafka及关系型数据库的主要挑战和应对思路。
|
数据源类型 |
主要技术挑战 |
核心解决方案 |
|---|---|---|
|
Hive / 计算引擎 |
1. SQL解析复杂性:复杂嵌套SQL、UDF(用户自定义函数)导致字段映射关系难以准确解析。 |
1. 采用强大SQL解析器:使用Apache Calcite等工具解析SQL,生成详细语法树以提取字段关系。 |
|
Kafka / 流数据源 |
1. 动态数据追踪:数据持续流动,难以像静态数据一样进行事后分析。 |
1. 运行时动态追踪:在Flink等流处理作业中嵌入追踪代码,实时记录数据来源和转换逻辑。 |
|
关系型数据库 (MySQL等) |
1. 异构环境适配:不同数据库(MySQL, Oracle, SQL Server)的SQL方言和元数据表结构不同。 |
1. 统一解析与适配:利用Druid等支持多方言的SQL解析库,或为不同数据库开发适配器。 |
关键技术选型建议
在应对上述挑战时,一些关键的技术选型能显著提升效果:
-
SQL解析:推荐使用 Apache Calcite 这类功能强大的SQL解析引擎,它能够将SQL语句解析成抽象的语法树(AST),从而为深入分析字段间的依赖关系奠定基础。
-
采集策略:优先考虑基于运行时监听(Listener/Hook) 的方案。与事后解析SQL脚本相比,运行时采集能获取到最准确、最完整的上下文信息(如UDF逻辑、临时表),有效避免因元数据变更或脚本缺失导致的解析失败。
-
存储方案:面对海量的字段级血缘关系(可能达到亿级),传统的关联数据库查询性能可能不佳。图数据库(如JanusGraph, Neo4j) 是更自然和高效的选择,因为它们天生适合存储和遍历复杂的网络关系。
实践中的注意事项
在实际落地过程中,还有几点需要特别留意:
-
平衡性能与开销:血缘采集作为数据平台的支撑系统,其首要原则是不影响业务数据的正常生产和加工。异步处理、资源隔离、采样等机制是保证这一点的重要手段。
-
版本兼容性:特别是对于Hive、Spark等活跃的开源项目,不同版本间的Hook接口、执行计划细节可能存在差异。在升级组件时,需要重新测试和适配血缘采集模块。
-
建立统一元模型:为了整合不同数据源的血缘,需要设计一个统一的元数据模型,来定义“字段”、“表”、“数据任务”等核心实体及其关系,这是实现跨数据源血缘追溯的基础。
4.9 UDF和复杂SQL转换场景中字段映射准确性
传统强类型与SQL解析
在UDF开发中,强类型约束是确保字段映射准确性的基础。以Flink为例,您可以使用 @FunctionHint和 @DataTypeHint注解,在UDF代码中直接明确定义输出字段的名称和类型。这种方式能有效利用编译时检查来避免运行时因类型不匹配导致的错误。
对于复杂SQL语句,深度SQL解析是理解字段映射关系的前提。其过程通常是将SQL语句通过词法分析和语法分析,转换为抽象语法树,从而提取出表对象、列对象、查询条件等上下文信息。基于AST,可以进行更精确的SQL改写,例如,准确识别出需要加密的字段位置并将其替换为特定的加密函数调用,而不是简单的字符串替换。
逻辑计划分析与形式化验证
要进一步提升复杂转换(如多级UDF嵌套或复杂JSON解析)的准确性,可以借助更先进的分析与验证技术。
-
逻辑计划分析:现代大数据引擎(如Spark、Flink)会将SQL查询和UDF转换为逻辑计划。通过分析此计划,可以更精确地推断数据流和字段 lineage(血缘关系)。例如,将JSON解析的UDF调用映射到逻辑计划中的特定操作符,从而更清晰地理解输入/输出结构。
-
形式化验证与AI辅助:对于极其复杂的逻辑,可以采用形式化方法验证UDF与目标SQL的等价性。微软研究的QURE框架是这方面的前沿探索,它利用大语言模型(LLM)将UDF(特别是Python/Pandas UDF)初步翻译为SQL,然后通过形式化验证(如利用Hoare逻辑)来确保翻译后的SQL与原始UDF在语义上完全等价。这种方法能系统性地保证转换的准确性,避免人工翻译可能带来的错误。
AI增强与统一优化框架
AI技术也为解决复杂字段映射问题提供了新思路。
-
AI辅助翻译与推断:直接利用大语言模型理解和翻译UDF逻辑已显示出潜力。例如,LLM能够将包含复杂循环、条件判断或特定数据结构(如Python字典)的UDF代码,转换为功能等效的SQL表达式。关键在于通过后续的验证机制来保证AI输出的可靠性。
-
统一优化执行:从整体架构考虑,将UDF内联(Inlining)到查询计划中进行统一优化,是提升性能和准确性的高级策略。QURE框架在验证UDF与SQL等价后,会进行内联,使得优化器能基于整个查询语境进行优化,从而获得显著的性能提升。
核心策略总结
下表概括了这些技术的核心思路与适用场景:
|
技术方向 |
核心思路 |
典型场景/优势 |
|---|---|---|
|
强类型约束 |
在UDF定义中显式声明字段类型和名称。 |
基础且有效,利用编程语言或框架的类型系统在编译或注册时检查错误。 |
|
深度SQL解析与改写 |
基于AST进行精准的语法分析和语义转换。 |
适用于数据库网关、加密中间件等需要对SQL进行精确干预的场景。 |
|
逻辑计划分析与形式化验证 |
在大数据引擎的逻辑层面对UDF和SQL的语义进行等价性证明。 |
处理极其复杂的UDF逻辑,保证转换的绝对正确性,适用于高安全、高一致性要求的场景。 |
|
AI增强与统一优化 |
利用LLM等AI技术辅助代码转换,并将UDF逻辑融入整体查询计划进行优化。 |
应对快速变化的需求和复杂逻辑,潜力巨大,旨在提升开发效率和执行性能。 |
4.10 Spark、Flink和Trino这三大主流引擎在处理UDF逻辑计划上的差异
理解Spark、Flink和Trino这三大主流引擎在处理UDF逻辑计划上的差异,对于构建高效、可靠的数据处理管道至关重要。下面这个表格清晰地展示了它们在核心架构、优化逻辑和适用场景上的关键不同。
|
特性维度 |
Apache Spark |
Apache Flink |
Trino |
|---|---|---|---|
|
核心架构理念 |
批处理为基,微批仿流 |
流处理为基,批乃特殊流 |
MPP架构,专注交互式分析 |
|
UDF集成方式 |
深度绑定Catalyst优化器 |
逻辑计划与运行时强关联 |
基于字节码生成的函数框架 |
|
优化关键 |
基于规则的优化 |
流式上下文优化 |
基于代价的优化与向量化 |
|
适用场景 |
复杂的批处理ETL、ML管道 |
有状态的实时流处理、事件驱动应用 |
高速即席查询、多数据源联邦分析 |
核心差异详解
上述表格概括了整体定位,以下是对这些差异的深入解析:
-
Spark:深度集成的批处理优化专家
Spark将UDF视为逻辑计划中的一个算子。其强大的Catalyst优化器会对包含UDF的整个计划进行一系列基于规则(Rule-based)的优化。例如,它会尝试将UDF之前的过滤条件“下推” 到数据源附近,从而尽量减少进入UDF的数据量。此外,其Tungsten引擎会生成直接在二进制数据上工作的代码,减少了JVM对象开销,这对于提升UDF执行效率至关重要。然而,由于其“微批处理”的流处理模型,在实时性要求极高的场景下,UDF的调用会带来一定的延迟。
-
Flink:为流而生的状态处理大师
Flink从设计之初就将流处理作为第一公民,并将批处理视为流的一个特例。这使得它的UDF优化天然地融入了流式思维。其优化器会特别关注UDF操作在有状态计算(如窗口聚合、连接)中的效率,并优化状态的管理和访问。更重要的是,Flink的逻辑计划优化会充分考虑时间语义和水位线的传播,确保在乱序事件流中UDF处理的正确性。这种深度集成让Flink在需要低延迟和精确一次处理的实时流场景中表现出色。
-
Trino:高速即席查询的执行引擎
Trino作为一个大规模并行处理引擎,其设计目标是实现交互式的SQL查询速度。它对UDF的处理方式更为“直接”和“务实”。它拥有一个基于代价的优化器,能够为复杂的查询(包括包含UDF的查询)选择高效的连接顺序和执行计划。同时,Trino会为UDF调用生成高度优化的字节码,并尽可能利用向量化执行,让CPU缓存和指令流水线发挥最大效能,从而在数据扫描和计算阶段获得极速体验。这使得它特别适合用于需要快速响应的即席查询和多数据源联邦分析场景。
实践建议与选择考量
了解这些差异后,你可以根据实际需求做出更合适的技术选型或优化:
-
场景选择:
-
如果你的核心业务是复杂的批处理ETL、机器学习数据预处理,且生态统一性很重要,Spark是稳健的选择。
-
如果需要处理持续的实时数据流,且应用涉及复杂的事件顺序、状态维护或窗口计算,Flink的流式原生架构优势明显。
-
如果追求亚秒级响应的交互式数据分析,需要跨多个异构数据源进行快速查询,Trino是更合适的工具。
-
-
UDF开发优化:
-
在Spark中,应尽量使用DataFrame API而非低效的RDD API,并充分利用其内置的高级函数,以减少序列化开销。
-
在Flink中,要善用其状态管理和时间窗口机制,并确保UDF函数是可序列化的,以适应其分布式运行时模型。
-
在Trino中,可以探索其向量化UDF的支持,以进一步提升批量数据处理的吞吐量。
-
4.11 纯文本知识数据管理的数据血缘、数据注解以及历史版本管理
核心方法概览
|
管理维度 |
核心目标 |
关键技术/方法 |
|---|---|---|
|
数据血缘 |
追踪数据的起源、流转与转换关系,确保可追溯性。 |
基于BERT等模型的语义分析、文本块聚类与时间序列分析、大语言模型(LLM)驱动的迭代式图谱推理。 |
|
数据注解 |
为数据添加机器可读的标签或元数据,提升其可理解性与可利用性。 |
实体识别与分类(如BIO标记法)、关系抽取、利用大语言模型(LLM)进行自动化或辅助标注。 |
|
历史版本管理 |
记录并管理数据随时间的变化,支持审计与回溯。 |
基于唯一标识符(如UUID)和元数据快照的版本模型、内容差分与向量相似度对比、标签化版本策略。 |
数据血缘:追踪数据的来龙去脉
数据血缘的核心在于理解数据是如何产生、演变和关联的。对于非结构化的纯文本,传统方法面临挑战,而现代技术提供了新的解决方案。
-
语义分析技术:通过像BERT这样的预训练语言模型,可以将文档或文本块转换为高维向量(嵌入)。这些向量能够捕捉深层的语义信息。通过计算这些向量之间的相似度(如余弦相似度),可以发现内容高度相关的文档,即使它们没有直接的引用关系。
-
动态图谱推理:更先进的方法将数据血缘构建为知识图谱。当用户进行查询时,系统可以基于大语言模型(LLM)进行迭代式推理:先提取关键词在向量数据库中检索相关节点和边,形成候选子图;若信息不足,LLM会生成新的关键词再次检索,扩展子图,直到获得满足需求的答案。这种方法能动态、精准地揭示复杂的数据关系。
数据注解:赋予数据更丰富的内涵
数据注解是为原始数据添加结构化或半结构化标签的过程,使其更容易被机器理解和处理。
-
实体识别与关系抽取:这是基础且关键的注解方法。
-
实体识别 旨在识别文本中提到的特定实体,如人名、地点、组织、专业术语等。常用的方法如BIO标记法(B-开始,I-内部,O-外部)有助于确定实体的边界和类型。
-
关系抽取 则更进一步,旨在识别文本中不同实体之间的语义关系(如“工作在”、“位于”)。这有助于构建数据之间的关联网络。
-
-
LLM在注解中的应用:大语言模型(LLM)的出现极大地提升了数据注解的效率和范围。它们可以用于:
-
自动化注解:根据指令自动为文本打上情感标签、主题分类等。
-
生成复杂标注:例如,生成“思维链”(Chain-of-Thought)式的推理步骤注解,解释某个结论是如何得出的。
-
辅助知识蒸馏:LLM可以作为“教师模型”,生成高质量的标注数据,用于训练更小巧、专精的“学生模型”。
-
历史版本管理:记录数据的每一次蜕变
对于知识库等纯文本数据,有效的版本管理至关重要。
-
版本模型的核心:一个稳健的版本系统通常依赖于唯一的文档标识符(如UUID) 和完整的元数据记录(包括导入时间、文件大小、哈希值等)。即使文档内容更新,其唯一标识符保持不变,从而将所有历史版本关联起来。
-
变更检测与对比:系统通过比较文件哈希或元数据来检测变更。当发现新版本时,不仅可以进行文本内容差分,还可以利用向量相似度从语义层面对比不同版本分块之间的差异,更智能地识别内容演变。
-
标签化与管理策略:采用类似软件版本的语义化版本标签(如v1.0, v1.1)管理重要版本。可以通过标签批量操作文档(如按版本标签检索或清理),并制定合理的版本保留策略以平衡存储成本与追溯需求。
综合应用与工作流
在实践中,这三者可以紧密结合,形成一个强大的数据治理闭环。例如,一份行业研究报告的迭代过程可以这样管理:
-
版本入库:当报告V1.0被首次导入系统时,为其分配UUID,并自动进行数据注解,识别出其中的关键实体(如公司名、技术术语)和观点。
-
更新与比对:当报告更新至V1.1时,系统通过历史版本管理 记录差异,并自动运行数据血缘 分析,确认V1.1是V1.0的修订版,而非一份全新文档。
-
知识整合:系统可能会发现V1.1中提到的某个新概念与知识图谱中另一份市场数据报告存在语义关联,从而自动建立数据血缘 链接,丰富了知识网络。
4.12 利用BERT等模型计算语义相似度
利用BERT等模型计算语义相似度,主要有两种高效的方法:一是使用预训练模型直接生成句子向量再进行相似度计算,二是在特定数据集上对模型进行微调以适应特定领域的语义理解。
|
步骤 |
关键活动 |
说明与推荐 |
|---|---|---|
|
1. 环境与模型准备 |
安装必要的库,加载预训练模型。 |
核心库: |
|
2. 数据预处理 |
对文本进行清洗和标准化编码。 |
清洗文本(去除特殊字符、多余空格等)。使用模型对应的分词器(Tokenizer)将文本转换为模型可接受的输入格式(如input_ids, attention_mask),并统一填充(padding)和截断(truncation)长度 。 |
|
3. 获取句子向量 |
将文本转化为高维向量表示。 |
BERT原生模型:通常取最后一层隐藏状态中 |
|
4. 计算相似度 |
度量两个向量之间的语义相似性。 |
最常用且有效的方法是余弦相似度(Cosine Similarity),其值域为[-1,1]或[0,1],值越大表示语义越相似 。 |
方法一:使用预训练模型直接计算(快速上手)
这种方法无需训练,适合快速验证、处理通用领域问题或计算资源有限的情况。
# 示例代码(基于 Sentence-BERT)
from sentence_transformers import SentenceTransformer, util
# 1. 加载预训练模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 2. 准备句子
sentences = [
"A man is playing a guitar.",
"A man is playing an instrument."
]
# 3. 生成句子嵌入向量
embeddings = model.encode(sentences, convert_to_tensor=True)
# 4. 计算余弦相似度
cosine_similarity = util.pytorch_cos_sim(embeddings[0], embeddings[1]).item()
print(f"语义相似度: {cosine_similarity:.4f}")方法二:微调模型(追求最优性能)
当你的任务涉及特定领域(如医疗、金融)或对精度要求极高时,在领域相关数据上微调BERT模型是必要步骤 。
-
数据准备:需要包含句子对和对应相似度分数(或相关性标签)的数据集,例如STSB(Semantic Textual Similarity Benchmark)。
-
模型选择与加载:加载预训练模型(如
bert-base-uncased),并根据任务类型(分类或回归)设置分类头 。 -
训练循环:
-
损失函数:对于相似度打分(回归任务),常用均方误差损失(MSE Loss) 或余弦相似度损失;对于判断是否相似(分类任务),则使用交叉熵损失 。
-
负样本构造:这是提升模型判别能力的关键。可以使用Triplet Loss,通过精心构造(目标句,语义相近的正例句,语义不同的负例句)三元组,让模型学会拉近正例、推远负例 。美团技术团队在实践中就采用了Skip-Above采样等方式构造高质量负样本 。
-
-
评估与预测:在预留的验证集上评估模型性能,使用斯皮尔曼相关系数等指标衡量预测分数与真实分数的相关性 。
最佳实践与技巧
-
模型选择:平衡速度与精度。
paraphrase-MiniLM-L6-v2模型在速度和性能间取得了良好平衡,非常适合作为起点。若追求更高精度,可考虑更大的模型
4.13 基于大语言模型的知识图谱推理
基于大语言模型的知识图谱推理,为数据血缘分析带来了新的突破。下面这个表格概括了几个关键的应用场景及其核心价值。
|
应用场景 |
核心功能 |
技术亮点 / 解决的关键问题 |
|---|---|---|
|
民政数据治理 |
自动化构建民政数据血缘知识图谱 |
利用LLM解析复杂SQL逻辑,识别字段级血缘,消除虚拟表冗余,提升数据质量与管理效率。 |
|
电力量测系统分析 |
支持复杂查询的迭代式子图推理 |
结合LLM迭代推理与PCST算法,动态扩展子图,实现精准溯源与知识发现,并具备知识补全机制。 |
|
多行业通用数据溯源 |
全链路、自适应数据血缘关系建模 |
采用多模态Transformer模型处理多源异构元数据,捕捉深层语义关联,并能在线学习以适应元数据变化。 |
|
SQL分析专用场景 |
智能数据血缘问答与问题诊断 |
将SQL血缘信息向量化后构建智能体,不仅能展示血缘关系,还能主动定位数据问题并给出解决建议。 |
核心技术与趋势
综合这些应用案例,可以看到基于LLM的数据血缘分析呈现出几个明确的技术趋势:
-
动态化与智能化:技术从依赖静态规则转向具备动态推理和自适应学习能力。例如,迭代式子图推理方法可以根据查询动态扩展关联信息,而非仅依赖预设路径。
-
深度语义理解:LLM的引入使得系统能够理解数据的业务语义。这意味着血缘分析不再局限于简单的表字段映射,还能理解数据背后的业务逻辑和转换意图。
-
自动化与易用性:这些方法显著降低了数据血缘分析的技术门槛。传统上需要数据库专家手动解析复杂SQL语句的工作,现在可以通过LLM实现自动化或半自动化处理,降低了专业依赖和成本。
-
从“关系展示”到“决策支持”:现代数据血缘分析的价值不再仅仅是展示数据流向,更在于能够进行影响分析、根因定位和智能问答,直接为数据开发和治理决策提供支持。
4.14 实际项目中实体识别和关系抽取的协同工作
在实际项目中,实体识别和关系抽取的协同工作,核心在于如何让它们相互促进,以更精准地从文本中提取结构化知识。以下是主要的协同模式及其应用考量。
|
协同模式 |
核心思路 |
优势 |
挑战 |
典型技术/方法 |
|---|---|---|---|---|
|
流水线模式 |
先进行实体识别,再对识别出的实体进行关系分类。 |
模块化,易于实现和调试;两个任务可独立优化。 |
错误传播:实体识别错误会直接影响关系抽取。 信息割裂:关系分类时无法充分利用实体识别阶段的深层特征。 |
实体识别:BiLSTM-CRF;关系分类:SVM, CNN, RNN |
|
联合抽取模式 |
使用单一模型同时输出实体及其关系,将两个任务统一建模。 |
全局优化:通过共享参数,共同学习两个任务,减少错误累积。 效率更高:避免生成冗余的实体对。 |
模型设计更复杂;对标注数据要求高(需要标注实体和关系)。 |
表格填充:将文本转为矩阵,统一标注实体和关系。 序列到序列:将文本直接生成三元组序列。 |
选择与优化策略
在实际项目中选择哪种模式,需要综合考量:
-
数据与资源
-
如果数据量有限或计算资源紧张,成熟的流水线模型或简单的联合模型(如基于标注的方法)可能更合适。
-
如果拥有大量高质量标注数据且追求最佳性能,可尝试更复杂的联合模型(如基于生成或表格填充的模型)。
-
-
任务需求
-
对于重叠关系(如一个实体参与多个关系)和嵌套实体较多的复杂场景,联合抽取模型通常表现更好。
-
如果业务场景中关系类型非常固定,有时基于预定义规则的简单方法也能快速见效。
-
-
迭代与优化
-
主动学习:系统可以筛选出模型不确定的样本(如实体或关系得分低的案例),交由专家标注,用于增量训练,持续优化模型。
-
强化学习:可引入强化学习框架,将关系视为高层决策,实体作为参数,以层次化方式处理两者协同。
-
总结与建议
实体识别与关系抽取的协同工作,是从“识别是什么”到“理解为什么”的关键一步。
-
对于刚启动或复杂度不高的项目,可以从模块化的流水线模式入手,快速验证可行性。
-
对于追求高精度、处理复杂文本的项目,建议探索联合抽取模式,尤其是基于预训练语言模型(如BERT)的方法,这是当前的主流研究方向。
-
无论选择哪种模式,高质量的数据和持续的迭代优化都是成功的关键。
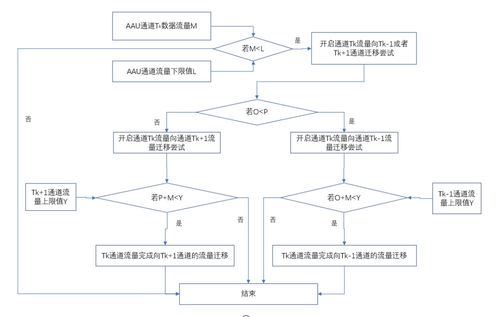
4.15 迭代式子图推理与PCST(Prize-Collecting Steiner Tree)算法
迭代式子图推理与PCST(Prize-Collecting Steiner Tree)算法的协同工作,是一个动态优化与精准检索相结合的过程。它核心解决了从大规模知识图谱中高效提取最相关连通子图的难题。
这个流程之所以能高效运转,关键在于PCST算法在每个迭代周期内扮演的“最优子图架构师”角色。它的工作可以分解为以下几个核心步骤:
-
奖励分配:系统首先计算每个图谱节点和边与当前查询关键词的语义相似度(通常使用余弦相似度)。相似度越高的节点和边,被赋予的“奖励”值就越大。这好比是在地图上为每个地点标注了其与“寻找咖啡店”这一目标的相关性。
-
成本约束:同时,每条边都会被赋予一个固定的“成本”值,旨在控制最终子图的规模,防止其过于庞大。
-
优化求解:PCST算法的目标变得非常明确:寻找一个连通子图,使得其内部节点和边的总奖励减去连接它们的边的总成本后的“净收益”最大化。这个过程就像是规划一条路线,要确保经过的地点(高奖励节点)足够多、足够关键,同时又要保证路线的总长度(连接成本)尽可能合理。
协同工作的核心优势
通过流程图和上述分解,你可以看到迭代推理与PCST算法的协同创造了巨大价值:
-
动态聚焦:迭代式推理允许系统不再是一次性的“盲搜”,而是根据已有信息动态调整搜索方向,像侦探破案一样逐步深入。
-
保障连通与相关:PCST算法确保了每次返回的不是一堆散乱的点,而是一个连通的子图。这对于数据血缘分析至关重要,因为你需要的是完整的数据链路,而不仅仅是几个孤立的数据点。
-
效率与精度的平衡:PCST的“奖励-成本”模型能有效平衡信息的全面性和检索的效率,避免返回不必要的大量信息,从而显著提升处理大规模图谱的效率。
总而言之,迭代式子图推理如同一位“战略家”,规划着探索的路径和方向;而PCST算法则是一位“战术大师”,在每一轮探索中都能精准地构建出最优的连通子图。两者协同,共同实现了在海量知识图谱中高效、准确地进行复杂查询和推理的目标。
4.16 这种“符号主义”与“连接主义”的融合解决多种复杂的知识推理问题
|
应用场景 |
核心协同逻辑 |
独特价值与解决的关键问题 |
|---|---|---|
|
智能问答与对话 |
将KG作为精准、结构化的知识库,供LLM检索验证,增强回答的可靠性和深度。 |
解决LLM的“幻觉”问题,提供带来源依据的答案;支持多跳推理(如“A公司的CEO毕业于哪所大学?”)。 |
|
知识图谱构建与补全 |
利用LLM的语义理解能力,从非结构化文本中自动化抽取实体和关系,辅助或加速KG构建。 |
大幅降低图谱构建的人力与时间成本;利用LLM的泛化能力发现潜在的新关系,实现知识补全。 |
|
个性化推荐系统 |
KG整合用户、物品、属性等多元数据,LLM理解用户深层次意图,共同生成更精准、可解释的推荐。 |
实现跨领域的精准推荐(如基于兴趣相似的“朋友”关系推荐商品);提供推荐理由,提升用户体验和信任度。 |
|
决策支持与解释性分析 |
KG对复杂系统(如供应链、交通网络)进行结构化建模,LLM分析其动态模式,并提供自然语言解读。 |
提升系统行为的可解释性;辅助分析动态演变模式,预测潜在风险,支持战略决策。 |
场景详解与技术实现
下面我们进一步探讨这些场景背后的技术思路和实现方式。
-
智能问答与对话:在此场景下,知识图谱充当了一个可靠的外部知识源。当用户提出问题时,系统首先会利用LLM解析问题意图,然后根据意图在知识图谱中检索相关的子图或事实路径。最后,LLM将检索到的精准知识组织成流畅、易于理解的答案。这种方法尤其适合医疗、金融等对事实准确性要求极高的领域,可以有效控制大模型“编造”信息的风险。
-
知识图谱构建与补全:这里的协同体现在将LLM视为一个强大的信息提取工具。传统图谱构建需要大量人工标注,而LLM可以自动化地从海量文本中完成实体识别、关系抽取、指代消解等核心任务。此外,LLM还能基于已学知识,对现有图谱进行推理,提出新的关系假设,从而实现知识补全。
-
个性化推荐与解释性分析:协同方法能将分散的数据点连接成一张丰富的语义网络。知识图谱可以整合用户行为、物品属性、上下文信息等,形成一张全面的关系网。LLM则擅长深入理解用户查询的语义,并生成个性化的推荐理由。例如,在社交网络中,可以分析用户在物理图中的连通关系和概念图中的兴趣相似度,从而在紧密且兴趣相投的社群中进行精准的商品推荐。对于动态系统,如传感器网络,可以通过分析连接子图的演变模式,理解网络拓扑的稳定性,为网络优化和抗攻击设计提供决策支持。
如何选择应用方向
面对多种应用场景,可以基于以下核心诉求来选择合适的方向:
-
如果您的核心诉求是答案的精准可靠:应优先考虑在智能问答等场景中引入知识图谱,利用其来约束和验证LLM的输出。
-
如果您的核心诉求是高效整合多源异构数据并发现洞察:在推荐系统或决策支持等场景中应用协同方法可能更合适。这能帮助您将数据转化为深度的关系洞察。
-
如果您的核心诉求是降低知识管理的成本并保持其时效性:可以重点探索知识图谱的自动化构建与补全,利用LLM实现知识库的持续自我更新。
4.17 知识图谱的构建与补全
在知识图谱的构建与补全中,利用大型语言模型(LLM)生成关系是一项高效的技术,但确保其准确性和可靠性是核心关键。目前,业界主要通过自动化验证和人机协同两大路径来构建坚实的质量防线。
关系验证的核心方法
为了系统化地保障LLM生成关系的质量,下图梳理了关键的验证方法与技术:
详细解读图中的各类方法。
自动化验证路径
自动化验证效率高,适合处理大规模数据,是首要的验证防线。
-
基于规则的验证:该方法预设一系列逻辑约束和格式标准,对LLM生成的三元组(即“头实体-关系-尾实体”)进行快速筛查。
-
数量与格式检测:检查生成的三元组数量是否合理(如避免过多或过少),并确保其符合预定义的格式(如是否为
(头实体, 关系, 尾实体)的结构)。这是最基本的速度筛查 。 -
逻辑冲突检查:依据预定义的规则库进行深度逻辑校验。例如,检查一个人的出生日期是否在逝世日期之前,或一个城市的入口不可能为负数等。SAC-KG框架中的验证器就采用了此类方法 。
-
-
基于语义的验证:此方法侧重于分析关系在语义层面的合理性。
-
向量相似度分析:通过计算实体和关系在向量空间中的表示,评估其语义上的连贯性。例如,检查“首都”关系两端的实体向量是否通常与“城市”和“国家”的语义相近。
-
知识图谱嵌入评估:利用专门的KGE模型,通过计算三元组的得分来评估其可信度,得分越高,表明该关系在现有知识图谱的上下文中越可能成立 。
-
-
基于外部证据的验证:这是目前非常重要的方法,旨在为生成的关系寻找客观事实支撑。
-
RAG检索验证:当LLM生成关系后,系统会从外部知识源(如权威数据库、专业文献或互联网)检索相关文档或信息。通过比较生成的关系与检索到的证据,判断其事实准确性。CogMG框架就采用了此策略,有效降低了模型“幻觉”风险 。
-
多源交叉验证:针对关键或敏感的关系,从多个独立来源进行交叉比对。若多个可靠来源均支持同一关系,则其可靠性大大增强 。
-
人机协同验证路径
对于复杂、专业或高风险领域的关系,人的判断不可或缺。
-
交互式专家审核:系统提供友好界面,将LLM生成的关系、其置信度以及支持或矛盾的外部证据一并呈现给领域专家。专家可以直接修正、或选择采纳、拒绝关系。CogMG框架就设计了此类管理界面,将最终决定权交予专家 。
-
审计轨迹记录:系统需记录完整的审计轨迹,包括关系的生成来源、验证过程、修改记录及最终审核人。这确保了验证过程的透明度和可追溯性,便于后续复查与优化 。
构建可靠的验证流程
一个稳健的验证系统通常不是单一方法的运用,而是将多种方法组合成一条自动化与人工审核相结合的流水线。
-
初筛与标准化:首先利用基于规则的验证对LLM的原始输出进行快速清洗,过滤掉明显不合规或低级错误的结果。
-
评分与排序:随后,应用基于语义的验证和基于外部证据的验证为每个关系生成一个可信度分数。系统可根据分数对结果进行排序,便于优先处理高价值或高风险的候选关系。
-
分级审核:根据关系的可信度分数及其重要性,实施分级审核。高分且非关键的关系可直接自动化入库;低分或涉及重要实体的关系,则送入人机协同验证环节,由专家进行最终裁定。
核心原则与最佳实践
要有效实施验证,请牢记以下原则:
-
多重证据原则:不要仅依赖单一验证方法。规则、语义、外部证据和人工判断应相互补充,形成交叉验证的合力。
-
可解释性与透明度:验证系统应能提供决策依据,例如,指出是哪些规则被触发或展示了哪些支持性文档,这有助于建立对自动化流程的信任,并辅助专家快速决策。
-
持续迭代:验证规则、语义模型和检索的知识源都需要定期更新和优化,以适应新的知识和不断变化的数据。
4.18 LLM生成的关系设计
在医疗、金融这类高风险领域,LLM生成的关系或结论一旦出错,可能直接导致误诊、财务损失等严重后果。因此,其验证工作远不止于技术指标,更是一套融合了领域知识、合规要求与伦理考量的系统工程。
以下表格梳理了这些领域需要特别注意的关键要求:
|
验证维度 |
医疗领域的特殊要求 |
金融领域的特殊要求 |
|---|---|---|
|
事实准确性与可靠性 |
严防“幻觉”,需与最新临床指南、药品数据库(如医保目录)、ICD编码等权威知识源核对。强调可追溯性,生成内容需有明确医学文献或数据支持。 |
确保与官方财报、监管公告、市场数据等权威信息源一致。关系推理需符合严密的商业逻辑和金融法规,避免误导性陈述。 |
|
领域合规与伦理规范 |
严格遵守HIPAA等患者隐私法规,数据需去标识化。模型决策需通过伦理审查,确保公平无偏见,不因种族、性别等因素产生歧视性输出。 |
符合《金融信息服务安全规范》 等行业标准,确保信息的准确性、完整性、保密性。模型使用需符合金融监管机构(如证监会)的合规要求。 |
|
专业评估与可解释性 |
输出结果必须经由执业医师或资深临床专家进行专业性复审。使用SHAP、LIME等技术提供符合临床思维的解释,说明诊断或治疗建议的推理路径。 |
关键结论(如风险评估、投资建议)需由金融分析师或风控专家确认。模型需提供清晰的推理逻辑和决策依据,满足内部风控和监管问询的需要。 |
|
动态数据与时效性 |
医学知识更新迅速,模型需定期更新知识库以反映最新研究成果和诊疗方案。需监控模型性能,避免因知识陈旧导致输出不准。 |
金融市场瞬息万变,模型需能处理实时或高频数据。验证需包含压力测试,模拟极端市场条件下的表现,确保稳健性。 |
|
错误容忍度与应急预案 |
明确不同错误的严重等级(如将药物剂量错误定为最高风险),并建立相应的人工复核与紧急干预流程。模型应能坦诚承认认知边界,对不确定或超出知识范围的问题给出谨慎回应。 |
制定清晰的错误应对预案,一旦发现模型生成重大错误关系(如错误的风险评估),需有能力快速撤回、更正并通知受影响方,将潜在损失和声誉风险降至最低。 |
构建稳健的验证体系
要满足上述特殊要求,可以着手构建一个多层次的验证体系:
-
技术层面:积极采用检索增强生成(RAG) 技术,将LLM的回答牢牢锚定在权威、结构化的领域知识库(如最新的临床指南、金融监管文件)上,这是对抗“幻觉”最有效的技术手段之一。同时,建立持续监控和反馈闭环,定期用新产生的合规案例或医学发现测试模型,及时发现并修正性能衰减或偏差。
-
流程层面:将人工审核作为高风险决策的必要环节,明确不同风险等级的输出所对应的专家复核流程。此外,建立完善的文档记录机制,保存模型生成结果、所用数据、验证过程和审核记录,以满足审计和监管追溯的要求。
-
指南与基准:积极参考行业内的专业评估框架。例如,在医疗领域可以关注TRIPOD-LLM这类针对临床预测模型的报告指南。同时,利用已有的领域基准(如医疗领域的MedBench、金融领域的FinBen)对模型能力进行标准化测试,这有助于发现系统性的弱点。
总结
在医疗和金融领域验证LLM,核心是从“技术正确”迈向“负责任的可信赖”。这意味着验证工作必须深度融合领域知识,恪守合规底线,并将人类的专业判断置于人机协作的核心位置。
五、现有数据安全方案的分析
5.1 当前数据安全方案的各类缺陷
|
缺陷类别 |
核心问题 |
典型表现与影响 |
|---|---|---|
|
逻辑与设计缺陷 |
安全机制的内在逻辑存在根本性矛盾或设计上易被绕过。 |
• 黑名单防御:用有限的已知恶意规则库对抗无限的攻击手法变异,注定失败。 |
|
知识缺陷 |
对安全技术的原理、局限性和适用条件认知不足,误用或过度依赖。 |
• 对“匿名化”的误解:误认为k-匿名等技术能完全匿名数据,忽视其可能无法抵御交叉数据关联攻击的风险。 |
|
信息论与媒体缺陷 |
安全方案在信息理论层面存在先天不足,或未考虑数据在不同媒介中的完整生命周期。 |
• “匿名化”的理论极限:某些匿名化技术本身缺乏坚实的数学基础,无法从理论上证明其安全边界。 |
|
企业认知缺陷 |
企业在战略、管理和投入上对数据安全的重视不足或存在偏差。 |
• 安全与业务的割裂:将安全视为纯成本部门,或仅在合规驱动下进行“打勾式”安全建设,导致投入不足或与业务实际脱节。 |
构建更健壮的安全体系
认识到这些缺陷后,构建更健壮的安全体系需要从根本理念上进行调整:
-
从“黑名单”到“白名单”与“零信任”:摒弃依赖已知威胁特征的“黑名单”思路,转而采用默认拒绝的“白名单”策略,只允许已知合法的操作。同时,秉承“从不信任,始终验证”的零信任原则,对所有访问请求进行严格认证和授权。
-
追求经过数学验证的安全:在关键领域,优先选择那些经过严格数学证明的技术,如差分隐私(能精确量化并控制隐私泄露风险)和同态加密(允许在加密数据上直接进行计算)。
-
技术与管理并重的纵深防御:技术层面,构建覆盖数据全生命周期的、多层次的防御体系(如输入验证、输出编码、访问控制、审计日志)。管理层面,则需建立完善的数据安全治理框架,明确责任,并持续开展员工安全意识教育。
总结
当前数据安全方案的诸多缺陷,根源在于未能系统性地应对数据的复杂性和动态性。真正的安全不在于寻求一劳永逸的“银弹”,而在于建立一种持续演进、动态适应、并深度融合技术、管理与流程的深层防御文化。这要求我们从根本上转变思路,从被动防御转向主动免疫,从依赖经验直觉转向遵循科学原理。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 11
11 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)