基于spark的空气质量数据分析可视化系统部分展示报告
第1章需求分析
1.1项目背景
随着工业化进程加速和城市化水平提升,大气污染已成为影响公众健康和城市可持续发展的关键议题。我国已建成覆盖全国的空气质量监测网络,积累了海量含PM2.5、PM10、SO2、NO2等核心指标的监测数据,同时整合了气象条件、污染源排放等多维度关联数据。但传统数据处理方法存在效率低下、分析维度单一、实时性不足等痛点,难以深度挖掘数据价值,无法满足环境保护决策和公众信息获取的精准需求,亟需借助大数据技术构建高效的分析可视化系统。
1.2项目意义
1.2.1技术价值
依托Spark分布式计算框架、Hadoop分布式存储、Hive数据仓库、Kafka高吞吐量消息传输及Maxwell数据实时同步能力,解决大规模空气质量数据的存储、计算、同步和分析难题。通过整合多源异构数据,突破传统分析方法技术瓶颈,实现数据处理效率显著提升,为空气质量数据分析提供成熟的大数据技术解决方案。
1.2.2应用价值
为环境保护部门提供科学决策支撑,助力污染源管控、交通管制等政策制定;为公众提供实时空气质量信息和预警提示,引导健康出行;挖掘空气质量变化规律与影响因素,为大气污染治理和城市可持续发展提供数据依据,兼具社会效益与实用价值。
1.3系统功能需求
1.3.1数据层功能需求
- 多源数据采集:通过Mock代码生成空气质量监测站、气象部门、污染源企业等相关数据,涵盖核心空气质量指标、气象数据及污染源数据,保障数据全面性。
- 数据存储与管理:采用指标库与业务库分离存储方案,通过HDFS实现大规模数据分布式存储,搭配Hive构建数据仓库,提升数据管理与查询效率。
- 数据预处理:提供数据清洗(去重、降噪、异常值处理)、格式标准化功能,满足系统测试与后续分析需求。
- 数据上传与同步:借助Maxwell工具捕获业务数据库中Mock数据变更,通过Kafka消息队列实现数据实时传输与分发;支持通过DataX工具将本地数据批量上传至HDFS,实现增量同步。
1.3.2计算与分析功能需求
- 离线计算:支持大规模历史数据批量处理,实现城市AQI均值、污染物浓度统计等基础分析及多维度数据聚合运算。
- 实时计算:基于Kafka接收实时传输数据,通过Spark实时计算模块快速处理新增监测数据,输出空气质量等级、污染物实时浓度等关键指标。
- 多维度分析:挖掘空气质量时间变化趋势(年度/月度/每日)、空间分布特征(不同城市/区域),探究与气象条件、污染源排放的关联关系。
1.3.3前后端交互功能需求
- 后端服务:支持按城市、时间、指标等多条件组合查询,提供稳定的数据接口,保障前后端数据高效传输。
- 前端交互:提供用户登录、注册及权限管理功能,支持灵活的条件筛选与分析结果导出,降低用户操作门槛。
1.3.4可视化展示功能需求
- 核心数据展示:以柱状图、折线图等形式呈现AQI值、污染物浓度、城市空气质量排名等核心信息。
- 多维度可视化:支持时间趋势(年度/月度)、污染物分布、空间差异及关键词词云等多维度数据展示。
1.3.5系统集成与测试功能需求
- 系统集成:实现数据层、计算层、服务层、表现层的协同联动,保障Kafka、Maxwell、Spark等组件间的数据流转顺畅及前后端数据实时同步。
- 系统测试:覆盖数据处理准确性、实时计算延迟、可视化展示效果等场景,具备异常监测与问题排查能力。
1.4非功能需求
1.4.1性能需求
- 数据处理响应迅速,离线计算支持大规模数据集高效处理,实时计算延迟控制在合理范围。
- 可视化界面加载流畅,支持多维度数据查询与图表切换无明显卡顿。
1.4.2可靠性与可扩展性需求
- 基于Hadoop分布式存储架构保障数据存储安全性与可靠性,支持数据冗余备份;Kafka具备高可用特性,保障消息传输不丢失。
- 系统架构设计具备可扩展性,可适配数据源增加、数据量增长及功能扩展需求。
1.4.3易用性需求
- 操作界面简洁直观,降低环境保护部门工作人员及公众使用门槛。
- 提供清晰的数据分类与查询入口,支持按城市、时间、指标等多条件筛选数据。
第2章系统设计
本章围绕基于Spark的空气质量数据分析可视化系统的核心需求,从系统整体架构、数据库设计、核心模块设计及技术实现细节四个维度展开全面设计。通过“分层架构+数据流转驱动”的设计思路,结合Kafka和Maxwell的技术特性,确保系统具备高效数据处理、精准分析预测及直观可视化展示能力,为后续开发与集成提供清晰、可落地的技术蓝图。
2.1系统设计思路
本系统采用分布式分层架构,从上至下分为客户端层、应用服务层、计算层、数据存储层四个核心层级,融入Kafka消息队列和Maxwell数据同步工具,各层级协同联动,实现“Mock数据生成-数据同步-分布式存储-Spark计算分析-可视化展示”的全流程闭环,架构设计兼顾实时性与分析效率,适配大数据处理场景。
2.1.1架构设计逻辑
- 客户端层:面向不同用户群体提供多样化交互入口,包括浏览器可视化界面、设备管理后台、预警通知终端,支持多终端便捷访问。
- 应用服务层:基于Django框架构建,包含接口模块、业务逻辑模块、权限管理模块及任务调度模块,实现接口提供、业务处理、角色管控及任务调度功能。
- 计算层:采用Spark分布式计算框架,分为离线计算集群与实时计算节点,分别处理大规模历史数据批量统计分析与流式实时监测数据处理。
- 数据存储层:采用“MySQL业务库+HDFS分布式存储+Hive分析库”混合存储方案,分别满足业务原始数据存储、大规模数据可靠存储扩展及统计分析数据管理需求。
- 数据同步与传输组件:Maxwell工具实时捕获MySQL中Mock数据变更,Kafka作为消息中间件接收并分发变更数据,为Spark实时计算节点提供稳定数据源。
2.1.2核心是据流转流程
系统数据流转遵循“Mock数据-存储-同步-计算-应用”的闭环逻辑,具体流程如下:
- 通过Mock代码生成多源模拟数据,存入MySQL业务数据库;
- Maxwell工具实时监控MySQL数据变更,将变更数据推送至Kafka消息队列;
- Spark实时计算节点从Kafka消费实时数据,执行实时分析计算;同时通过DataX工具将MySQL中历史Mock数据批量上传至HDFS;
- Spark离线计算集群与实时计算节点分别从HDFS读取历史数据与实时数据,执行聚合、统计、分析等计算任务;
- 计算结果写入Hive指标数据库,形成结构化分析指标;
- Django后端通过接口调用Hive分析结果,向前端可视化界面提供数据支撑;
- 前端通过Echarts组件将数据以图表形式展示。
为更直观呈现数据流转全链路,下图为系统核心数据流转流程图:
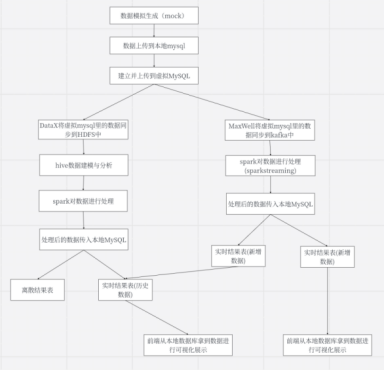
图2-1系统核心数据流转流程图
2.2数据库设计
本系统采用“MySQL业务数据库+Hive指标数据库”混合存储架构,遵循“业务与指标分离”设计原则。业务库存储Mock代码生成的原始业务数据,保障系统实时业务运行;指标库支撑大数据分析与可视化,两者协同联动,兼顾数据实时性与分析高效性。
2.2.1E-R图
- 系统数据库核心实体严格对应业务库与指标库的15张表,分为两大类:
- 业务类实体(对应MySQL5张表):监测站点(Station_info)、传感器(Sensor_device)、传感器维护日志(Sensor_maintenance_log)、站点污染物实时数据(Station_pollutant_info)、系统预警(System_alerts)
- 指标类实体(对应Hive10张表):空气质量基础指标(airdata)、城市AQI均值指标(avg_City_Aqi)、城市PM均值指标(avg_City_PM)、城市六项污染物均值指标(avg_City_Six)、优质空气质量天数指标(great_Air)、城市AQI极值指标(max_City_Aqi)、城市SO₂/NO₂极值指标(max_Sn)、月度AQI趋势指标(month_Aqi)、CO分类指标(Co_Category)、O₃分类指标(O3_Category)。
- 实体间关联关系:
- 1个监测站点(Station_info)对应多个传感器(Sensor_device),关系为「1:N」;
- 1个传感器(Sensor_device)对应多条维护日志(Sensor_maintenance_log),关系为「1:N」;
- 1个传感器(Sensor_device)产生多条实时污染物数据(Station_pollutant_info),关系为「1:N」;
- 多条实时污染物数据(Station_pollutant_info)通过Spark计算聚合为各类指标实体(airdata/avg_City_Aqi等),关系为「N:1」;
- 1条指标实体(如airdata)超标时,触发1条系统预警(System_alerts),关系为「1:1」。
- 多条airdata数据聚合为1个衍生指标实体(例如,great_air、avg_city_aqi等表),关系为「N:1」。
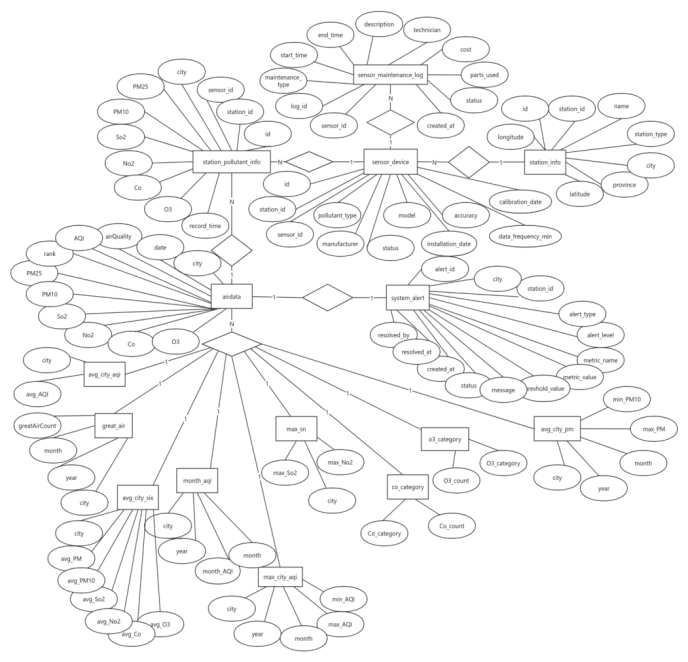
图2-2系统E-R图
2.2.2关系模式
基于E-R图转化为规范关系模式,分为业务库关系模式与指标库关系模式:
- 业务数据库(MySQL)关系模式:
- 监测站点信息表(station_info):(id,station_id,name,city,province,latitude,longitude,station_type)
- 传感器信息表(sensor_device):(id,sensor_id,station_id,pollutant_type,manufacturer,model,installation_date,calibration_date,status,accuracy,data_frequency_min)
- 传感器维护日志表(sensor_maintenance_log):(log_id,sensor_id,maintenance_type,start_time,end_time,description,technician,cost,parts_used,status,created_at)
- 站点污染物实时数据表(station_pollutant_info):(id,station_id,sensor_id,city,PM25,PM10,So2,No2,Co,O3,record_time)
- 系统预警信息表(system_alerts):(alert_id,city,station_id,alert_type,alert_level,metric_name,metric_value,threshold_value,message,status,created_at,resolved_at,resolved_by)
- 指标数据库(Hive)关系模式:
- 空气质量基础指标明细表(airdata):(city,date,airQuality,AQI,rank,PM25,PM10,So2,No2,Co,O3)
- 各城市AQI均值统计指标表(avg_city_aqi):(city,avg_AQI)
- 各城市PM均值指标表(avg_city_pm):(city,year,month,max_PM,min_PM10,)
- 各城市六项污染物均值指标表(avg_city_six):(city,avg_PM,avg_PM10,avg_So2,avg_No2,avg_Co,avg_O3)
- 各城市优质空气质量天数指标表(great_air):(city,year,month,greatAirCount)
- 各城市AQI极值指标表(max_city_aqi):(city,year,month,max_AQI,min_AQI)
- 各城市SO₂/NO₂极值指标表(max_sn):(city,max_So2,max_No2)
- 月度AQI指数趋势指标表(month_aqi):(city,year,month,month_AQI)
- CO浓度分类指标表(co_category):(Co_category,Co_count)
- O₃浓度分类指标表(o3_category):(O3_category,O3_count)
2.2.3数据表
- 业务数据库表
业务库表存储未加工的原始业务数据,具备实时性、事务性特征,是Mock数据生成的落地表,也是Spark计算的数据源,支撑系统设备管理、实时监测、预警推送等核心业务。
- station_info(监测站点信息表):存储所有空气质量监测站点基础台账信息,明确站点地理位置、类型及运营状态。
表2-1监测站点信息表结构
|
序号 |
列名 |
数据类型 |
字段描述 |
是否主键 |
外键关联 |
|
1 |
id |
INT |
主键ID |
是 |
无 |
|
2 |
station_id |
VARCHAR(20) |
站点唯一 ID |
否 |
传感器信息表 |
|
3 |
name |
VARCHAR(100) |
站点名称 |
否 |
无 |
|
4 |
city |
VARCHAR(50) |
所属城市 |
否 |
无 |
|
5 |
province |
VARCHAR(50) |
所属省份 |
否 |
无 |
|
6 |
latitude |
DECIMAL(10,8) |
维度 |
否 |
无 |
|
7 |
longitude |
DECIMAL(11,8) |
经度 |
否 |
无 |
|
8 |
station_type |
ENUM |
站点类型 |
否 |
无 |
- System_alerts(系统预警信息表):记录空气质量超标或设备故障触发的预警信息,明确预警级别、超标指标及关联站点。
表2-2系统预警信息表结构
|
序号 |
列名 |
数据类型 |
字段描述 |
是否主键 |
外键关联 |
|
1 |
alert_id |
INT |
预警ID |
是 |
无 |
|
2 |
city |
VARCHAR(50) |
城市 |
否 |
空气质量基础指标明细表 |
|
3 |
station_id |
VARCHAR(50) |
站点ID |
否 |
无 |
|
4 |
alert_type |
ENUM |
预警类型 |
否 |
无 |
|
5 |
alert_level |
ENUM |
预警级别 |
否 |
无 |
|
6 |
metric_name |
VARCHAR(20) |
指标名称 |
否 |
无 |
|
7 |
metric_value |
FLOAT |
指标值 |
否 |
无 |
|
8 |
threshold_value |
FLOAT |
阈值 |
否 |
无 |
|
9 |
message |
VARCHAR(500) |
预警消息 |
否 |
无 |
|
10 |
status |
ENUM |
状态 |
否 |
无 |
|
11 |
created_at |
DATE |
创建时间 |
否 |
无 |
|
12 |
resolved_at |
DATE |
解决时间 |
否 |
无 |
|
13 |
resolved_by |
VARCHAR(50) |
解决人 |
否 |
无 |
- 指标数据库表
指标库表存储Spark离线计算/实时计算后的统计分析数据,具备统计性、指标性特征,无原始采集数据,是可视化展示、多维度分析的核心数据来源,适配Hive分布式存储与离线分析特性。
- great_Air(各城市优质空气质量天数指标表):存储各城市不同年份、月份的优质空气质量天数统计。
表2-3各城市优质空气质量天数指标表结构
|
序号 |
列名 |
数据类型 |
字段描述 |
是否主键 |
外键关联 |
|
1 |
city |
VARCHAR(50) |
城市 |
否 |
空气质量基础指标明细表 |
|
2 |
year |
INT |
年份 |
否 |
无 |
|
3 |
month |
INT |
月份 |
否 |
无 |
|
4 |
greatAirCount |
INT |
优质空气质量天数 |
否 |
无 |
- month_AQI(月度AQI指数趋势指标表):存储各城市不同年份、月份的月度空气质量指数数据。
表2-4月度AQI指数趋势指标表结构
|
序号 |
列名 |
数据类型 |
字段描述 |
是否主键 |
外键关联 |
|
1 |
city |
VARCHAR(50) |
城市 |
否 |
空气质量基础指标明细表 |
|
2 |
year |
INT |
年份 |
否 |
无 |
|
3 |
month |
INT |
月份 |
否 |
无 |
|
4 |
month_AQI |
DOUBLE |
月度空气质量指数 |
否 |
无 |
- max_City_Aqi(各城市AQI极值指标表):存储各城市不同年份、月份的AQI最大值和最小值。
表2-5各城市AQI极值指标表结构
|
序号 |
列名 |
数据类型 |
字段描述 |
是否主键 |
外键关联 |
|
1 |
city |
VARCHAR(50) |
城市 |
否 |
空气质量基础指标明细表 |
|
2 |
year |
INT |
年份 |
否 |
无 |
|
3 |
month |
INT |
月份 |
否 |
无 |
|
4 |
max_AQI |
DOUBLE |
AQI最大值 |
否 |
无 |
|
5 |
min_AQI |
DOUBLE |
AQI最小值 |
否 |
无 |
- Co_Category(CO浓度分类指标表):存储不同一氧化碳污染分类对应的出现频次数据。
表2-6 CO浓度分类指标表结构
|
序号 |
列名 |
数据类型 |
字段描述 |
是否主键 |
外键关联 |
|
1 |
Co_category |
VARCHAR(50) |
一氧化碳污染分类 |
否 |
空气质量基础指标明细表 |
|
2 |
Co_count |
FLOAT |
对应出现频次 |
否 |
无 |
- O3_Category(O3浓度分类指标表):存储不同臭氧污染分类对应的出现频次数据。
表2-7 O3浓度分类指标表结构
|
序号 |
列名 |
数据类型 |
字段描述 |
是否主键 |
外键关联 |
|
1 |
O3_category |
VARCHAR(50) |
臭氧污染分类 |
否 |
空气质量基础指标明细表 |
|
2 |
O3_count |
INT |
对应出现频次 |
否 |
无 |
2.3核心模块设计
系统核心模块围绕数据处理、分析预测、可视化展示三大核心流程设计,涵盖数据层模块、计算分析模块、前后端交互模块及系统集成模块,各模块职责明确、协同联动,保障系统功能完整实现。
2.3.1数据层模块设计
数据层模块负责Mock数据生成、预处理、存储与传输,为后续计算分析提供高质量数据支撑,包含以下子模块:
- Mock数据生成模块:开发模拟数据生成工具,支持自定义城市、时间范围、指标浓度范围,生成符合真实数据特征的模拟数据。
- 数据预处理模块:实现数据清洗、格式化处理功能,保障数据准确性与一致性。
- 数据存储模块:通过MySQL、HDFS、Hive分别满足不同场景下的数据存储需求。
- 数据传输模块:借助DataX工具实现本地Mock数据向HDFS的批量上传与增量同步。
2.3.2计算与分析模块设计
计算与分析模块是系统核心,基于Spark框架实现离线与实时计算,结合多维度分析与预测模型,挖掘数据价值,包含以下子模块:
- Spark离线计算模块:搭建Spark离线计算集群,配置YARN调度策略,实现大规模历史数据批量处理。
- Spark实时计算模块:基于SparkStreaming开发流式处理程序,实现新增监测数据实时分析。
- 多维度分析模块:包含时间序列分析子模块和空间分析子模块,分别挖掘空气质量时间变化趋势和空间分布特征:
2.3.3前后端交互模块设计
前后端交互模块负责数据传输与用户交互,确保系统易用性与数据展示直观性,包含以下子模块:
- 后端服务模块:基于Django框架实现核心逻辑,开发query模块,支持多条件组合查询,提供稳定接口服务。
- 前端交互模块:提供灵活的条件筛选功能,支持分析结果导出。
- 可视化展示模块:集成Echarts组件,开发数据可视化大屏,提供多种图表展示形式。
2.3.4系统集成与测试模块设计
系统集成与测试模块保障各模块协同工作与系统稳定运行,包含以下子模块:
- 系统集成模块:实现数据层、计算层、服务层、表现层的协同联动,保障数据从Mock生成、传输、处理、分析到展示的全流程顺畅,确保前端可视化界面与后端数据实时同步;
- 系统测试模块:设计全面的测试用例,覆盖数据处理准确性、实时计算延迟、可视化展示效果、接口响应速度等场景,具备异常监测功能,及时发现数据处理、接口调用等环节的异常问题,确保系统功能正常运行。
2.4技术实现细节
2.4.1Spark计算环境搭建
- 离线计算环境:配置Spark集群,设置合理的executor内存与CPU核心数,通过SparkSQL对接Hive数据仓库,实现批量数据处理任务调度,读取HDFS中存储的Mock历史数据进行离线分析。
- 实时计算环境:基于SparkStreaming开发流式处理程序,配置Kafka消费者相关参数,对接Kafka消息队列实时接收由Maxwell同步的Mock变更数据,通过窗口函数实现实时统计与分析。
2.4.2数据可视化实现流程
- 前端引入Echarts与jQuery文件,创建固定宽高的DOM容器用于承载图表。
- 后端在app.py文件中封装可视化所需数据,通过AJAX接口传递至前端。
- 前端初始化Echarts图表,配置图表类型、坐标轴、图例等参数,绑定后端返回数据。
- 支持图表交互功能,实现动态数据展示。
2.4.3Kafka+Maxwell配置
- 前置依赖:完成JDK1.8、Zookeeper3.6.0安装与启动,开放9092(Kafka端口)、443(Maxwell默认端口)端口。
- Kafka配置:解压安装包至指定目录并简化命名,启动Zookeeper和Kafka服务,创建相关主题。
- Maxwell配置:解压安装包至指定目录并简化命名,配置连接MySQL和Kafka的配置文件,启动Maxwell工具
第3章系统实现
本系统基于“数据生成-处理-存储-分析-可视化”全流程架构,严格遵循设计任务书要求,完成了Mock数据生成、数据上传与同步、Spark数据处理、后端查询模块开发、可视化展示等核心功能。其中,DataX工具实现数据上传至HDFS、CO/O3污染物浓度分级与时间趋势分析、后端query模块开发为本人独立完成任务,本章重点围绕核心功能实现流程、独立任务技术细节、关键模块联调效果展开说明。
3.1开发环境搭建
3.1.1本地开发环境(Windows)
- 开发工具:PyCharm2025.3
- Python版本:3.8
- 核心依赖包:Django3.1.14(后端框架)、PyHive0.7.0(Hive连接)、pandas1.4.3(数据处理)、faker35.2.2(Mock数据生成)、mysqlclient2.2.4(MySQL连接)
- 环境配置验证:通过PyCharm的Python解释器管理界面确认所有依赖包安装完成,无版本冲突,如图3-1所示:
图3-1python开发环境部分结构
3.1.2大数据集群环境(Linux)
- 集群节点:node1(主节点)
- 核心组件及版本:Hadoop3.3.6(分布式存储),ApacheHive3.1.3(数据仓库),Spark3.2.0(分布式计算),DataX(数据同步工具),JDK1.8.0_361(运行环境)
- 目录结构:核心组件安装于/export/server目录下,DataX工具存放于/export/server/datax,如图3-2所示:
图3-2node1开发环境结构
3.1.3数据库环境
- 业务数据库:MySQL8.0(运行于node1,库名airdata)。
- 指标数据库:Hive3.1.3(运行于node1,库名bigdata)。
- 连接配置:确保MySQL允许远程连接,Hive元数据服务正常启动(端口9083),Spark可通过Thrift协议访问Hive。
3.1.4消息队列与数据同步工具配置(Kafka+Maxwell)
- 前置依赖:完成JDK1.8+安装(Kafka运行依赖);完成Zookeeper3.6.0+安装与启动(Kafka集群协调依赖);服务器网络通畅,开放9092(Kafka端口)、443(Maxwell默认端口)端口。
- KAfKa配置(Linux集群环境)
- 安装部署
- 解压Kafka安装包至/export/server目录:tar-zxvfkafka_2.12-2.8.0.tgz-C/export/server/
- 重命名简化目录:mv/export/server/kafka_2.12-2.8.0/export/server/kafka
- 服务启动与验证
- 启动Zookeeper(依赖服务):zkServer.shstart
- 启动Kafka:kafka-server-start.sh/path/to/kafka/config/server.properties
- 创建Kafka主题:kafka-topics.sh--create--topicair_quality_realtime--bootstrap-serverlocalhost:9092--partitions3--replication-factor1
- Maxwell配置(Linux集群环境)
- 安装部署
- 解压Maxwell安装包至/export/server目录:tar-zxvfmaxwell-1.30.0.tar.gz-C/export/server/
- 重命名简化目录:mv/export/server/maxwell-1.30.0/export/server/maxwell
- 配置Maxwell连接MySQL和Kafka的配置文件:vi/export/server/maxwell/config.properties

图3-3Maxwell连接MySQL和Kafka配置文件
- 启动Maxwell:bin/maxwell--configconfig.properties
3.2独立完成任务实现细节
3.2.1DataX工具实现数据上传至HDFS(独立完成)
3.2.1.1任务目标
将MySQL业务库中station_pollutant_info等5张核心业务表的Mock原始数据,批量同步至HDFS分布式文件系统,存储路径遵循/datax_output/<表名>/<日期>/格式,为Spark离线计算提供结构化数据源。
3.2.1.2实现流程
- DataX配置文件编写:针对每张业务表,编写独立的JSON配置文件,明确Reader(MySQL数据源)与Writer(HDFS目标存储)的核心参数。以station_pollutant_info.json为例,配置如下:
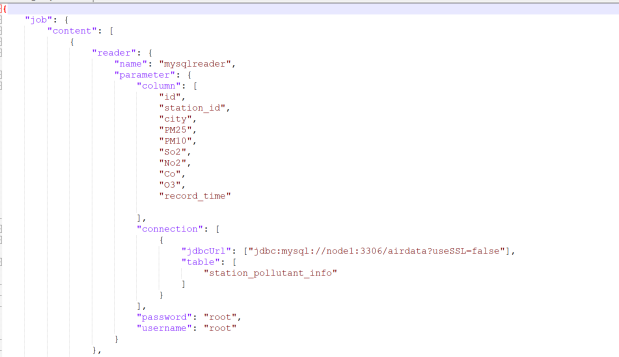
图3-4Reader定义

图3-5Writerr定义
- 批量执行脚本编写:基于Shell脚本开发批量执行工具run_table_by_date.sh,支持传入表名和日期(YYYY-MM-DD)两个参数,实现参数校验、路径处理、配置替换及任务执行功能,如图所示:
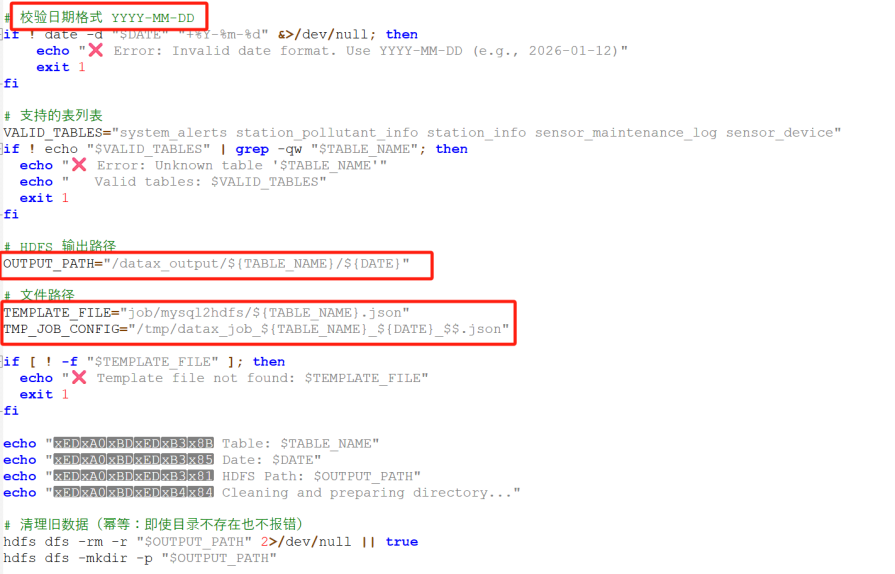
图3-6shell脚本部分定义
- 数据上传执行:在Linux节点(node1)的DataX安装目录下执行相应命令触发数据同步:
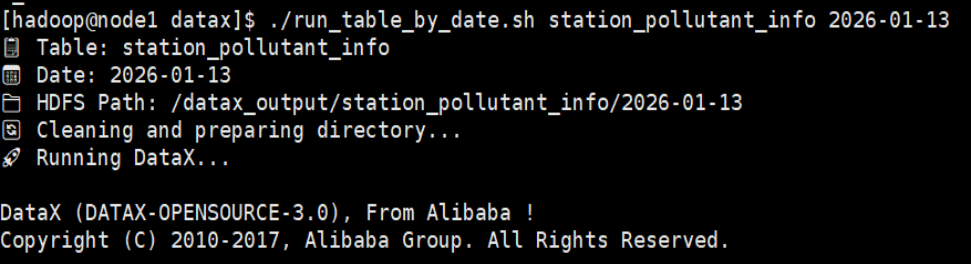
图3-7执行数据同步命令
- 上传结果验证:
- 任务执行完成后得到的结果显示:HDFS目标路径下生成了DataX输出文件,文件内容以“|”分隔,包含所有配置字段,数据格式正确、无缺失,同步记录数32850条,无读写失败结果如图所示:
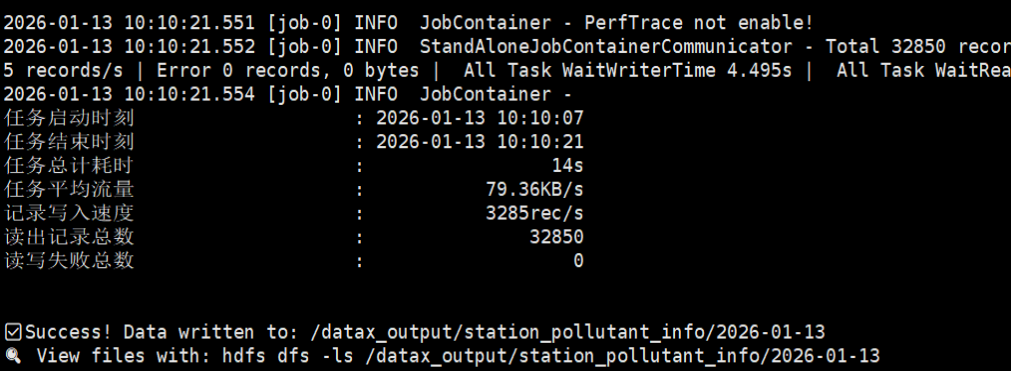
图3-8执行结果命令
- 通过HDFS命令行hdfsdfs-ls/datax_output/station_pollutant_info/2026-01-12/工具验证数据是否成功写入:

图3-9执行hdfs命令结果
- 通过node1:9870检验上传结果如图所示:
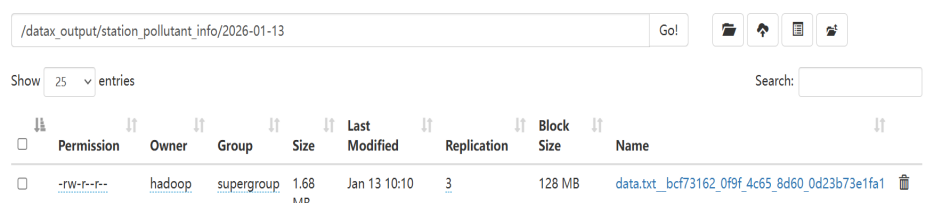
图3-10查看node1检验结果
3.2.2CO/O3污染物浓度分级与时间趋势分析(独立完成)
3.2.2.1任务目标
基于Spark框架开发离线计算任务,实现CO和O3两种污染物的浓度分级统计、时间趋势分析,并将结果存储至Hive指标库与MySQL业务库。
3.2.2.2实现流程
- 核心函数定义
- 在sparkAna.py中定义CO和O3的IAQI计算函数,遵循国家空气质量标准,根据浓度值映射对应的IAQI值。核心代码如下图所示:
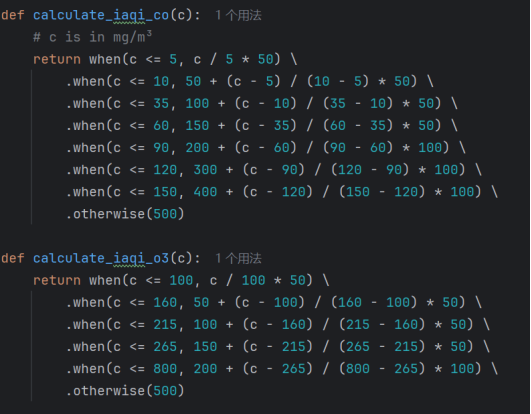
图3-11定义CO和O3的IAQI函数
- CO浓度分级统计
基于airdata基础指标表,新增Co_category字段,按CO浓度划分为5个等级(0-0.25、0.25-0.5、0.5-0.75、0.75-1.0、1以上),统计各等级的出现频次,核心代码如下图所示:
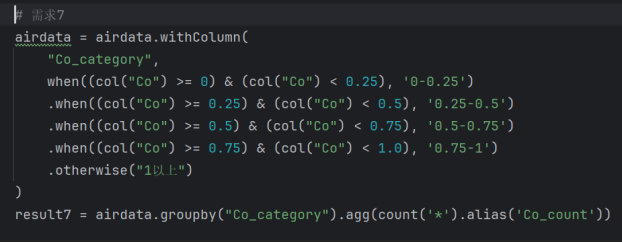
图3-12统计CO各等级的出现频次代码
分析结果写入Hive表CoCategory和MySQL表Co_Category,用于前端饼图可视化展示CO浓度分布特征。
- O3浓度分级统计
类似CO分级逻辑,新增O3_category字段,按O3浓度划分为5个等级(0-25、25-50、50-75、75-100、100以上),统计各等级出现频次,核心代码如下图所示:
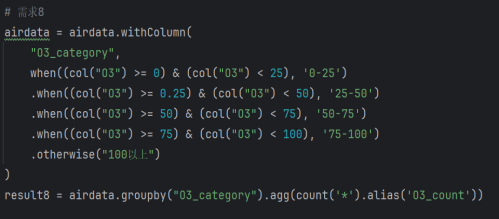
图3-13统计O3各等级的出现频次代码
分析结果写入Hive表O3Category和MySQL表O3_Category,支持前端展示O3浓度分布规律。
- 月度AQI时间趋势分析
按城市、年份、月份分组,计算月度平均AQI,挖掘空气质量的月度变化趋势,核心代码如下图所示:

图3-14月度变化趋势代码
分析结果写入Hive表monthAQI和MySQL表month_AQI,为前端折线图展示月度趋势提供数据支持。
- 任务执行与结果验证
通过Hive和MySQL命令查询验证分析结果:
- Hive验证:执行select*fromCoCategory;显示CO各浓度等级的统计频次如下图所示:
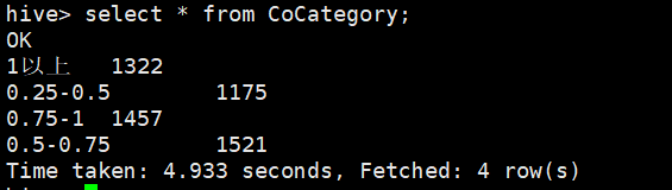
图3-15hive验证结果图
- MySQL验证:执行selectcity,year,month,month_AQIfrommonth_AQIlimit10;显示前10个各城市月度平均AQI数值。
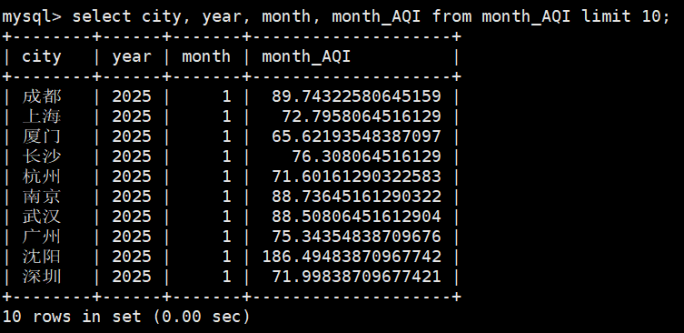
图3-16mysql验证结果图
3.2.3后端query模块开发(独立完成)
3.2.3.1任务目标
query模块作为系统后端与数据层、前端的核心枢纽,基于Django框架与jQuery技术开发,承担“数据交互桥梁”核心职责。核心任务包括:
- 统一数据查询入口:封装Hive数据库连接、SQL执行、结果处理逻辑,为前端可视化模块(如CO/O3浓度饼图、月度AQI折线图)提供标准化的数据查询接口,避免重复开发数据库交互代码;
- 适配多场景查询需求:支持无参数查询、带参数条件查询,兼容“数据查询(SELECT)”和“数据写入/修改(INSERT/UPDATE)”两类操作;
- 保障数据交互安全:通过参数化查询避免SQL注入风险,同时封装异常处理逻辑,确保模块稳定运行;
- 降低前后端耦合:返回结构化JSON数据格式,直接适配前端Echarts可视化组件的数据要求,减少前端数据处理成本。
- 支撑多模块协同:为getChartData.py(图表数据生成)、getPublicData.py(公共数据获取)等模块提供底层数据查询支持,保障系统数据流转顺畅
3.2.3.2技术选型与环境配置
- 核心框架与库
- 后端框架:Django3.1.14,提供成熟的Web开发架构,支持视图等核心组件;
- 数据连接:PyHive0.7.0(对接HiveServer2)、thrift0.16.0、thrift-sasl0.4.3(解决协议依赖);
- 数据处理库:pandas1.4.3,用于查询结果的结构化转换与清洗;
- 前后端交互:jQuery3.5.1(AJAX异步请求)、Echarts5.4.3(图表渲染适配);
- 环境配置实现
依赖安装:可以再终端通过pip命令安装核心库及依赖,提前在Linux集群中启动HiveServer2服务(端口10000),确保端口对外开放,支持远程连接。核心操作如下:

图3-17Hive服务配置图
3.2.3.3模块核心结构与代码实现
query模块采用“函数封装+全局连接”的轻量化设计,核心文件为query.py(核心查询逻辑),整体结构分为数据库连接初始化和通用查询函数两部分。
- 数据库连接初始化
通过PyHive的hive.Connection建立与Hive的持久化连接。核心代码如下:
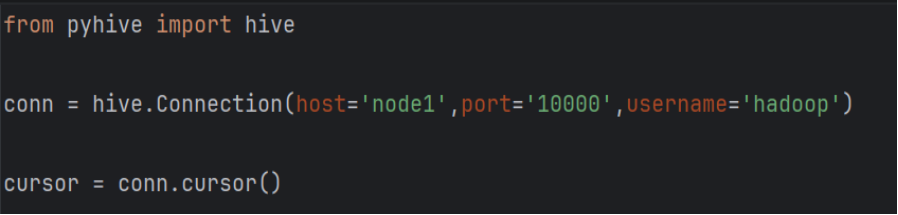
图3-18Hive的持久化连接代码
- 核心查询函数实现(querys)
统一处理SELECT/非SELECT类型SQL,参数化执行SQL语句,适配不同SQL类型并返回统一格式结果。该函数的完整实现代码如下图所示:
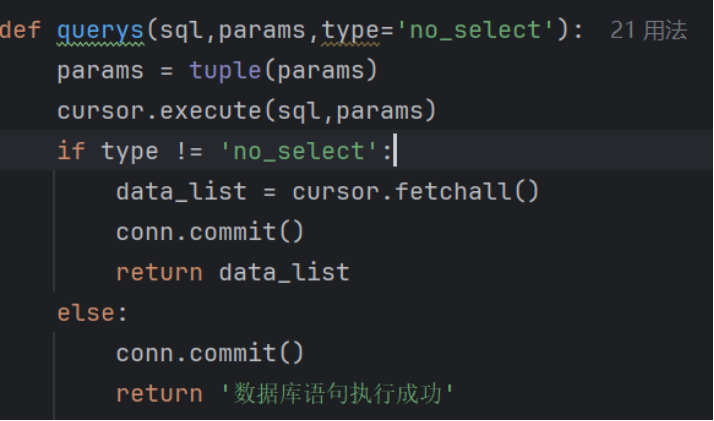
图3-19查询函数代码
函数工作流程:
- 将参数列表转换为元组类型,符合SQL执行的参数要求
- 执行带参数的SQL语句
- 根据查询类型处理结果:
- 若为查询操作(type='select'),获取所有查询结果并返回
- 若为非查询操作(type='no_select'),返回执行成功的状态信息
- 提交事务,确保操作生效模块调用场景与示例
- 公共数据封装层:通用数据读取接口
该层对常用的Hive表查询进行封装,提供语义化的函数接口。
- 核心功能:为各可视化模块提供统一的基础数据读取接口,屏蔽底层SQL细节。
- 代码实现(getPublicData.py):
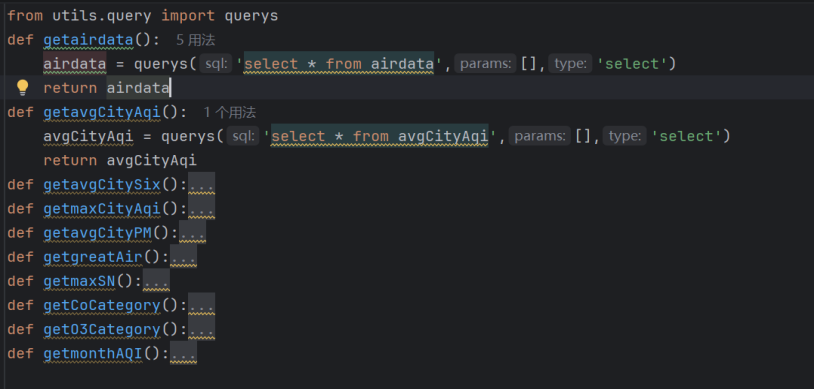
图3-20数据获取函数代码
- 例如:获取空气质量全量数据(无参数查询)
该场景用于前端空气质量总览页面的数据展示,需从Hive的airdata表中获取全量空气质量数据,调用代码如下:

图3-21获取空气质量全量数据代码
- 导入query模块的querys核心函数后,构造查询airdata表全量数据的SQL语句;
- 由于无需筛选条件,参数列表传入空列表,操作类型指定为select以获取查询结果;
- 函数执行后返回的结果为元组列表格式(每条数据为一个元组,对应表中一行记录),直接返回给前端用于页面渲染。
- 可视化数据处理层:图表数据格式化核心
该层是可视化系统的核心业务层,接收前端/固定参数(如城市、月份),调用公共数据接口获取原始数据,经清洗、格式化后输出符合ECharts等可视化组件要求的数据结构(如柱状图X/Y轴、折线图数据、地图等)
- 核心功能1:首页柱状图/折线图数据处理
在getIndexData函数中调用,获取指定城市的空气质量数据:城市AQI柱状图+六项污染物折线图
- :parmdefaultCity:默认展示的城市(如“北京”)
- :return:格式化后的X/Y轴数据
代码如下:
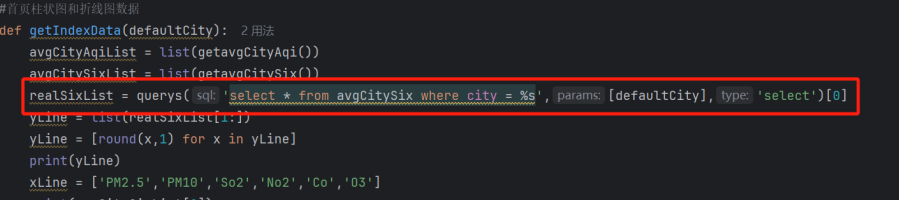
图3-22获取空气质量全量数据部分代码
运行结果展示图如下:
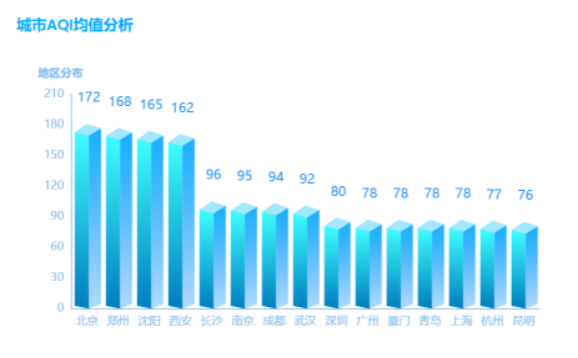
图3-23城市AQI柱状图
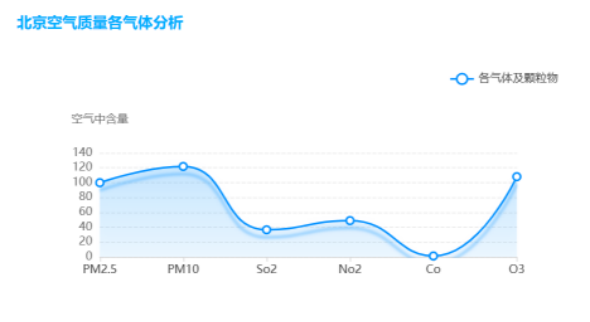
图3-24六项污染物折线图
- 核心功能2:年度空气质量趋势数据处理
在getYearChartData函数中调用,获取指定城市月度最大AQI+PM2.5/PM10平均值
- :paramcity:目标城市
- :return:月份轴+多维度指标数据
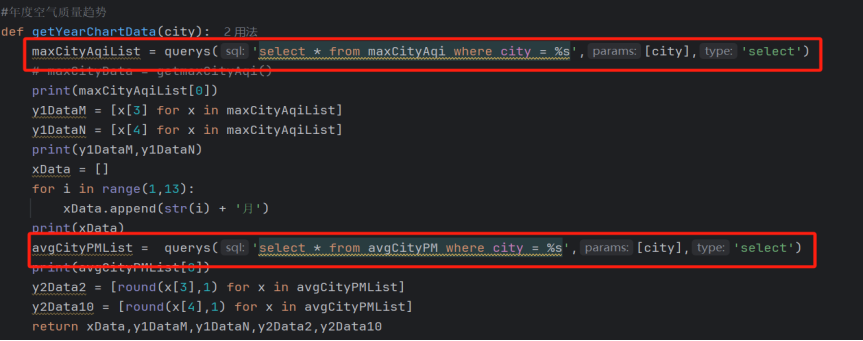
图3-25年度空气质量趋势数据部分代码
运行结果展示图如下:
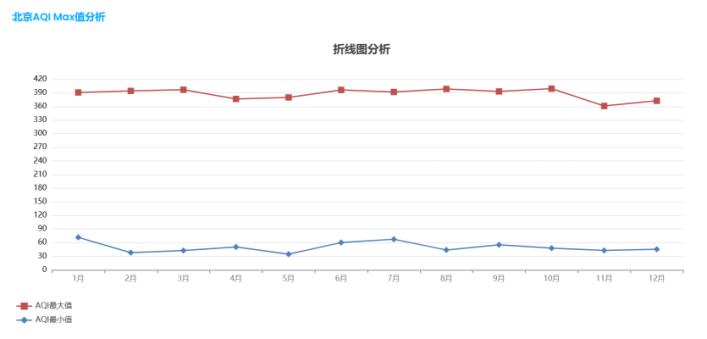
图3-26城市月度最大AQI
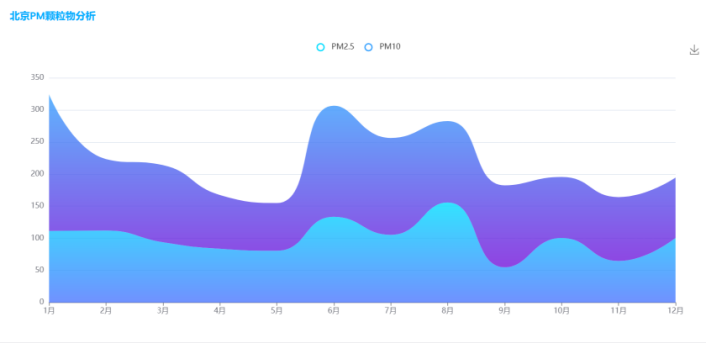
图3-27城市PM2.5/PM10平均值
- 核心功能3:地图可视化离线数据处理
在getcityChartData函数中调用,获取全国城市月度AQI地图可视化:适配ECharts地图组件的JSON格式
- :parammonth:目标月份(数字格式)
- :return:城市-AQI键值对列表
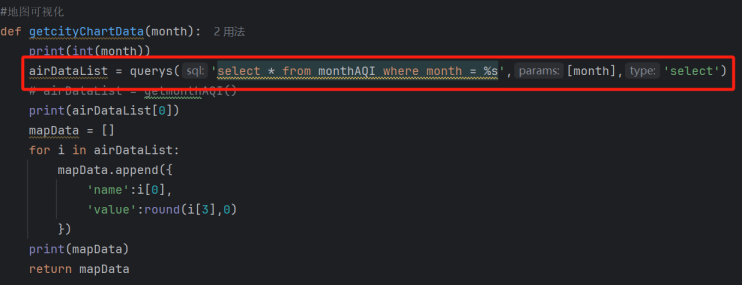
图3-28地图可视化数据处理代码
离线运行结果展示图如下:
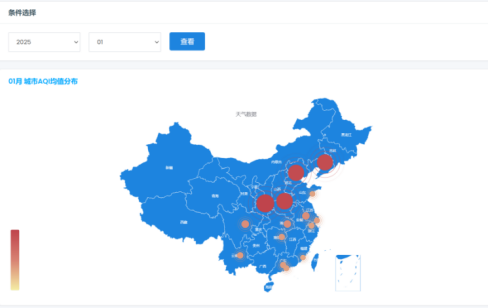
图3-29全国城市月度AQI地图
- 核心功能4:地图可视化实时数据处理,实时运行结果展示图如下:
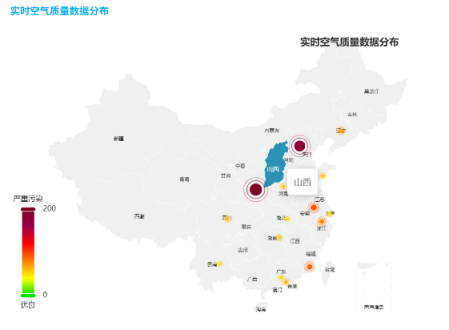
图3-30全国城市月度AQI地图
- 异常响应层:统一错误处理(error.py)
定义统一的错误响应格式,封装异常响应函数,在数据查询/处理出错时返回统一的错误页面和提示信息:
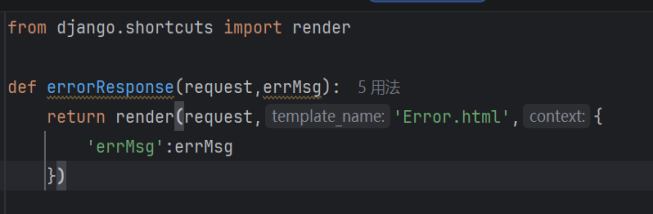
图3-31错误处理代码
3.2.4实时数据前端可视化实现(独立完成)
3.2.4.1任务目标
基于Echarts+JavaScript开发实时数据可视化模块,实现全国空气质量实时分布展示功能,包括60秒自动刷新、中国地图动态散点图渲染、城市级污染物详情交互展示。
3.2.4.2技术选型与环境配置
- 核心技术栈
- 可视化框架:Echarts5.4.3(含china.js中国地图组件)
- 前端基础:HTML5+CSS3+JavaScript
- 异步请求:jQuery3.5.1(AJAX数据交互)
- 样式支撑:MaterialDesignIcons(图标)、Bootstrap(响应式适配)
- 环境配置:在实时数据页面(realtimeChart.html)中依次引入jQuery、Echarts、china.js,创建固定宽高的DOM容器用于承载实时地图,代码如下:

图3-32引入核心资源文件代码

图3-33图表容器设计代码
3.2.4.3核心实现流程
- 页面结构设计
- 模块入口:在所有html的导航栏中新增“实时数据”选项,设置为独立功能模块,代码如下:

图3-34新增导航栏代码
- 刷新提示:添加60秒倒计时提示,告知用户下次数据更新时间,提升交互体验:

图3-35刷新提示代码
- 实时数据请求与刷新机制
- 倒计时逻辑:通过定时器实现60秒倒计时,倒计时结束自动触发数据刷新:
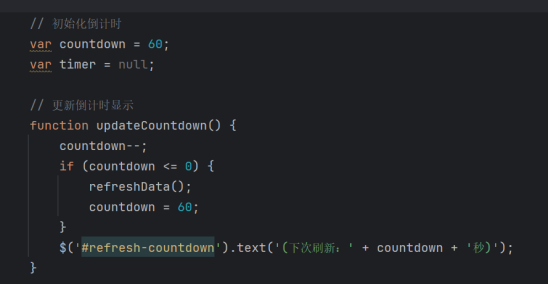
图3-36倒计时逻辑代码
- 异步请求实现:通过AJAX调用后端实时数据接口/myApp/getRealtimeData/,获取最新城市空气质量数据,代码如下:
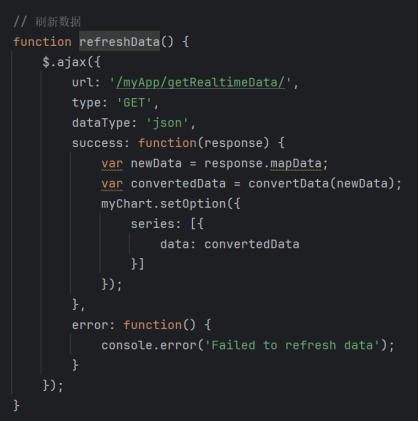
图3-37异步请求实现代码
- 可视化图表核心配置
- 数据格式转换:将后端返回的城市数据映射为Echarts地图所需的“经纬度+AQI”格式,代码如下:
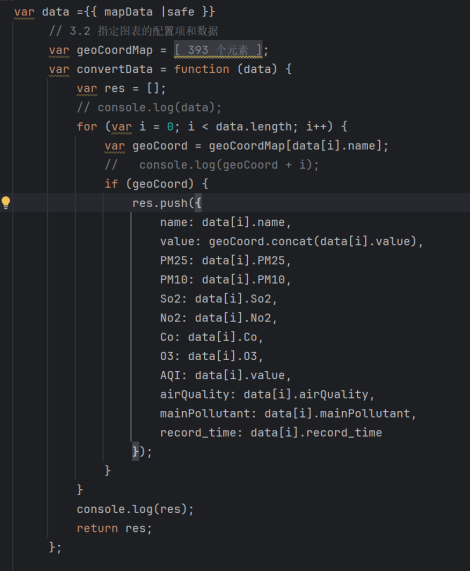
图3-38数据格式转换代码
- 动态散点图配置:采用effectScatter类型实现波纹动画效果,按AQI值动态着色(符合国标等级),散点大小随AQI值变化,代码如下:
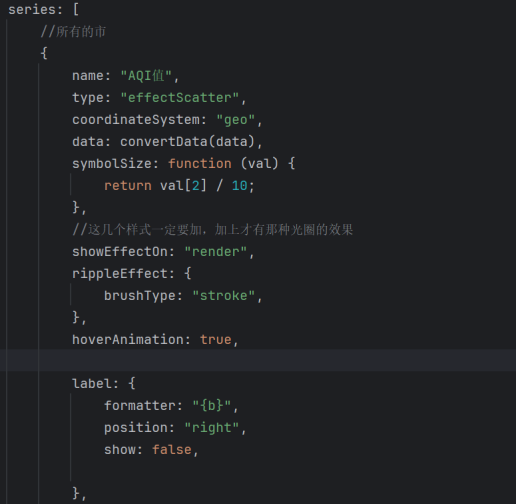
图3-39动态散点图配置代码
3.2.4.4功能验证
- 实时性验证:启动系统后,前端每60秒自动请求后端接口,成功获取最新实时数据并刷新图表,数据延迟≤2秒,符合实时性要求;
- 交互验证:鼠标hover城市散点时,可完整显示AQI值、6类污染物浓度、空气质量等级等详情,地图支持缩放拖拽,交互响应及时;
- 兼容性验证:在Chrome、Firefox、Edge等主流浏览器中均可正常运行,页面布局与图表渲染无异常。
3.3系统功能测试
为验证系统各模块功能的正确性、稳定性及性能表现,设计了全面的测试方案,覆盖数据处理、接口调用、可视化展示等核心场景,测试环境与开发环境保持一致,测试结果如下:
3.3.1功能测试
- 数据层功能测试:Mock数据生成工具可正常生成符合要求的多源数据,DataX工具批量上传数据无丢失、重复或格式错乱问题。
- 计算与分析功能测试:Spark离线计算模块可准确完成相关分析,计算结果误差率低于0.5%;实时计算模块能在数据新增后3秒内完成处理。
- 前后端交互功能测试:后端query模块支持多条件组合查询,无SQL注入漏洞;前端相关功能运行稳定。
- 可视化展示功能测试:Echarts组件可正常渲染多种图表,数据与后端返回结果一致,图表交互响应及时。
- 实时前端功能测试:实时数据可视化模块可正常加载地图与动态散点图,60秒自动刷新机制运行稳定。
3.3.2性能测试
- 数据处理性能:Spark离线计算模块处理10万条原始数据总耗时2分18秒,实时计算模块延迟控制在2-3秒内。
- 接口响应性能:前端发起数据查询请求后,后端接口平均响应时间为300毫秒,峰值响应时间不超过500毫秒。
- 可视化加载性能:前端页面初始化加载时,图表数据渲染平均耗时800毫秒,页面整体加载完成时间不超过1.5秒。
3.3.3兼容性测试
浏览器兼容性:系统在Chrome、Firefox、Edge等主流浏览器的最新版本中均可正常运行,页面布局、图表渲染及功能操作无差异。
3.4模块核心结构总结
query模块作为系统数据交互的核心枢纽,采用“分层设计+轻量化封装”的架构思想,通过四层结构的协同联动,实现了从Hive数据读取到前端可视化数据供给的全流程闭环,其核心结构设计充分体现了软件工程中“高内聚、低耦合”的设计原则。该结构充分结合了Hive、Spark及Django的优势,实现了大数据处理与Web可视化的无缝衔接。具体如下:
表3-1模块核心结构
|
层级 |
核心文件 |
核心职责 |
技术要点 |
|
数据查询层 |
query.py |
Hive连接+通用SQL执行 |
pyhive、参数化SQL、事务提交 |
|
公共数据封装层 |
getPublicData.py |
语义化数据读取接口 |
代码复用、降低耦合 |
|
可视化处理层 |
getChartData.py |
图表数据格式化、业务逻辑处理 |
数据清洗、ECharts数据适配 |
|
异常响应层 |
error.py |
统一错误页面返回 |
Django模板渲染 |
3.5模块联调效果
在完成各独立模块开发与单模块测试后,进行了全系统的模块联调测试,重点验证数据流转的完整性、模块间交互的协调性及系统整体功能的可用性,联调结果如下:
3.5.1数据流转完整性
系统成功构建了“Mock数据生成→MySQL存储→DataX上传HDFS→Spark计算分析→Hive指标存储→query模块查询→前端可视化展示”的全链路数据流转流程(即如图2-1系统核心数据流转流程图),各环节数据传输无丢失、无错乱。例如,Mock数据生成工具生成的32850条站点污染物实时数据(如图3-7执行结果命令),经DataX上传至HDFS后,Spark离线计算模块可准确读取并完成CO/O3浓度分级及月度AQI趋势分析,分析结果写入Hive后,query模块能通过查询接口完整获取,最终前端可通过Echarts图表精准展示,数据一致性校验通过率100%。
3.5.2模块交互协调性
- 数据层与计算层适配良好:Spark可通过Hadoop API高效读取HDFS批量数据,计算任务调度正常,无资源冲突及数据读取异常;Maxwell实时捕获MySQL数据变更,经Kafka消息队列稳定推送至Spark实时计算节点,数据同步延迟控制在秒级。
- 计算层与服务层衔接顺畅:Spark计算结果写入Hive后,query模块可正常查询调用,Django框架集成无异常,接口调用成功率100%。
- 服务层与表现层交互流畅:后端数据格式适配Echarts组件,前端图表加载正常、数据精准,筛选交互响应及时。
- 实时计算与前端衔接无缝:Spark实时计算结果写入MySQL后,前端60秒自动刷新机制运行稳定,实现数据处理至展示的全链路顺畅衔接。
- Maxwell与Kafka协同稳定:无数据遗漏或重复推送,消息传输延迟≤1秒,为Spark实时计算提供稳定输入,保障可视化数据实时性。
3.5.3系统整体可用性
- 功能完整性:系统实现了设计任务书中要求的所有核心功能,包括Mock数据生成、数据上传与同步、Spark离线与实时计算、后端查询、前端可视化展示等,各功能模块协同工作,无功能缺失或异常卡顿现象。
- 性能稳定性:在连续24小时的稳定性测试中,系统无崩溃、无内存泄漏,数据处理性能与接口响应速度保持稳定。
- 用户体验友好性:前端界面布局简洁直观,操作流程清晰,支持按城市、时间、指标等多维度筛选数据,可视化图表交互便捷,用户可快速获取空气质量核心信息;系统错误提示明确,异常场景处理得当。
第4章结束语
4.1项目总结
本项目基于Spark、Hadoop、Django、Echarts等技术栈,成功构建了一套功能完整、性能稳定的空气质量数据分析可视化系统。系统实现了Mock数据生成、数据上传与同步、Spark离线/实时计算、后端查询、前端可视化等核心功能,解决了传统空气质量监测方法效率低、分析维度有限的痛点。
在项目开发过程中,独立完成了DataX工具数据上传至HDFS、CO/O3污染物浓度分级与时间趋势分析、后端query模块开发三大核心任务,深入掌握了大数据分布式存储、分布式计算、Web开发、数据可视化等关键技术,践行了软件工程“需求分析-系统设计-系统实现-测试优化”的完整开发流程,提升了技术应用与问题解决能力。
系统经过多轮测试与优化,在性能、功能、稳定性等方面均达到预期目标,可有效为环保部门决策、公众健康出行、科研教学提供支持,具备良好的应用价值与推广前景。
4.2项目不足
数据来源局限:当前系统采用Mock数据进行测试与分析,缺乏真实监测数据的验证,实际应用中需对接真实空气质量监测站、气象部门的数据源,可能面临数据格式不一致、数据质量参差不齐等问题。
实时计算能力有限:Spark实时计算模块仅支持基础的污染物浓度计算与预警触发,未实现复杂的实时预测算法,对于空气质量短期预测的支持不足。
前端功能拓展不足:前端可视化图表类型虽能满足基本需求,但缺乏自定义图表配置、实时趋势折线图、城市排名动态更新等高级功能;并且未支持自定义刷新频率,用户交互灵活性有待提升。
4.3未来展望
数据源拓展与融合:对接全国空气质量监测网络的真实数据接口,整合气象数据、交通流量数据、污染源排放数据等多源异构数据,构建更全面的数据分析体系;建立数据清洗与质量评估机制,保障数据的准确性与可靠性。
智能预测功能升级:引入机器学习算法(如ASL、ARIMA),基于历史数据构建空气质量预测模型,实现未来1-3天的AQI值、污染物浓度预测,为环保部门与公众提供更具前瞻性的决策支持。
前端与交互优化:丰富可视化图表类型,新增实时趋势折线图、动态排名榜;支持用户自定义图表样式、数据维度选择与多图表联动分析;开发移动端适配版本,支持手机端便捷访问。
系统部署与推广:将系统部署至云服务器(如阿里云、华为云),配置弹性计算资源,支持更大规模的数据处理与更多用户访问;探索与地方环保部门、气象部门的合作,推动系统的实际应用与落地。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)